 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SVLDL: Improved Speaker Age Estimation Using Selective Variance Label Distribution Learning
Oct 18, 2022
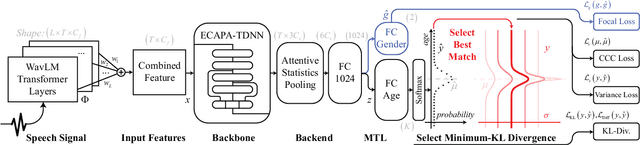
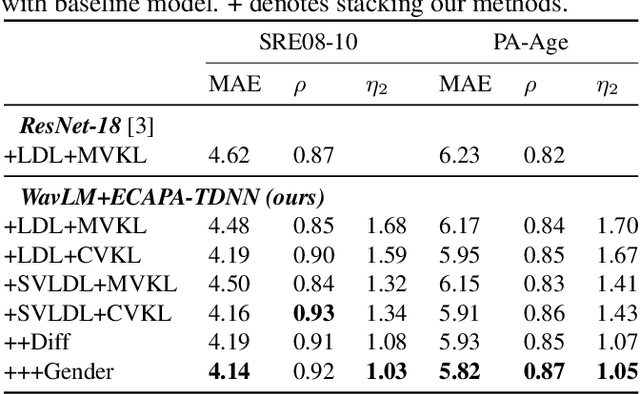
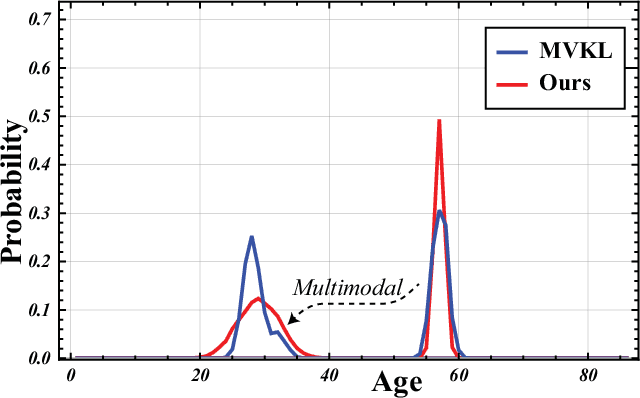

Estimating age from a single speech is a classic and challenging topic. Although Label Distribution Learning (LDL) can represent adjacent indistinguishable ages well, the uncertainty of the age estimate for each utterance varies from person to person, i.e., the variance of the age distribution is different. To address this issue, we propose selective variance label distribution learning (SVLDL) method to adapt the variance of different age distributions. Furthermore, the model uses WavLM as the speech feature extractor and adds the auxiliary task of gender recognition to further improve the performance. Two tricks are applied on the loss function to enhance the robustness of the age estimation and improve the quality of the fitted age distribution. Extensive experiments show that the model achieves state-of-the-art performance on all aspects of the NIST SRE08-10 and a real-world datasets.
Prabhupadavani: A Code-mixed Speech Translation Data for 25 Languages
Jan 27, 2022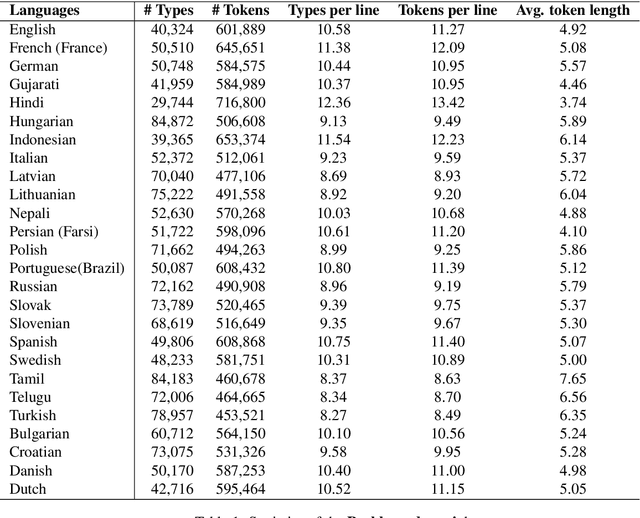
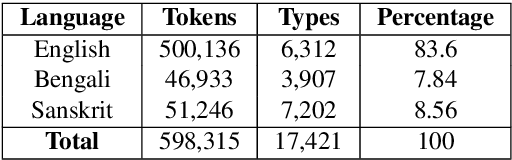


Nowadays, code-mixing has become ubiquitous in Natural Language Processing (NLP); however, no efforts have been made to address this phenomenon for Speech Translation (ST) task. This can be solely attributed to the lack of code-mixed ST task labelled data. Thus, we introduce Prabhupadavani, a multilingual code-mixed ST dataset for 25 languages, covering ten language families, containing 94 hours of speech by 130+ speakers, manually aligned with corresponding text in the target language. Prabhupadvani is the first code-mixed ST dataset available in the ST literature to the best of our knowledge. This data also can be used for a code-mixed machine translation task. All the dataset and code can be accessed at: \url{https://github.com/frozentoad9/CMST}
Revisiting Over-Smoothness in Text to Speech
Feb 26, 2022


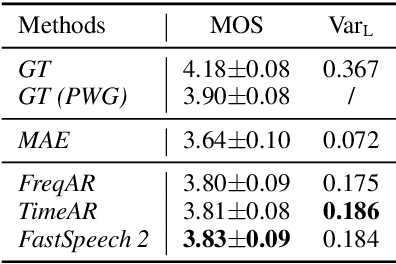
Non-autoregressive text to speech (NAR-TTS) models have attracted much attention from both academia and industry due to their fast generation speed. One limitation of NAR-TTS models is that they ignore the correlation in time and frequency domains while generating speech mel-spectrograms, and thus cause blurry and over-smoothed results. In this work, we revisit this over-smoothing problem from a novel perspective: the degree of over-smoothness is determined by the gap between the complexity of data distributions and the capability of modeling methods. Both simplifying data distributions and improving modeling methods can alleviate the problem. Accordingly, we first study methods reducing the complexity of data distributions. Then we conduct a comprehensive study on NAR-TTS models that use some advanced modeling methods. Based on these studies, we find that 1) methods that provide additional condition inputs reduce the complexity of data distributions to model, thus alleviating the over-smoothing problem and achieving better voice quality. 2) Among advanced modeling methods, Laplacian mixture loss performs well at modeling multimodal distributions and enjoys its simplicity, while GAN and Glow achieve the best voice quality while suffering from increased training or model complexity. 3) The two categories of methods can be combined to further alleviate the over-smoothness and improve the voice quality. 4) Our experiments on the multi-speaker dataset lead to similar conclusions as above and providing more variance information can reduce the difficulty of modeling the target data distribution and alleviate the requirements for model capacity.
Subject Enveloped Deep Sample Fuzzy Ensemble Learning Algorithm of Parkinson's Speech Data
Nov 17, 2021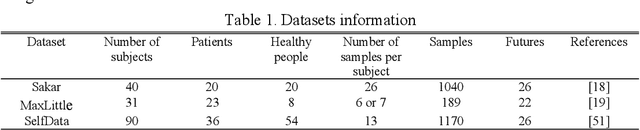
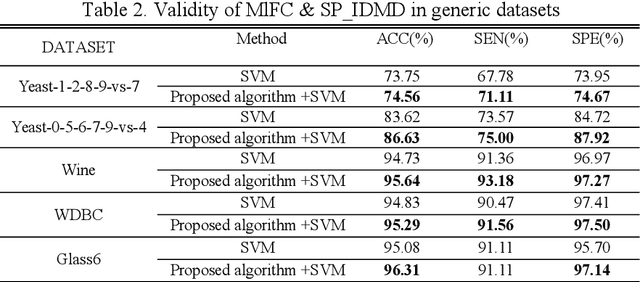

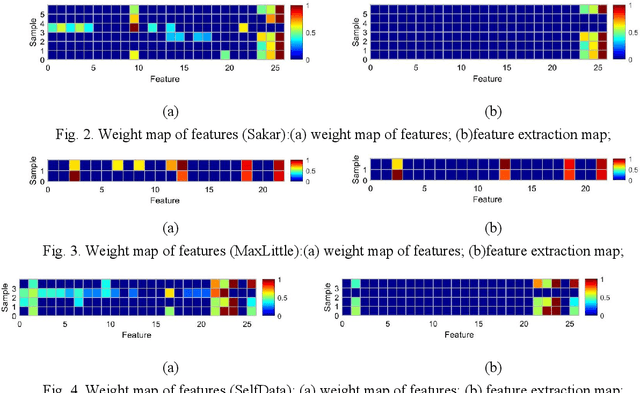
Parkinson disease (PD)'s speech recognition is an effective way for its diagnosis, which has become a hot and difficult research area in recent years. As we know, there are large corpuses (segments) within one subject. However, too large segments will increase the complexity of the classification model. Besides, the clinicians interested in finding diagnostic speech markers that reflect the pathology of the whole subject. Since the optimal relevant features of each speech sample segment are different, it is difficult to find the uniform diagnostic speech markers. Therefore, it is necessary to reconstruct the existing large segments within one subject into few segments even one segment within one subject, which can facilitate the extraction of relevant speech features to characterize diagnostic markers for the whole subject. To address this problem, an enveloped deep speech sample learning algorithm for Parkinson's subjects based on multilayer fuzzy c-mean (MlFCM) clustering and interlayer consistency preservation is proposed in this paper. The algorithm can be used to achieve intra-subject sample reconstruction for Parkinson's disease (PD) to obtain a small number of high-quality prototype sample segments. At the end of the paper, several representative PD speech datasets are selected and compared with the state-of-the-art related methods, respectively. The experimental results show that the proposed algorithm is effective signifcantly.
Enhancing ASR for Stuttered Speech with Limited Data Using Detect and Pass
Feb 08, 2022It is estimated that around 70 million people worldwide are affected by a speech disorder called stuttering. With recent advances in Automatic Speech Recognition (ASR), voice assistants are increasingly useful in our everyday lives. Many technologies in education, retail, telecommunication and healthcare can now be operated through voice. Unfortunately, these benefits are not accessible for People Who Stutter (PWS). We propose a simple but effective method called 'Detect and Pass' to make modern ASR systems accessible for People Who Stutter in a limited data setting. The algorithm uses a context aware classifier trained on a limited amount of data, to detect acoustic frames that contain stutter. To improve robustness on stuttered speech, this extra information is passed on to the ASR model to be utilized during inference. Our experiments show a reduction of 12.18% to 71.24% in Word Error Rate (WER) across various state of the art ASR systems. Upon varying the threshold of the associated posterior probability of stutter for each stacked frame used in determining low frame rate (LFR) acoustic features, we were able to determine an optimal setting that reduced the WER by 23.93% to 71.67% across different ASR systems.
A Feature Extraction based Model for Hate Speech Identification
Jan 11, 2022

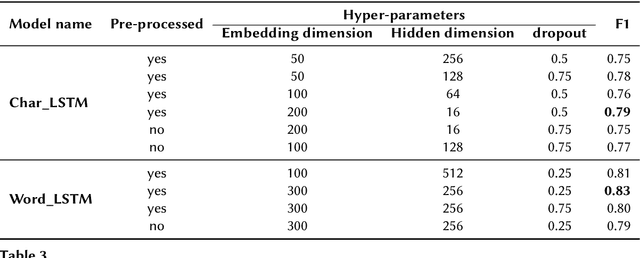

The detection of hate speech online has become an important task, as offensive language such as hurtful, obscene and insulting content can harm marginalized people or groups. This paper presents TU Berlin team experiments and results on the task 1A and 1B of the shared task on hate speech and offensive content identification in Indo-European languages 2021. The success of different Natural Language Processing models is evaluated for the respective subtasks throughout the competition. We tested different models based on recurrent neural networks in word and character levels and transfer learning approaches based on Bert on the provided dataset by the competition. Among the tested models that have been used for the experiments, the transfer learning-based models achieved the best results in both subtasks.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021
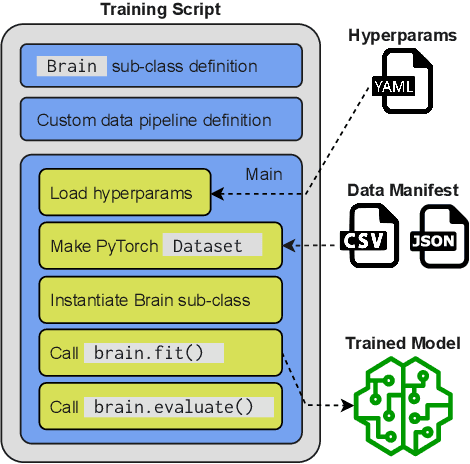

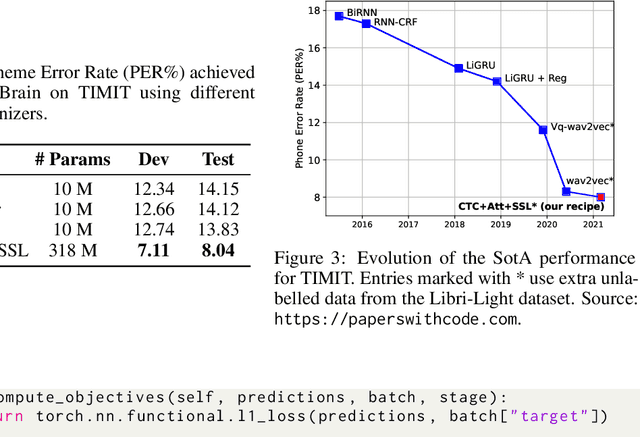
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
Unsupervised Personalization of an Emotion Recognition System: The Unique Properties of the Externalization of Valence in Speech
Jan 19, 2022
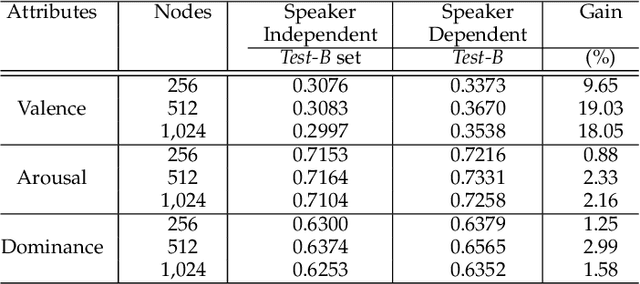
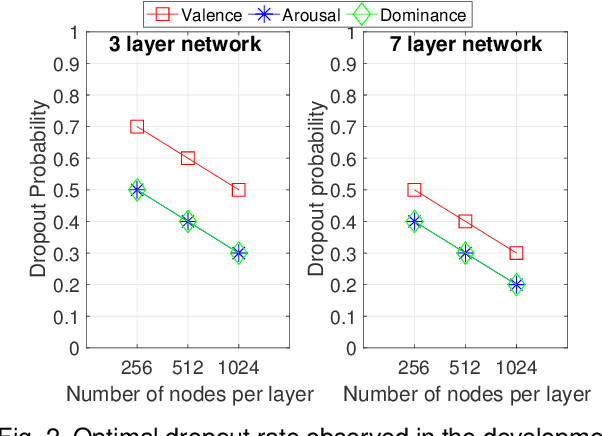
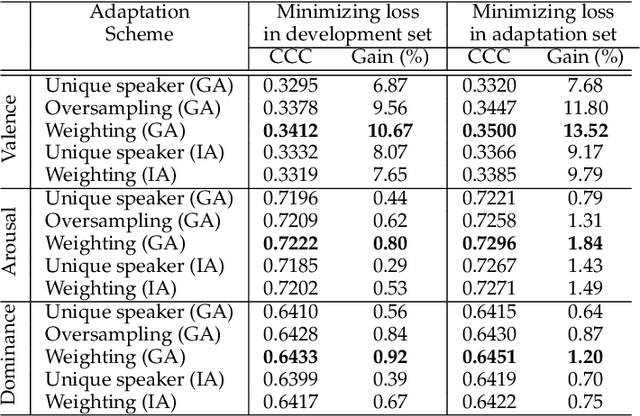
The prediction of valence from speech is an important, but challenging problem. The externalization of valence in speech has speaker-dependent cues, which contribute to performances that are often significantly lower than the prediction of other emotional attributes such as arousal and dominance. A practical approach to improve valence prediction from speech is to adapt the models to the target speakers in the test set. Adapting a speech emotion recognition (SER) system to a particular speaker is a hard problem, especially with deep neural networks (DNNs), since it requires optimizing millions of parameters. This study proposes an unsupervised approach to address this problem by searching for speakers in the train set with similar acoustic patterns as the speaker in the test set. Speech samples from the selected speakers are used to create the adaptation set. This approach leverages transfer learning using pre-trained models, which are adapted with these speech samples. We propose three alternative adaptation strategies: unique speaker, oversampling and weighting approaches. These methods differ on the use of the adaptation set in the personalization of the valence models. The results demonstrate that a valence prediction model can be efficiently personalized with these unsupervised approaches, leading to relative improvements as high as 13.52%.
Non-Parallel Voice Conversion for ASR Augmentation
Sep 15, 2022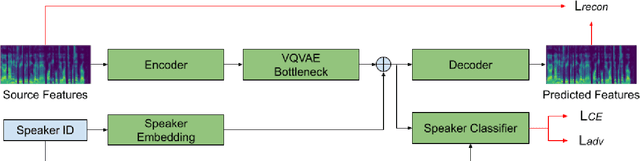
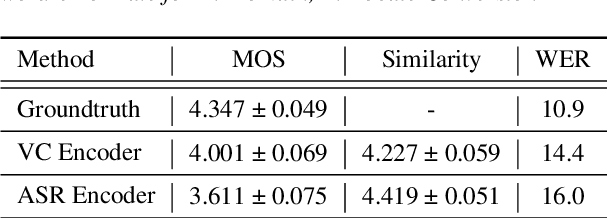
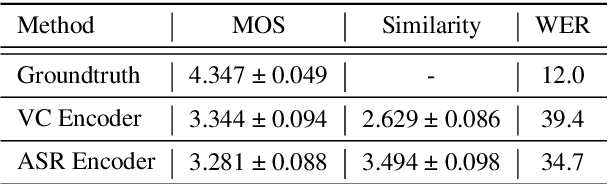
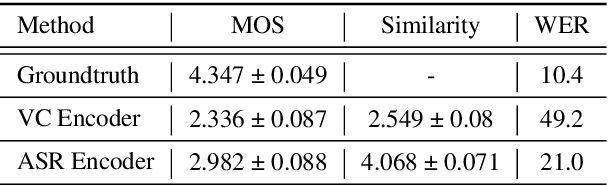
Automatic speech recognition (ASR) needs to be robust to speaker differences. Voice Conversion (VC) modifies speaker characteristics of input speech. This is an attractive feature for ASR data augmentation. In this paper, we demonstrate that voice conversion can be used as a data augmentation technique to improve ASR performance, even on LibriSpeech, which contains 2,456 speakers. For ASR augmentation, it is necessary that the VC model be robust to a wide range of input speech. This motivates the use of a non-autoregressive, non-parallel VC model, and the use of a pretrained ASR encoder within the VC model. This work suggests that despite including many speakers, speaker diversity may remain a limitation to ASR quality. Finally, interrogation of our VC performance has provided useful metrics for objective evaluation of VC quality.
A Survey on Neural Speech Synthesis
Jul 23, 2021

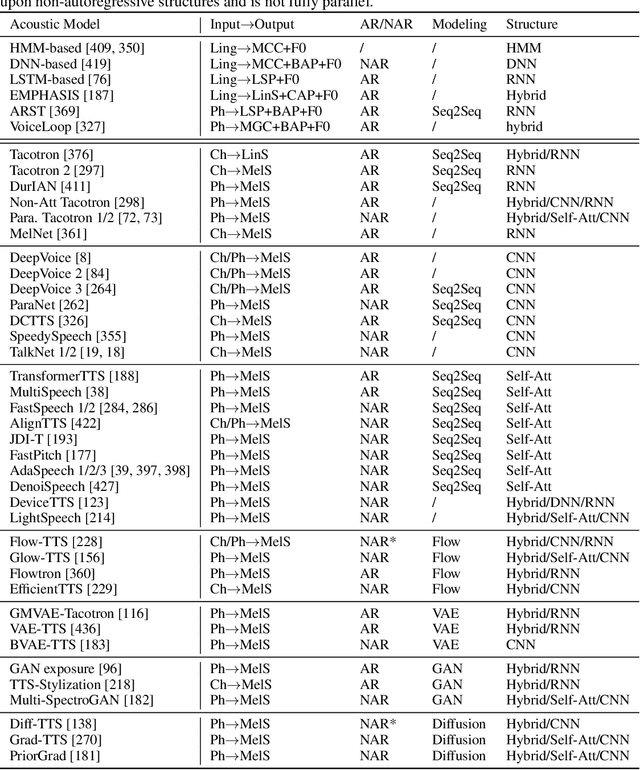
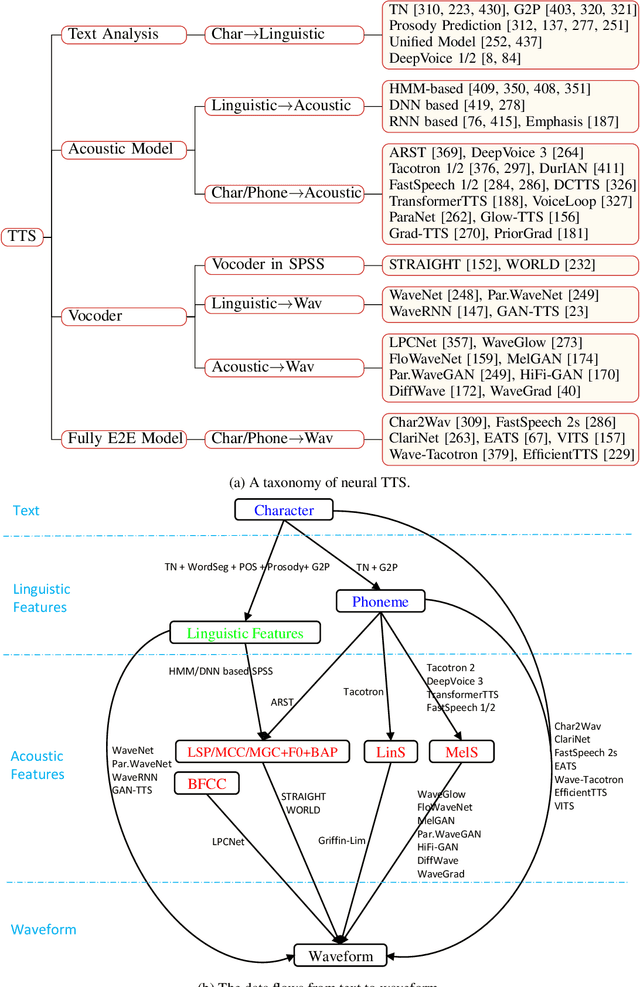
Text to speech (TTS), or speech synthesis, which aims to synthesize intelligible and natural speech given text, is a hot research topic in speech, language, and machine learning communities and has broad applications in the industry. As the development of deep learning and artificial intelligence, neural network-based TTS has significantly improved the quality of synthesized speech in recent years. In this paper, we conduct a comprehensive survey on neural TTS, aiming to provide a good understanding of current research and future trends. We focus on the key components in neural TTS, including text analysis, acoustic models and vocoders, and several advanced topics, including fast TTS, low-resource TTS, robust TTS, expressive TTS, and adaptive TTS, etc. We further summarize resources related to TTS (e.g., datasets, opensource implementations) and discuss future research directions. This survey can serve both academic researchers and industry practitioners working on TTS.