 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speaker conditioning of acoustic models using affine transformation for multi-speaker speech recognition
Oct 30, 2021
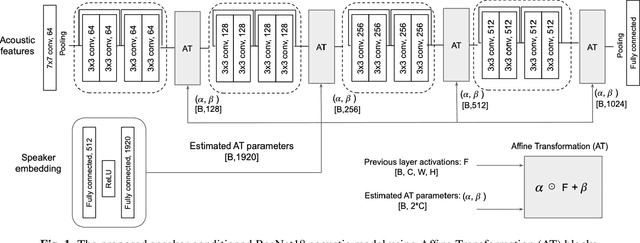
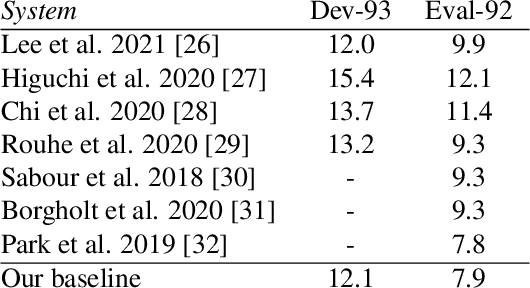
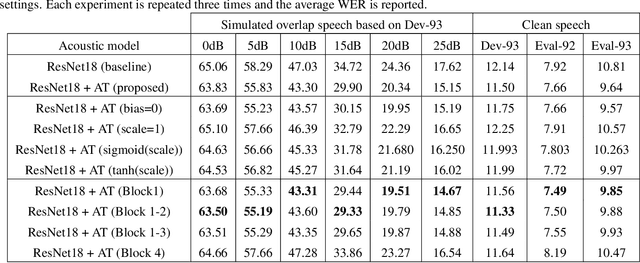
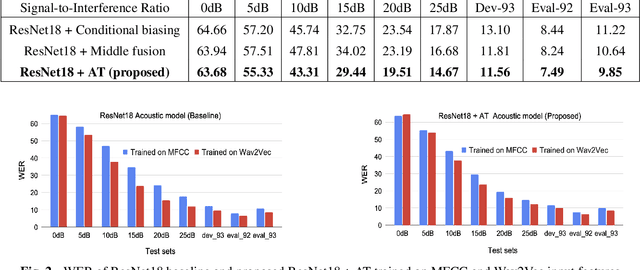
This study addresses the problem of single-channel Automatic Speech Recognition of a target speaker within an overlap speech scenario. In the proposed method, the hidden representations in the acoustic model are modulated by speaker auxiliary information to recognize only the desired speaker. Affine transformation layers are inserted into the acoustic model network to integrate speaker information with the acoustic features. The speaker conditioning process allows the acoustic model to perform computation in the context of target-speaker auxiliary information. The proposed speaker conditioning method is a general approach and can be applied to any acoustic model architecture. Here, we employ speaker conditioning on a ResNet acoustic model. Experiments on the WSJ corpus show that the proposed speaker conditioning method is an effective solution to fuse speaker auxiliary information with acoustic features for multi-speaker speech recognition, achieving +9% and +20% relative WER reduction for clean and overlap speech scenarios, respectively, compared to the original ResNet acoustic model baseline.
Brazilian Portuguese Speech Recognition Using Wav2vec 2.0
Jul 23, 2021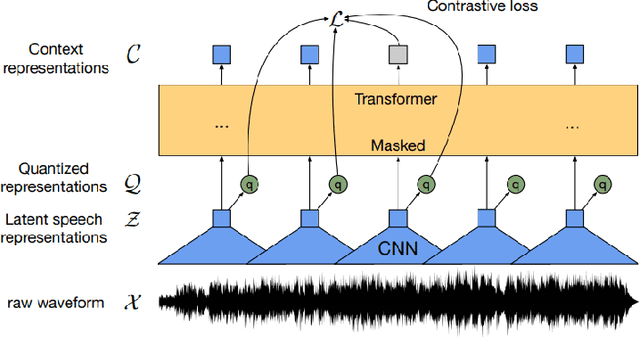

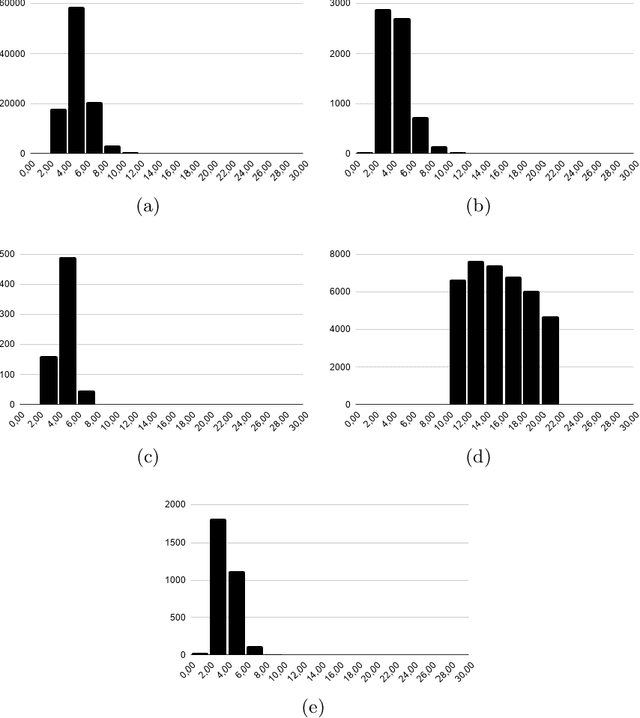
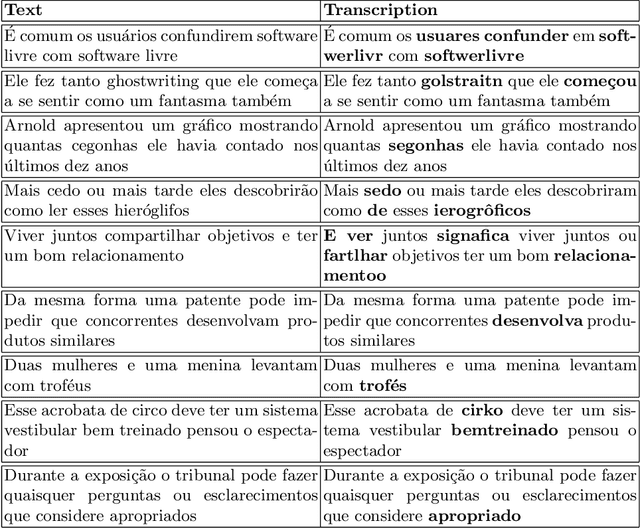
Deep learning techniques have been shown to be efficient in various tasks, especially in the development of speech recognition systems, that is, systems that aim to transcribe a sentence in audio in a sequence of words. Despite the progress in the area, speech recognition can still be considered difficult, especially for languages lacking available data, as Brazilian Portuguese. In this sense, this work presents the development of an public Automatic Speech Recognition system using only open available audio data, from the fine-tuning of the Wav2vec 2.0 XLSR-53 model pre-trained in many languages over Brazilian Portuguese data. The final model presents a Word Error Rate of 11.95% (Common Voice Dataset). This corresponds to 13% less than the best open Automatic Speech Recognition model for Brazilian Portuguese available according to our best knowledge, which is a promising result for the language. In general, this work validates the use of self-supervising learning techniques, in special, the use of the Wav2vec 2.0 architecture in the development of robust systems, even for languages having few available data.
Homophone Reveals the Truth: A Reality Check for Speech2Vec
Sep 23, 2022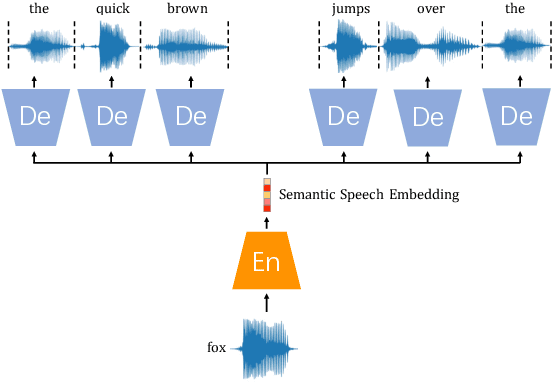

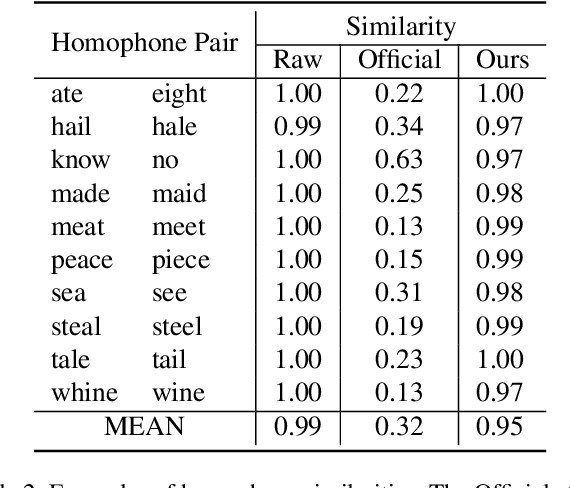
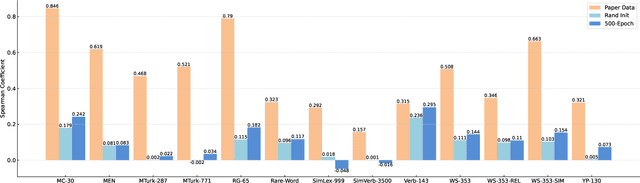
Generating spoken word embeddings that possess semantic information is a fascinating topic. Compared with text-based embeddings, they cover both phonetic and semantic characteristics, which can provide richer information and are potentially helpful for improving ASR and speech translation systems. In this paper, we review and examine the authenticity of a seminal work in this field: Speech2Vec. First, a homophone-based inspection method is proposed to check the speech embeddings released by the author of Speech2Vec. There is no indication that these embeddings are generated by the Speech2Vec model. Moreover, through further analysis of the vocabulary composition, we suspect that a text-based model fabricates these embeddings. Finally, we reproduce the Speech2Vec model, referring to the official code and optimal settings in the original paper. Experiments showed that this model failed to learn effective semantic embeddings. In word similarity benchmarks, it gets a correlation score of 0.08 in MEN and 0.15 in WS-353-SIM tests, which is over 0.5 lower than those described in the original paper. Our data and code are available.
Leveraging Low-Distortion Target Estimates for Improved Speech Enhancement
Oct 01, 2021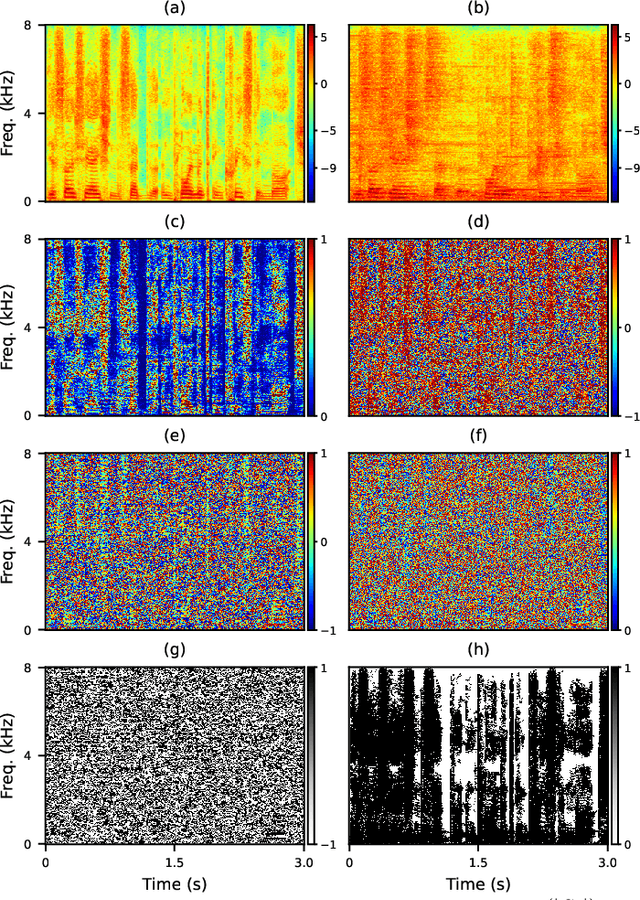
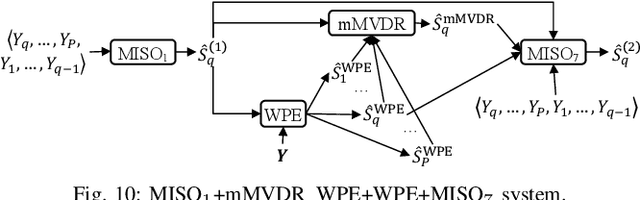
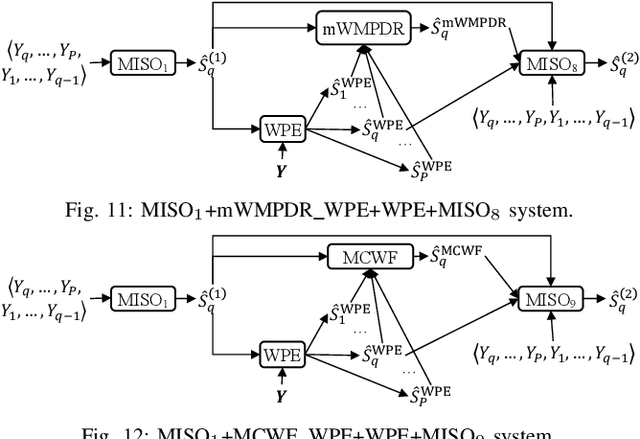
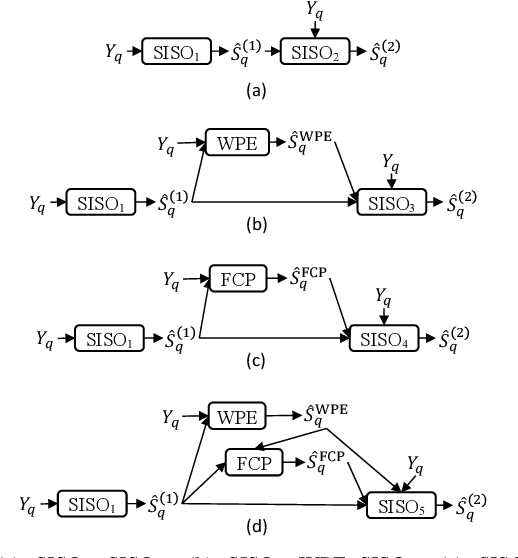
A promising approach for multi-microphone speech separation involves two deep neural networks (DNN), where the predicted target speech from the first DNN is used to compute signal statistics for time-invariant minimum variance distortionless response (MVDR) beamforming, and the MVDR result is then used as extra features for the second DNN to predict target speech. Previous studies suggested that the MVDR result can provide complementary information for the second DNN to better predict target speech. However, on fixed-geometry arrays, both DNNs can take in, for example, the real and imaginary (RI) components of the multi-channel mixture as features to leverage the spatial and spectral information for enhancement. It is not explained clearly why the linear MVDR result can be complementary and why it is still needed, considering that the DNNs and the beamformer use the same input, and the DNNs perform non-linear filtering and could render the linear filtering of MVDR unnecessary. Similarly, in monaural cases, one can replace the MVDR beamformer with a monaural weighted prediction error (WPE) filter. Although the linear WPE filter and the DNNs use the same mixture RI components as input, the WPE result is found to significantly improve the second DNN. This study provides a novel explanation from the perspective of the low-distortion nature of such algorithms, and finds that they can consistently improve phase estimation. Equipped with this understanding, we investigate several low-distortion target estimation algorithms including several beamformers, WPE, forward convolutive prediction, and their combinations, and use their results as extra features to train the second network to achieve better enhancement. Evaluation results on single- and multi-microphone speech dereverberation and enhancement tasks indicate the effectiveness of the proposed approach, and the validity of the proposed view.
Controllable cross-speaker emotion transfer for end-to-end speech synthesis
Sep 14, 2021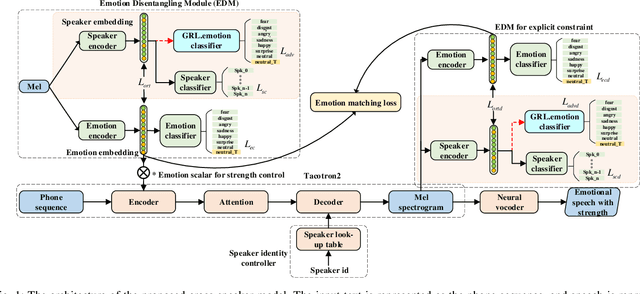
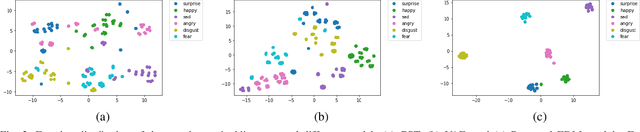
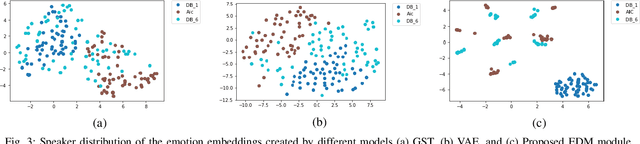
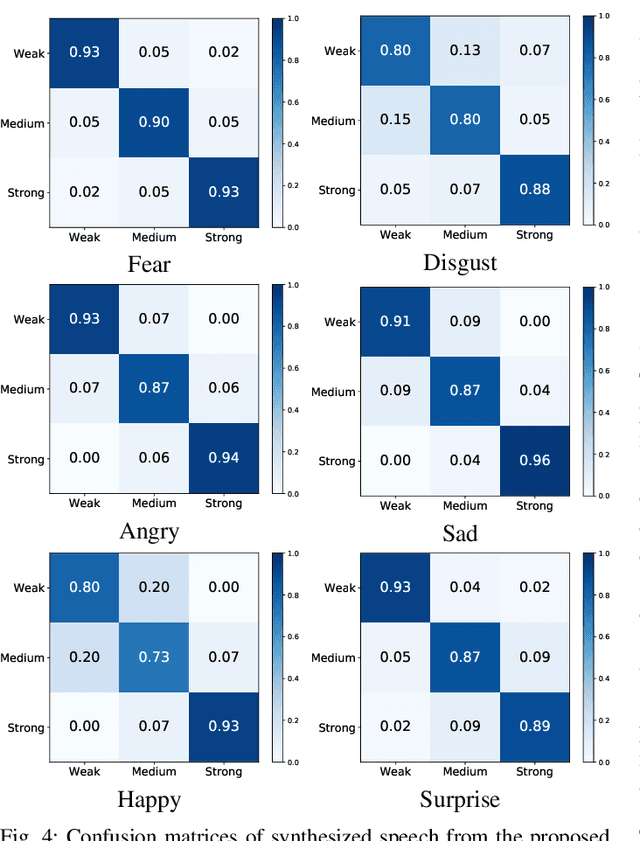
The cross-speaker emotion transfer task in TTS particularly aims to synthesize speech for a target speaker with the emotion transferred from reference speech recorded by another (source) speaker. During the emotion transfer process, the identity information of the source speaker could also affect the synthesized results, resulting in the issue of speaker leakage. This paper proposes a new method with the aim to synthesize controllable emotional expressive speech and meanwhile maintain the target speaker's identity in the cross-speaker emotion TTS task. The proposed method is a Tacotron2-based framework with the emotion embedding as the conditioning variable to provide emotion information. Two emotion disentangling modules are contained in our method to 1) get speaker-independent and emotion-discriminative embedding, and 2) explicitly constrain the emotion and speaker identity of synthetic speech to be that as expected. Moreover, we present an intuitive method to control the emotional strength in the synthetic speech for the target speaker. Specifically, the learned emotion embedding is adjusted with a flexible scalar value, which allows controlling the emotion strength conveyed by the embedding. Extensive experiments have been conducted on a Mandarin disjoint corpus, and the results demonstrate that the proposed method is able to synthesize reasonable emotional speech for the target speaker. Compared to the state-of-the-art reference embedding learned methods, our method gets the best performance on the cross-speaker emotion transfer task, indicating that our method achieves the new state-of-the-art performance on learning the speaker-independent emotion embedding. Furthermore, the strength ranking test and pitch trajectories plots demonstrate that the proposed method can effectively control the emotion strength, leading to prosody-diverse synthetic speech.
THUEE system description for NIST 2020 SRE CTS challenge
Oct 12, 2022
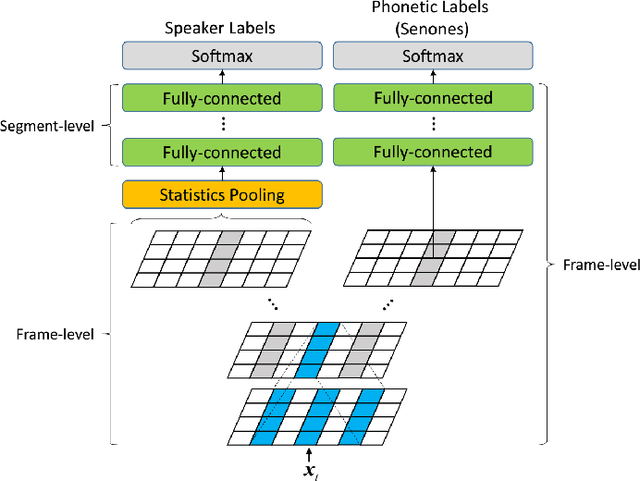
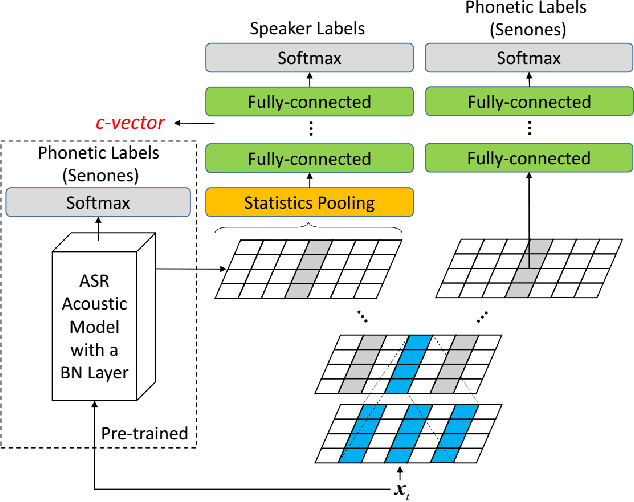

This paper presents the system description of the THUEE team for the NIST 2020 Speaker Recognition Evaluation (SRE) conversational telephone speech (CTS) challenge. The subsystems including ResNet74, ResNet152, and RepVGG-B2 are developed as speaker embedding extractors in this evaluation. We used combined AM-Softmax and AAM-Softmax based loss functions, namely CM-Softmax. We adopted a two-staged training strategy to further improve system performance. We fused all individual systems as our final submission. Our approach leads to excellent performance and ranks 1st in the challenge.
FDLP-Spectrogram: Capturing Speech Dynamics in Spectrograms for End-to-end Automatic Speech Recognition
Mar 25, 2021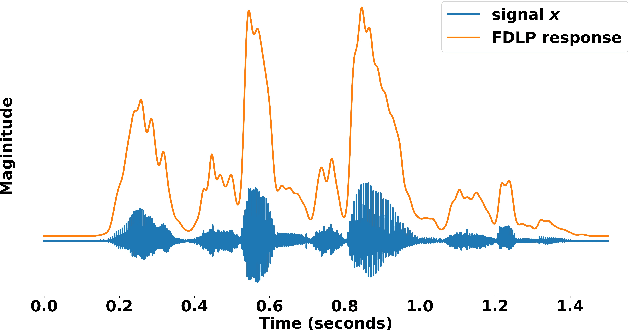

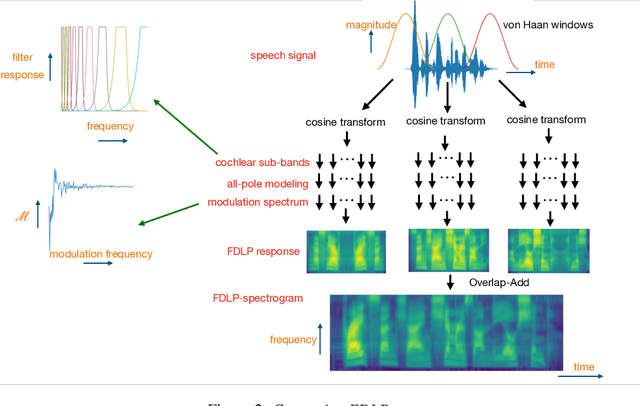

We propose a technique to compute spectrograms using Frequency Domain Linear Prediction (FDLP) that uses all-pole models to fit the Hilbert envelope of speech in different frequency sub-bands. The spectrogram of a complete speech utterance is computed by overlap-add of contiguous all-pole model responses. The long context window of 1.5 seconds allows us to capture the low frequency temporal modulations of speech in the spectrogram. For an end-to-end automatic speech recognition task, the FDLP-spectrogram performs at-par with the standard mel-spectrogram features for clean read speech training and test data. For more realistic mismatched train-test situations and noisy, reverberated training data, the FDLP-spectrogram shows up to 25% and 22% WER improvements over mel-spectrogram respectively.
S-DCCRN: Super Wide Band DCCRN with learnable complex feature for speech enhancement
Nov 16, 2021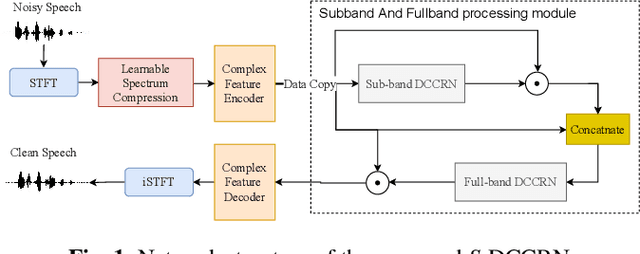
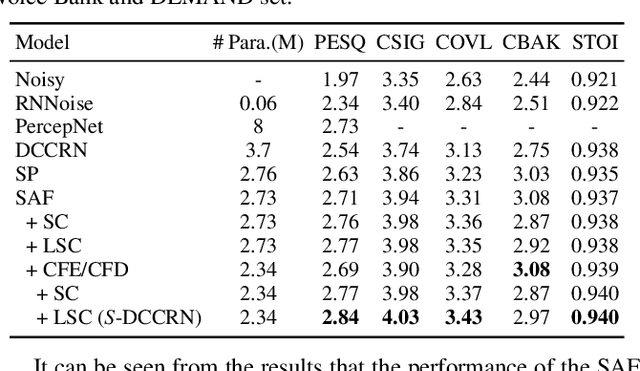
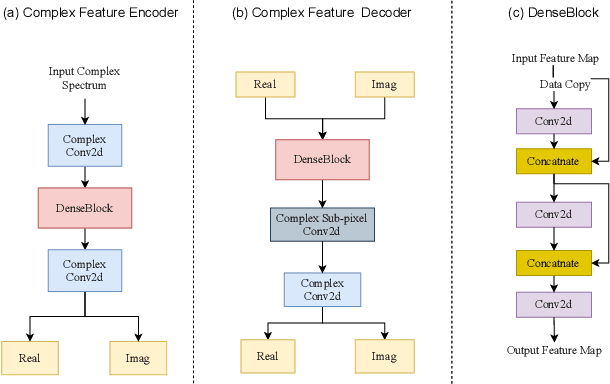
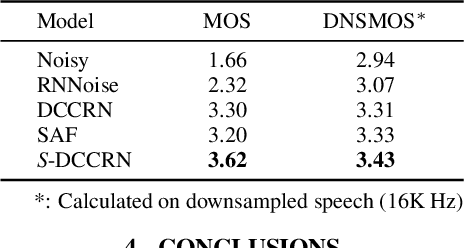
In speech enhancement, complex neural network has shown promising performance due to their effectiveness in processing complex-valued spectrum. Most of the recent speech enhancement approaches mainly focus on wide-band signal with a sampling rate of 16K Hz. However, research on super wide band (e.g., 32K Hz) or even full-band (48K) denoising is still lacked due to the difficulty of modeling more frequency bands and particularly high frequency components. In this paper, we extend our previous deep complex convolution recurrent neural network (DCCRN) substantially to a super wide band version -- S-DCCRN, to perform speech denoising on speech of 32K Hz sampling rate. We first employ a cascaded sub-band and full-band processing module, which consists of two small-footprint DCCRNs -- one operates on sub-band signal and one operates on full-band signal, aiming at benefiting from both local and global frequency information. Moreover, instead of simply adopting the STFT feature as input, we use a complex feature encoder trained in an end-to-end manner to refine the information of different frequency bands. We also use a complex feature decoder to revert the feature to time-frequency domain. Finally, a learnable spectrum compression method is adopted to adjust the energy of different frequency bands, which is beneficial for neural network learning. The proposed model, S-DCCRN, has surpassed PercepNet as well as several competitive models and achieves state-of-the-art performance in terms of speech quality and intelligibility. Ablation studies also demonstrate the effectiveness of different contributions.
A Multi-Stage Multi-Codebook VQ-VAE Approach to High-Performance Neural TTS
Sep 22, 2022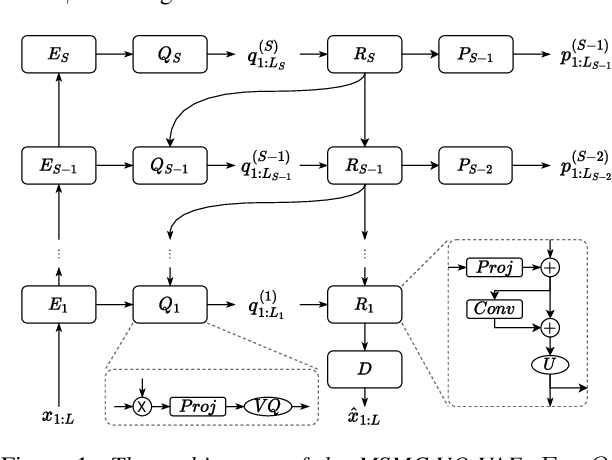
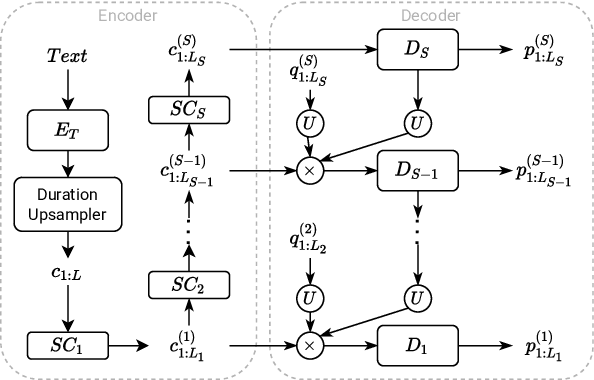
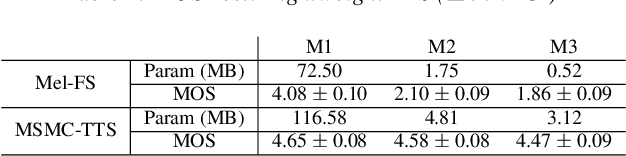
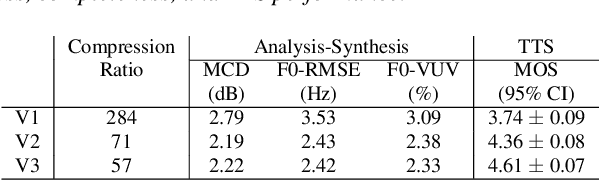
We propose a Multi-Stage, Multi-Codebook (MSMC) approach to high-performance neural TTS synthesis. A vector-quantized, variational autoencoder (VQ-VAE) based feature analyzer is used to encode Mel spectrograms of speech training data by down-sampling progressively in multiple stages into MSMC Representations (MSMCRs) with different time resolutions, and quantizing them with multiple VQ codebooks, respectively. Multi-stage predictors are trained to map the input text sequence to MSMCRs progressively by minimizing a combined loss of the reconstruction Mean Square Error (MSE) and "triplet loss". In synthesis, the neural vocoder converts the predicted MSMCRs into final speech waveforms. The proposed approach is trained and tested with an English TTS database of 16 hours by a female speaker. The proposed TTS achieves an MOS score of 4.41, which outperforms the baseline with an MOS of 3.62. Compact versions of the proposed TTS with much less parameters can still preserve high MOS scores. Ablation studies show that both multiple stages and multiple codebooks are effective for achieving high TTS performance.
Avocodo: Generative Adversarial Network for Artifact-free Vocoder
Jun 28, 2022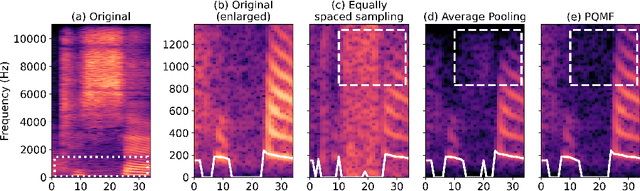
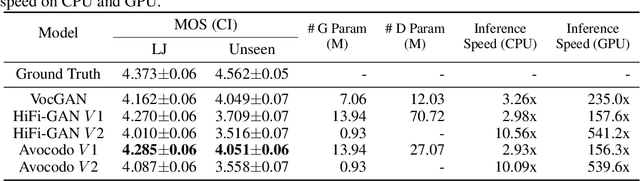
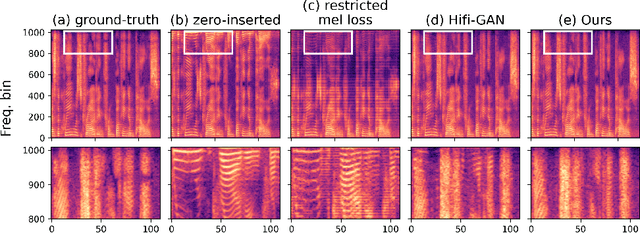
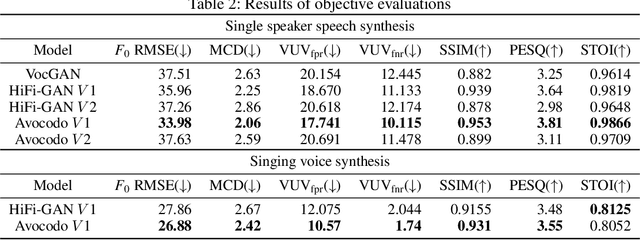
Neural vocoders based on the generative adversarial neural network (GAN) have been widely used due to their fast inference speed and lightweight networks while generating high-quality speech waveforms. Since the perceptually important speech components are primarily concentrated in the low-frequency band, most of the GAN-based neural vocoders perform multi-scale analysis that evaluates downsampled speech waveforms. This multi-scale analysis helps the generator improve speech intelligibility. However, in preliminary experiments, we observed that the multi-scale analysis which focuses on the low-frequency band causes unintended artifacts, e.g., aliasing and imaging artifacts, and these artifacts degrade the synthesized speech waveform quality. Therefore, in this paper, we investigate the relationship between these artifacts and GAN-based neural vocoders and propose a GAN-based neural vocoder, called Avocodo, that allows the synthesis of high-fidelity speech with reduced artifacts. We introduce two kinds of discriminators to evaluate waveforms in various perspectives: a collaborative multi-band discriminator and a sub-band discriminator. We also utilize a pseudo quadrature mirror filter bank to obtain downsampled multi-band waveforms while avoiding aliasing. The experimental results show that Avocodo outperforms conventional GAN-based neural vocoders in both speech and singing voice synthesis tasks and can synthesize artifact-free speech. Especially, Avocodo is even capable to reproduce high-quality waveforms of unseen speakers.