 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Joint Audio-Text Model for Expressive Speech-Driven 3D Facial Animation
Dec 07, 2021
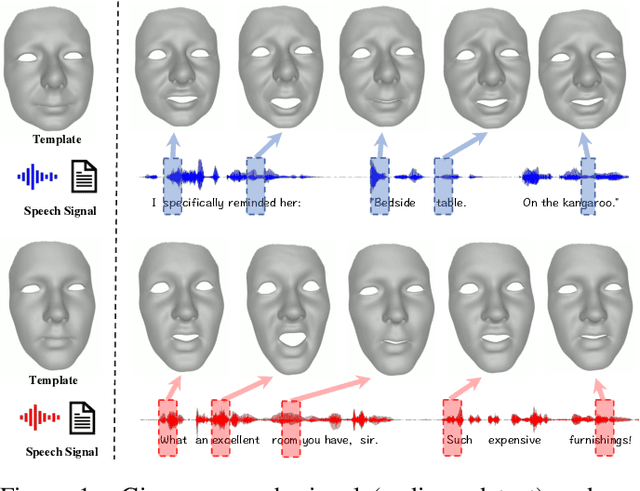
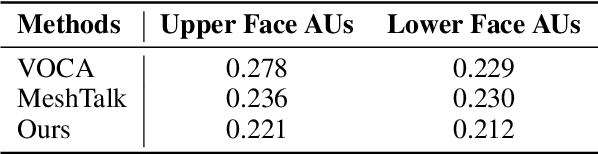
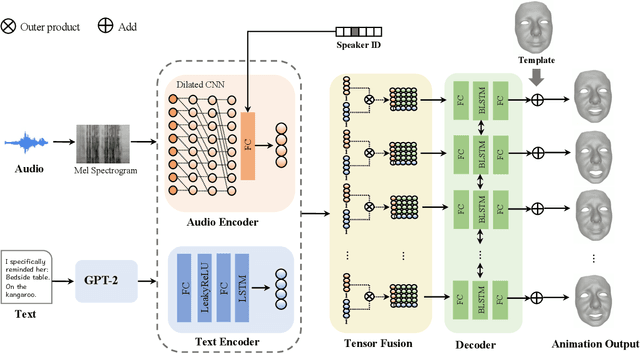
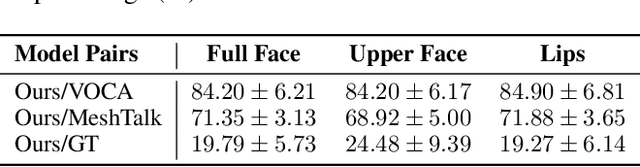
Speech-driven 3D facial animation with accurate lip synchronization has been widely studied. However, synthesizing realistic motions for the entire face during speech has rarely been explored. In this work, we present a joint audio-text model to capture the contextual information for expressive speech-driven 3D facial animation. The existing datasets are collected to cover as many different phonemes as possible instead of sentences, thus limiting the capability of the audio-based model to learn more diverse contexts. To address this, we propose to leverage the contextual text embeddings extracted from the powerful pre-trained language model that has learned rich contextual representations from large-scale text data. Our hypothesis is that the text features can disambiguate the variations in upper face expressions, which are not strongly correlated with the audio. In contrast to prior approaches which learn phoneme-level features from the text, we investigate the high-level contextual text features for speech-driven 3D facial animation. We show that the combined acoustic and textual modalities can synthesize realistic facial expressions while maintaining audio-lip synchronization. We conduct the quantitative and qualitative evaluations as well as the perceptual user study. The results demonstrate the superior performance of our model against existing state-of-the-art approaches.
Mix and Localize: Localizing Sound Sources in Mixtures
Nov 28, 2022
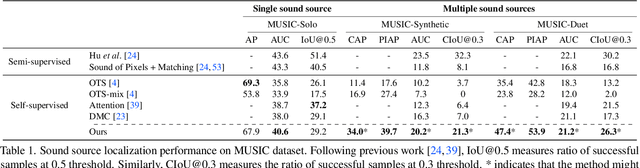
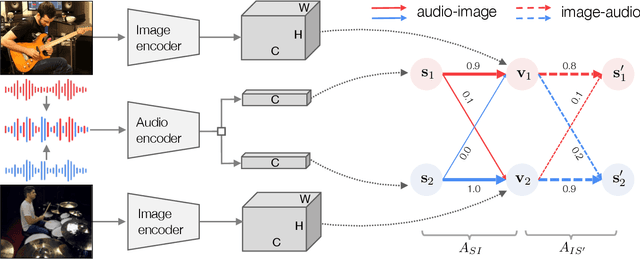
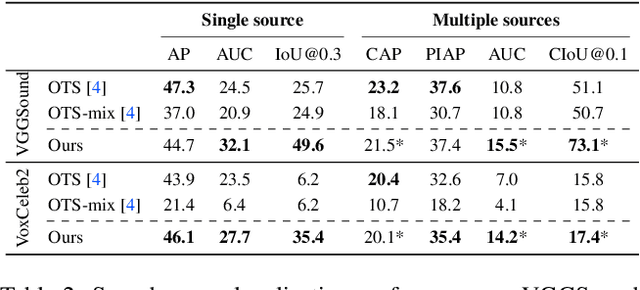
We present a method for simultaneously localizing multiple sound sources within a visual scene. This task requires a model to both group a sound mixture into individual sources, and to associate them with a visual signal. Our method jointly solves both tasks at once, using a formulation inspired by the contrastive random walk of Jabri et al. We create a graph in which images and separated sounds correspond to nodes, and train a random walker to transition between nodes from different modalities with high return probability. The transition probabilities for this walk are determined by an audio-visual similarity metric that is learned by our model. We show through experiments with musical instruments and human speech that our model can successfully localize multiple sounds, outperforming other self-supervised methods. Project site: https://hxixixh.github.io/mix-and-localize
Scaling Up Deliberation for Multilingual ASR
Oct 11, 2022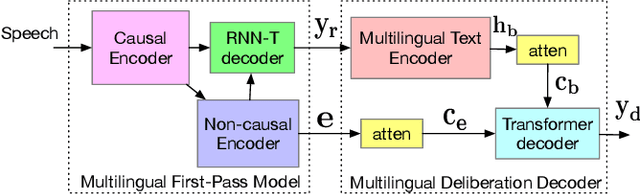
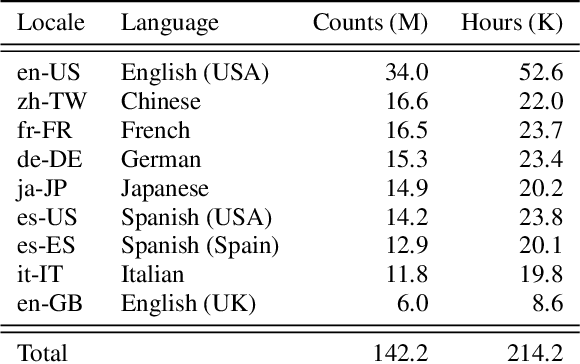
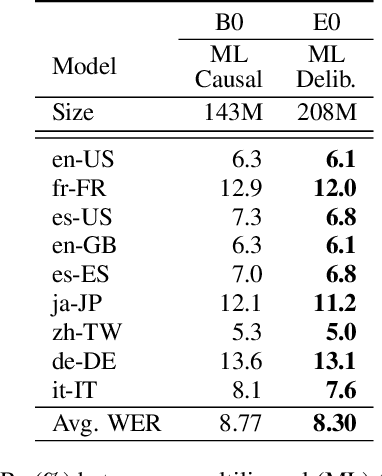
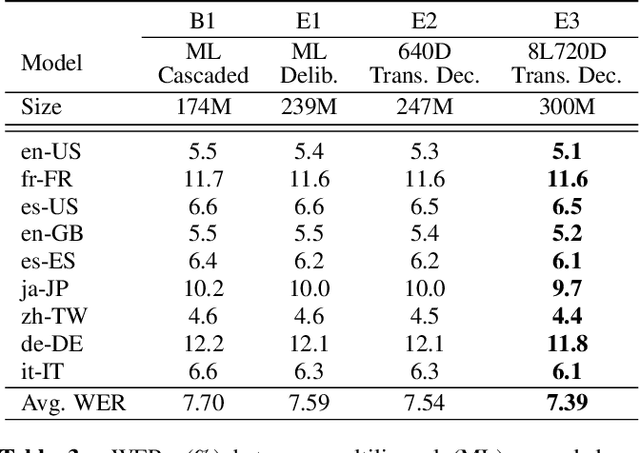
Multilingual end-to-end automatic speech recognition models are attractive due to its simplicity in training and deployment. Recent work on large-scale training of such models has shown promising results compared to monolingual models. However, the work often focuses on multilingual models themselves in a single-pass setup. In this work, we investigate second-pass deliberation for multilingual speech recognition. Our proposed deliberation is multilingual, i.e., the text encoder encodes hypothesis text from multiple languages, and the decoder attends to multilingual text and audio. We investigate scaling the deliberation text encoder and decoder, and compare scaling the deliberation decoder and the first-pass cascaded encoder. We show that deliberation improves the average WER on 9 languages by 4% relative compared to the single-pass model. By increasing the size of the deliberation up to 1B parameters, the average WER improvement increases to 9%, with up to 14% for certain languages. Our deliberation rescorer is based on transformer layers and can be parallelized during rescoring.
Probing Deep Speaker Embeddings for Speaker-related Tasks
Dec 14, 2022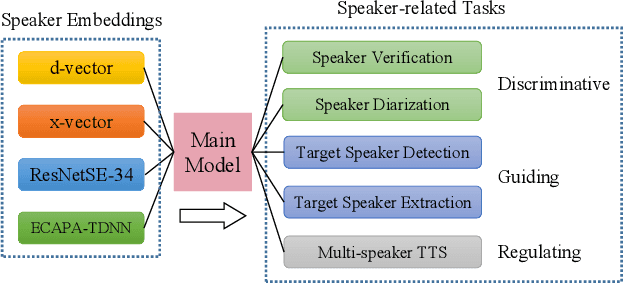

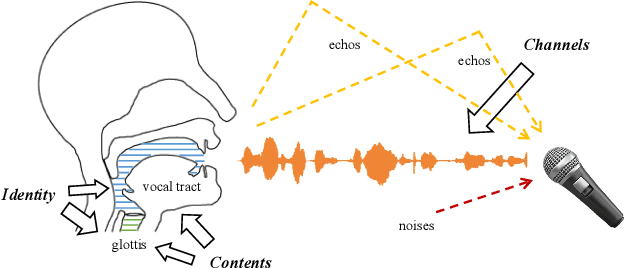
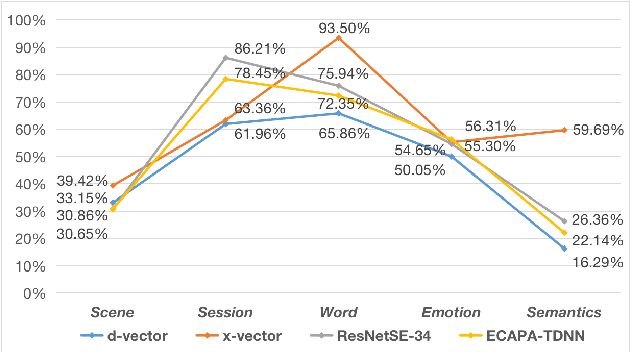
Deep speaker embeddings have shown promising results in speaker recognition, as well as in other speaker-related tasks. However, some issues are still under explored, for instance, the information encoded in these representations and their influence on downstream tasks. Four deep speaker embeddings are studied in this paper, namely, d-vector, x-vector, ResNetSE-34 and ECAPA-TDNN. Inspired by human voice mechanisms, we explored possibly encoded information from perspectives of identity, contents and channels; Based on this, experiments were conducted on three categories of speaker-related tasks to further explore impacts of different deep embeddings, including discriminative tasks (speaker verification and diarization), guiding tasks (target speaker detection and extraction) and regulating tasks (multi-speaker text-to-speech). Results show that all deep embeddings encoded channel and content information in addition to speaker identity, but the extent could vary and their performance on speaker-related tasks can be tremendously different: ECAPA-TDNN is dominant in discriminative tasks, and d-vector leads the guiding tasks, while regulating task is less sensitive to the choice of speaker representations. These may benefit future research utilizing speaker embeddings.
The IWSLT 2021 BUT Speech Translation Systems
Jul 13, 2021
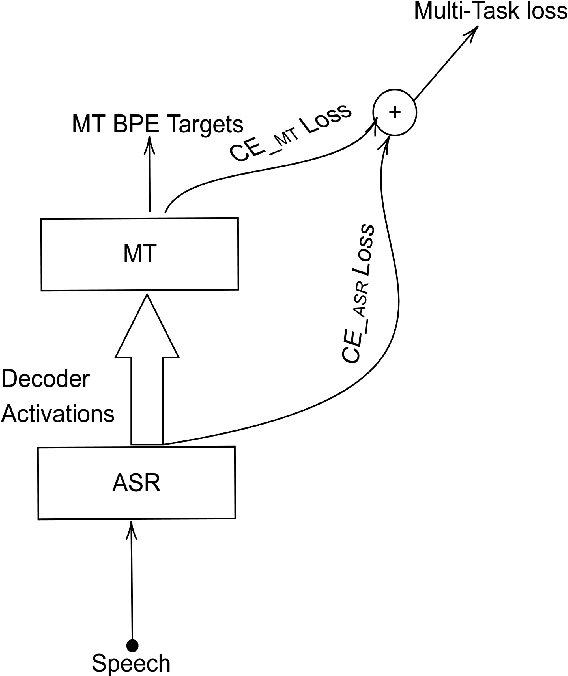
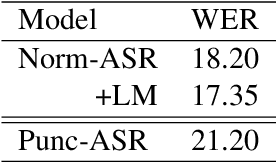
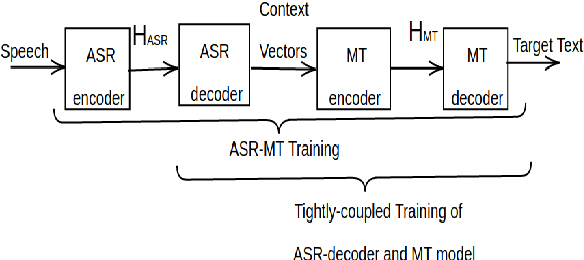
The paper describes BUT's English to German offline speech translation(ST) systems developed for IWSLT2021. They are based on jointly trained Automatic Speech Recognition-Machine Translation models. Their performances is evaluated on MustC-Common test set. In this work, we study their efficiency from the perspective of having a large amount of separate ASR training data and MT training data, and a smaller amount of speech-translation training data. Large amounts of ASR and MT training data are utilized for pre-training the ASR and MT models. Speech-translation data is used to jointly optimize ASR-MT models by defining an end-to-end differentiable path from speech to translations. For this purpose, we use the internal continuous representations from the ASR-decoder as the input to MT module. We show that speech translation can be further improved by training the ASR-decoder jointly with the MT-module using large amount of text-only MT training data. We also show significant improvements by training an ASR module capable of generating punctuated text, rather than leaving the punctuation task to the MT module.
Investigating self-supervised front ends for speech spoofing countermeasures
Nov 15, 2021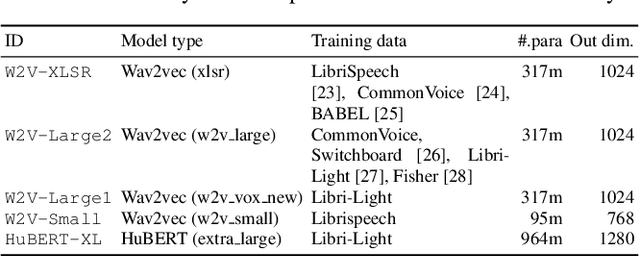
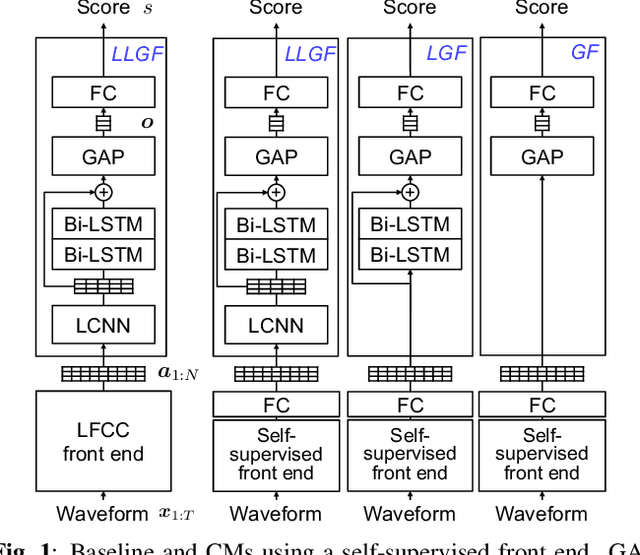
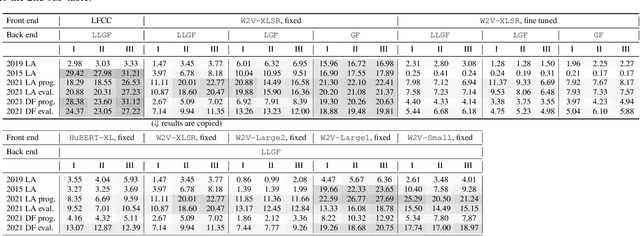
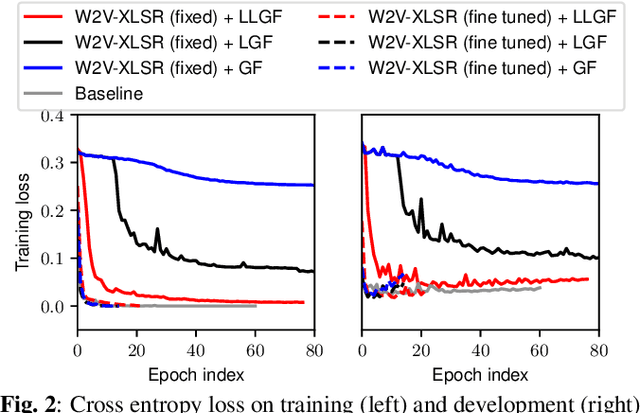
Self-supervised speech model is a rapid progressing research topic, and many pre-trained models have been released and used in various down-stream tasks. For speech anti-spoofing, most countermeasures (CMs) are using signal processing algorithms to extract acoustic features for classification. In this study, we use pre-trained self-supervised speech models as the front end of spoofing CMs. We investigated different back end architectures to be combined with the self-supervised front end, the effectiveness of fine tuning the front end, and the performance of using different pre-trained self-supervised models. Our experiments found that, when a good pre-trained front end was fine tuned with either a shallow or a deep neural-network-based back end on the ASVspoof 2019 logical access (LA) training set, the resulting CM not only achieved a low EER score on the 2019 LA test set but also significantly outperformed the baseline on ASVspoof 2015, 2021 LA, and 2021 deepfake test sets.
An Objective Evaluation Framework for Pathological Speech Synthesis
Jul 01, 2021



The development of pathological speech systems is currently hindered by the lack of a standardised objective evaluation framework. In this work, (1) we utilise existing detection and analysis techniques to propose a general framework for the consistent evaluation of synthetic pathological speech. This framework evaluates the voice quality and the intelligibility aspects of speech and is shown to be complementary using our experiments. (2) Using our proposed evaluation framework, we develop and test a dysarthric voice conversion system (VC) using CycleGAN-VC and a PSOLA-based speech rate modification technique. We show that the developed system is able to synthesise dysarthric speech with different levels of speech intelligibility.
Domain Specific Wav2vec 2.0 Fine-tuning For The SE&R 2022 Challenge
Jul 29, 2022
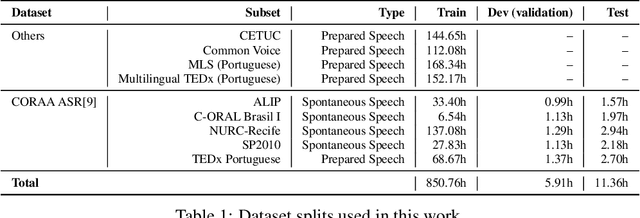
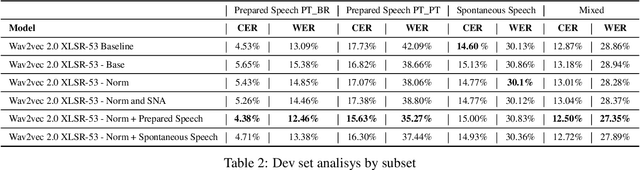
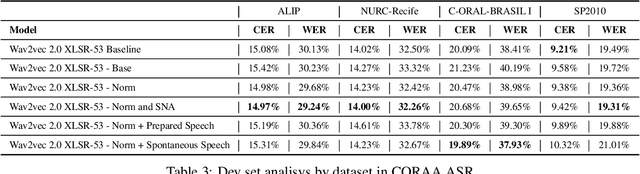
This paper presents our efforts to build a robust ASR model for the shared task Automatic Speech Recognition for spontaneous and prepared speech & Speech Emotion Recognition in Portuguese (SE&R 2022). The goal of the challenge is to advance the ASR research for the Portuguese language, considering prepared and spontaneous speech in different dialects. Our method consist on fine-tuning an ASR model in a domain-specific approach, applying gain normalization and selective noise insertion. The proposed method improved over the strong baseline provided on the test set in 3 of the 4 tracks available
Acoustic-aware Non-autoregressive Spell Correction with Mask Sample Decoding
Oct 16, 2022
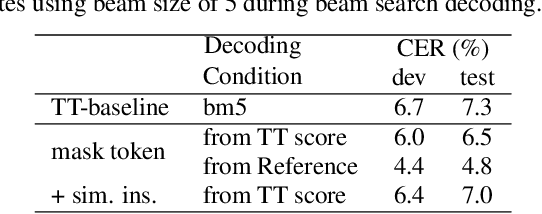

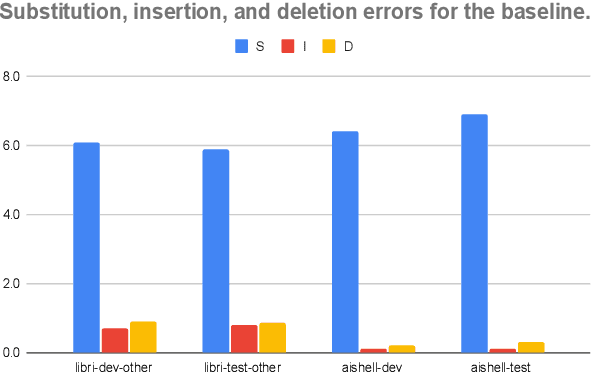
Masked language model (MLM) has been widely used for understanding tasks, e.g. BERT. Recently, MLM has also been used for generation tasks. The most popular one in speech is using Mask-CTC for non-autoregressive speech recognition. In this paper, we take one step further, and explore the possibility of using MLM as a non-autoregressive spell correction (SC) model for transformer-transducer (TT), denoted as MLM-SC. Our initial experiments show that MLM-SC provides no improvements on Librispeech data. The problem might be the choice of modeling units (word pieces) and the inaccuracy of the TT confidence scores for English data. To solve the problem, we propose a mask sample decoding (MS-decode) method where the masked tokens can have the choice of being masked or not to compensate for the inaccuracy. As a result, we reduce the WER of a streaming TT from 7.6% to 6.5% on the Librispeech test-other data and the CER from 7.3% to 6.1% on the Aishell test data, respectively.
Deep Learning-based Non-Intrusive Multi-Objective Speech Assessment Model with Cross-Domain Features
Nov 03, 2021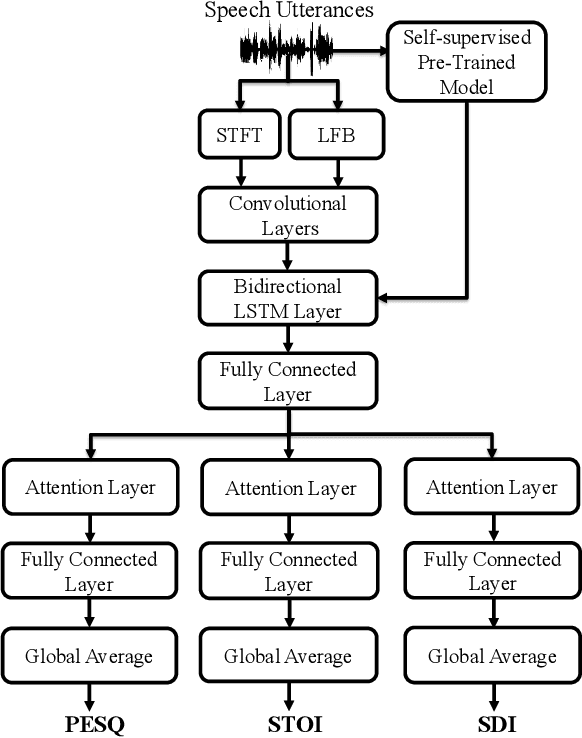
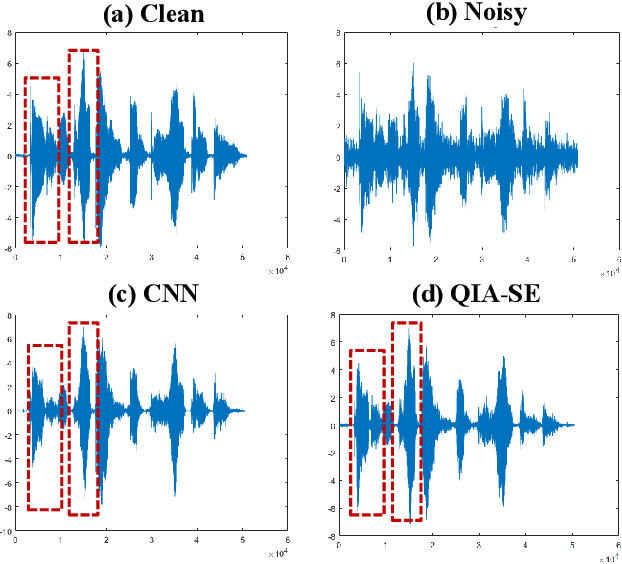
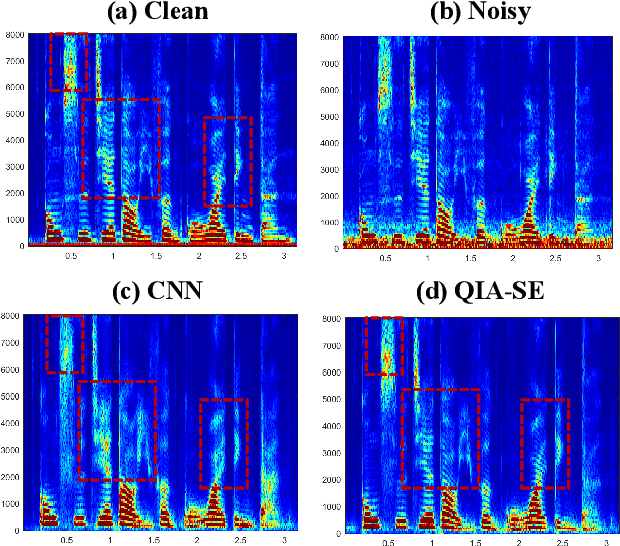
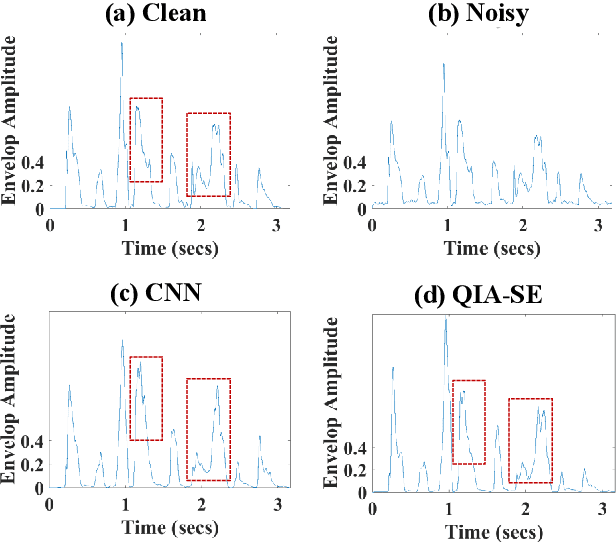
In this study, we propose a cross-domain multi-objective speech assessment model, i.e., the MOSA-Net, which can estimate multiple speech assessment metrics simultaneously. More specifically, the MOSA-Net is designed to estimate speech quality, intelligibility, and distortion assessment scores based on a test speech signal as input. It comprises a convolutional neural network and bidirectional long short-term memory (CNN-BLSTM) architecture for representation extraction, as well as a multiplicative attention layer and a fully-connected layer for each assessment metric. In addition, cross-domain features (spectral and time-domain features) and latent representations from self-supervised learned models are used as inputs to combine rich acoustic information from different speech representations to obtain more accurate assessments. Experimental results reveal that the MOSA-Net can precisely predict perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI) scores when tested on both noisy and enhanced speech utterances under either seen test conditions (where the test speakers and noise types are involved in the training set) or unseen test conditions (where the test speakers and noise types are not involved in the training set). In light of the confirmed prediction capability, we further adopt the latent representations of the MOSA-Net to guide the speech enhancement (SE) process and derive a quality-intelligibility (QI)-aware SE (QIA-SE) approach accordingly. Experimental results show that QIA-SE provides superior enhancement performance compared with the baseline SE system in terms of objective evaluation metrics and qualitative evaluation test.