 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Understanding Postpartum Parents' Experiences via Two Digital Platforms
Dec 22, 2022

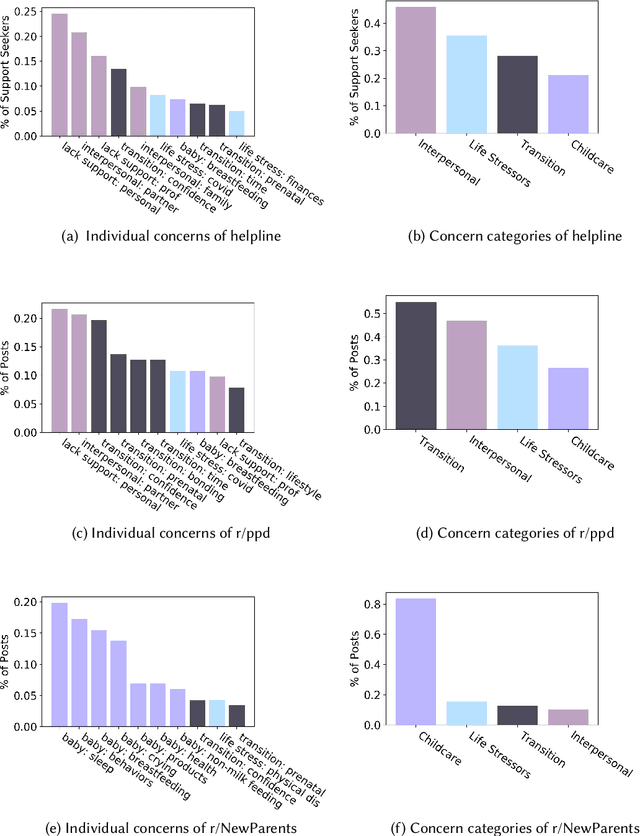
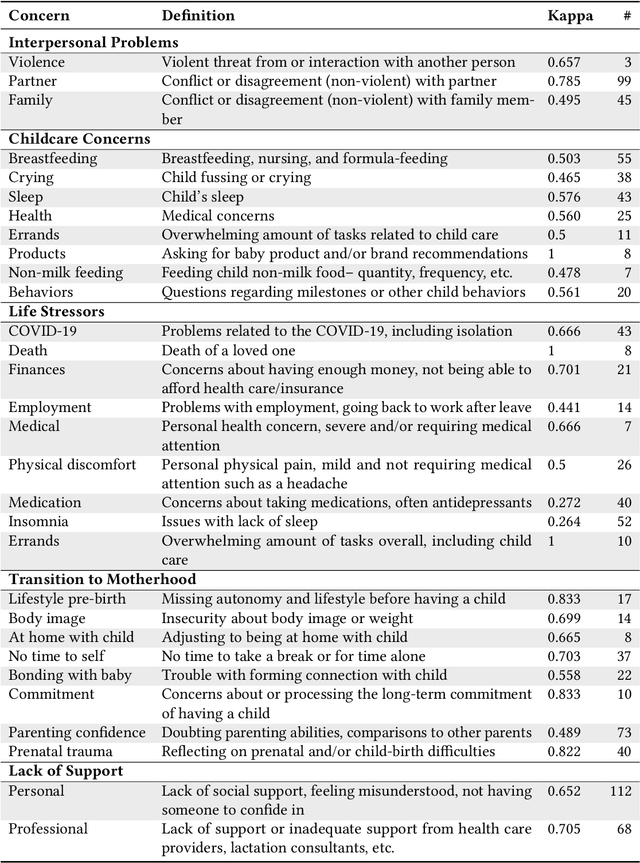
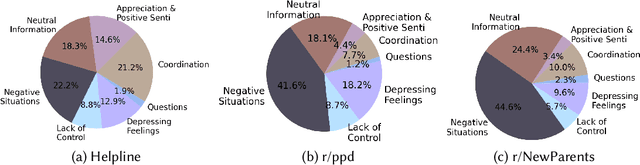
Digital platforms, including online forums and helplines, have emerged as avenues of support for caregivers suffering from postpartum mental health distress. Understanding support seekers' experiences as shared on these platforms could provide crucial insight into caregivers' needs during this vulnerable time. In the current work, we provide a descriptive analysis of the concerns, psychological states, and motivations shared by healthy and distressed postpartum support seekers on two digital platforms, a one-on-one digital helpline and a publicly available online forum. Using a combination of human annotations, dictionary models and unsupervised techniques, we find stark differences between the experiences of distressed and healthy mothers. Distressed mothers described interpersonal problems and a lack of support, with 8.60% - 14.56% reporting severe symptoms including suicidal ideation. In contrast, the majority of healthy mothers described childcare issues, such as questions about breastfeeding or sleeping, and reported no severe mental health concerns. Across the two digital platforms, we found that distressed mothers shared similar content. However, the patterns of speech and affect shared by distressed mothers differed between the helpline vs. the online forum, suggesting the design of these platforms may shape meaningful measures of their support-seeking experiences. Our results provide new insight into the experiences of caregivers suffering from postpartum mental health distress. We conclude by discussing methodological considerations for understanding content shared by support seekers and design considerations for the next generation of support tools for postpartum parents.
FaceFormer: Speech-Driven 3D Facial Animation with Transformers
Dec 28, 2021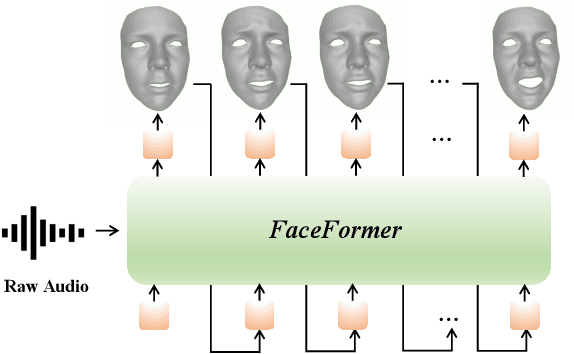
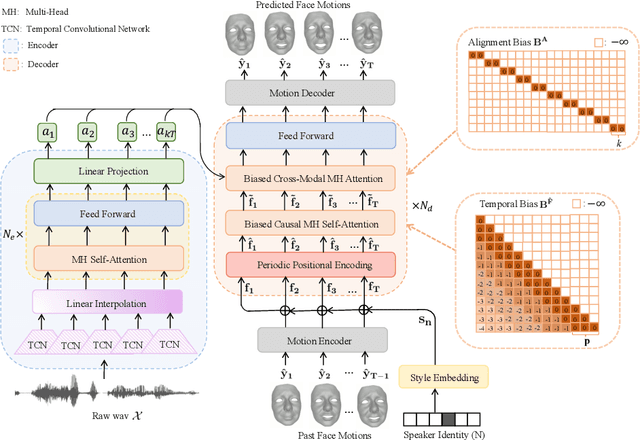

Speech-driven 3D facial animation is challenging due to the complex geometry of human faces and the limited availability of 3D audio-visual data. Prior works typically focus on learning phoneme-level features of short audio windows with limited context, occasionally resulting in inaccurate lip movements. To tackle this limitation, we propose a Transformer-based autoregressive model, FaceFormer, which encodes the long-term audio context and autoregressively predicts a sequence of animated 3D face meshes. To cope with the data scarcity issue, we integrate the self-supervised pre-trained speech representations. Also, we devise two biased attention mechanisms well suited to this specific task, including the biased cross-modal multi-head (MH) attention and the biased causal MH self-attention with a periodic positional encoding strategy. The former effectively aligns the audio-motion modalities, whereas the latter offers abilities to generalize to longer audio sequences. Extensive experiments and a perceptual user study show that our approach outperforms the existing state-of-the-arts. We encourage watching the video. The code will be made available.
Talking Head Generation with Audio and Speech Related Facial Action Units
Oct 19, 2021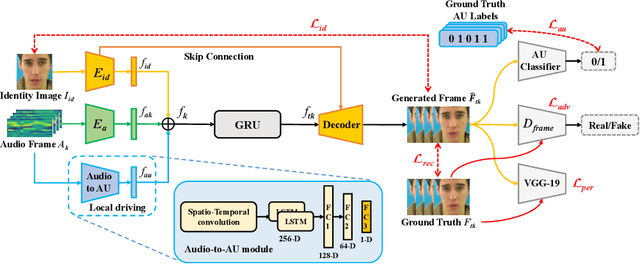
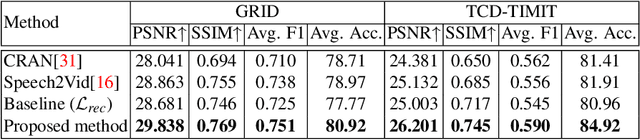


The task of talking head generation is to synthesize a lip synchronized talking head video by inputting an arbitrary face image and audio clips. Most existing methods ignore the local driving information of the mouth muscles. In this paper, we propose a novel recurrent generative network that uses both audio and speech-related facial action units (AUs) as the driving information. AU information related to the mouth can guide the movement of the mouth more accurately. Since speech is highly correlated with speech-related AUs, we propose an Audio-to-AU module in our system to predict the speech-related AU information from speech. In addition, we use AU classifier to ensure that the generated images contain correct AU information. Frame discriminator is also constructed for adversarial training to improve the realism of the generated face. We verify the effectiveness of our model on the GRID dataset and TCD-TIMIT dataset. We also conduct an ablation study to verify the contribution of each component in our model. Quantitative and qualitative experiments demonstrate that our method outperforms existing methods in both image quality and lip-sync accuracy.
WenetSpeech: A 10000+ Hours Multi-domain Mandarin Corpus for Speech Recognition
Oct 12, 2021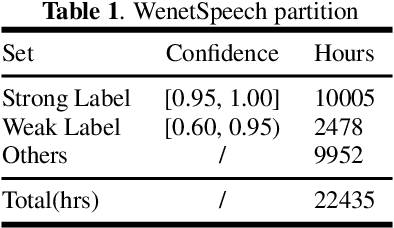

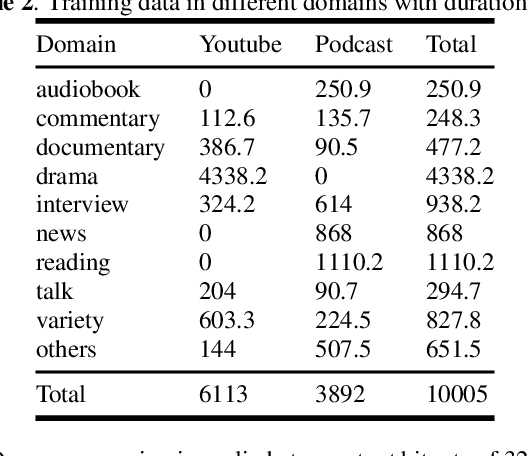
In this paper, we present WenetSpeech, a multi-domain Mandarin corpus consisting of 10000+ hours high-quality labeled speech, 2400+ hours weakly labeled speech, and about 10000 hours unlabeled speech, with 22400+ hours in total. We collect the data from YouTube and Podcast, which covers a variety of speaking styles, scenarios, domains, topics, and noisy conditions. An optical character recognition (OCR) based method is introduced to generate the audio/text segmentation candidates for the YouTube data on its corresponding video captions, while a high-quality ASR transcription system is used to generate audio/text pair candidates for the Podcast data. Then we propose a novel end-to-end label error detection approach to further validate and filter the candidates. We also provide three manually labelled high-quality test sets along with WenetSpeech for evaluation -- Dev for cross-validation purpose in training, Test_Net, collected from Internet for matched test, and Test\_Meeting, recorded from real meetings for more challenging mismatched test. Baseline systems trained with WenetSpeech are provided for three popular speech recognition toolkits, namely Kaldi, ESPnet, and WeNet, and recognition results on the three test sets are also provided as benchmarks. To the best of our knowledge, WenetSpeech is the current largest open-sourced Mandarin speech corpus with transcriptions, which benefits research on production-level speech recognition.
Universal Paralinguistic Speech Representations Using Self-Supervised Conformers
Oct 09, 2021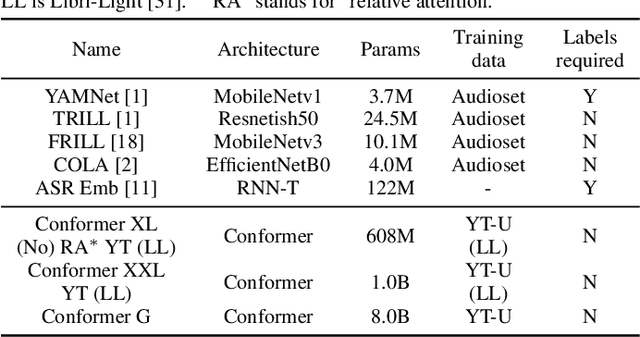
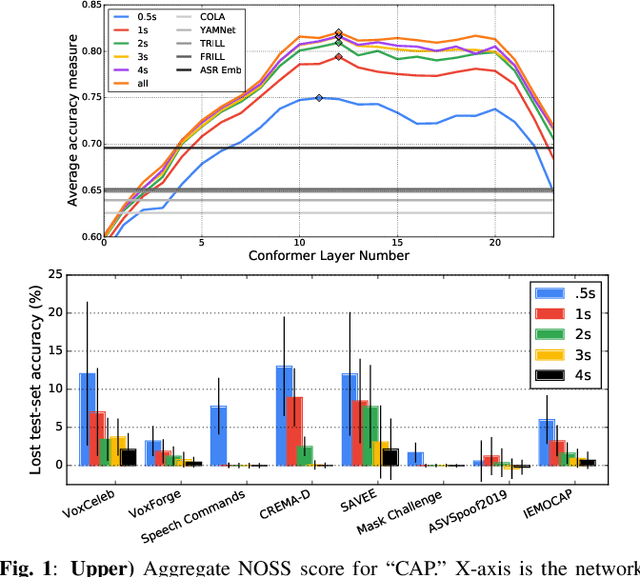
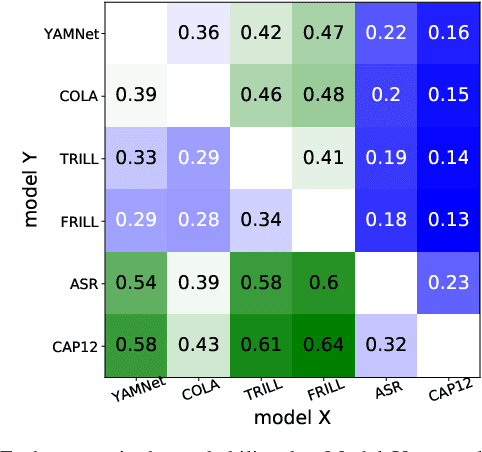
Many speech applications require understanding aspects beyond the words being spoken, such as recognizing emotion, detecting whether the speaker is wearing a mask, or distinguishing real from synthetic speech. In this work, we introduce a new state-of-the-art paralinguistic representation derived from large-scale, fully self-supervised training of a 600M+ parameter Conformer-based architecture. We benchmark on a diverse set of speech tasks and demonstrate that simple linear classifiers trained on top of our time-averaged representation outperform nearly all previous results, in some cases by large margins. Our analyses of context-window size demonstrate that, surprisingly, 2 second context-windows achieve 98% the performance of the Conformers that use the full long-term context. Furthermore, while the best per-task representations are extracted internally in the network, stable performance across several layers allows a single universal representation to reach near optimal performance on all tasks.
Building African Voices
Jul 01, 2022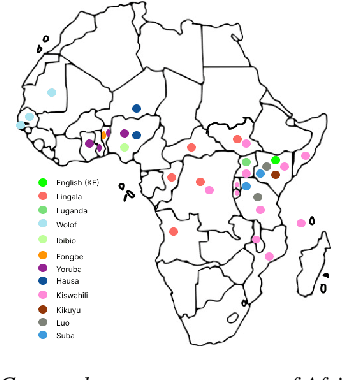
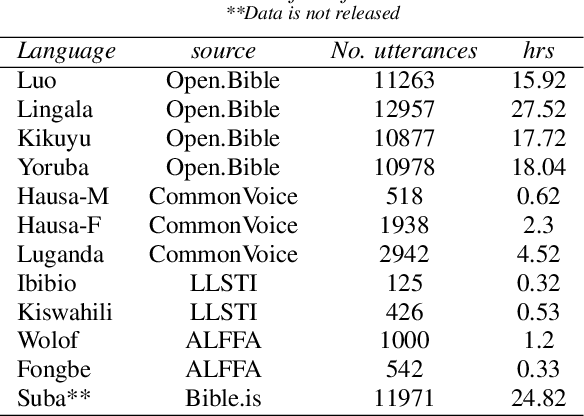
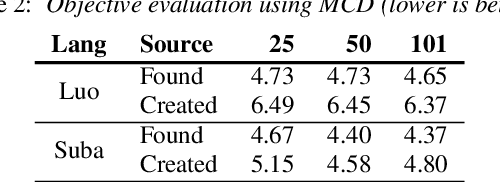
Modern speech synthesis techniques can produce natural-sounding speech given sufficient high-quality data and compute resources. However, such data is not readily available for many languages. This paper focuses on speech synthesis for low-resourced African languages, from corpus creation to sharing and deploying the Text-to-Speech (TTS) systems. We first create a set of general-purpose instructions on building speech synthesis systems with minimum technological resources and subject-matter expertise. Next, we create new datasets and curate datasets from "found" data (existing recordings) through a participatory approach while considering accessibility, quality, and breadth. We demonstrate that we can develop synthesizers that generate intelligible speech with 25 minutes of created speech, even when recorded in suboptimal environments. Finally, we release the speech data, code, and trained voices for 12 African languages to support researchers and developers.
Memories are One-to-Many Mapping Alleviators in Talking Face Generation
Dec 09, 2022
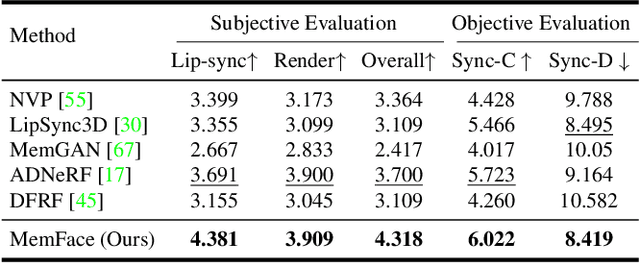
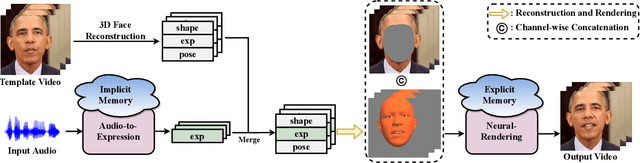
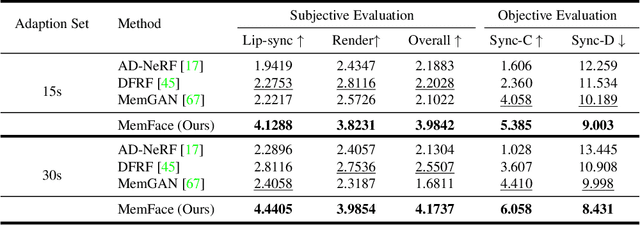
Talking face generation aims at generating photo-realistic video portraits of a target person driven by input audio. Due to its nature of one-to-many mapping from the input audio to the output video (e.g., one speech content may have multiple feasible visual appearances), learning a deterministic mapping like previous works brings ambiguity during training, and thus causes inferior visual results. Although this one-to-many mapping could be alleviated in part by a two-stage framework (i.e., an audio-to-expression model followed by a neural-rendering model), it is still insufficient since the prediction is produced without enough information (e.g., emotions, wrinkles, etc.). In this paper, we propose MemFace to complement the missing information with an implicit memory and an explicit memory that follow the sense of the two stages respectively. More specifically, the implicit memory is employed in the audio-to-expression model to capture high-level semantics in the audio-expression shared space, while the explicit memory is employed in the neural-rendering model to help synthesize pixel-level details. Our experimental results show that our proposed MemFace surpasses all the state-of-the-art results across multiple scenarios consistently and significantly.
End-to-End Multi-Person Audio/Visual Automatic Speech Recognition
May 11, 2022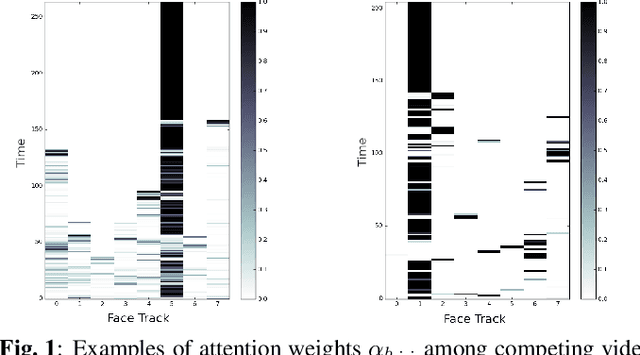

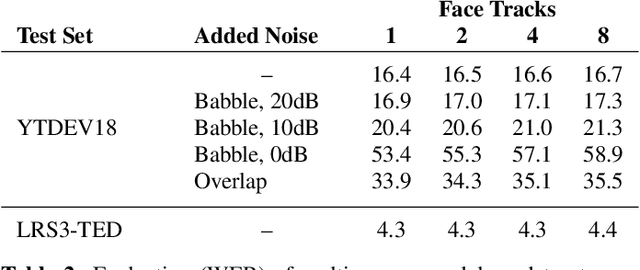
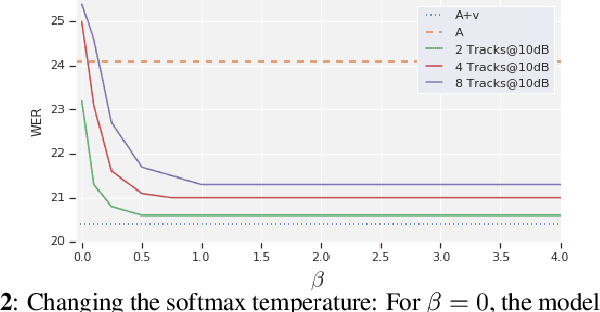
Traditionally, audio-visual automatic speech recognition has been studied under the assumption that the speaking face on the visual signal is the face matching the audio. However, in a more realistic setting, when multiple faces are potentially on screen one needs to decide which face to feed to the A/V ASR system. The present work takes the recent progress of A/V ASR one step further and considers the scenario where multiple people are simultaneously on screen (multi-person A/V ASR). We propose a fully differentiable A/V ASR model that is able to handle multiple face tracks in a video. Instead of relying on two separate models for speaker face selection and audio-visual ASR on a single face track, we introduce an attention layer to the ASR encoder that is able to soft-select the appropriate face video track. Experiments carried out on an A/V system trained on over 30k hours of YouTube videos illustrate that the proposed approach can automatically select the proper face tracks with minor WER degradation compared to an oracle selection of the speaking face while still showing benefits of employing the visual signal instead of the audio alone.
Towards Automatic Speech to Sign Language Generation
Jun 24, 2021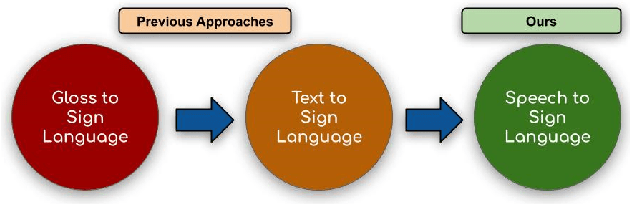
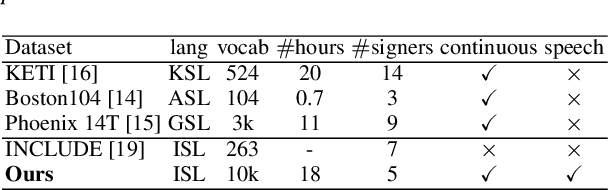

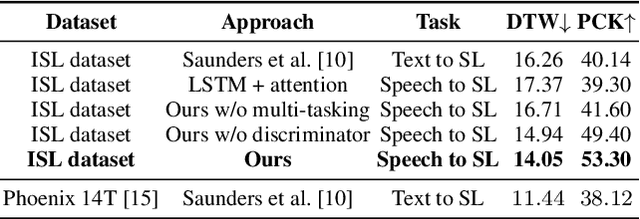
We aim to solve the highly challenging task of generating continuous sign language videos solely from speech segments for the first time. Recent efforts in this space have focused on generating such videos from human-annotated text transcripts without considering other modalities. However, replacing speech with sign language proves to be a practical solution while communicating with people suffering from hearing loss. Therefore, we eliminate the need of using text as input and design techniques that work for more natural, continuous, freely uttered speech covering an extensive vocabulary. Since the current datasets are inadequate for generating sign language directly from speech, we collect and release the first Indian sign language dataset comprising speech-level annotations, text transcripts, and the corresponding sign-language videos. Next, we propose a multi-tasking transformer network trained to generate signer's poses from speech segments. With speech-to-text as an auxiliary task and an additional cross-modal discriminator, our model learns to generate continuous sign pose sequences in an end-to-end manner. Extensive experiments and comparisons with other baselines demonstrate the effectiveness of our approach. We also conduct additional ablation studies to analyze the effect of different modules of our network. A demo video containing several results is attached to the supplementary material.
Zero-shot Speech Translation
Jul 13, 2021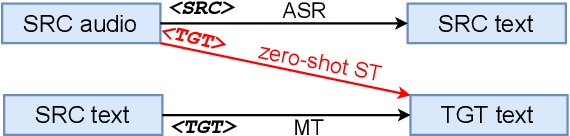
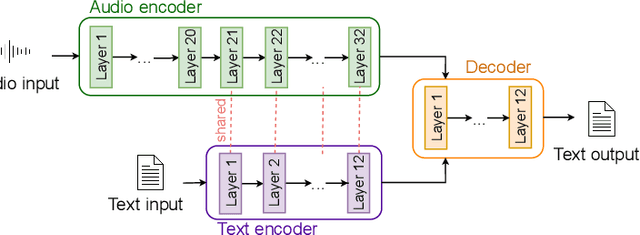

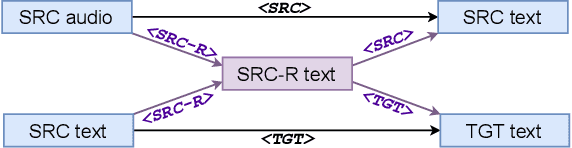
Speech Translation (ST) is the task of translating speech in one language into text in another language. Traditional cascaded approaches for ST, using Automatic Speech Recognition (ASR) and Machine Translation (MT) systems, are prone to error propagation. End-to-end approaches use only one system to avoid propagating error, yet are difficult to employ due to data scarcity. We explore zero-shot translation, which enables translating a pair of languages that is unseen during training, thus avoid the use of end-to-end ST data. Zero-shot translation has been shown to work for multilingual machine translation, yet has not been studied for speech translation. We attempt to build zero-shot ST models that are trained only on ASR and MT tasks but can do ST task during inference. The challenge is that the representation of text and audio is significantly different, thus the models learn ASR and MT tasks in different ways, making it non-trivial to perform zero-shot. These models tend to output the wrong language when performing zero-shot ST. We tackle the issues by including additional training data and an auxiliary loss function that minimizes the text-audio difference. Our experiment results and analysis show that the methods are promising for zero-shot ST. Moreover, our methods are particularly useful in the few-shot settings where a limited amount of ST data is available, with improvements of up to +11.8 BLEU points compared to direct end-to-end ST models and +3.9 BLEU points compared to ST models fine-tuned from pre-trained ASR model.