 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Fully Unsupervised Training of Few-shot Keyword Spotting
Oct 07, 2022
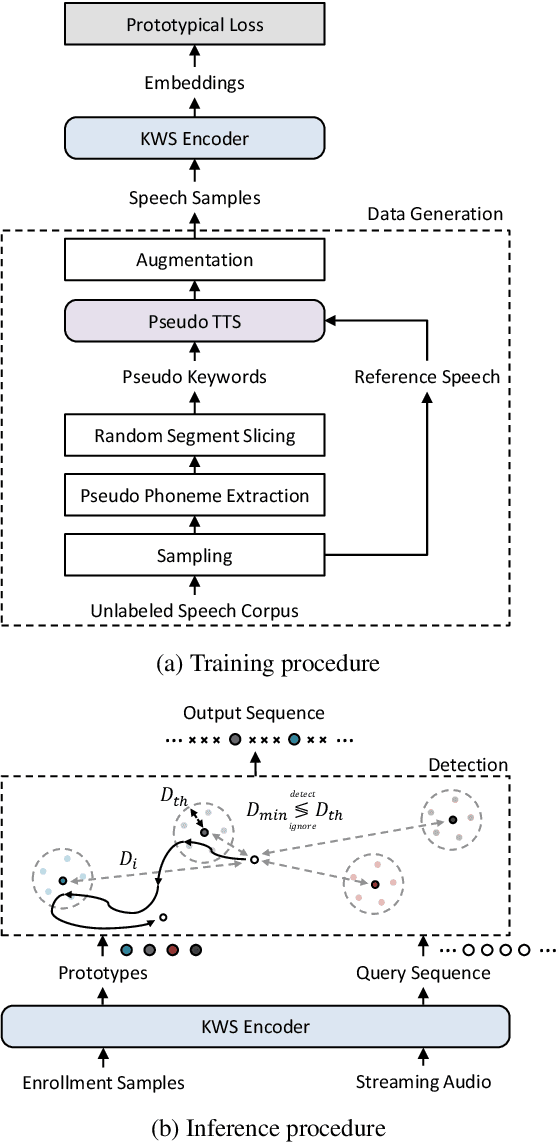
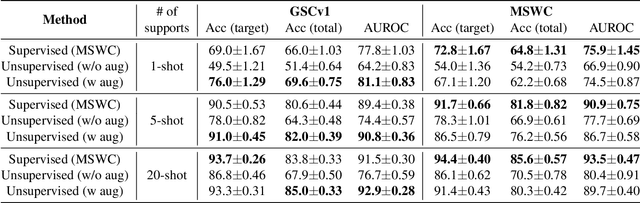

For training a few-shot keyword spotting (FS-KWS) model, a large labeled dataset containing massive target keywords has known to be essential to generalize to arbitrary target keywords with only a few enrollment samples. To alleviate the expensive data collection with labeling, in this paper, we propose a novel FS-KWS system trained only on synthetic data. The proposed system is based on metric learning enabling target keywords to be detected using distance metrics. Exploiting the speech synthesis model that generates speech with pseudo phonemes instead of texts, we easily obtain a large collection of multi-view samples with the same semantics. These samples are sufficient for training, considering metric learning does not intrinsically necessitate labeled data. All of the components in our framework do not require any supervision, making our method unsupervised. Experimental results on real datasets show our proposed method is competitive even without any labeled and real datasets.
Residual Adapters for Parameter-Efficient ASR Adaptation to Atypical and Accented Speech
Sep 14, 2021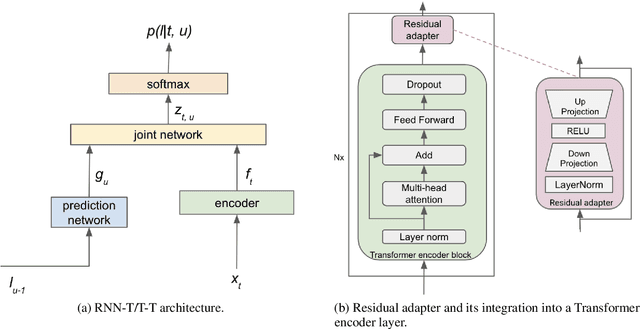
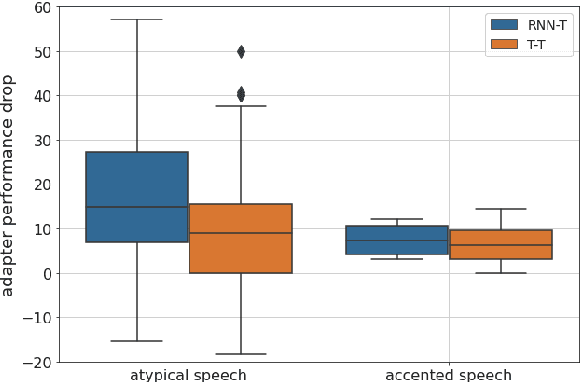
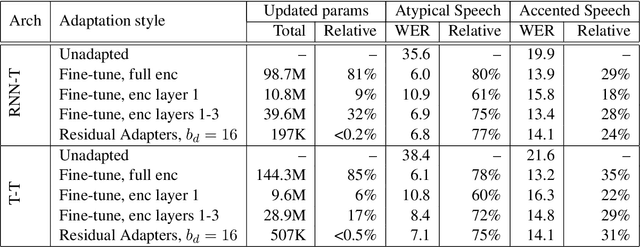
Automatic Speech Recognition (ASR) systems are often optimized to work best for speakers with canonical speech patterns. Unfortunately, these systems perform poorly when tested on atypical speech and heavily accented speech. It has previously been shown that personalization through model fine-tuning substantially improves performance. However, maintaining such large models per speaker is costly and difficult to scale. We show that by adding a relatively small number of extra parameters to the encoder layers via so-called residual adapter, we can achieve similar adaptation gains compared to model fine-tuning, while only updating a tiny fraction (less than 0.5%) of the model parameters. We demonstrate this on two speech adaptation tasks (atypical and accented speech) and for two state-of-the-art ASR architectures.
Investigation of Deep Neural Network Acoustic Modelling Approaches for Low Resource Accented Mandarin Speech Recognition
Jan 24, 2022The Mandarin Chinese language is known to be strongly influenced by a rich set of regional accents, while Mandarin speech with each accent is quite low resource. Hence, an important task in Mandarin speech recognition is to appropriately model the acoustic variabilities imposed by accents. In this paper, an investigation of implicit and explicit use of accent information on a range of deep neural network (DNN) based acoustic modelling techniques is conducted. Meanwhile, approaches of multi-accent modelling including multi-style training, multi-accent decision tree state tying, DNN tandem and multi-level adaptive network (MLAN) tandem hidden Markov model (HMM) modelling are combined and compared in this paper. On a low resource accented Mandarin speech recognition task consisting of four regional accents, an improved MLAN tandem HMM systems explicitly leveraging the accent information was proposed and significantly outperformed the baseline accent independent DNN tandem systems by 0.8%-1.5% absolute (6%-9% relative) in character error rate after sequence level discriminative training and adaptation.
* Published in JOURNAL OF INTEGRATION TECHNOLOGY CNKI:SUN:JCJI.0.2015-06-003
Attribute Inference Attack of Speech Emotion Recognition in Federated Learning Settings
Dec 26, 2021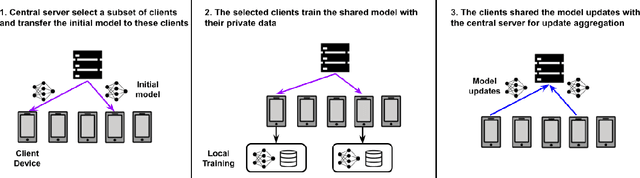
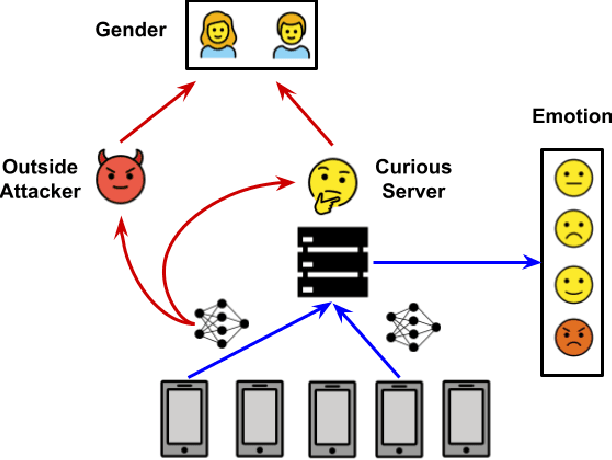
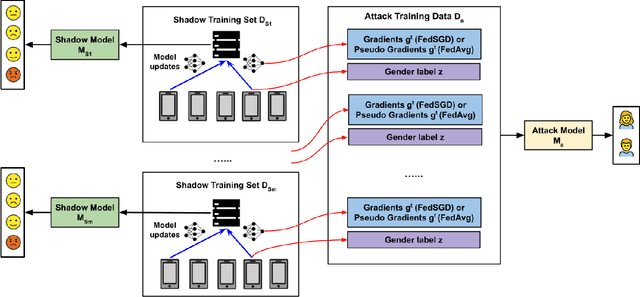
Speech emotion recognition (SER) processes speech signals to detect and characterize expressed perceived emotions. Many SER application systems often acquire and transmit speech data collected at the client-side to remote cloud platforms for inference and decision making. However, speech data carry rich information not only about emotions conveyed in vocal expressions, but also other sensitive demographic traits such as gender, age and language background. Consequently, it is desirable for SER systems to have the ability to classify emotion constructs while preventing unintended/improper inferences of sensitive and demographic information. Federated learning (FL) is a distributed machine learning paradigm that coordinates clients to train a model collaboratively without sharing their local data. This training approach appears secure and can improve privacy for SER. However, recent works have demonstrated that FL approaches are still vulnerable to various privacy attacks like reconstruction attacks and membership inference attacks. Although most of these have focused on computer vision applications, such information leakages exist in the SER systems trained using the FL technique. To assess the information leakage of SER systems trained using FL, we propose an attribute inference attack framework that infers sensitive attribute information of the clients from shared gradients or model parameters, corresponding to the FedSGD and the FedAvg training algorithms, respectively. As a use case, we empirically evaluate our approach for predicting the client's gender information using three SER benchmark datasets: IEMOCAP, CREMA-D, and MSP-Improv. We show that the attribute inference attack is achievable for SER systems trained using FL. We further identify that most information leakage possibly comes from the first layer in the SER model.
Learning a Neural Diff for Speech Models
Aug 17, 2021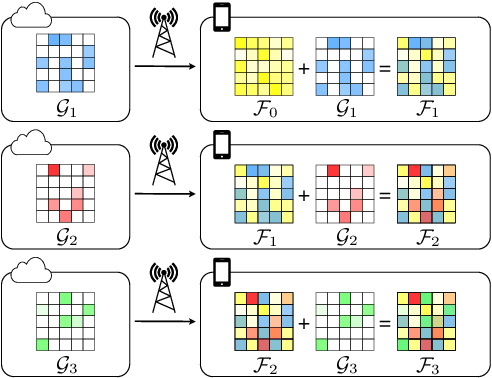
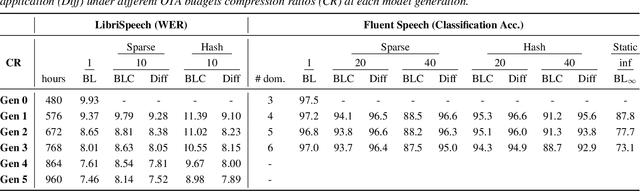
As more speech processing applications execute locally on edge devices, a set of resource constraints must be considered. In this work we address one of these constraints, namely over-the-network data budgets for transferring models from server to device. We present neural update approaches for release of subsequent speech model generations abiding by a data budget. We detail two architecture-agnostic methods which learn compact representations for transmission to devices. We experimentally validate our techniques with results on two tasks (automatic speech recognition and spoken language understanding) on open source data sets by demonstrating when applied in succession, our budgeted updates outperform comparable model compression baselines by significant margins.
Task-aware Warping Factors in Mask-based Speech Enhancement
Aug 27, 2021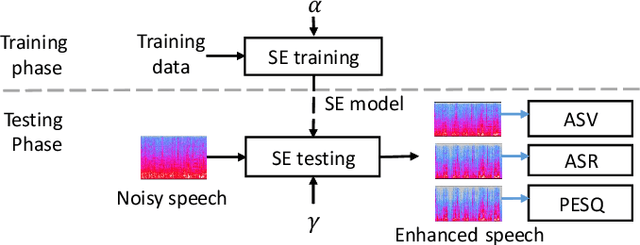
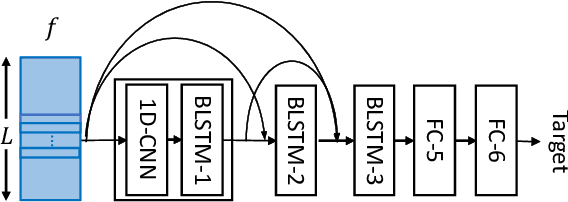
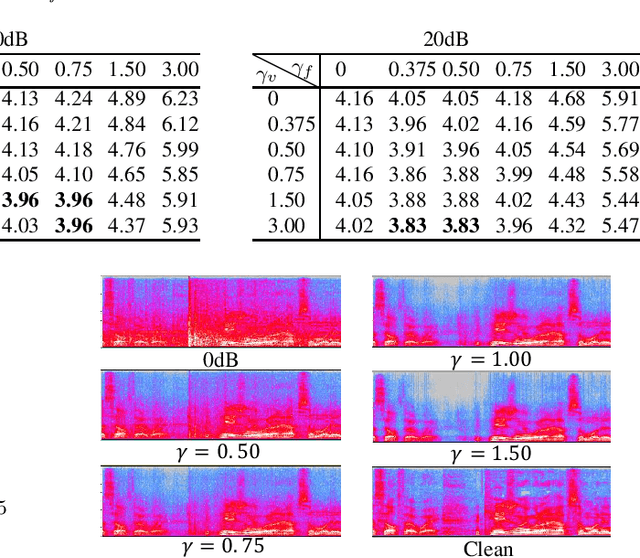
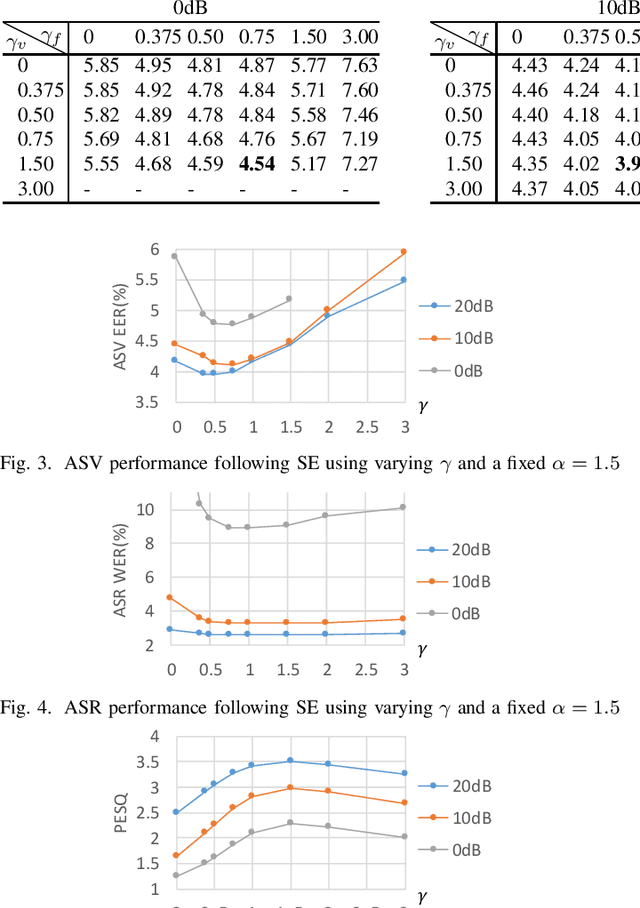
This paper proposes the use of two task-aware warping factors in mask-based speech enhancement (SE). One controls the balance between speech-maintenance and noise-removal in training phases, while the other controls SE power applied to specific downstream tasks in testing phases. Our intention is to alleviate the problem that SE systems trained to improve speech quality often fail to improve other downstream tasks, such as automatic speaker verification (ASV) and automatic speech recognition (ASR), because they do not share the same objects. It is easy to apply the proposed dual-warping factors approach to any mask-based SE method, and it allows a single SE system to handle multiple tasks without task-dependent training. The effectiveness of our proposed approach has been confirmed on the SITW dataset for ASV evaluation and the LibriSpeech dataset for ASR and speech quality evaluations of 0-20dB. We show that different warping values are necessary for a single SE to achieve optimal performance w.r.t. the three tasks. With the use of task-dependent warping factors, speech quality was improved by an 84.7% PESQ increase, ASV had a 22.4% EER reduction, and ASR had a 52.2% WER reduction, on 0dB speech. The effectiveness of the task-dependent warping factors were also cross-validated on VoxCeleb-1 test set for ASV and LibriSpeech dev-clean set for ASV and quality evaluations. The proposed method is highly effective and easy to apply in practice.
Mono vs Multilingual BERT for Hate Speech Detection and Text Classification: A Case Study in Marathi
Apr 19, 2022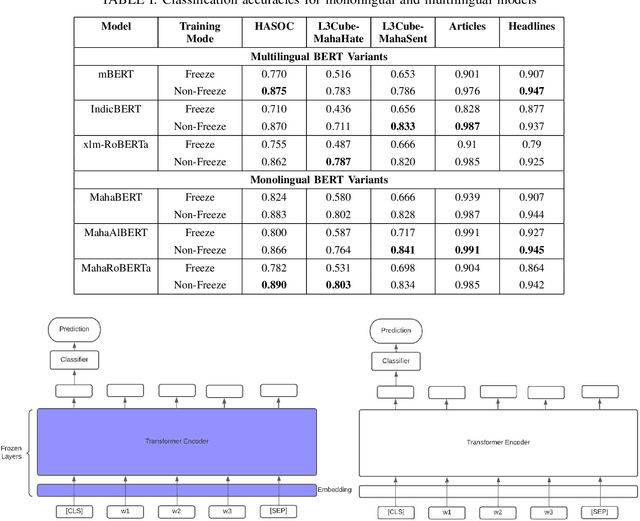
Transformers are the most eminent architectures used for a vast range of Natural Language Processing tasks. These models are pre-trained over a large text corpus and are meant to serve state-of-the-art results over tasks like text classification. In this work, we conduct a comparative study between monolingual and multilingual BERT models. We focus on the Marathi language and evaluate the models on the datasets for hate speech detection, sentiment analysis and simple text classification in Marathi. We use standard multilingual models such as mBERT, indicBERT and xlm-RoBERTa and compare with MahaBERT, MahaALBERT and MahaRoBERTa, the monolingual models for Marathi. We further show that Marathi monolingual models outperform the multilingual BERT variants on five different downstream fine-tuning experiments. We also evaluate sentence embeddings from these models by freezing the BERT encoder layers. We show that monolingual MahaBERT based models provide rich representations as compared to sentence embeddings from multi-lingual counterparts. However, we observe that these embeddings are not generic enough and do not work well on out of domain social media datasets. We consider two Marathi hate speech datasets L3Cube-MahaHate, HASOC-2021, a Marathi sentiment classification dataset L3Cube-MahaSent, and Marathi Headline, Articles classification datasets.
Push-Pull: Characterizing the Adversarial Robustness for Audio-Visual Active Speaker Detection
Oct 03, 2022
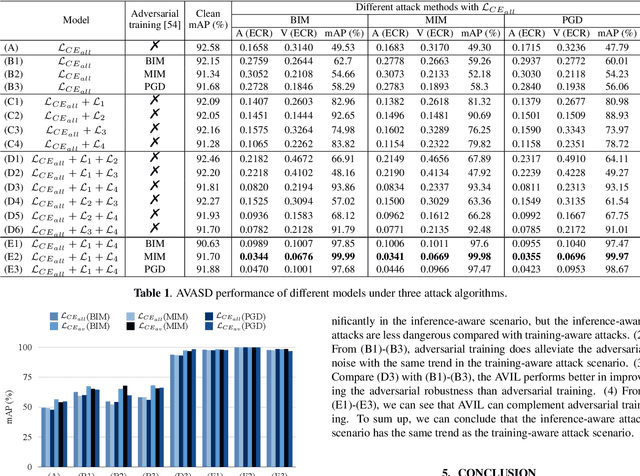
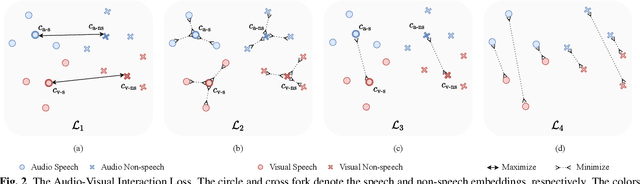
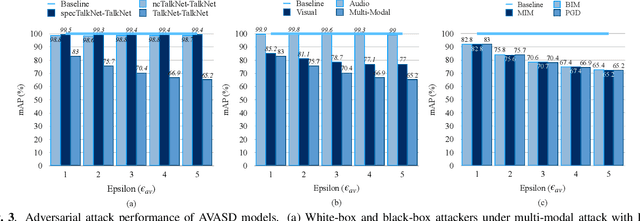
Audio-visual active speaker detection (AVASD) is well-developed, and now is an indispensable front-end for several multi-modal applications. However, to the best of our knowledge, the adversarial robustness of AVASD models hasn't been investigated, not to mention the effective defense against such attacks. In this paper, we are the first to reveal the vulnerability of AVASD models under audio-only, visual-only, and audio-visual adversarial attacks through extensive experiments. What's more, we also propose a novel audio-visual interaction loss (AVIL) for making attackers difficult to find feasible adversarial examples under an allocated attack budget. The loss aims at pushing the inter-class embeddings to be dispersed, namely non-speech and speech clusters, sufficiently disentangled, and pulling the intra-class embeddings as close as possible to keep them compact. Experimental results show the AVIL outperforms the adversarial training by 33.14 mAP (%) under multi-modal attacks.
FaceFormer: Speech-Driven 3D Facial Animation with Transformers
Dec 28, 2021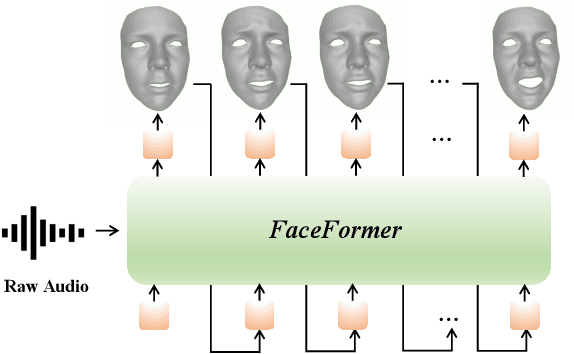
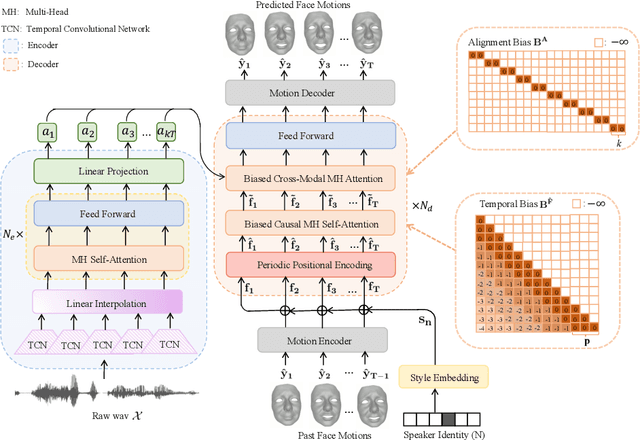

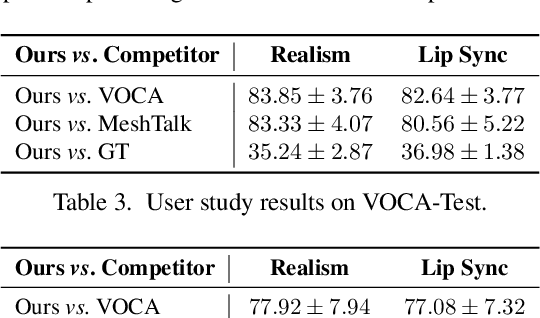
Speech-driven 3D facial animation is challenging due to the complex geometry of human faces and the limited availability of 3D audio-visual data. Prior works typically focus on learning phoneme-level features of short audio windows with limited context, occasionally resulting in inaccurate lip movements. To tackle this limitation, we propose a Transformer-based autoregressive model, FaceFormer, which encodes the long-term audio context and autoregressively predicts a sequence of animated 3D face meshes. To cope with the data scarcity issue, we integrate the self-supervised pre-trained speech representations. Also, we devise two biased attention mechanisms well suited to this specific task, including the biased cross-modal multi-head (MH) attention and the biased causal MH self-attention with a periodic positional encoding strategy. The former effectively aligns the audio-motion modalities, whereas the latter offers abilities to generalize to longer audio sequences. Extensive experiments and a perceptual user study show that our approach outperforms the existing state-of-the-arts. We encourage watching the video. The code will be made available.
PercepNet+: A Phase and SNR Aware PercepNet for Real-Time Speech Enhancement
Mar 04, 2022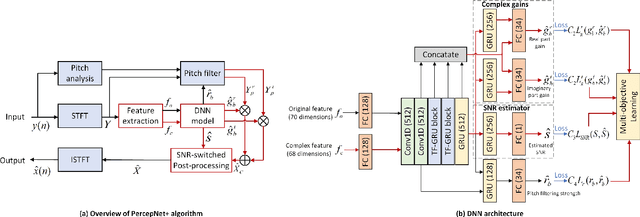
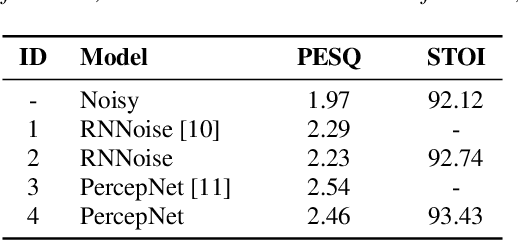
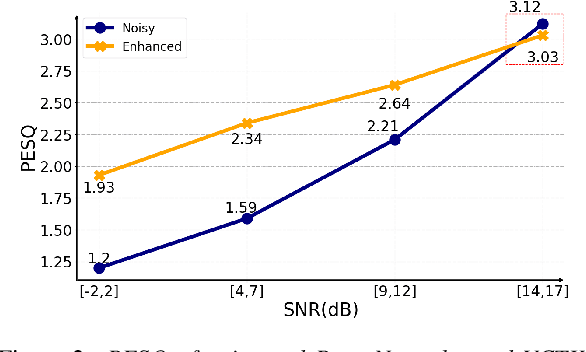
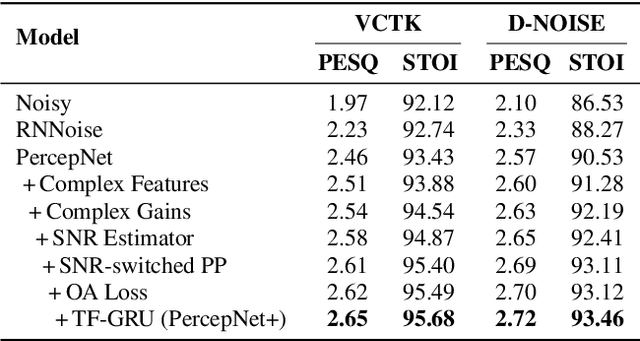
PercepNet, a recent extension of the RNNoise, an efficient, high-quality and real-time full-band speech enhancement technique, has shown promising performance in various public deep noise suppression tasks. This paper proposes a new approach, named PercepNet+, to further extend the PercepNet with four significant improvements. First, we introduce a phase-aware structure to leverage the phase information into PercepNet, by adding the complex features and complex subband gains as the deep network input and output respectively. Then, a signal-to-noise ratio (SNR) estimator and an SNR switched post-processing are specially designed to alleviate the over attenuation (OA) that appears in high SNR conditions of the original PercepNet. Moreover, the GRU layer is replaced by TF-GRU to model both temporal and frequency dependencies. Finally, we propose to integrate the loss of complex subband gain, SNR, pitch filtering strength, and an OA loss in a multi-objective learning manner to further improve the speech enhancement performance. Experimental results show that, the proposed PercepNet+ outperforms the original PercepNet significantly in terms of both PESQ and STOI, without increasing the model size too much.