 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Discovering Phonetic Inventories with Crosslingual Automatic Speech Recognition
Jan 28, 2022
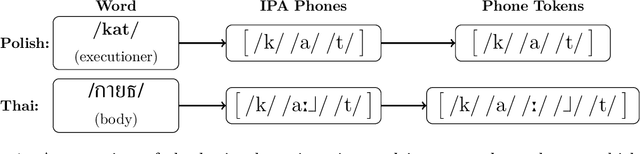
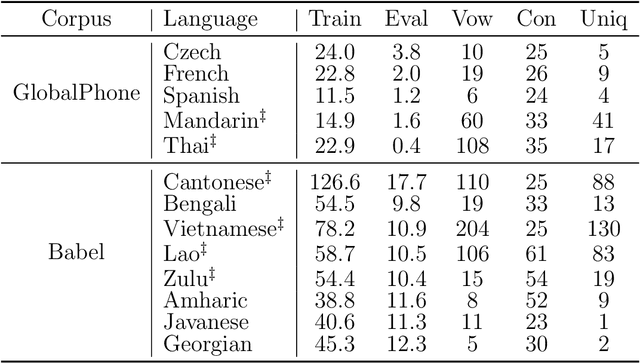
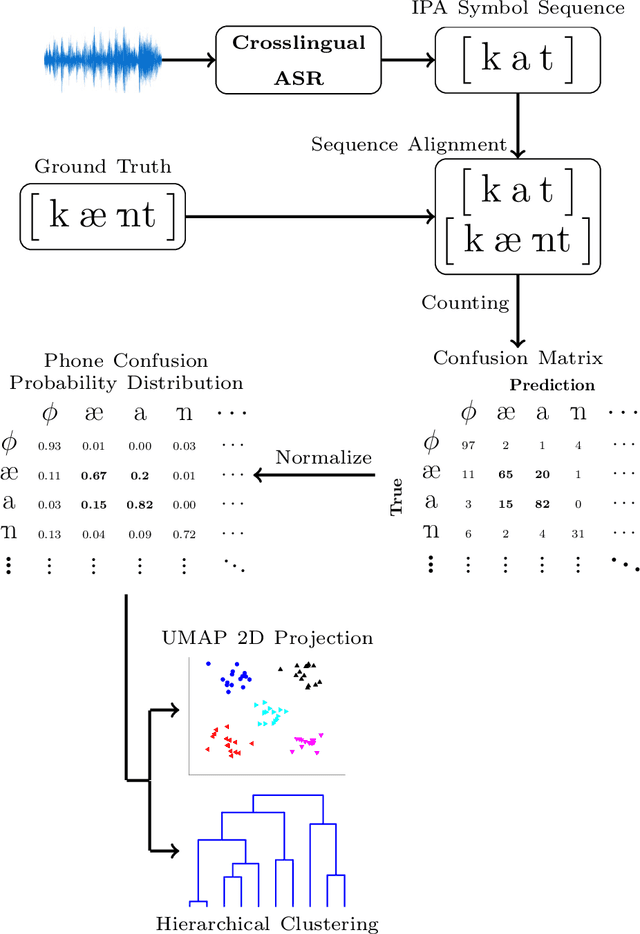
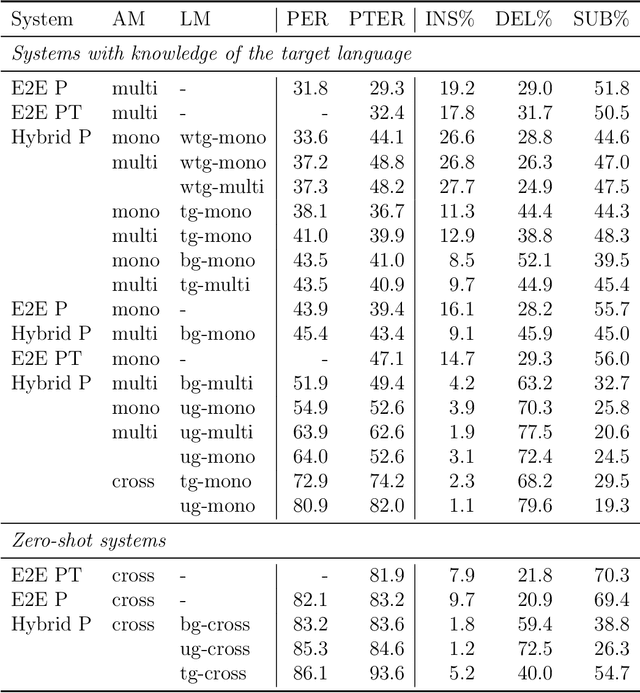
The high cost of data acquisition makes Automatic Speech Recognition (ASR) model training problematic for most existing languages, including languages that do not even have a written script, or for which the phone inventories remain unknown. Past works explored multilingual training, transfer learning, as well as zero-shot learning in order to build ASR systems for these low-resource languages. While it has been shown that the pooling of resources from multiple languages is helpful, we have not yet seen a successful application of an ASR model to a language unseen during training. A crucial step in the adaptation of ASR from seen to unseen languages is the creation of the phone inventory of the unseen language. The ultimate goal of our work is to build the phone inventory of a language unseen during training in an unsupervised way without any knowledge about the language. In this paper, we 1) investigate the influence of different factors (i.e., model architecture, phonotactic model, type of speech representation) on phone recognition in an unknown language; 2) provide an analysis of which phones transfer well across languages and which do not in order to understand the limitations of and areas for further improvement for automatic phone inventory creation; and 3) present different methods to build a phone inventory of an unseen language in an unsupervised way. To that end, we conducted mono-, multi-, and crosslingual experiments on a set of 13 phonetically diverse languages and several in-depth analyses. We found a number of universal phone tokens (IPA symbols) that are well-recognized cross-linguistically. Through a detailed analysis of results, we conclude that unique sounds, similar sounds, and tone languages remain a major challenge for phonetic inventory discovery.
Speech Representations and Phoneme Classification for Preserving the Endangered Language of Ladin
Aug 27, 2021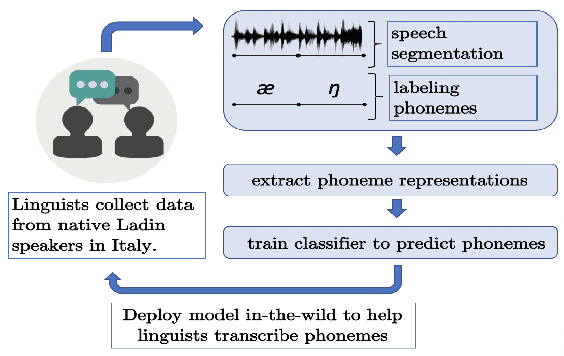
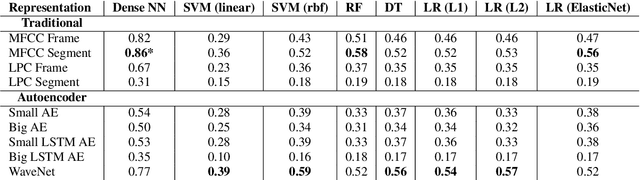
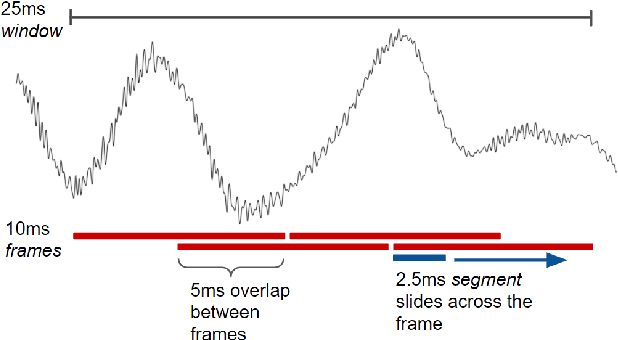
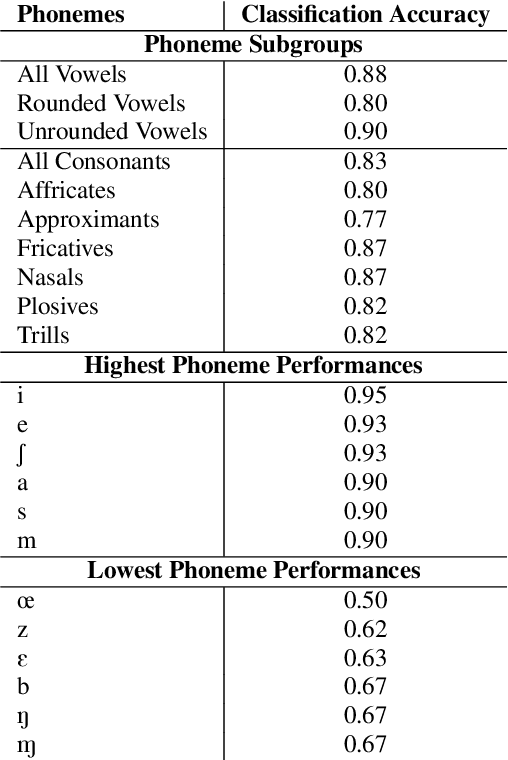
A vast majority of the world's 7,000 spoken languages are predicted to become extinct within this century, including the endangered language of Ladin from the Italian Alps. Linguists who work to preserve a language's phonetic and phonological structure can spend hours transcribing each minute of speech from native speakers. To address this problem in the context of Ladin, our paper presents the first analysis of speech representations and machine learning models for classifying 32 phonemes of Ladin. We experimented with a novel dataset of the Fascian dialect of Ladin, collected from native speakers in Italy. We created frame-level and segment-level speech feature extraction approaches and conducted extensive experiments with 8 different classifiers trained on 9 different speech representations. Our speech representations ranged from traditional features (MFCC, LPC) to features learned with deep neural network models (autoencoders, LSTM autoencoders, and WaveNet). Our highest-performing classifier, trained on MFCC representations of speech signals, achieved an 86% average accuracy across all Ladin phonemes. We also obtained average accuracies above 77% for all Ladin phoneme subgroups examined. Our findings contribute insights for learning discriminative Ladin phoneme representations and demonstrate the potential for leveraging machine learning and speech signal processing to preserve Ladin and other endangered languages.
Inter-channel Conv-TasNet for multichannel speech enhancement
Nov 08, 2021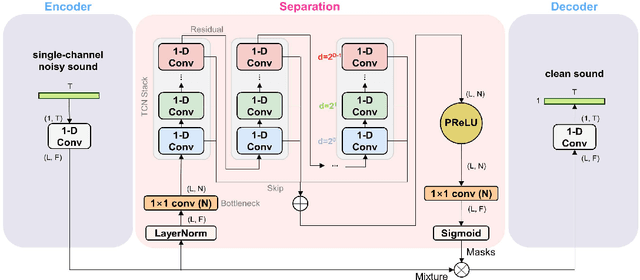

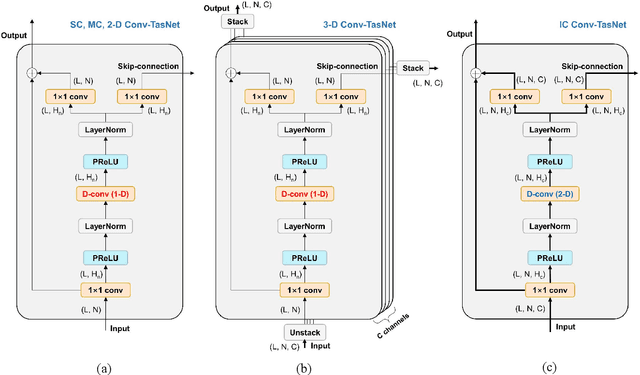
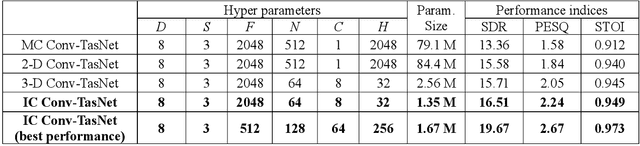
Speech enhancement in multichannel settings has been realized by utilizing the spatial information embedded in multiple microphone signals. Moreover, deep neural networks (DNNs) have been recently advanced in this field; however, studies on the efficient multichannel network structure fully exploiting spatial information and inter-channel relationships is still in its early stages. In this study, we propose an end-to-end time-domain speech enhancement network that can facilitate the use of inter-channel relationships at individual layers of a DNN. The proposed technique is based on a fully convolutional time-domain audio separation network (Conv-TasNet), originally developed for speech separation tasks. We extend Conv-TasNet into several forms that can handle multichannel input signals and learn inter-channel relationships. To this end, we modify the encoder-mask-decoder structures of the network to be compatible with 3-D tensors defined over spatial channels, features, and time dimensions. In particular, we conduct extensive parameter analyses on the convolution structure and propose independent assignment of the depthwise and 1$\times$1 convolution layers to the feature and spatial dimensions, respectively. We demonstrate that the enriched inter-channel information from the proposed network plays a significant role in suppressing noisy signals impinging from various directions. The proposed inter-channel Conv-TasNet outperforms the state-of-the-art multichannel variants of neural networks, even with one-tenth of their parameter size. The performance of the proposed model is evaluated using the CHiME-3 dataset, which exhibits a remarkable improvement in SDR, PESQ, and STOI.
A study on cross-corpus speech emotion recognition and data augmentation
Jan 10, 2022
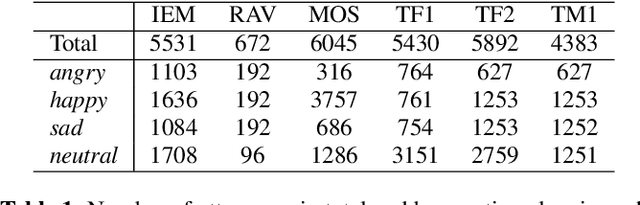

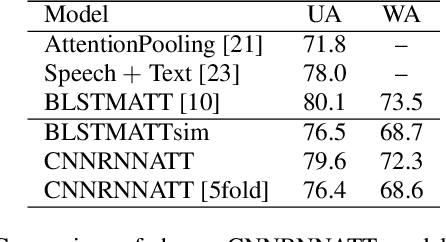
Models that can handle a wide range of speakers and acoustic conditions are essential in speech emotion recognition (SER). Often, these models tend to show mixed results when presented with speakers or acoustic conditions that were not visible during training. This paper investigates the impact of cross-corpus data complementation and data augmentation on the performance of SER models in matched (test-set from same corpus) and mismatched (test-set from different corpus) conditions. Investigations using six emotional speech corpora that include single and multiple speakers as well as variations in emotion style (acted, elicited, natural) and recording conditions are presented. Observations show that, as expected, models trained on single corpora perform best in matched conditions while performance decreases between 10-40% in mismatched conditions, depending on corpus specific features. Models trained on mixed corpora can be more stable in mismatched contexts, and the performance reductions range from 1 to 8% when compared with single corpus models in matched conditions. Data augmentation yields additional gains up to 4% and seem to benefit mismatched conditions more than matched ones.
Canonical Cortical Graph Neural Networks and its Application for Speech Enhancement in Future Audio-Visual Hearing Aids
Jun 06, 2022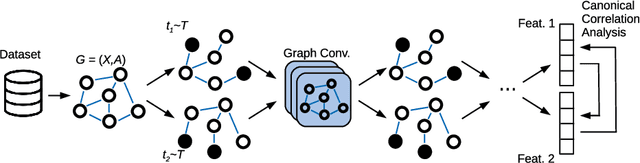
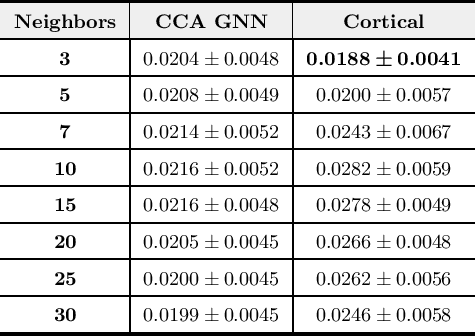
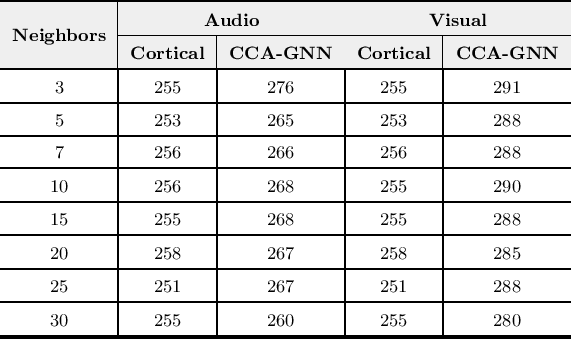
Despite the recent success of machine learning algorithms, most of these models still face several drawbacks when considering more complex tasks requiring interaction between different sources, such as multimodal input data and logical time sequence. On the other hand, the biological brain is highly sharpened in this sense, empowered to automatically manage and integrate such a stream of information through millions of years of evolution. In this context, this paper finds inspiration from recent discoveries on cortical circuits in the brain to propose a more biologically plausible self-supervised machine learning approach that combines multimodal information using intra-layer modulations together with canonical correlation analysis (CCA), as well as a memory mechanism to keep track of temporal data, the so-called Canonical Cortical Graph Neural networks. The approach outperformed recent state-of-the-art results considering both better clean audio reconstruction and energy efficiency, described by a reduced and smother neuron firing rate distribution, suggesting the model as a suitable approach for speech enhancement in future audio-visual hearing aid devices.
Modeling Dependent Structure for Utterances in ASR Evaluation
Sep 07, 2022
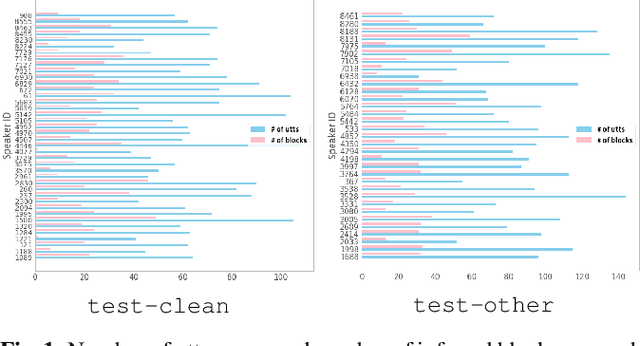
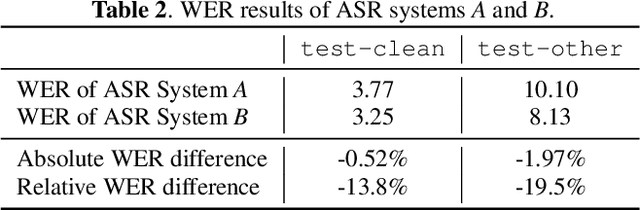
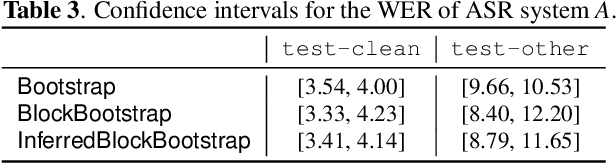
The bootstrap resampling method has been popular for performing significance analysis on word error rate (WER) in automatic speech recognition (ASR) evaluations. To deal with the issue of dependent speech data, the blockwise bootstrap approach is also proposed that by dividing utterances into uncorrelated blocks, it resamples these blocks instead of original data. However, it is always nontrivial to uncover the dependent structure among utterances, which could lead to subjective findings in statistical testing. In this paper, we present graphical lasso based methods to explicitly model such dependency and estimate the independent blocks of utterances in a rigorous way. Then the blockwise bootstrap is applied on top of the inferred blocks. We show that the resulting variance estimator for WER is consistent under mild conditions. We also demonstrate the validity of proposed approach on LibriSpeech data.
Identifying Source Speakers for Voice Conversion based Spoofing Attacks on Speaker Verification Systems
Jun 18, 2022
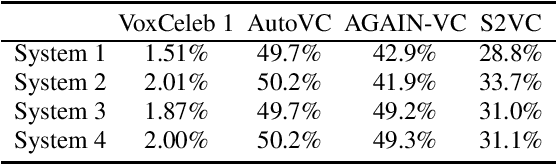


An automatic speaker verification system aims to verify the speaker identity of a speech signal. However, a voice conversion system manipulates the original person's speech signal to make it sound like the target speaker's voice and deceive the speaker verification system. Most countermeasures for voice conversion-based spoofing attacks are designed to discriminate bona fide speech from spoofed speech for speaker verification systems. In this paper, we investigate the problem of source speaker identification -- inferring the identity of the source speaker given the voice converted speech. To perform source speaker identification, we simply add voice-converted speech data with the label of source speaker identity to the genuine speech dataset during speaker embedding network training. Experimental results show the feasibility of source speaker identification when training and testing with converted speeches from the same voice conversion model(s). When testing on converted speeches from an unseen voice conversion algorithm, the performance of source speaker identification improves when more voice conversion models are used during training.
Signal inpainting from Fourier magnitudes
Oct 28, 2022
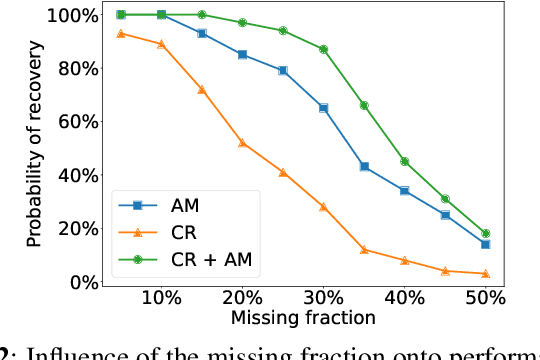
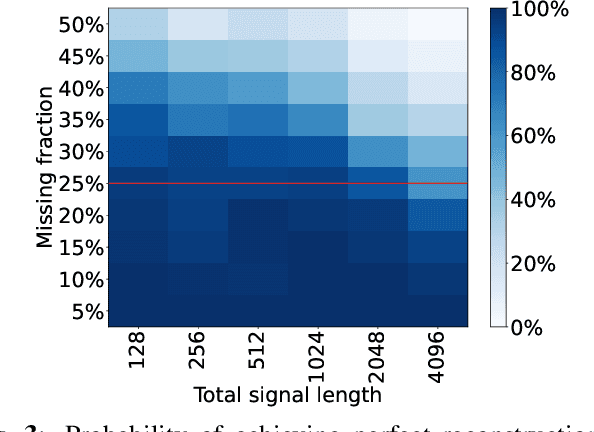
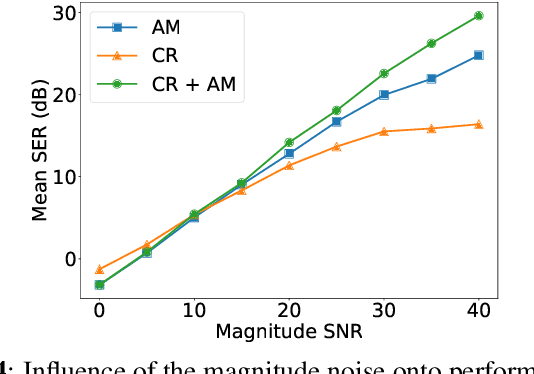
Signal inpainting is the task of restoring degraded or missing samples in a signal. In this paper we address signal inpainting when Fourier magnitudes are observed. We propose a mathematical formulation of the problem that highlights its connection with phase retrieval, and we introduce two methods for solving it. First, we derive an alternating minimization scheme, which shares similarities with the Gerchberg-Saxton algorithm, a classical phase retrieval method. Second, we propose a convex relaxation of the problem, which is inspired by recent approaches that reformulate phase retrieval into a semidefinite program. We assess the potential of these methods for the task of inpainting gaps in speech signals. Our methods exhibit both a high probability of recovering the original signals and robustness to magnitude noise.
CI-AVSR: A Cantonese Audio-Visual Speech Dataset for In-car Command Recognition
Jan 11, 2022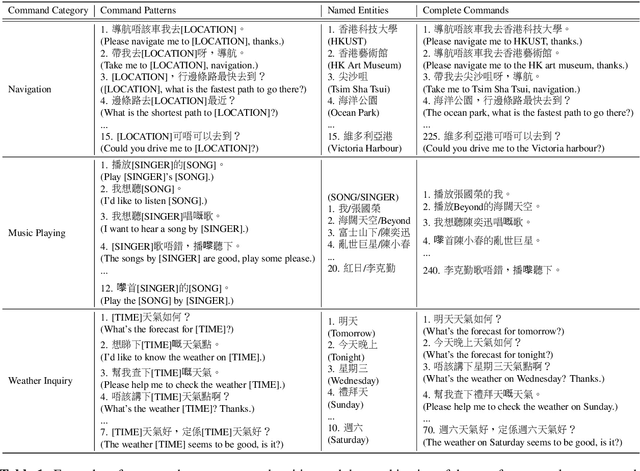
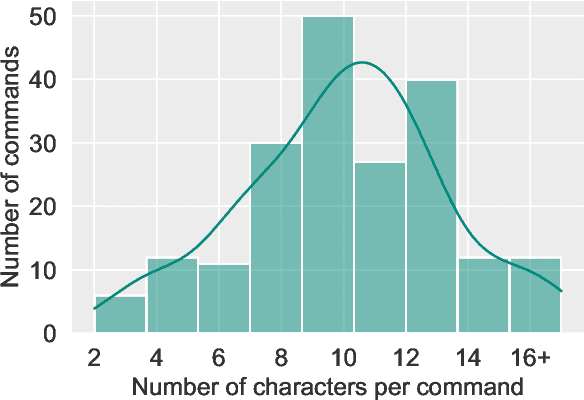
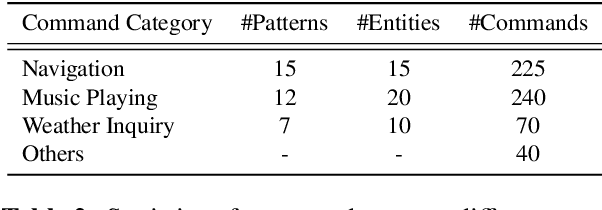
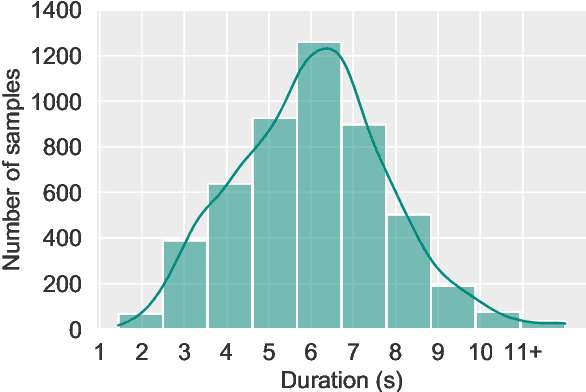
With the rise of deep learning and intelligent vehicle, the smart assistant has become an essential in-car component to facilitate driving and provide extra functionalities. In-car smart assistants should be able to process general as well as car-related commands and perform corresponding actions, which eases driving and improves safety. However, there is a data scarcity issue for low resource languages, hindering the development of research and applications. In this paper, we introduce a new dataset, Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR), for in-car command recognition in the Cantonese language with both video and audio data. It consists of 4,984 samples (8.3 hours) of 200 in-car commands recorded by 30 native Cantonese speakers. Furthermore, we augment our dataset using common in-car background noises to simulate real environments, producing a dataset 10 times larger than the collected one. We provide detailed statistics of both the clean and the augmented versions of our dataset. Moreover, we implement two multimodal baselines to demonstrate the validity of CI-AVSR. Experiment results show that leveraging the visual signal improves the overall performance of the model. Although our best model can achieve a considerable quality on the clean test set, the speech recognition quality on the noisy data is still inferior and remains as an extremely challenging task for real in-car speech recognition systems. The dataset and code will be released at https://github.com/HLTCHKUST/CI-AVSR.