 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Multi-accent Speech Separation with One Shot Learning
Jun 28, 2021
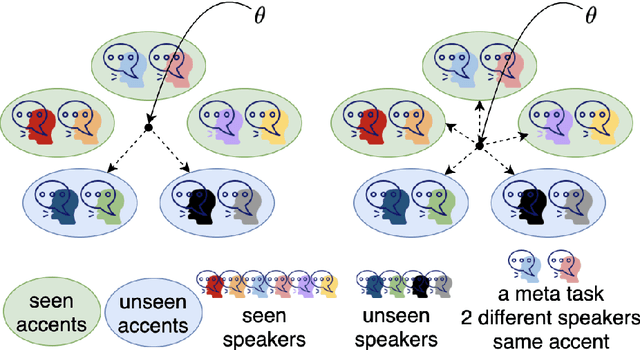
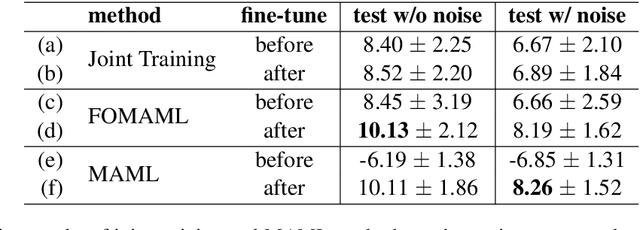
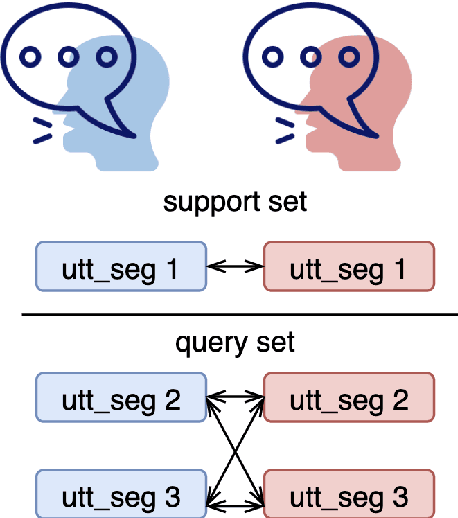
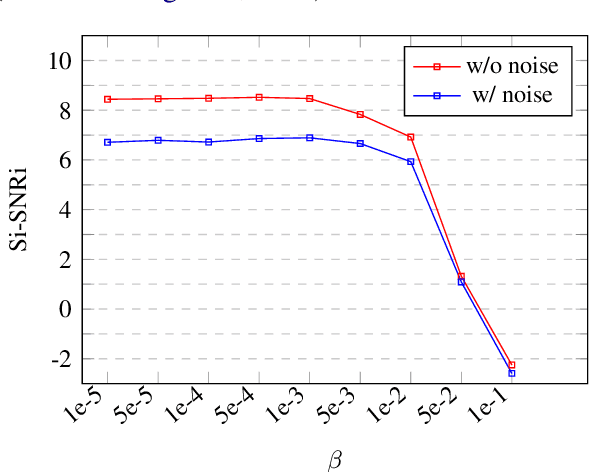
Speech separation is a problem in the field of speech processing that has been studied in full swing recently. However, there has not been much work studying a multi-accent speech separation scenario. Unseen speakers with new accents and noise aroused the domain mismatch problem which cannot be easily solved by conventional joint training methods. Thus, we applied MAML and FOMAML to tackle this problem and obtained higher average Si-SNRi values than joint training on almost all the unseen accents. This proved that these two methods do have the ability to generate well-trained parameters for adapting to speech mixtures of new speakers and accents. Furthermore, we found out that FOMAML obtains similar performance compared to MAML while saving a lot of time.
FedAudio: A Federated Learning Benchmark for Audio Tasks
Nov 18, 2022
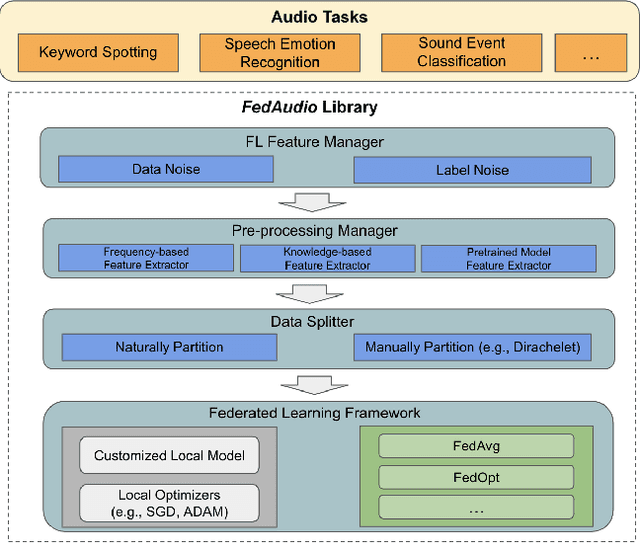

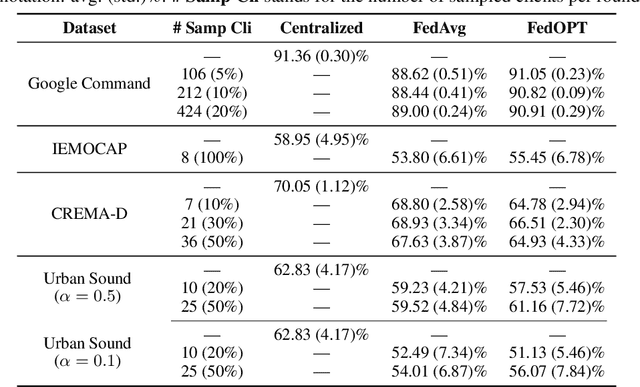
Federated learning (FL) has gained substantial attention in recent years due to the data privacy concerns related to the pervasiveness of consumer devices that continuously collect data from users. While a number of FL benchmarks have been developed to facilitate FL research, none of them include audio data and audio-related tasks. In this paper, we fill this critical gap by introducing a new FL benchmark for audio tasks which we refer to as FedAudio. FedAudio includes four representative and commonly used audio datasets from three important audio tasks that are well aligned with FL use cases. In particular, a unique contribution of FedAudio is the introduction of data noises and label errors to the datasets to emulate challenges when deploying FL systems in real-world settings. FedAudio also includes the benchmark results of the datasets and a PyTorch library with the objective of facilitating researchers to fairly compare their algorithms. We hope FedAudio could act as a catalyst to inspire new FL research for audio tasks and thus benefit the acoustic and speech research community. The datasets and benchmark results can be accessed at https://github.com/zhang-tuo-pdf/FedAudio.
Adaptive User-Centered Multimodal Interaction towards Reliable and Trusted Automotive Interfaces
Nov 07, 2022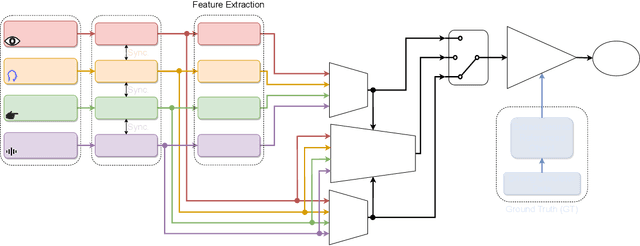
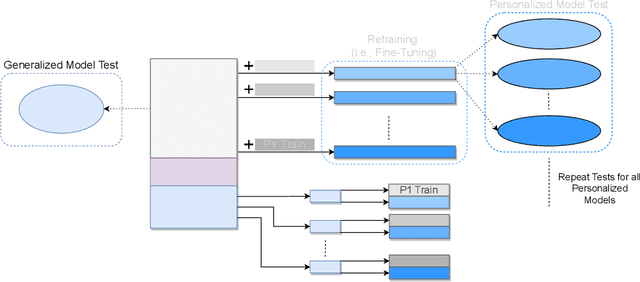
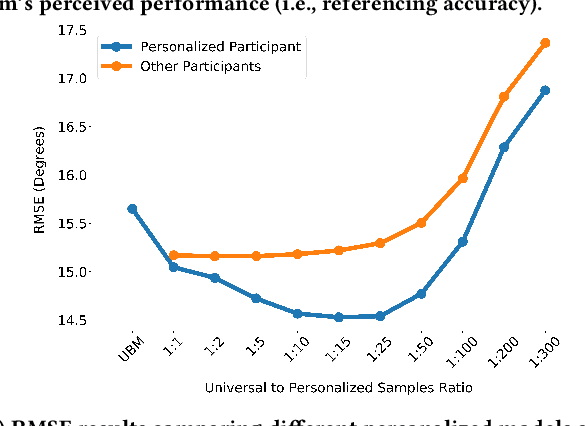
With the recently increasing capabilities of modern vehicles, novel approaches for interaction emerged that go beyond traditional touch-based and voice command approaches. Therefore, hand gestures, head pose, eye gaze, and speech have been extensively investigated in automotive applications for object selection and referencing. Despite these significant advances, existing approaches mostly employ a one-model-fits-all approach unsuitable for varying user behavior and individual differences. Moreover, current referencing approaches either consider these modalities separately or focus on a stationary situation, whereas the situation in a moving vehicle is highly dynamic and subject to safety-critical constraints. In this paper, I propose a research plan for a user-centered adaptive multimodal fusion approach for referencing external objects from a moving vehicle. The proposed plan aims to provide an open-source framework for user-centered adaptation and personalization using user observations and heuristics, multimodal fusion, clustering, transfer-of-learning for model adaptation, and continuous learning, moving towards trusted human-centered artificial intelligence.
Restoring degraded speech via a modified diffusion model
Apr 22, 2021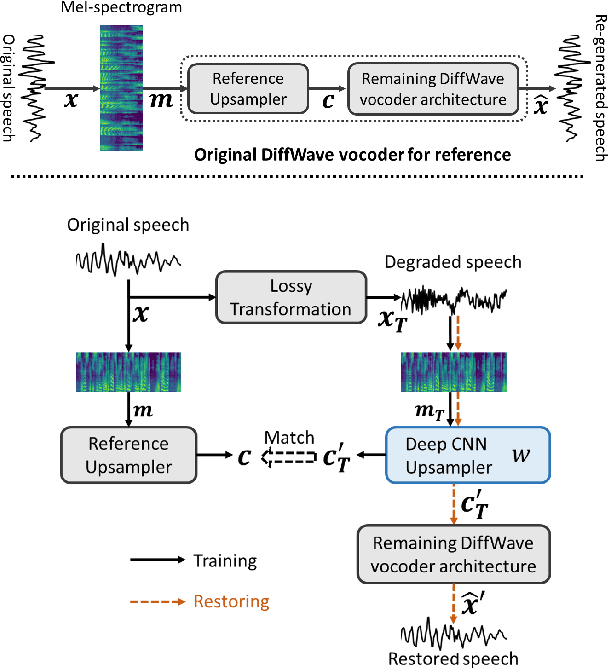
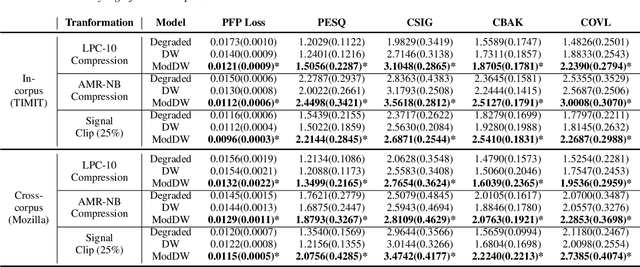
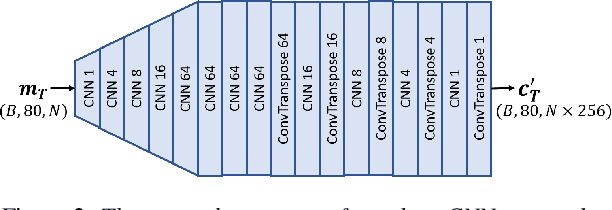

There are many deterministic mathematical operations (e.g. compression, clipping, downsampling) that degrade speech quality considerably. In this paper we introduce a neural network architecture, based on a modification of the DiffWave model, that aims to restore the original speech signal. DiffWave, a recently published diffusion-based vocoder, has shown state-of-the-art synthesized speech quality and relatively shorter waveform generation times, with only a small set of parameters. We replace the mel-spectrum upsampler in DiffWave with a deep CNN upsampler, which is trained to alter the degraded speech mel-spectrum to match that of the original speech. The model is trained using the original speech waveform, but conditioned on the degraded speech mel-spectrum. Post-training, only the degraded mel-spectrum is used as input and the model generates an estimate of the original speech. Our model results in improved speech quality (original DiffWave model as baseline) on several different experiments. These include improving the quality of speech degraded by LPC-10 compression, AMR-NB compression, and signal clipping. Compared to the original DiffWave architecture, our scheme achieves better performance on several objective perceptual metrics and in subjective comparisons. Improvements over baseline are further amplified in a out-of-corpus evaluation setting.
Best of Both Worlds: Multi-task Audio-Visual Automatic Speech Recognition and Active Speaker Detection
May 10, 2022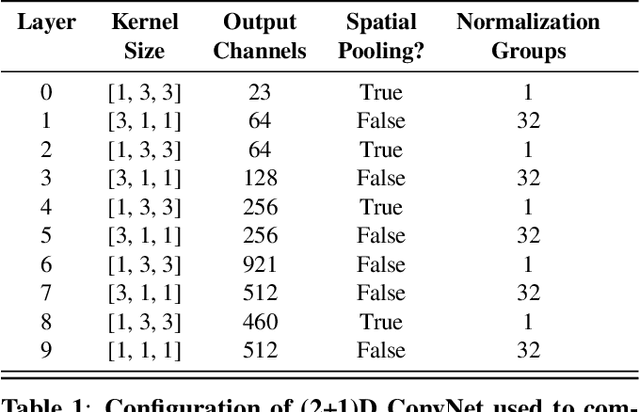
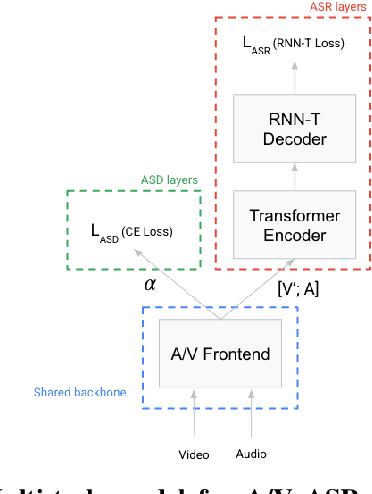
Under noisy conditions, automatic speech recognition (ASR) can greatly benefit from the addition of visual signals coming from a video of the speaker's face. However, when multiple candidate speakers are visible this traditionally requires solving a separate problem, namely active speaker detection (ASD), which entails selecting at each moment in time which of the visible faces corresponds to the audio. Recent work has shown that we can solve both problems simultaneously by employing an attention mechanism over the competing video tracks of the speakers' faces, at the cost of sacrificing some accuracy on active speaker detection. This work closes this gap in active speaker detection accuracy by presenting a single model that can be jointly trained with a multi-task loss. By combining the two tasks during training we reduce the ASD classification accuracy by approximately 25%, while simultaneously improving the ASR performance when compared to the multi-person baseline trained exclusively for ASR.
BLOOM-Net: Blockwise Optimization for Masking Networks Toward Scalable and Efficient Speech Enhancement
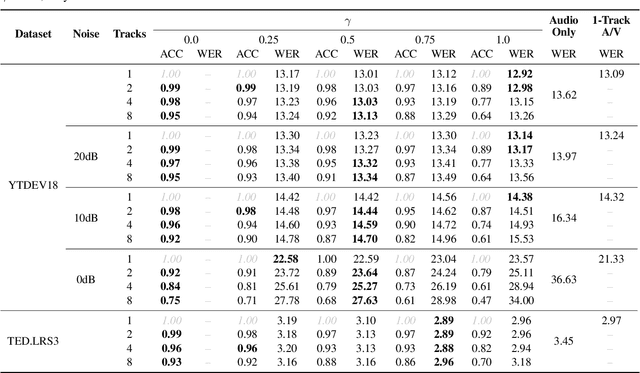
Nov 17, 2021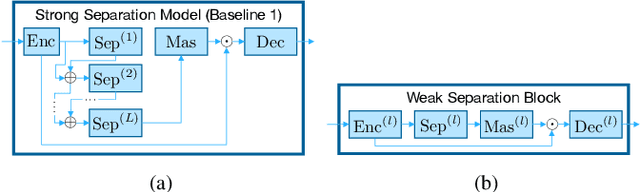
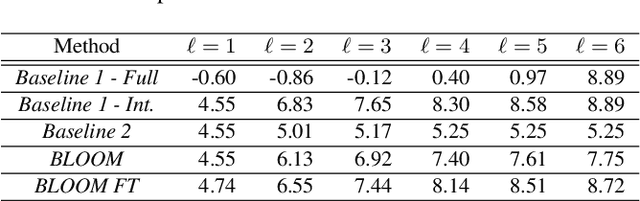
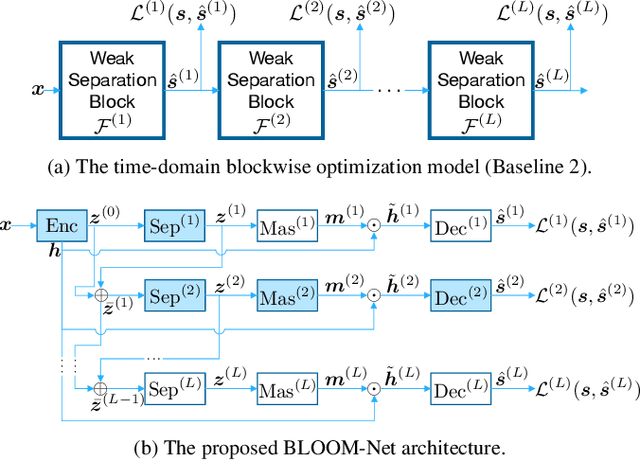

In this paper, we present a blockwise optimization method for masking-based networks (BLOOM-Net) for training scalable speech enhancement networks. Here, we design our network with a residual learning scheme and train the internal separator blocks sequentially to obtain a scalable masking-based deep neural network for speech enhancement. Its scalability lets it adjust the run-time complexity based on the test-time resource constraints: once deployed, the model can alter its complexity dynamically depending on the test time environment. To this end, we modularize our models in that they can flexibly accommodate varying needs for enhancement performance and constraints on the resources, incurring minimal memory or training overhead due to the added scalability. Our experiments on speech enhancement demonstrate that the proposed blockwise optimization method achieves the desired scalability with only a slight performance degradation compared to corresponding models trained end-to-end.
FST: the FAIR Speech Translation System for the IWSLT21 Multilingual Shared Task
Aug 14, 2021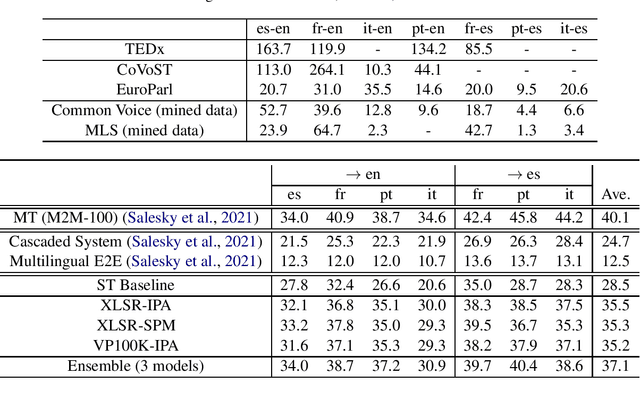
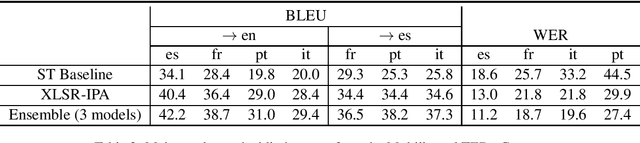
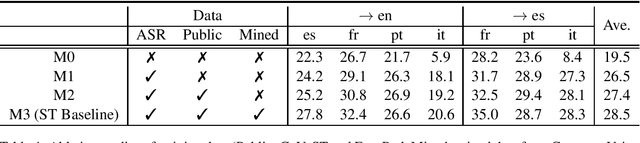
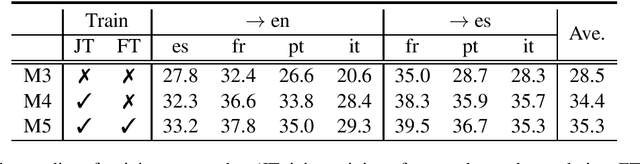
In this paper, we describe our end-to-end multilingual speech translation system submitted to the IWSLT 2021 evaluation campaign on the Multilingual Speech Translation shared task. Our system is built by leveraging transfer learning across modalities, tasks and languages. First, we leverage general-purpose multilingual modules pretrained with large amounts of unlabelled and labelled data. We further enable knowledge transfer from the text task to the speech task by training two tasks jointly. Finally, our multilingual model is finetuned on speech translation task-specific data to achieve the best translation results. Experimental results show our system outperforms the reported systems, including both end-to-end and cascaded based approaches, by a large margin. In some translation directions, our speech translation results evaluated on the public Multilingual TEDx test set are even comparable with the ones from a strong text-to-text translation system, which uses the oracle speech transcripts as input.
Learning Nigerian accent embeddings from speech: preliminary results based on SautiDB-Naija corpus
Dec 12, 2021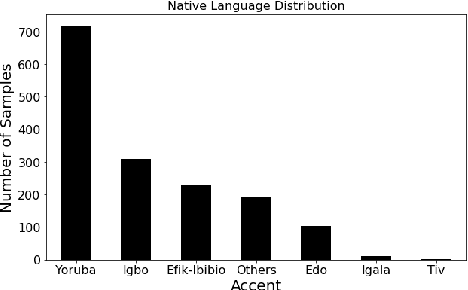
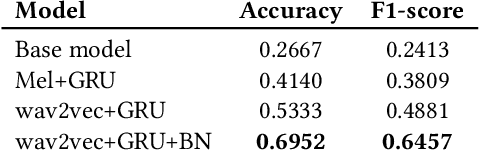
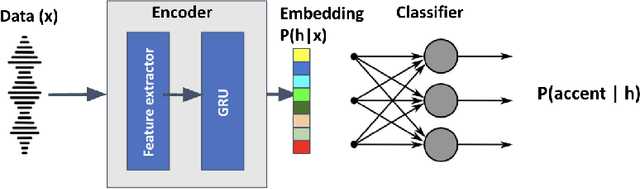
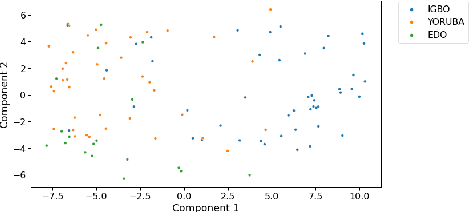
This paper describes foundational efforts with SautiDB-Naija, a novel corpus of non-native (L2) Nigerian English speech. We describe how the corpus was created and curated as well as preliminary experiments with accent classification and learning Nigerian accent embeddings. The initial version of the corpus includes over 900 recordings from L2 English speakers of Nigerian languages, such as Yoruba, Igbo, Edo, Efik-Ibibio, and Igala. We further demonstrate how fine-tuning on a pre-trained model like wav2vec can yield representations suitable for related speech tasks such as accent classification. SautiDB-Naija has been published to Zenodo for general use under a flexible Creative Commons License.
A Fine-tuned Wav2vec 2.0/HuBERT Benchmark For Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding
Nov 04, 2021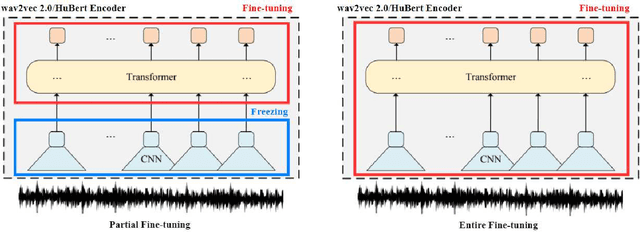
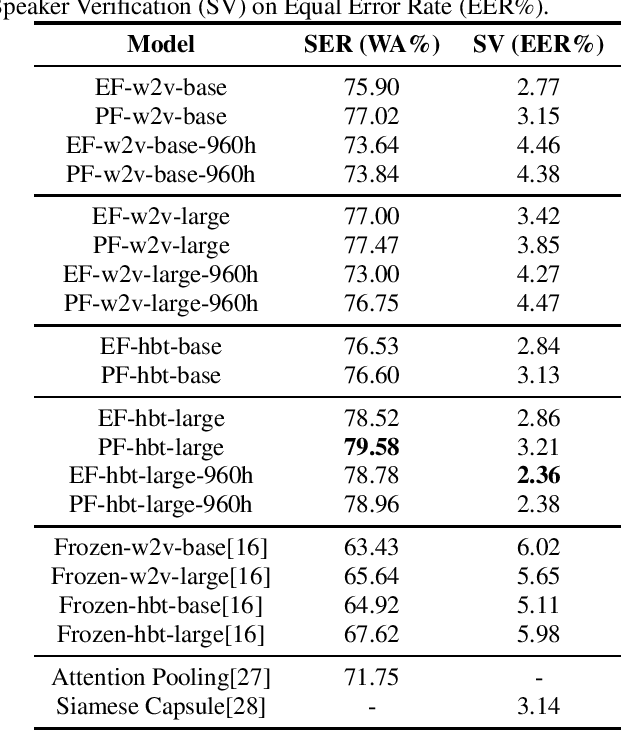
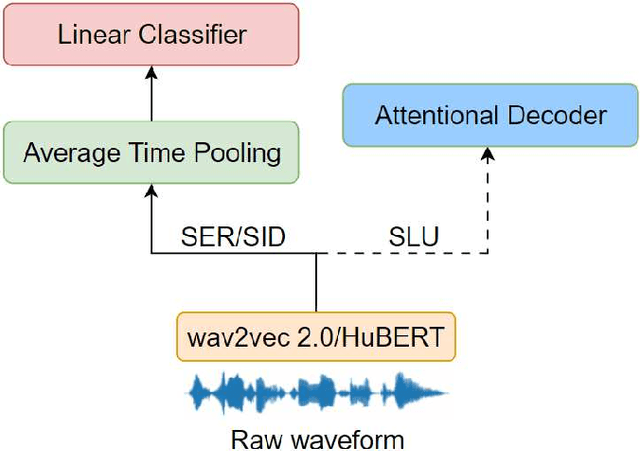
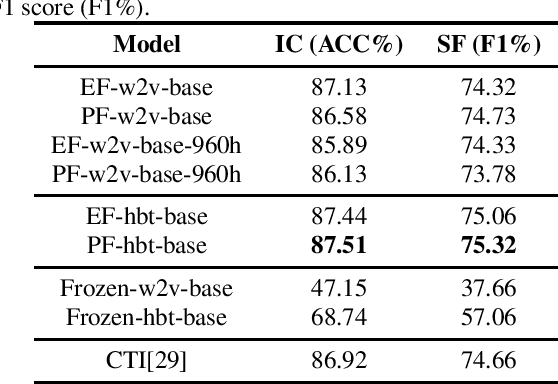
Self-supervised speech representations such as wav2vec 2.0 and HuBERT are making revolutionary progress in Automatic Speech Recognition (ASR). However, self-supervised models have not been totally proved to produce better performance on tasks other than ASR. In this work, we explore partial fine-tuning and entire fine-tuning on wav2vec 2.0 and HuBERT pre-trained models for three non-ASR speech tasks : Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding. We also compare pre-trained models with/without ASR fine-tuning. With simple down-stream frameworks, the best scores reach 79.58% weighted accuracy for Speech Emotion Recognition on IEMOCAP, 2.36% equal error rate for Speaker Verification on VoxCeleb1, 87.51% accuracy for Intent Classification and 75.32% F1 for Slot Filling on SLURP, thus setting a new state-of-the-art for these three benchmarks, proving that fine-tuned wav2vec 2.0 and HuBERT models can better learn prosodic, voice-print and semantic representations.
I see what you hear: a vision-inspired method to localize words
Oct 24, 2022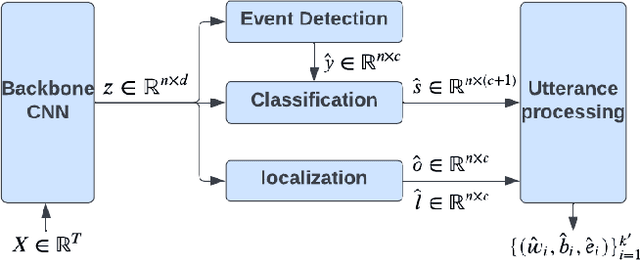
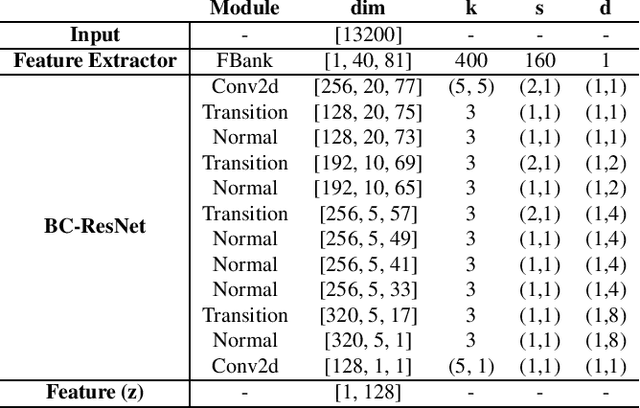
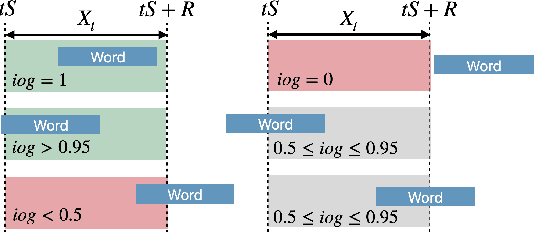

This paper explores the possibility of using visual object detection techniques for word localization in speech data. Object detection has been thoroughly studied in the contemporary literature for visual data. Noting that an audio can be interpreted as a 1-dimensional image, object localization techniques can be fundamentally useful for word localization. Building upon this idea, we propose a lightweight solution for word detection and localization. We use bounding box regression for word localization, which enables our model to detect the occurrence, offset, and duration of keywords in a given audio stream. We experiment with LibriSpeech and train a model to localize 1000 words. Compared to existing work, our method reduces model size by 94%, and improves the F1 score by 6.5\%.