 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Analysis and Utilization of Entrainment on Acoustic and Emotion Features in User-agent Dialogue
Dec 07, 2022
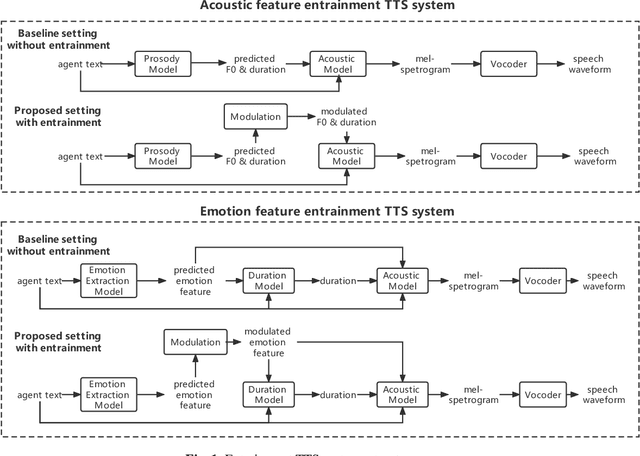
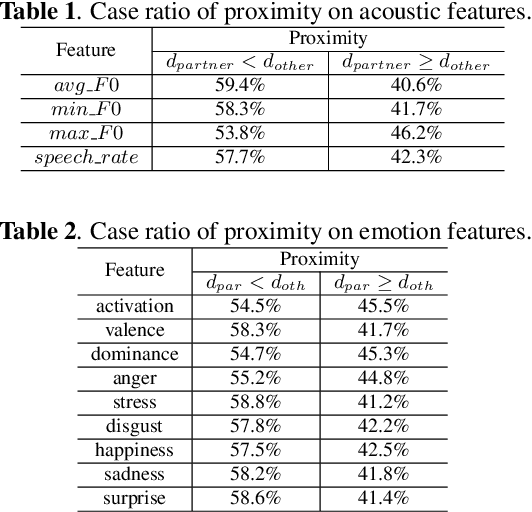
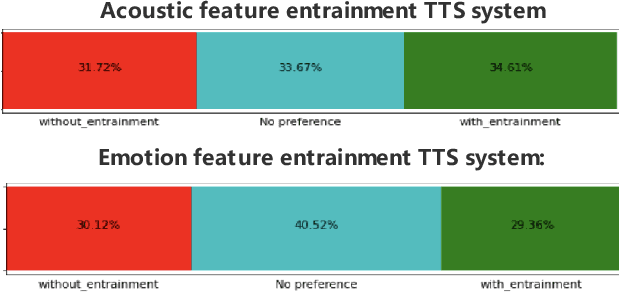
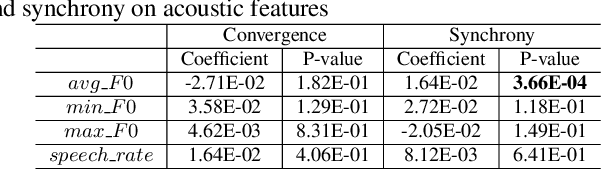
Entrainment is the phenomenon by which an interlocutor adapts their speaking style to align with their partner in conversations. It has been found in different dimensions as acoustic, prosodic, lexical or syntactic. In this work, we explore and utilize the entrainment phenomenon to improve spoken dialogue systems for voice assistants. We first examine the existence of the entrainment phenomenon in human-to-human dialogues in respect to acoustic feature and then extend the analysis to emotion features. The analysis results show strong evidence of entrainment in terms of both acoustic and emotion features. Based on this findings, we implement two entrainment policies and assess if the integration of entrainment principle into a Text-to-Speech (TTS) system improves the synthesis performance and the user experience. It is found that the integration of the entrainment principle into a TTS system brings performance improvement when considering acoustic features, while no obvious improvement is observed when considering emotion features.
Lattice-Free Sequence Discriminative Training for Phoneme-Based Neural Transducers
Dec 07, 2022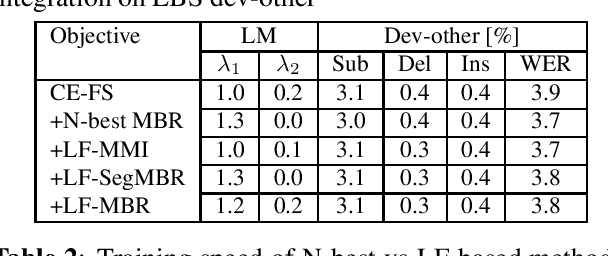
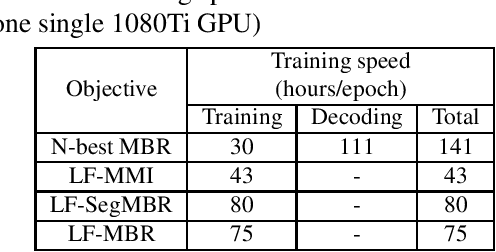
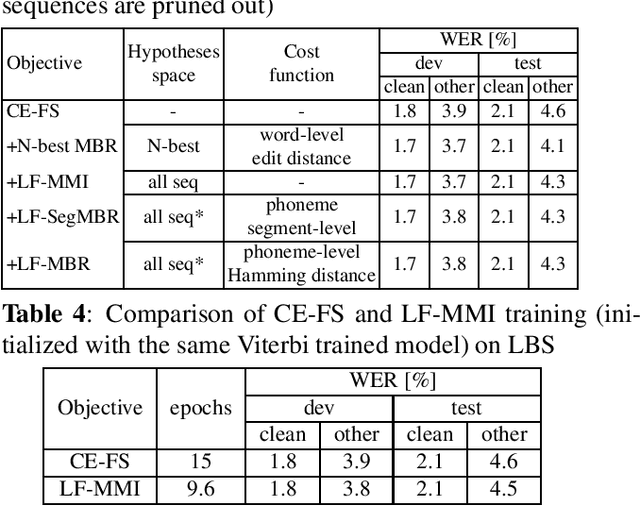
Recently, RNN-Transducers have achieved remarkable results on various automatic speech recognition tasks. However, lattice-free sequence discriminative training methods, which obtain superior performance in hybrid modes, are rarely investigated in RNN-Transducers. In this work, we propose three lattice-free training objectives, namely lattice-free maximum mutual information, lattice-free segment-level minimum Bayes risk, and lattice-free minimum Bayes risk, which are used for the final posterior output of the phoneme-based neural transducer with a limited context dependency. Compared to criteria using N-best lists, lattice-free methods eliminate the decoding step for hypotheses generation during training, which leads to more efficient training. Experimental results show that lattice-free methods gain up to 6.5% relative improvement in word error rate compared to a sequence-level cross-entropy trained model. Compared to the N-best-list based minimum Bayes risk objectives, lattice-free methods gain 40% - 70% relative training time speedup with a small degradation in performance.
CORAA: a large corpus of spontaneous and prepared speech manually validated for speech recognition in Brazilian Portuguese
Oct 14, 2021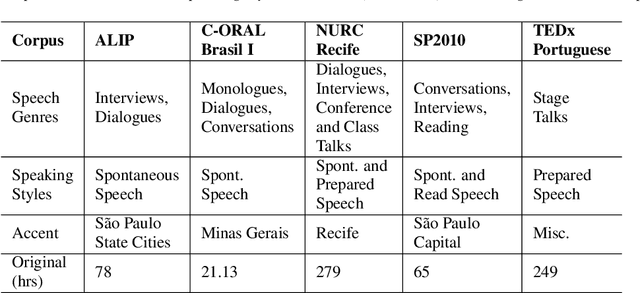
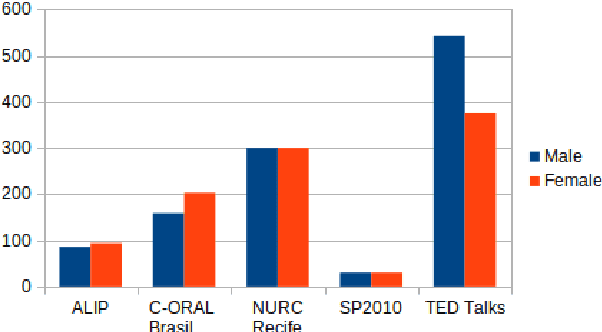
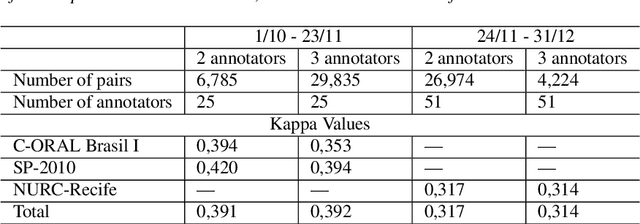
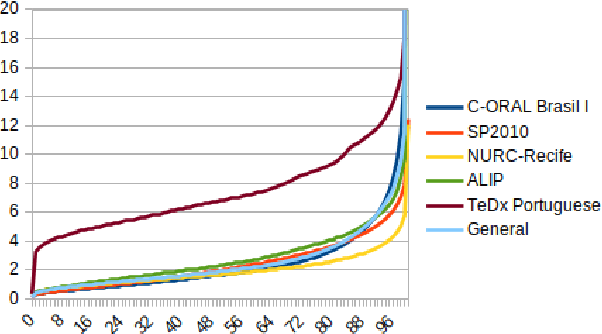
Automatic Speech recognition (ASR) is a complex and challenging task. In recent years, there have been significant advances in the area. In particular, for the Brazilian Portuguese (BP) language, there were about 376 hours public available for ASR task until the second half of 2020. With the release of new datasets in early 2021, this number increased to 574 hours. The existing resources, however, are composed of audios containing only read and prepared speech. There is a lack of datasets including spontaneous speech, which are essential in different ASR applications. This paper presents CORAA (Corpus of Annotated Audios) v1. with 291 hours, a publicly available dataset for ASR in BP containing validated pairs (audio-transcription). CORAA also contains European Portuguese audios (4.69 hours). We also present two public ASR models based on Wav2Vec 2.0 XLSR-53 and fine-tuned over CORAA. Our best model achieved a Word Error Rate of 27.35% on CORAA test set and 16.01% on Common Voice test set. When measuring the Character Error Rate, we obtained 14.26% and 5.45% for CORAA and Common Voice, respectively. CORAA corpora were assembled to both improve ASR models in BP with phenomena from spontaneous speech and motivate young researchers to start their studies on ASR for Portuguese. All the corpora are publicly available at https://github.com/nilc-nlp/CORAA under the CC BY-NC-ND 4.0 license.
Gated Recurrent Neural Networks with Weighted Time-Delay Feedback
Dec 01, 2022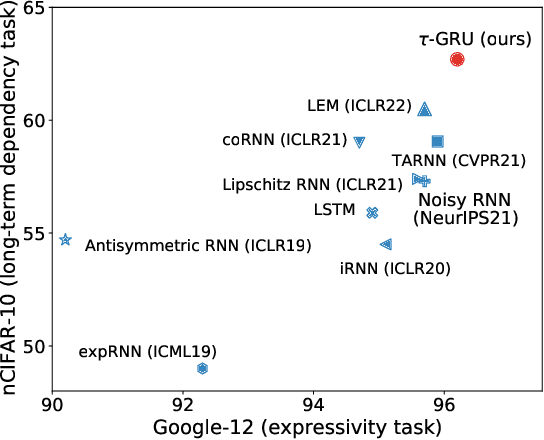
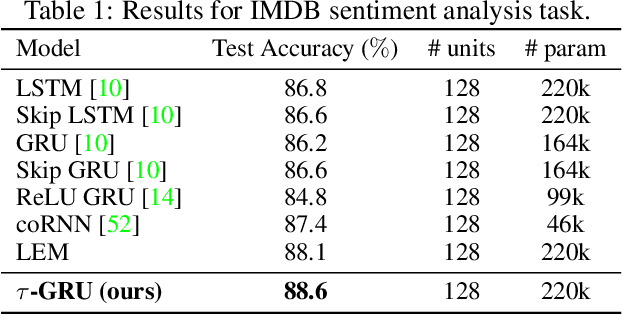
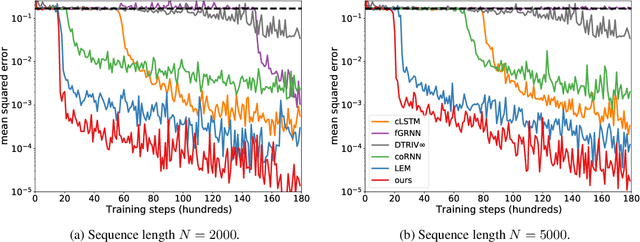
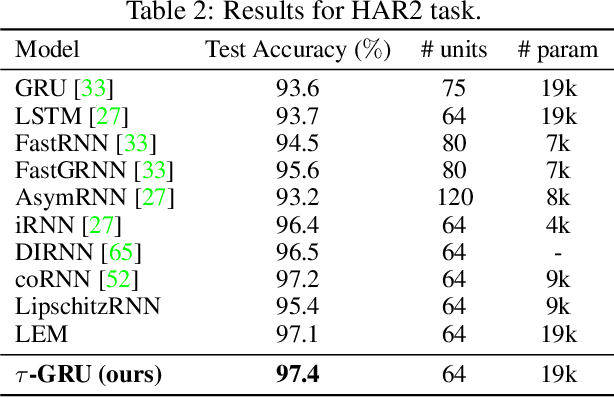
We introduce a novel gated recurrent unit (GRU) with a weighted time-delay feedback mechanism in order to improve the modeling of long-term dependencies in sequential data. This model is a discretized version of a continuous-time formulation of a recurrent unit, where the dynamics are governed by delay differential equations (DDEs). By considering a suitable time-discretization scheme, we propose $\tau$-GRU, a discrete-time gated recurrent unit with delay. We prove the existence and uniqueness of solutions for the continuous-time model, and we demonstrate that the proposed feedback mechanism can help improve the modeling of long-term dependencies. Our empirical results show that $\tau$-GRU can converge faster and generalize better than state-of-the-art recurrent units and gated recurrent architectures on a range of tasks, including time-series classification, human activity recognition, and speech recognition.
Foundation Transformers
Oct 12, 2022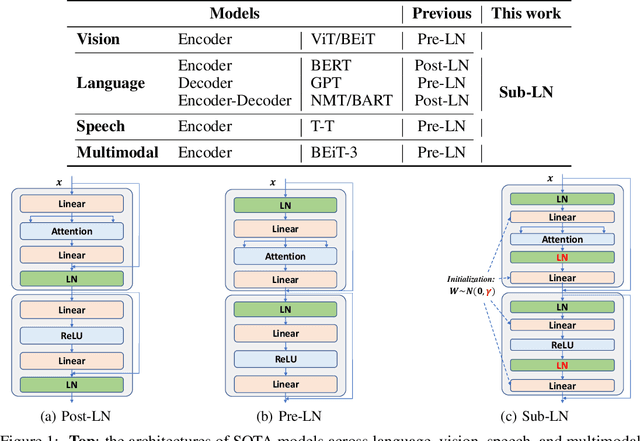
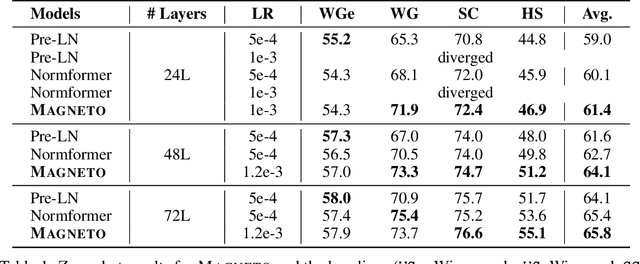
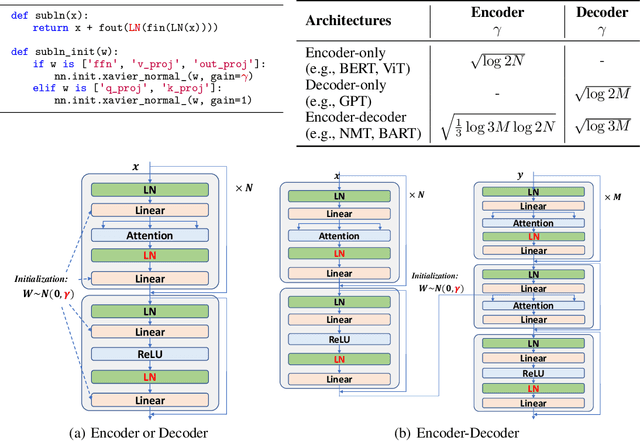
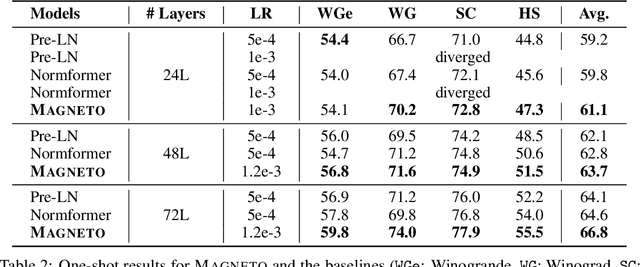
A big convergence of model architectures across language, vision, speech, and multimodal is emerging. However, under the same name "Transformers", the above areas use different implementations for better performance, e.g., Post-LayerNorm for BERT, and Pre-LayerNorm for GPT and vision Transformers. We call for the development of Foundation Transformer for true general-purpose modeling, which serves as a go-to architecture for various tasks and modalities with guaranteed training stability. In this work, we introduce a Transformer variant, named Magneto, to fulfill the goal. Specifically, we propose Sub-LayerNorm for good expressivity, and the initialization strategy theoretically derived from DeepNet for stable scaling up. Extensive experiments demonstrate its superior performance and better stability than the de facto Transformer variants designed for various applications, including language modeling (i.e., BERT, and GPT), machine translation, vision pretraining (i.e., BEiT), speech recognition, and multimodal pretraining (i.e., BEiT-3).
GNN-SL: Sequence Labeling Based on Nearest Examples via GNN
Dec 12, 2022
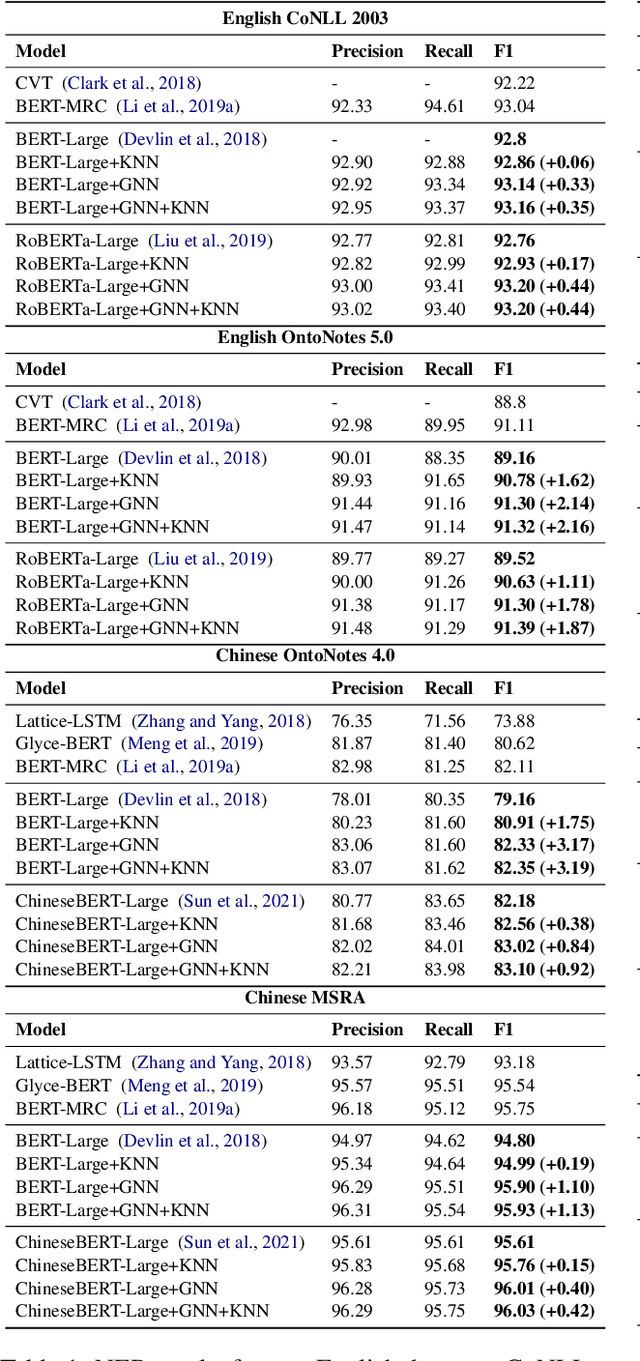
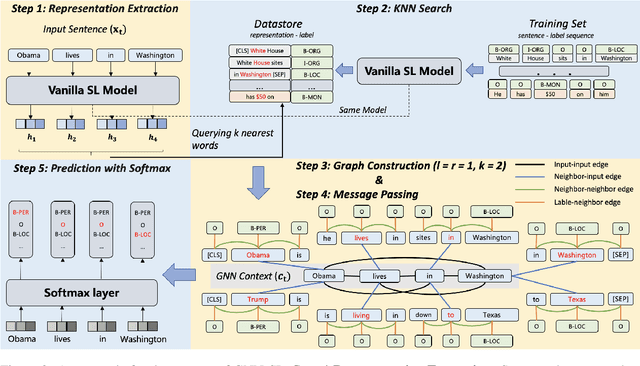
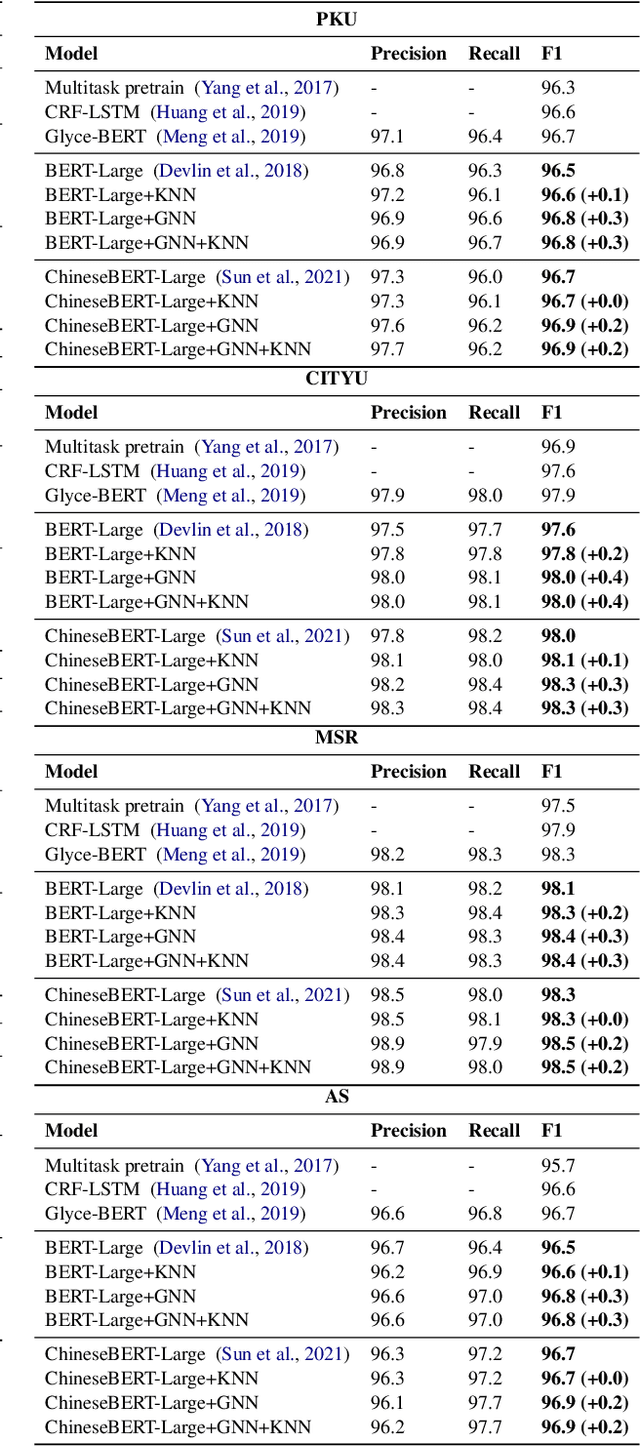
To better handle long-tail cases in the sequence labeling (SL) task, in this work, we introduce graph neural networks sequence labeling (GNN-SL), which augments the vanilla SL model output with similar tagging examples retrieved from the whole training set. Since not all the retrieved tagging examples benefit the model prediction, we construct a heterogeneous graph, and leverage graph neural networks (GNNs) to transfer information between the retrieved tagging examples and the input word sequence. The augmented node which aggregates information from neighbors is used to do prediction. This strategy enables the model to directly acquire similar tagging examples and improves the general quality of predictions. We conduct a variety of experiments on three typical sequence labeling tasks: Named Entity Recognition (NER), Part of Speech Tagging (POS), and Chinese Word Segmentation (CWS) to show the significant performance of our GNN-SL. Notably, GNN-SL achieves SOTA results of 96.9 (+0.2) on PKU, 98.3 (+0.4) on CITYU, 98.5 (+0.2) on MSR, and 96.9 (+0.2) on AS for the CWS task, and results comparable to SOTA performances on NER datasets, and POS datasets.
GIST-AiTeR System for the Diarization Task of the 2022 VoxCeleb Speaker Recognition Challenge
Sep 21, 2022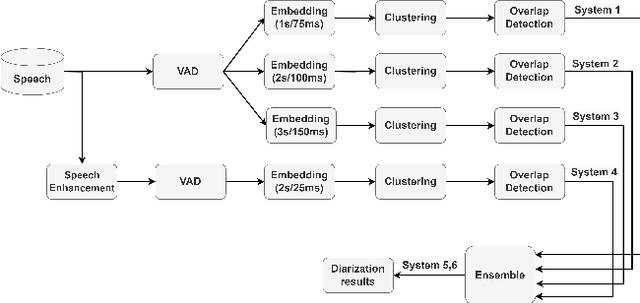
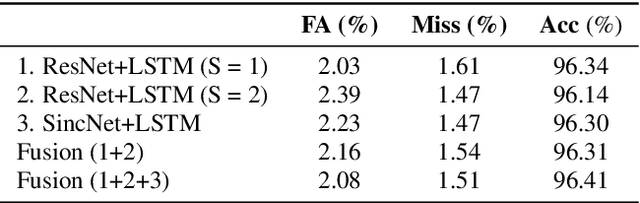
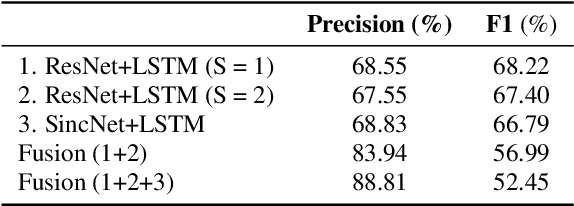
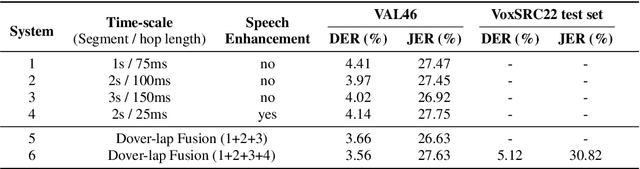
This report describes the submission system of the GIST-AiTeR team at the 2022 VoxCeleb Speaker Recognition Challenge (VoxSRC) Track 4. Our system mainly includes speech enhancement, voice activity detection , multi-scaled speaker embedding, probabilistic linear discriminant analysis-based speaker clustering, and overlapped speech detection models. We first construct four different diarization systems according to different model combinations with the best experimental efforts. Our final submission is an ensemble system of all the four systems and achieves a diarization error rate of 5.12\% on the challenge evaluation set, ranked third at the diarization track of the challenge.
HuBERT-EE: Early Exiting HuBERT for Efficient Speech Recognition
Apr 13, 2022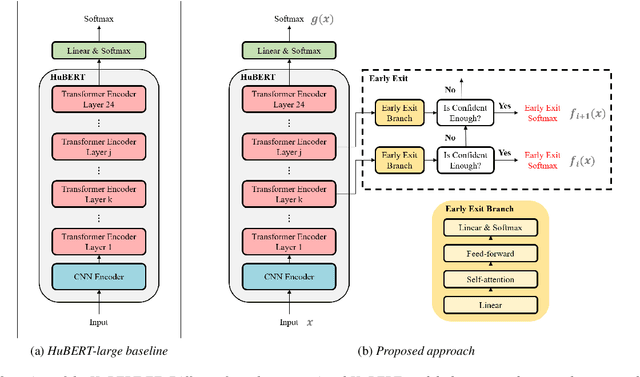
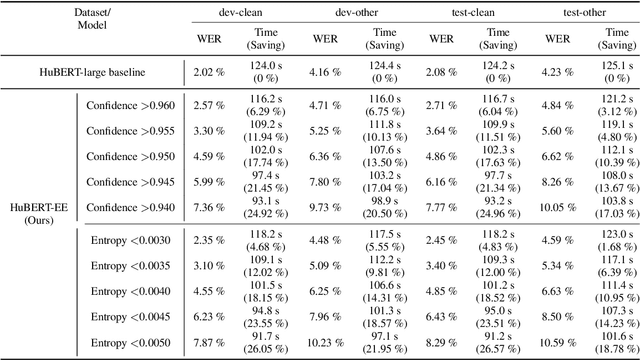

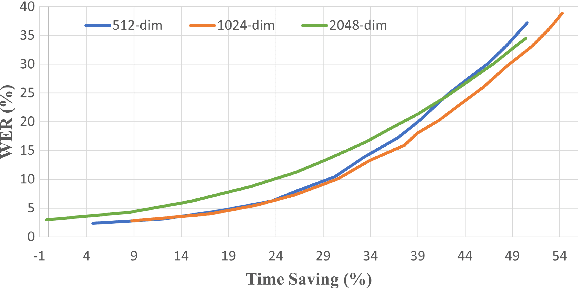
Pre-training with self-supervised models, such as Hidden-unit BERT (HuBERT) and wav2vec 2.0, has brought significant improvements in automatic speech recognition (ASR). However, these models usually require an expensive computational cost to achieve outstanding performance, slowing down the inference speed. To improve the model efficiency, we propose an early exit scheme for ASR, namely HuBERT-EE, that allows the model to stop the inference dynamically. In HuBERT-EE, multiple early exit branches are added at the intermediate layers, and each branch is used to decide whether a prediction can be exited early. Experimental results on the LibriSpeech dataset show that HuBERT-EE can accelerate the inference of a large-scale HuBERT model while simultaneously balancing the trade-off between the word error rate (WER) performance and the latency.
Synt++: Utilizing Imperfect Synthetic Data to Improve Speech Recognition
Oct 21, 2021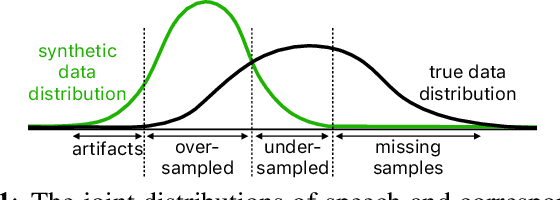
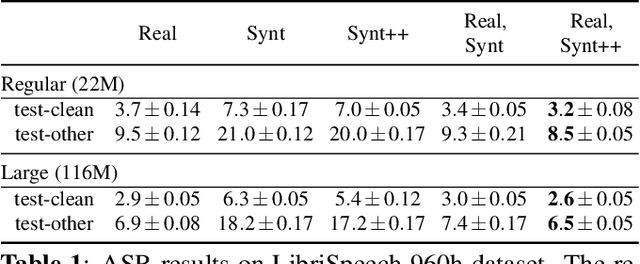
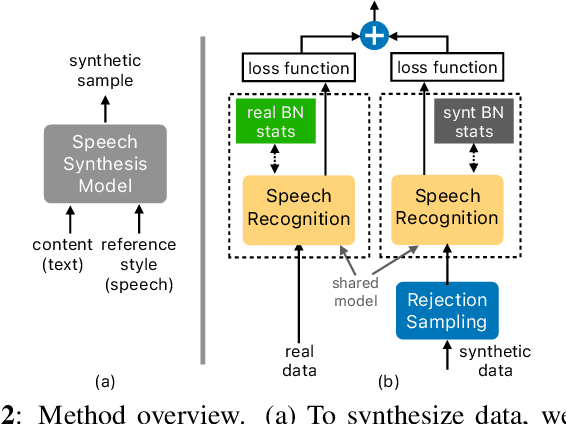
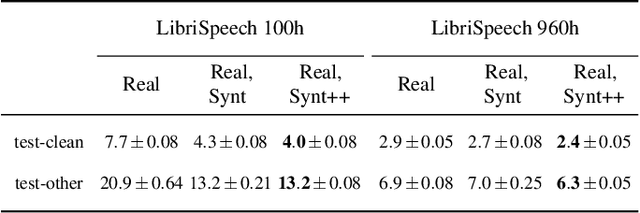
With recent advances in speech synthesis, synthetic data is becoming a viable alternative to real data for training speech recognition models. However, machine learning with synthetic data is not trivial due to the gap between the synthetic and the real data distributions. Synthetic datasets may contain artifacts that do not exist in real data such as structured noise, content errors, or unrealistic speaking styles. Moreover, the synthesis process may introduce a bias due to uneven sampling of the data manifold. We propose two novel techniques during training to mitigate the problems due to the distribution gap: (i) a rejection sampling algorithm and (ii) using separate batch normalization statistics for the real and the synthetic samples. We show that these methods significantly improve the training of speech recognition models using synthetic data. We evaluate the proposed approach on keyword detection and Automatic Speech Recognition (ASR) tasks, and observe up to 18% and 13% relative error reduction, respectively, compared to naively using the synthetic data.
Domain Adaptation and Autoencoder Based Unsupervised Speech Enhancement
Dec 09, 2021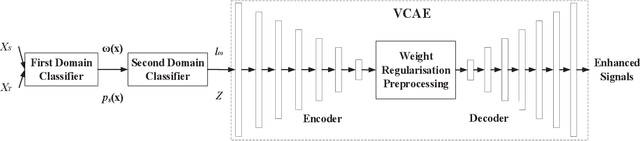
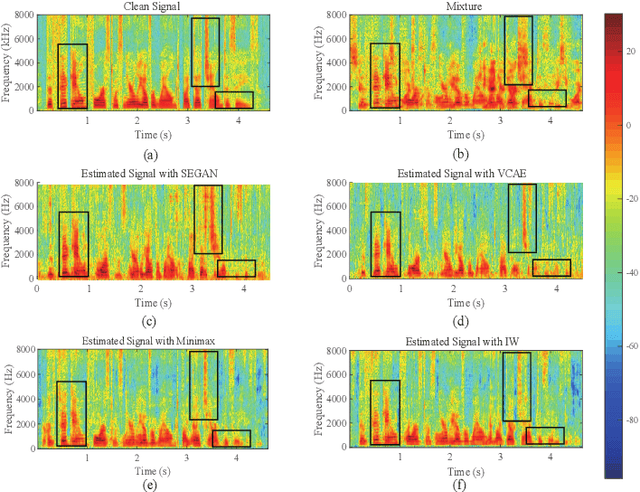
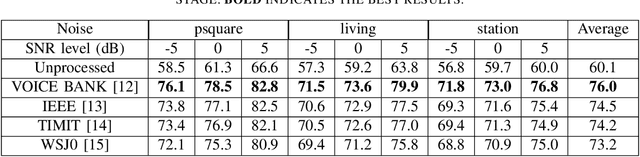
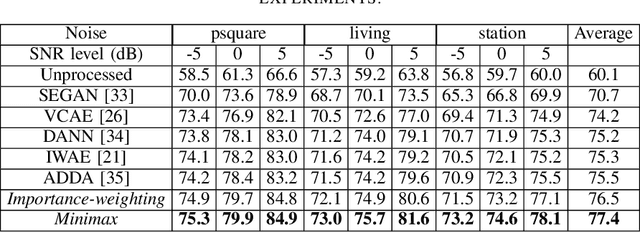
As a category of transfer learning, domain adaptation plays an important role in generalizing the model trained in one task and applying it to other similar tasks or settings. In speech enhancement, a well-trained acoustic model can be exploited to obtain the speech signal in the context of other languages, speakers, and environments. Recent domain adaptation research was developed more effectively with various neural networks and high-level abstract features. However, the related studies are more likely to transfer the well-trained model from a rich and more diverse domain to a limited and similar domain. Therefore, in this study, the domain adaptation method is proposed in unsupervised speech enhancement for the opposite circumstance that transferring to a larger and richer domain. On the one hand, the importance-weighting (IW) approach is exploited with a variance constrained autoencoder to reduce the shift of shared weights between the source and target domains. On the other hand, in order to train the classifier with the worst-case weights and minimize the risk, the minimax method is proposed. Both the proposed IW and minimax methods are evaluated from the VOICE BANK and IEEE datasets to the TIMIT dataset. The experiment results show that the proposed methods outperform the state-of-the-art approaches.