 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
More than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech
Nov 19, 2021
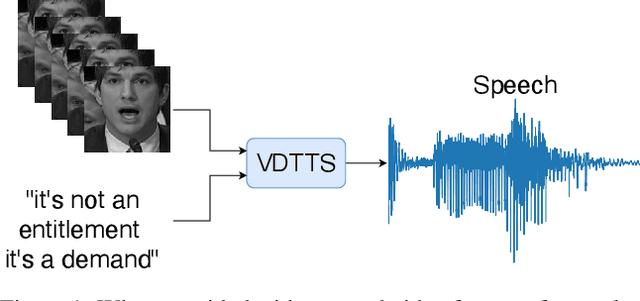
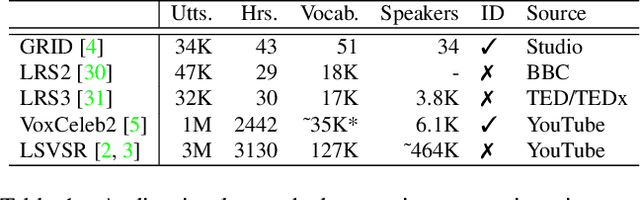
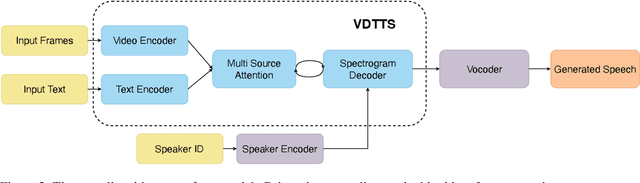
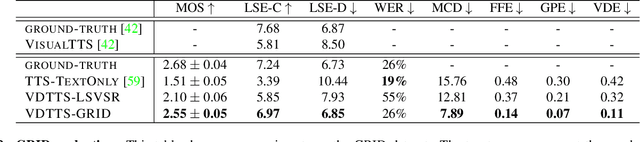
In this paper we present VDTTS, a Visually-Driven Text-to-Speech model. Motivated by dubbing, VDTTS takes advantage of video frames as an additional input alongside text, and generates speech that matches the video signal. We demonstrate how this allows VDTTS to, unlike plain TTS models, generate speech that not only has prosodic variations like natural pauses and pitch, but is also synchronized to the input video. Experimentally, we show our model produces well synchronized outputs, approaching the video-speech synchronization quality of the ground-truth, on several challenging benchmarks including "in-the-wild" content from VoxCeleb2. We encourage the reader to view the demo videos demonstrating video-speech synchronization, robustness to speaker ID swapping, and prosody.
FeaRLESS: Feature Refinement Loss for Ensembling Self-Supervised Learning Features in Robust End-to-end Speech Recognition
Jun 30, 2022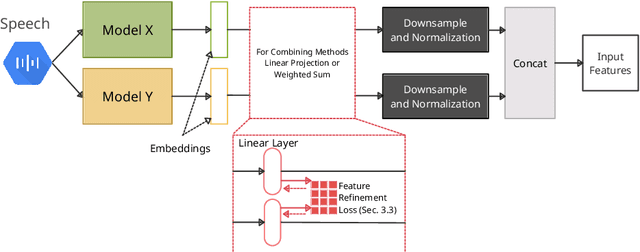
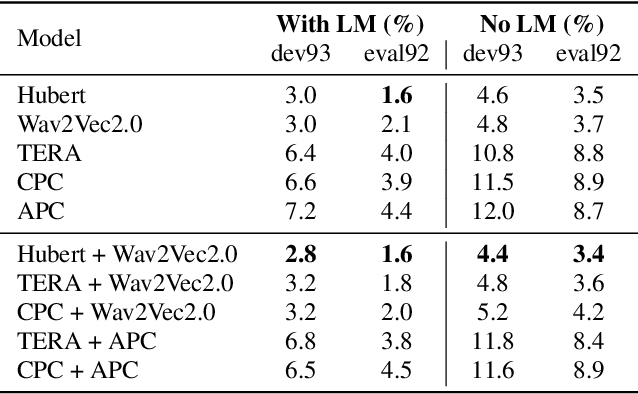
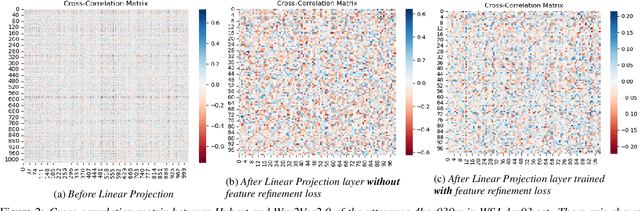
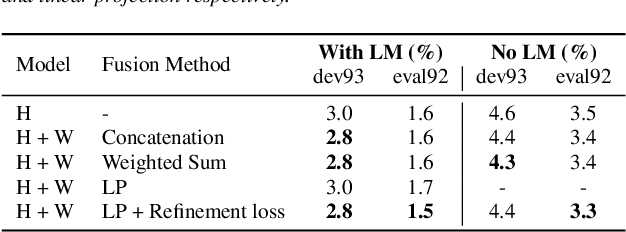
Self-supervised learning representations (SSLR) have resulted in robust features for downstream tasks in many fields. Recently, several SSLRs have shown promising results on automatic speech recognition (ASR) benchmark corpora. However, previous studies have only shown performance for solitary SSLRs as an input feature for ASR models. In this study, we propose to investigate the effectiveness of diverse SSLR combinations using various fusion methods within end-to-end (E2E) ASR models. In addition, we will show there are correlations between these extracted SSLRs. As such, we further propose a feature refinement loss for decorrelation to efficiently combine the set of input features. For evaluation, we show that the proposed 'FeaRLESS learning features' perform better than systems without the proposed feature refinement loss for both the WSJ and Fearless Steps Challenge (FSC) corpora.
Prabhupadavani: A Code-mixed Speech Translation Data for 25 Languages
Jan 27, 2022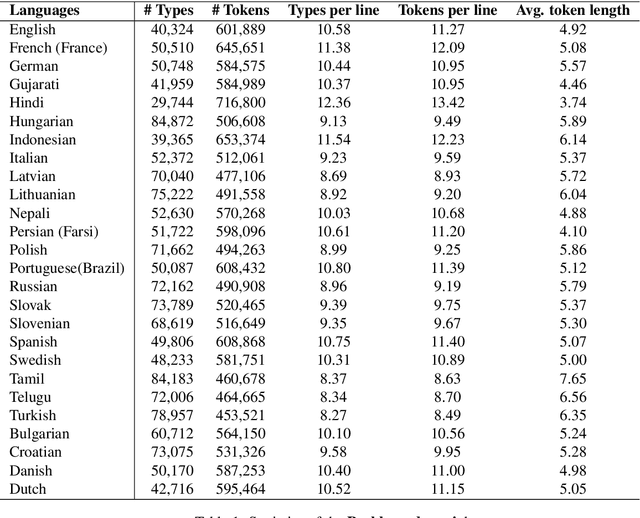
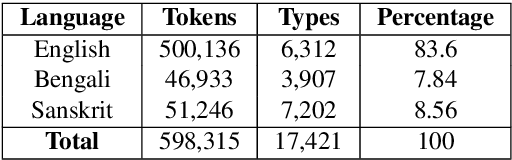


Nowadays, code-mixing has become ubiquitous in Natural Language Processing (NLP); however, no efforts have been made to address this phenomenon for Speech Translation (ST) task. This can be solely attributed to the lack of code-mixed ST task labelled data. Thus, we introduce Prabhupadavani, a multilingual code-mixed ST dataset for 25 languages, covering ten language families, containing 94 hours of speech by 130+ speakers, manually aligned with corresponding text in the target language. Prabhupadvani is the first code-mixed ST dataset available in the ST literature to the best of our knowledge. This data also can be used for a code-mixed machine translation task. All the dataset and code can be accessed at: \url{https://github.com/frozentoad9/CMST}
Enhancing ASR for Stuttered Speech with Limited Data Using Detect and Pass
Feb 08, 2022It is estimated that around 70 million people worldwide are affected by a speech disorder called stuttering. With recent advances in Automatic Speech Recognition (ASR), voice assistants are increasingly useful in our everyday lives. Many technologies in education, retail, telecommunication and healthcare can now be operated through voice. Unfortunately, these benefits are not accessible for People Who Stutter (PWS). We propose a simple but effective method called 'Detect and Pass' to make modern ASR systems accessible for People Who Stutter in a limited data setting. The algorithm uses a context aware classifier trained on a limited amount of data, to detect acoustic frames that contain stutter. To improve robustness on stuttered speech, this extra information is passed on to the ASR model to be utilized during inference. Our experiments show a reduction of 12.18% to 71.24% in Word Error Rate (WER) across various state of the art ASR systems. Upon varying the threshold of the associated posterior probability of stutter for each stacked frame used in determining low frame rate (LFR) acoustic features, we were able to determine an optimal setting that reduced the WER by 23.93% to 71.67% across different ASR systems.
Deep Learning-based Non-Intrusive Multi-Objective Speech Assessment Model with Cross-Domain Features
Dec 01, 2021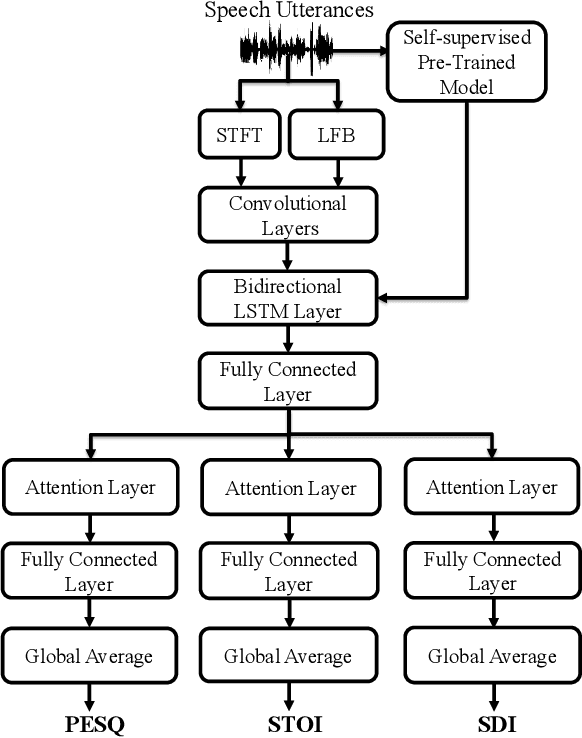
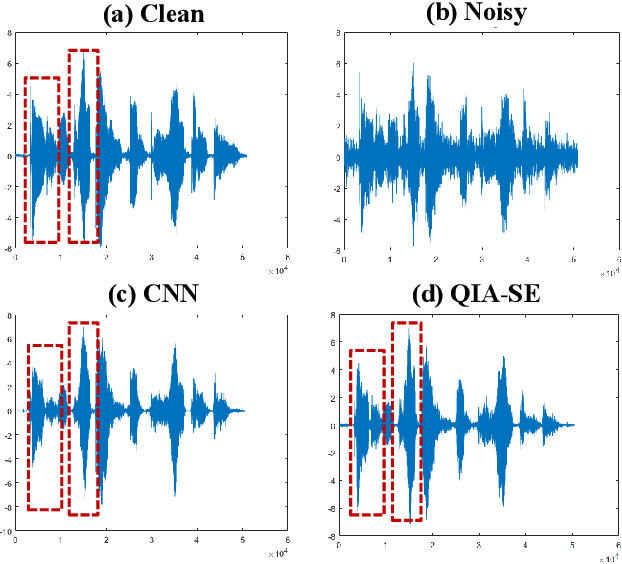
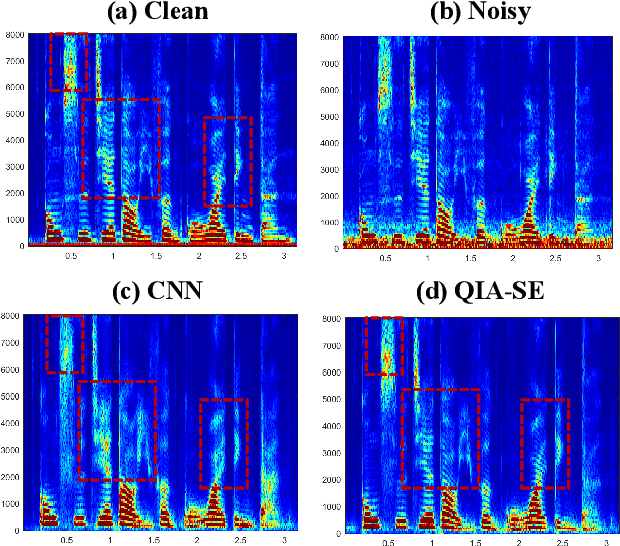
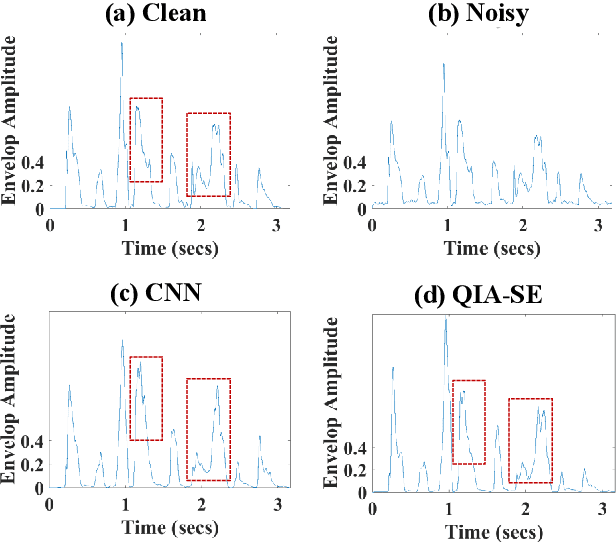
In this study, we propose a cross-domain multi-objective speech assessment model called MOSA-Net, which can estimate multiple speech assessment metrics simultaneously. More specifically, MOSA-Net is designed to estimate the speech quality, intelligibility, and distortion assessment scores of an input test speech signal. It comprises a convolutional neural network and bidirectional long short-term memory (CNN-BLSTM) architecture for representation extraction, and a multiplicative attention layer and a fully-connected layer for each assessment metric. In addition, cross-domain features (spectral and time-domain features) and latent representations from self-supervised learned models are used as inputs to combine rich acoustic information from different speech representations to obtain more accurate assessments. Experimental results show that MOSA-Net can precisely predict perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI) scores when tested on noisy and enhanced speech utterances under either seen test conditions or unseen test conditions. Moreover, MOSA-Net, originally trained to assess objective scores, can be used as a pre-trained model to be effectively adapted to an assessment model for predicting subjective quality and intelligibility scores with a limited amount of training data. In light of the confirmed prediction capability, we further adopt the latent representations of MOSA-Net to guide the speech enhancement (SE) process and derive a quality-intelligibility (QI)-aware SE (QIA-SE) approach accordingly. Experimental results show that QIA-SE provides superior enhancement performance compared with the baseline SE system in terms of objective evaluation metrics and qualitative evaluation test.
Impact of Dataset on Acoustic Models for Automatic Speech Recognition
Mar 25, 2022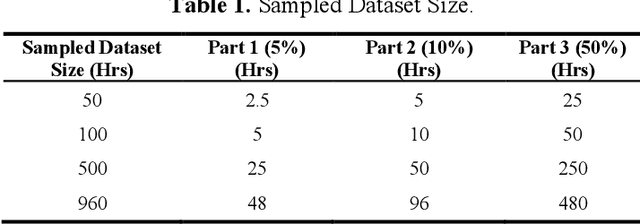
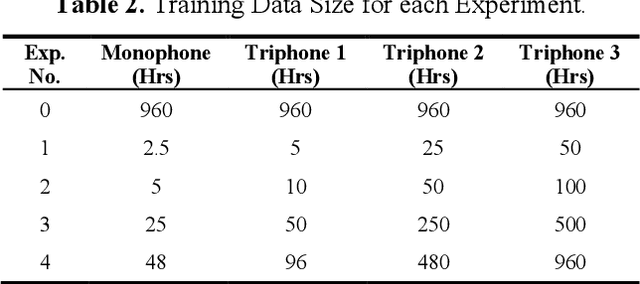
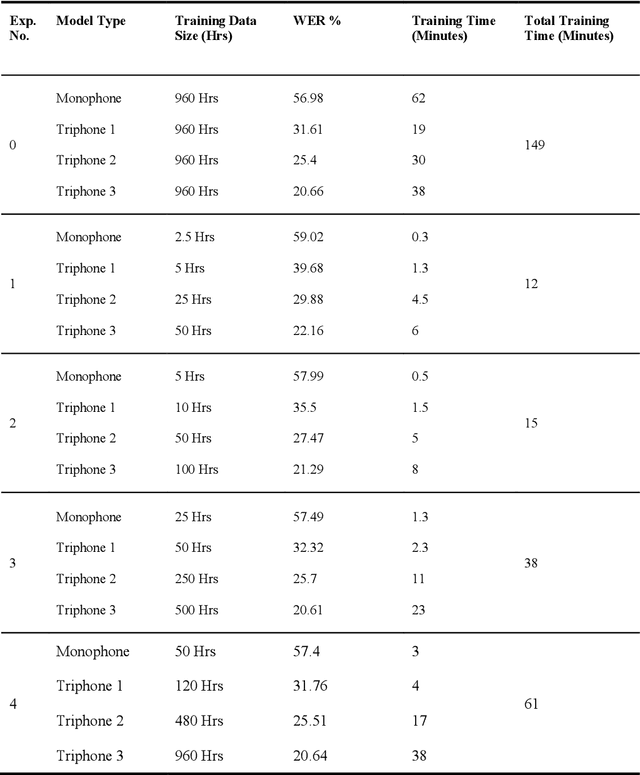
In Automatic Speech Recognition, GMM-HMM had been widely used for acoustic modelling. With the current advancement of deep learning, the Gaussian Mixture Model (GMM) from acoustic models has been replaced with Deep Neural Network, namely DNN-HMM Acoustic Models. The GMM models are widely used to create the alignments of the training data for the hybrid deep neural network model, thus making it an important task to create accurate alignments. Many factors such as training dataset size, training data augmentation, model hyperparameters, etc., affect the model learning. Traditionally in machine learning, larger datasets tend to have better performance, while smaller datasets tend to trigger over-fitting. The collection of speech data and their accurate transcriptions is a significant challenge that varies over different languages, and in most cases, it might be limited to big organizations. Moreover, in the case of available large datasets, training a model using such data requires additional time and computing resources, which may not be available. While the data about the accuracy of state-of-the-art ASR models on open-source datasets are published, the study about the impact of the size of a dataset on acoustic models is not readily available. This work aims to investigate the impact of dataset size variations on the performance of various GMM-HMM Acoustic Models and their respective computational costs.
High Fidelity Speech Regeneration with Application to Speech Enhancement
Jan 31, 2021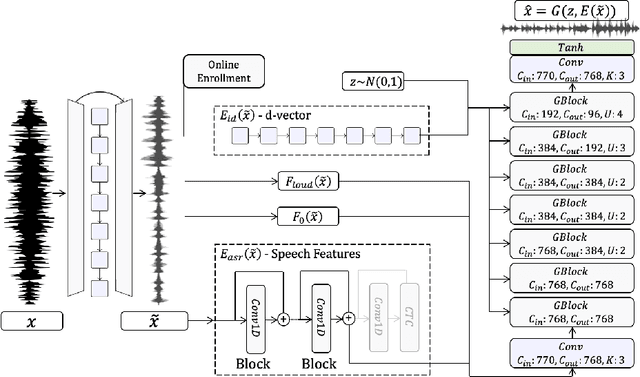
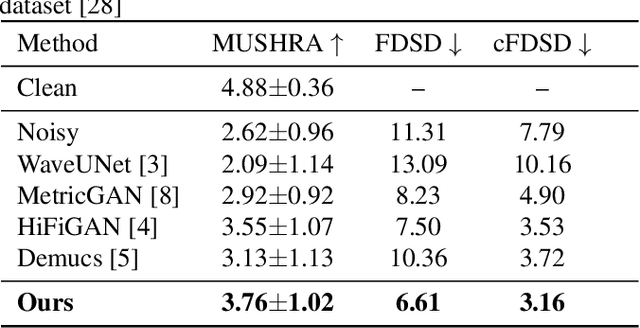
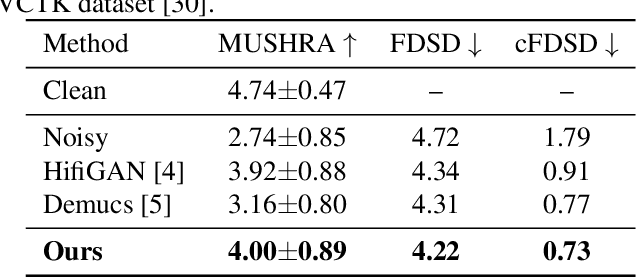
Speech enhancement has seen great improvement in recent years mainly through contributions in denoising, speaker separation, and dereverberation methods that mostly deal with environmental effects on vocal audio. To enhance speech beyond the limitations of the original signal, we take a regeneration approach, in which we recreate the speech from its essence, including the semi-recognized speech, prosody features, and identity. We propose a wav-to-wav generative model for speech that can generate 24khz speech in a real-time manner and which utilizes a compact speech representation, composed of ASR and identity features, to achieve a higher level of intelligibility. Inspired by voice conversion methods, we train to augment the speech characteristics while preserving the identity of the source using an auxiliary identity network. Perceptual acoustic metrics and subjective tests show that the method obtains valuable improvements over recent baselines.
APOLLO: A Simple Approach for Adaptive Pretraining of Language Models for Logical Reasoning
Dec 19, 2022
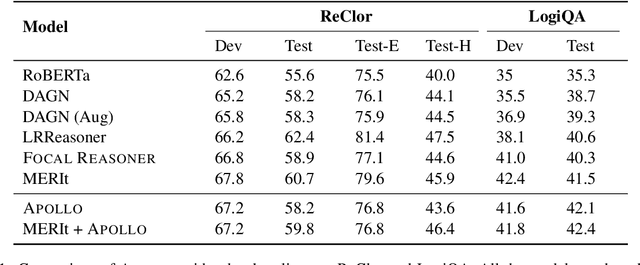
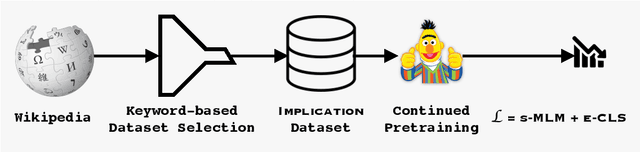
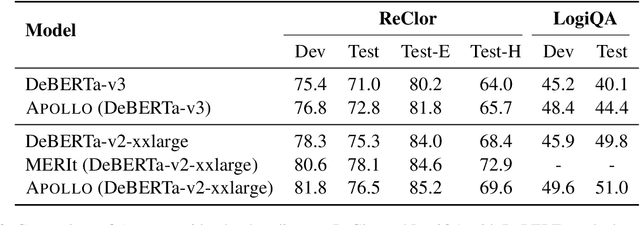
Logical reasoning of text is an important ability that requires understanding the information present in the text, their interconnections, and then reasoning through them to infer new conclusions. Prior works on improving the logical reasoning ability of language models require complex processing of training data (e.g., aligning symbolic knowledge to text), yielding task-specific data augmentation solutions that restrict the learning of general logical reasoning skills. In this work, we propose APOLLO, an adaptively pretrained language model that has improved logical reasoning abilities. We select a subset of Wikipedia, based on a set of logical inference keywords, for continued pretraining of a language model. We use two self-supervised loss functions: a modified masked language modeling loss where only specific parts-of-speech words, that would likely require more reasoning than basic language understanding, are masked, and a sentence-level classification loss that teaches the model to distinguish between entailment and contradiction types of sentences. The proposed training paradigm is both simple and independent of task formats. We demonstrate the effectiveness of APOLLO by comparing it with prior baselines on two logical reasoning datasets. APOLLO performs comparably on ReClor and outperforms baselines on LogiQA.
Unsupervised Personalization of an Emotion Recognition System: The Unique Properties of the Externalization of Valence in Speech
Jan 19, 2022
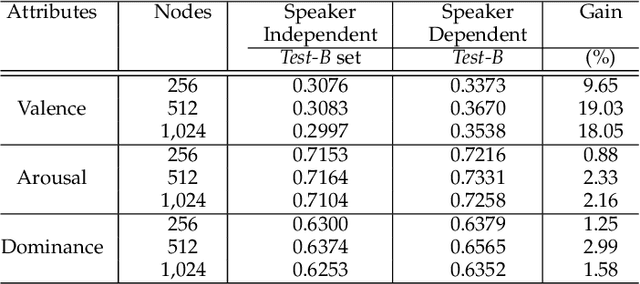
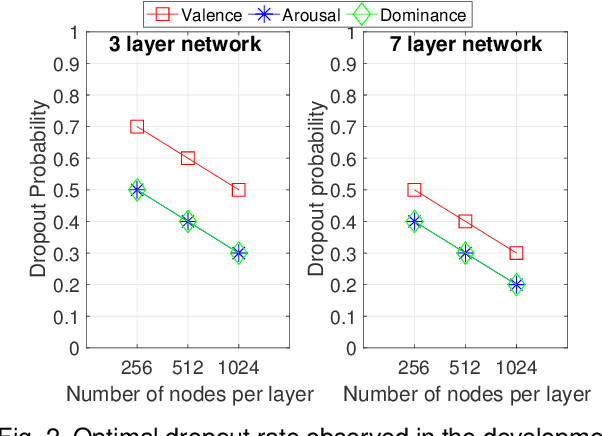
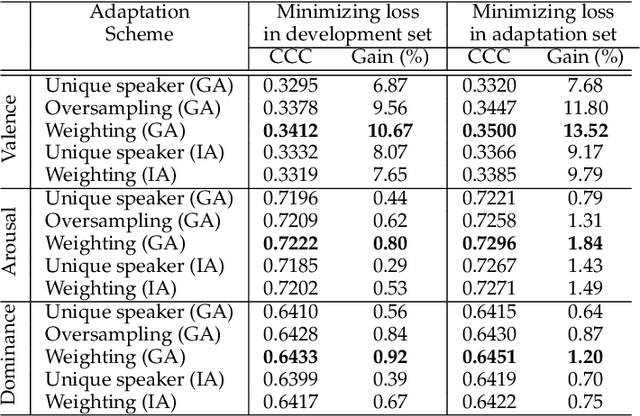
The prediction of valence from speech is an important, but challenging problem. The externalization of valence in speech has speaker-dependent cues, which contribute to performances that are often significantly lower than the prediction of other emotional attributes such as arousal and dominance. A practical approach to improve valence prediction from speech is to adapt the models to the target speakers in the test set. Adapting a speech emotion recognition (SER) system to a particular speaker is a hard problem, especially with deep neural networks (DNNs), since it requires optimizing millions of parameters. This study proposes an unsupervised approach to address this problem by searching for speakers in the train set with similar acoustic patterns as the speaker in the test set. Speech samples from the selected speakers are used to create the adaptation set. This approach leverages transfer learning using pre-trained models, which are adapted with these speech samples. We propose three alternative adaptation strategies: unique speaker, oversampling and weighting approaches. These methods differ on the use of the adaptation set in the personalization of the valence models. The results demonstrate that a valence prediction model can be efficiently personalized with these unsupervised approaches, leading to relative improvements as high as 13.52%.
A Feature Extraction based Model for Hate Speech Identification
Jan 11, 2022

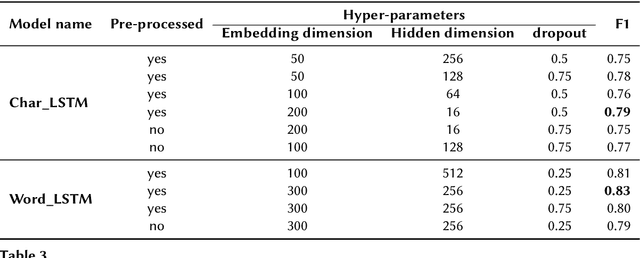

The detection of hate speech online has become an important task, as offensive language such as hurtful, obscene and insulting content can harm marginalized people or groups. This paper presents TU Berlin team experiments and results on the task 1A and 1B of the shared task on hate speech and offensive content identification in Indo-European languages 2021. The success of different Natural Language Processing models is evaluated for the respective subtasks throughout the competition. We tested different models based on recurrent neural networks in word and character levels and transfer learning approaches based on Bert on the provided dataset by the competition. Among the tested models that have been used for the experiments, the transfer learning-based models achieved the best results in both subtasks.