 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Robotic Speech Synthesis: Perspectives on Interactions, Scenarios, and Ethics
Mar 17, 2022
In recent years, many works have investigated the feasibility of conversational robots for performing specific tasks, such as healthcare and interview. Along with this development comes a practical issue: how should we synthesize robotic voices to meet the needs of different situations? In this paper, we discuss this issue from three perspectives: 1) the difficulties of synthesizing non-verbal and interaction-oriented speech signals, particularly backchannels; 2) the scenario classification for robotic voice synthesis; 3) the ethical issues regarding the design of robot voice for its emotion and identity. We present the findings of relevant literature and our prior work, trying to bring the attention of human-robot interaction researchers to design better conversational robots in the future.
Listen, Adapt, Better WER: Source-free Single-utterance Test-time Adaptation for Automatic Speech Recognition
Mar 27, 2022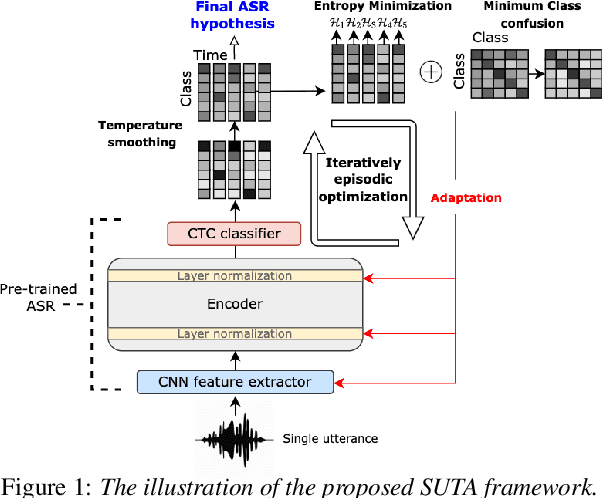

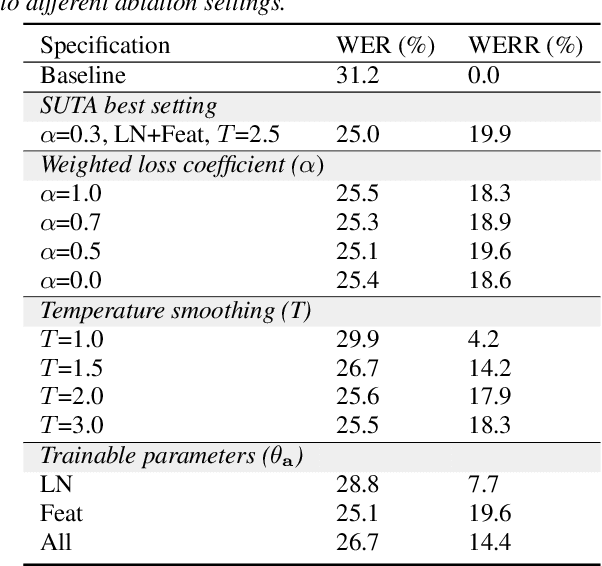
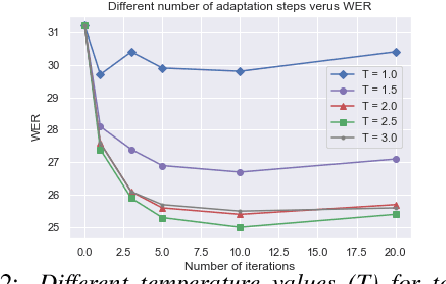
Although deep learning-based end-to-end Automatic Speech Recognition (ASR) has shown remarkable performance in recent years, it suffers severe performance regression on test samples drawn from different data distributions. Test-time Adaptation (TTA), previously explored in the computer vision area, aims to adapt the model trained on source domains to yield better predictions for test samples, often out-of-domain, without accessing the source data. Here, we propose the Single-Utterance Test-time Adaptation (SUTA) framework for ASR, which is the first TTA study in speech area to our best knowledge. The single-utterance TTA is a more realistic setting that does not assume test data are sampled from identical distribution and does not delay on-demand inference due to pre-collection for the batch of adaptation data. SUTA consists of unsupervised objectives with an efficient adaptation strategy. The empirical results demonstrate that SUTA effectively improves the performance of the source ASR model evaluated on multiple out-of-domain target corpora and in-domain test samples.
DPCCN: Densely-Connected Pyramid Complex Convolutional Network for Robust Speech Separation And Extraction
Dec 27, 2021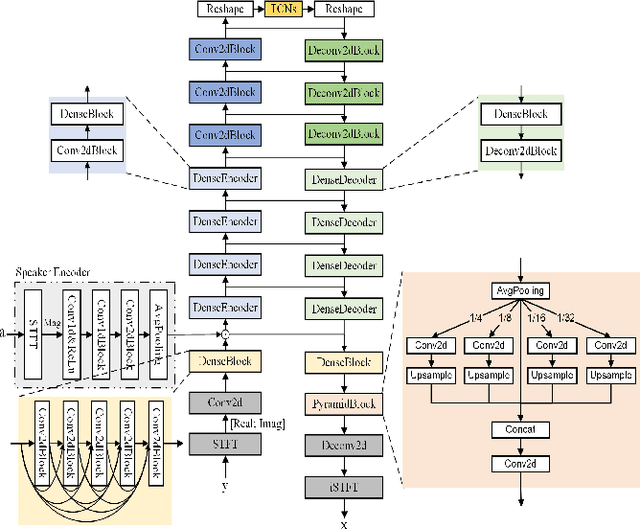
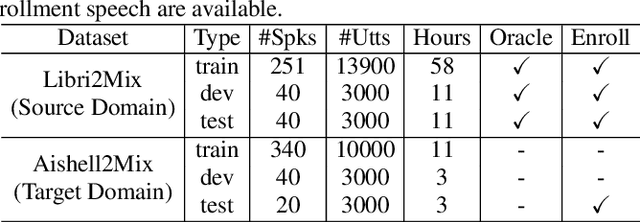
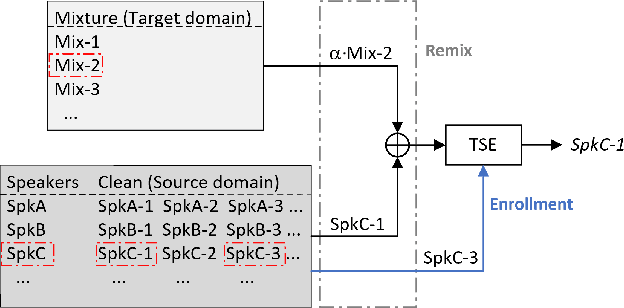

In recent years, a number of time-domain speech separation methods have been proposed. However, most of them are very sensitive to the environments and wide domain coverage tasks. In this paper, from the time-frequency domain perspective, we propose a densely-connected pyramid complex convolutional network, termed DPCCN, to improve the robustness of speech separation under complicated conditions. Furthermore, we generalize the DPCCN to target speech extraction (TSE) by integrating a new specially designed speaker encoder. Moreover, we also investigate the robustness of DPCCN to unsupervised cross-domain TSE tasks. A Mixture-Remix approach is proposed to adapt the target domain acoustic characteristics for fine-tuning the source model. We evaluate the proposed methods not only under noisy and reverberant in-domain condition, but also in clean but cross-domain conditions. Results show that for both speech separation and extraction, the DPCCN-based systems achieve significantly better performance and robustness than the currently dominating time-domain methods, especially for the cross-domain tasks. Particularly, we find that the Mixture-Remix fine-tuning with DPCCN significantly outperforms the TD-SpeakerBeam for unsupervised cross-domain TSE, with around 3.5 dB performance improvement on target domain test set, without any source domain performance degradation.
Progressive Disentangled Representation Learning for Fine-Grained Controllable Talking Head Synthesis
Nov 26, 2022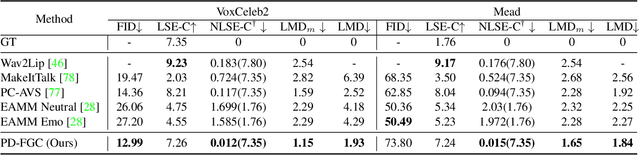
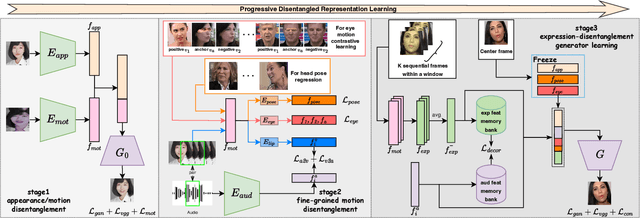
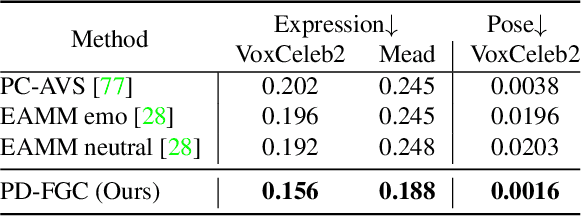

We present a novel one-shot talking head synthesis method that achieves disentangled and fine-grained control over lip motion, eye gaze&blink, head pose, and emotional expression. We represent different motions via disentangled latent representations and leverage an image generator to synthesize talking heads from them. To effectively disentangle each motion factor, we propose a progressive disentangled representation learning strategy by separating the factors in a coarse-to-fine manner, where we first extract unified motion feature from the driving signal, and then isolate each fine-grained motion from the unified feature. We introduce motion-specific contrastive learning and regressing for non-emotional motions, and feature-level decorrelation and self-reconstruction for emotional expression, to fully utilize the inherent properties of each motion factor in unstructured video data to achieve disentanglement. Experiments show that our method provides high quality speech&lip-motion synchronization along with precise and disentangled control over multiple extra facial motions, which can hardly be achieved by previous methods.
AudioLM: a Language Modeling Approach to Audio Generation
Sep 07, 2022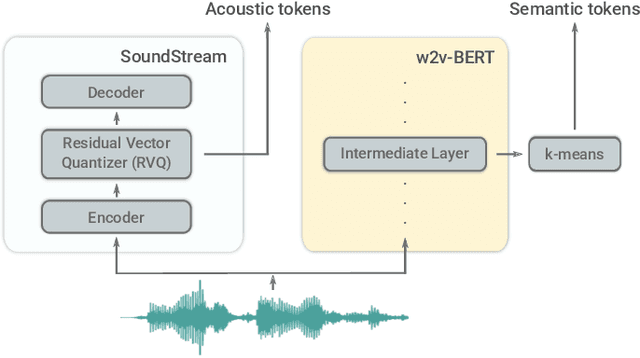

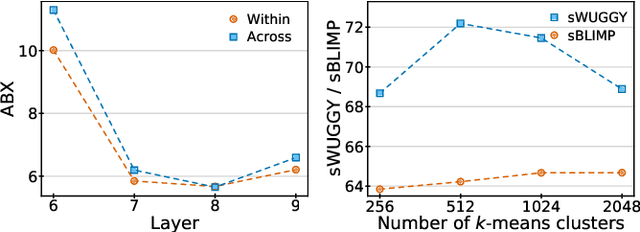

We introduce AudioLM, a framework for high-quality audio generation with long-term consistency. AudioLM maps the input audio to a sequence of discrete tokens and casts audio generation as a language modeling task in this representation space. We show how existing audio tokenizers provide different trade-offs between reconstruction quality and long-term structure, and we propose a hybrid tokenization scheme to achieve both objectives. Namely, we leverage the discretized activations of a masked language model pre-trained on audio to capture long-term structure and the discrete codes produced by a neural audio codec to achieve high-quality synthesis. By training on large corpora of raw audio waveforms, AudioLM learns to generate natural and coherent continuations given short prompts. When trained on speech, and without any transcript or annotation, AudioLM generates syntactically and semantically plausible speech continuations while also maintaining speaker identity and prosody for unseen speakers. Furthermore, we demonstrate how our approach extends beyond speech by generating coherent piano music continuations, despite being trained without any symbolic representation of music.
Fusing ASR Outputs in Joint Training for Speech Emotion Recognition
Oct 29, 2021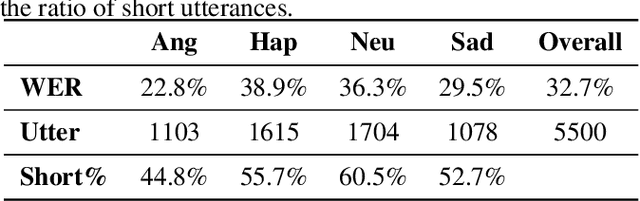
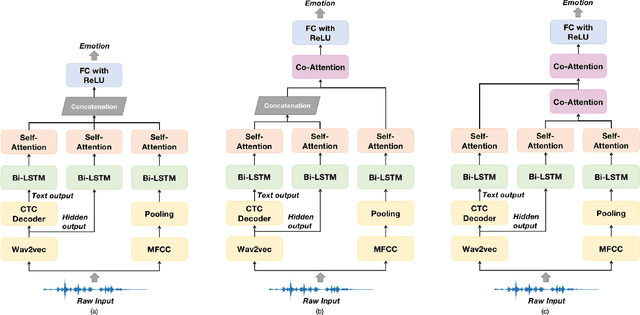
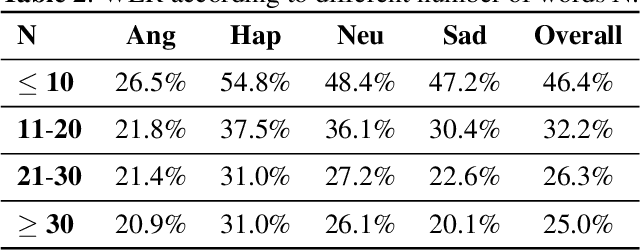

Alongside acoustic information, linguistic features based on speech transcripts have been proven useful in Speech Emotion Recognition (SER). However, due to the scarcity of emotion labelled data and the difficulty of recognizing emotional speech, it is hard to obtain reliable linguistic features and models in this research area. In this paper, we propose to fuse Automatic Speech Recognition (ASR) outputs into the pipeline for joint training SER. The relationship between ASR and SER is understudied, and it is unclear what and how ASR features benefit SER. By examining various ASR outputs and fusion methods, our experiments show that in joint ASR-SER training, incorporating both ASR hidden and text output using a hierarchical co-attention fusion approach improves the SER performance the most. On the IEMOCAP corpus, our approach achieves 63.4% weighted accuracy, which is close to the baseline results achieved by combining ground-truth transcripts. In addition, we also present novel word error rate analysis on IEMOCAP and layer-difference analysis of the Wav2vec 2.0 model to better understand the relationship between ASR and SER.
ASRPU: A Programmable Accelerator for Low-Power Automatic Speech Recognition
Feb 10, 2022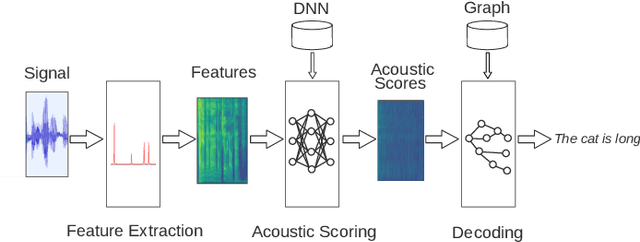

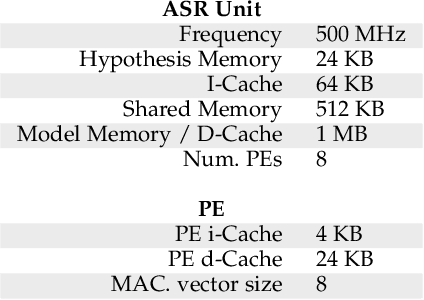
The outstanding accuracy achieved by modern Automatic Speech Recognition (ASR) systems is enabling them to quickly become a mainstream technology. ASR is essential for many applications, such as speech-based assistants, dictation systems and real-time language translation. However, highly accurate ASR systems are computationally expensive, requiring on the order of billions of arithmetic operations to decode each second of audio, which conflicts with a growing interest in deploying ASR on edge devices. On these devices, hardware acceleration is key for achieving acceptable performance. However, ASR is a rich and fast-changing field, and thus, any overly specialized hardware accelerator may quickly become obsolete. In this paper, we tackle those challenges by proposing ASRPU, a programmable accelerator for on-edge ASR. ASRPU contains a pool of general-purpose cores that execute small pieces of parallel code. Each of these programs computes one part of the overall decoder (e.g. a layer in a neural network). The accelerator automates some carefully chosen parts of the decoder to simplify the programming without sacrificing generality. We provide an analysis of a modern ASR system implemented on ASRPU and show that this architecture can achieve real-time decoding with a very low power budget.
Building African Voices
Jul 01, 2022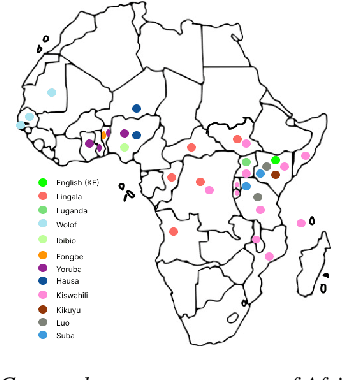
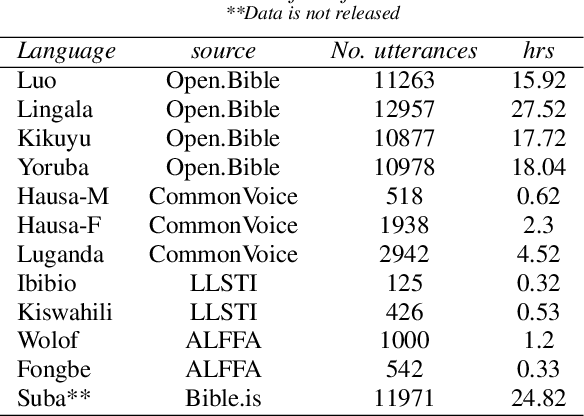
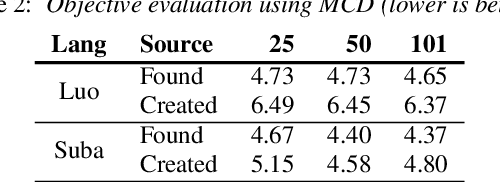
Modern speech synthesis techniques can produce natural-sounding speech given sufficient high-quality data and compute resources. However, such data is not readily available for many languages. This paper focuses on speech synthesis for low-resourced African languages, from corpus creation to sharing and deploying the Text-to-Speech (TTS) systems. We first create a set of general-purpose instructions on building speech synthesis systems with minimum technological resources and subject-matter expertise. Next, we create new datasets and curate datasets from "found" data (existing recordings) through a participatory approach while considering accessibility, quality, and breadth. We demonstrate that we can develop synthesizers that generate intelligible speech with 25 minutes of created speech, even when recorded in suboptimal environments. Finally, we release the speech data, code, and trained voices for 12 African languages to support researchers and developers.
Mono vs Multilingual BERT for Hate Speech Detection and Text Classification: A Case Study in Marathi
Apr 19, 2022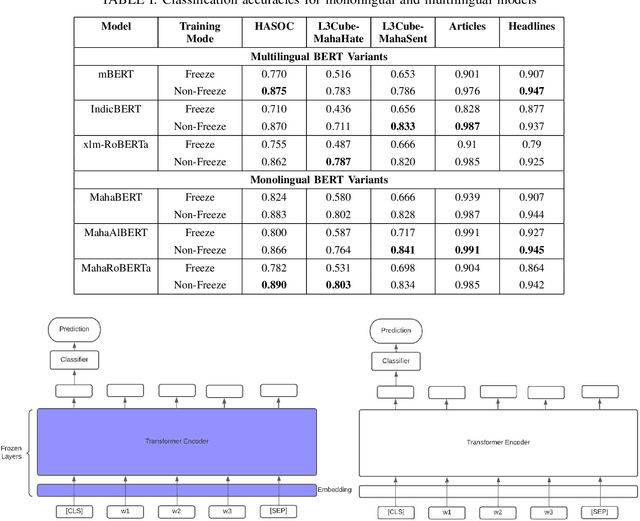
Transformers are the most eminent architectures used for a vast range of Natural Language Processing tasks. These models are pre-trained over a large text corpus and are meant to serve state-of-the-art results over tasks like text classification. In this work, we conduct a comparative study between monolingual and multilingual BERT models. We focus on the Marathi language and evaluate the models on the datasets for hate speech detection, sentiment analysis and simple text classification in Marathi. We use standard multilingual models such as mBERT, indicBERT and xlm-RoBERTa and compare with MahaBERT, MahaALBERT and MahaRoBERTa, the monolingual models for Marathi. We further show that Marathi monolingual models outperform the multilingual BERT variants on five different downstream fine-tuning experiments. We also evaluate sentence embeddings from these models by freezing the BERT encoder layers. We show that monolingual MahaBERT based models provide rich representations as compared to sentence embeddings from multi-lingual counterparts. However, we observe that these embeddings are not generic enough and do not work well on out of domain social media datasets. We consider two Marathi hate speech datasets L3Cube-MahaHate, HASOC-2021, a Marathi sentiment classification dataset L3Cube-MahaSent, and Marathi Headline, Articles classification datasets.
Pseudo-Labeling for Massively Multilingual Speech Recognition
Oct 30, 2021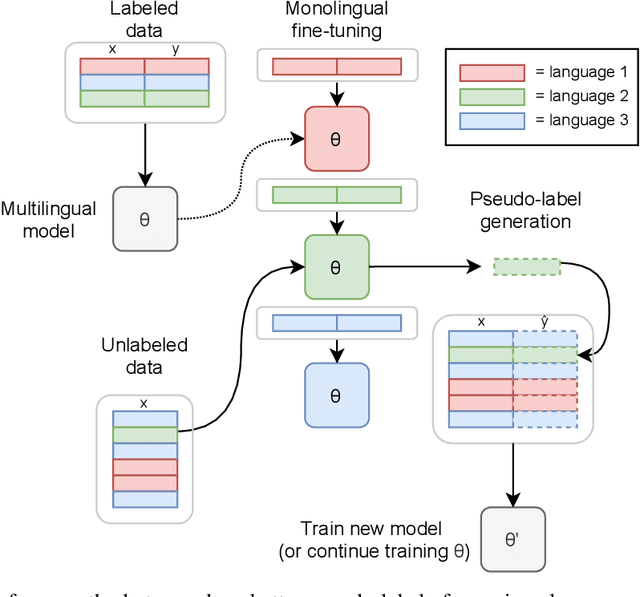
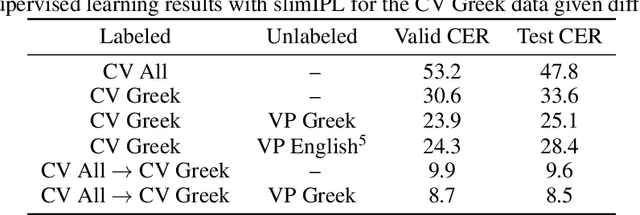
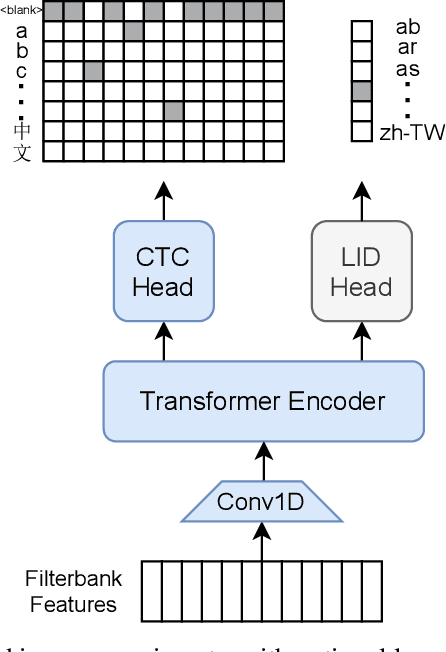
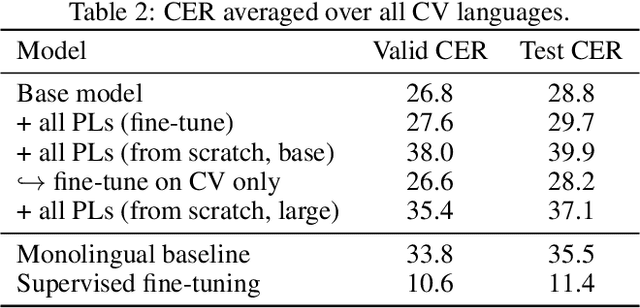
Semi-supervised learning through pseudo-labeling has become a staple of state-of-the-art monolingual speech recognition systems. In this work, we extend pseudo-labeling to massively multilingual speech recognition with 60 languages. We propose a simple pseudo-labeling recipe that works well even with low-resource languages: train a supervised multilingual model, fine-tune it with semi-supervised learning on a target language, generate pseudo-labels for that language, and train a final model using pseudo-labels for all languages, either from scratch or by fine-tuning. Experiments on the labeled Common Voice and unlabeled VoxPopuli datasets show that our recipe can yield a model with better performance for many languages that also transfers well to LibriSpeech.