 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Implicit Acoustic Echo Cancellation for Keyword Spotting and Device-Directed Speech Detection
Nov 20, 2021
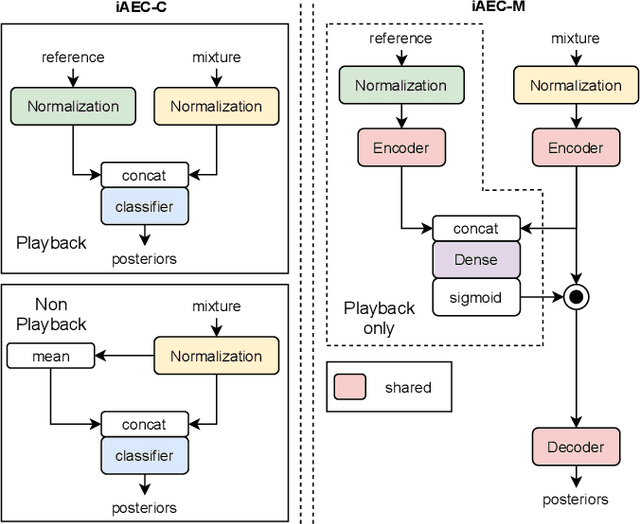
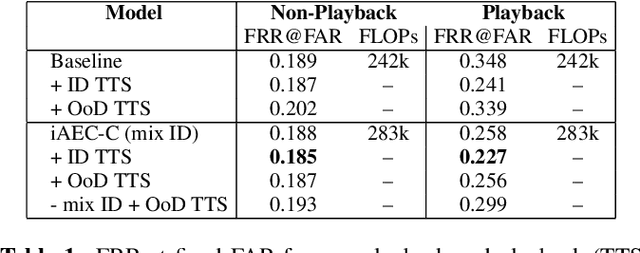
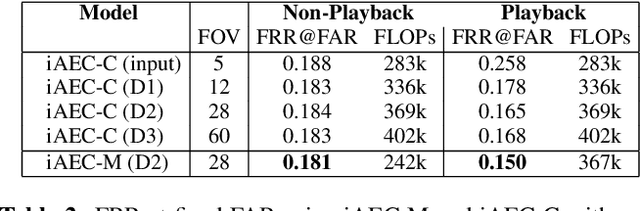
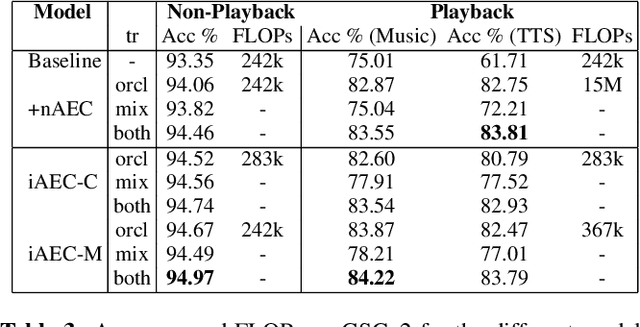
In many speech-enabled human-machine interaction scenarios, user speech can overlap with the device playback audio. In these instances, the performance of tasks such as keyword-spotting (KWS) and device-directed speech detection (DDD) can degrade significantly. To address this problem, we propose an implicit acoustic echo cancellation (iAEC) framework where a neural network is trained to exploit the additional information from a reference microphone channel to learn to ignore the interfering signal and improve detection performance. We study this framework for the tasks of KWS and DDD on, respectively, an augmented version of Google Speech Commands v2 and a real-world Alexa device dataset. Notably, we show a $56\%$ reduction in false-reject rate for the DDD task during device playback conditions. We also show comparable or superior performance over a strong end-to-end neural echo cancellation + KWS baseline for the KWS task with an order of magnitude less computational requirements.
Cross-Speaker Emotion Transfer for Low-Resource Text-to-Speech Using Non-Parallel Voice Conversion with Pitch-Shift Data Augmentation
Apr 21, 2022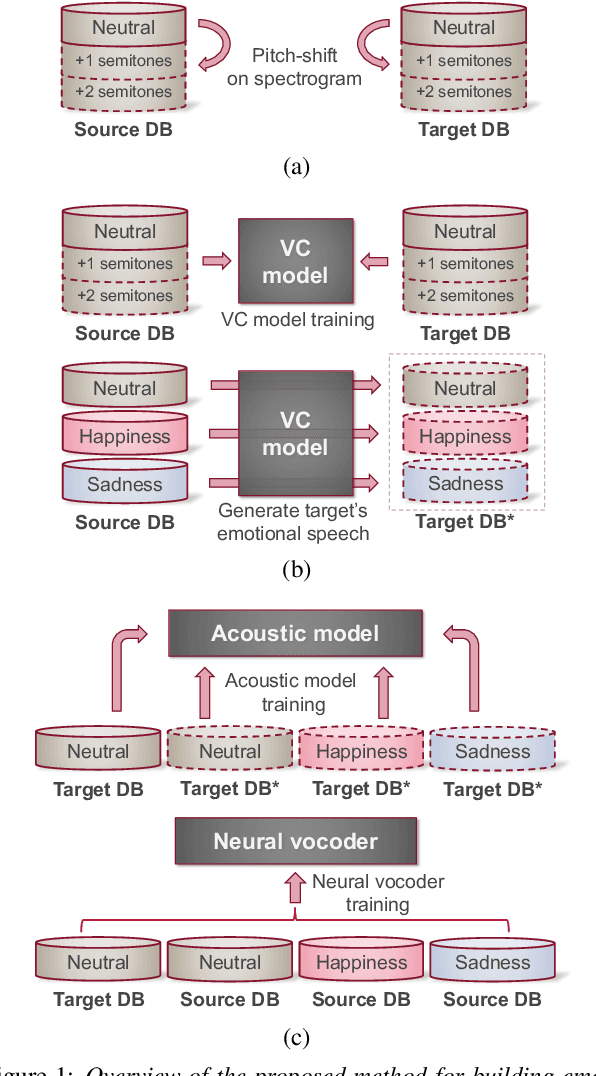
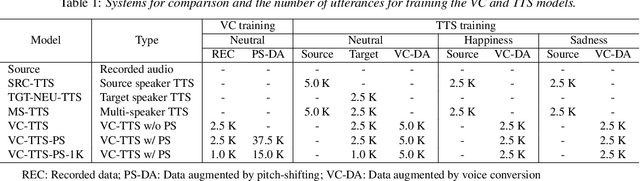
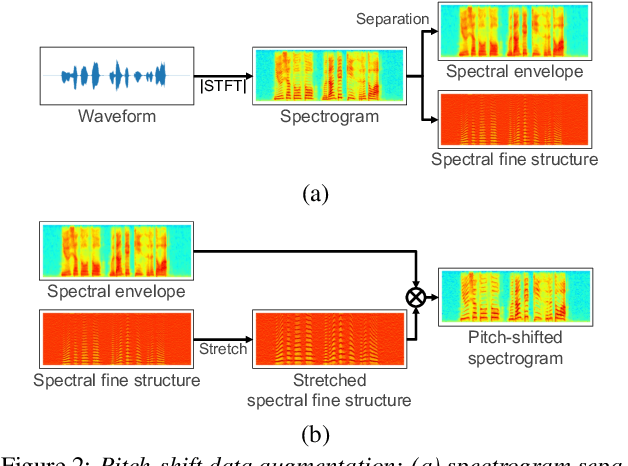
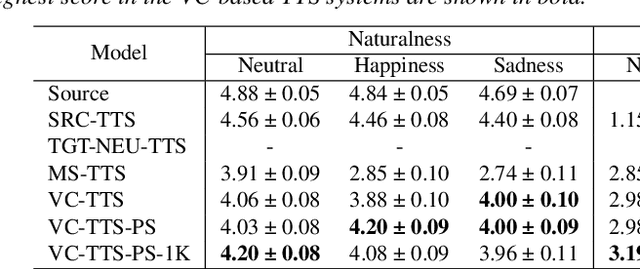
Data augmentation via voice conversion (VC) has been successfully applied to low-resource expressive text-to-speech (TTS) when only neutral data for the target speaker are available. Although the quality of VC is crucial for this approach, it is challenging to learn a stable VC model because the amount of data is limited in low-resource scenarios, and highly expressive speech has large acoustic variety. To address this issue, we propose a novel data augmentation method that combines pitch-shifting and VC techniques. Because pitch-shift data augmentation enables the coverage of a variety of pitch dynamics, it greatly stabilizes training for both VC and TTS models, even when only 1,000 utterances of the target speaker's neutral data are available. Subjective test results showed that a FastSpeech 2-based emotional TTS system with the proposed method improved naturalness and emotional similarity compared with conventional methods.
Mixed Emotion Modelling for Emotional Voice Conversion
Oct 26, 2022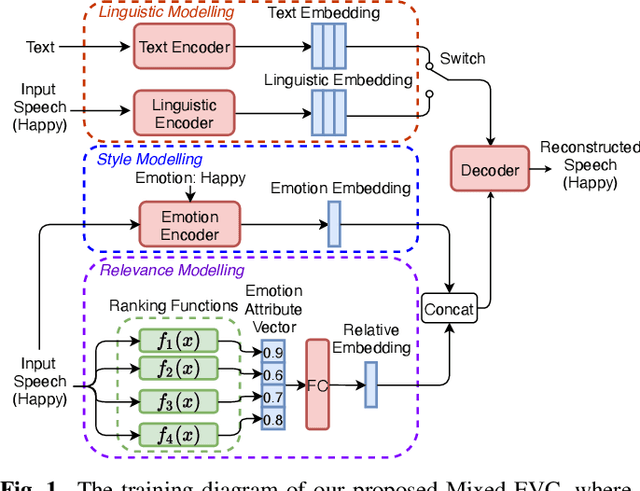
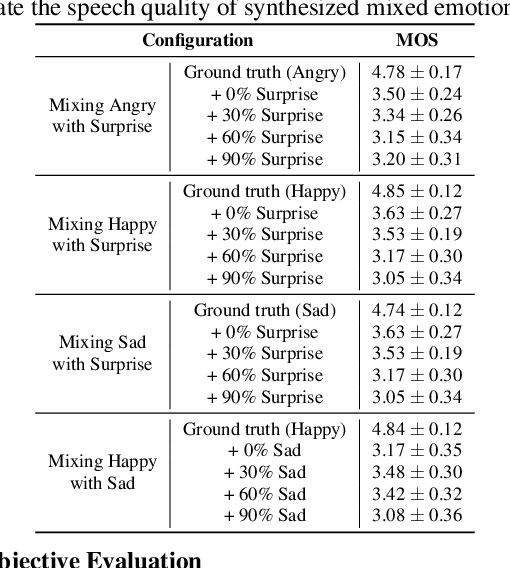
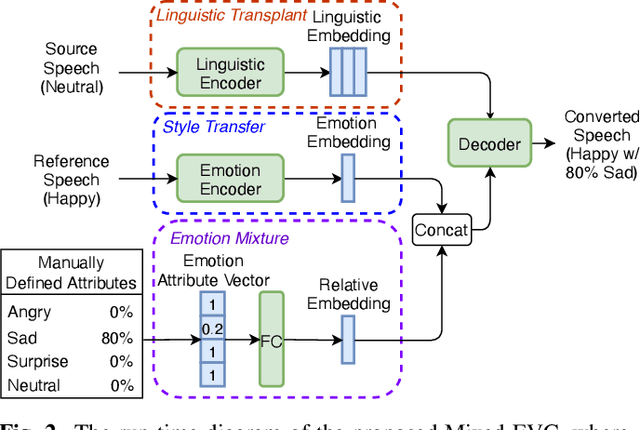

Emotional voice conversion (EVC) aims to convert the emotional state of an utterance from one emotion to another while preserving the linguistic content and speaker identity. Current studies mostly focus on modelling the conversion between several specific emotion types. Synthesizing mixed effects of emotions could help us to better imitate human emotions, and facilitate more natural human-computer interaction. In this research, for the first time, we formulate and study the research problem of mixed emotion synthesis for EVC. We regard emotional styles as a series of emotion attributes that are learnt from a ranking-based support vector machine (SVM). Each attribute measures the degree of the relevance between the speech recordings belonging to different emotion types. We then incorporate those attributes into a sequence-to-sequence (seq2seq) emotional voice conversion framework. During the training, the framework not only learns to characterize the input emotional style, but also quantifies its relevance with other emotion types. At run-time, various emotional mixtures can be produced by manually defining the attributes. We conduct objective and subjective evaluations to validate our idea in terms of mixed emotion synthesis. We further build an emotion triangle as an application of emotion transition. Codes and speech samples are publicly available.
Automatic Speech Recognition Datasets in Cantonese Language: A Survey and a New Dataset
Jan 07, 2022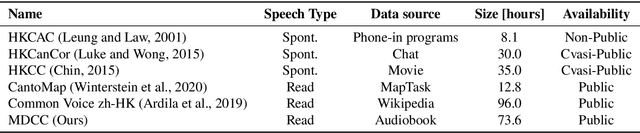
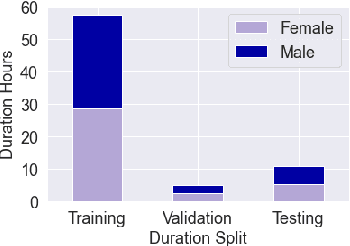
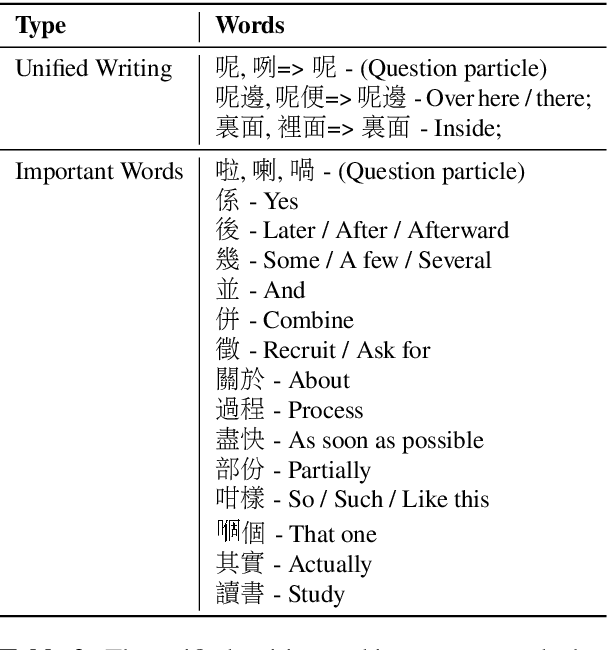
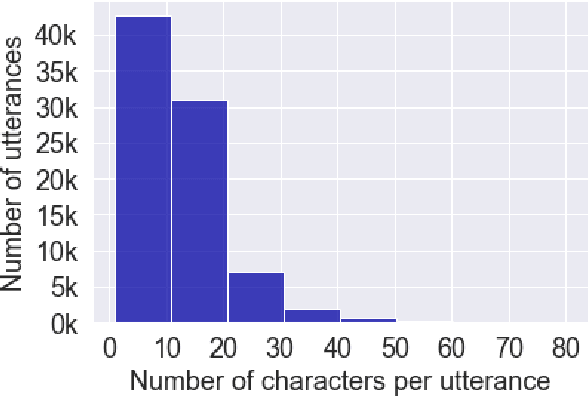
Automatic speech recognition (ASR) on low resource languages improves access of linguistic minorities to technological advantages provided by Artificial Intelligence (AI). In this paper, we address a problem of data scarcity of Hong Kong Cantonese language by creating a new Cantonese dataset. Our dataset, Multi-Domain Cantonese Corpus (MDCC), consists of 73.6 hours of clean read speech paired with transcripts, collected from Cantonese audiobooks from Hong Kong. It combines philosophy, politics, education, culture, lifestyle and family domains, covering a wide range of topics. We also review all existing Cantonese datasets and perform experiments on the two biggest datasets (MDCC and Common Voice zh-HK). We analyze the existing datasets according to their speech type, data source, total size and availability. The results of experiments conducted with Fairseq S2T Transformer, a state-of-the-art ASR model, show the effectiveness of our dataset. In addition, we create a powerful and robust Cantonese ASR model by applying multi-dataset learning on MDCC and Common Voice zh-HK.
RT-1: Robotics Transformer for Real-World Control at Scale
Dec 13, 2022



By transferring knowledge from large, diverse, task-agnostic datasets, modern machine learning models can solve specific downstream tasks either zero-shot or with small task-specific datasets to a high level of performance. While this capability has been demonstrated in other fields such as computer vision, natural language processing or speech recognition, it remains to be shown in robotics, where the generalization capabilities of the models are particularly critical due to the difficulty of collecting real-world robotic data. We argue that one of the keys to the success of such general robotic models lies with open-ended task-agnostic training, combined with high-capacity architectures that can absorb all of the diverse, robotic data. In this paper, we present a model class, dubbed Robotics Transformer, that exhibits promising scalable model properties. We verify our conclusions in a study of different model classes and their ability to generalize as a function of the data size, model size, and data diversity based on a large-scale data collection on real robots performing real-world tasks. The project's website and videos can be found at robotics-transformer.github.io
Musical Speech: A Transformer-based Composition Tool
Aug 02, 2021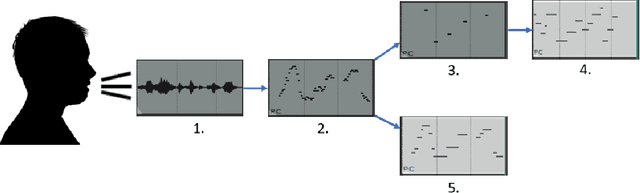
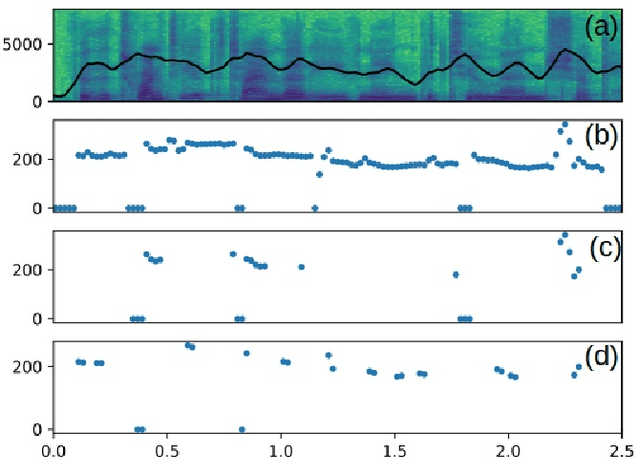
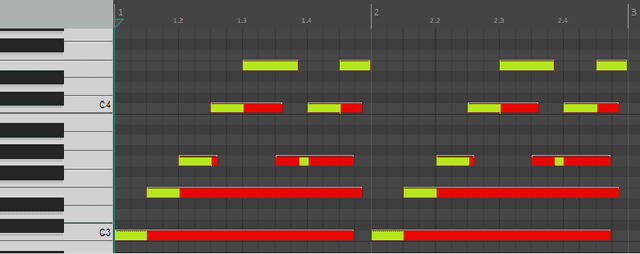
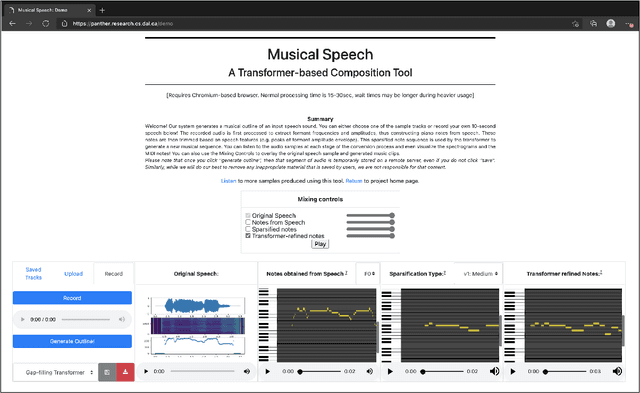
In this paper, we propose a new compositional tool that will generate a musical outline of speech recorded/provided by the user for use as a musical building block in their compositions. The tool allows any user to use their own speech to generate musical material, while still being able to hear the direct connection between their recorded speech and the resulting music. The tool is built on our proposed pipeline. This pipeline begins with speech-based signal processing, after which some simple musical heuristics are applied, and finally these pre-processed signals are passed through Transformer models trained on new musical tasks. We illustrate the effectiveness of our pipeline -- which does not require a paired dataset for training -- through examples of music created by musicians making use of our tool.
Fusing ASR Outputs in Joint Training for Speech Emotion Recognition
Oct 29, 2021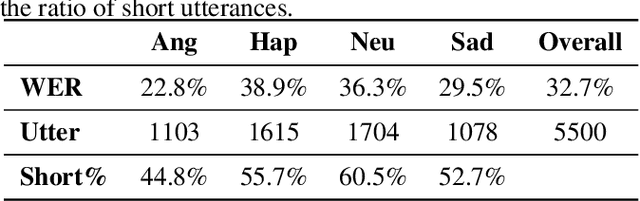
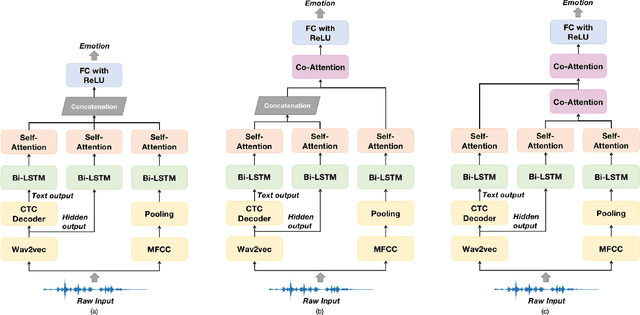
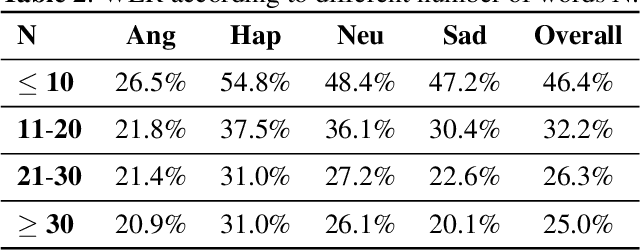

Alongside acoustic information, linguistic features based on speech transcripts have been proven useful in Speech Emotion Recognition (SER). However, due to the scarcity of emotion labelled data and the difficulty of recognizing emotional speech, it is hard to obtain reliable linguistic features and models in this research area. In this paper, we propose to fuse Automatic Speech Recognition (ASR) outputs into the pipeline for joint training SER. The relationship between ASR and SER is understudied, and it is unclear what and how ASR features benefit SER. By examining various ASR outputs and fusion methods, our experiments show that in joint ASR-SER training, incorporating both ASR hidden and text output using a hierarchical co-attention fusion approach improves the SER performance the most. On the IEMOCAP corpus, our approach achieves 63.4% weighted accuracy, which is close to the baseline results achieved by combining ground-truth transcripts. In addition, we also present novel word error rate analysis on IEMOCAP and layer-difference analysis of the Wav2vec 2.0 model to better understand the relationship between ASR and SER.
DPCCN: Densely-Connected Pyramid Complex Convolutional Network for Robust Speech Separation And Extraction
Dec 27, 2021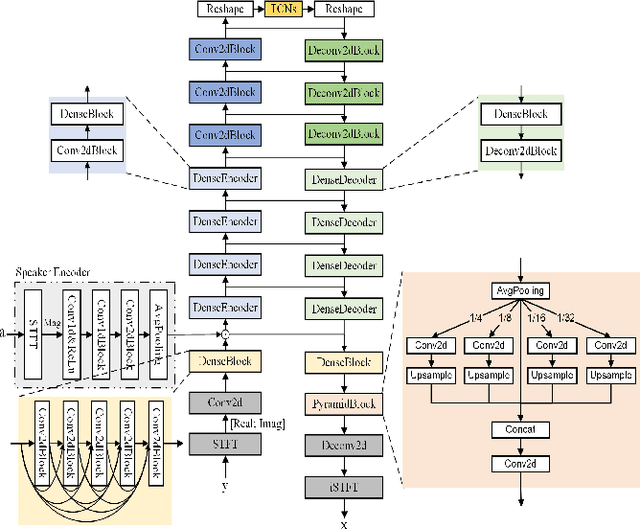
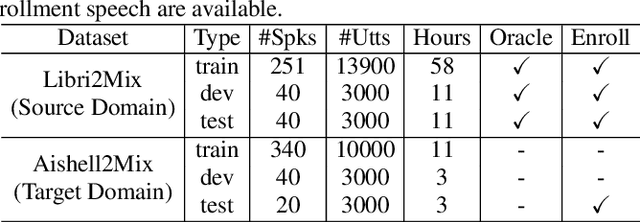
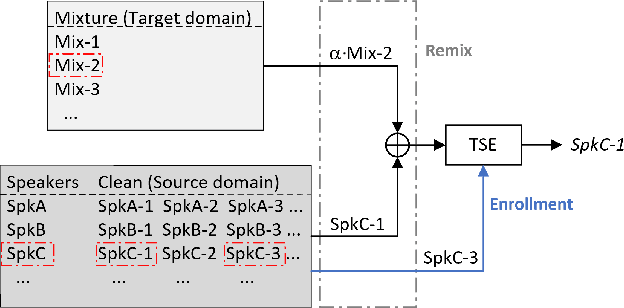

In recent years, a number of time-domain speech separation methods have been proposed. However, most of them are very sensitive to the environments and wide domain coverage tasks. In this paper, from the time-frequency domain perspective, we propose a densely-connected pyramid complex convolutional network, termed DPCCN, to improve the robustness of speech separation under complicated conditions. Furthermore, we generalize the DPCCN to target speech extraction (TSE) by integrating a new specially designed speaker encoder. Moreover, we also investigate the robustness of DPCCN to unsupervised cross-domain TSE tasks. A Mixture-Remix approach is proposed to adapt the target domain acoustic characteristics for fine-tuning the source model. We evaluate the proposed methods not only under noisy and reverberant in-domain condition, but also in clean but cross-domain conditions. Results show that for both speech separation and extraction, the DPCCN-based systems achieve significantly better performance and robustness than the currently dominating time-domain methods, especially for the cross-domain tasks. Particularly, we find that the Mixture-Remix fine-tuning with DPCCN significantly outperforms the TD-SpeakerBeam for unsupervised cross-domain TSE, with around 3.5 dB performance improvement on target domain test set, without any source domain performance degradation.
Pseudo-Labeling for Massively Multilingual Speech Recognition
Oct 30, 2021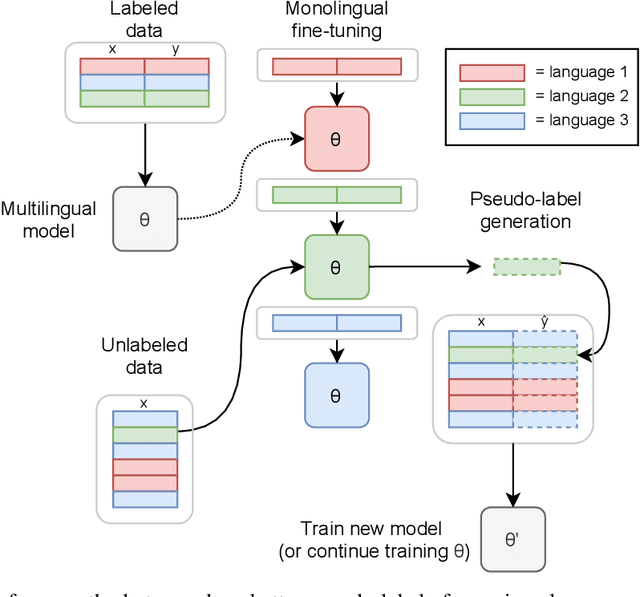
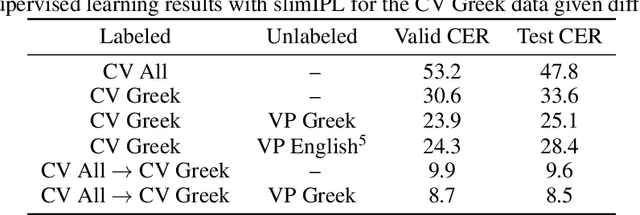
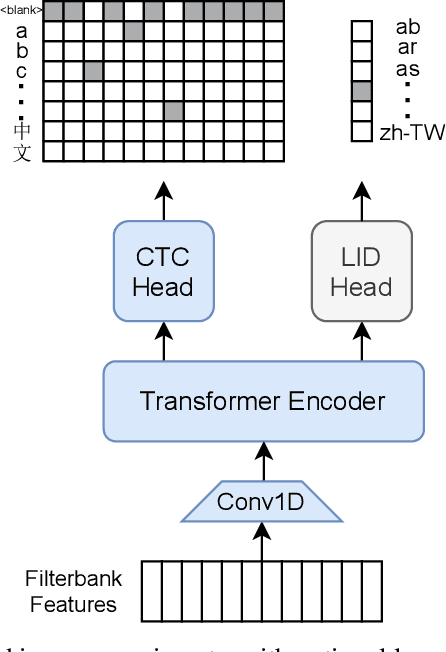
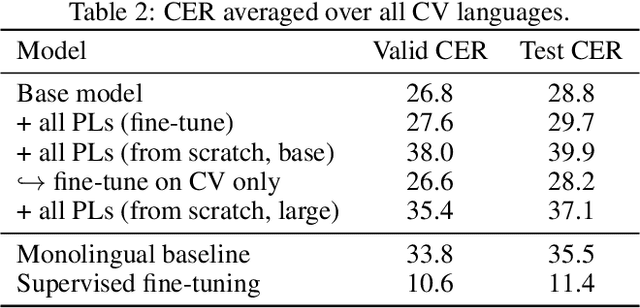
Semi-supervised learning through pseudo-labeling has become a staple of state-of-the-art monolingual speech recognition systems. In this work, we extend pseudo-labeling to massively multilingual speech recognition with 60 languages. We propose a simple pseudo-labeling recipe that works well even with low-resource languages: train a supervised multilingual model, fine-tune it with semi-supervised learning on a target language, generate pseudo-labels for that language, and train a final model using pseudo-labels for all languages, either from scratch or by fine-tuning. Experiments on the labeled Common Voice and unlabeled VoxPopuli datasets show that our recipe can yield a model with better performance for many languages that also transfers well to LibriSpeech.
Improvements to Embedding-Matching Acoustic-to-Word ASR Using Multiple-Hypothesis Pronunciation-Based Embeddings
Oct 30, 2022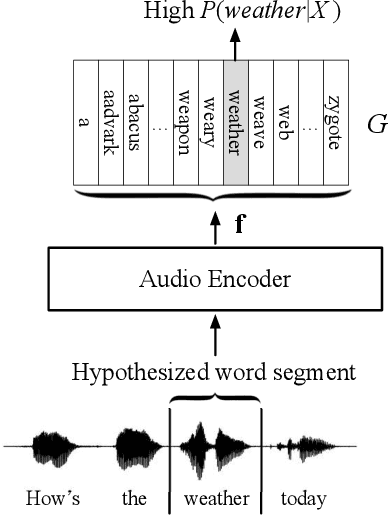
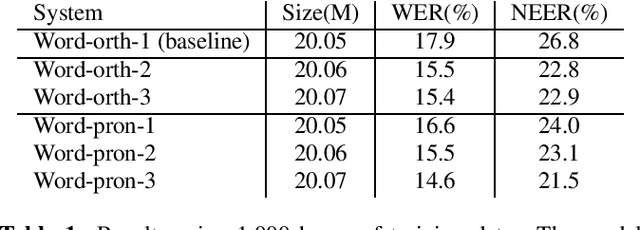
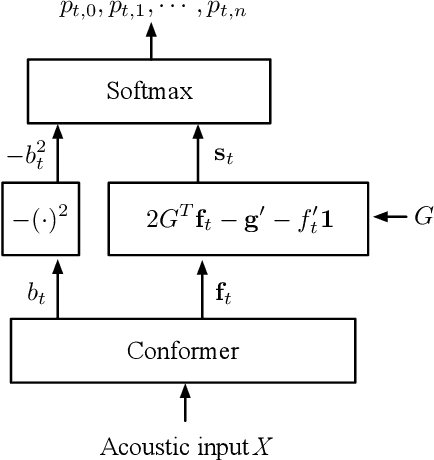
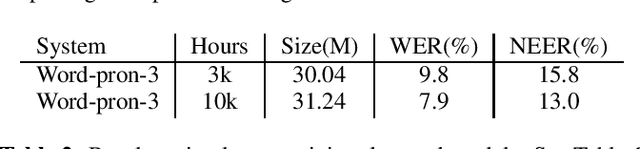
In embedding-matching acoustic-to-word (A2W) ASR, every word in the vocabulary is represented by a fixed-dimension embedding vector that can be added or removed independently of the rest of the system. The approach is potentially an elegant solution for the dynamic out-of-vocabulary (OOV) words problem, where speaker- and context-dependent named entities like contact names must be incorporated into the ASR on-the-fly for every speech utterance at testing time. Challenges still remain, however, in improving the overall accuracy of embedding-matching A2W. In this paper, we contribute two methods that improve the accuracy of embedding-matching A2W. First, we propose internally producing multiple embeddings, instead of a single embedding, at each instance in time, which allows the A2W model to propose a richer set of hypotheses over multiple time segments in the audio. Second, we propose using word pronunciation embeddings rather than word orthography embeddings to reduce ambiguities introduced by words that have more than one sound. We show that the above ideas give significant accuracy improvement, with the same training data and nearly identical model size, in scenarios where dynamic OOV words play a crucial role. On a dataset of various queries to a speech-based digital assistant that include many user-dependent contact names, we observe up to 18% decrease in word error rate using the proposed improvements.