 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Masks Fusion with Multi-Target Learning For Speech Enhancement
Sep 28, 2021
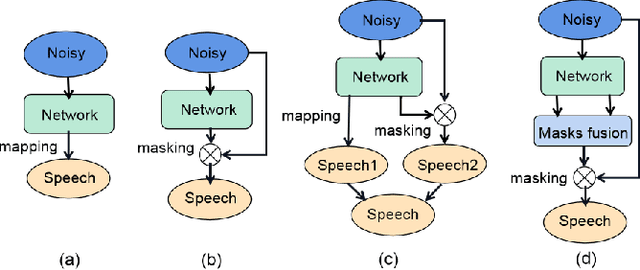
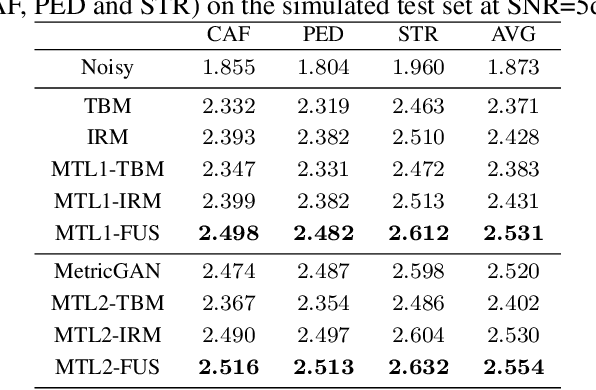
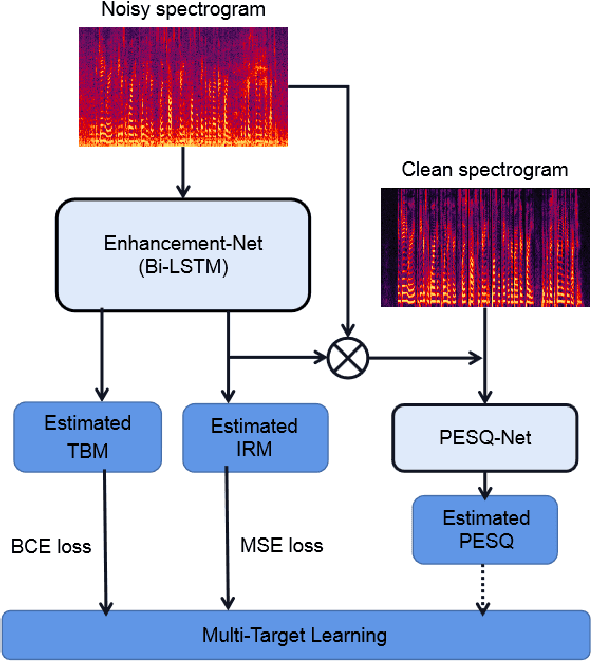
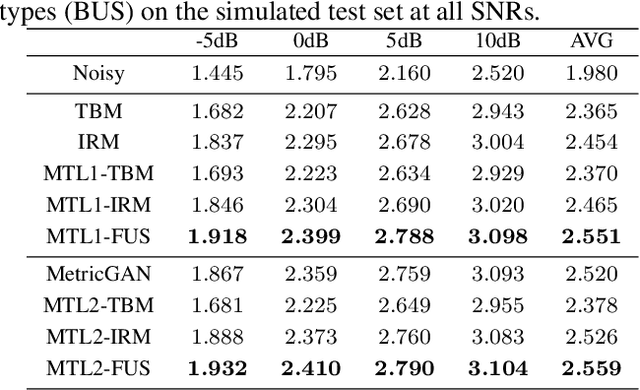
Recently, deep neural network (DNN) based time-frequency (T-F) mask estimation has shown remarkable effectiveness for speech enhancement. Typically, a single T-F mask is first estimated based on DNN and then used to mask the spectrogram of noisy speech in an order to suppress the noise. This work proposes a multi-mask fusion method for speech enhancement. It simultaneously estimates two complementary masks, e.g., ideal ratio mask (IRM) and target binary mask (TBM), and then fuse them to obtain a refined mask for speech enhancement. The advantage of the new method is twofold. First, simultaneously estimating multiple complementary masks brings benefit endowed by multi-target learning. Second, multi-mask fusion can exploit the complementarity of multiple masks to boost the performance of speech enhancement. Experimental results show that the proposed method can achieve significant PESQ improvement and reduce the recognition error rate of back-end over traditional masking-based methods. Code is available at https://github.com/lc-zhou/mask-fusion.
Classifying Autism from Crowdsourced Semi-Structured Speech Recordings: A Machine Learning Approach
Jan 04, 2022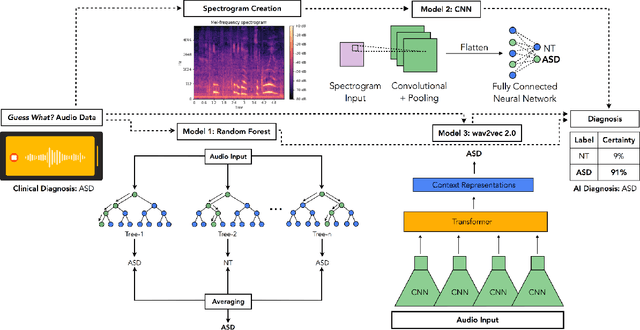

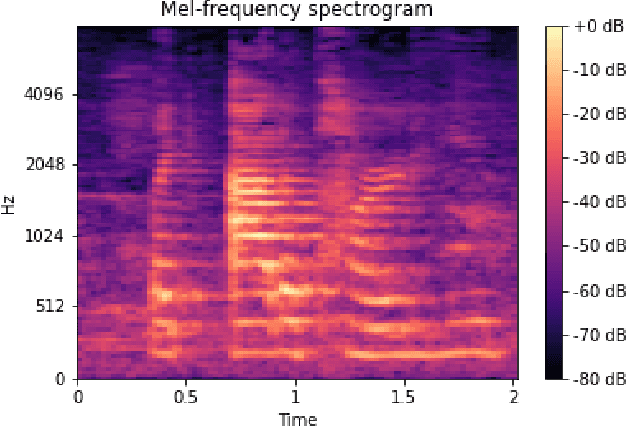
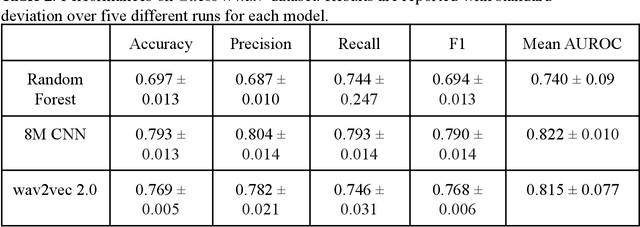
Autism spectrum disorder (ASD) is a neurodevelopmental disorder which results in altered behavior, social development, and communication patterns. In past years, autism prevalence has tripled, with 1 in 54 children now affected. Given that traditional diagnosis is a lengthy, labor-intensive process, significant attention has been given to developing systems that automatically screen for autism. Prosody abnormalities are among the clearest signs of autism, with affected children displaying speech idiosyncrasies including echolalia, monotonous intonation, atypical pitch, and irregular linguistic stress patterns. In this work, we present a suite of machine learning approaches to detect autism in self-recorded speech audio captured from autistic and neurotypical (NT) children in home environments. We consider three methods to detect autism in child speech: first, Random Forests trained on extracted audio features (including Mel-frequency cepstral coefficients); second, convolutional neural networks (CNNs) trained on spectrograms; and third, fine-tuned wav2vec 2.0--a state-of-the-art Transformer-based ASR model. We train our classifiers on our novel dataset of cellphone-recorded child speech audio curated from Stanford's Guess What? mobile game, an app designed to crowdsource videos of autistic and neurotypical children in a natural home environment. The Random Forest classifier achieves 70% accuracy, the fine-tuned wav2vec 2.0 model achieves 77% accuracy, and the CNN achieves 79% accuracy when classifying children's audio as either ASD or NT. Our models were able to predict autism status when training on a varied selection of home audio clips with inconsistent recording quality, which may be more generalizable to real world conditions. These results demonstrate that machine learning methods offer promise in detecting autism automatically from speech without specialized equipment.
Towards Language Modelling in the Speech Domain Using Sub-word Linguistic Units
Oct 31, 2021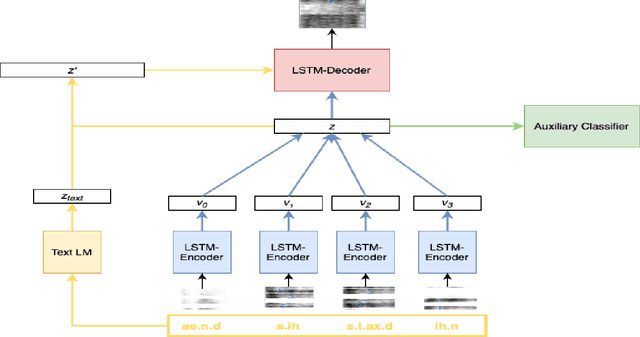

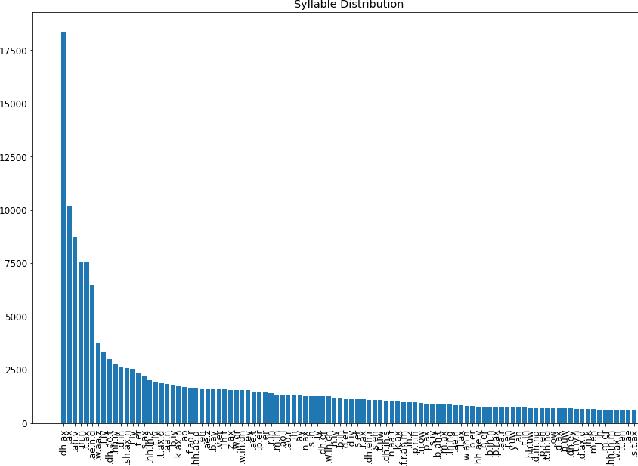
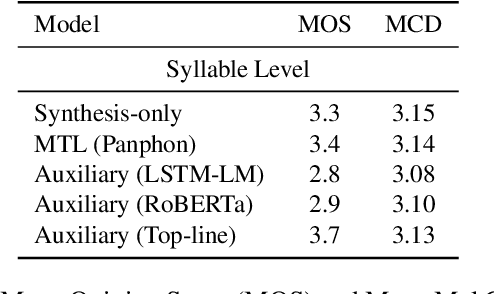
Language models (LMs) for text data have been studied extensively for their usefulness in language generation and other downstream tasks. However, language modelling purely in the speech domain is still a relatively unexplored topic, with traditional speech LMs often depending on auxiliary text LMs for learning distributional aspects of the language. For the English language, these LMs treat words as atomic units, which presents inherent challenges to language modelling in the speech domain. In this paper, we propose a novel LSTM-based generative speech LM that is inspired by the CBOW model and built on linguistic units including syllables and phonemes. This offers better acoustic consistency across utterances in the dataset, as opposed to single melspectrogram frames, or whole words. With a limited dataset, orders of magnitude smaller than that required by contemporary generative models, our model closely approximates babbling speech. We show the effect of training with auxiliary text LMs, multitask learning objectives, and auxiliary articulatory features. Through our experiments, we also highlight some well known, but poorly documented challenges in training generative speech LMs, including the mismatch between the supervised learning objective with which these models are trained such as Mean Squared Error (MSE), and the true objective, which is speech quality. Our experiments provide an early indication that while validation loss and Mel Cepstral Distortion (MCD) are not strongly correlated with generated speech quality, traditional text language modelling metrics like perplexity and next-token-prediction accuracy might be.
Dyadic Interaction Assessment from Free-living Audio for Depression Severity Assessment
Sep 08, 2022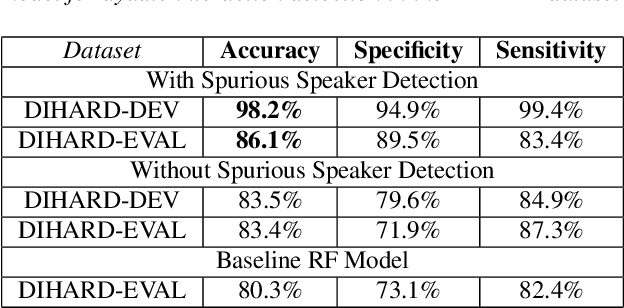
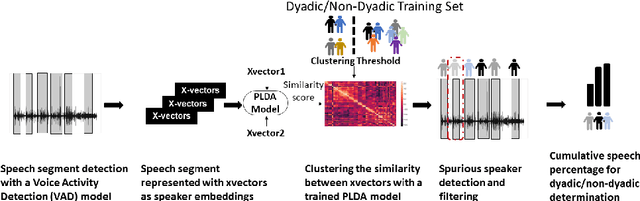
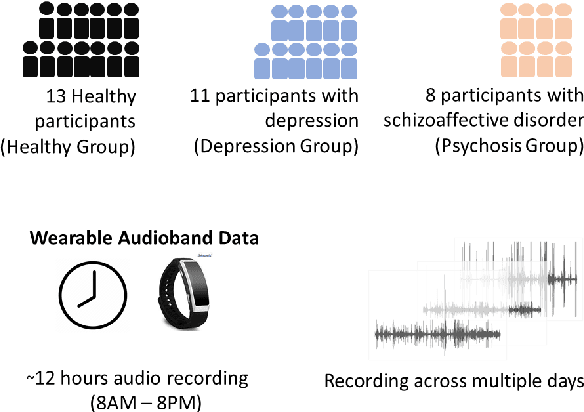
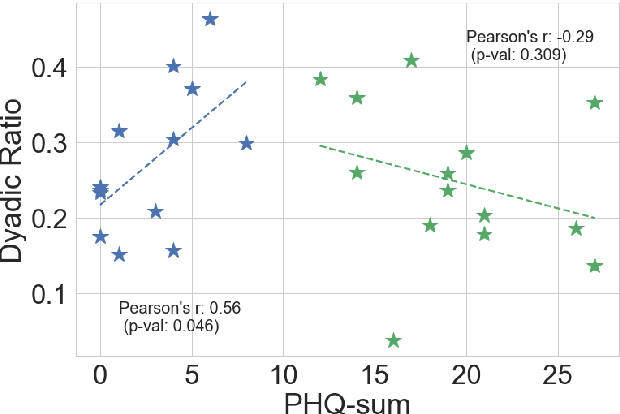
Psychomotor retardation in depression has been associated with speech timing changes from dyadic clinical interviews. In this work, we investigate speech timing features from free-living dyadic interactions. Apart from the possibility of continuous monitoring to complement clinical visits, a study in free-living conditions would also allow inferring sociability features such as dyadic interaction frequency implicated in depression. We adapted a speaker count estimator as a dyadic interaction detector with a specificity of 89.5% and a sensitivity of 86.1% in the DIHARD dataset. Using the detector, we obtained speech timing features from the detected dyadic interactions in multi-day audio recordings of 32 participants comprised of 13 healthy individuals, 11 individuals with depression, and 8 individuals with psychotic disorders. The dyadic interaction frequency increased with depression severity in participants with no or mild depression, indicating a potential diagnostic marker of depression onset. However, the dyadic interaction frequency decreased with increasing depression severity for participants with moderate or severe depression. In terms of speech timing features, the response time had a significant positive correlation with depression severity. Our work shows the potential of dyadic interaction analysis from audio recordings of free-living to obtain markers of depression severity.
Speech watermarking: a solution for authentication of forensic audio digital recordings
Feb 23, 2022
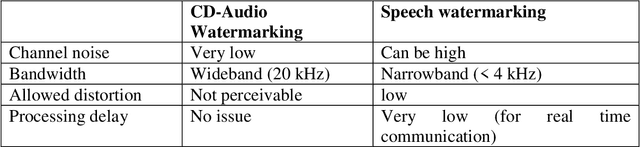
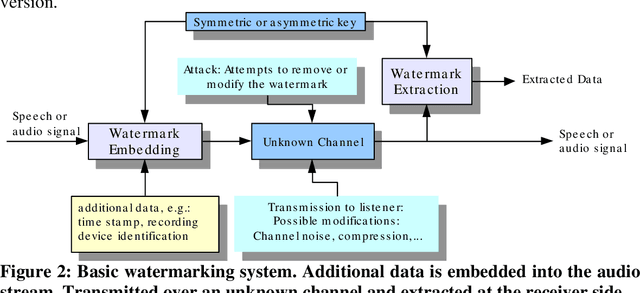
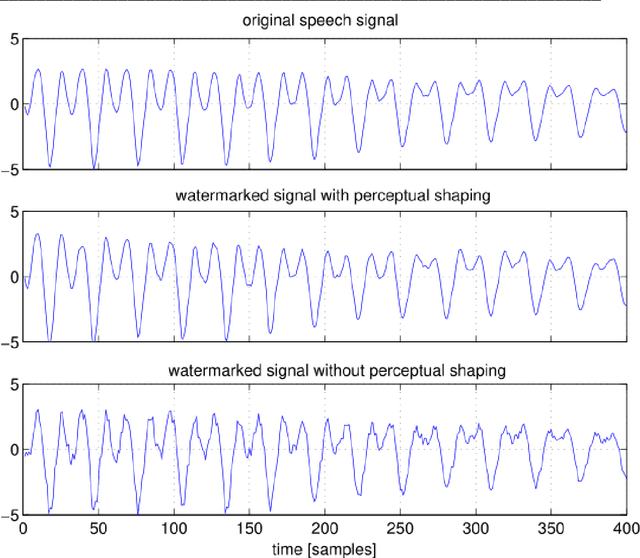
In this paper we discuss the problem of authentication of forensic audio when using digital recordings. Although forensic audio has been addressed in several papers the existing approaches are focused on analog magnetic recordings, which are becoming old-fashion due to the large amount of digital recorders available on the market (optical, solid-state, hard disks, etc). We present an approach based on digital signal processing that consist of spread spectrum techniques for speech watermarking. This approach presents the advantage that the authentication is based on the signal itself rather than the recording support. Thus, it is valid for whatever recording device. In addition, our proposal permits the introduction of relevant information such as recording date and time and all the relevant data (this is not possible with classical systems). Our experimental results reveal that the speech watermarking procedure does not interfere in a significant way with the posterior forensic speaker identification.
* 14 pages
NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-robust Expressive TTS
Nov 04, 2022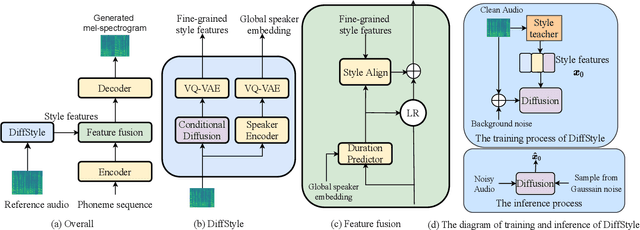
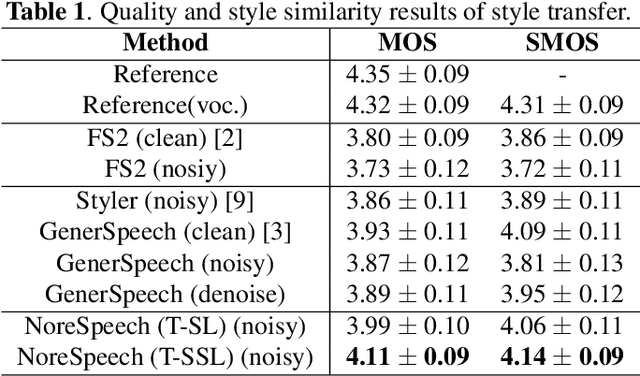

Expressive text-to-speech (TTS) can synthesize a new speaking style by imiating prosody and timbre from a reference audio, which faces the following challenges: (1) The highly dynamic prosody information in the reference audio is difficult to extract, especially, when the reference audio contains background noise. (2) The TTS systems should have good generalization for unseen speaking styles. In this paper, we present a \textbf{no}ise-\textbf{r}obust \textbf{e}xpressive TTS model (NoreSpeech), which can robustly transfer speaking style in a noisy reference utterance to synthesized speech. Specifically, our NoreSpeech includes several components: (1) a novel DiffStyle module, which leverages powerful probabilistic denoising diffusion models to learn noise-agnostic speaking style features from a teacher model by knowledge distillation; (2) a VQ-VAE block, which maps the style features into a controllable quantized latent space for improving the generalization of style transfer; and (3) a straight-forward but effective parameter-free text-style alignment module, which enables NoreSpeech to transfer style to a textual input from a length-mismatched reference utterance. Experiments demonstrate that NoreSpeech is more effective than previous expressive TTS models in noise environments. Audio samples and code are available at: \href{http://dongchaoyang.top/NoreSpeech\_demo/}{http://dongchaoyang.top/NoreSpeech\_demo/}
FedSpeech: Federated Text-to-Speech with Continual Learning
Oct 14, 2021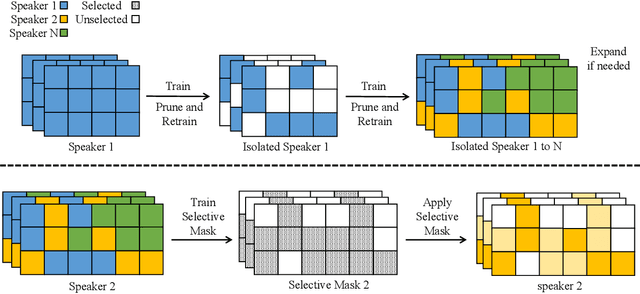
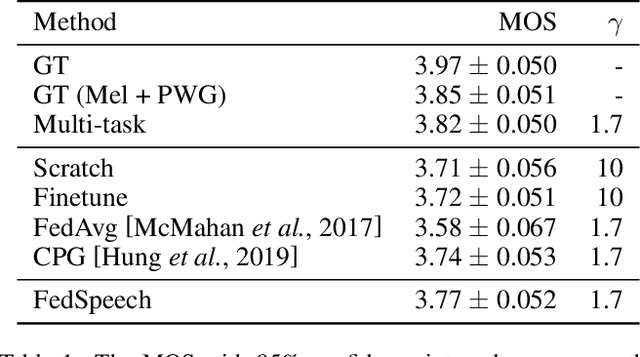
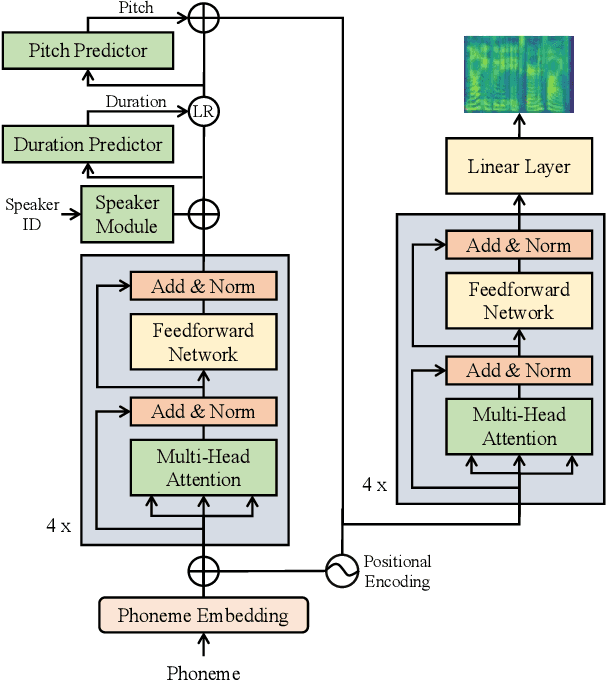
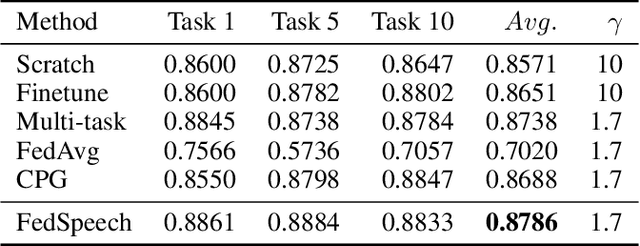
Federated learning enables collaborative training of machine learning models under strict privacy restrictions and federated text-to-speech aims to synthesize natural speech of multiple users with a few audio training samples stored in their devices locally. However, federated text-to-speech faces several challenges: very few training samples from each speaker are available, training samples are all stored in local device of each user, and global model is vulnerable to various attacks. In this paper, we propose a novel federated learning architecture based on continual learning approaches to overcome the difficulties above. Specifically, 1) we use gradual pruning masks to isolate parameters for preserving speakers' tones; 2) we apply selective masks for effectively reusing knowledge from tasks; 3) a private speaker embedding is introduced to keep users' privacy. Experiments on a reduced VCTK dataset demonstrate the effectiveness of FedSpeech: it nearly matches multi-task training in terms of multi-speaker speech quality; moreover, it sufficiently retains the speakers' tones and even outperforms the multi-task training in the speaker similarity experiment.
* Accepted by IJCAI 2021
4D ASR: Joint modeling of CTC, Attention, Transducer, and Mask-Predict decoders
Dec 21, 2022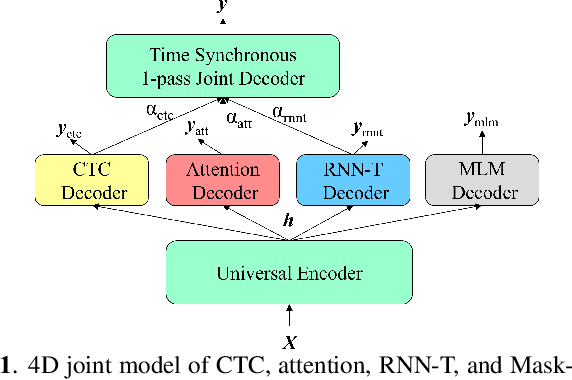
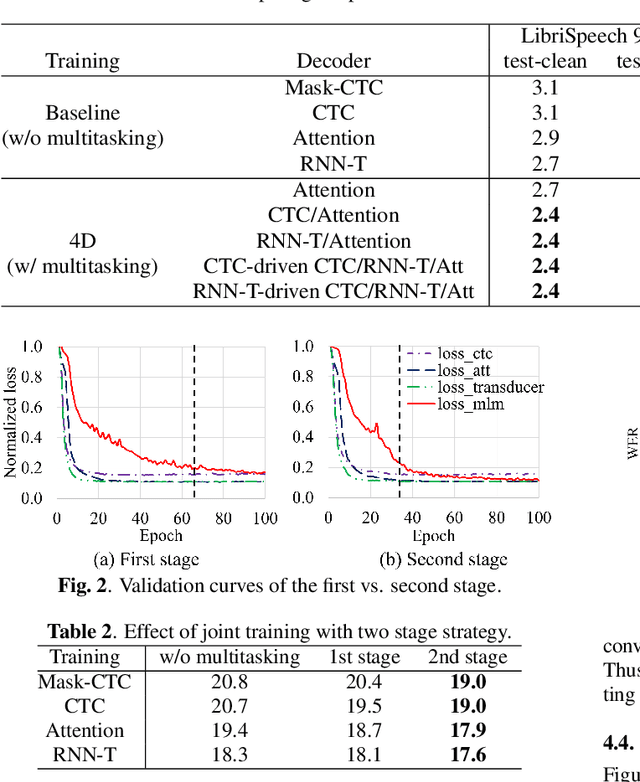
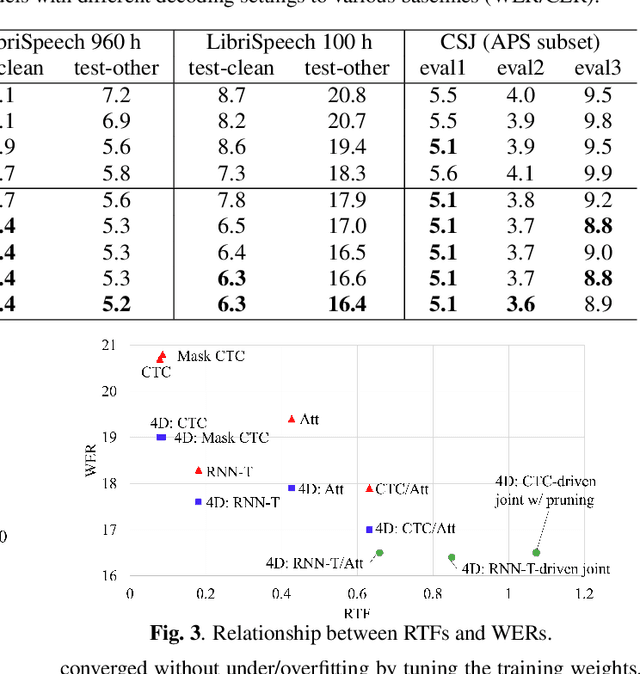
The network architecture of end-to-end (E2E) automatic speech recognition (ASR) can be classified into several models, including connectionist temporal classification (CTC), recurrent neural network transducer (RNN-T), attention mechanism, and non-autoregressive mask-predict models. Since each of these network architectures has pros and cons, a typical use case is to switch these separate models depending on the application requirement, resulting in the increased overhead of maintaining all models. Several methods for integrating two of these complementary models to mitigate the overhead issue have been proposed; however, if we integrate more models, we will further benefit from these complementary models and realize broader applications with a single system. This paper proposes four-decoder joint modeling (4D) of CTC, attention, RNN-T, and mask-predict, which has the following three advantages: 1) The four decoders are jointly trained so that they can be easily switched depending on the application scenarios. 2) Joint training may bring model regularization and improve the model robustness thanks to their complementary properties. 3) Novel one-pass joint decoding methods using CTC, attention, and RNN-T further improves the performance. The experimental results showed that the proposed model consistently reduced the WER.
Framewise WaveGAN: High Speed Adversarial Vocoder in Time Domain with Very Low Computational Complexity
Dec 08, 2022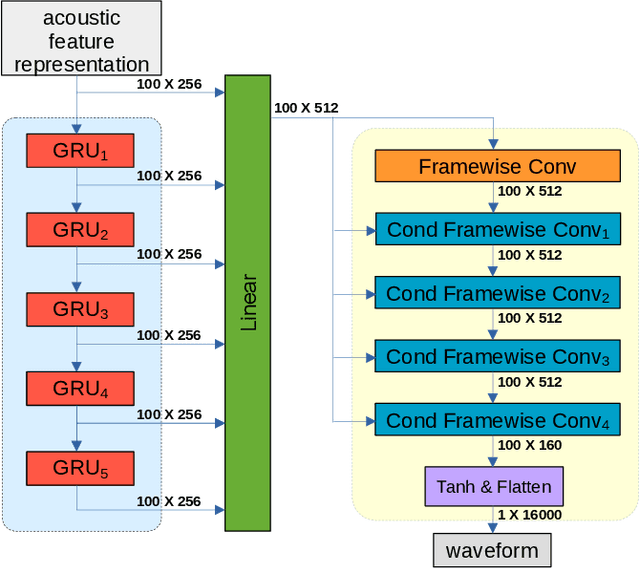
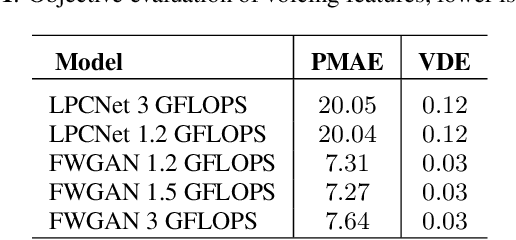
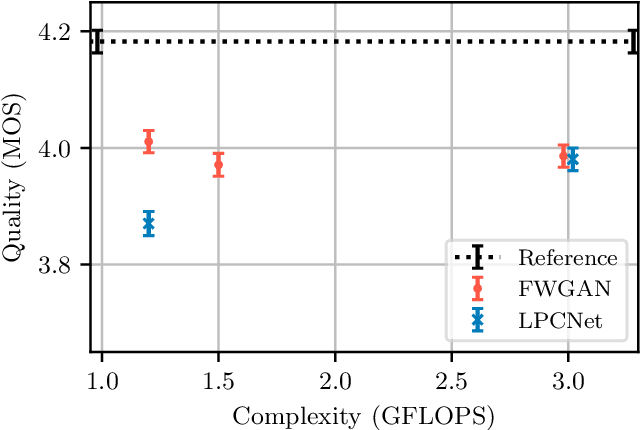
GAN vocoders are currently one of the state-of-the-art methods for building high-quality neural waveform generative models. However, most of their architectures require dozens of billion floating-point operations per second (GFLOPS) to generate speech waveforms in samplewise manner. This makes GAN vocoders still challenging to run on normal CPUs without accelerators or parallel computers. In this work, we propose a new architecture for GAN vocoders that mainly depends on recurrent and fully-connected networks to directly generate the time domain signal in framewise manner. This results in considerable reduction of the computational cost and enables very fast generation on both GPUs and low-complexity CPUs. Experimental results show that our Framewise WaveGAN vocoder achieves significantly higher quality than auto-regressive maximum-likelihood vocoders such as LPCNet at a very low complexity of 1.2 GFLOPS. This makes GAN vocoders more practical on edge and low-power devices.
The Sound of Silence: Efficiency of First Digit Features in Synthetic Audio Detection
Oct 06, 2022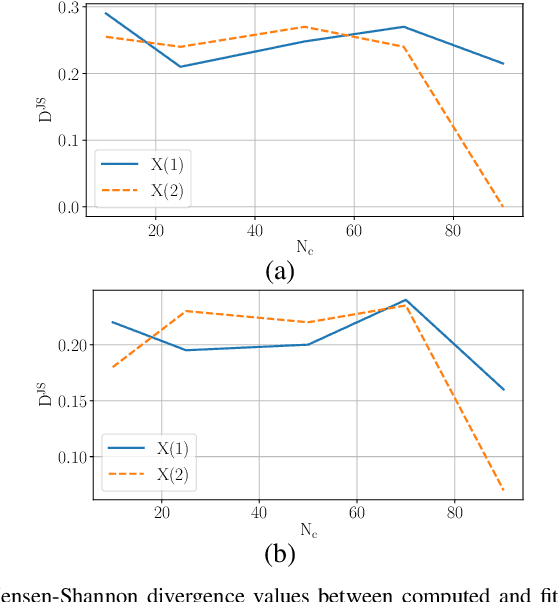
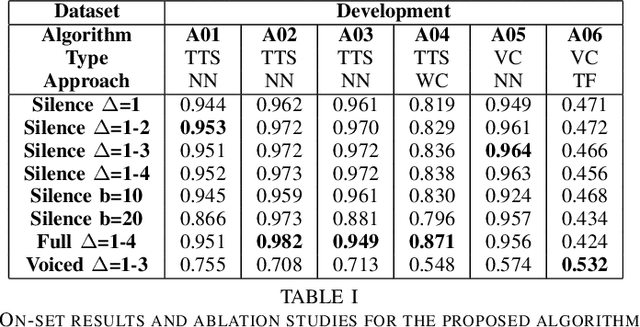
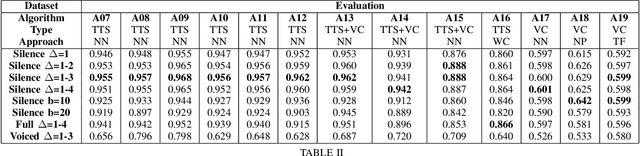
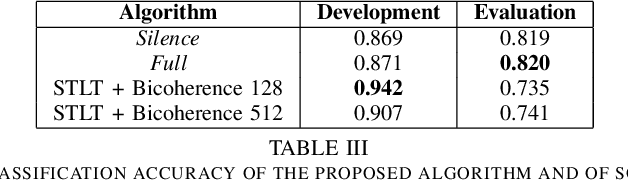
The recent integration of generative neural strategies and audio processing techniques have fostered the widespread of synthetic speech synthesis or transformation algorithms. This capability proves to be harmful in many legal and informative processes (news, biometric authentication, audio evidence in courts, etc.). Thus, the development of efficient detection algorithms is both crucial and challenging due to the heterogeneity of forgery techniques. This work investigates the discriminative role of silenced parts in synthetic speech detection and shows how first digit statistics extracted from MFCC coefficients can efficiently enable a robust detection. The proposed procedure is computationally-lightweight and effective on many different algorithms since it does not rely on large neural detection architecture and obtains an accuracy above 90\% in most of the classes of the ASVSpoof dataset.