 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Leveraging Low-Distortion Target Estimates for Improved Speech Enhancement
Oct 01, 2021
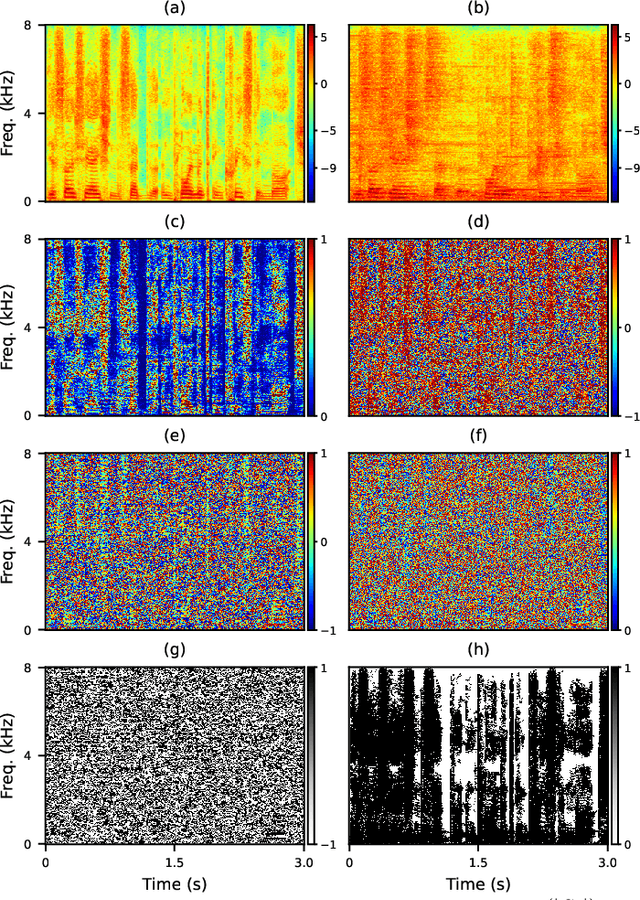
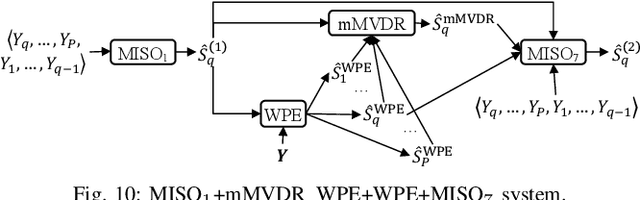
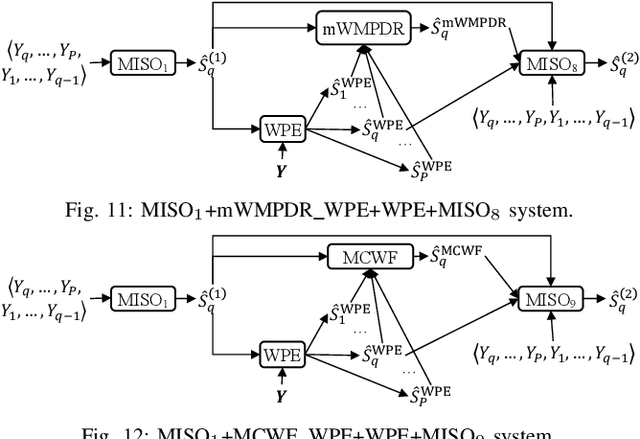
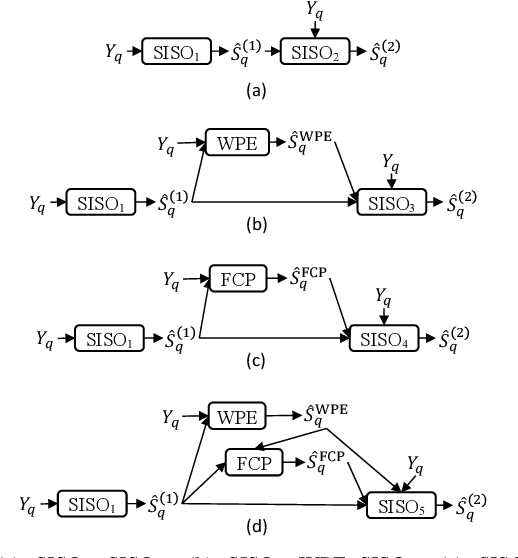
A promising approach for multi-microphone speech separation involves two deep neural networks (DNN), where the predicted target speech from the first DNN is used to compute signal statistics for time-invariant minimum variance distortionless response (MVDR) beamforming, and the MVDR result is then used as extra features for the second DNN to predict target speech. Previous studies suggested that the MVDR result can provide complementary information for the second DNN to better predict target speech. However, on fixed-geometry arrays, both DNNs can take in, for example, the real and imaginary (RI) components of the multi-channel mixture as features to leverage the spatial and spectral information for enhancement. It is not explained clearly why the linear MVDR result can be complementary and why it is still needed, considering that the DNNs and the beamformer use the same input, and the DNNs perform non-linear filtering and could render the linear filtering of MVDR unnecessary. Similarly, in monaural cases, one can replace the MVDR beamformer with a monaural weighted prediction error (WPE) filter. Although the linear WPE filter and the DNNs use the same mixture RI components as input, the WPE result is found to significantly improve the second DNN. This study provides a novel explanation from the perspective of the low-distortion nature of such algorithms, and finds that they can consistently improve phase estimation. Equipped with this understanding, we investigate several low-distortion target estimation algorithms including several beamformers, WPE, forward convolutive prediction, and their combinations, and use their results as extra features to train the second network to achieve better enhancement. Evaluation results on single- and multi-microphone speech dereverberation and enhancement tasks indicate the effectiveness of the proposed approach, and the validity of the proposed view.
A Convolutional Neural Network Based Approach to Recognize Bangla Spoken Digits from Speech Signal
Nov 12, 2021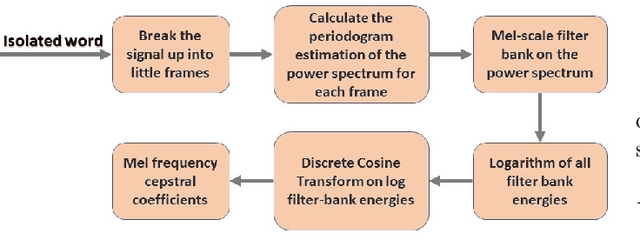
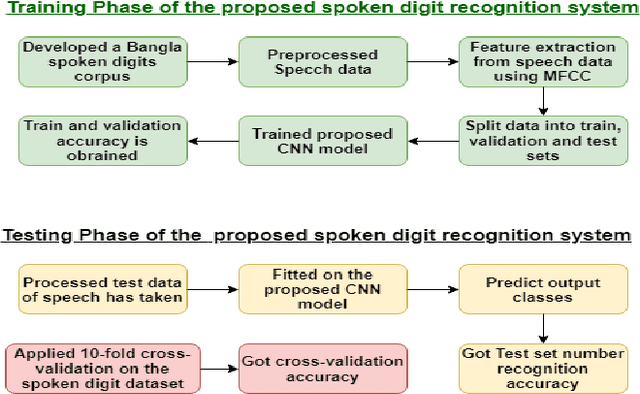
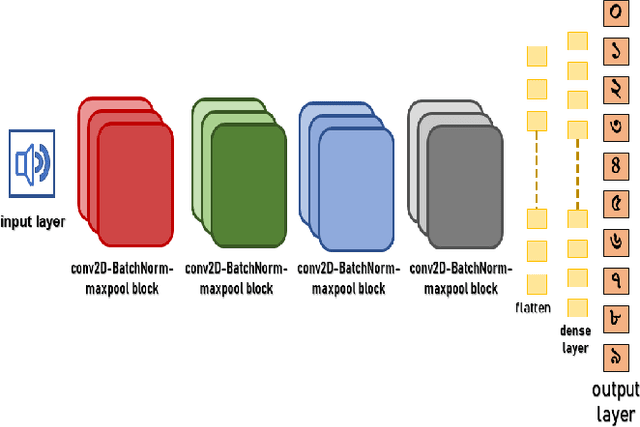
Speech recognition is a technique that converts human speech signals into text or words or in any form that can be easily understood by computers or other machines. There have been a few studies on Bangla digit recognition systems, the majority of which used small datasets with few variations in genders, ages, dialects, and other variables. Audio recordings of Bangladeshi people of various genders, ages, and dialects were used to create a large speech dataset of spoken '0-9' Bangla digits in this study. Here, 400 noisy and noise-free samples per digit have been recorded for creating the dataset. Mel Frequency Cepstrum Coefficients (MFCCs) have been utilized for extracting meaningful features from the raw speech data. Then, to detect Bangla numeral digits, Convolutional Neural Networks (CNNs) were utilized. The suggested technique recognizes '0-9' Bangla spoken digits with 97.1% accuracy throughout the whole dataset. The efficiency of the model was also assessed using 10-fold crossvalidation, which yielded a 96.7% accuracy.
RyanSpeech: A Corpus for Conversational Text-to-Speech Synthesis
Jun 15, 2021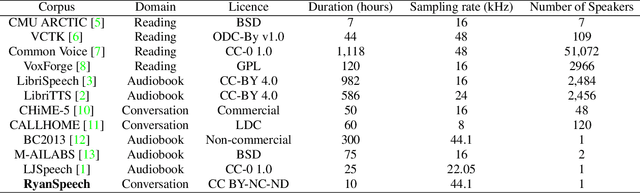
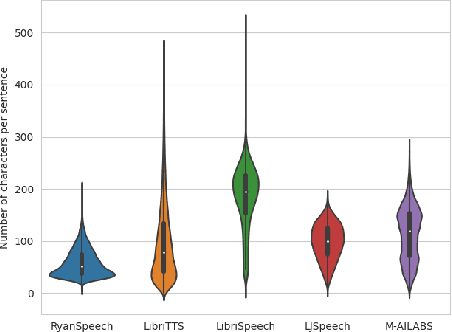
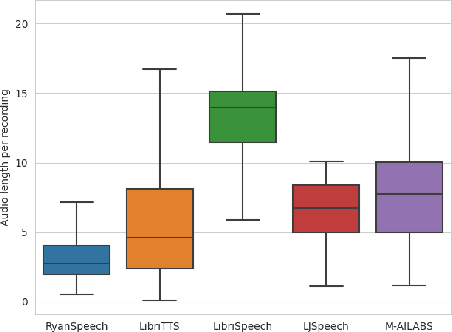
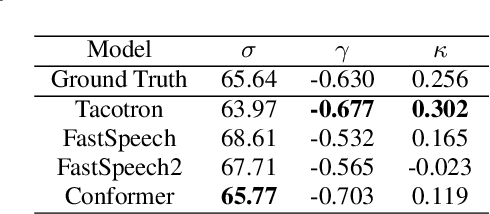
This paper introduces RyanSpeech, a new speech corpus for research on automated text-to-speech (TTS) systems. Publicly available TTS corpora are often noisy, recorded with multiple speakers, or lack quality male speech data. In order to meet the need for a high quality, publicly available male speech corpus within the field of speech recognition, we have designed and created RyanSpeech which contains textual materials from real-world conversational settings. These materials contain over 10 hours of a professional male voice actor's speech recorded at 44.1 kHz. This corpus's design and pipeline make RyanSpeech ideal for developing TTS systems in real-world applications. To provide a baseline for future research, protocols, and benchmarks, we trained 4 state-of-the-art speech models and a vocoder on RyanSpeech. The results show 3.36 in mean opinion scores (MOS) in our best model. We have made both the corpus and trained models for public use.
OFASys: A Multi-Modal Multi-Task Learning System for Building Generalist Models
Dec 08, 2022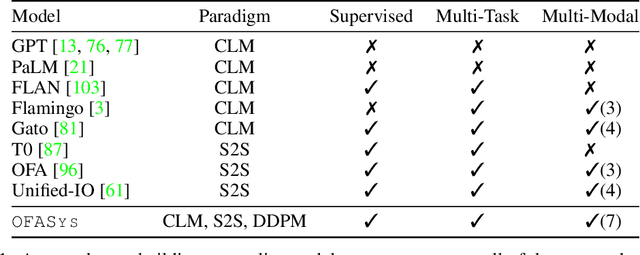
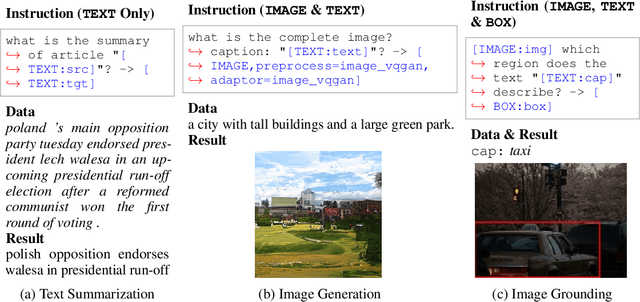
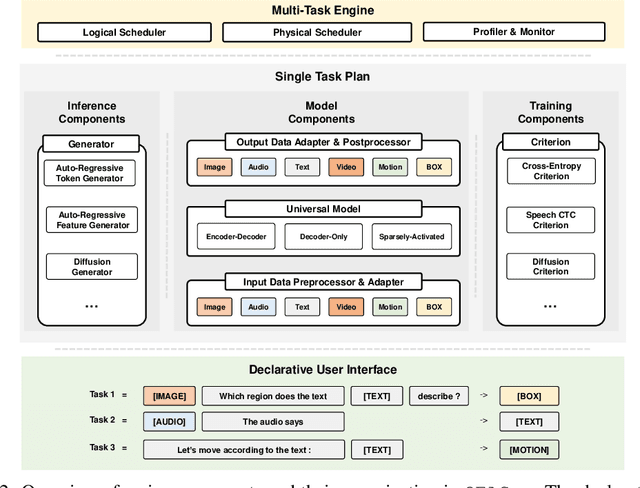

Generalist models, which are capable of performing diverse multi-modal tasks in a task-agnostic way within a single model, have been explored recently. Being, hopefully, an alternative to approaching general-purpose AI, existing generalist models are still at an early stage, where modality and task coverage is limited. To empower multi-modal task-scaling and speed up this line of research, we release a generalist model learning system, OFASys, built on top of a declarative task interface named multi-modal instruction. At the core of OFASys is the idea of decoupling multi-modal task representations from the underlying model implementations. In OFASys, a task involving multiple modalities can be defined declaratively even with just a single line of code. The system automatically generates task plans from such instructions for training and inference. It also facilitates multi-task training for diverse multi-modal workloads. As a starting point, we provide presets of 7 different modalities and 23 highly-diverse example tasks in OFASys, with which we also develop a first-in-kind, single model, OFA+, that can handle text, image, speech, video, and motion data. The single OFA+ model achieves 95% performance in average with only 16% parameters of 15 task-finetuned models, showcasing the performance reliability of multi-modal task-scaling provided by OFASys. Available at https://github.com/OFA-Sys/OFASys
Improving Label-Deficient Keyword Spotting Using Self-Supervised Pretraining
Oct 04, 2022
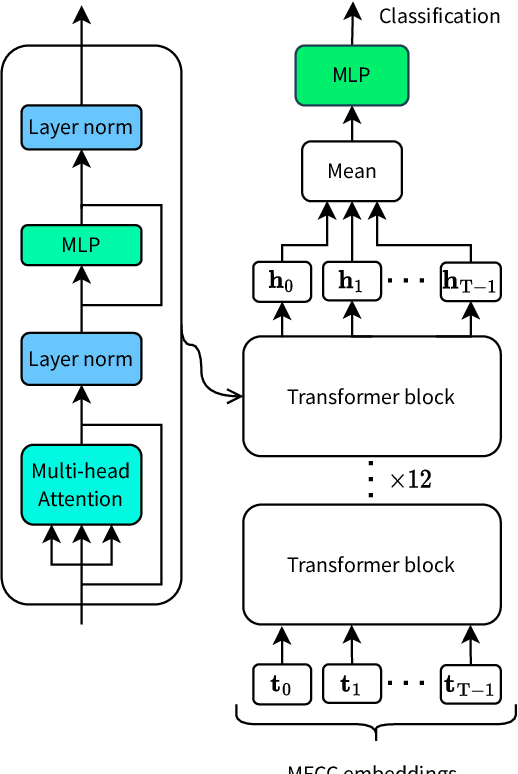

In recent years, the development of accurate deep keyword spotting (KWS) models has resulted in KWS technology being embedded in a number of technologies such as voice assistants. Many of these models rely on large amounts of labelled data to achieve good performance. As a result, their use is restricted to applications for which a large labelled speech data set can be obtained. Self-supervised learning seeks to mitigate the need for large labelled data sets by leveraging unlabelled data, which is easier to obtain in large amounts. However, most self-supervised methods have only been investigated for very large models, whereas KWS models are desired to be small. In this paper, we investigate the use of self-supervised pretraining for the smaller KWS models in a label-deficient scenario. We pretrain the Keyword Transformer model using the self-supervised framework Data2Vec and carry out experiments on a label-deficient setup of the Google Speech Commands data set. It is found that the pretrained models greatly outperform the models without pretraining, showing that Data2Vec pretraining can increase the performance of KWS models in label-deficient scenarios. The source code is made publicly available.
Audio Deepfake Detection Based on a Combination of F0 Information and Real Plus Imaginary Spectrogram Features
Aug 02, 2022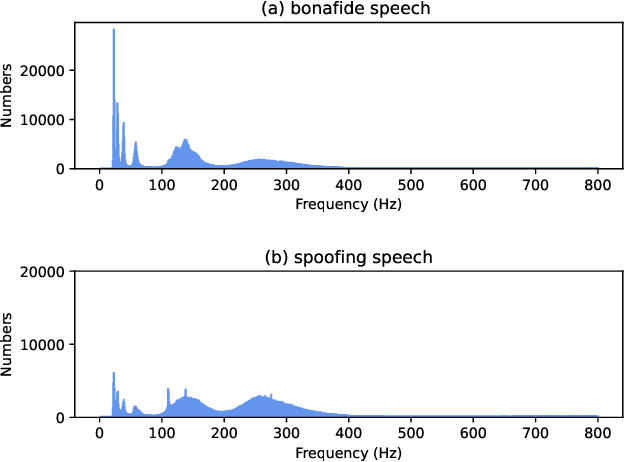

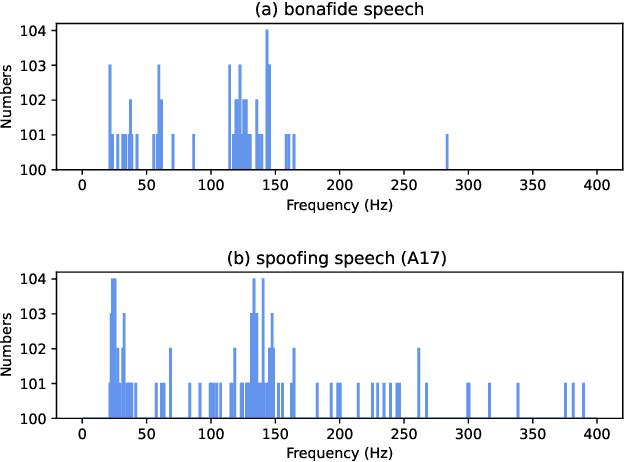
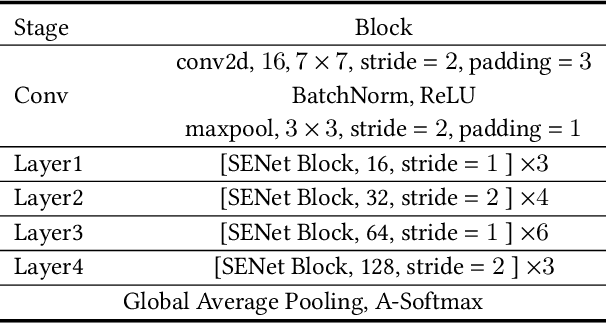
Recently, pioneer research works have proposed a large number of acoustic features (log power spectrogram, linear frequency cepstral coefficients, constant Q cepstral coefficients, etc.) for audio deepfake detection, obtaining good performance, and showing that different subbands have different contributions to audio deepfake detection. However, this lacks an explanation of the specific information in the subband, and these features also lose information such as phase. Inspired by the mechanism of synthetic speech, the fundamental frequency (F0) information is used to improve the quality of synthetic speech, while the F0 of synthetic speech is still too average, which differs significantly from that of real speech. It is expected that F0 can be used as important information to discriminate between bonafide and fake speech, while this information cannot be used directly due to the irregular distribution of F0. Insteadly, the frequency band containing most of F0 is selected as the input feature. Meanwhile, to make full use of the phase and full-band information, we also propose to use real and imaginary spectrogram features as complementary input features and model the disjoint subbands separately. Finally, the results of F0, real and imaginary spectrogram features are fused. Experimental results on the ASVspoof 2019 LA dataset show that our proposed system is very effective for the audio deepfake detection task, achieving an equivalent error rate (EER) of 0.43%, which surpasses almost all systems.
Semantic Communications for Speech Recognition
Jul 22, 2021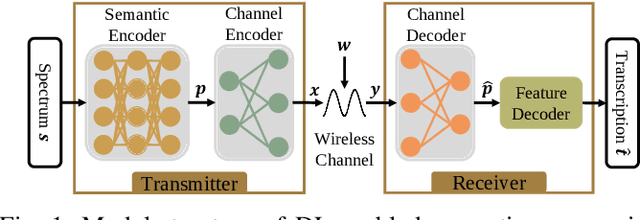
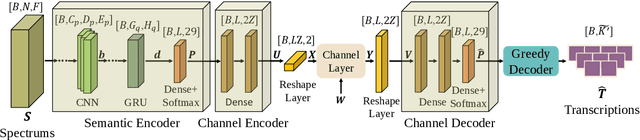
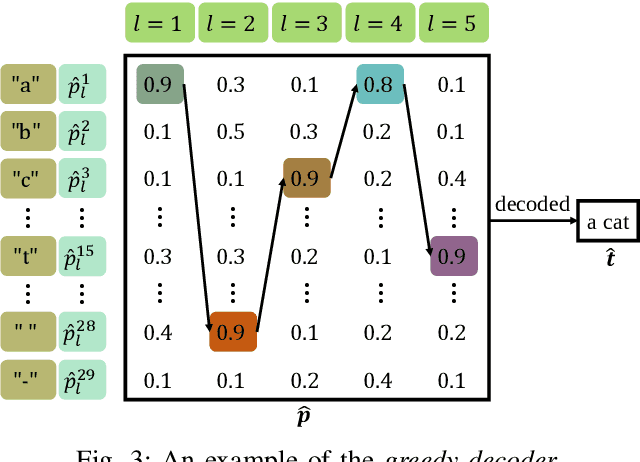
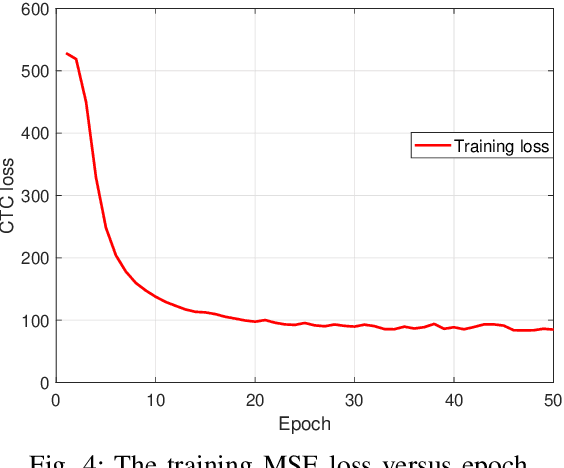
The traditional communications transmit all the source date represented by bits, regardless of the content of source and the semantic information required by the receiver. However, in some applications, the receiver only needs part of the source data that represents critical semantic information, which prompts to transmit the application-related information, especially when bandwidth resources are limited. In this paper, we consider a semantic communication system for speech recognition by designing the transceiver as an end-to-end (E2E) system. Particularly, a deep learning (DL)-enabled semantic communication system, named DeepSC-SR, is developed to learn and extract text-related semantic features at the transmitter, which motivates the system to transmit much less than the source speech data without performance degradation. Moreover, in order to facilitate the proposed DeepSC-SR for dynamic channel environments, we investigate a robust model to cope with various channel environments without requiring retraining. The simulation results demonstrate that our proposed DeepSC-SR outperforms the traditional communication systems in terms of the speech recognition metrics, such as character-error-rate and word-error-rate, and is more robust to channel variations, especially in the low signal-to-noise (SNR) regime.
Accent-Robust Automatic Speech Recognition Using Supervised and Unsupervised Wav2vec Embeddings
Oct 08, 2021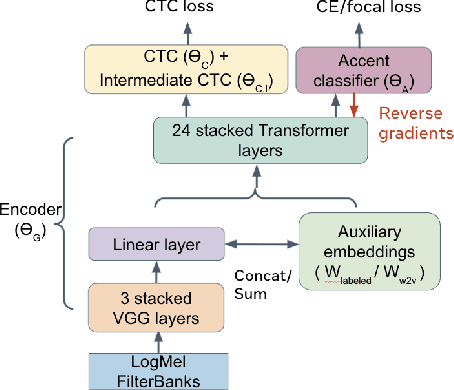
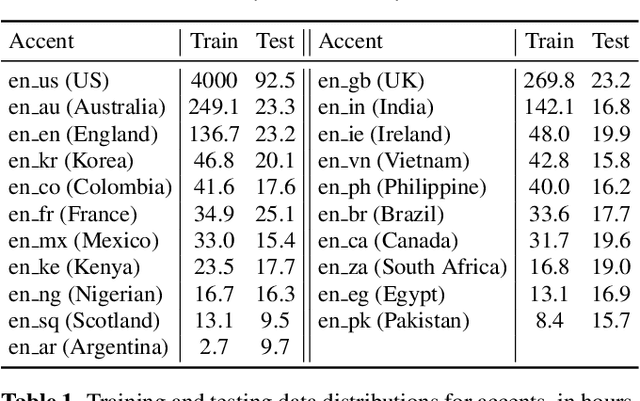
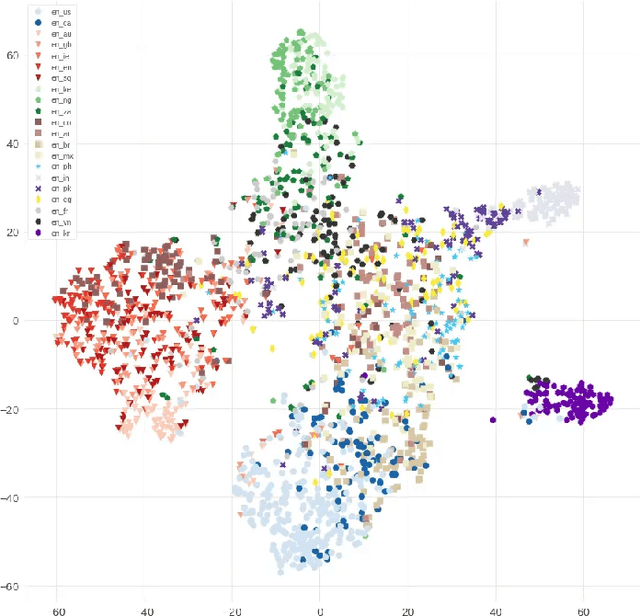

Speech recognition models often obtain degraded performance when tested on speech with unseen accents. Domain-adversarial training (DAT) and multi-task learning (MTL) are two common approaches for building accent-robust ASR models. ASR models using accent embeddings is another approach for improving robustness to accents. In this study, we perform systematic comparisons of DAT and MTL approaches using a large volume of English accent corpus (4000 hours of US English speech and 1244 hours of 20 non-US-English accents speech). We explore embeddings trained under supervised and unsupervised settings: a separate embedding matrix trained using accent labels, and embeddings extracted from a fine-tuned wav2vec model. We find that our DAT model trained with supervised embeddings achieves the best performance overall and consistently provides benefits for all testing datasets, and our MTL model trained with wav2vec embeddings are helpful learning accent-invariant features and improving novel/unseen accents. We also illustrate that wav2vec embeddings have more advantages for building accent-robust ASR when no accent labels are available for training supervised embeddings.
S-DCCRN: Super Wide Band DCCRN with learnable complex feature for speech enhancement
Nov 16, 2021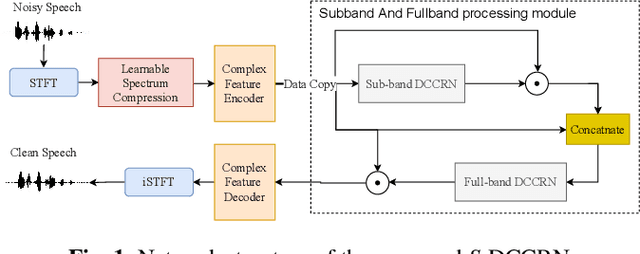
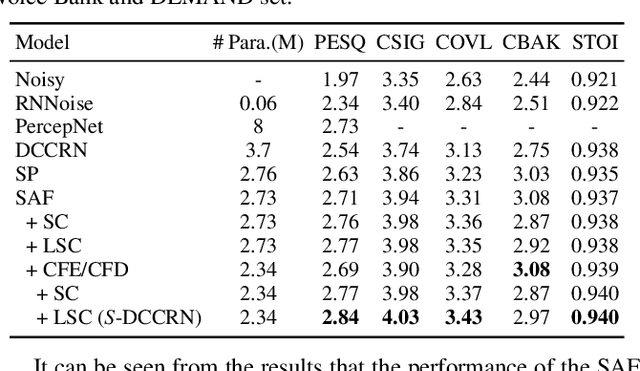
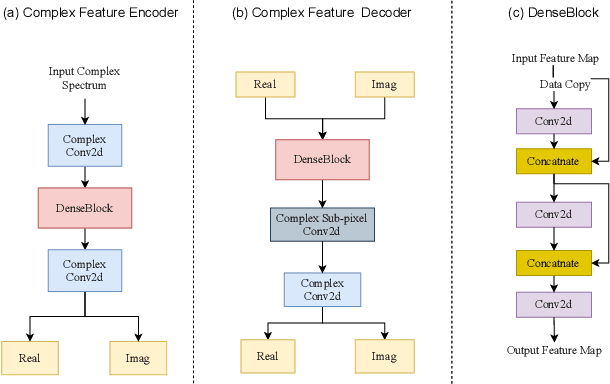
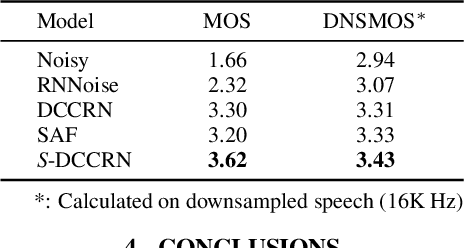
In speech enhancement, complex neural network has shown promising performance due to their effectiveness in processing complex-valued spectrum. Most of the recent speech enhancement approaches mainly focus on wide-band signal with a sampling rate of 16K Hz. However, research on super wide band (e.g., 32K Hz) or even full-band (48K) denoising is still lacked due to the difficulty of modeling more frequency bands and particularly high frequency components. In this paper, we extend our previous deep complex convolution recurrent neural network (DCCRN) substantially to a super wide band version -- S-DCCRN, to perform speech denoising on speech of 32K Hz sampling rate. We first employ a cascaded sub-band and full-band processing module, which consists of two small-footprint DCCRNs -- one operates on sub-band signal and one operates on full-band signal, aiming at benefiting from both local and global frequency information. Moreover, instead of simply adopting the STFT feature as input, we use a complex feature encoder trained in an end-to-end manner to refine the information of different frequency bands. We also use a complex feature decoder to revert the feature to time-frequency domain. Finally, a learnable spectrum compression method is adopted to adjust the energy of different frequency bands, which is beneficial for neural network learning. The proposed model, S-DCCRN, has surpassed PercepNet as well as several competitive models and achieves state-of-the-art performance in terms of speech quality and intelligibility. Ablation studies also demonstrate the effectiveness of different contributions.
Kosp2e: Korean Speech to English Translation Corpus
Jul 06, 2021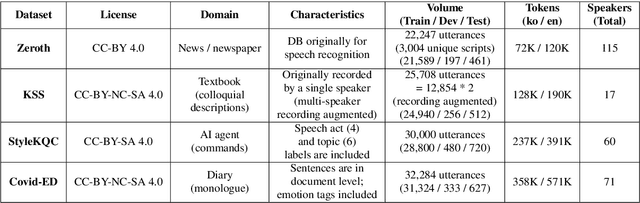
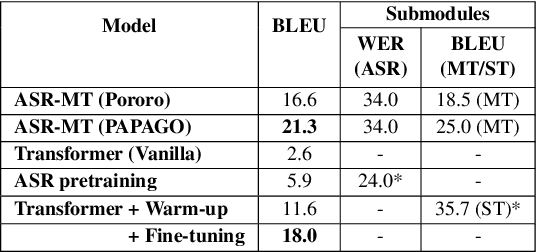
Most speech-to-text (S2T) translation studies use English speech as a source, which makes it difficult for non-English speakers to take advantage of the S2T technologies. For some languages, this problem was tackled through corpus construction, but the farther linguistically from English or the more under-resourced, this deficiency and underrepresentedness becomes more significant. In this paper, we introduce kosp2e (read as `kospi'), a corpus that allows Korean speech to be translated into English text in an end-to-end manner. We adopt open license speech recognition corpus, translation corpus, and spoken language corpora to make our dataset freely available to the public, and check the performance through the pipeline and training-based approaches. Using pipeline and various end-to-end schemes, we obtain the highest BLEU of 21.3 and 18.0 for each based on the English hypothesis, validating the feasibility of our data. We plan to supplement annotations for other target languages through community contributions in the future.