 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Automatic Speech Recognition Datasets in Cantonese Language: A Survey and a New Dataset
Jan 07, 2022
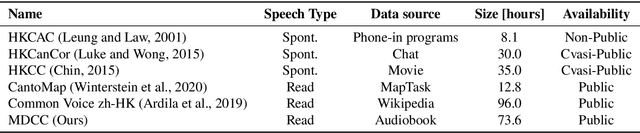
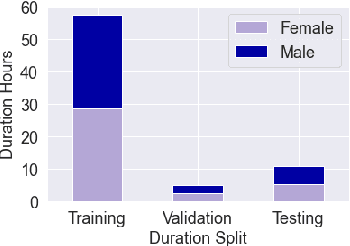
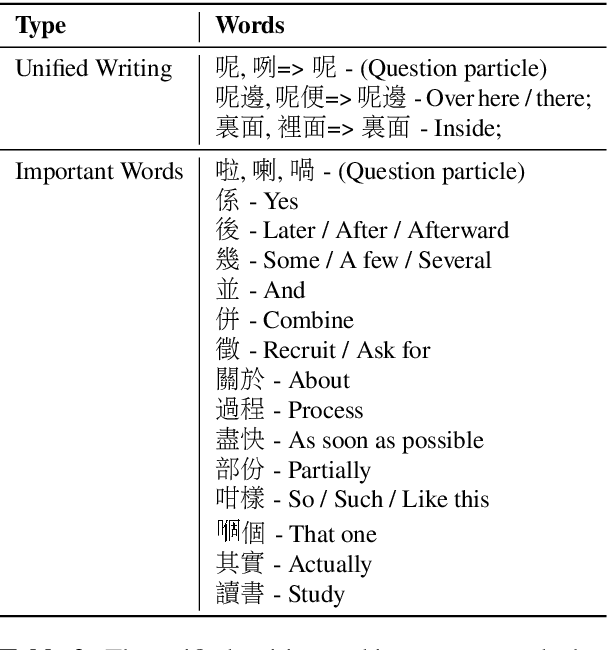
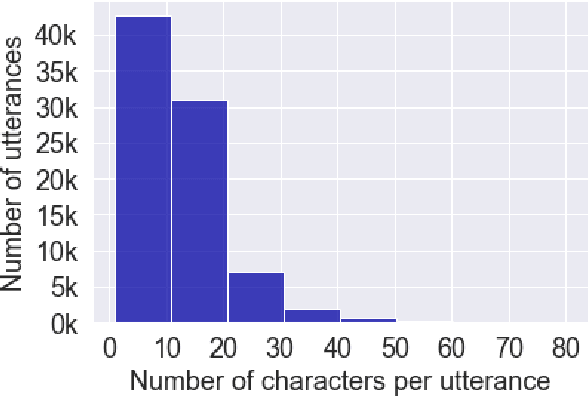
Automatic speech recognition (ASR) on low resource languages improves access of linguistic minorities to technological advantages provided by Artificial Intelligence (AI). In this paper, we address a problem of data scarcity of Hong Kong Cantonese language by creating a new Cantonese dataset. Our dataset, Multi-Domain Cantonese Corpus (MDCC), consists of 73.6 hours of clean read speech paired with transcripts, collected from Cantonese audiobooks from Hong Kong. It combines philosophy, politics, education, culture, lifestyle and family domains, covering a wide range of topics. We also review all existing Cantonese datasets and perform experiments on the two biggest datasets (MDCC and Common Voice zh-HK). We analyze the existing datasets according to their speech type, data source, total size and availability. The results of experiments conducted with Fairseq S2T Transformer, a state-of-the-art ASR model, show the effectiveness of our dataset. In addition, we create a powerful and robust Cantonese ASR model by applying multi-dataset learning on MDCC and Common Voice zh-HK.
Memories are One-to-Many Mapping Alleviators in Talking Face Generation
Dec 09, 2022
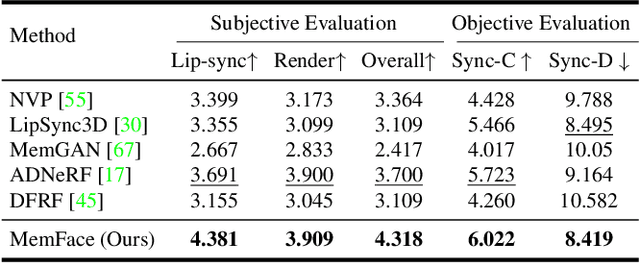
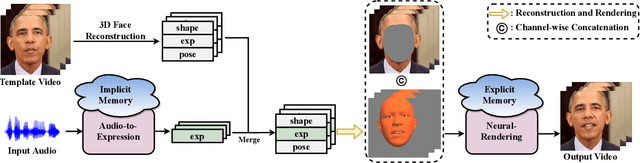
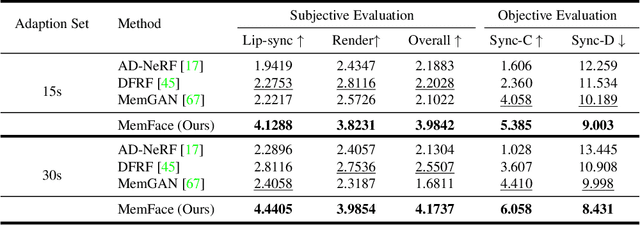
Talking face generation aims at generating photo-realistic video portraits of a target person driven by input audio. Due to its nature of one-to-many mapping from the input audio to the output video (e.g., one speech content may have multiple feasible visual appearances), learning a deterministic mapping like previous works brings ambiguity during training, and thus causes inferior visual results. Although this one-to-many mapping could be alleviated in part by a two-stage framework (i.e., an audio-to-expression model followed by a neural-rendering model), it is still insufficient since the prediction is produced without enough information (e.g., emotions, wrinkles, etc.). In this paper, we propose MemFace to complement the missing information with an implicit memory and an explicit memory that follow the sense of the two stages respectively. More specifically, the implicit memory is employed in the audio-to-expression model to capture high-level semantics in the audio-expression shared space, while the explicit memory is employed in the neural-rendering model to help synthesize pixel-level details. Our experimental results show that our proposed MemFace surpasses all the state-of-the-art results across multiple scenarios consistently and significantly.
Accidental Learners: Spoken Language Identification in Multilingual Self-Supervised Models
Nov 09, 2022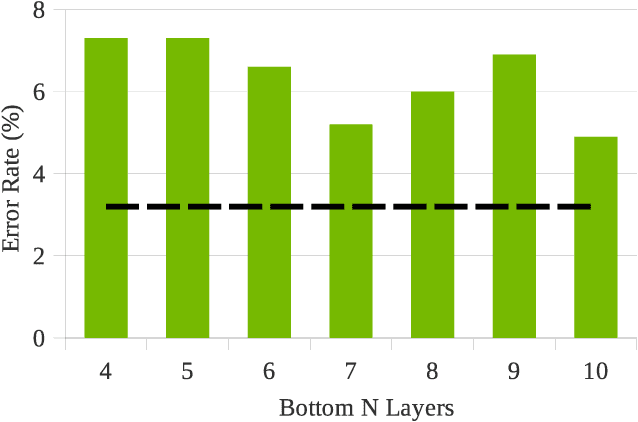
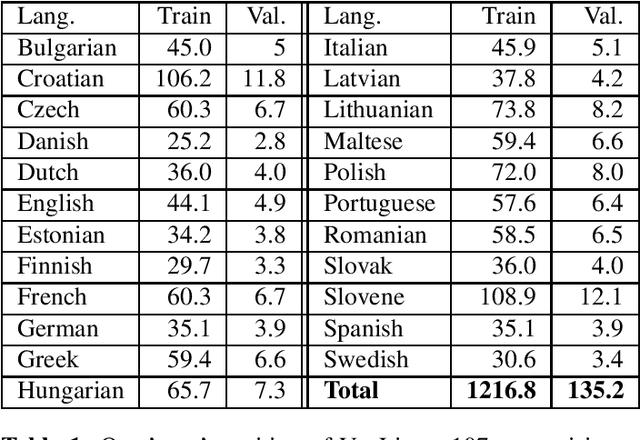
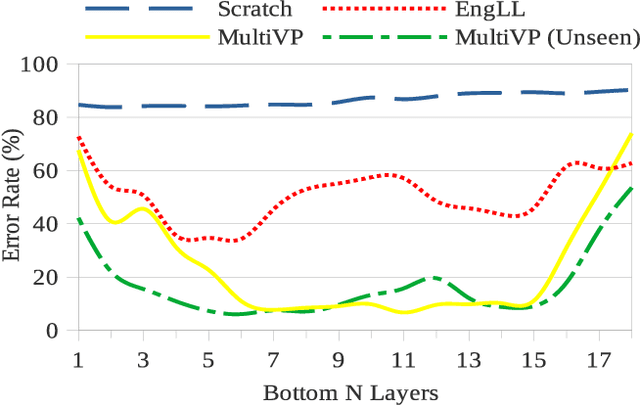
In this paper, we extend previous self-supervised approaches for language identification by experimenting with Conformer based architecture in a multilingual pre-training paradigm. We find that pre-trained speech models optimally encode language discriminatory information in lower layers. Further, we demonstrate that the embeddings obtained from these layers are significantly robust to classify unseen languages and different acoustic environments without additional training. After fine-tuning a pre-trained Conformer model on the VoxLingua107 dataset, we achieve results similar to current state-of-the-art systems for language identification. More, our model accomplishes this with 5x less parameters. We open-source the model through the NVIDIA NeMo toolkit.
A comparison of several AI techniques for authorship attribution on Romanian texts
Nov 09, 2022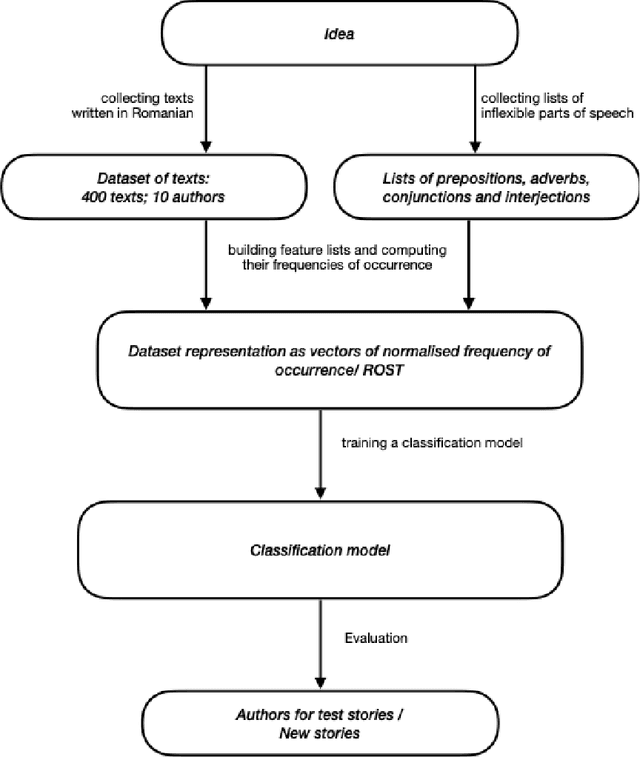
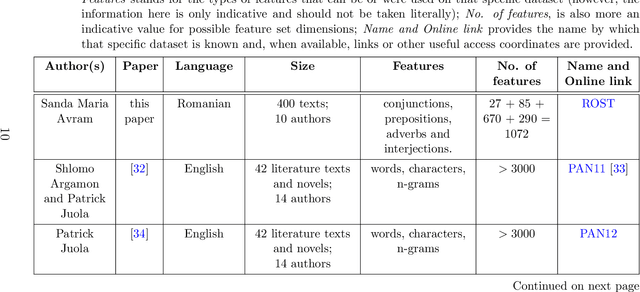
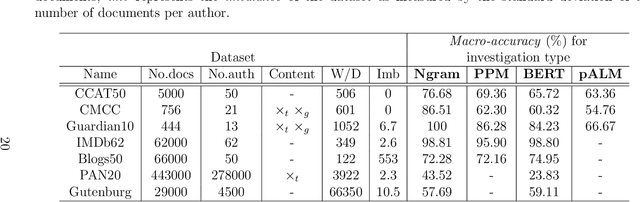
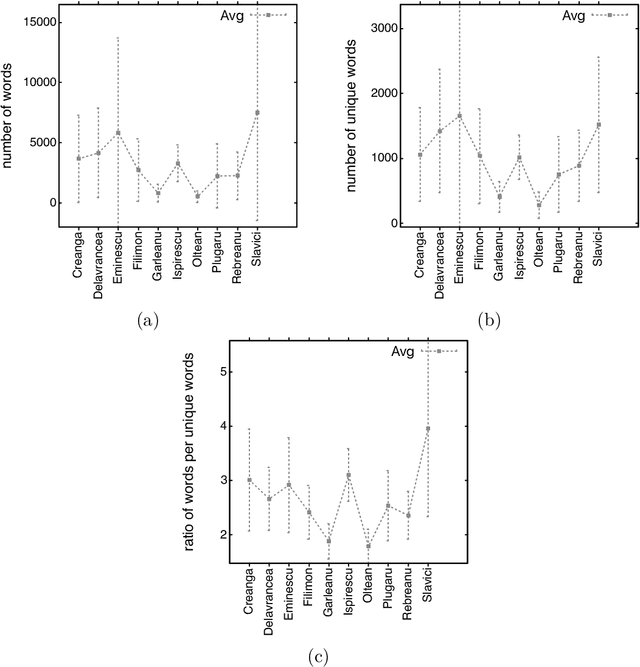
Determining the author of a text is a difficult task. Here we compare multiple AI techniques for classifying literary texts written by multiple authors by taking into account a limited number of speech parts (prepositions, adverbs, and conjunctions). We also introduce a new dataset composed of texts written in the Romanian language on which we have run the algorithms. The compared methods are Artificial Neural Networks, Support Vector Machines, Multi Expression Programming, Decision Trees with C5.0, and k-Nearest Neighbour. Numerical experiments show, first of all, that the problem is difficult, but some algorithms are able to generate decent errors on the test set.
Implicit Acoustic Echo Cancellation for Keyword Spotting and Device-Directed Speech Detection
Nov 20, 2021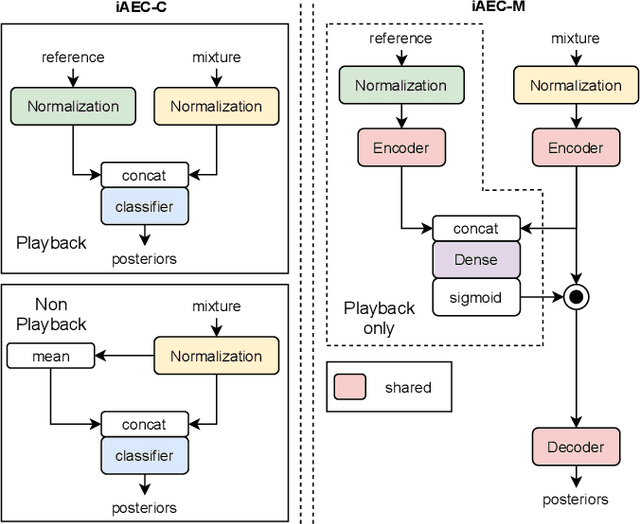
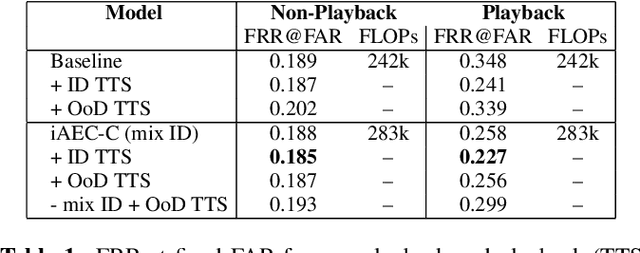
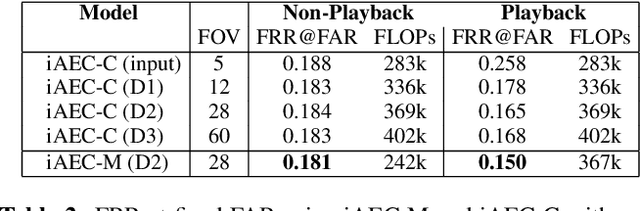
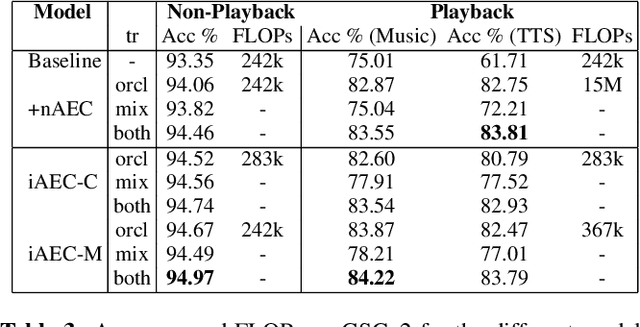
In many speech-enabled human-machine interaction scenarios, user speech can overlap with the device playback audio. In these instances, the performance of tasks such as keyword-spotting (KWS) and device-directed speech detection (DDD) can degrade significantly. To address this problem, we propose an implicit acoustic echo cancellation (iAEC) framework where a neural network is trained to exploit the additional information from a reference microphone channel to learn to ignore the interfering signal and improve detection performance. We study this framework for the tasks of KWS and DDD on, respectively, an augmented version of Google Speech Commands v2 and a real-world Alexa device dataset. Notably, we show a $56\%$ reduction in false-reject rate for the DDD task during device playback conditions. We also show comparable or superior performance over a strong end-to-end neural echo cancellation + KWS baseline for the KWS task with an order of magnitude less computational requirements.
User-Level Differential Privacy against Attribute Inference Attack of Speech Emotion Recognition in Federated Learning
Apr 05, 2022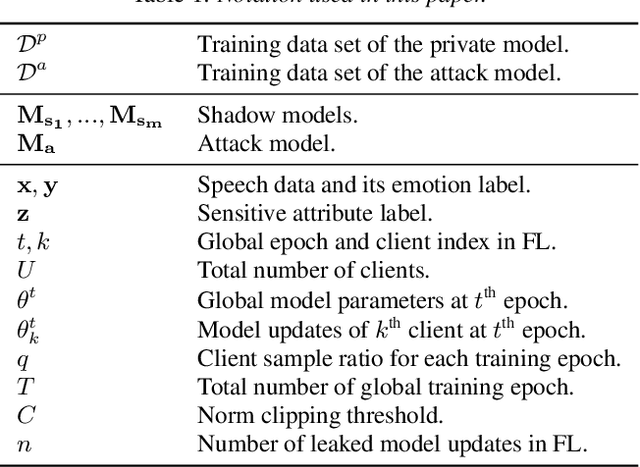
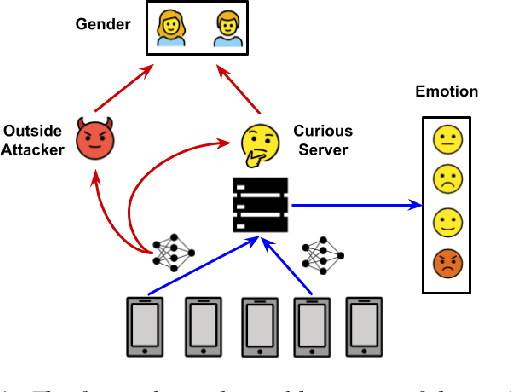
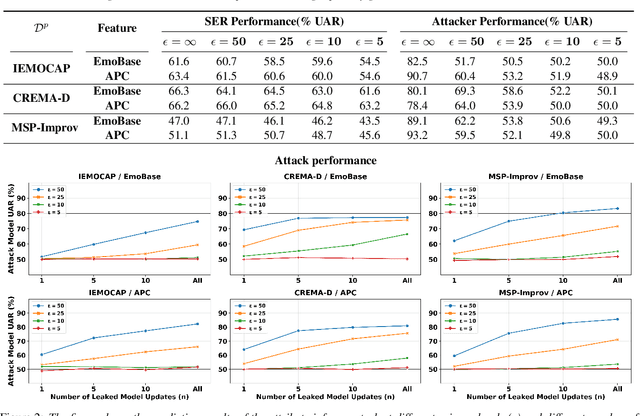
Many existing privacy-enhanced speech emotion recognition (SER) frameworks focus on perturbing the original speech data through adversarial training within a centralized machine learning setup. However, this privacy protection scheme can fail since the adversary can still access the perturbed data. In recent years, distributed learning algorithms, especially federated learning (FL), have gained popularity to protect privacy in machine learning applications. While FL provides good intuition to safeguard privacy by keeping the data on local devices, prior work has shown that privacy attacks, such as attribute inference attacks, are achievable for SER systems trained using FL. In this work, we propose to evaluate the user-level differential privacy (UDP) in mitigating the privacy leaks of the SER system in FL. UDP provides theoretical privacy guarantees with privacy parameters $\epsilon$ and $\delta$. Our results show that the UDP can effectively decrease attribute information leakage while keeping the utility of the SER system with the adversary accessing one model update. However, the efficacy of the UDP suffers when the FL system leaks more model updates to the adversary. We make the code publicly available to reproduce the results in https://github.com/usc-sail/fed-ser-leakage.
DPCCN: Densely-Connected Pyramid Complex Convolutional Network for Robust Speech Separation And Extraction
Dec 27, 2021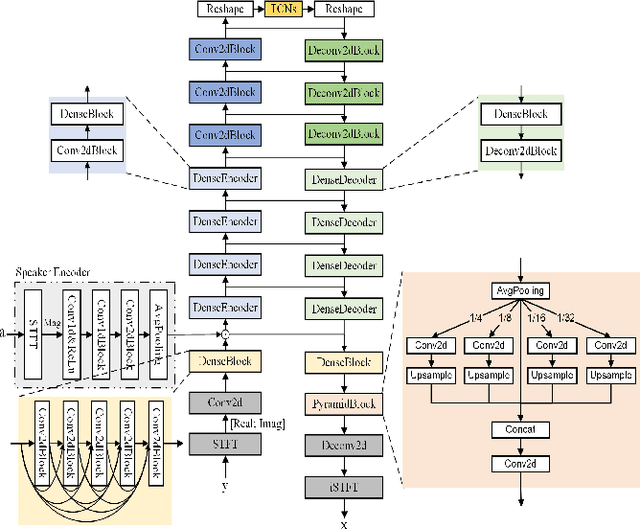
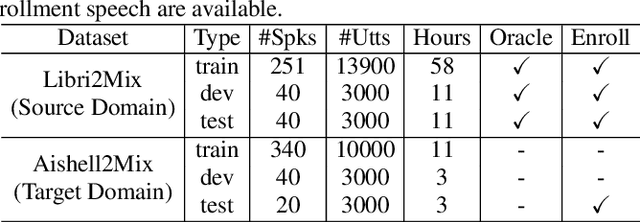
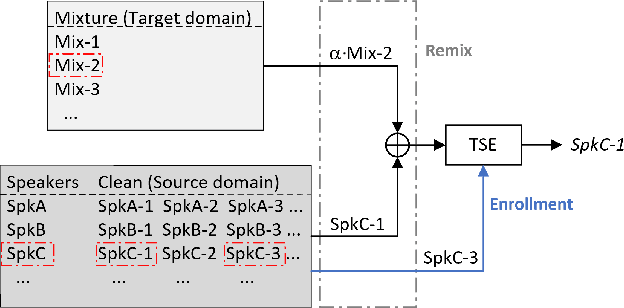

In recent years, a number of time-domain speech separation methods have been proposed. However, most of them are very sensitive to the environments and wide domain coverage tasks. In this paper, from the time-frequency domain perspective, we propose a densely-connected pyramid complex convolutional network, termed DPCCN, to improve the robustness of speech separation under complicated conditions. Furthermore, we generalize the DPCCN to target speech extraction (TSE) by integrating a new specially designed speaker encoder. Moreover, we also investigate the robustness of DPCCN to unsupervised cross-domain TSE tasks. A Mixture-Remix approach is proposed to adapt the target domain acoustic characteristics for fine-tuning the source model. We evaluate the proposed methods not only under noisy and reverberant in-domain condition, but also in clean but cross-domain conditions. Results show that for both speech separation and extraction, the DPCCN-based systems achieve significantly better performance and robustness than the currently dominating time-domain methods, especially for the cross-domain tasks. Particularly, we find that the Mixture-Remix fine-tuning with DPCCN significantly outperforms the TD-SpeakerBeam for unsupervised cross-domain TSE, with around 3.5 dB performance improvement on target domain test set, without any source domain performance degradation.
Robotic Speech Synthesis: Perspectives on Interactions, Scenarios, and Ethics
Mar 17, 2022In recent years, many works have investigated the feasibility of conversational robots for performing specific tasks, such as healthcare and interview. Along with this development comes a practical issue: how should we synthesize robotic voices to meet the needs of different situations? In this paper, we discuss this issue from three perspectives: 1) the difficulties of synthesizing non-verbal and interaction-oriented speech signals, particularly backchannels; 2) the scenario classification for robotic voice synthesis; 3) the ethical issues regarding the design of robot voice for its emotion and identity. We present the findings of relevant literature and our prior work, trying to bring the attention of human-robot interaction researchers to design better conversational robots in the future.
Learnable Front Ends Based on Temporal Modulation for Music Tagging
Nov 28, 2022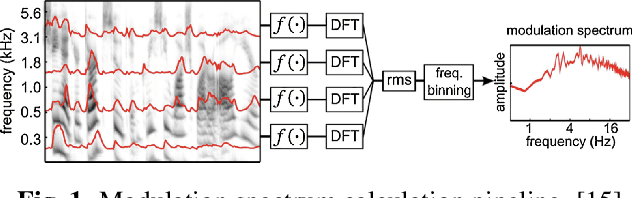
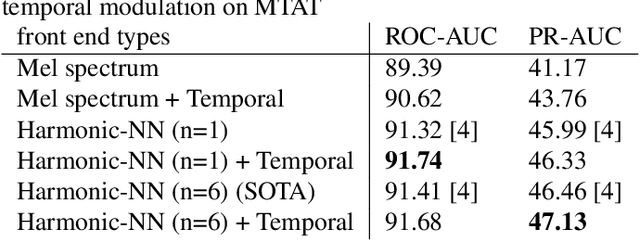
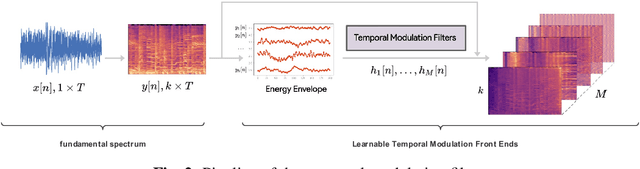
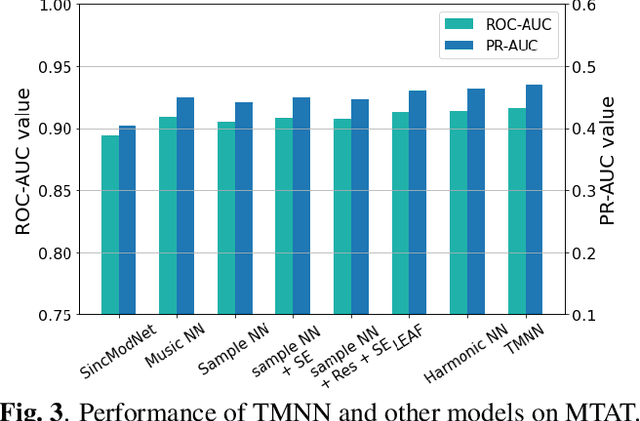
While end-to-end systems are becoming popular in auditory signal processing including automatic music tagging, models using raw audio as input needs a large amount of data and computational resources without domain knowledge. Inspired by the fact that temporal modulation is regarded as an essential component in auditory perception, we introduce the Temporal Modulation Neural Network (TMNN) that combines Mel-like data-driven front ends and temporal modulation filters with a simple ResNet back end. The structure includes a set of temporal modulation filters to capture long-term patterns in all frequency channels. Experimental results show that the proposed front ends surpass state-of-the-art (SOTA) methods on the MagnaTagATune dataset in automatic music tagging, and they are also helpful for keyword spotting on speech commands. Moreover, the model performance for each tag suggests that genre or instrument tags with complex rhythm and mood tags can especially be improved with temporal modulation.
Fusing ASR Outputs in Joint Training for Speech Emotion Recognition
Oct 29, 2021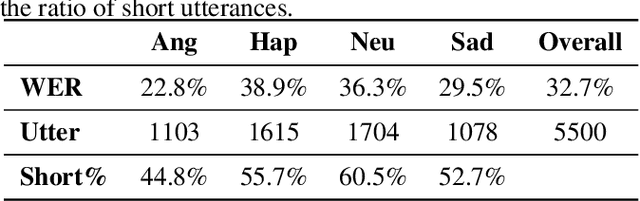
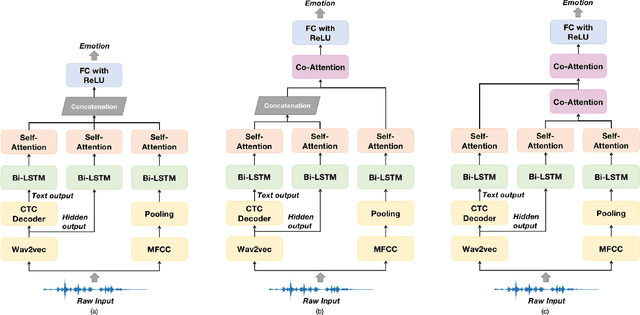
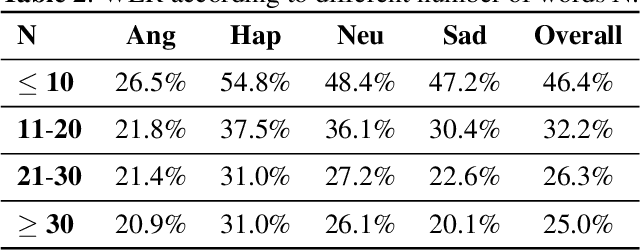

Alongside acoustic information, linguistic features based on speech transcripts have been proven useful in Speech Emotion Recognition (SER). However, due to the scarcity of emotion labelled data and the difficulty of recognizing emotional speech, it is hard to obtain reliable linguistic features and models in this research area. In this paper, we propose to fuse Automatic Speech Recognition (ASR) outputs into the pipeline for joint training SER. The relationship between ASR and SER is understudied, and it is unclear what and how ASR features benefit SER. By examining various ASR outputs and fusion methods, our experiments show that in joint ASR-SER training, incorporating both ASR hidden and text output using a hierarchical co-attention fusion approach improves the SER performance the most. On the IEMOCAP corpus, our approach achieves 63.4% weighted accuracy, which is close to the baseline results achieved by combining ground-truth transcripts. In addition, we also present novel word error rate analysis on IEMOCAP and layer-difference analysis of the Wav2vec 2.0 model to better understand the relationship between ASR and SER.