 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Multi-Stage Multi-Codebook VQ-VAE Approach to High-Performance Neural TTS
Sep 22, 2022
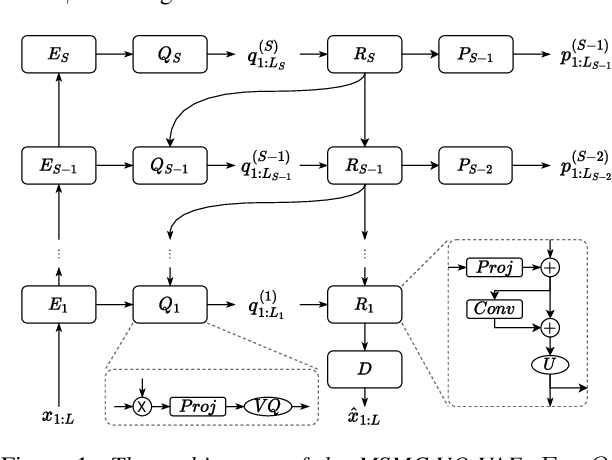
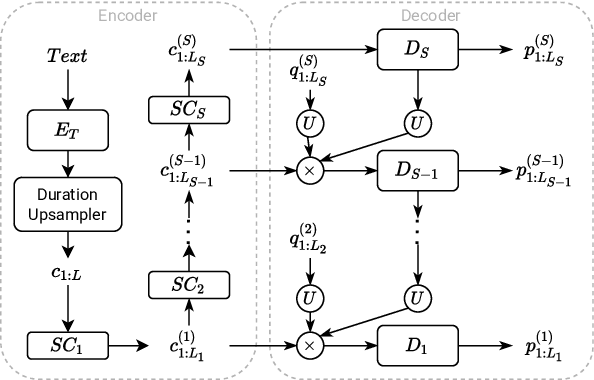
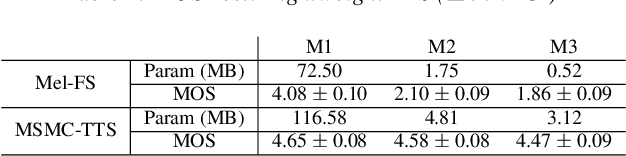
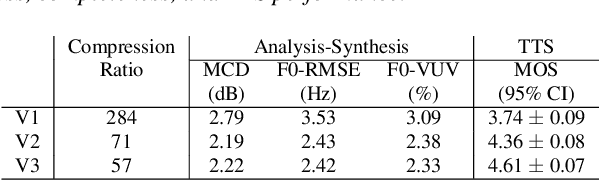
We propose a Multi-Stage, Multi-Codebook (MSMC) approach to high-performance neural TTS synthesis. A vector-quantized, variational autoencoder (VQ-VAE) based feature analyzer is used to encode Mel spectrograms of speech training data by down-sampling progressively in multiple stages into MSMC Representations (MSMCRs) with different time resolutions, and quantizing them with multiple VQ codebooks, respectively. Multi-stage predictors are trained to map the input text sequence to MSMCRs progressively by minimizing a combined loss of the reconstruction Mean Square Error (MSE) and "triplet loss". In synthesis, the neural vocoder converts the predicted MSMCRs into final speech waveforms. The proposed approach is trained and tested with an English TTS database of 16 hours by a female speaker. The proposed TTS achieves an MOS score of 4.41, which outperforms the baseline with an MOS of 3.62. Compact versions of the proposed TTS with much less parameters can still preserve high MOS scores. Ablation studies show that both multiple stages and multiple codebooks are effective for achieving high TTS performance.
FST: the FAIR Speech Translation System for the IWSLT21 Multilingual Shared Task
Aug 14, 2021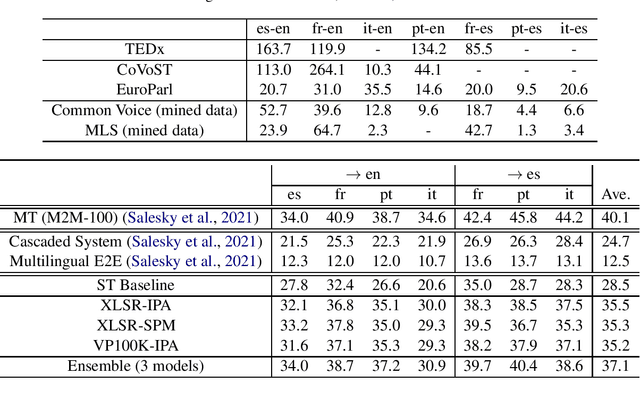
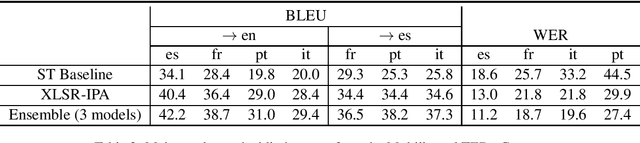
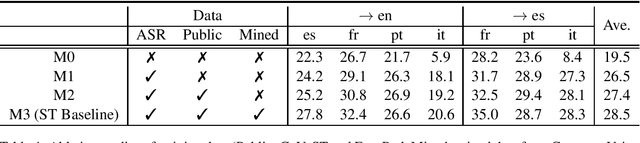
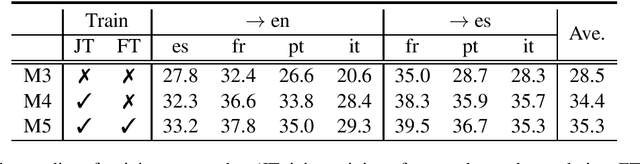
In this paper, we describe our end-to-end multilingual speech translation system submitted to the IWSLT 2021 evaluation campaign on the Multilingual Speech Translation shared task. Our system is built by leveraging transfer learning across modalities, tasks and languages. First, we leverage general-purpose multilingual modules pretrained with large amounts of unlabelled and labelled data. We further enable knowledge transfer from the text task to the speech task by training two tasks jointly. Finally, our multilingual model is finetuned on speech translation task-specific data to achieve the best translation results. Experimental results show our system outperforms the reported systems, including both end-to-end and cascaded based approaches, by a large margin. In some translation directions, our speech translation results evaluated on the public Multilingual TEDx test set are even comparable with the ones from a strong text-to-text translation system, which uses the oracle speech transcripts as input.
Canonical Cortical Graph Neural Networks and its Application for Speech Enhancement in Future Audio-Visual Hearing Aids
Jun 06, 2022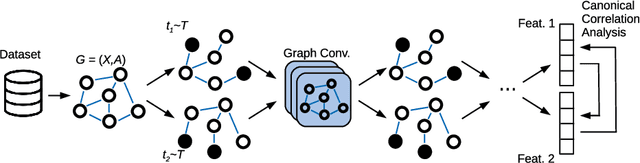
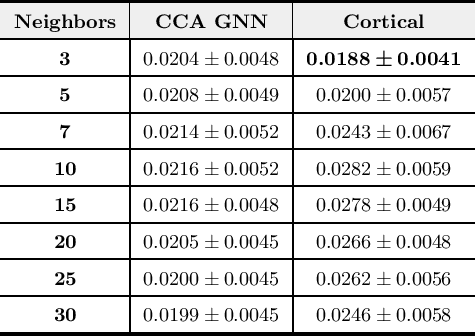
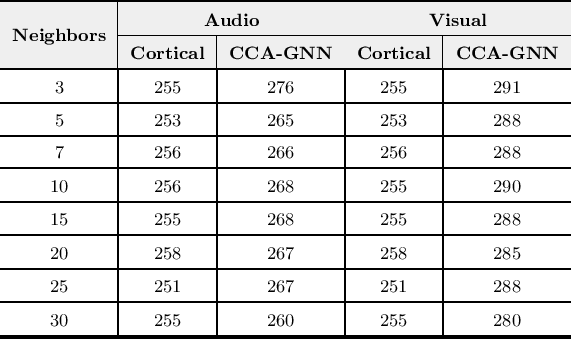
Despite the recent success of machine learning algorithms, most of these models still face several drawbacks when considering more complex tasks requiring interaction between different sources, such as multimodal input data and logical time sequence. On the other hand, the biological brain is highly sharpened in this sense, empowered to automatically manage and integrate such a stream of information through millions of years of evolution. In this context, this paper finds inspiration from recent discoveries on cortical circuits in the brain to propose a more biologically plausible self-supervised machine learning approach that combines multimodal information using intra-layer modulations together with canonical correlation analysis (CCA), as well as a memory mechanism to keep track of temporal data, the so-called Canonical Cortical Graph Neural networks. The approach outperformed recent state-of-the-art results considering both better clean audio reconstruction and energy efficiency, described by a reduced and smother neuron firing rate distribution, suggesting the model as a suitable approach for speech enhancement in future audio-visual hearing aid devices.
Identifying Source Speakers for Voice Conversion based Spoofing Attacks on Speaker Verification Systems
Jun 18, 2022
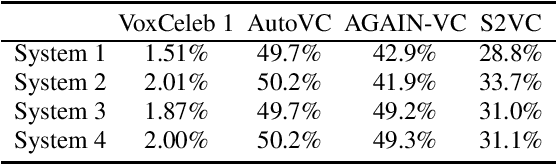


An automatic speaker verification system aims to verify the speaker identity of a speech signal. However, a voice conversion system manipulates the original person's speech signal to make it sound like the target speaker's voice and deceive the speaker verification system. Most countermeasures for voice conversion-based spoofing attacks are designed to discriminate bona fide speech from spoofed speech for speaker verification systems. In this paper, we investigate the problem of source speaker identification -- inferring the identity of the source speaker given the voice converted speech. To perform source speaker identification, we simply add voice-converted speech data with the label of source speaker identity to the genuine speech dataset during speaker embedding network training. Experimental results show the feasibility of source speaker identification when training and testing with converted speeches from the same voice conversion model(s). When testing on converted speeches from an unseen voice conversion algorithm, the performance of source speaker identification improves when more voice conversion models are used during training.
Hate speech detection using static BERT embeddings
Jun 29, 2021
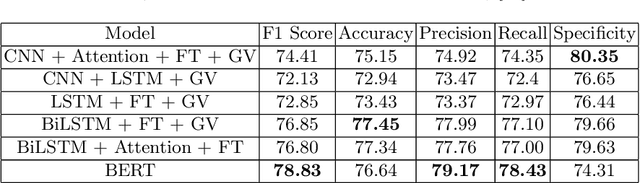
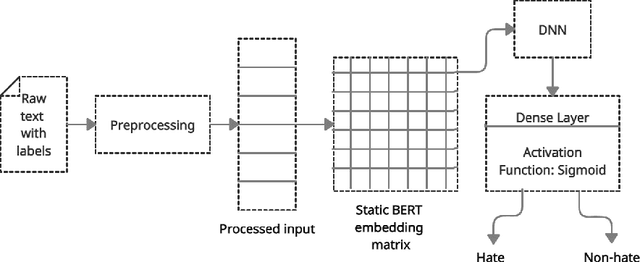
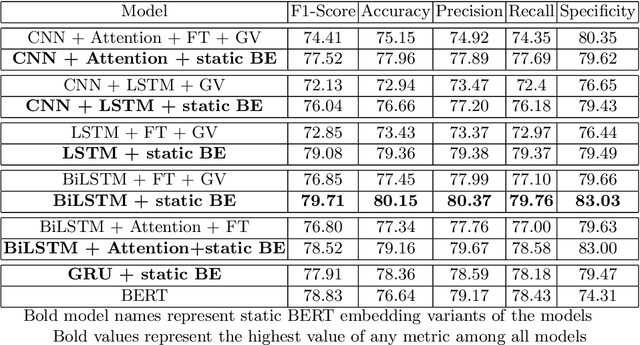
With increasing popularity of social media platforms hate speech is emerging as a major concern, where it expresses abusive speech that targets specific group characteristics, such as gender, religion or ethnicity to spread violence. Earlier people use to verbally deliver hate speeches but now with the expansion of technology, some people are deliberately using social media platforms to spread hate by posting, sharing, commenting, etc. Whether it is Christchurch mosque shootings or hate crimes against Asians in west, it has been observed that the convicts are very much influenced from hate text present online. Even though AI systems are in place to flag such text but one of the key challenges is to reduce the false positive rate (marking non hate as hate), so that these systems can detect hate speech without undermining the freedom of expression. In this paper, we use ETHOS hate speech detection dataset and analyze the performance of hate speech detection classifier by replacing or integrating the word embeddings (fastText (FT), GloVe (GV) or FT + GV) with static BERT embeddings (BE). With the extensive experimental trails it is observed that the neural network performed better with static BE compared to using FT, GV or FT + GV as word embeddings. In comparison to fine-tuned BERT, one metric that significantly improved is specificity.
BLOOM-Net: Blockwise Optimization for Masking Networks Toward Scalable and Efficient Speech Enhancement
Nov 17, 2021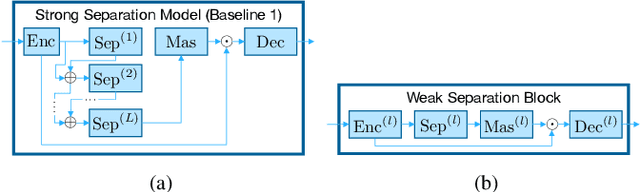
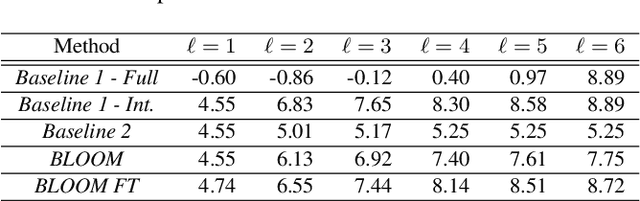
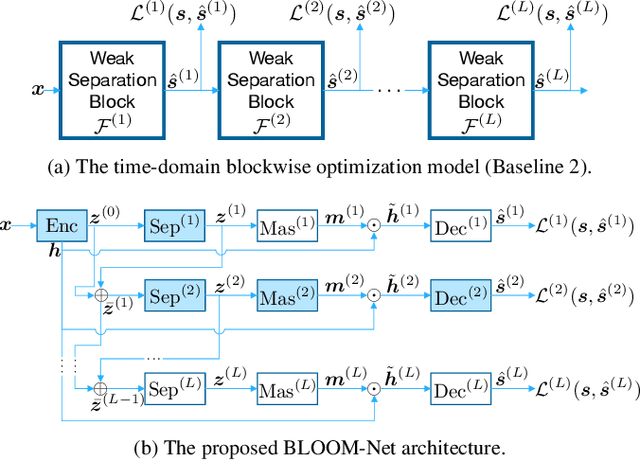

In this paper, we present a blockwise optimization method for masking-based networks (BLOOM-Net) for training scalable speech enhancement networks. Here, we design our network with a residual learning scheme and train the internal separator blocks sequentially to obtain a scalable masking-based deep neural network for speech enhancement. Its scalability lets it adjust the run-time complexity based on the test-time resource constraints: once deployed, the model can alter its complexity dynamically depending on the test time environment. To this end, we modularize our models in that they can flexibly accommodate varying needs for enhancement performance and constraints on the resources, incurring minimal memory or training overhead due to the added scalability. Our experiments on speech enhancement demonstrate that the proposed blockwise optimization method achieves the desired scalability with only a slight performance degradation compared to corresponding models trained end-to-end.
A Conformer Based Acoustic Model for Robust Automatic Speech Recognition
Mar 01, 2022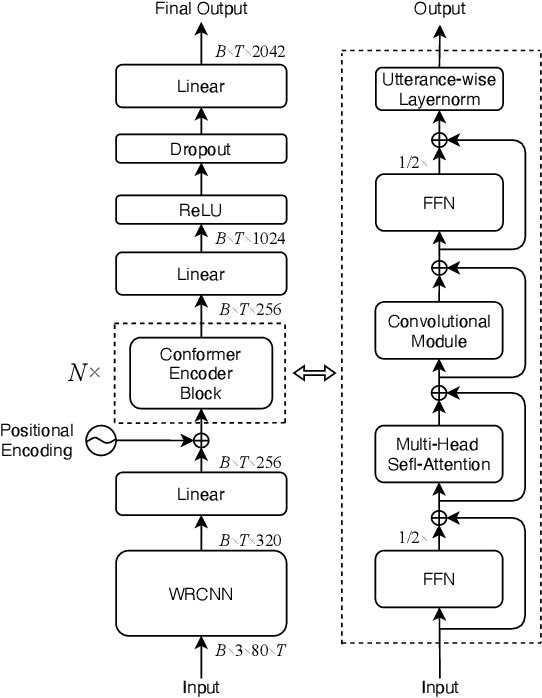
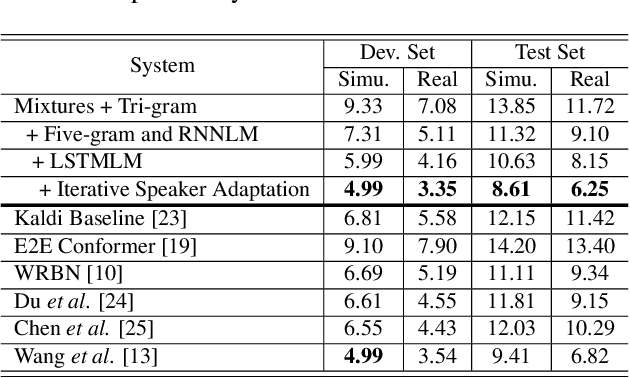
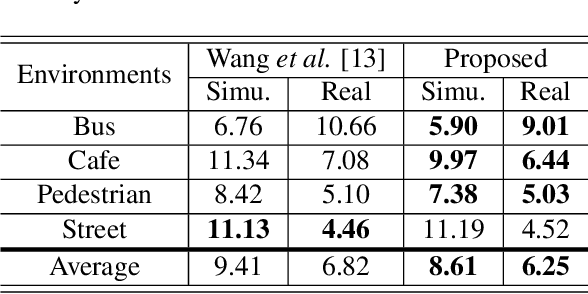
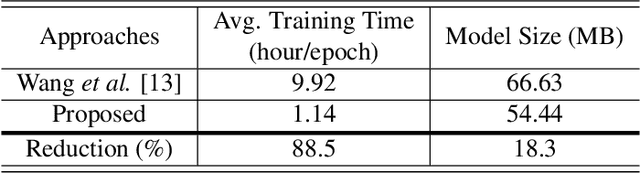
This study addresses robust automatic speech recognition (ASR) by introducing a Conformer-based acoustic model. The proposed model builds on a state-of-the-art recognition system using a bi-directional long short-term memory (BLSTM) model with utterance-wise dropout and iterative speaker adaptation, but employs a Conformer encoder instead of the BLSTM network. The Conformer encoder uses a convolution-augmented attention mechanism for acoustic modeling. The proposed system is evaluated on the monaural ASR task of the CHiME-4 corpus. Coupled with utterance-wise normalization and speaker adaptation, our model achieves $6.25\%$ word error rate, which outperforms the previous best system by $8.4\%$ relatively. In addition, the proposed Conformer-based model is $18.3\%$ smaller in model size and reduces training time by $88.5\%$.
Embedding Recurrent Layers with Dual-Path Strategy in a Variant of Convolutional Network for Speaker-Independent Speech Separation
Mar 25, 2022
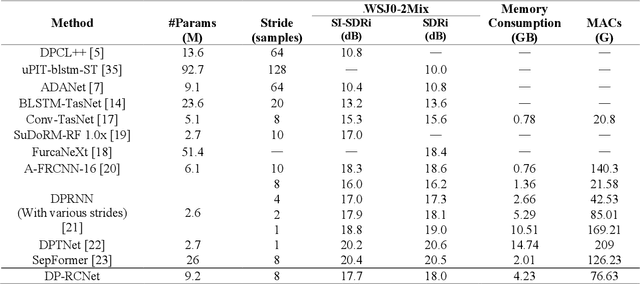
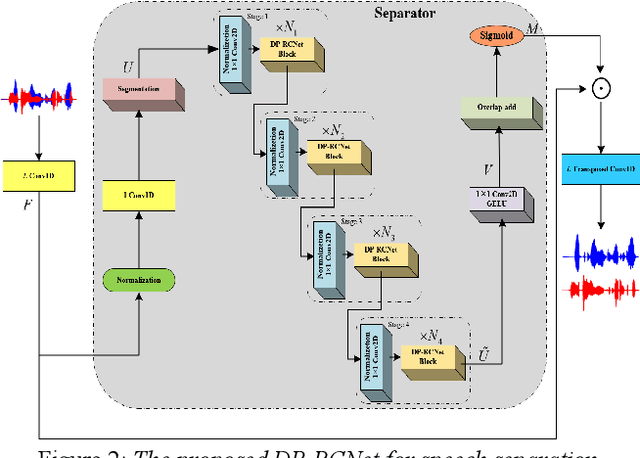
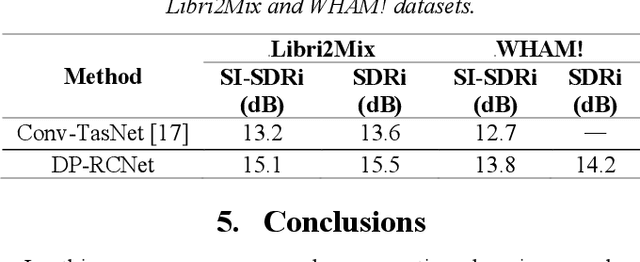
Speaker-independent speech separation has achieved remarkable performance in recent years with the development of deep neural network (DNN). Various network architectures, from traditional convolutional neural network (CNN) and recurrent neural network (RNN) to advanced transformer, have been designed sophistically to improve separation performance. However, the state-of-the-art models usually suffer from several flaws related to the computation, such as large model size, huge memory consumption and computational complexity. To find the balance between the performance and computational efficiency and to further explore the modeling ability of traditional network structure, we combine RNN and a newly proposed variant of convolutional network to cope with speech separation problem. By embedding two RNNs into basic block of this variant with the help of dual-path strategy, the proposed network can effectively learn the local information and global dependency. Besides, a four-staged structure enables the separation procedure to be performed gradually at finer and finer scales as the feature dimension increases. The experimental results on various datasets have proven the effectiveness of the proposed method and shown that a trade-off between the separation performance and computational efficiency is well achieved.
Cross-lingual Capsule Network for Hate Speech Detection in Social Media
Aug 06, 2021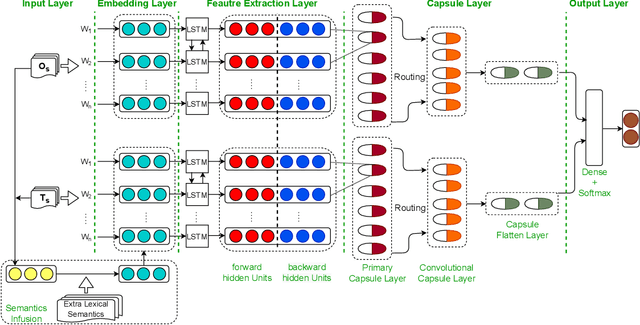
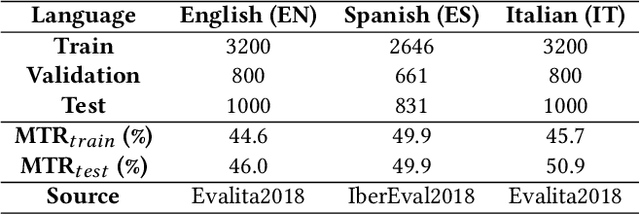
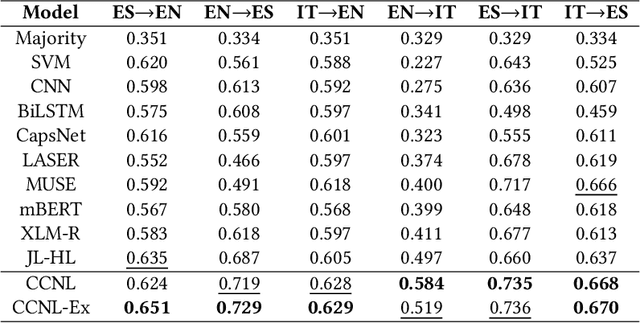
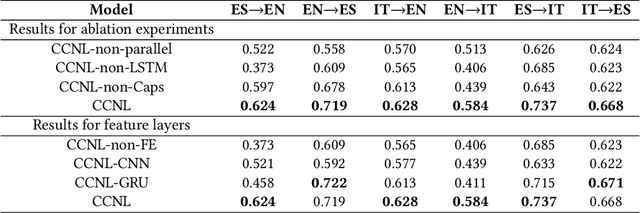
Most hate speech detection research focuses on a single language, generally English, which limits their generalisability to other languages. In this paper we investigate the cross-lingual hate speech detection task, tackling the problem by adapting the hate speech resources from one language to another. We propose a cross-lingual capsule network learning model coupled with extra domain-specific lexical semantics for hate speech (CCNL-Ex). Our model achieves state-of-the-art performance on benchmark datasets from AMI@Evalita2018 and AMI@Ibereval2018 involving three languages: English, Spanish and Italian, outperforming state-of-the-art baselines on all six language pairs.
fairseq S^2: A Scalable and Integrable Speech Synthesis Toolkit
Sep 14, 2021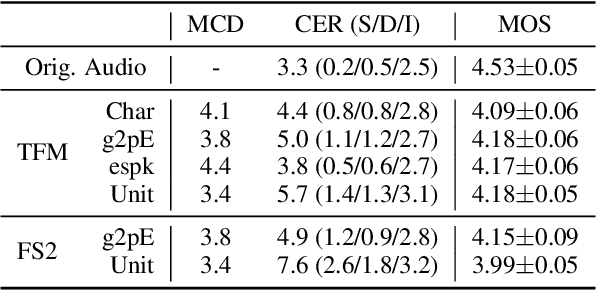
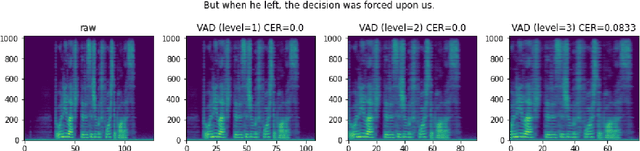

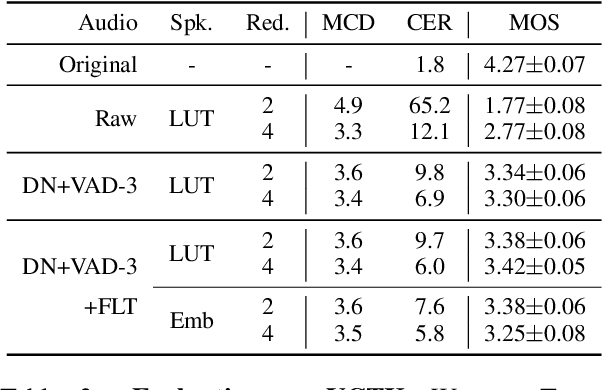
This paper presents fairseq S^2, a fairseq extension for speech synthesis. We implement a number of autoregressive (AR) and non-AR text-to-speech models, and their multi-speaker variants. To enable training speech synthesis models with less curated data, a number of preprocessing tools are built and their importance is shown empirically. To facilitate faster iteration of development and analysis, a suite of automatic metrics is included. Apart from the features added specifically for this extension, fairseq S^2 also benefits from the scalability offered by fairseq and can be easily integrated with other state-of-the-art systems provided in this framework. The code, documentation, and pre-trained models are available at https://github.com/pytorch/fairseq/tree/master/examples/speech_synthesis.