 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Analyzing Acoustic Word Embeddings from Pre-trained Self-supervised Speech Models
Oct 28, 2022
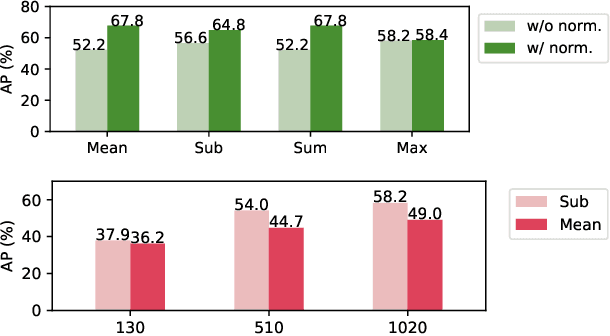
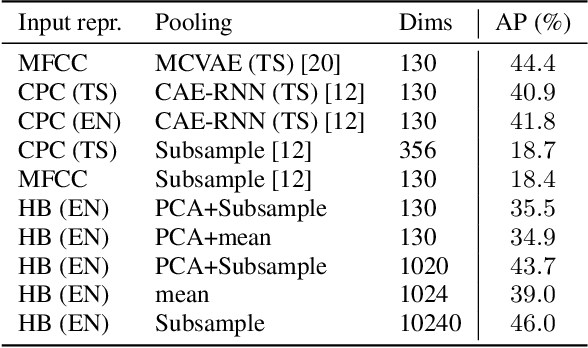
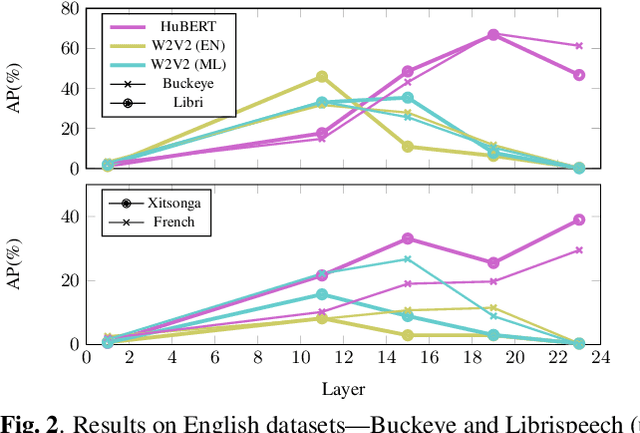

Given the strong results of self-supervised models on various tasks, there have been surprisingly few studies exploring self-supervised representations for acoustic word embeddings (AWE), fixed-dimensional vectors representing variable-length spoken word segments. In this work, we study several pre-trained models and pooling methods for constructing AWEs with self-supervised representations. Owing to the contextualized nature of self-supervised representations, we hypothesize that simple pooling methods, such as averaging, might already be useful for constructing AWEs. When evaluating on a standard word discrimination task, we find that HuBERT representations with mean-pooling rival the state of the art on English AWEs. More surprisingly, despite being trained only on English, HuBERT representations evaluated on Xitsonga, Mandarin, and French consistently outperform the multilingual model XLSR-53 (as well as Wav2Vec 2.0 trained on English).
CI-AVSR: A Cantonese Audio-Visual Speech Dataset for In-car Command Recognition
Jan 11, 2022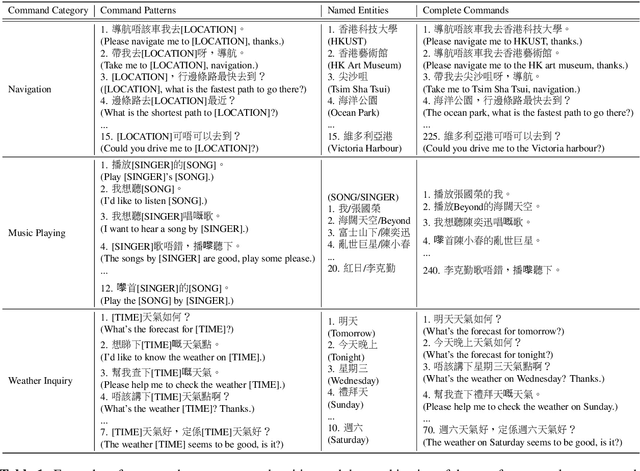
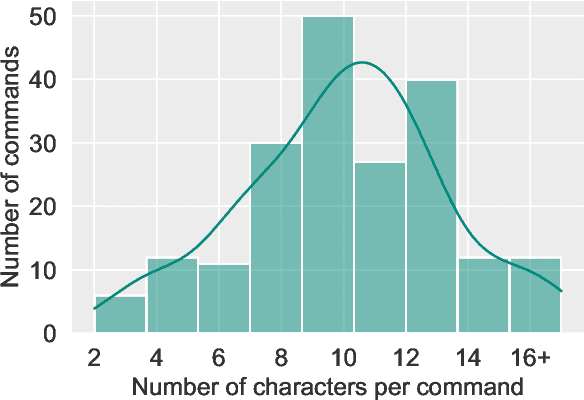
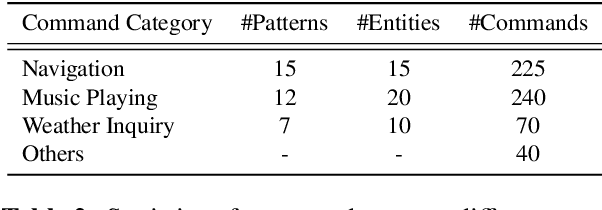
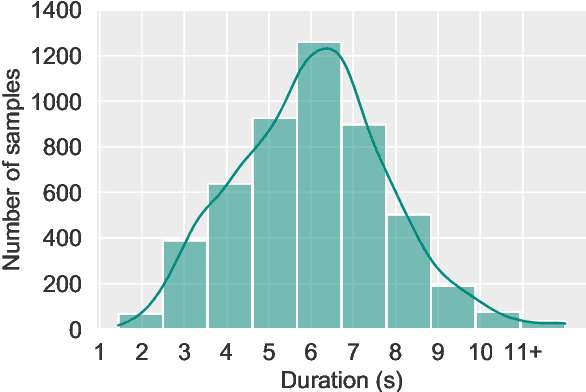
With the rise of deep learning and intelligent vehicle, the smart assistant has become an essential in-car component to facilitate driving and provide extra functionalities. In-car smart assistants should be able to process general as well as car-related commands and perform corresponding actions, which eases driving and improves safety. However, there is a data scarcity issue for low resource languages, hindering the development of research and applications. In this paper, we introduce a new dataset, Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR), for in-car command recognition in the Cantonese language with both video and audio data. It consists of 4,984 samples (8.3 hours) of 200 in-car commands recorded by 30 native Cantonese speakers. Furthermore, we augment our dataset using common in-car background noises to simulate real environments, producing a dataset 10 times larger than the collected one. We provide detailed statistics of both the clean and the augmented versions of our dataset. Moreover, we implement two multimodal baselines to demonstrate the validity of CI-AVSR. Experiment results show that leveraging the visual signal improves the overall performance of the model. Although our best model can achieve a considerable quality on the clean test set, the speech recognition quality on the noisy data is still inferior and remains as an extremely challenging task for real in-car speech recognition systems. The dataset and code will be released at https://github.com/HLTCHKUST/CI-AVSR.
Measuring Cognitive Status from Speech in a Smart Home Environment
Oct 18, 2021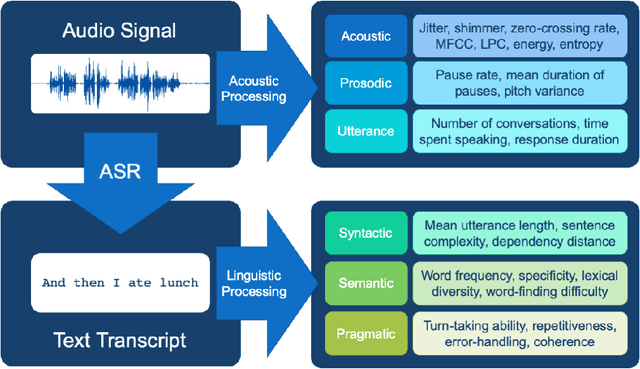
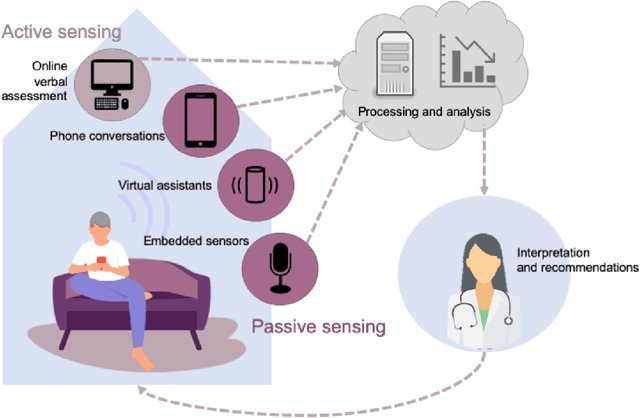
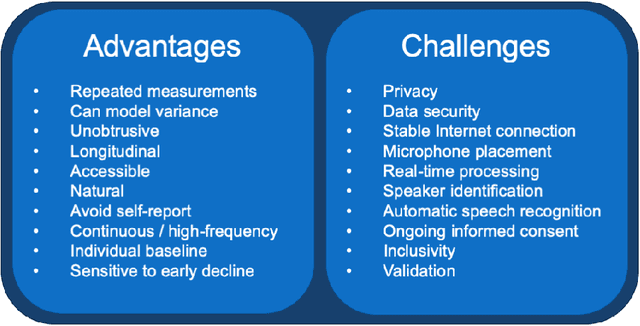
The population is aging, and becoming more tech-savvy. The United Nations predicts that by 2050, one in six people in the world will be over age 65 (up from one in 11 in 2019), and this increases to one in four in Europe and Northern America. Meanwhile, the proportion of American adults over 65 who own a smartphone has risen 24 percentage points from 2013-2017, and the majority have Internet in their homes. Smart devices and smart home technology have profound potential to transform how people age, their ability to live independently in later years, and their interactions with their circle of care. Cognitive health is a key component to independence and well-being in old age, and smart homes present many opportunities to measure cognitive status in a continuous, unobtrusive manner. In this article, we focus on speech as a measurement instrument for cognitive health. Existing methods of cognitive assessment suffer from a number of limitations that could be addressed through smart home speech sensing technologies. We begin with a brief tutorial on measuring cognitive status from speech, including some pointers to useful open-source software toolboxes for the interested reader. We then present an overview of the preliminary results from pilot studies on active and passive smart home speech sensing for the measurement of cognitive health, and conclude with some recommendations and challenge statements for the next wave of work in this area, to help overcome both technical and ethical barriers to success.
Meta-TTS: Meta-Learning for Few-Shot Speaker Adaptive Text-to-Speech
Nov 07, 2021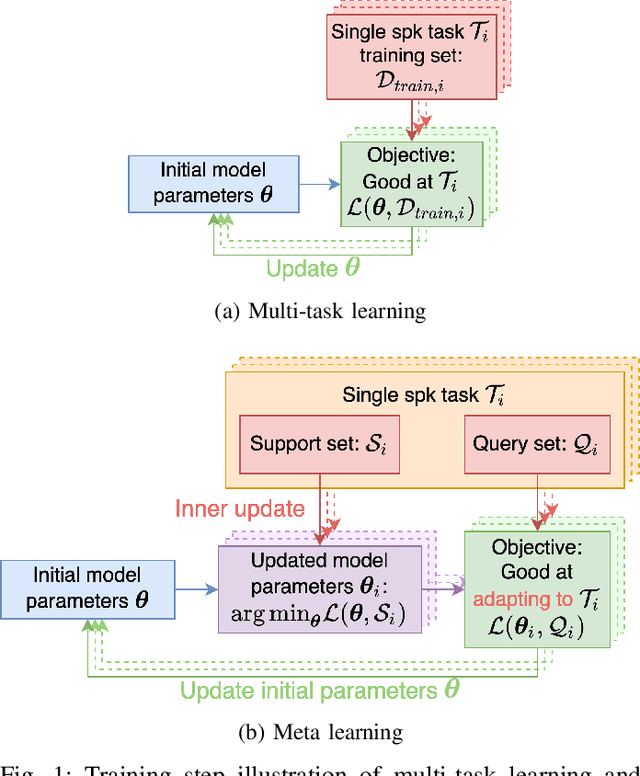
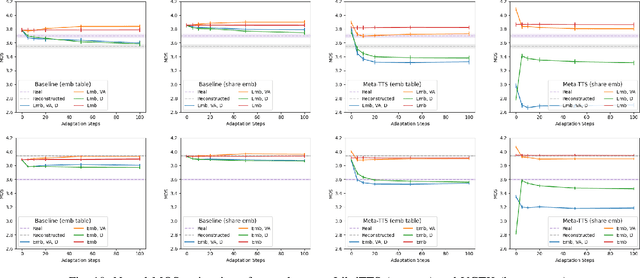
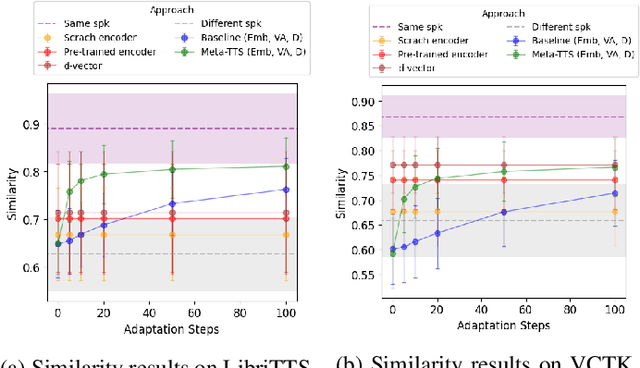
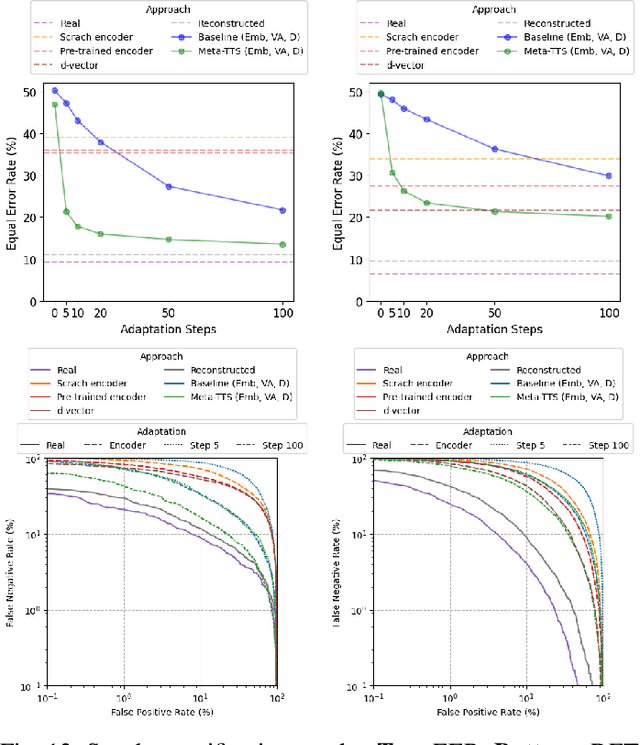
Personalizing a speech synthesis system is a highly desired application, where the system can generate speech with the user's voice with rare enrolled recordings. There are two main approaches to build such a system in recent works: speaker adaptation and speaker encoding. On the one hand, speaker adaptation methods fine-tune a trained multi-speaker text-to-speech (TTS) model with few enrolled samples. However, they require at least thousands of fine-tuning steps for high-quality adaptation, making it hard to apply on devices. On the other hand, speaker encoding methods encode enrollment utterances into a speaker embedding. The trained TTS model can synthesize the user's speech conditioned on the corresponding speaker embedding. Nevertheless, the speaker encoder suffers from the generalization gap between the seen and unseen speakers. In this paper, we propose applying a meta-learning algorithm to the speaker adaptation method. More specifically, we use Model Agnostic Meta-Learning (MAML) as the training algorithm of a multi-speaker TTS model, which aims to find a great meta-initialization to adapt the model to any few-shot speaker adaptation tasks quickly. Therefore, we can also adapt the meta-trained TTS model to unseen speakers efficiently. Our experiments compare the proposed method (Meta-TTS) with two baselines: a speaker adaptation method baseline and a speaker encoding method baseline. The evaluation results show that Meta-TTS can synthesize high speaker-similarity speech from few enrollment samples with fewer adaptation steps than the speaker adaptation baseline and outperforms the speaker encoding baseline under the same training scheme. When the speaker encoder of the baseline is pre-trained with extra 8371 speakers of data, Meta-TTS can still outperform the baseline on LibriTTS dataset and achieve comparable results on VCTK dataset.
The Conversational Short-phrase Speaker Diarization (CSSD) Task: Dataset, Evaluation Metric and Baselines
Aug 17, 2022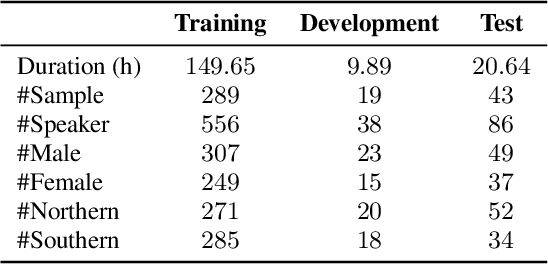

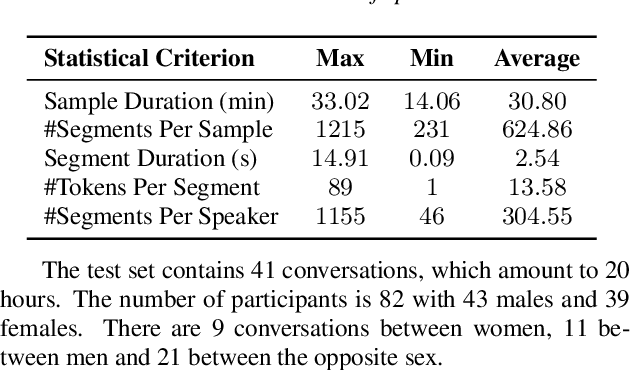
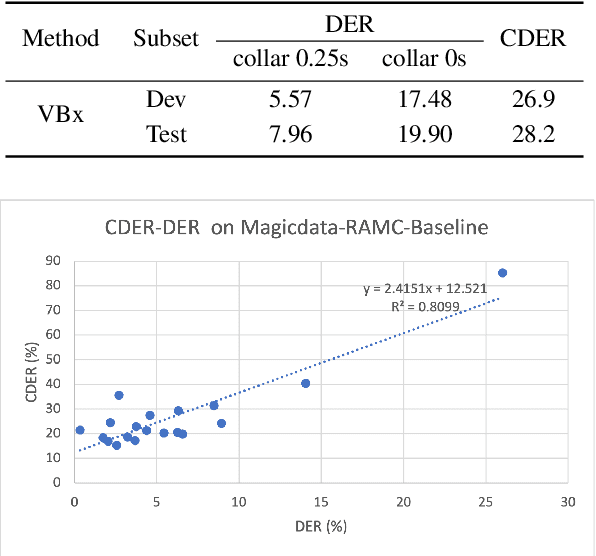
The conversation scenario is one of the most important and most challenging scenarios for speech processing technologies because people in conversation respond to each other in a casual style. Detecting the speech activities of each person in a conversation is vital to downstream tasks, like natural language processing, machine translation, etc. People refer to the detection technology of "who speak when" as speaker diarization (SD). Traditionally, diarization error rate (DER) has been used as the standard evaluation metric of SD systems for a long time. However, DER fails to give enough importance to short conversational phrases, which are short but important on the semantic level. Also, a carefully and accurately manually-annotated testing dataset suitable for evaluating the conversational SD technologies is still unavailable in the speech community. In this paper, we design and describe the Conversational Short-phrases Speaker Diarization (CSSD) task, which consists of training and testing datasets, evaluation metric and baselines. In the dataset aspect, despite the previously open-sourced 180-hour conversational MagicData-RAMC dataset, we prepare an individual 20-hour conversational speech test dataset with carefully and artificially verified speakers timestamps annotations for the CSSD task. In the metric aspect, we design the new conversational DER (CDER) evaluation metric, which calculates the SD accuracy at the utterance level. In the baseline aspect, we adopt a commonly used method: Variational Bayes HMM x-vector system, as the baseline of the CSSD task. Our evaluation metric is publicly available at https://github.com/SpeechClub/CDER_Metric.
THUEE system description for NIST 2020 SRE CTS challenge
Oct 12, 2022
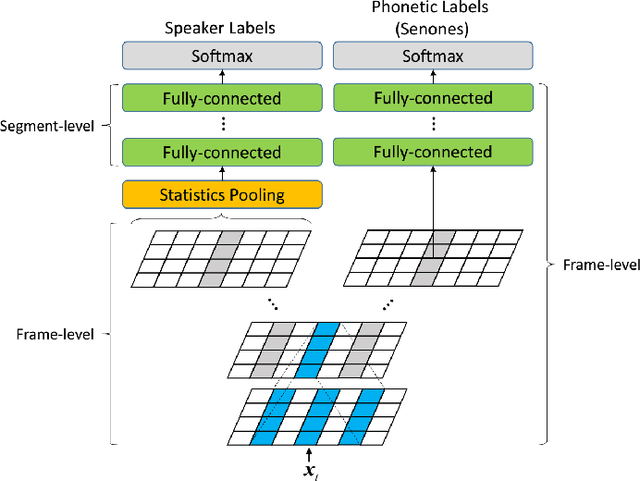
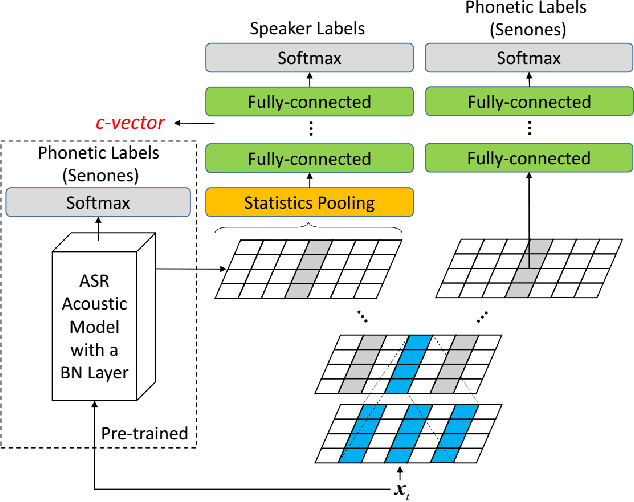

This paper presents the system description of the THUEE team for the NIST 2020 Speaker Recognition Evaluation (SRE) conversational telephone speech (CTS) challenge. The subsystems including ResNet74, ResNet152, and RepVGG-B2 are developed as speaker embedding extractors in this evaluation. We used combined AM-Softmax and AAM-Softmax based loss functions, namely CM-Softmax. We adopted a two-staged training strategy to further improve system performance. We fused all individual systems as our final submission. Our approach leads to excellent performance and ranks 1st in the challenge.
Improving Character Error Rate Is Not Equal to Having Clean Speech: Speech Enhancement for ASR Systems with Black-box Acoustic Models
Oct 12, 2021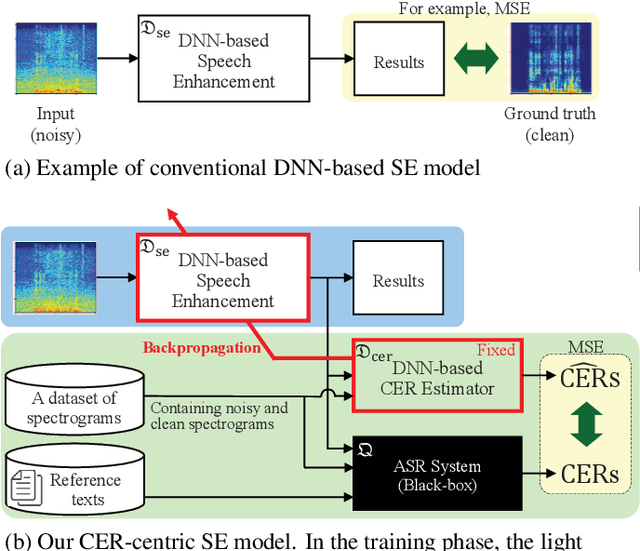
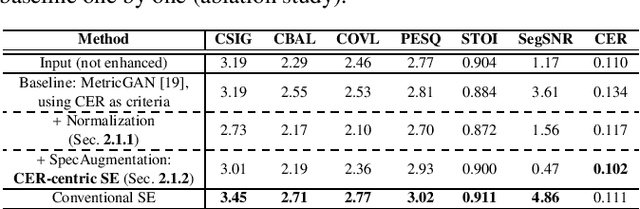
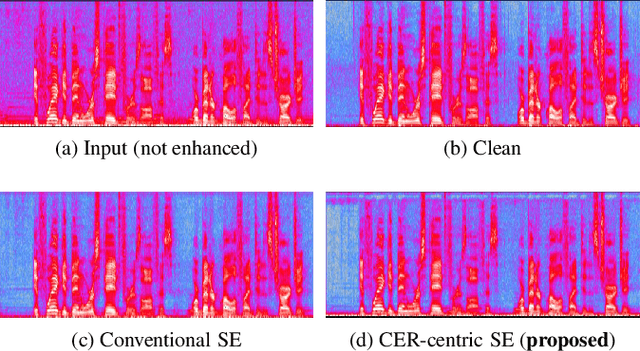
A deep neural network (DNN)-based speech enhancement (SE) aiming to maximize the performance of an automatic speech recognition (ASR) system is proposed in this paper. In order to optimize the DNN-based SE model in terms of the character error rate (CER), which is one of the metric to evaluate the ASR system and generally non-differentiable, our method uses two DNNs: one for speech processing and one for mimicking the output CERs derived through an acoustic model (AM). Then both of DNNs are alternately optimized in the training phase. Even if the AM is a black-box, e.g., like one provided by a third-party, the proposed method enables the DNN-based SE model to be optimized in terms of the CER since the DNN mimicking the AM is differentiable. Consequently, it becomes feasible to build CER-centric SE model that has no negative effect, e.g., additional calculation cost and changing network architecture, on the inference phase since our method is merely a training scheme for the existing DNN-based methods. Experimental results show that our method improved CER by 7.3% relative derived through a black-box AM although certain noise levels are kept.
Acoustical Analysis of Speech Under Physical Stress in Relation to Physical Activities and Physical Literacy
Nov 20, 2021
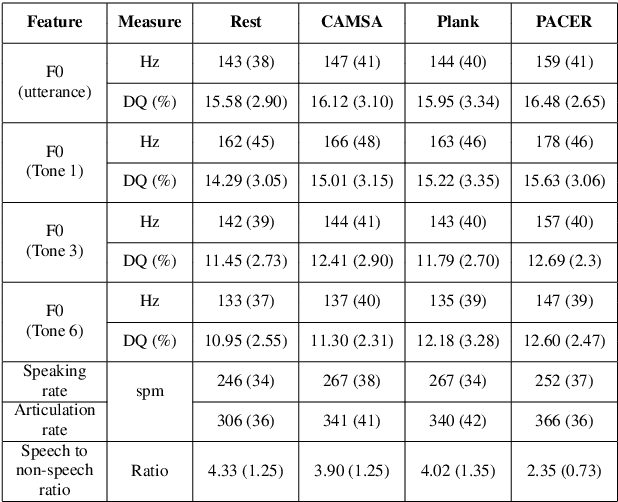
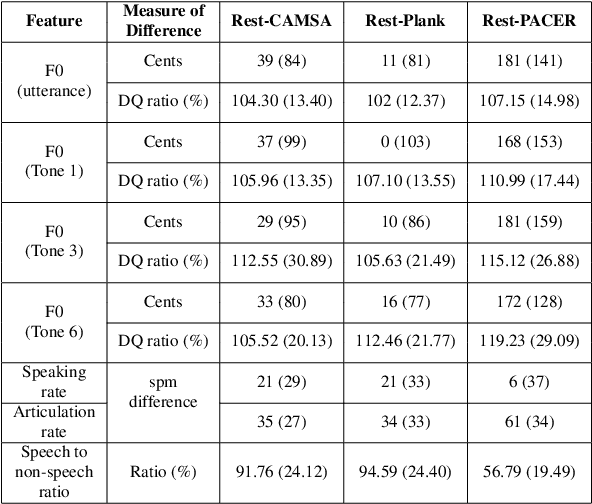
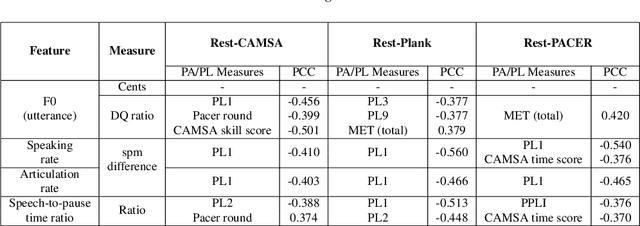
Human speech production encompasses physiological processes that naturally react to physic stress. Stress caused by physical activity (PA), e.g., running, may lead to significant changes in a person's speech. The major changes are related to the aspects of pitch level, speaking rate, pause pattern, and breathiness. The extent of change depends presumably on physical fitness and well-being of the person, as well as intensity of PA. The general wellness of a person is further related to his/her physical literacy (PL), which refers to a holistic description of engagement in PA. This paper presents the development of a Cantonese speech database that contains audio recordings of speech before and after physical exercises of different intensity levels. The corpus design and data collection process are described. Preliminary results of acoustical analysis are presented to illustrate the impact of PA on pitch level, pitch range, speaking and articulation rate, and time duration of pauses. It is also noted that the effect of PA is correlated to some of the PA and PL measures.
Prosodic Clustering for Phoneme-level Prosody Control in End-to-End Speech Synthesis
Nov 19, 2021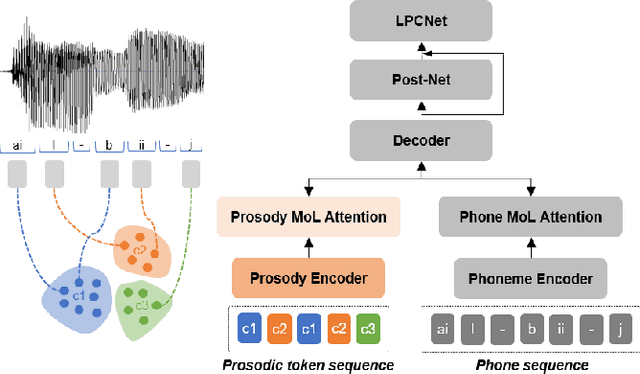
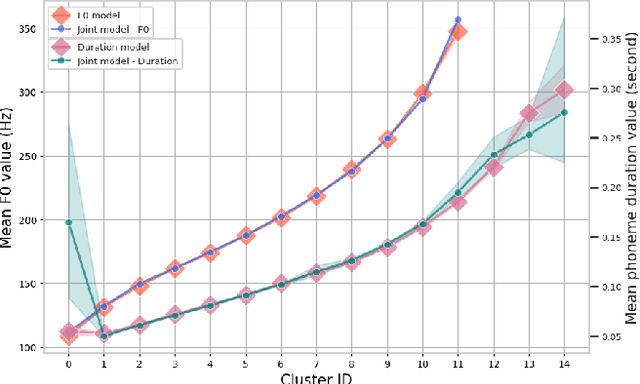
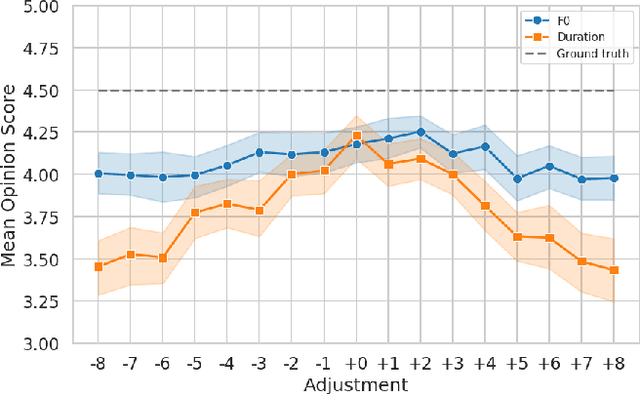
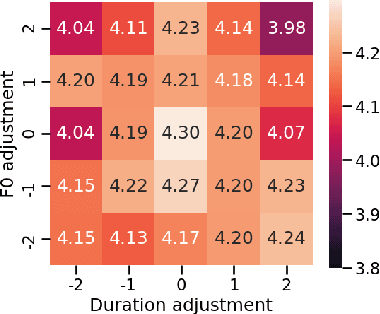
This paper presents a method for controlling the prosody at the phoneme level in an autoregressive attention-based text-to-speech system. Instead of learning latent prosodic features with a variational framework as is commonly done, we directly extract phoneme-level F0 and duration features from the speech data in the training set. Each prosodic feature is discretized using unsupervised clustering in order to produce a sequence of prosodic labels for each utterance. This sequence is used in parallel to the phoneme sequence in order to condition the decoder with the utilization of a prosodic encoder and a corresponding attention module. Experimental results show that the proposed method retains the high quality of generated speech, while allowing phoneme-level control of F0 and duration. By replacing the F0 cluster centroids with musical notes, the model can also provide control over the note and octave within the range of the speaker.
A Multi-Stage Multi-Codebook VQ-VAE Approach to High-Performance Neural TTS
Sep 22, 2022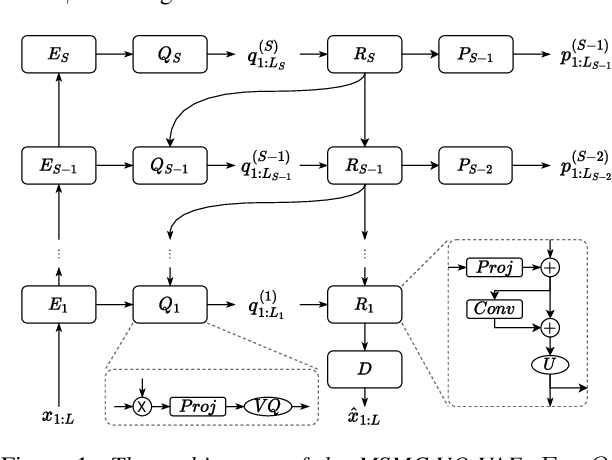
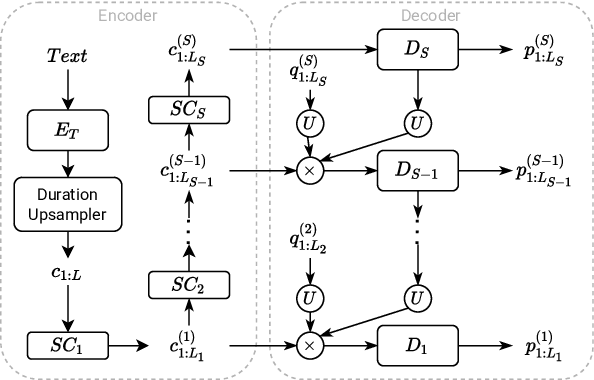
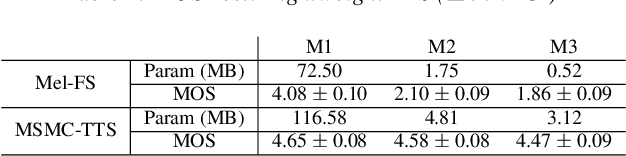
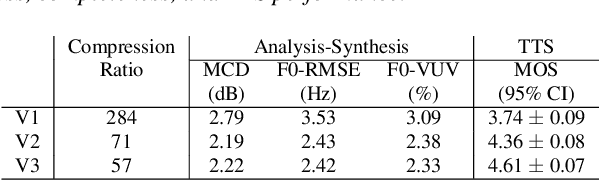
We propose a Multi-Stage, Multi-Codebook (MSMC) approach to high-performance neural TTS synthesis. A vector-quantized, variational autoencoder (VQ-VAE) based feature analyzer is used to encode Mel spectrograms of speech training data by down-sampling progressively in multiple stages into MSMC Representations (MSMCRs) with different time resolutions, and quantizing them with multiple VQ codebooks, respectively. Multi-stage predictors are trained to map the input text sequence to MSMCRs progressively by minimizing a combined loss of the reconstruction Mean Square Error (MSE) and "triplet loss". In synthesis, the neural vocoder converts the predicted MSMCRs into final speech waveforms. The proposed approach is trained and tested with an English TTS database of 16 hours by a female speaker. The proposed TTS achieves an MOS score of 4.41, which outperforms the baseline with an MOS of 3.62. Compact versions of the proposed TTS with much less parameters can still preserve high MOS scores. Ablation studies show that both multiple stages and multiple codebooks are effective for achieving high TTS performance.