 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Robust Speech Representation Learning via Flow-based Embedding Regularization
Dec 07, 2021
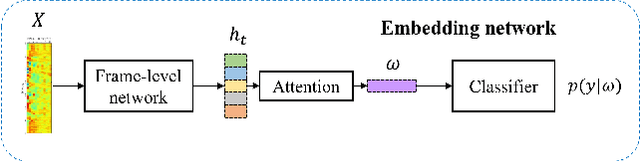

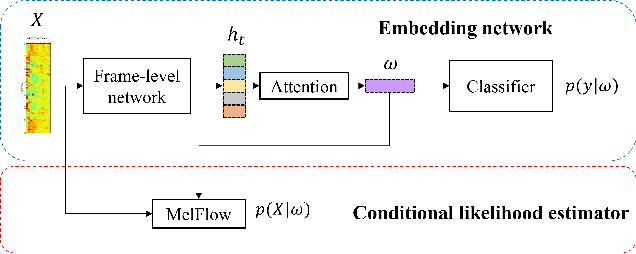
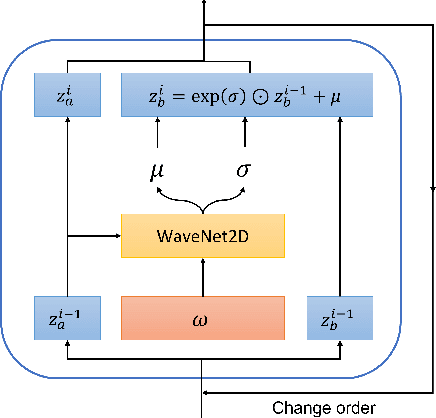
Over the recent years, various deep learning-based methods were proposed for extracting a fixed-dimensional embedding vector from speech signals. Although the deep learning-based embedding extraction methods have shown good performance in numerous tasks including speaker verification, language identification and anti-spoofing, their performance is limited when it comes to mismatched conditions due to the variability within them unrelated to the main task. In order to alleviate this problem, we propose a novel training strategy that regularizes the embedding network to have minimum information about the nuisance attributes. To achieve this, our proposed method directly incorporates the information bottleneck scheme into the training process, where the mutual information is estimated using the main task classifier and an auxiliary normalizing flow network. The proposed method was evaluated on different speech processing tasks and showed improvement over the standard training strategy in all experimentation.
Analysis of Male and Female Speakers' Word Choices in Public Speeches
Nov 11, 2022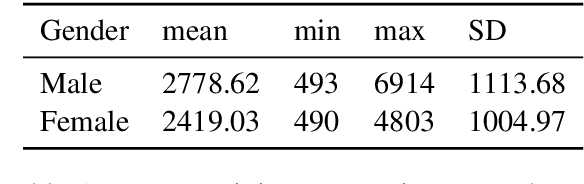
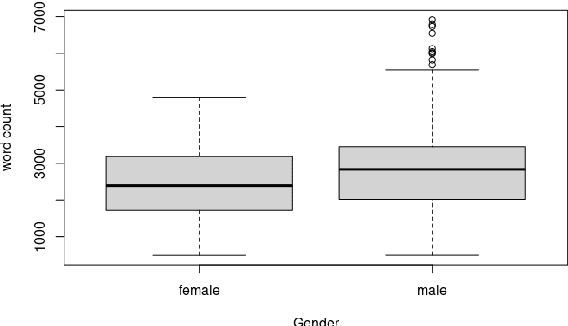
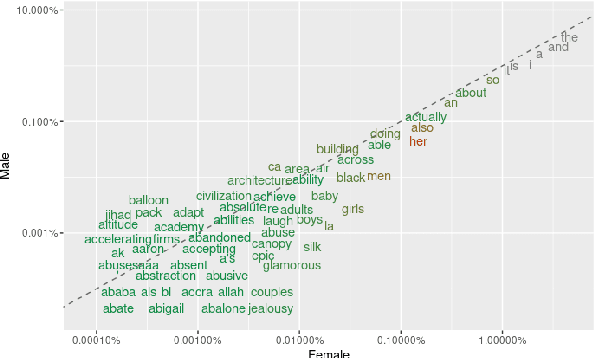
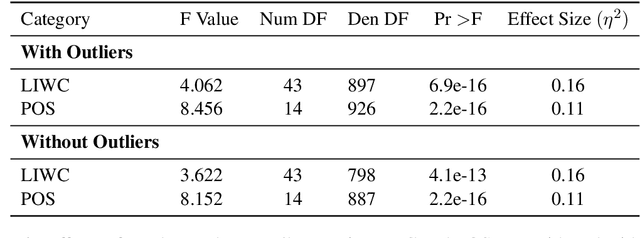
The extent to which men and women use language differently has been questioned previously. Finding clear and consistent gender differences in language is not conclusive in general, and the research is heavily influenced by the context and method employed to identify the difference. In addition, the majority of the research was conducted in written form, and the sample was collected in writing. Therefore, we compared the word choices of male and female presenters in public addresses such as TED lectures. The frequency of numerous types of words, such as parts of speech (POS), linguistic, psychological, and cognitive terms were analyzed statistically to determine how male and female speakers use words differently. Based on our data, we determined that male speakers use specific types of linguistic, psychological, cognitive, and social words in considerably greater frequency than female speakers.
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021
Nov 19, 2021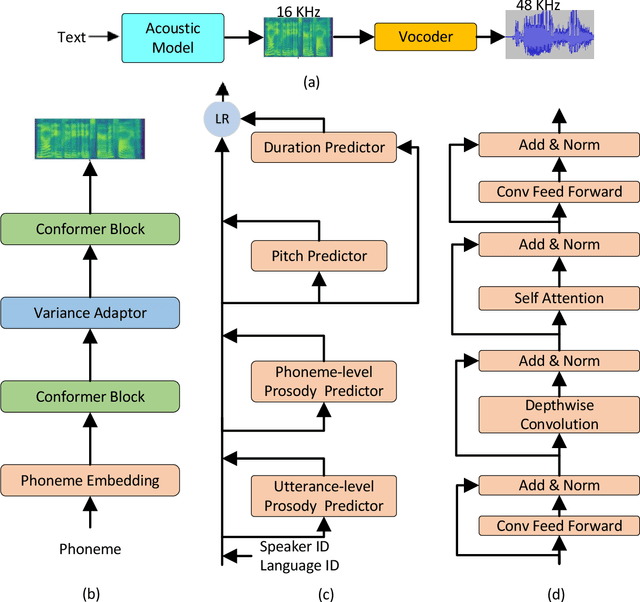
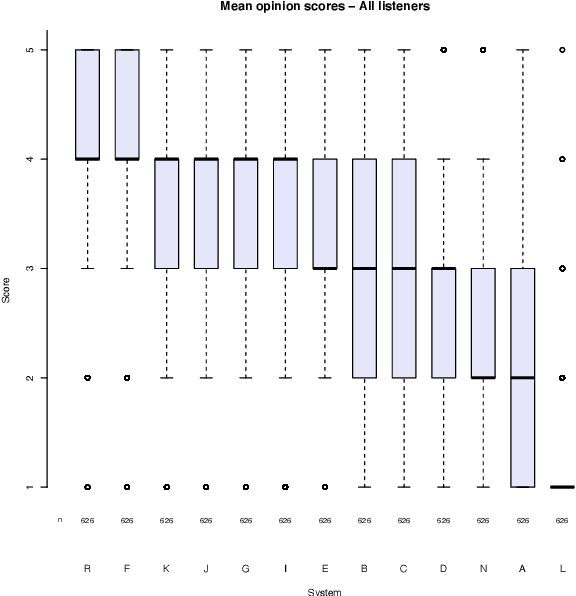
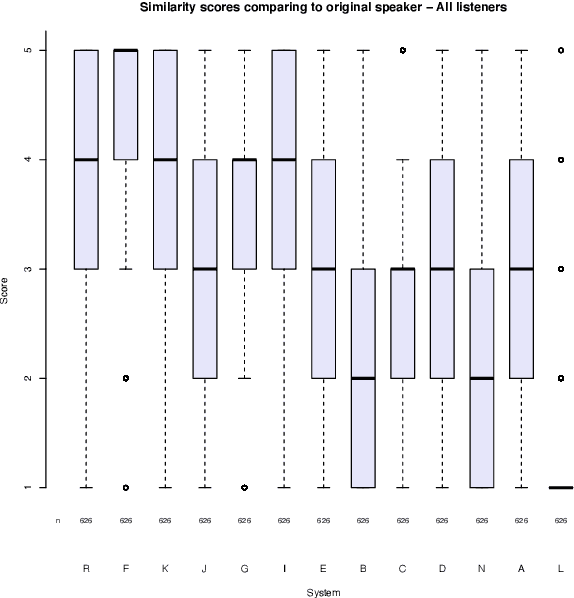
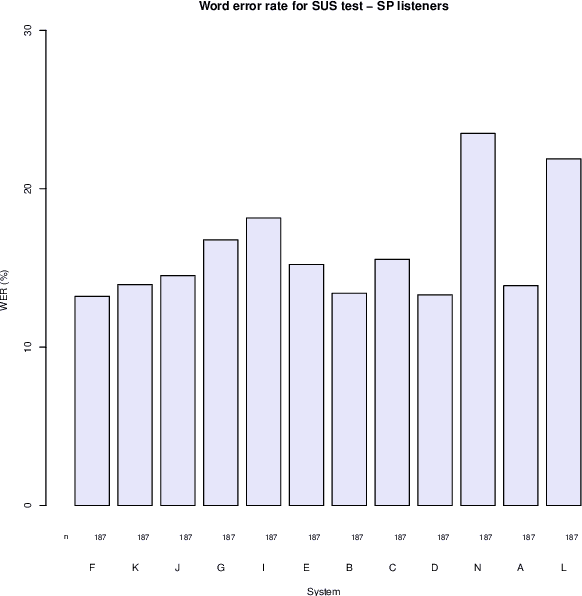
This paper describes the Microsoft end-to-end neural text to speech (TTS) system: DelightfulTTS for Blizzard Challenge 2021. The goal of this challenge is to synthesize natural and high-quality speech from text, and we approach this goal in two perspectives: The first is to directly model and generate waveform in 48 kHz sampling rate, which brings higher perception quality than previous systems with 16 kHz or 24 kHz sampling rate; The second is to model the variation information in speech through a systematic design, which improves the prosody and naturalness. Specifically, for 48 kHz modeling, we predict 16 kHz mel-spectrogram in acoustic model, and propose a vocoder called HiFiNet to directly generate 48 kHz waveform from predicted 16 kHz mel-spectrogram, which can better trade off training efficiency, modelling stability and voice quality. We model variation information systematically from both explicit (speaker ID, language ID, pitch and duration) and implicit (utterance-level and phoneme-level prosody) perspectives: 1) For speaker and language ID, we use lookup embedding in training and inference; 2) For pitch and duration, we extract the values from paired text-speech data in training and use two predictors to predict the values in inference; 3) For utterance-level and phoneme-level prosody, we use two reference encoders to extract the values in training, and use two separate predictors to predict the values in inference. Additionally, we introduce an improved Conformer block to better model the local and global dependency in acoustic model. For task SH1, DelightfulTTS achieves 4.17 mean score in MOS test and 4.35 in SMOS test, which indicates the effectiveness of our proposed system
Unsupervised Domain Adaptation in Speech Recognition using Phonetic Features
Aug 04, 2021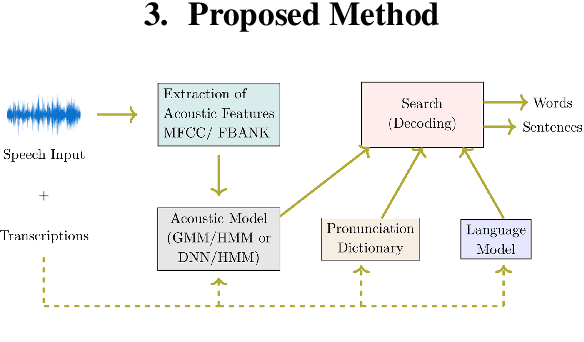
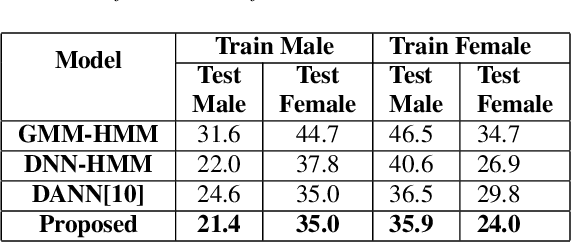
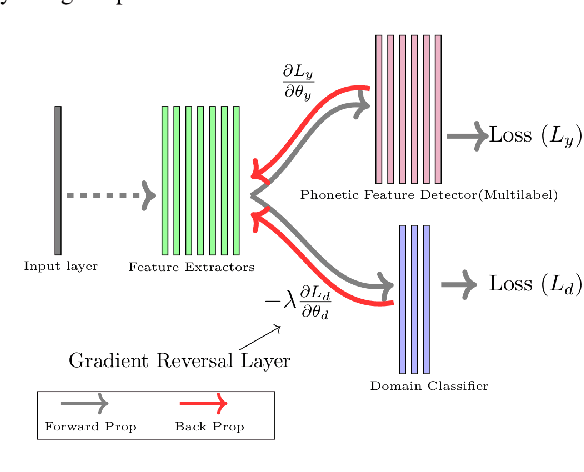
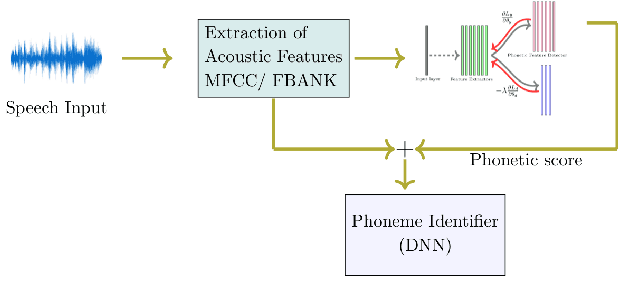
Automatic speech recognition is a difficult problem in pattern recognition because several sources of variability exist in the speech input like the channel variations, the input might be clean or noisy, the speakers may have different accent and variations in the gender, etc. As a result, domain adaptation is important in speech recognition where we train the model for a particular source domain and test it on a different target domain. In this paper, we propose a technique to perform unsupervised gender-based domain adaptation in speech recognition using phonetic features. The experiments are performed on the TIMIT dataset and there is a considerable decrease in the phoneme error rate using the proposed approach.
Audio Anti-spoofing Using a Simple Attention Module and Joint Optimization Based on Additive Angular Margin Loss and Meta-learning
Nov 17, 2022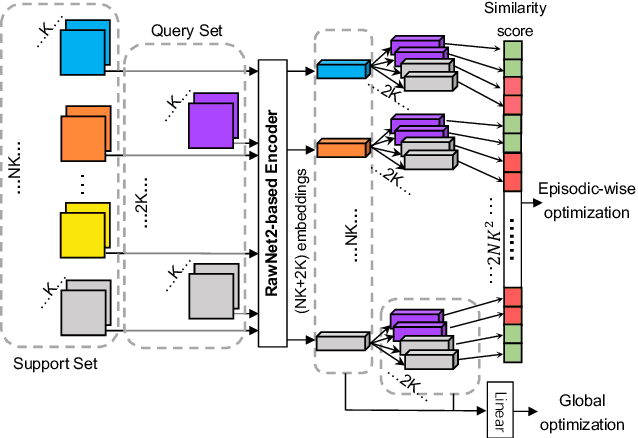
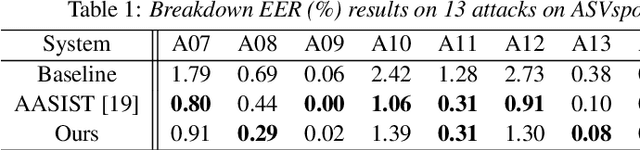
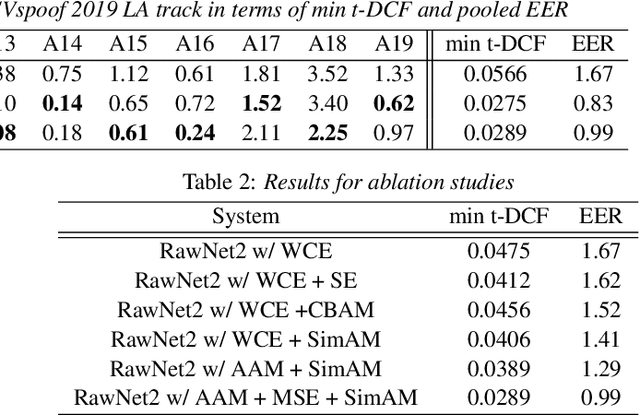
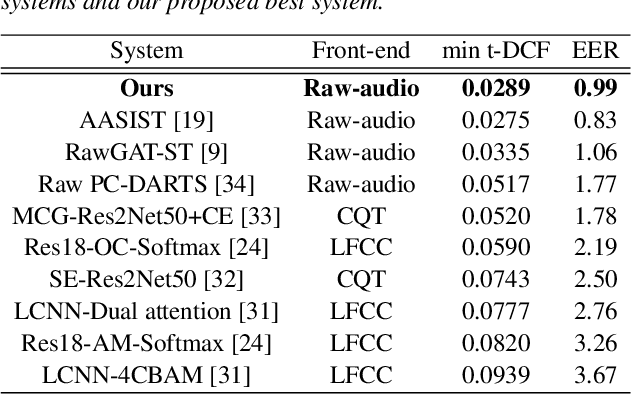
Automatic speaker verification systems are vulnerable to a variety of access threats, prompting research into the formulation of effective spoofing detection systems to act as a gate to filter out such spoofing attacks. This study introduces a simple attention module to infer 3-dim attention weights for the feature map in a convolutional layer, which then optimizes an energy function to determine each neuron's importance. With the advancement of both voice conversion and speech synthesis technologies, unseen spoofing attacks are constantly emerging to limit spoofing detection system performance. Here, we propose a joint optimization approach based on the weighted additive angular margin loss for binary classification, with a meta-learning training framework to develop an efficient system that is robust to a wide range of spoofing attacks for model generalization enhancement. As a result, when compared to current state-of-the-art systems, our proposed approach delivers a competitive result with a pooled EER of 0.99% and min t-DCF of 0.0289.
Hope Speech detection in under-resourced Kannada language
Aug 10, 2021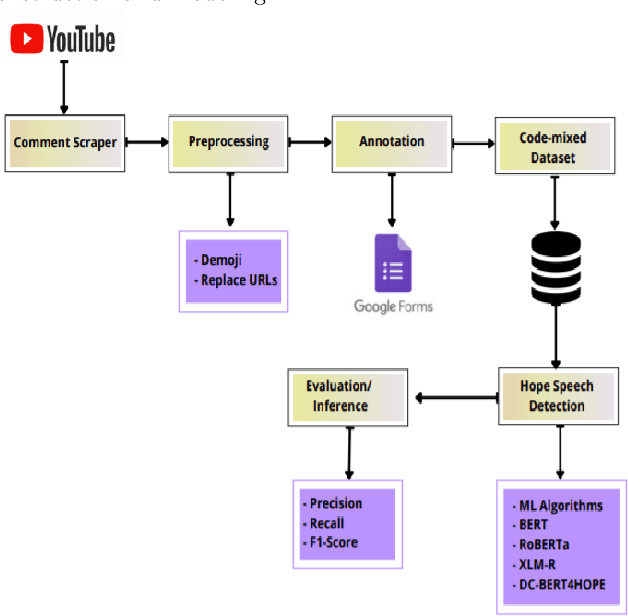
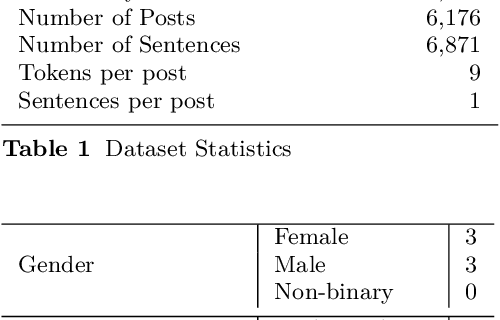
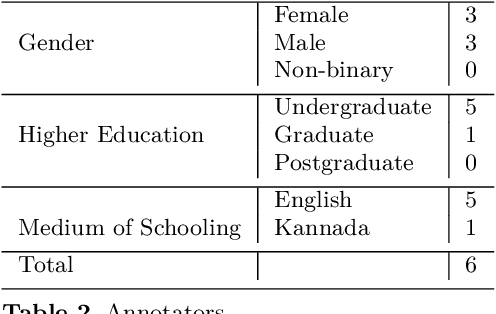
Numerous methods have been developed to monitor the spread of negativity in modern years by eliminating vulgar, offensive, and fierce comments from social media platforms. However, there are relatively lesser amounts of study that converges on embracing positivity, reinforcing supportive and reassuring content in online forums. Consequently, we propose creating an English-Kannada Hope speech dataset, KanHope and comparing several experiments to benchmark the dataset. The dataset consists of 6,176 user-generated comments in code mixed Kannada scraped from YouTube and manually annotated as bearing hope speech or Not-hope speech. In addition, we introduce DC-BERT4HOPE, a dual-channel model that uses the English translation of KanHope for additional training to promote hope speech detection. The approach achieves a weighted F1-score of 0.756, bettering other models. Henceforth, KanHope aims to instigate research in Kannada while broadly promoting researchers to take a pragmatic approach towards online content that encourages, positive, and supportive.
Spatially Selective Deep Non-linear Filters for Speaker Extraction
Nov 04, 2022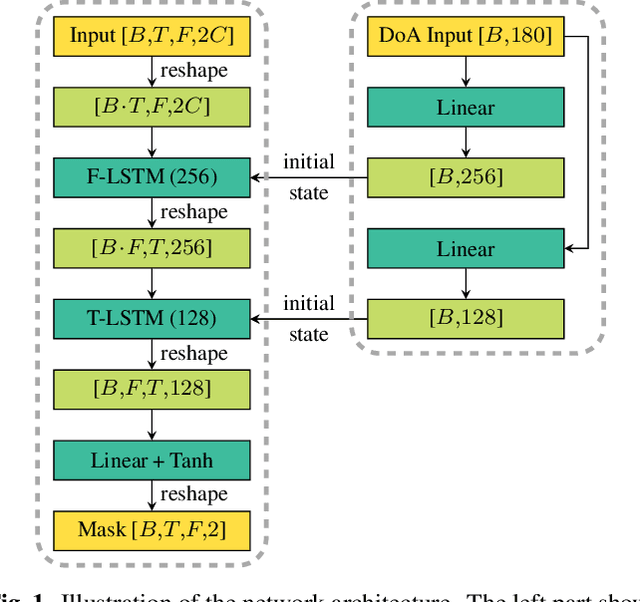
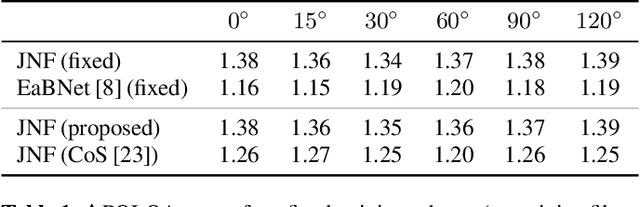
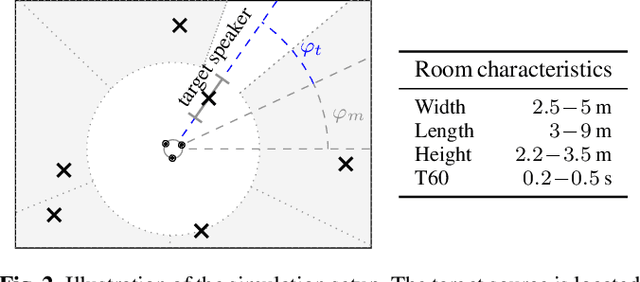
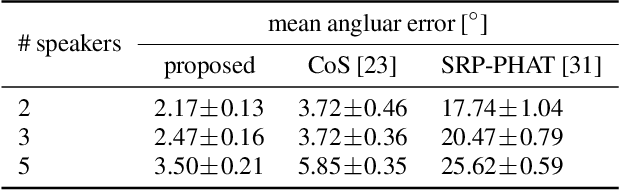
In a scenario with multiple persons talking simultaneously, the spatial characteristics of the signals are the most distinct feature for extracting the target signal. In this work, we develop a deep joint spatial-spectral non-linear filter that can be steered in an arbitrary target direction. For this we propose a simple and effective conditioning mechanism, which sets the initial state of the filter's recurrent layers based on the target direction. We show that this scheme is more effective than the baseline approach and increases the flexibility of the filter at no performance cost. The resulting spatially selective non-linear filters can also be used for speech separation of an arbitrary number of speakers and enable very accurate multi-speaker localization as we demonstrate in this paper.
Show Me Your Face, And I'll Tell You How You Speak
Jun 28, 2022

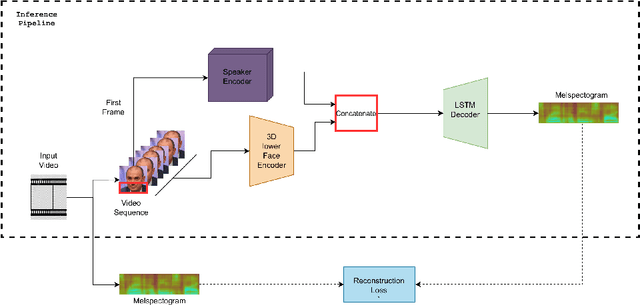

When we speak, the prosody and content of the speech can be inferred from the movement of our lips. In this work, we explore the task of lip to speech synthesis, i.e., learning to generate speech given only the lip movements of a speaker where we focus on learning accurate lip to speech mappings for multiple speakers in unconstrained, large vocabulary settings. We capture the speaker's voice identity through their facial characteristics, i.e., age, gender, ethnicity and condition them along with the lip movements to generate speaker identity aware speech. To this end, we present a novel method "Lip2Speech", with key design choices to achieve accurate lip to speech synthesis in unconstrained scenarios. We also perform various experiments and extensive evaluation using quantitative, qualitative metrics and human evaluation.
ASMDD: Arabic Speech Mispronunciation Detection Dataset
Nov 01, 2021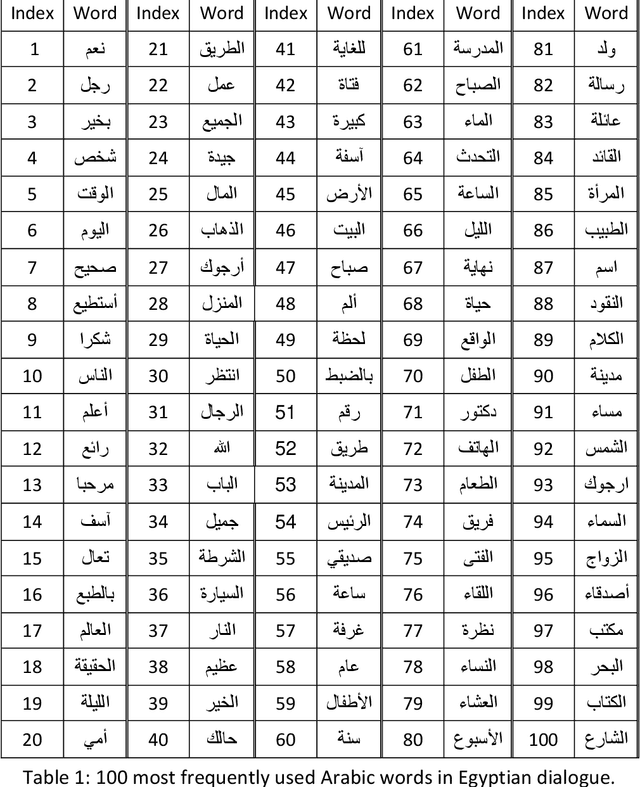
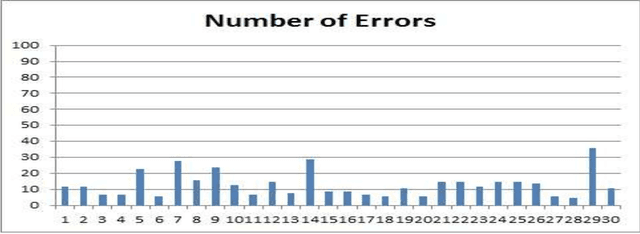
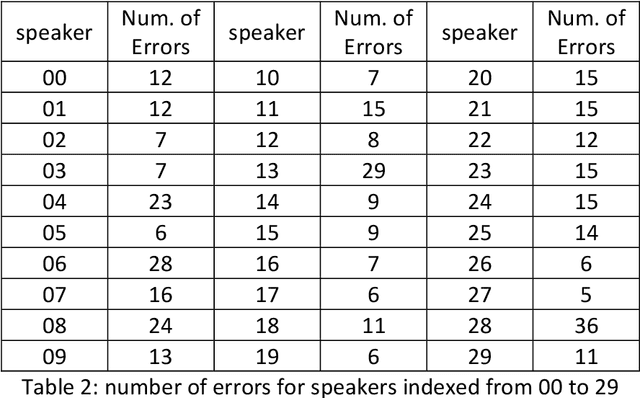
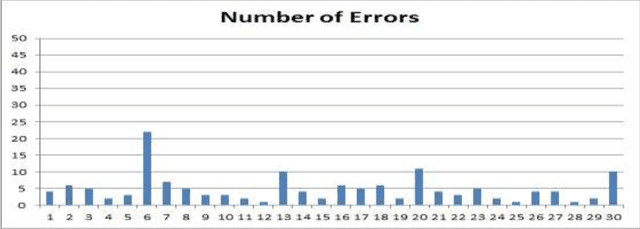
The largest dataset of Arabic speech mispronunciation detections in Egyptian dialogues is introduced. The dataset is composed of annotated audio files representing the top 100 words that are most frequently used in the Arabic language, pronounced by 100 Egyptian children (aged between 2 and 8 years old). The dataset is collected and annotated on segmental pronunciation error detections by expert listeners.
Creating a morphological and syntactic tagged corpus for the Uzbek language
Oct 27, 2022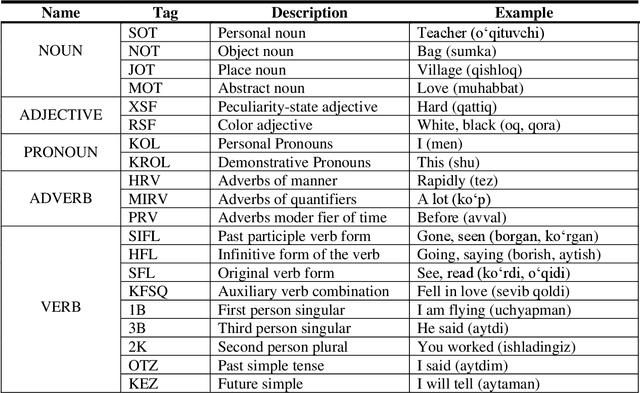
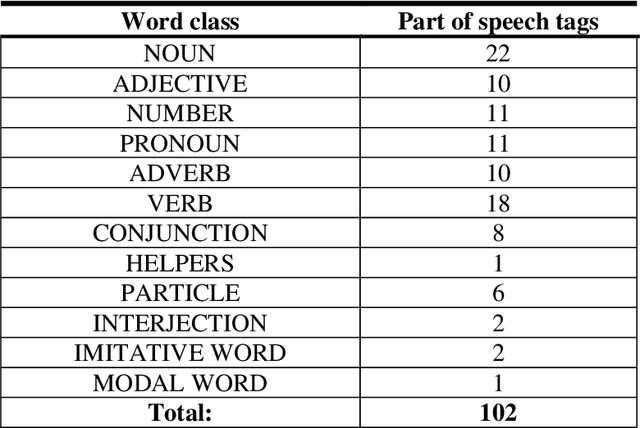
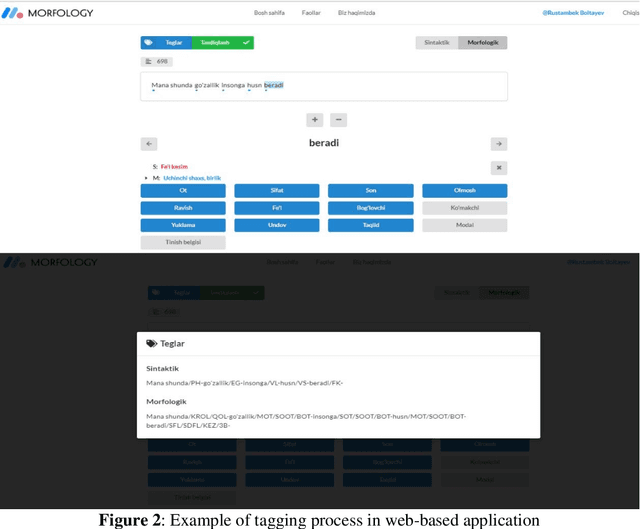
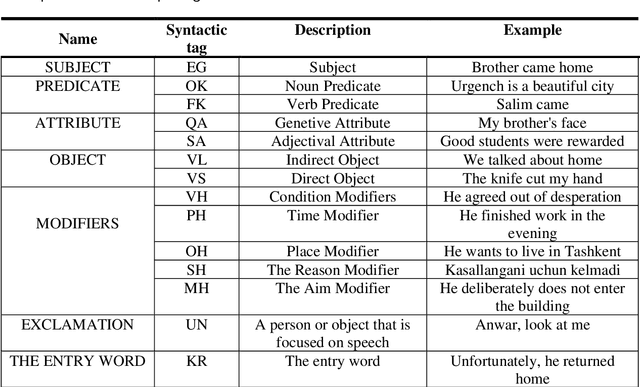
Nowadays, creation of the tagged corpora is becoming one of the most important tasks of Natural Language Processing (NLP). There are not enough tagged corpora to build machine learning models for the low-resource Uzbek language. In this paper, we tried to fill that gap by developing a novel Part Of Speech (POS) and syntactic tagset for creating the syntactic and morphologically tagged corpus of the Uzbek language. This work also includes detailed description and presentation of a web-based application to work on a tagging as well. Based on the developed annotation tool and the software, we share our experience results of the first stage of the tagged corpus creation