 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
FDLP-Spectrogram: Capturing Speech Dynamics in Spectrograms for End-to-end Automatic Speech Recognition
Mar 25, 2021
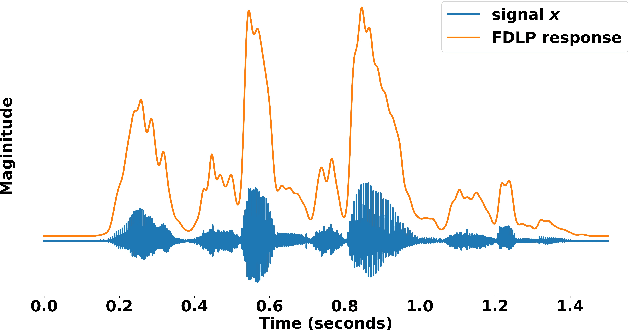

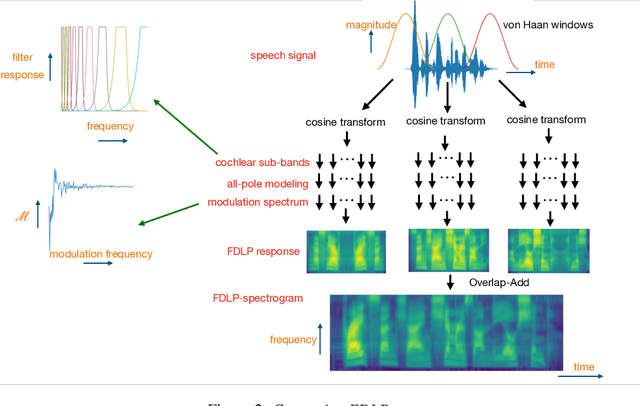

We propose a technique to compute spectrograms using Frequency Domain Linear Prediction (FDLP) that uses all-pole models to fit the Hilbert envelope of speech in different frequency sub-bands. The spectrogram of a complete speech utterance is computed by overlap-add of contiguous all-pole model responses. The long context window of 1.5 seconds allows us to capture the low frequency temporal modulations of speech in the spectrogram. For an end-to-end automatic speech recognition task, the FDLP-spectrogram performs at-par with the standard mel-spectrogram features for clean read speech training and test data. For more realistic mismatched train-test situations and noisy, reverberated training data, the FDLP-spectrogram shows up to 25% and 22% WER improvements over mel-spectrogram respectively.
S-DCCRN: Super Wide Band DCCRN with learnable complex feature for speech enhancement
Nov 16, 2021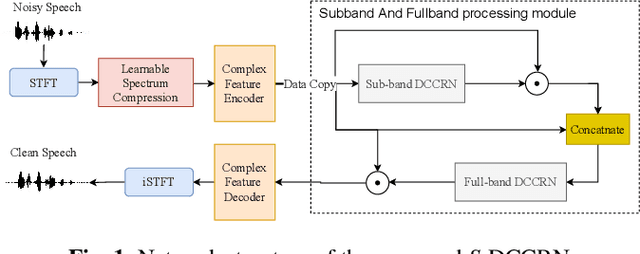
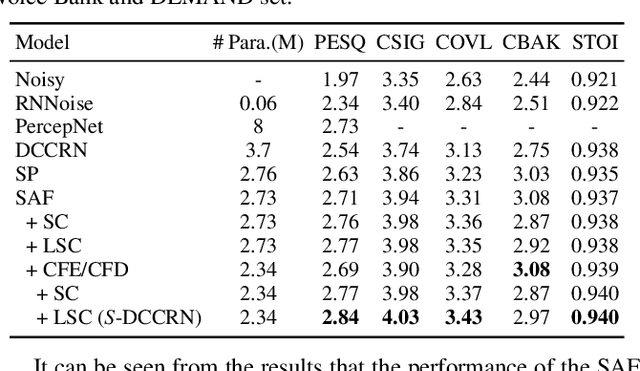
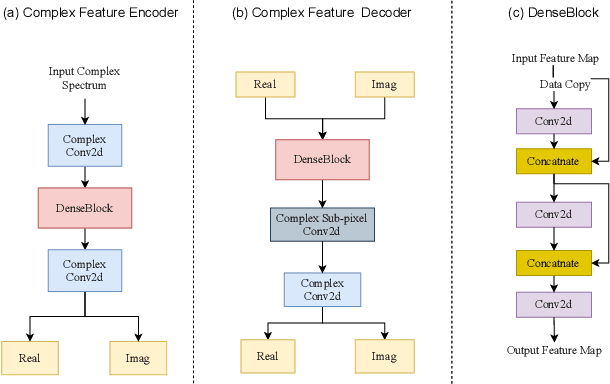
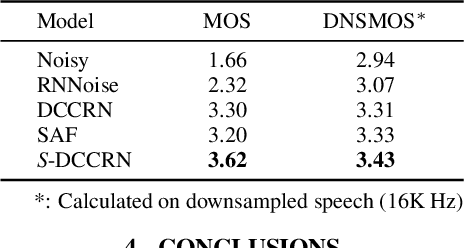
In speech enhancement, complex neural network has shown promising performance due to their effectiveness in processing complex-valued spectrum. Most of the recent speech enhancement approaches mainly focus on wide-band signal with a sampling rate of 16K Hz. However, research on super wide band (e.g., 32K Hz) or even full-band (48K) denoising is still lacked due to the difficulty of modeling more frequency bands and particularly high frequency components. In this paper, we extend our previous deep complex convolution recurrent neural network (DCCRN) substantially to a super wide band version -- S-DCCRN, to perform speech denoising on speech of 32K Hz sampling rate. We first employ a cascaded sub-band and full-band processing module, which consists of two small-footprint DCCRNs -- one operates on sub-band signal and one operates on full-band signal, aiming at benefiting from both local and global frequency information. Moreover, instead of simply adopting the STFT feature as input, we use a complex feature encoder trained in an end-to-end manner to refine the information of different frequency bands. We also use a complex feature decoder to revert the feature to time-frequency domain. Finally, a learnable spectrum compression method is adopted to adjust the energy of different frequency bands, which is beneficial for neural network learning. The proposed model, S-DCCRN, has surpassed PercepNet as well as several competitive models and achieves state-of-the-art performance in terms of speech quality and intelligibility. Ablation studies also demonstrate the effectiveness of different contributions.
The Conversational Short-phrase Speaker Diarization (CSSD) Task: Dataset, Evaluation Metric and Baselines
Aug 17, 2022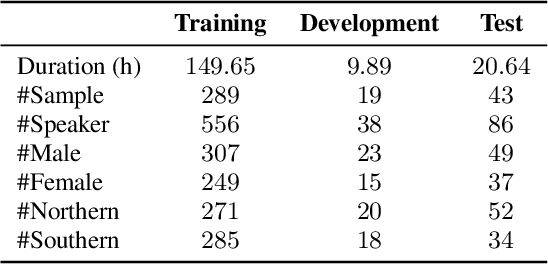

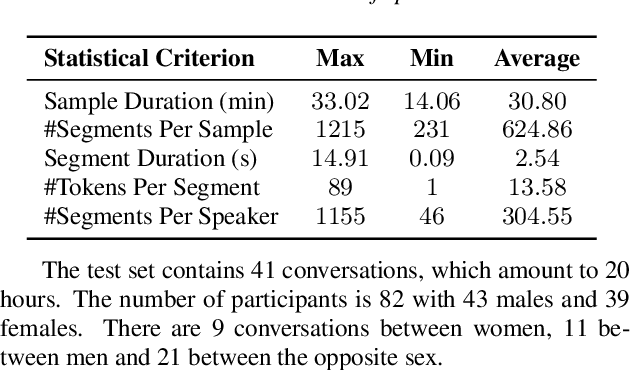
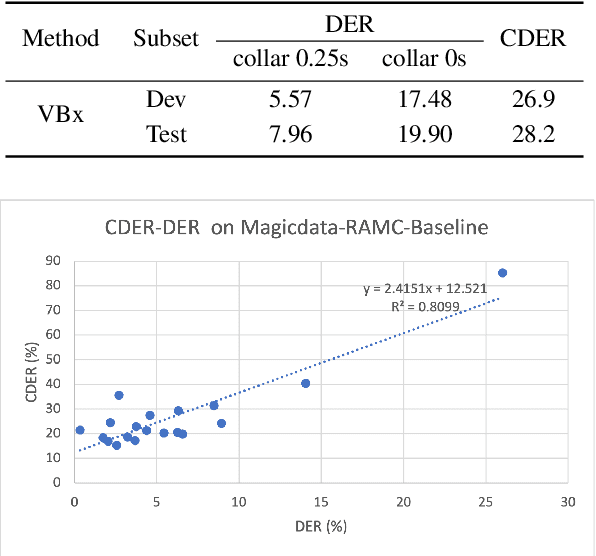
The conversation scenario is one of the most important and most challenging scenarios for speech processing technologies because people in conversation respond to each other in a casual style. Detecting the speech activities of each person in a conversation is vital to downstream tasks, like natural language processing, machine translation, etc. People refer to the detection technology of "who speak when" as speaker diarization (SD). Traditionally, diarization error rate (DER) has been used as the standard evaluation metric of SD systems for a long time. However, DER fails to give enough importance to short conversational phrases, which are short but important on the semantic level. Also, a carefully and accurately manually-annotated testing dataset suitable for evaluating the conversational SD technologies is still unavailable in the speech community. In this paper, we design and describe the Conversational Short-phrases Speaker Diarization (CSSD) task, which consists of training and testing datasets, evaluation metric and baselines. In the dataset aspect, despite the previously open-sourced 180-hour conversational MagicData-RAMC dataset, we prepare an individual 20-hour conversational speech test dataset with carefully and artificially verified speakers timestamps annotations for the CSSD task. In the metric aspect, we design the new conversational DER (CDER) evaluation metric, which calculates the SD accuracy at the utterance level. In the baseline aspect, we adopt a commonly used method: Variational Bayes HMM x-vector system, as the baseline of the CSSD task. Our evaluation metric is publicly available at https://github.com/SpeechClub/CDER_Metric.
HLT-NUS SUBMISSION FOR 2020 NIST Conversational Telephone Speech SRE
Nov 12, 2021
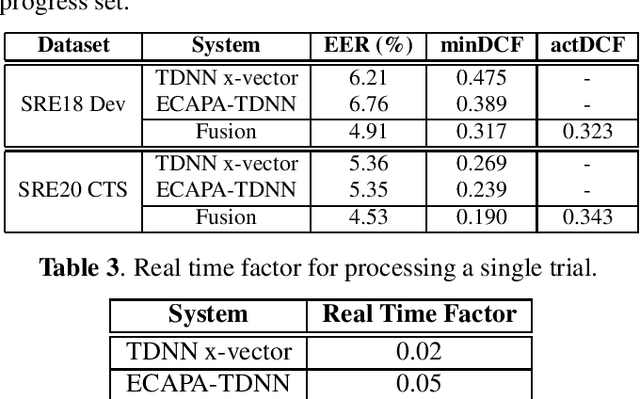
This work provides a brief description of Human Language Technology (HLT) Laboratory, National University of Singapore (NUS) system submission for 2020 NIST conversational telephone speech (CTS) speaker recognition evaluation (SRE). The challenge focuses on evaluation under CTS data containing multilingual speech. The systems developed at HLT-NUS consider time-delay neural network (TDNN) x-vector and ECAPA-TDNN systems. We also perform domain adaption of probabilistic linear discriminant analysis (PLDA) model and adaptive s-norm on our systems. The score level fusion of TDNN x-vector and ECAPA-TDNN systems is carried out, which improves the final system performance of our submission to 2020 NIST CTS SRE.
Accent-Robust Automatic Speech Recognition Using Supervised and Unsupervised Wav2vec Embeddings
Oct 08, 2021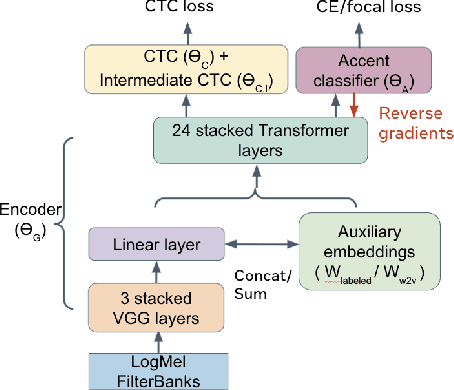
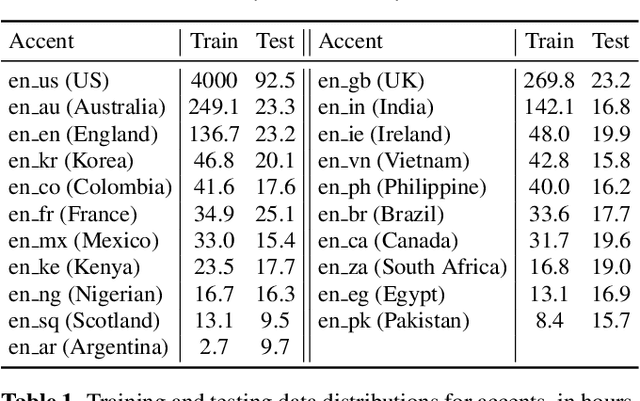
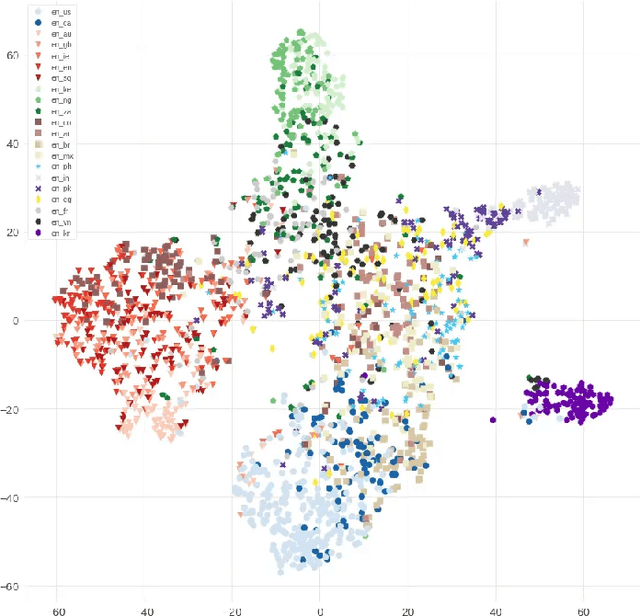

Speech recognition models often obtain degraded performance when tested on speech with unseen accents. Domain-adversarial training (DAT) and multi-task learning (MTL) are two common approaches for building accent-robust ASR models. ASR models using accent embeddings is another approach for improving robustness to accents. In this study, we perform systematic comparisons of DAT and MTL approaches using a large volume of English accent corpus (4000 hours of US English speech and 1244 hours of 20 non-US-English accents speech). We explore embeddings trained under supervised and unsupervised settings: a separate embedding matrix trained using accent labels, and embeddings extracted from a fine-tuned wav2vec model. We find that our DAT model trained with supervised embeddings achieves the best performance overall and consistently provides benefits for all testing datasets, and our MTL model trained with wav2vec embeddings are helpful learning accent-invariant features and improving novel/unseen accents. We also illustrate that wav2vec embeddings have more advantages for building accent-robust ASR when no accent labels are available for training supervised embeddings.
Universal Adaptor: Converting Mel-Spectrograms Between Different Configurations for Speech Synthesis
Apr 01, 2022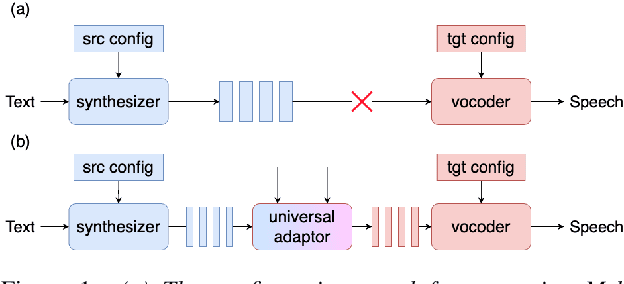

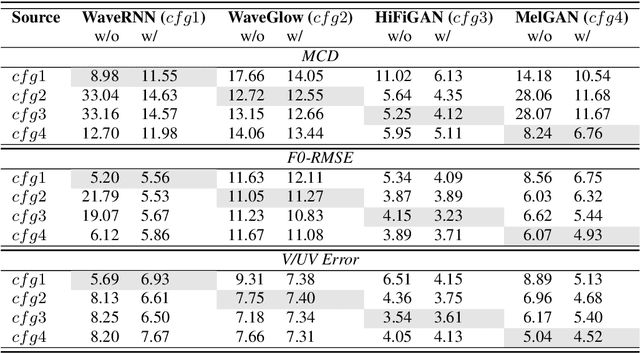
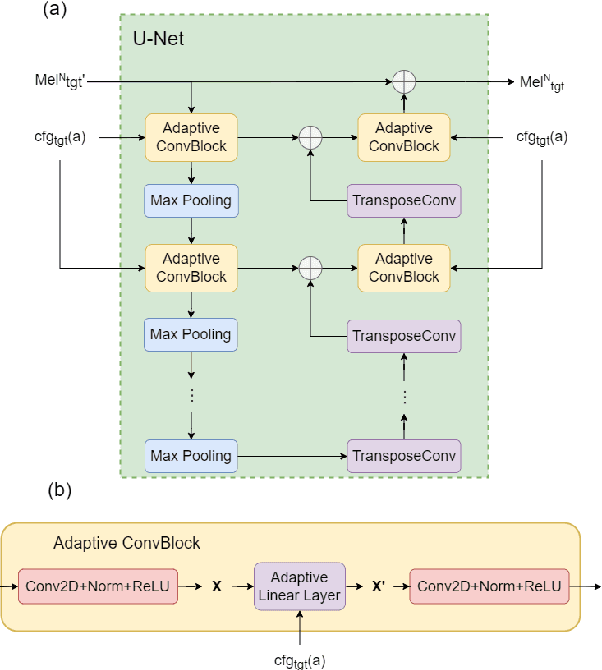
Most recent TTS systems are composed of a synthesizer and a vocoder. However, the existing synthesizers and vocoders can only be matched to acoustic features extracted with a specific configuration. Hence, we can't combine arbitrary synthesizers and vocoders together to form a complete TTS system, not to mention applying to a newly developed model. In this paper, we proposed a universal adaptor, which takes a Mel-spectogram parametrized by the source configuration and converts it into a Mel-spectrogram parametrized by the target configuration, as long as we feed in the source and the target configurations. Experiments show that the quality of speeches synthesized from our output of the universal adaptor is comparable to those synthesized from ground truth Mel-spectrogram. Moreover, our universal adaptor can be applied in the recent TTS systems and in multi-speaker speech synthesis without dropping quality.
RyanSpeech: A Corpus for Conversational Text-to-Speech Synthesis
Jun 15, 2021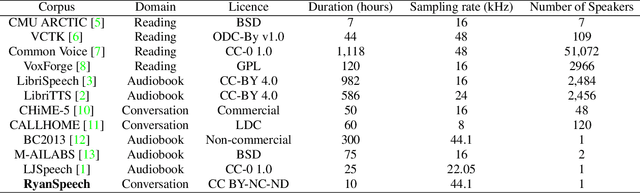
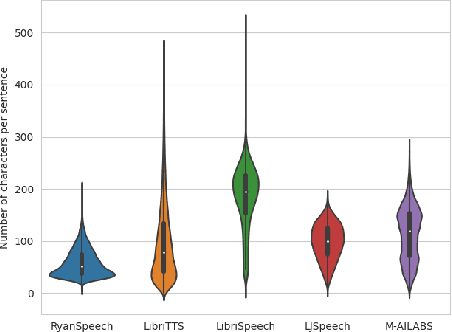
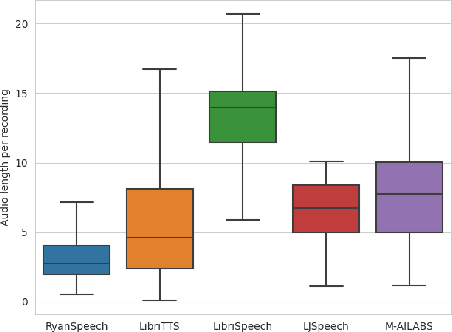
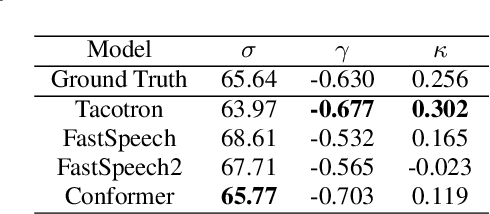
This paper introduces RyanSpeech, a new speech corpus for research on automated text-to-speech (TTS) systems. Publicly available TTS corpora are often noisy, recorded with multiple speakers, or lack quality male speech data. In order to meet the need for a high quality, publicly available male speech corpus within the field of speech recognition, we have designed and created RyanSpeech which contains textual materials from real-world conversational settings. These materials contain over 10 hours of a professional male voice actor's speech recorded at 44.1 kHz. This corpus's design and pipeline make RyanSpeech ideal for developing TTS systems in real-world applications. To provide a baseline for future research, protocols, and benchmarks, we trained 4 state-of-the-art speech models and a vocoder on RyanSpeech. The results show 3.36 in mean opinion scores (MOS) in our best model. We have made both the corpus and trained models for public use.
Prediction of Listener Perception of Argumentative Speech in a Crowdsourced Dataset Using (Psycho-)Linguistic and Fluency Features
Nov 30, 2021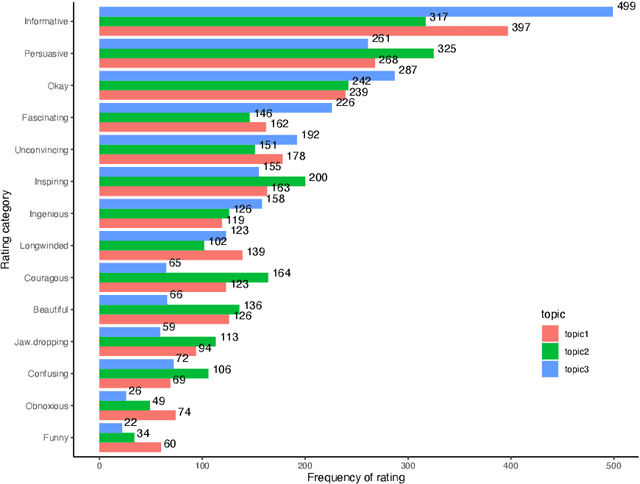
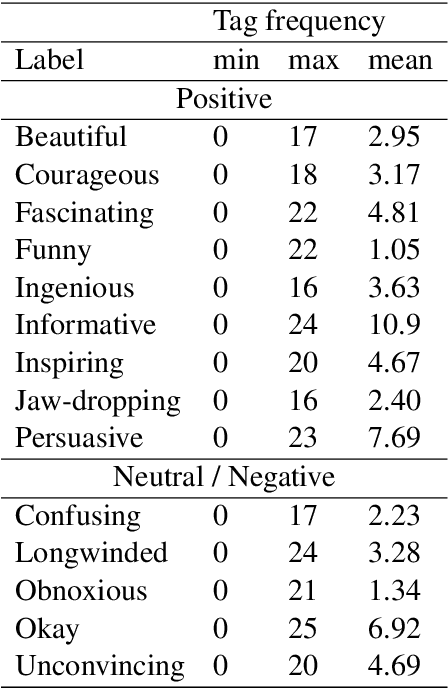
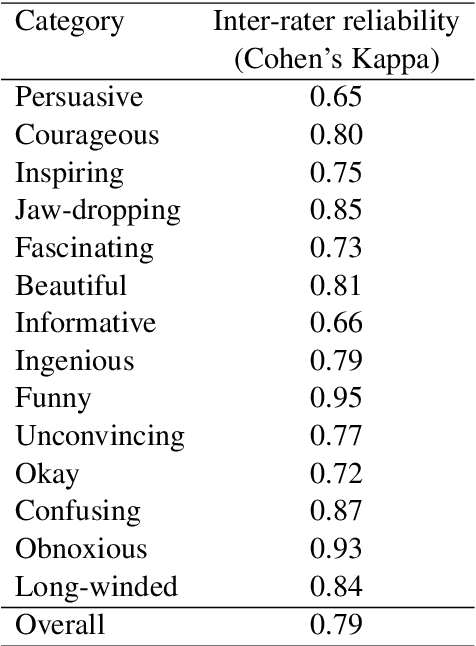

One of the key communicative competencies is the ability to maintain fluency in monologic speech and the ability to produce sophisticated language to argue a position convincingly. In this paper we aim to predict TED talk-style affective ratings in a crowdsourced dataset of argumentative speech consisting of 7 hours of speech from 110 individuals. The speech samples were elicited through task prompts relating to three debating topics. The samples received a total of 2211 ratings from 737 human raters pertaining to 14 affective categories. We present an effective approach to the classification task of predicting these categories through fine-tuning a model pre-trained on a large dataset of TED talks public speeches. We use a combination of fluency features derived from a state-of-the-art automatic speech recognition system and a large set of human-interpretable linguistic features obtained from an automatic text analysis system. Classification accuracy was greater than 60% for all 14 rating categories, with a peak performance of 72% for the rating category 'informative'. In a secondary experiment, we determined the relative importance of features from different groups using SP-LIME.
FSER: Deep Convolutional Neural Networks for Speech Emotion Recognition
Sep 15, 2021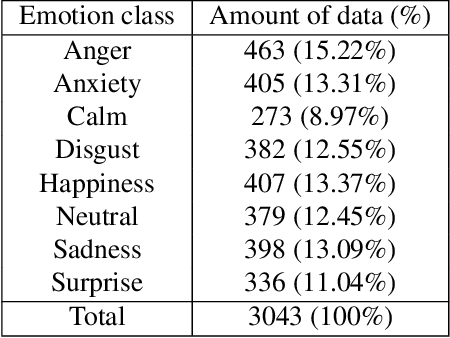
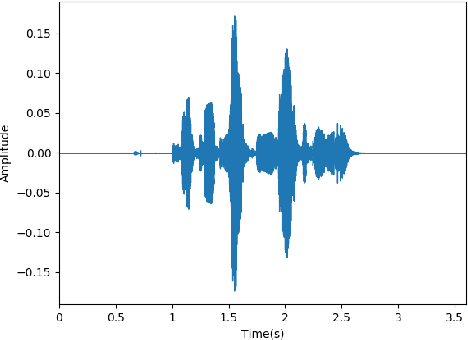
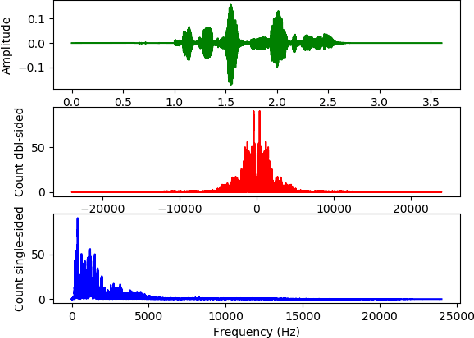
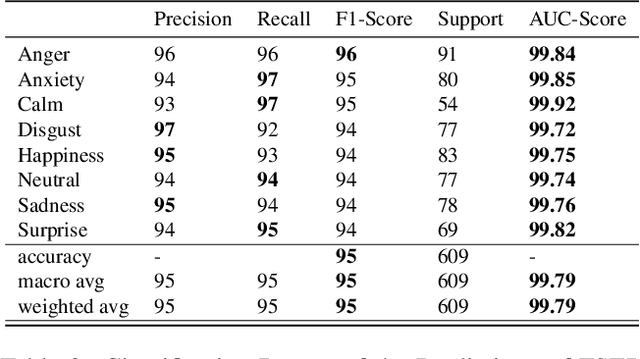
Using mel-spectrograms over conventional MFCCs features, we assess the abilities of convolutional neural networks to accurately recognize and classify emotions from speech data. We introduce FSER, a speech emotion recognition model trained on four valid speech databases, achieving a high-classification accuracy of 95,05\%, over 8 different emotion classes: anger, anxiety, calm, disgust, happiness, neutral, sadness, surprise. On each benchmark dataset, FSER outperforms the best models introduced so far, achieving a state-of-the-art performance. We show that FSER stays reliable, independently of the language, sex identity, and any other external factor. Additionally, we describe how FSER could potentially be used to improve mental and emotional health care and how our analysis and findings serve as guidelines and benchmarks for further works in the same direction.
SEOFP-NET: Compression and Acceleration of Deep Neural Networks for Speech Enhancement Using Sign-Exponent-Only Floating-Points
Nov 08, 2021
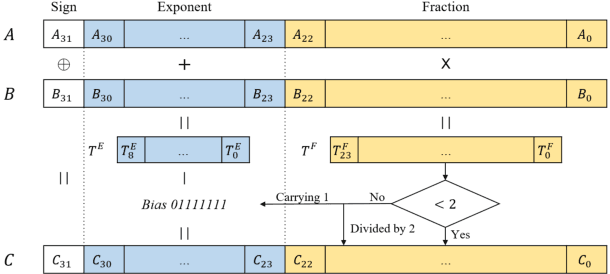
Numerous compression and acceleration strategies have achieved outstanding results on classification tasks in various fields, such as computer vision and speech signal processing. Nevertheless, the same strategies have yielded ungratified performance on regression tasks because the nature between these and classification tasks differs. In this paper, a novel sign-exponent-only floating-point network (SEOFP-NET) technique is proposed to compress the model size and accelerate the inference time for speech enhancement, a regression task of speech signal processing. The proposed method compressed the sizes of deep neural network (DNN)-based speech enhancement models by quantizing the fraction bits of single-precision floating-point parameters during training. Before inference implementation, all parameters in the trained SEOFP-NET model are slightly adjusted to accelerate the inference time by replacing the floating-point multiplier with an integer-adder. For generalization, the SEOFP-NET technique is introduced to different speech enhancement tasks in speech signal processing with different model architectures under various corpora. The experimental results indicate that the size of SEOFP-NET models can be significantly compressed by up to 81.249% without noticeably downgrading their speech enhancement performance, and the inference time can be accelerated to 1.212x compared with the baseline models. The results also verify that the proposed SEOFP-NET can cooperate with other efficiency strategies to achieve a synergy effect for model compression. In addition, the just noticeable difference (JND) was applied to the user study experiment to statistically analyze the effect of speech enhancement on listening. The results indicate that the listeners cannot facilely differentiate between the enhanced speech signals processed by the baseline model and the proposed SEOFP-NET.