 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Meta-TTS: Meta-Learning for Few-Shot Speaker Adaptive Text-to-Speech
Nov 07, 2021
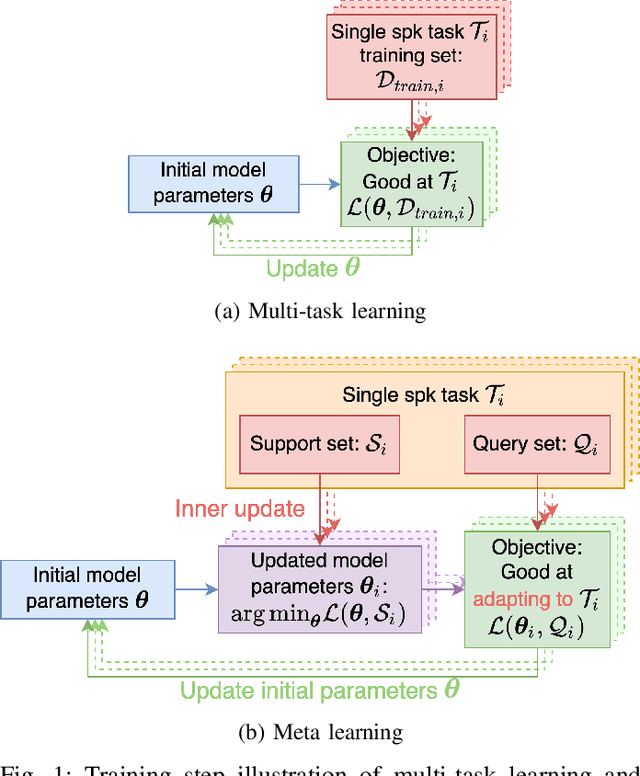
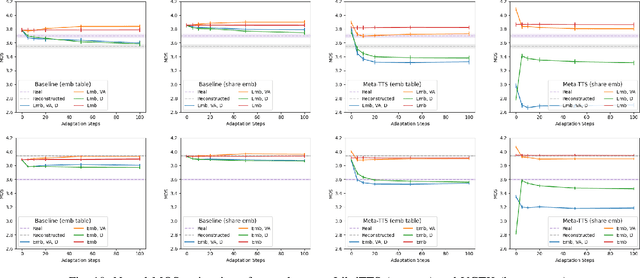
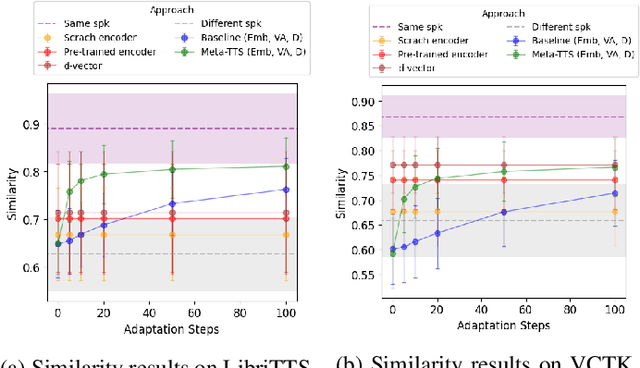
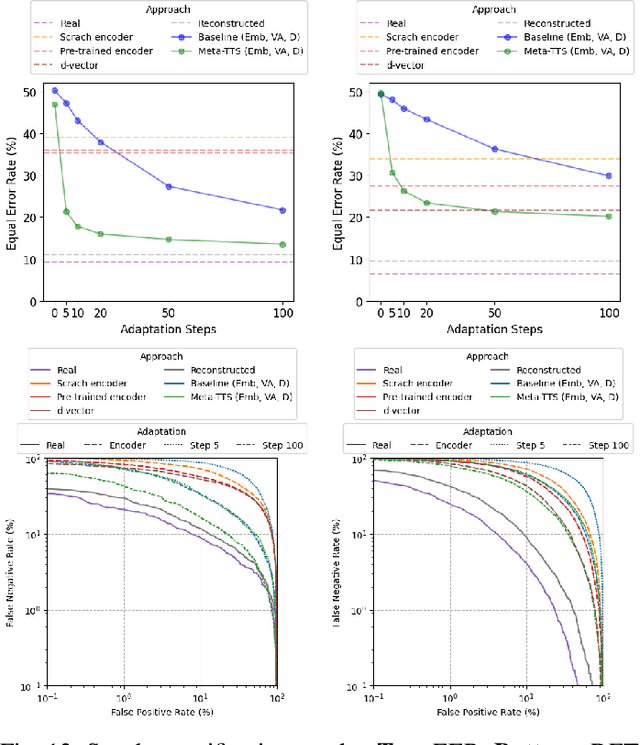
Personalizing a speech synthesis system is a highly desired application, where the system can generate speech with the user's voice with rare enrolled recordings. There are two main approaches to build such a system in recent works: speaker adaptation and speaker encoding. On the one hand, speaker adaptation methods fine-tune a trained multi-speaker text-to-speech (TTS) model with few enrolled samples. However, they require at least thousands of fine-tuning steps for high-quality adaptation, making it hard to apply on devices. On the other hand, speaker encoding methods encode enrollment utterances into a speaker embedding. The trained TTS model can synthesize the user's speech conditioned on the corresponding speaker embedding. Nevertheless, the speaker encoder suffers from the generalization gap between the seen and unseen speakers. In this paper, we propose applying a meta-learning algorithm to the speaker adaptation method. More specifically, we use Model Agnostic Meta-Learning (MAML) as the training algorithm of a multi-speaker TTS model, which aims to find a great meta-initialization to adapt the model to any few-shot speaker adaptation tasks quickly. Therefore, we can also adapt the meta-trained TTS model to unseen speakers efficiently. Our experiments compare the proposed method (Meta-TTS) with two baselines: a speaker adaptation method baseline and a speaker encoding method baseline. The evaluation results show that Meta-TTS can synthesize high speaker-similarity speech from few enrollment samples with fewer adaptation steps than the speaker adaptation baseline and outperforms the speaker encoding baseline under the same training scheme. When the speaker encoder of the baseline is pre-trained with extra 8371 speakers of data, Meta-TTS can still outperform the baseline on LibriTTS dataset and achieve comparable results on VCTK dataset.
FF2: A Feature Fusion Two-Stream Framework for Punctuation Restoration
Nov 09, 2022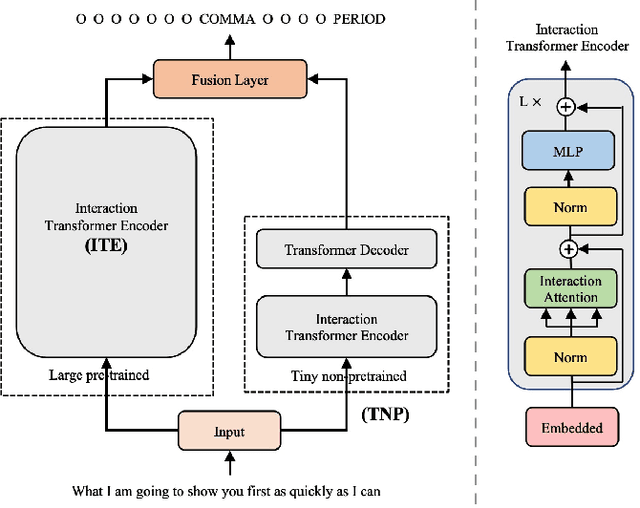
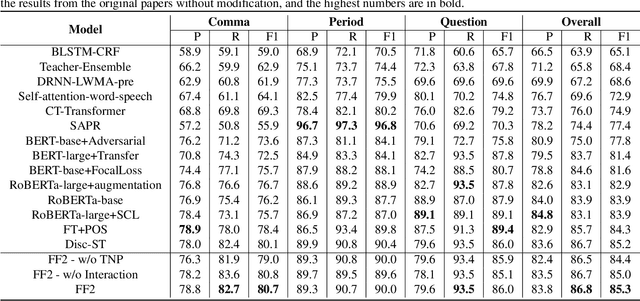
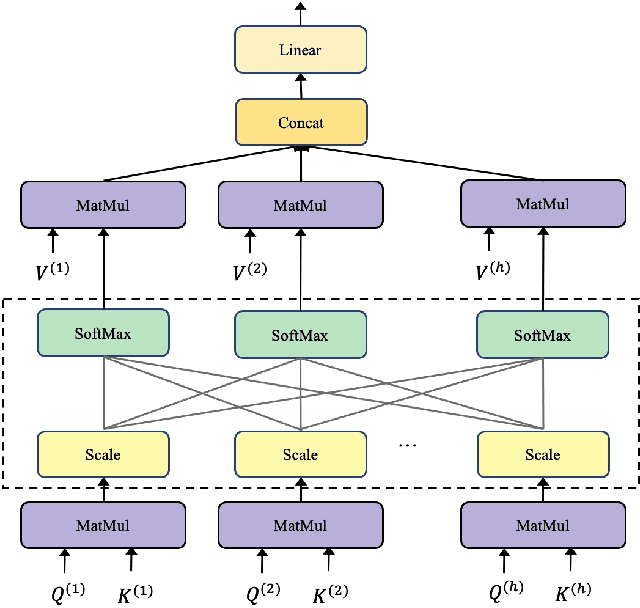
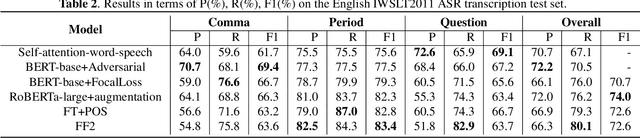
To accomplish punctuation restoration, most existing methods focus on introducing extra information (e.g., part-of-speech) or addressing the class imbalance problem. Recently, large-scale transformer-based pre-trained language models (PLMS) have been utilized widely and obtained remarkable success. However, the PLMS are trained on the large dataset with marks, which may not fit well with the small dataset without marks, causing the convergence to be not ideal. In this study, we propose a Feature Fusion two-stream framework (FF2) to bridge the gap. Specifically, one stream leverages a pre-trained language model to capture the semantic feature, while another auxiliary module captures the feature at hand. We also modify the computation of multi-head attention to encourage communication among heads. Then, two features with different perspectives are aggregated to fuse information and enhance context awareness. Without additional data, the experimental results on the popular benchmark IWSLT demonstrate that FF2 achieves new SOTA performance, which verifies that our approach is effective.
A Diffeomorphic Flow-based Variational Framework for Multi-speaker Emotion Conversion
Nov 09, 2022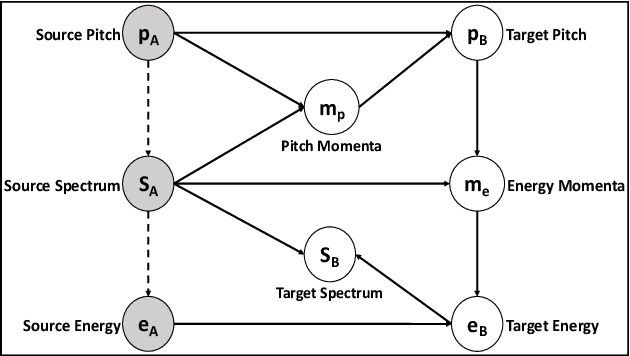
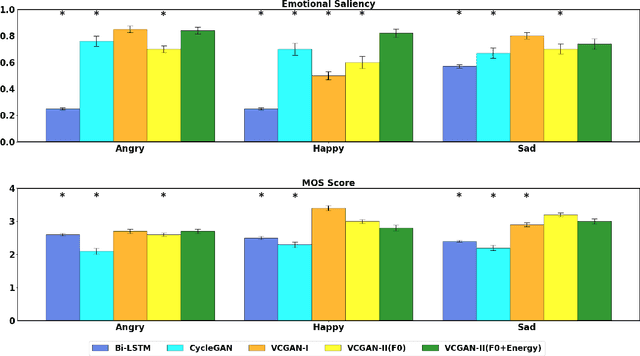
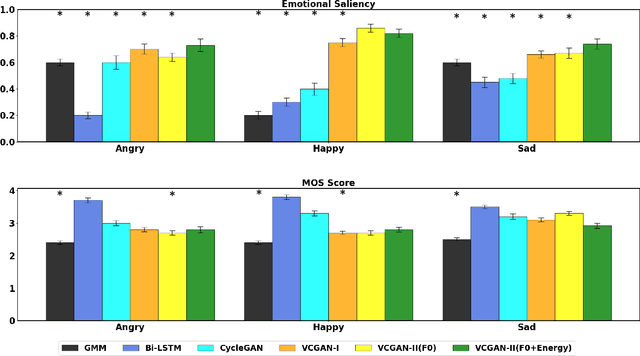
This paper introduces a new framework for non-parallel emotion conversion in speech. Our framework is based on two key contributions. First, we propose a stochastic version of the popular CycleGAN model. Our modified loss function introduces a Kullback Leibler (KL) divergence term that aligns the source and target data distributions learned by the generators, thus overcoming the limitations of sample wise generation. By using a variational approximation to this stochastic loss function, we show that our KL divergence term can be implemented via a paired density discriminator. We term this new architecture a variational CycleGAN (VCGAN). Second, we model the prosodic features of target emotion as a smooth and learnable deformation of the source prosodic features. This approach provides implicit regularization that offers key advantages in terms of better range alignment to unseen and out of distribution speakers. We conduct rigorous experiments and comparative studies to demonstrate that our proposed framework is fairly robust with high performance against several state-of-the-art baselines.
Acoustical Analysis of Speech Under Physical Stress in Relation to Physical Activities and Physical Literacy
Nov 20, 2021
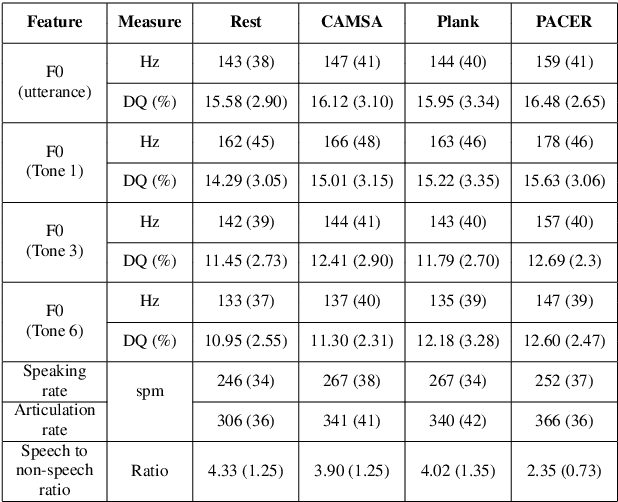
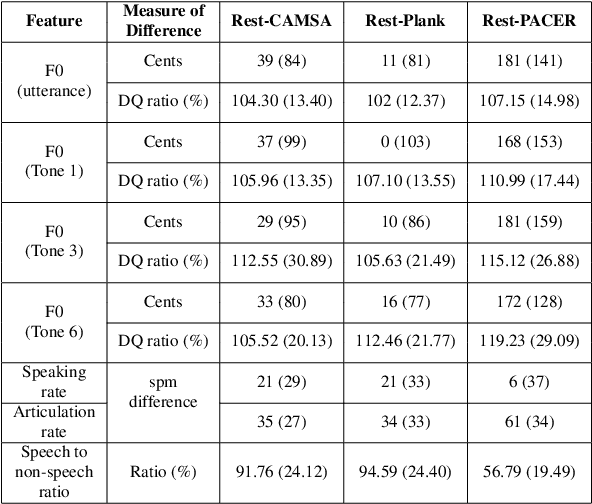
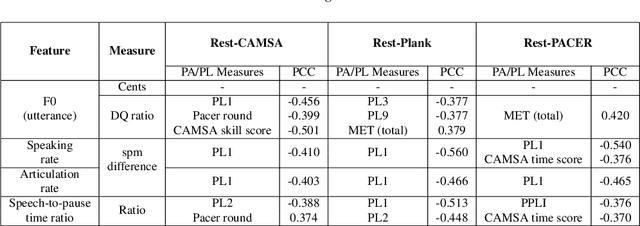
Human speech production encompasses physiological processes that naturally react to physic stress. Stress caused by physical activity (PA), e.g., running, may lead to significant changes in a person's speech. The major changes are related to the aspects of pitch level, speaking rate, pause pattern, and breathiness. The extent of change depends presumably on physical fitness and well-being of the person, as well as intensity of PA. The general wellness of a person is further related to his/her physical literacy (PL), which refers to a holistic description of engagement in PA. This paper presents the development of a Cantonese speech database that contains audio recordings of speech before and after physical exercises of different intensity levels. The corpus design and data collection process are described. Preliminary results of acoustical analysis are presented to illustrate the impact of PA on pitch level, pitch range, speaking and articulation rate, and time duration of pauses. It is also noted that the effect of PA is correlated to some of the PA and PL measures.
A Conformer Based Acoustic Model for Robust Automatic Speech Recognition
Mar 01, 2022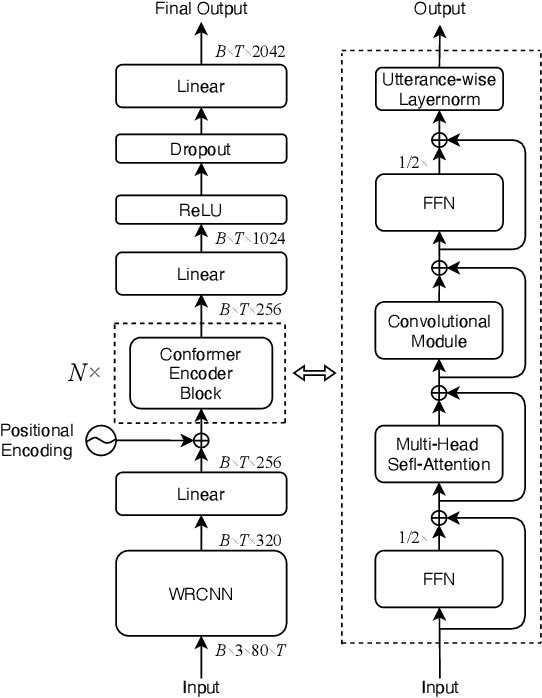
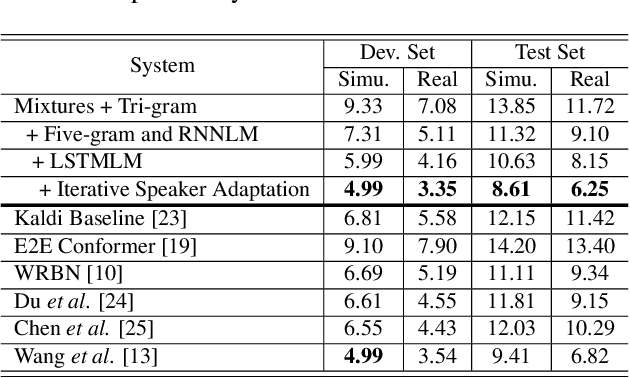
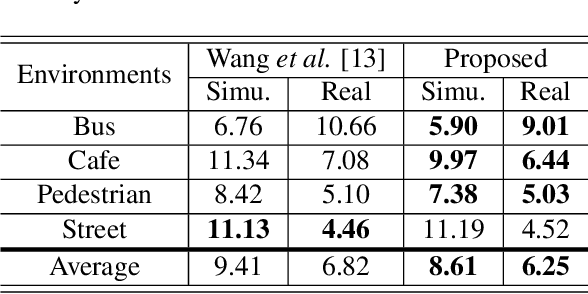
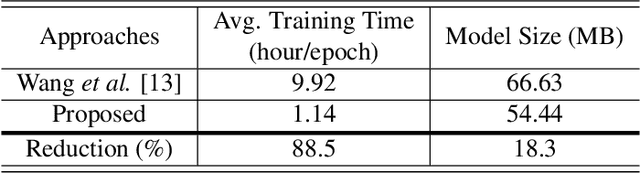
This study addresses robust automatic speech recognition (ASR) by introducing a Conformer-based acoustic model. The proposed model builds on a state-of-the-art recognition system using a bi-directional long short-term memory (BLSTM) model with utterance-wise dropout and iterative speaker adaptation, but employs a Conformer encoder instead of the BLSTM network. The Conformer encoder uses a convolution-augmented attention mechanism for acoustic modeling. The proposed system is evaluated on the monaural ASR task of the CHiME-4 corpus. Coupled with utterance-wise normalization and speaker adaptation, our model achieves $6.25\%$ word error rate, which outperforms the previous best system by $8.4\%$ relatively. In addition, the proposed Conformer-based model is $18.3\%$ smaller in model size and reduces training time by $88.5\%$.
Prosodic Clustering for Phoneme-level Prosody Control in End-to-End Speech Synthesis
Nov 19, 2021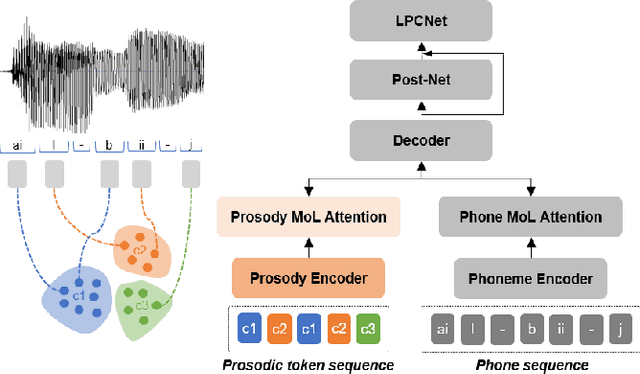
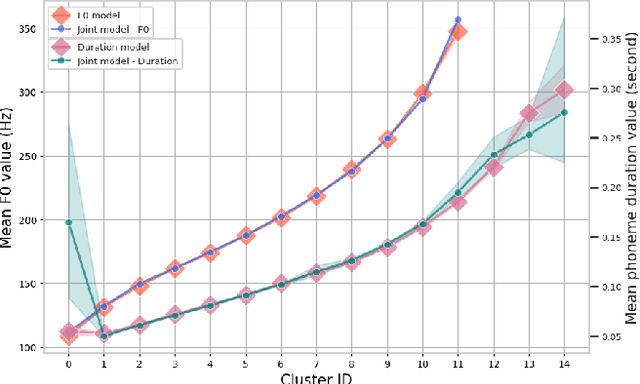
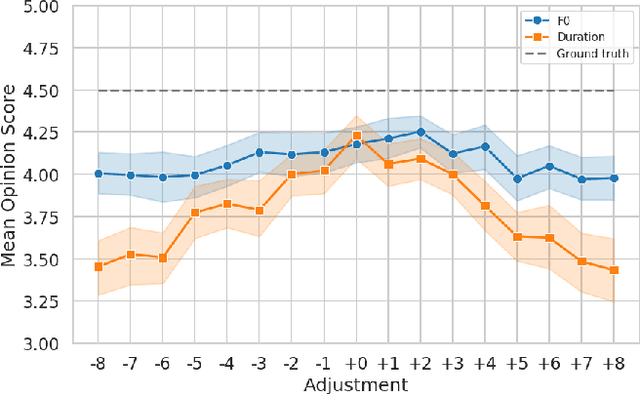
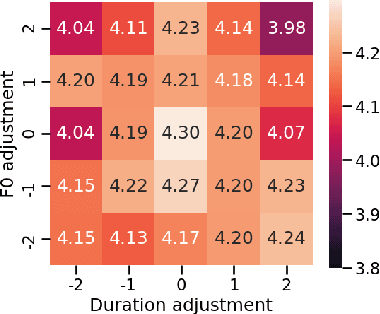
This paper presents a method for controlling the prosody at the phoneme level in an autoregressive attention-based text-to-speech system. Instead of learning latent prosodic features with a variational framework as is commonly done, we directly extract phoneme-level F0 and duration features from the speech data in the training set. Each prosodic feature is discretized using unsupervised clustering in order to produce a sequence of prosodic labels for each utterance. This sequence is used in parallel to the phoneme sequence in order to condition the decoder with the utilization of a prosodic encoder and a corresponding attention module. Experimental results show that the proposed method retains the high quality of generated speech, while allowing phoneme-level control of F0 and duration. By replacing the F0 cluster centroids with musical notes, the model can also provide control over the note and octave within the range of the speaker.
Multi-accent Speech Separation with One Shot Learning
Jun 28, 2021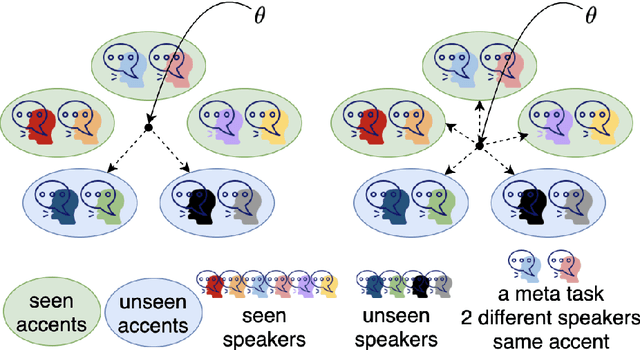
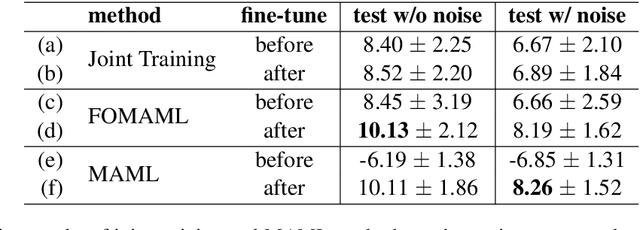
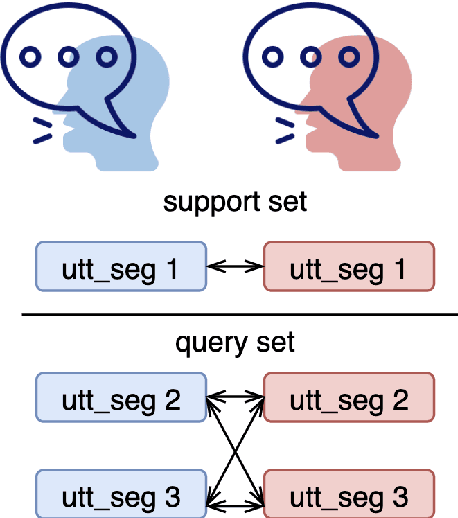
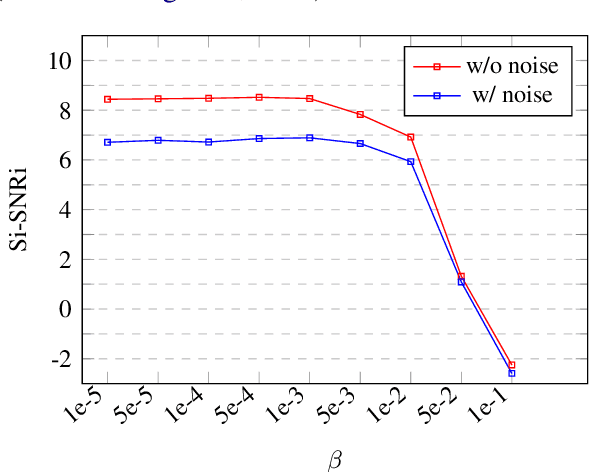
Speech separation is a problem in the field of speech processing that has been studied in full swing recently. However, there has not been much work studying a multi-accent speech separation scenario. Unseen speakers with new accents and noise aroused the domain mismatch problem which cannot be easily solved by conventional joint training methods. Thus, we applied MAML and FOMAML to tackle this problem and obtained higher average Si-SNRi values than joint training on almost all the unseen accents. This proved that these two methods do have the ability to generate well-trained parameters for adapting to speech mixtures of new speakers and accents. Furthermore, we found out that FOMAML obtains similar performance compared to MAML while saving a lot of time.
Improving Character Error Rate Is Not Equal to Having Clean Speech: Speech Enhancement for ASR Systems with Black-box Acoustic Models
Oct 12, 2021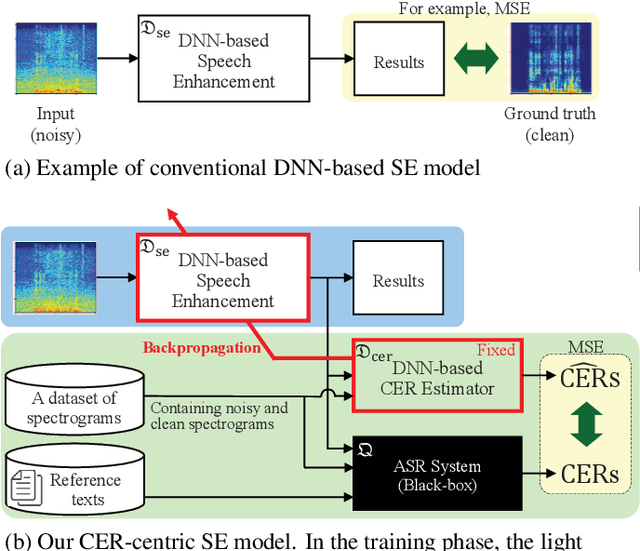
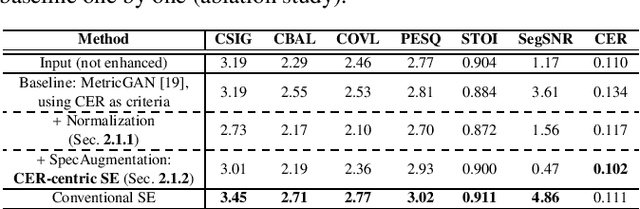
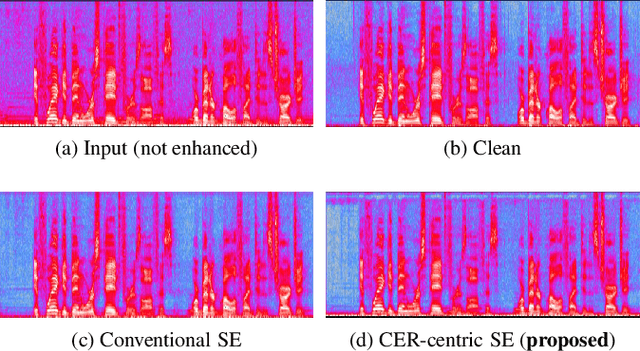
A deep neural network (DNN)-based speech enhancement (SE) aiming to maximize the performance of an automatic speech recognition (ASR) system is proposed in this paper. In order to optimize the DNN-based SE model in terms of the character error rate (CER), which is one of the metric to evaluate the ASR system and generally non-differentiable, our method uses two DNNs: one for speech processing and one for mimicking the output CERs derived through an acoustic model (AM). Then both of DNNs are alternately optimized in the training phase. Even if the AM is a black-box, e.g., like one provided by a third-party, the proposed method enables the DNN-based SE model to be optimized in terms of the CER since the DNN mimicking the AM is differentiable. Consequently, it becomes feasible to build CER-centric SE model that has no negative effect, e.g., additional calculation cost and changing network architecture, on the inference phase since our method is merely a training scheme for the existing DNN-based methods. Experimental results show that our method improved CER by 7.3% relative derived through a black-box AM although certain noise levels are kept.
ParaTTS: Learning Linguistic and Prosodic Cross-sentence Information in Paragraph-based TTS
Sep 14, 2022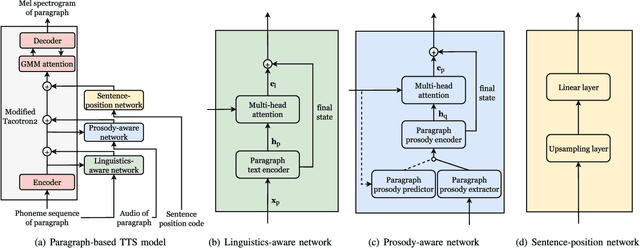


Recent advancements in neural end-to-end TTS models have shown high-quality, natural synthesized speech in a conventional sentence-based TTS. However, it is still challenging to reproduce similar high quality when a whole paragraph is considered in TTS, where a large amount of contextual information needs to be considered in building a paragraph-based TTS model. To alleviate the difficulty in training, we propose to model linguistic and prosodic information by considering cross-sentence, embedded structure in training. Three sub-modules, including linguistics-aware, prosody-aware and sentence-position networks, are trained together with a modified Tacotron2. Specifically, to learn the information embedded in a paragraph and the relations among the corresponding component sentences, we utilize linguistics-aware and prosody-aware networks. The information in a paragraph is captured by encoders and the inter-sentence information in a paragraph is learned with multi-head attention mechanisms. The relative sentence position in a paragraph is explicitly exploited by a sentence-position network. Trained on a storytelling audio-book corpus (4.08 hours), recorded by a female Mandarin Chinese speaker, the proposed TTS model demonstrates that it can produce rather natural and good-quality speech paragraph-wise. The cross-sentence contextual information, such as break and prosodic variations between consecutive sentences, can be better predicted and rendered than the sentence-based model. Tested on paragraph texts, of which the lengths are similar to, longer than, or much longer than the typical paragraph length of the training data, the TTS speech produced by the new model is consistently preferred over the sentence-based model in subjective tests and confirmed in objective measures.
Restoring degraded speech via a modified diffusion model
Apr 22, 2021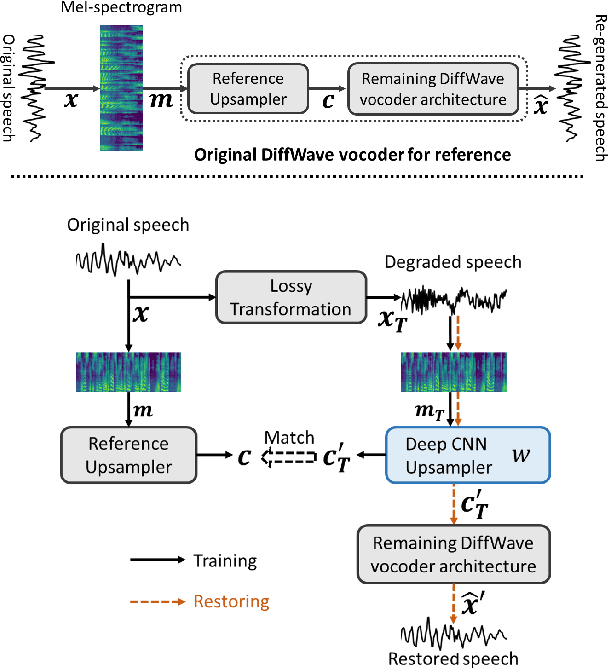
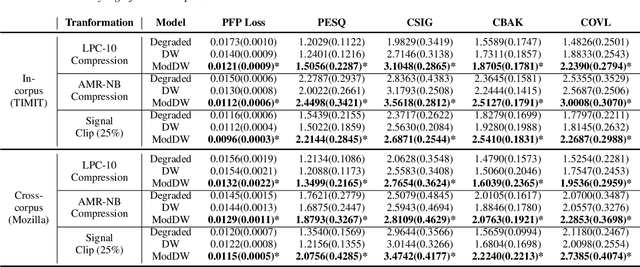
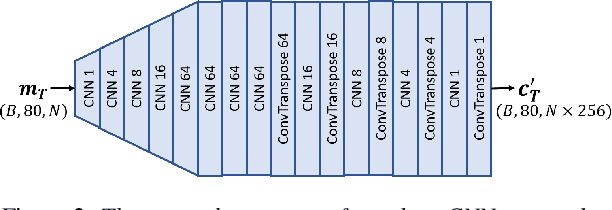

There are many deterministic mathematical operations (e.g. compression, clipping, downsampling) that degrade speech quality considerably. In this paper we introduce a neural network architecture, based on a modification of the DiffWave model, that aims to restore the original speech signal. DiffWave, a recently published diffusion-based vocoder, has shown state-of-the-art synthesized speech quality and relatively shorter waveform generation times, with only a small set of parameters. We replace the mel-spectrum upsampler in DiffWave with a deep CNN upsampler, which is trained to alter the degraded speech mel-spectrum to match that of the original speech. The model is trained using the original speech waveform, but conditioned on the degraded speech mel-spectrum. Post-training, only the degraded mel-spectrum is used as input and the model generates an estimate of the original speech. Our model results in improved speech quality (original DiffWave model as baseline) on several different experiments. These include improving the quality of speech degraded by LPC-10 compression, AMR-NB compression, and signal clipping. Compared to the original DiffWave architecture, our scheme achieves better performance on several objective perceptual metrics and in subjective comparisons. Improvements over baseline are further amplified in a out-of-corpus evaluation setting.