 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Conformer Based Acoustic Model for Robust Automatic Speech Recognition
Mar 20, 2022
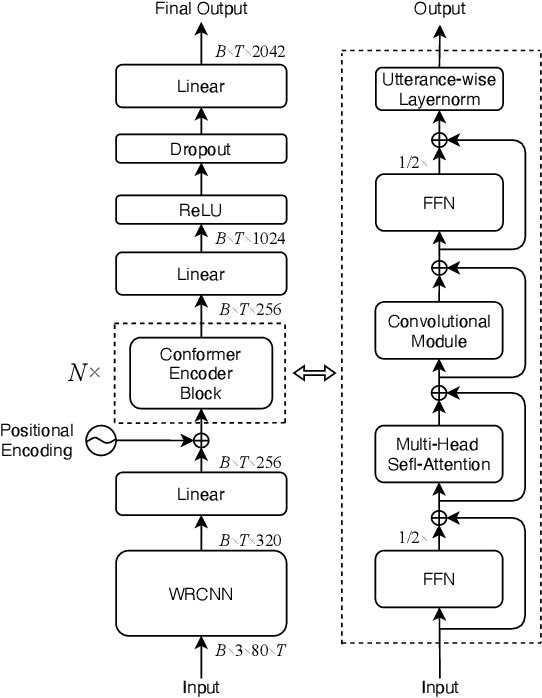
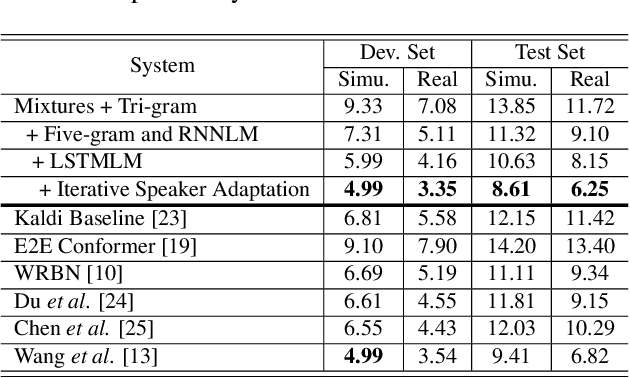
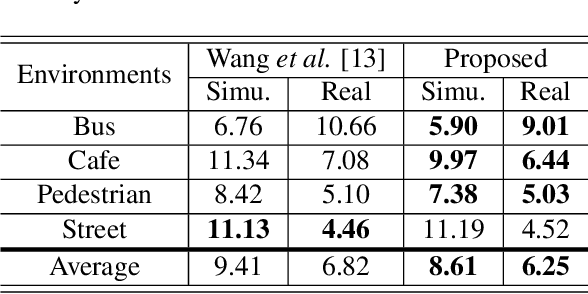
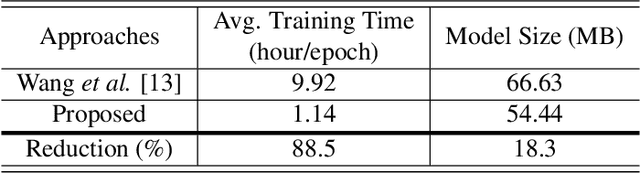
This study addresses robust automatic speech recognition (ASR) by introducing a Conformer-based acoustic model. The proposed model builds on a state-of-the-art recognition system using a bi-directional long short-term memory (BLSTM) model with utterance-wise dropout and iterative speaker adaptation, but employs a Conformer encoder instead of the BLSTM network. The Conformer encoder uses a convolution-augmented attention mechanism for acoustic modeling. The proposed system is evaluated on the monaural ASR task of the CHiME-4 corpus. Coupled with utterance-wise normalization and speaker adaptation, our model achieves $6.25\%$ word error rate, which outperforms the previous best system by $8.4\%$ relatively. In addition, the proposed Conformer-based model is $18.3\%$ smaller in model size and reduces total training time by $79.6\%$.
NANSY++: Unified Voice Synthesis with Neural Analysis and Synthesis
Nov 17, 2022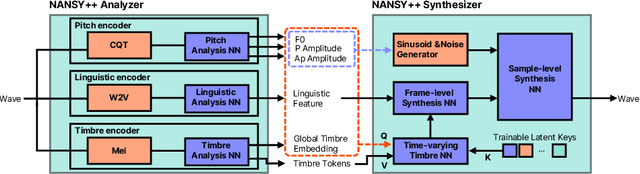
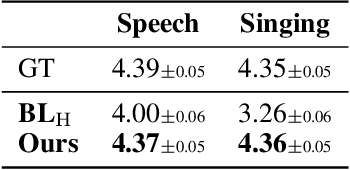
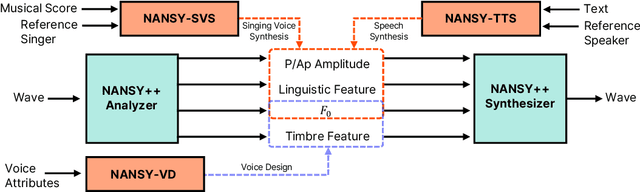

Various applications of voice synthesis have been developed independently despite the fact that they generate "voice" as output in common. In addition, most of the voice synthesis models still require a large number of audio data paired with annotated labels (e.g., text transcription and music score) for training. To this end, we propose a unified framework of synthesizing and manipulating voice signals from analysis features, dubbed NANSY++. The backbone network of NANSY++ is trained in a self-supervised manner that does not require any annotations paired with audio. After training the backbone network, we efficiently tackle four voice applications - i.e. voice conversion, text-to-speech, singing voice synthesis, and voice designing - by partially modeling the analysis features required for each task. Extensive experiments show that the proposed framework offers competitive advantages such as controllability, data efficiency, and fast training convergence, while providing high quality synthesis. Audio samples: tinyurl.com/8tnsy3uc.
Mel Spectrogram Inversion with Stable Pitch
Aug 26, 2022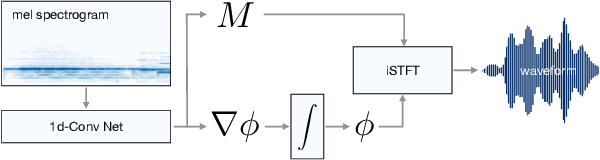
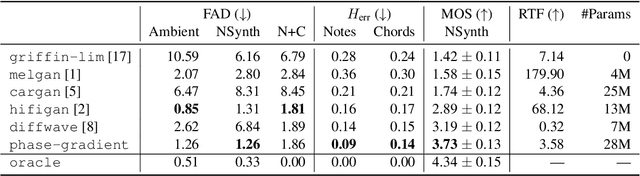
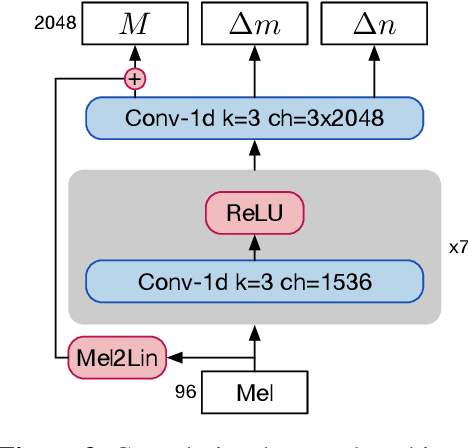
Vocoders are models capable of transforming a low-dimensional spectral representation of an audio signal, typically the mel spectrogram, to a waveform. Modern speech generation pipelines use a vocoder as their final component. Recent vocoder models developed for speech achieve a high degree of realism, such that it is natural to wonder how they would perform on music signals. Compared to speech, the heterogeneity and structure of the musical sound texture offers new challenges. In this work we focus on one specific artifact that some vocoder models designed for speech tend to exhibit when applied to music: the perceived instability of pitch when synthesizing sustained notes. We argue that the characteristic sound of this artifact is due to the lack of horizontal phase coherence, which is often the result of using a time-domain target space with a model that is invariant to time-shifts, such as a convolutional neural network. We propose a new vocoder model that is specifically designed for music. Key to improving the pitch stability is the choice of a shift-invariant target space that consists of the magnitude spectrum and the phase gradient. We discuss the reasons that inspired us to re-formulate the vocoder task, outline a working example, and evaluate it on musical signals. Our method results in 60% and 10% improved reconstruction of sustained notes and chords with respect to existing models, using a novel harmonic error metric.
An Exploration of Self-Supervised Pretrained Representations for End-to-End Speech Recognition
Oct 09, 2021
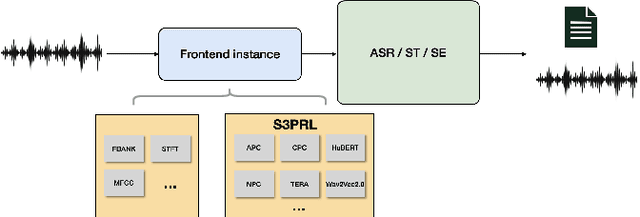
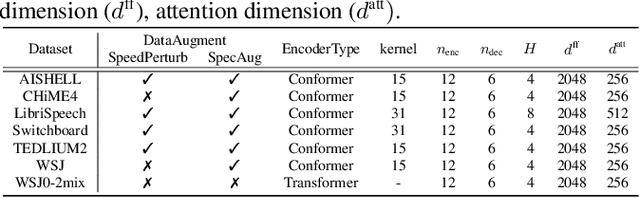
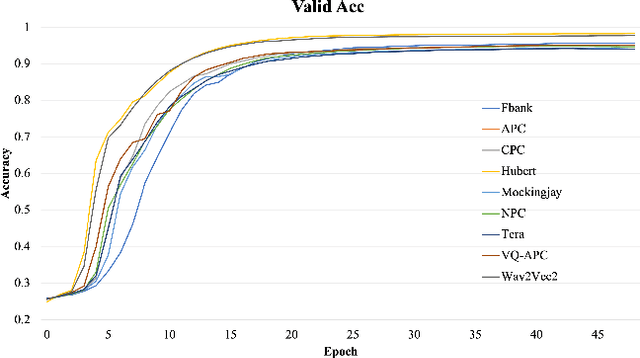
Self-supervised pretraining on speech data has achieved a lot of progress. High-fidelity representation of the speech signal is learned from a lot of untranscribed data and shows promising performance. Recently, there are several works focusing on evaluating the quality of self-supervised pretrained representations on various tasks without domain restriction, e.g. SUPERB. However, such evaluations do not provide a comprehensive comparison among many ASR benchmark corpora. In this paper, we focus on the general applications of pretrained speech representations, on advanced end-to-end automatic speech recognition (E2E-ASR) models. We select several pretrained speech representations and present the experimental results on various open-source and publicly available corpora for E2E-ASR. Without any modification of the back-end model architectures or training strategy, some of the experiments with pretrained representations, e.g., WSJ, WSJ0-2mix with HuBERT, reach or outperform current state-of-the-art (SOTA) recognition performance. Moreover, we further explore more scenarios for whether the pretraining representations are effective, such as the cross-language or overlapped speech. The scripts, configuratons and the trained models have been released in ESPnet to let the community reproduce our experiments and improve them.
A Part-of-Speech Tagger for Yiddish: First Steps in Tagging the Yiddish Book Center Corpus
Apr 03, 2022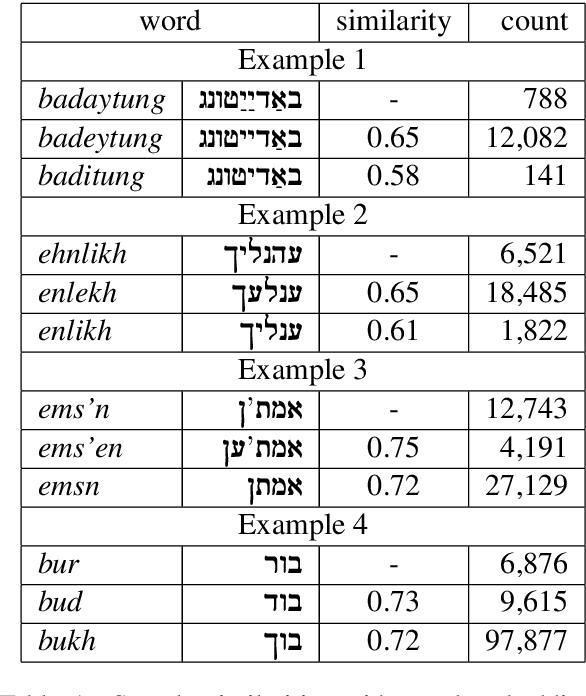
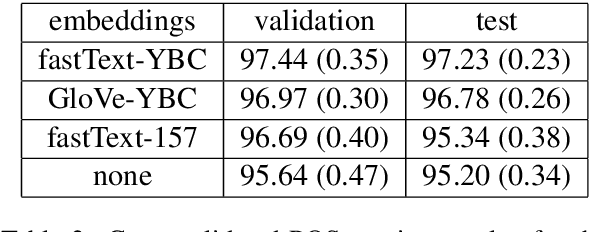
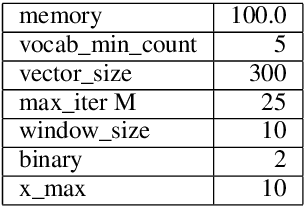
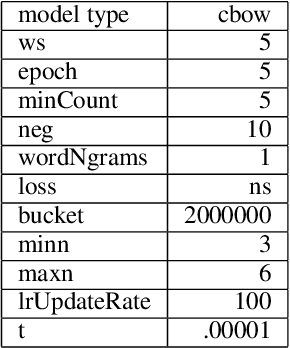
We describe the construction and evaluation of a part-of-speech tagger for Yiddish (the first one, to the best of our knowledge). This is the first step in a larger project of automatically assigning part-of-speech tags and syntactic structure to Yiddish text for purposes of linguistic research. We combine two resources for the current work - an 80K word subset of the Penn Parsed Corpus of Historical Yiddish (PPCHY) (Santorini, 2021) and 650 million words of OCR'd Yiddish text from the Yiddish Book Center (YBC). We compute word embeddings on the YBC corpus, and these embeddings are used with a tagger model trained and evaluated on the PPCHY. Yiddish orthography in the YBC corpus has many spelling inconsistencies, and we present some evidence that even simple non-contextualized embeddings are able to capture the relationships among spelling variants without the need to first "standardize" the corpus. We evaluate the tagger performance on a 10-fold cross-validation split, with and without the embeddings, showing that the embeddings improve tagger performance. However, a great deal of work remains to be done, and we conclude by discussing some next steps, including the need for additional annotated training and test data.
NWPU-ASLP System for the VoicePrivacy 2022 Challenge
Sep 24, 2022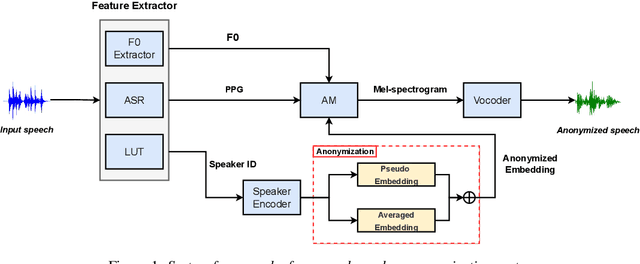

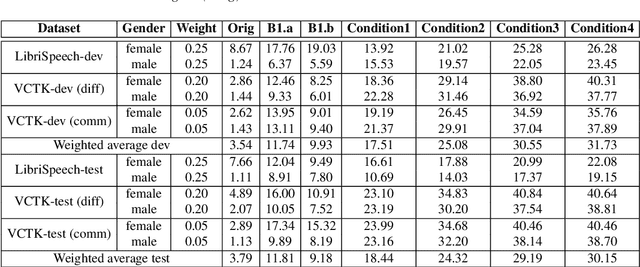
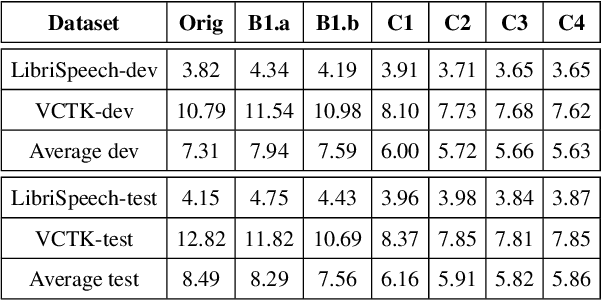
This paper presents the NWPU-ASLP speaker anonymization system for VoicePrivacy 2022 Challenge. Our submission does not involve additional Automatic Speaker Verification (ASV) model or x-vector pool. Our system consists of four modules, including feature extractor, acoustic model, anonymization module, and neural vocoder. First, the feature extractor extracts the Phonetic Posteriorgram (PPG) and pitch from the input speech signal. Then, we reserve a pseudo speaker ID from a speaker look-up table (LUT), which is subsequently fed into a speaker encoder to generate the pseudo speaker embedding that is not corresponding to any real speaker. To ensure the pseudo speaker is distinguishable, we further average the randomly selected speaker embedding and weighted concatenate it with the pseudo speaker embedding to generate the anonymized speaker embedding. Finally, the acoustic model outputs the anonymized mel-spectrogram from the anonymized speaker embedding and a modified version of HifiGAN transforms the mel-spectrogram into the anonymized speech waveform. Experimental results demonstrate the effectiveness of our proposed anonymization system.
FaceFormer: Speech-Driven 3D Facial Animation with Transformers
Dec 10, 2021
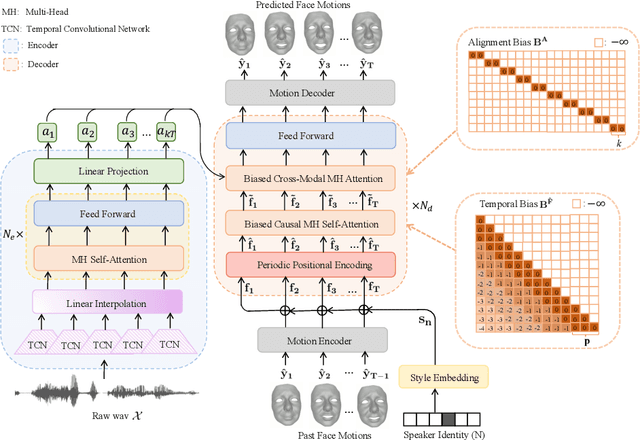

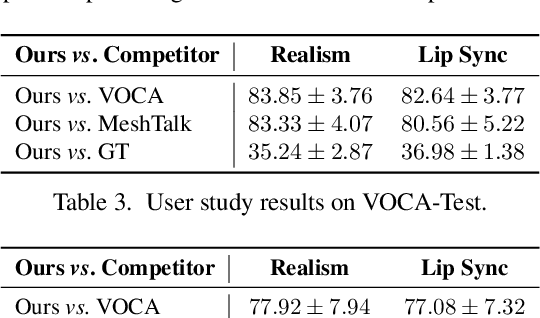
Speech-driven 3D facial animation is challenging due to the complex geometry of human faces and the limited availability of 3D audio-visual data. Prior works typically focus on learning phoneme-level features of short audio windows with limited context, occasionally resulting in inaccurate lip movements. To tackle this limitation, we propose a Transformer-based autoregressive model, FaceFormer, which encodes the long-term audio context and autoregressively predicts a sequence of animated 3D face meshes. To cope with the data scarcity issue, we integrate the self-supervised pre-trained speech representations. Also, we devise two biased attention mechanisms well suited to this specific task, including the biased cross-modal multi-head (MH) attention and the biased causal MH self-attention with a periodic positional encoding strategy. The former effectively aligns the audio-motion modalities, whereas the latter offers abilities to generalize to longer audio sequences. Extensive experiments and a perceptual user study show that our approach outperforms the existing state-of-the-arts. The code will be made available.
Detecting Dementia from Speech and Transcripts using Transformers
Oct 27, 2021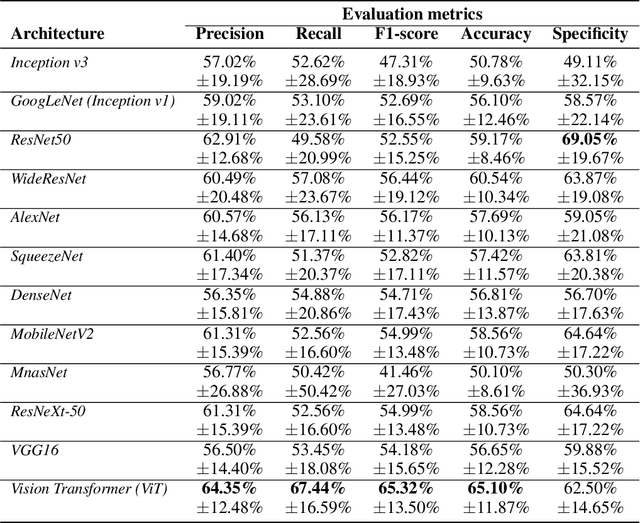
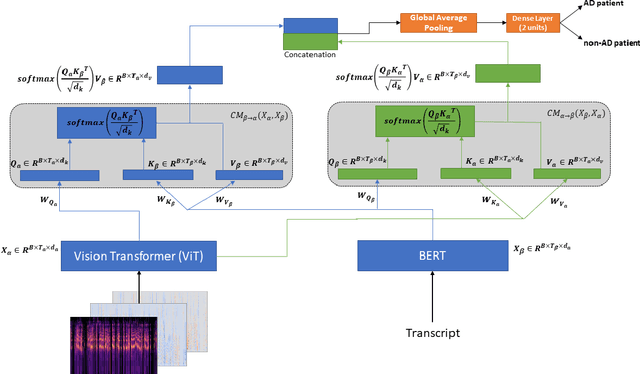
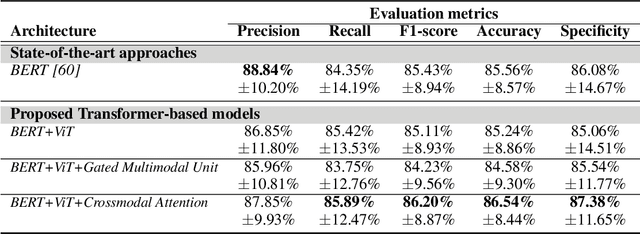
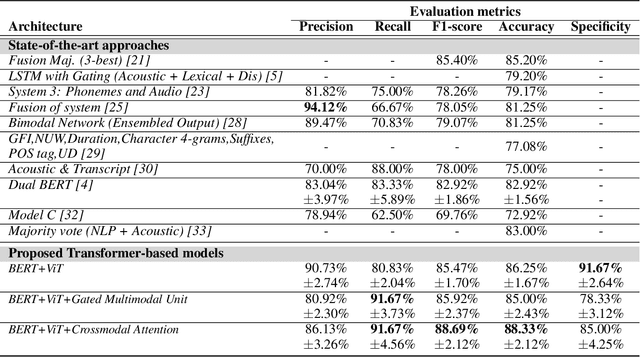
Alzheimer's disease (AD) constitutes a neurodegenerative disease with serious consequences to peoples' everyday lives, if it is not diagnosed early since there is no available cure. Because of the cost of examinations for diagnosing dementia, i.e., Magnetic Resonance Imaging (MRI), electroencephalogram (EEG) signals etc., current work has been focused on diagnosing dementia from spontaneous speech. However, little work has been done regarding the conversion of speech data to Log-Mel spectrograms and Mel-frequency cepstral coefficients (MFCCs) and the usage of pretrained models. Concurrently, little work has been done in terms of both the usage of transformer networks and the way the two modalities, i.e., speech and transcripts, are combined in a single neural network. To address these limitations, first we employ several pretrained models, with Vision Transformer (ViT) achieving the highest evaluation results. Secondly, we propose multimodal models. More specifically, our introduced models include Gated Multimodal Unit in order to control the influence of each modality towards the final classification and crossmodal attention so as to capture in an effective way the relationships between the two modalities. Extensive experiments conducted on the ADReSS Challenge dataset demonstrate the effectiveness of the proposed models and their superiority over state-of-the-art approaches.
SpeechNet: A Universal Modularized Model for Speech Processing Tasks
May 31, 2021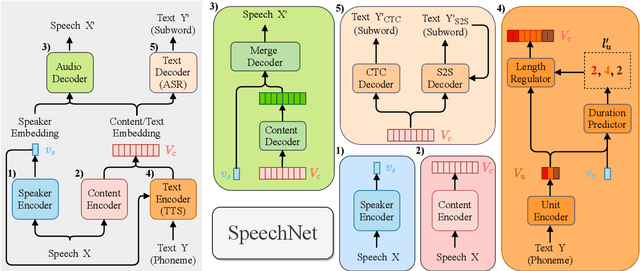
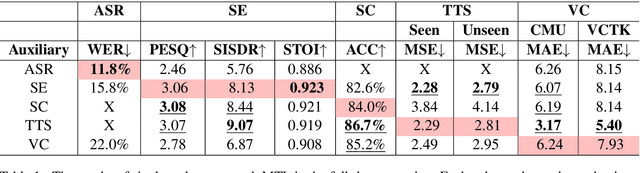
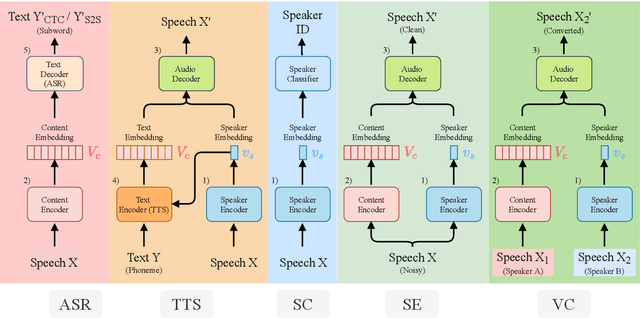
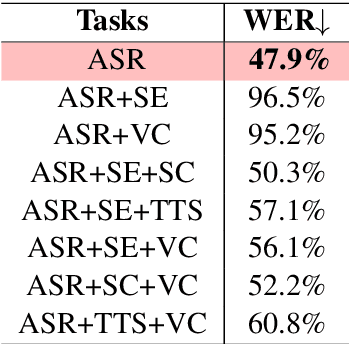
There is a wide variety of speech processing tasks ranging from extracting content information from speech signals to generating speech signals. For different tasks, model networks are usually designed and tuned separately. If a universal model can perform multiple speech processing tasks, some tasks might be improved with the related abilities learned from other tasks. The multi-task learning of a wide variety of speech processing tasks with a universal model has not been studied. This paper proposes a universal modularized model, SpeechNet, which treats all speech processing tasks into a speech/text input and speech/text output format. We select five essential speech processing tasks for multi-task learning experiments with SpeechNet. We show that SpeechNet learns all of the above tasks, and we further analyze which tasks can be improved by other tasks. SpeechNet is modularized and flexible for incorporating more modules, tasks, or training approaches in the future. We release the code and experimental settings to facilitate the research of modularized universal models and multi-task learning of speech processing tasks.
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
Jun 06, 2021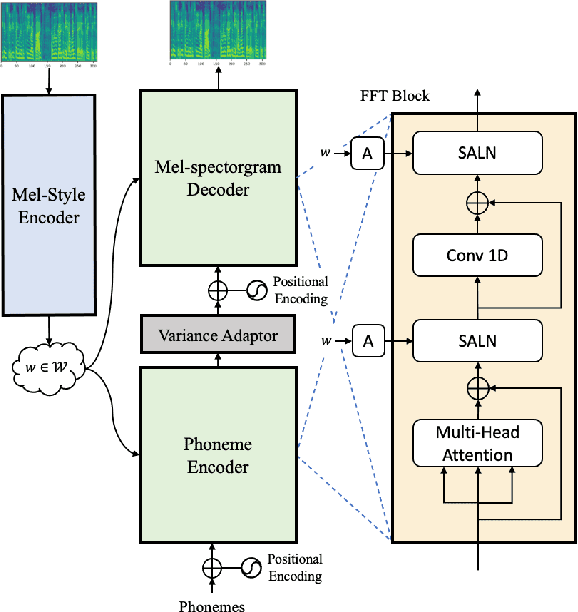
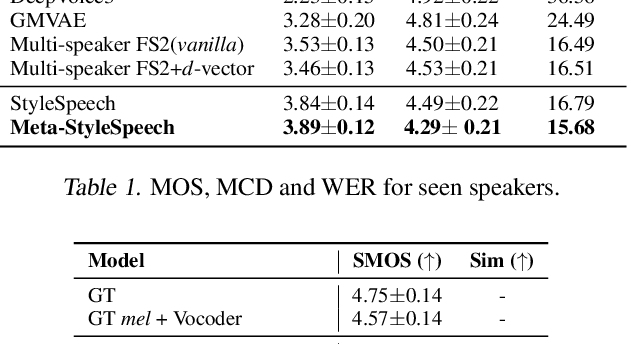
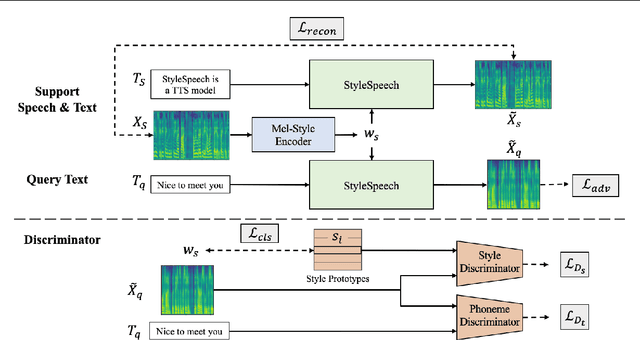

With rapid progress in neural text-to-speech (TTS) models, personalized speech generation is now in high demand for many applications. For practical applicability, a TTS model should generate high-quality speech with only a few audio samples from the given speaker, that are also short in length. However, existing methods either require to fine-tune the model or achieve low adaptation quality without fine-tuning. In this work, we propose StyleSpeech, a new TTS model which not only synthesizes high-quality speech but also effectively adapts to new speakers. Specifically, we propose Style-Adaptive Layer Normalization (SALN) which aligns gain and bias of the text input according to the style extracted from a reference speech audio. With SALN, our model effectively synthesizes speech in the style of the target speaker even from single speech audio. Furthermore, to enhance StyleSpeech's adaptation to speech from new speakers, we extend it to Meta-StyleSpeech by introducing two discriminators trained with style prototypes, and performing episodic training. The experimental results show that our models generate high-quality speech which accurately follows the speaker's voice with single short-duration (1-3 sec) speech audio, significantly outperforming baselines.