 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SpeechNet: A Universal Modularized Model for Speech Processing Tasks
May 31, 2021
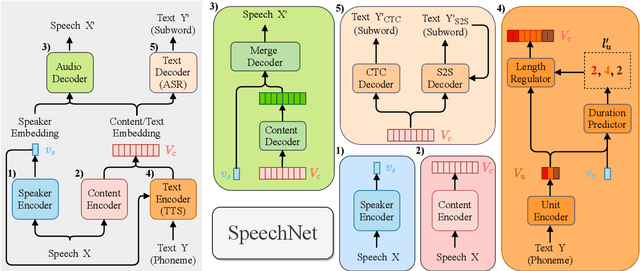
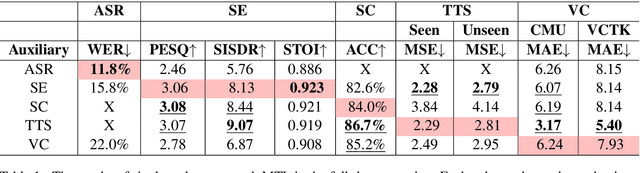
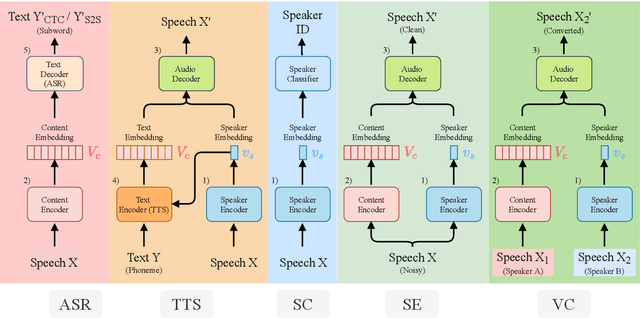
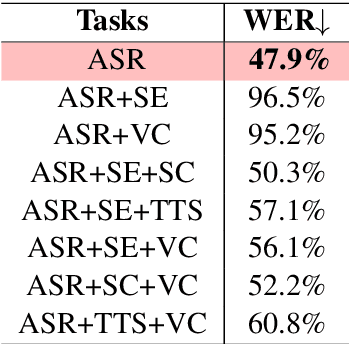
There is a wide variety of speech processing tasks ranging from extracting content information from speech signals to generating speech signals. For different tasks, model networks are usually designed and tuned separately. If a universal model can perform multiple speech processing tasks, some tasks might be improved with the related abilities learned from other tasks. The multi-task learning of a wide variety of speech processing tasks with a universal model has not been studied. This paper proposes a universal modularized model, SpeechNet, which treats all speech processing tasks into a speech/text input and speech/text output format. We select five essential speech processing tasks for multi-task learning experiments with SpeechNet. We show that SpeechNet learns all of the above tasks, and we further analyze which tasks can be improved by other tasks. SpeechNet is modularized and flexible for incorporating more modules, tasks, or training approaches in the future. We release the code and experimental settings to facilitate the research of modularized universal models and multi-task learning of speech processing tasks.
Contrastive Regularization for Multimodal Emotion Recognition Using Audio and Text
Nov 20, 2022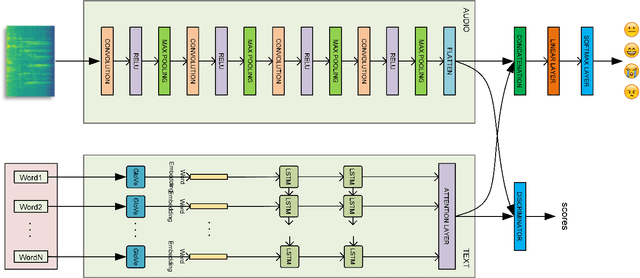

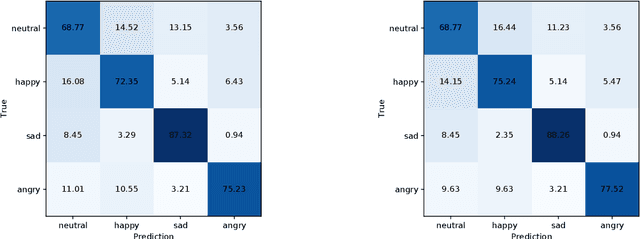
Speech emotion recognition is a challenge and an important step towards more natural human-computer interaction (HCI). The popular approach is multimodal emotion recognition based on model-level fusion, which means that the multimodal signals can be encoded to acquire embeddings, and then the embeddings are concatenated together for the final classification. However, due to the influence of noise or other factors, each modality does not always tend to the same emotional category, which affects the generalization of a model. In this paper, we propose a novel regularization method via contrastive learning for multimodal emotion recognition using audio and text. By introducing a discriminator to distinguish the difference between the same and different emotional pairs, we explicitly restrict the latent code of each modality to contain the same emotional information, so as to reduce the noise interference and get more discriminative representation. Experiments are performed on the standard IEMOCAP dataset for 4-class emotion recognition. The results show a significant improvement of 1.44\% and 1.53\% in terms of weighted accuracy (WA) and unweighted accuracy (UA) compared to the baseline system.
Robust Speech Representation Learning via Flow-based Embedding Regularization
Dec 07, 2021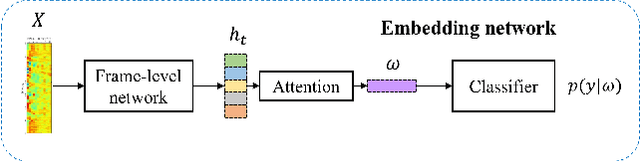

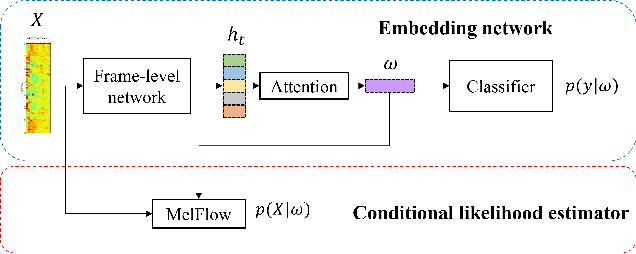
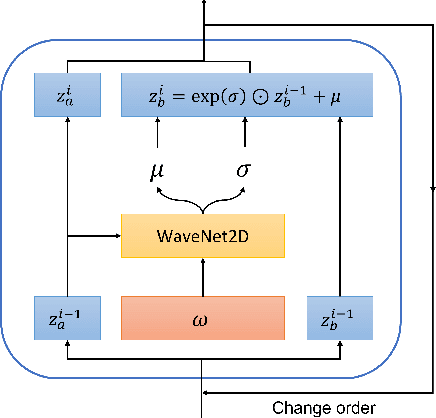
Over the recent years, various deep learning-based methods were proposed for extracting a fixed-dimensional embedding vector from speech signals. Although the deep learning-based embedding extraction methods have shown good performance in numerous tasks including speaker verification, language identification and anti-spoofing, their performance is limited when it comes to mismatched conditions due to the variability within them unrelated to the main task. In order to alleviate this problem, we propose a novel training strategy that regularizes the embedding network to have minimum information about the nuisance attributes. To achieve this, our proposed method directly incorporates the information bottleneck scheme into the training process, where the mutual information is estimated using the main task classifier and an auxiliary normalizing flow network. The proposed method was evaluated on different speech processing tasks and showed improvement over the standard training strategy in all experimentation.
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021
Nov 19, 2021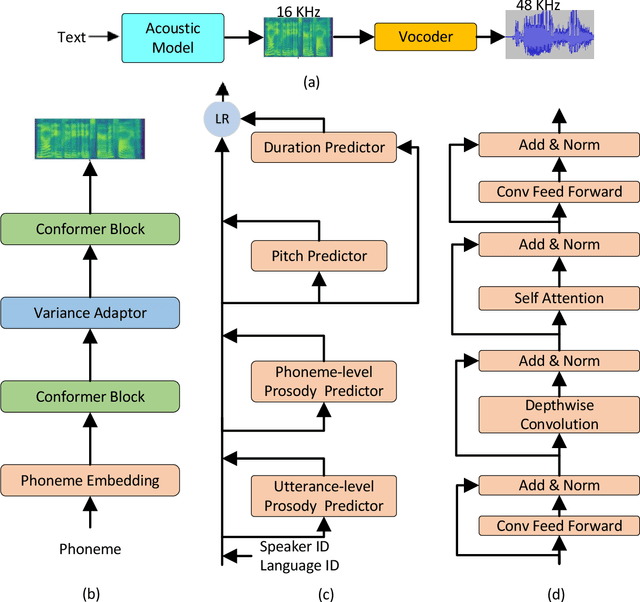
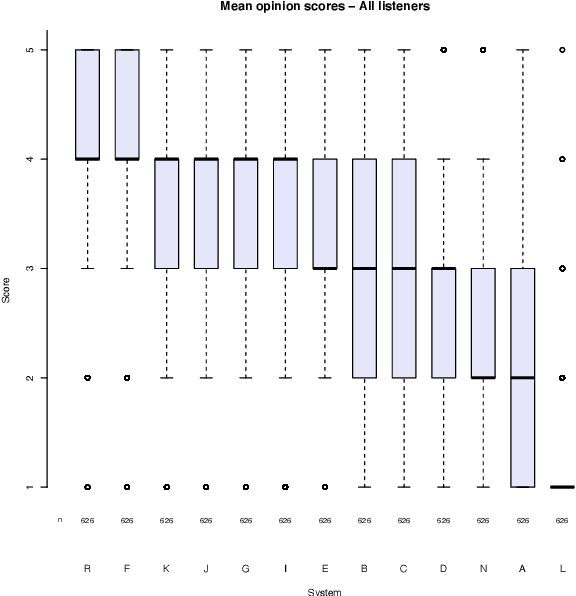
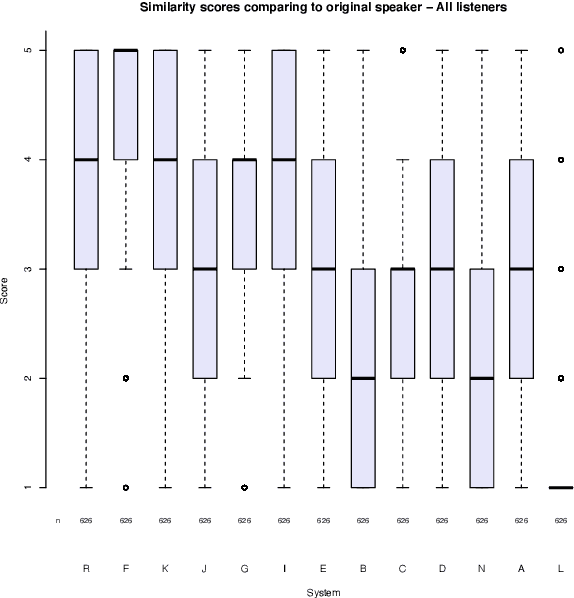
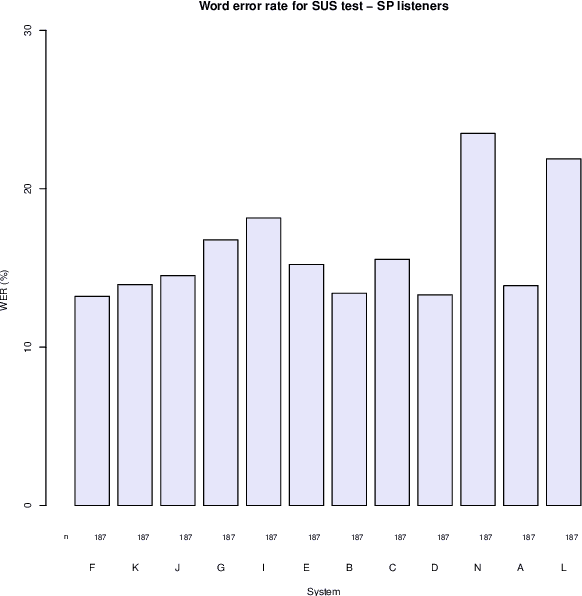
This paper describes the Microsoft end-to-end neural text to speech (TTS) system: DelightfulTTS for Blizzard Challenge 2021. The goal of this challenge is to synthesize natural and high-quality speech from text, and we approach this goal in two perspectives: The first is to directly model and generate waveform in 48 kHz sampling rate, which brings higher perception quality than previous systems with 16 kHz or 24 kHz sampling rate; The second is to model the variation information in speech through a systematic design, which improves the prosody and naturalness. Specifically, for 48 kHz modeling, we predict 16 kHz mel-spectrogram in acoustic model, and propose a vocoder called HiFiNet to directly generate 48 kHz waveform from predicted 16 kHz mel-spectrogram, which can better trade off training efficiency, modelling stability and voice quality. We model variation information systematically from both explicit (speaker ID, language ID, pitch and duration) and implicit (utterance-level and phoneme-level prosody) perspectives: 1) For speaker and language ID, we use lookup embedding in training and inference; 2) For pitch and duration, we extract the values from paired text-speech data in training and use two predictors to predict the values in inference; 3) For utterance-level and phoneme-level prosody, we use two reference encoders to extract the values in training, and use two separate predictors to predict the values in inference. Additionally, we introduce an improved Conformer block to better model the local and global dependency in acoustic model. For task SH1, DelightfulTTS achieves 4.17 mean score in MOS test and 4.35 in SMOS test, which indicates the effectiveness of our proposed system
HiFi++: a Unified Framework for Neural Vocoding, Bandwidth Extension and Speech Enhancement
Mar 24, 2022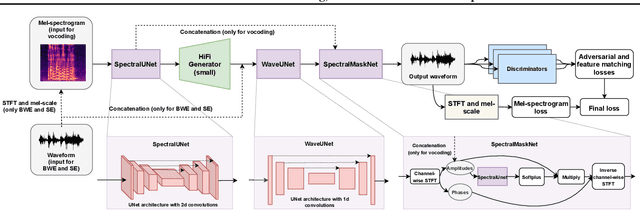
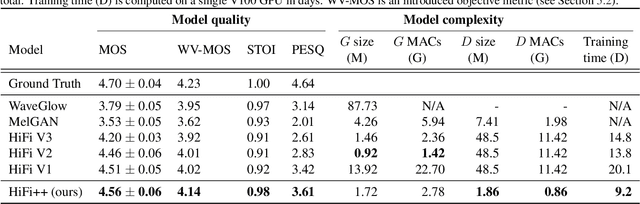
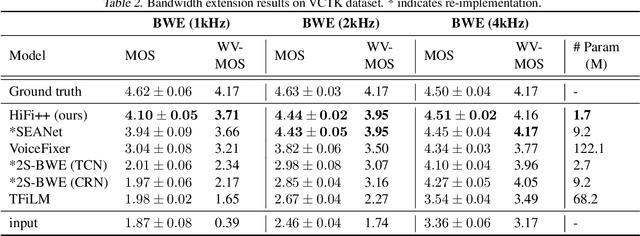
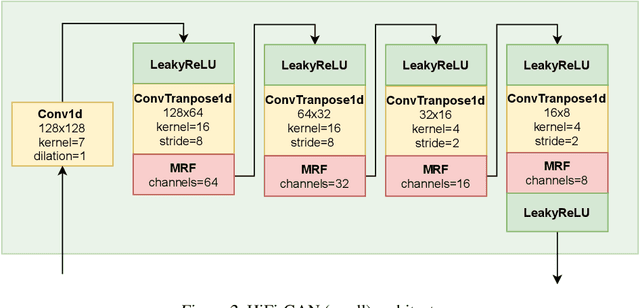
Generative adversarial networks have recently demonstrated outstanding performance in neural vocoding outperforming best autoregressive and flow-based models. In this paper, we show that this success can be extended to other tasks of conditional audio generation. In particular, building upon HiFi vocoders, we propose a novel HiFi++ general framework for neural vocoding, bandwidth extension, and speech enhancement. We show that with the improved generator architecture and simplified multi-discriminator training, HiFi++ performs on par with the state-of-the-art in these tasks while spending significantly less memory and computational resources. The effectiveness of our approach is validated through a series of extensive experiments.
Going In Style: Audio Backdoors Through Stylistic Transformations
Nov 11, 2022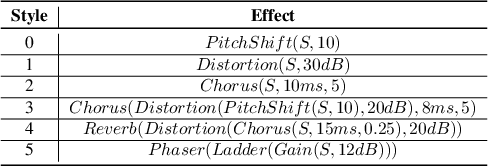
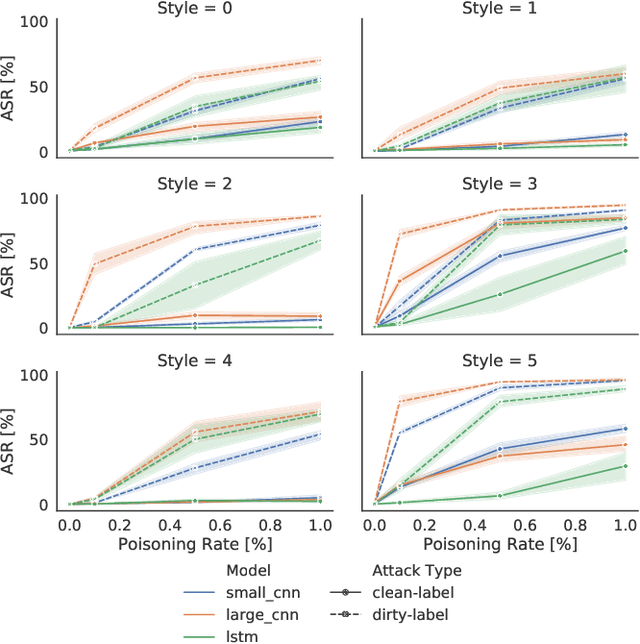
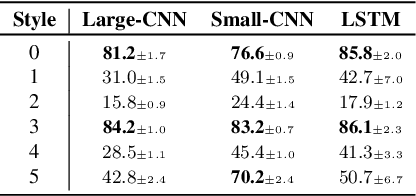
A backdoor attack places triggers in victims' deep learning models to enable a targeted misclassification at testing time. In general, triggers are fixed artifacts attached to samples, making backdoor attacks easy to spot. Only recently, a new trigger generation harder to detect has been proposed: the stylistic triggers that apply stylistic transformations to the input samples (e.g., a specific writing style). Currently, stylistic backdoor literature lacks a proper formalization of the attack, which is established in this paper. Moreover, most studies of stylistic triggers focus on text and images, while there is no understanding of whether they can work in sound. This work fills this gap. We propose JingleBack, the first stylistic backdoor attack based on audio transformations such as chorus and gain. Using 444 models in a speech classification task, we confirm the feasibility of stylistic triggers in audio, achieving 96% attack success.
Speaker Anonymization with Phonetic Intermediate Representations
Jul 11, 2022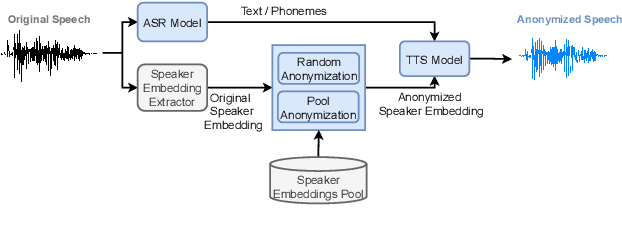
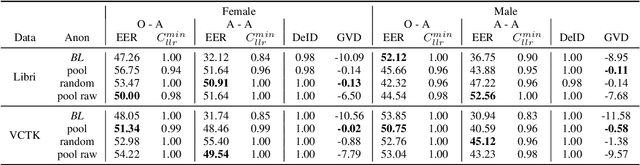
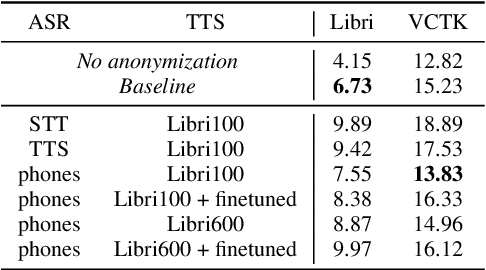

In this work, we propose a speaker anonymization pipeline that leverages high quality automatic speech recognition and synthesis systems to generate speech conditioned on phonetic transcriptions and anonymized speaker embeddings. Using phones as the intermediate representation ensures near complete elimination of speaker identity information from the input while preserving the original phonetic content as much as possible. Our experimental results on LibriSpeech and VCTK corpora reveal two key findings: 1) although automatic speech recognition produces imperfect transcriptions, our neural speech synthesis system can handle such errors, making our system feasible and robust, and 2) combining speaker embeddings from different resources is beneficial and their appropriate normalization is crucial. Overall, our final best system outperforms significantly the baselines provided in the Voice Privacy Challenge 2020 in terms of privacy robustness against a lazy-informed attacker while maintaining high intelligibility and naturalness of the anonymized speech.
Unsupervised Domain Adaptation in Speech Recognition using Phonetic Features
Aug 04, 2021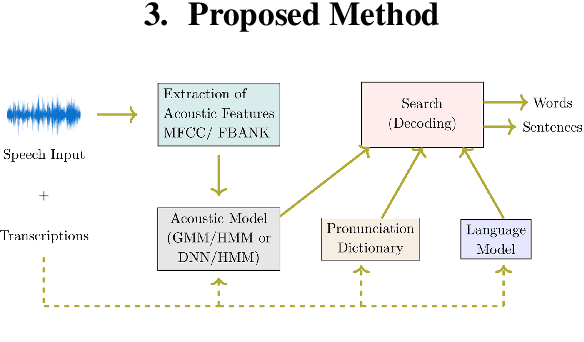
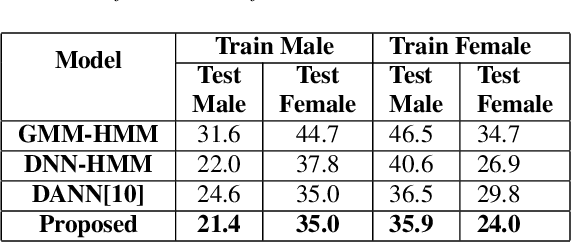
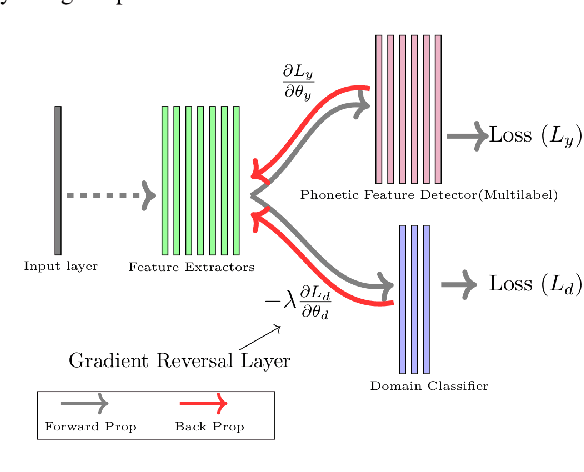
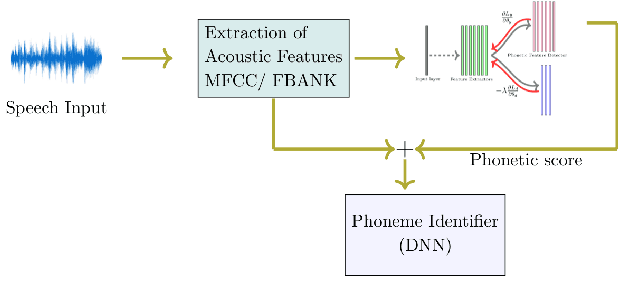
Automatic speech recognition is a difficult problem in pattern recognition because several sources of variability exist in the speech input like the channel variations, the input might be clean or noisy, the speakers may have different accent and variations in the gender, etc. As a result, domain adaptation is important in speech recognition where we train the model for a particular source domain and test it on a different target domain. In this paper, we propose a technique to perform unsupervised gender-based domain adaptation in speech recognition using phonetic features. The experiments are performed on the TIMIT dataset and there is a considerable decrease in the phoneme error rate using the proposed approach.
Hope Speech detection in under-resourced Kannada language
Aug 10, 2021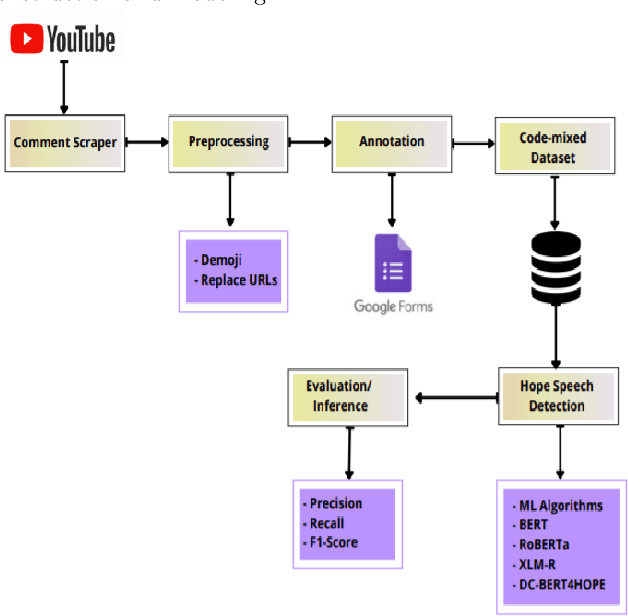
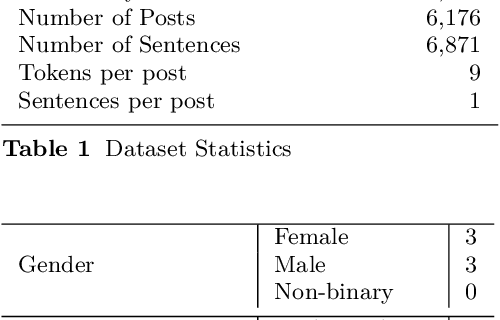
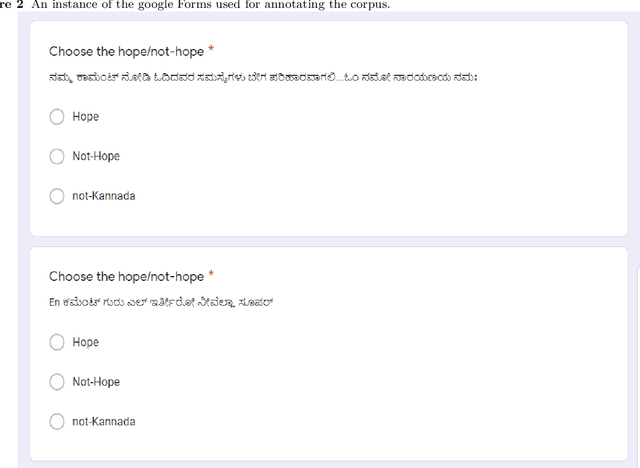
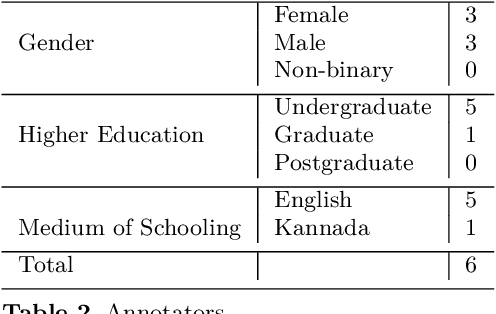
Numerous methods have been developed to monitor the spread of negativity in modern years by eliminating vulgar, offensive, and fierce comments from social media platforms. However, there are relatively lesser amounts of study that converges on embracing positivity, reinforcing supportive and reassuring content in online forums. Consequently, we propose creating an English-Kannada Hope speech dataset, KanHope and comparing several experiments to benchmark the dataset. The dataset consists of 6,176 user-generated comments in code mixed Kannada scraped from YouTube and manually annotated as bearing hope speech or Not-hope speech. In addition, we introduce DC-BERT4HOPE, a dual-channel model that uses the English translation of KanHope for additional training to promote hope speech detection. The approach achieves a weighted F1-score of 0.756, bettering other models. Henceforth, KanHope aims to instigate research in Kannada while broadly promoting researchers to take a pragmatic approach towards online content that encourages, positive, and supportive.
ASMDD: Arabic Speech Mispronunciation Detection Dataset
Nov 01, 2021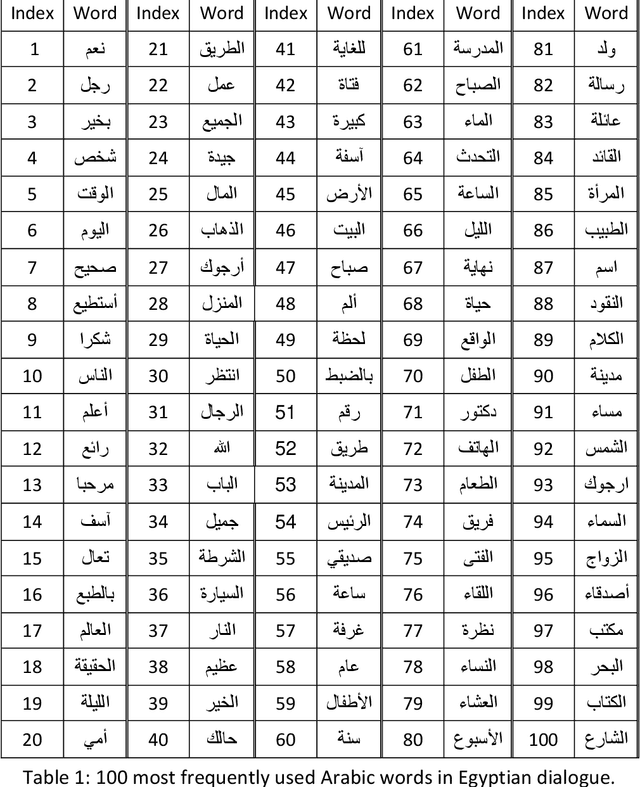
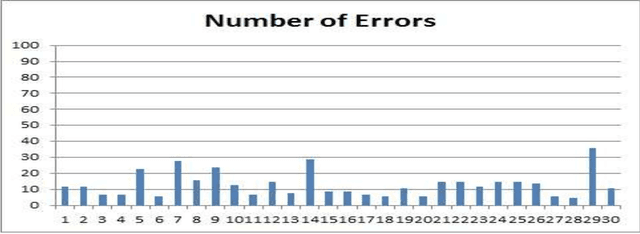
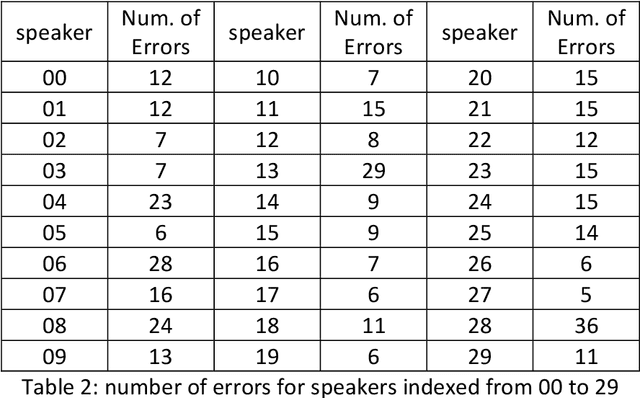
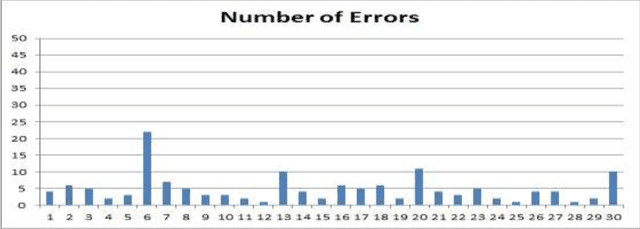
The largest dataset of Arabic speech mispronunciation detections in Egyptian dialogues is introduced. The dataset is composed of annotated audio files representing the top 100 words that are most frequently used in the Arabic language, pronounced by 100 Egyptian children (aged between 2 and 8 years old). The dataset is collected and annotated on segmental pronunciation error detections by expert listeners.