 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Sub-8-Bit Quantization Aware Training for 8-Bit Neural Network Accelerator with On-Device Speech Recognition
Jun 30, 2022
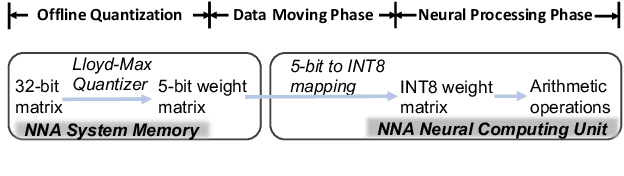
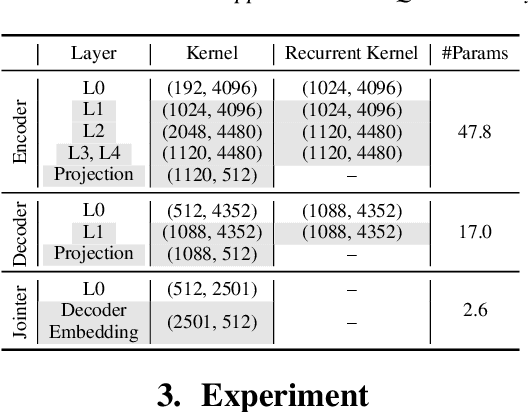
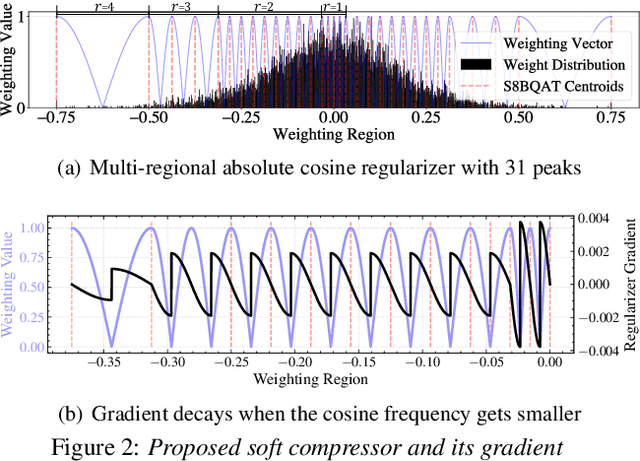
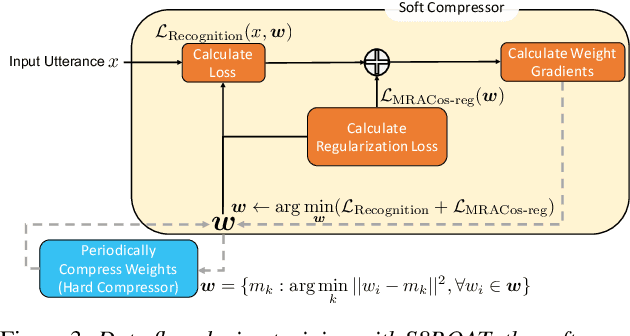
We present a novel sub-8-bit quantization-aware training (S8BQAT) scheme for 8-bit neural network accelerators. Our method is inspired from Lloyd-Max compression theory with practical adaptations for a feasible computational overhead during training. With the quantization centroids derived from a 32-bit baseline, we augment training loss with a Multi-Regional Absolute Cosine (MRACos) regularizer that aggregates weights towards their nearest centroid, effectively acting as a pseudo compressor. Additionally, a periodically invoked hard compressor is introduced to improve the convergence rate by emulating runtime model weight quantization. We apply S8BQAT on speech recognition tasks using Recurrent Neural NetworkTransducer (RNN-T) architecture. With S8BQAT, we are able to increase the model parameter size to reduce the word error rate by 4-16% relatively, while still improving latency by 5%.
Bangla hate speech detection on social media using attention-based recurrent neural network
Mar 31, 2022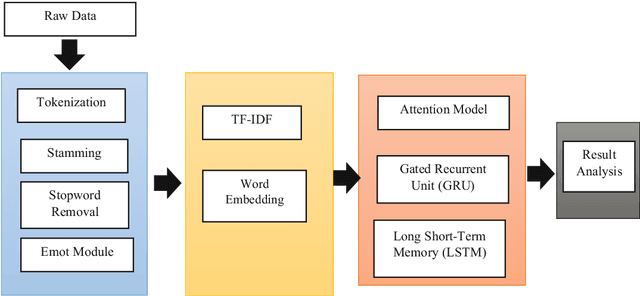

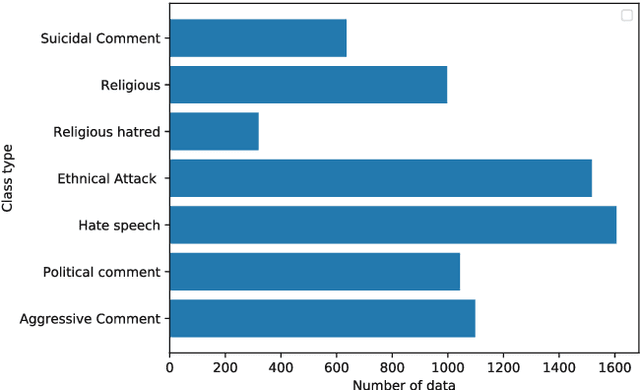

Hate speech has spread more rapidly through the daily use of technology and, most notably, by sharing your opinions or feelings on social media in a negative aspect. Although numerous works have been carried out in detecting hate speeches in English, German, and other languages, very few works have been carried out in the context of the Bengali language. In contrast, millions of people communicate on social media in Bengali. The few existing works that have been carried out need improvements in both accuracy and interpretability. This article proposed encoder decoder based machine learning model, a popular tool in NLP, to classify user's Bengali comments on Facebook pages. A dataset of 7,425 Bengali comments, consisting of seven distinct categories of hate speeches, was used to train and evaluate our model. For extracting and encoding local features from the comments, 1D convolutional layers were used. Finally, the attention mechanism, LSTM, and GRU based decoders have been used for predicting hate speech categories. Among the three encoder decoder algorithms, the attention-based decoder obtained the best accuracy (77%).
FeaRLESS: Feature Refinement Loss for Ensembling Self-Supervised Learning Features in Robust End-to-end Speech Recognition
Jun 30, 2022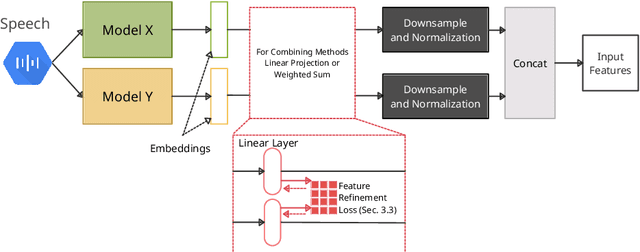
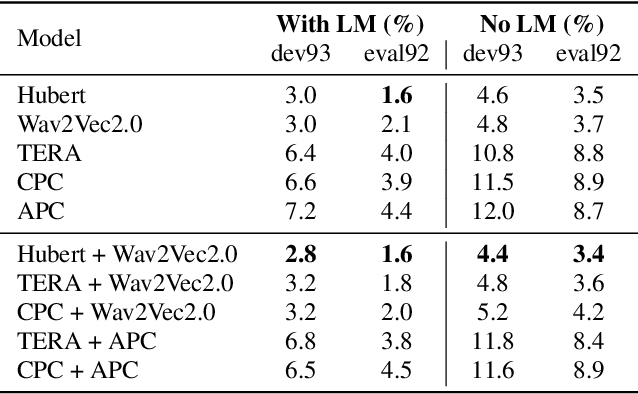
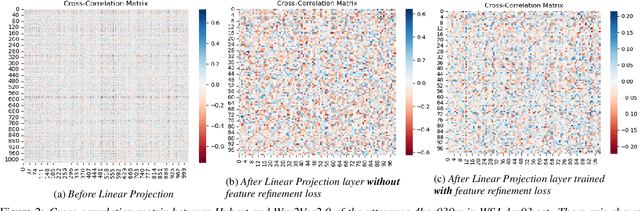
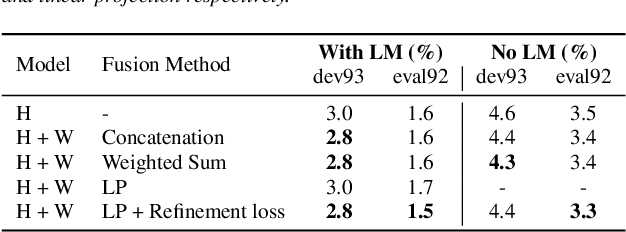
Self-supervised learning representations (SSLR) have resulted in robust features for downstream tasks in many fields. Recently, several SSLRs have shown promising results on automatic speech recognition (ASR) benchmark corpora. However, previous studies have only shown performance for solitary SSLRs as an input feature for ASR models. In this study, we propose to investigate the effectiveness of diverse SSLR combinations using various fusion methods within end-to-end (E2E) ASR models. In addition, we will show there are correlations between these extracted SSLRs. As such, we further propose a feature refinement loss for decorrelation to efficiently combine the set of input features. For evaluation, we show that the proposed 'FeaRLESS learning features' perform better than systems without the proposed feature refinement loss for both the WSJ and Fearless Steps Challenge (FSC) corpora.
Lisan: Yemenu, Irqi, Libyan, and Sudanese Arabic Dialect Copora with Morphological Annotations
Dec 13, 2022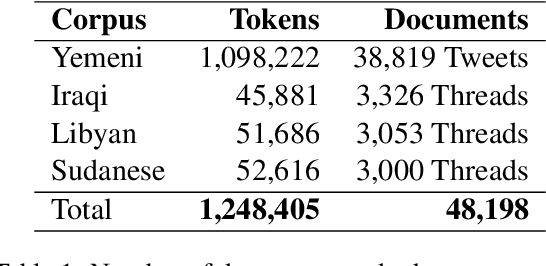
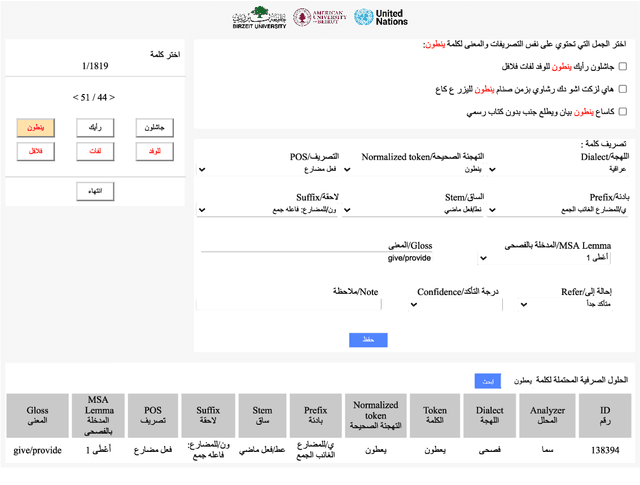
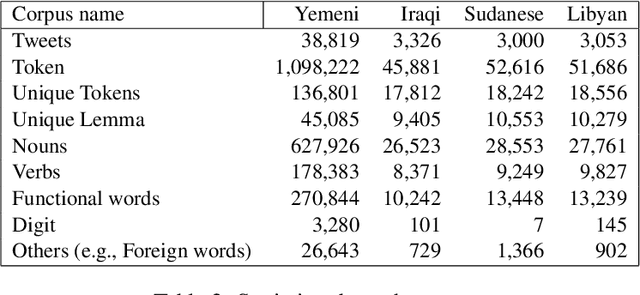
This article presents morphologically-annotated Yemeni, Sudanese, Iraqi, and Libyan Arabic dialects Lisan corpora. Lisan features around 1.2 million tokens. We collected the content of the corpora from several social media platforms. The Yemeni corpus (~ 1.05M tokens) was collected automatically from Twitter. The corpora of the other three dialects (~ 50K tokens each) came manually from Facebook and YouTube posts and comments. Thirty five (35) annotators who are native speakers of the target dialects carried out the annotations. The annotators segemented all words in the four corpora into prefixes, stems and suffixes and labeled each with different morphological features such as part of speech, lemma, and a gloss in English. An Arabic Dialect Annotation Toolkit ADAT was developped for the purpose of the annation. The annotators were trained on a set of guidelines and on how to use ADAT. We developed ADAT to assist the annotators and to ensure compatibility with SAMA and Curras tagsets. The tool is open source, and the four corpora are also available online.
How Much Does Prosody Help Turn-taking? Investigations using Voice Activity Projection Models
Sep 12, 2022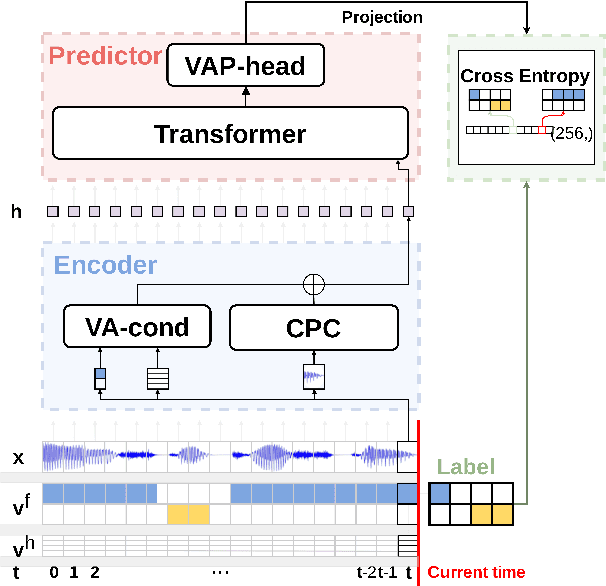

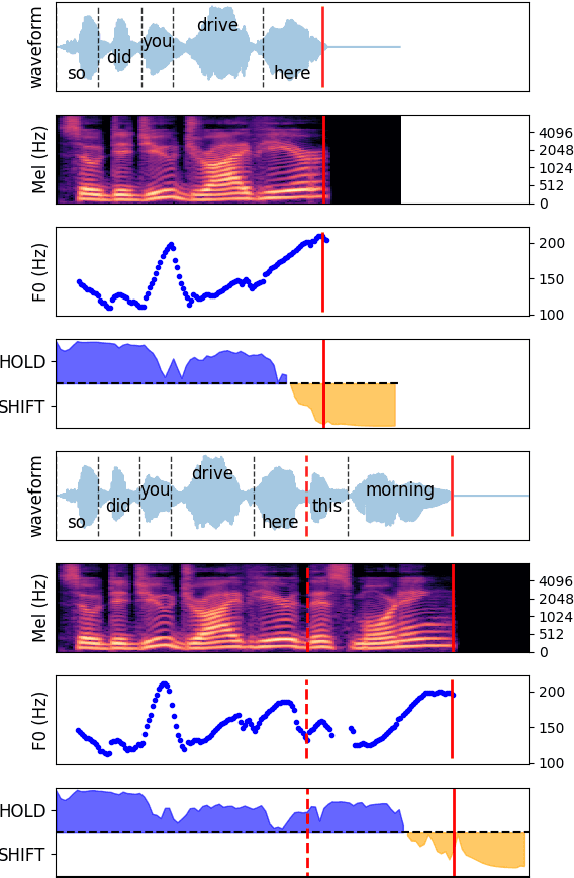
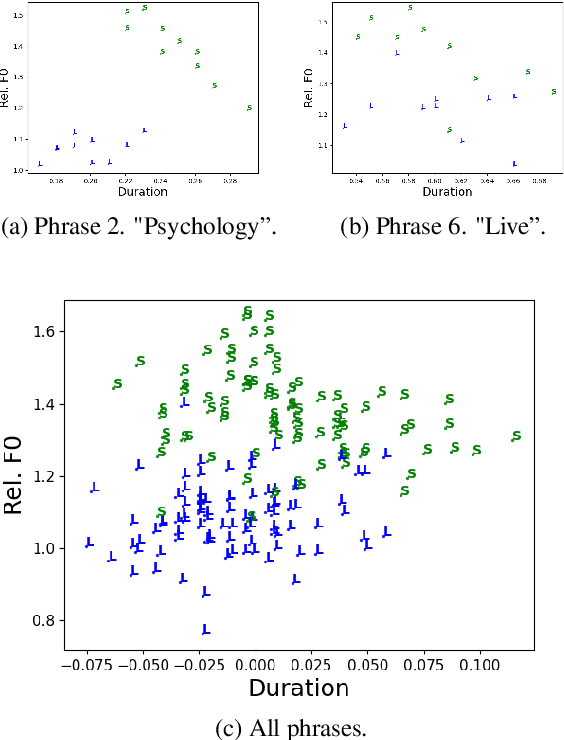
Turn-taking is a fundamental aspect of human communication and can be described as the ability to take turns, project upcoming turn shifts, and supply backchannels at appropriate locations throughout a conversation. In this work, we investigate the role of prosody in turn-taking using the recently proposed Voice Activity Projection model, which incrementally models the upcoming speech activity of the interlocutors in a self-supervised manner, without relying on explicit annotation of turn-taking events, or the explicit modeling of prosodic features. Through manipulation of the speech signal, we investigate how these models implicitly utilize prosodic information. We show that these systems learn to utilize various prosodic aspects of speech both on aggregate quantitative metrics of long-form conversations and on single utterances specifically designed to depend on prosody.
Hierarchical Softmax for End-to-End Low-resource Multilingual Speech Recognition
Apr 08, 2022
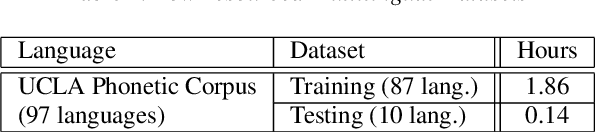
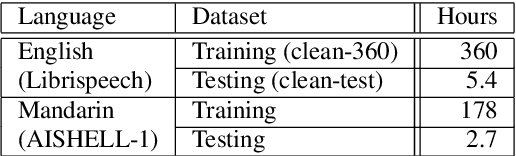
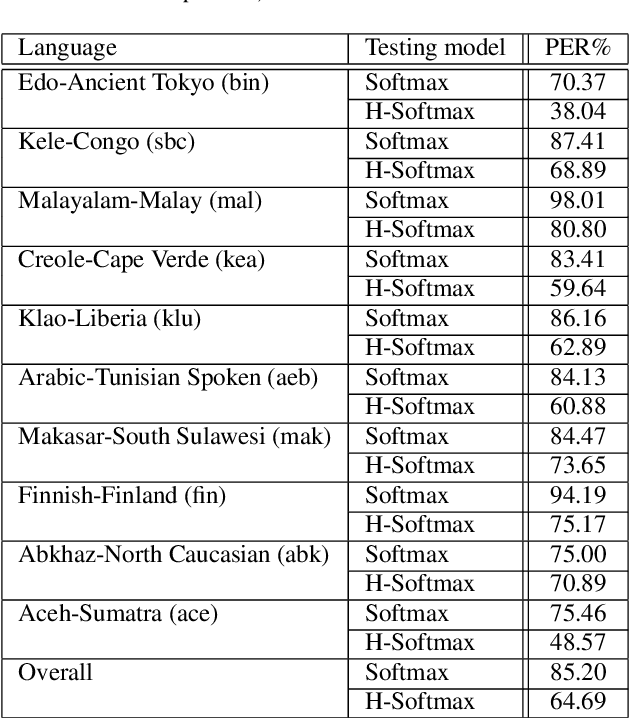
Low resource speech recognition has been long-suffering from insufficient training data. While neighbour languages are often used as assistant training data, it would be difficult for the model to induct similar units (character, subword, etc.) across the languages. In this paper, we assume similar units in neighbour language share similar term frequency and form a Huffman tree to perform multi-lingual hierarchical Softmax decoding. During decoding, the hierarchical structure can benefit the training of low-resource languages. Experimental results show the effectiveness of our method.
Subjective intelligibility of speech sounds enhanced by ideal ratio mask via crowdsourced remote experiments with effective data screening
Mar 31, 2022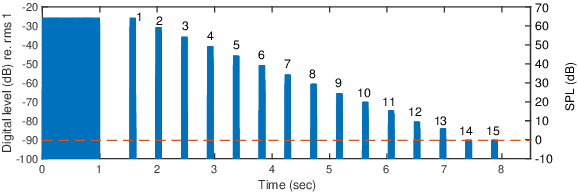
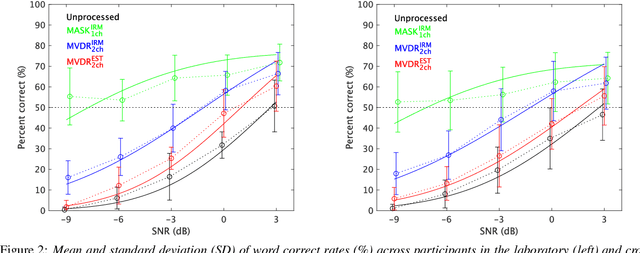
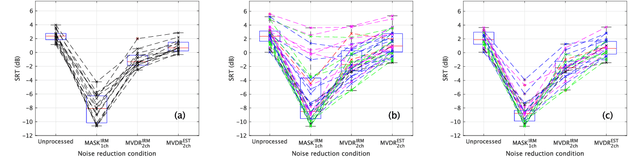
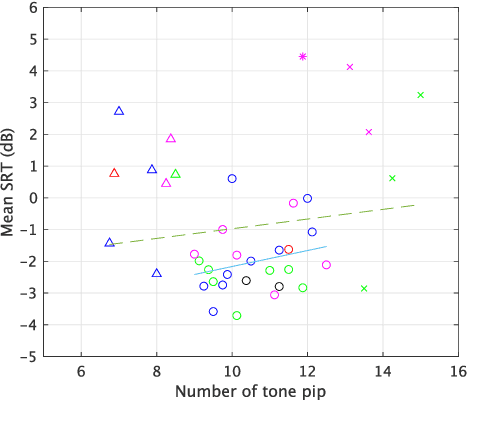
It is essential to perform speech intelligibility (SI) experiments with human listeners to evaluate the effectiveness of objective intelligibility measures. Recently crowdsourced remote testing has become popular to collect a massive amount and variety of data with relatively small cost and in short time. However, careful data screening is essential for attaining reliable SI data. We compared the results of laboratory and crowdsourced remote experiments to establish an effective data screening technique. We evaluated the SI of noisy speech sounds enhanced by a single-channel ideal ratio mask (IRM) and multi-channel mask-based beamformers. The results demonstrated that the SI scores were improved by these enhancement methods. In particular, the IRM-enhanced sounds were much better than the unprocessed and other enhanced sounds, indicating IRM enhancement may give the upper limit of speech enhancement performance. Moreover, tone pip tests, for which participants were asked to report the number of audible tone pips, reduced the variability of crowdsourced remote results so that the laboratory results became similar. Tone pip tests could be useful for future crowdsourced experiments because of their simplicity and effectiveness for data screening.
Speech Representation Learning Through Self-supervised Pretraining And Multi-task Finetuning
Oct 18, 2021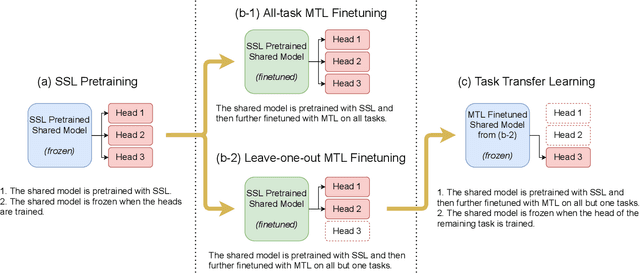
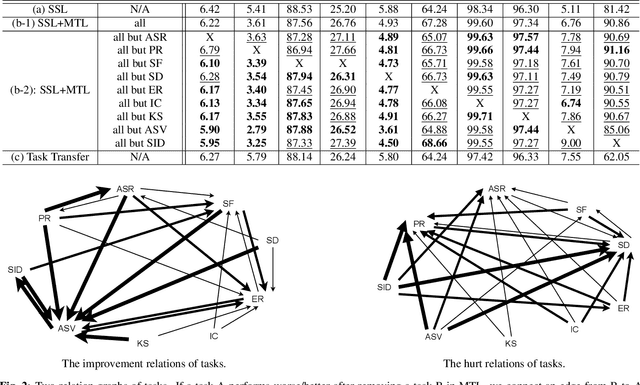
Speech representation learning plays a vital role in speech processing. Among them, self-supervised learning (SSL) has become an important research direction. It has been shown that an SSL pretraining model can achieve excellent performance in various downstream tasks of speech processing. On the other hand, supervised multi-task learning (MTL) is another representation learning paradigm, which has been proven effective in computer vision (CV) and natural language processing (NLP). However, there is no systematic research on the general representation learning model trained by supervised MTL in speech processing. In this paper, we show that MTL finetuning can further improve SSL pretraining. We analyze the generalizability of supervised MTL finetuning to examine if the speech representation learned by MTL finetuning can generalize to unseen new tasks.
Annealing Double-Head: An Architecture for Online Calibration of Deep Neural Networks
Dec 27, 2022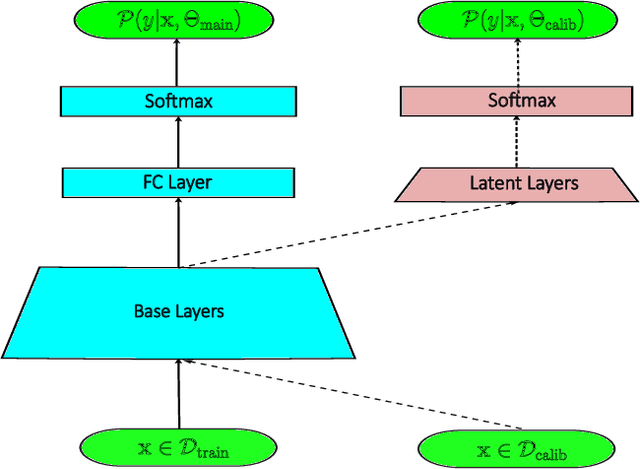
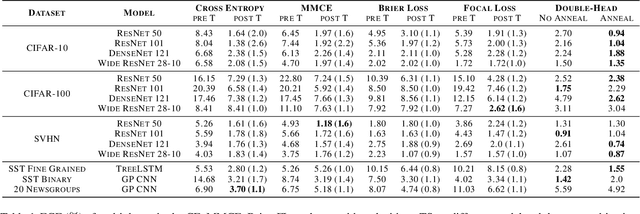
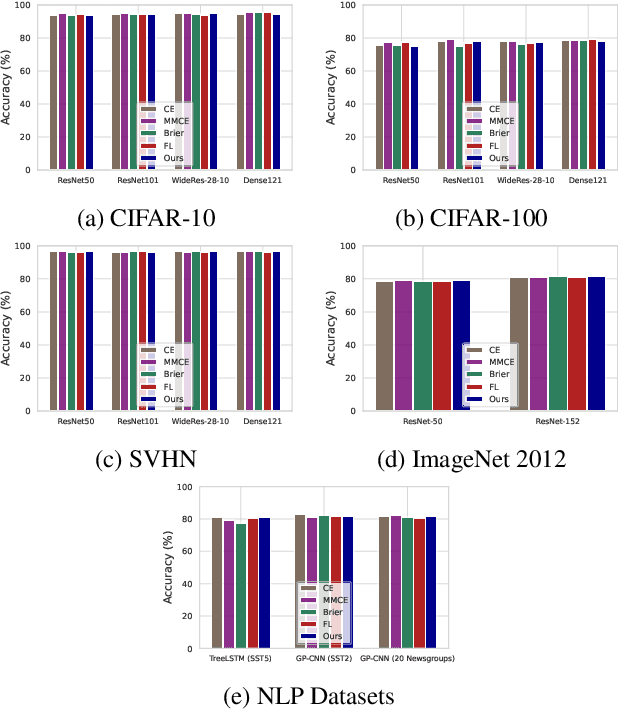

Model calibration, which is concerned with how frequently the model predicts correctly, not only plays a vital part in statistical model design, but also has substantial practical applications, such as optimal decision-making in the real world. However, it has been discovered that modern deep neural networks are generally poorly calibrated due to the overestimation (or underestimation) of predictive confidence, which is closely related to overfitting. In this paper, we propose Annealing Double-Head, a simple-to-implement but highly effective architecture for calibrating the DNN during training. To be precise, we construct an additional calibration head-a shallow neural network that typically has one latent layer-on top of the last latent layer in the normal model to map the logits to the aligned confidence. Furthermore, a simple Annealing technique that dynamically scales the logits by calibration head in training procedure is developed to improve its performance. Under both the in-distribution and distributional shift circumstances, we exhaustively evaluate our Annealing Double-Head architecture on multiple pairs of contemporary DNN architectures and vision and speech datasets. We demonstrate that our method achieves state-of-the-art model calibration performance without post-processing while simultaneously providing comparable predictive accuracy in comparison to other recently proposed calibration methods on a range of learning tasks.
Supervised Attention in Sequence-to-Sequence Models for Speech Recognition
Apr 25, 2022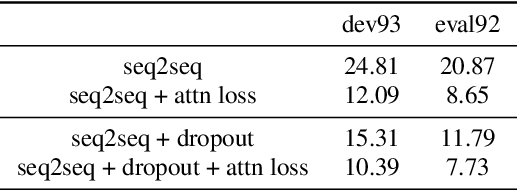
Attention mechanism in sequence-to-sequence models is designed to model the alignments between acoustic features and output tokens in speech recognition. However, attention weights produced by models trained end to end do not always correspond well with actual alignments, and several studies have further argued that attention weights might not even correspond well with the relevance attribution of frames. Regardless, visual similarity between attention weights and alignments is widely used during training as an indicator of the models quality. In this paper, we treat the correspondence between attention weights and alignments as a learning problem by imposing a supervised attention loss. Experiments have shown significant improved performance, suggesting that learning the alignments well during training critically determines the performance of sequence-to-sequence models.