 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Efficient Training of Neural Transducer for Speech Recognition
Apr 22, 2022
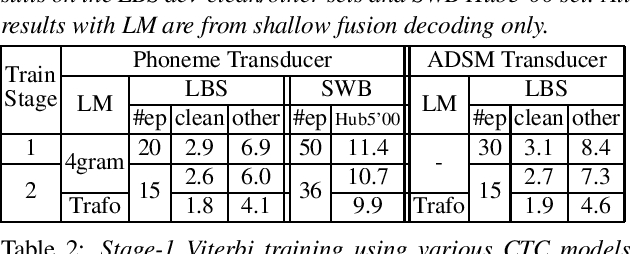
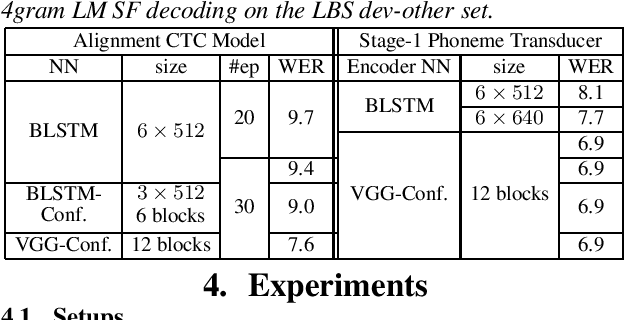
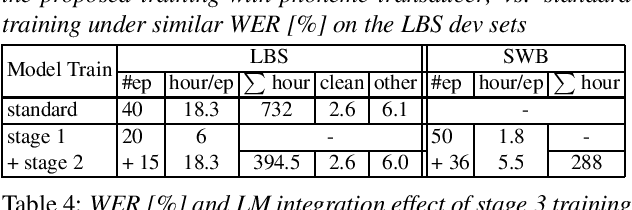
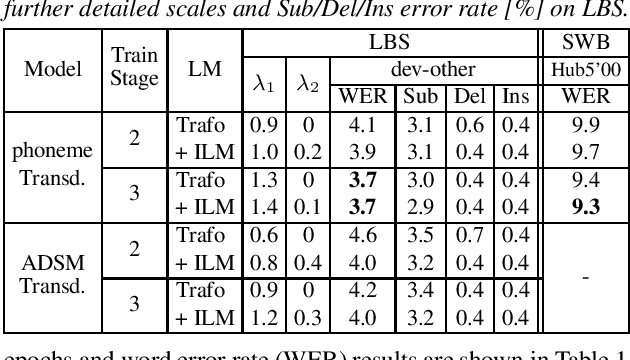
As one of the most popular sequence-to-sequence modeling approaches for speech recognition, the RNN-Transducer has achieved evolving performance with more and more sophisticated neural network models of growing size and increasing training epochs. While strong computation resources seem to be the prerequisite of training superior models, we try to overcome it by carefully designing a more efficient training pipeline. In this work, we propose an efficient 3-stage progressive training pipeline to build highly-performing neural transducer models from scratch with very limited computation resources in a reasonable short time period. The effectiveness of each stage is experimentally verified on both Librispeech and Switchboard corpora. The proposed pipeline is able to train transducer models approaching state-of-the-art performance with a single GPU in just 2-3 weeks. Our best conformer transducer achieves 4.1% WER on Librispeech test-other with only 35 epochs of training.
Speech Enhancement-assisted Stargan Voice Conversion in Noisy Environments
Oct 19, 2021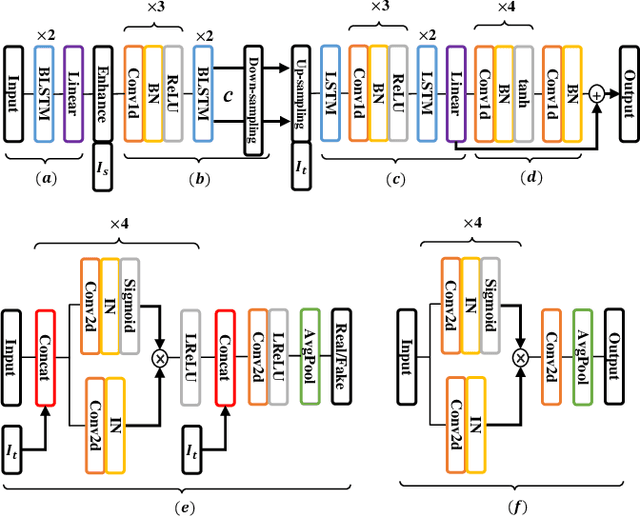

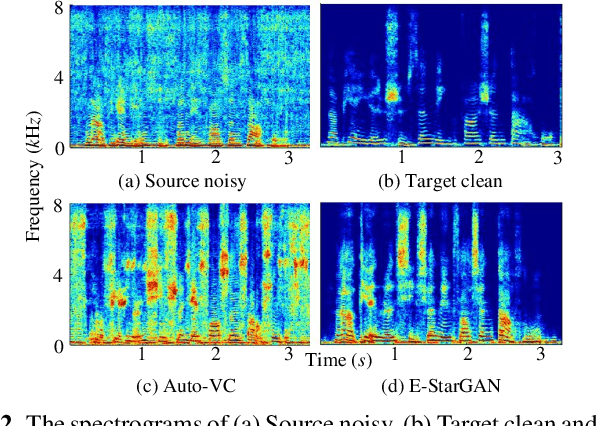
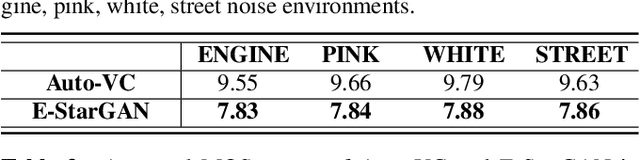
Numerous voice conversion (VC) techniques have been proposed for the conversion of voices among different speakers. Although the decent quality of converted speech can be observed when VC is applied in a clean environment, the quality will drop sharply when the system is running under noisy conditions. In order to address this issue, we propose a novel enhancement-based StarGAN (E-StarGAN) VC system, which leverages a speech enhancement (SE) technique for signal pre-processing. SE systems are generally used to reduce noise components in noisy speech and to generate enhanced speech for downstream application tasks. Therefore, we investigated the effectiveness of E-StarGAN, which combines VC and SE, and demonstrated the robustness of the proposed approach in various noisy environments. The results of VC experiments conducted on a Mandarin dataset show that when combined with SE, the proposed E-StarGAN VC model is robust to unseen noises. In addition, the subjective listening test results show that the proposed E-StarGAN model can improve the sound quality of speech signals converted from noise-corrupted source utterances.
Self-Supervised Learning based Monaural Speech Enhancement with Multi-Task Pre-Training
Dec 21, 2021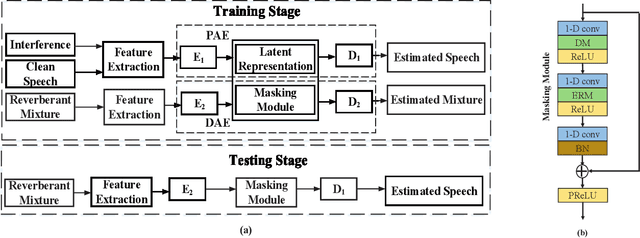
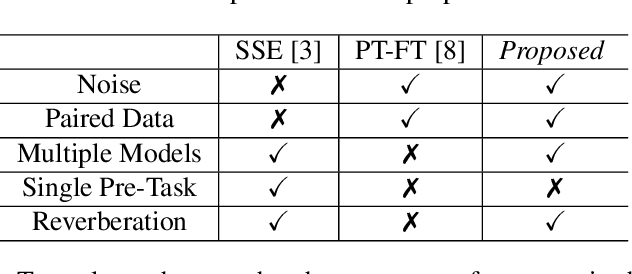
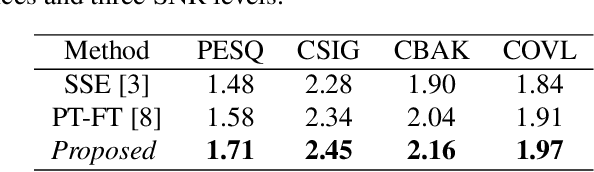
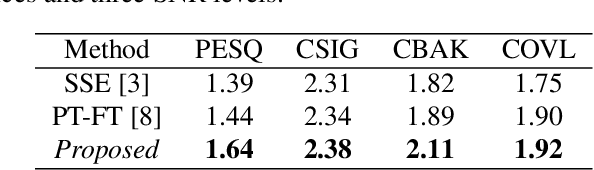
In self-supervised learning, it is challenging to reduce the gap between the enhancement performance on the estimated and target speech signals with existed pre-tasks. In this paper, we propose a multi-task pre-training method to improve the speech enhancement performance with self-supervised learning. Within the pre-training autoencoder (PAE), only a limited set of clean speech signals are required to learn their latent representations. Meanwhile, to solve the limitation of single pre-task, the proposed masking module exploits the dereverberated mask and estimated ratio mask to denoise the mixture as the second pre-task. Different from the PAE, where the target speech signals are estimated, the downstream task autoencoder (DAE) utilizes a large number of unlabeled and unseen reverberant mixtures to generate the estimated mixtures. The trained DAE is shared by the learned representations and masks. Experimental results on a benchmark dataset demonstrate that the proposed method outperforms the state-of-the-art approaches.
Personal VAD 2.0: Optimizing Personal Voice Activity Detection for On-Device Speech Recognition
Apr 13, 2022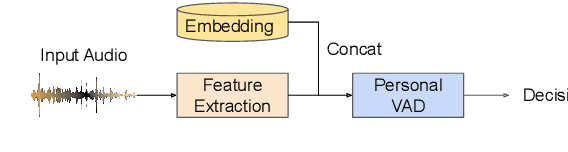
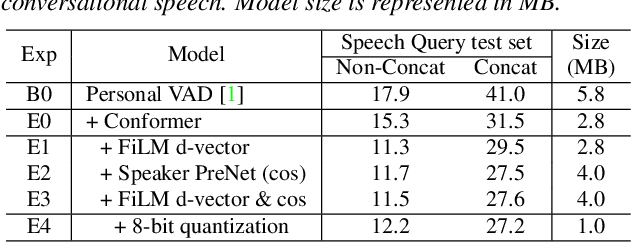
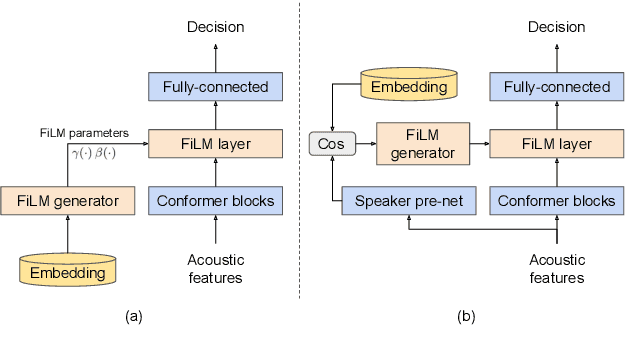
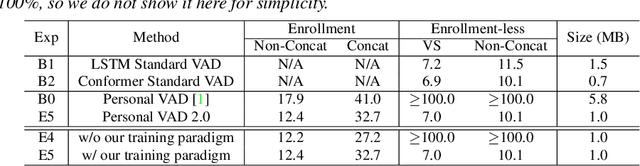
Personalization of on-device speech recognition (ASR) has seen explosive growth in recent years, largely due to the increasing popularity of personal assistant features on mobile devices and smart home speakers. In this work, we present Personal VAD 2.0, a personalized voice activity detector that detects the voice activity of a target speaker, as part of a streaming on-device ASR system. Although previous proof-of-concept studies have validated the effectiveness of Personal VAD, there are still several critical challenges to address before this model can be used in production: first, the quality must be satisfactory in both enrollment and enrollment-less scenarios; second, it should operate in a streaming fashion; and finally, the model size should be small enough to fit a limited latency and CPU/Memory budget. To meet the multi-faceted requirements, we propose a series of novel designs: 1) advanced speaker embedding modulation methods; 2) a new training paradigm to generalize to enrollment-less conditions; 3) architecture and runtime optimizations for latency and resource restrictions. Extensive experiments on a realistic speech recognition system demonstrated the state-of-the-art performance of our proposed method.
MAST: Multiscale Audio Spectrogram Transformers
Nov 02, 2022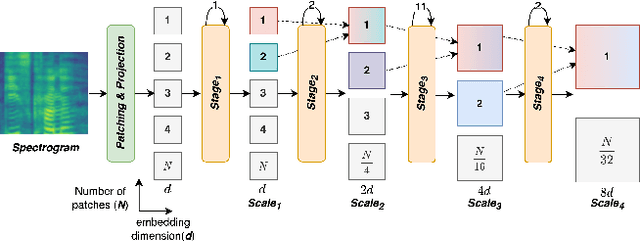
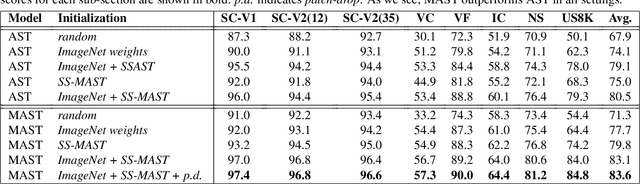
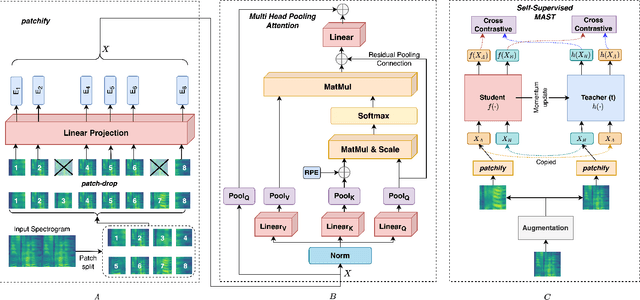
We present Multiscale Audio Spectrogram Transformer (MAST) for audio classification, which brings the concept of multiscale feature hierarchies to the Audio Spectrogram Transformer (AST). Given an input audio spectrogram we first patchify and project it into an initial temporal resolution and embedding dimension, post which the multiple stages in MAST progressively expand the embedding dimension while reducing the temporal resolution of the input. We use a pyramid structure that allows early layers of MAST operating at a high temporal resolution but low embedding space to model simple low-level acoustic information and deeper temporally coarse layers to model high-level acoustic information with high-dimensional embeddings. We also extend our approach to present a new Self-Supervised Learning (SSL) method called SS-MAST, which calculates a symmetric contrastive loss between latent representations from a student and a teacher encoder. In practice, MAST significantly outperforms AST by an average accuracy of 3.4% across 8 speech and non-speech tasks from the LAPE Benchmark. Moreover, SS-MAST achieves an absolute average improvement of 2.6% over SSAST for both AST and MAST encoders. We make all our codes available on GitHub at the time of publication.
Lisan: Yemenu, Irqi, Libyan, and Sudanese Arabic Dialect Copora with Morphological Annotations
Dec 13, 2022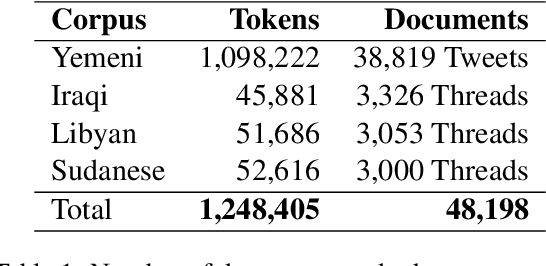
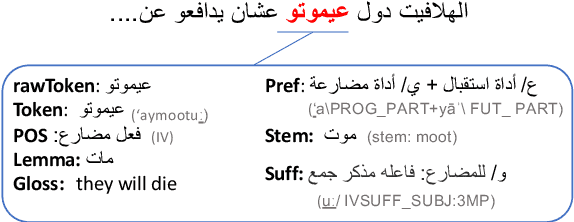
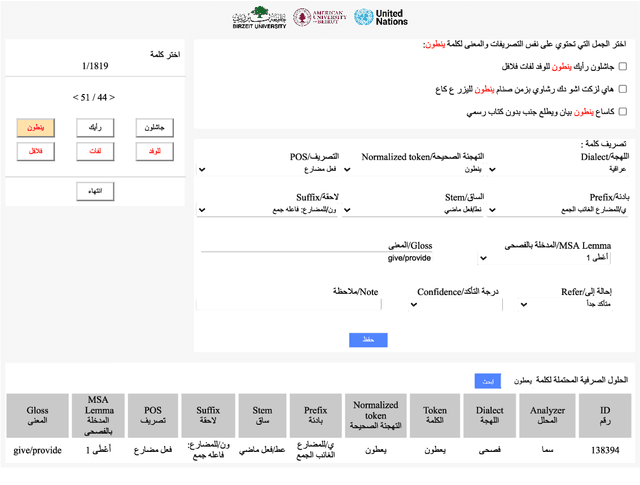
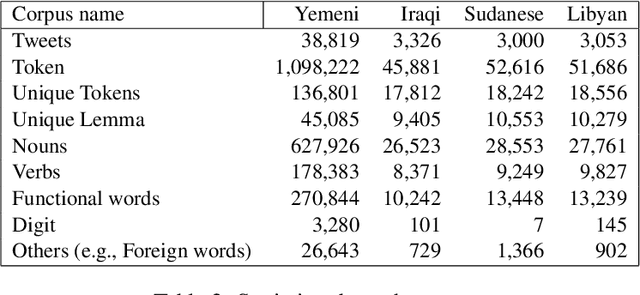
This article presents morphologically-annotated Yemeni, Sudanese, Iraqi, and Libyan Arabic dialects Lisan corpora. Lisan features around 1.2 million tokens. We collected the content of the corpora from several social media platforms. The Yemeni corpus (~ 1.05M tokens) was collected automatically from Twitter. The corpora of the other three dialects (~ 50K tokens each) came manually from Facebook and YouTube posts and comments. Thirty five (35) annotators who are native speakers of the target dialects carried out the annotations. The annotators segemented all words in the four corpora into prefixes, stems and suffixes and labeled each with different morphological features such as part of speech, lemma, and a gloss in English. An Arabic Dialect Annotation Toolkit ADAT was developped for the purpose of the annation. The annotators were trained on a set of guidelines and on how to use ADAT. We developed ADAT to assist the annotators and to ensure compatibility with SAMA and Curras tagsets. The tool is open source, and the four corpora are also available online.
How Bad Are Artifacts?: Analyzing the Impact of Speech Enhancement Errors on ASR
Jan 18, 2022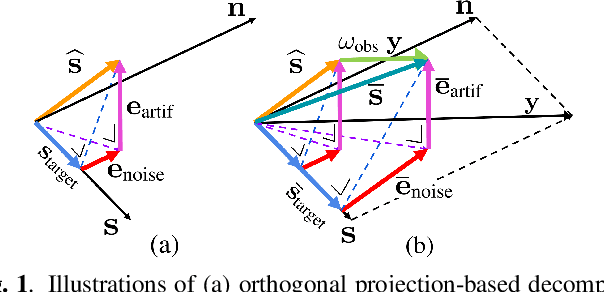
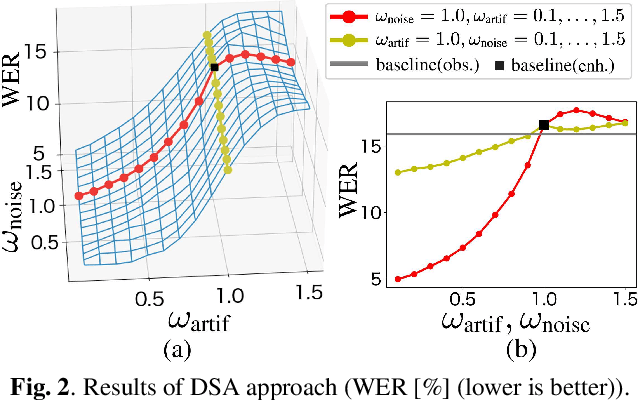
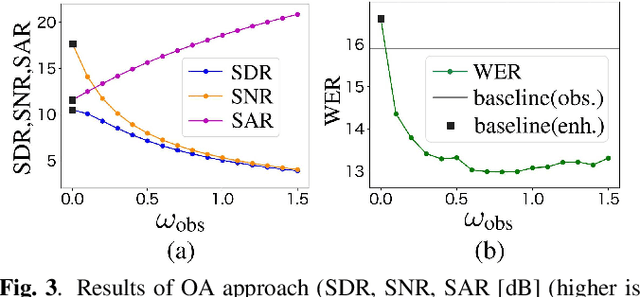
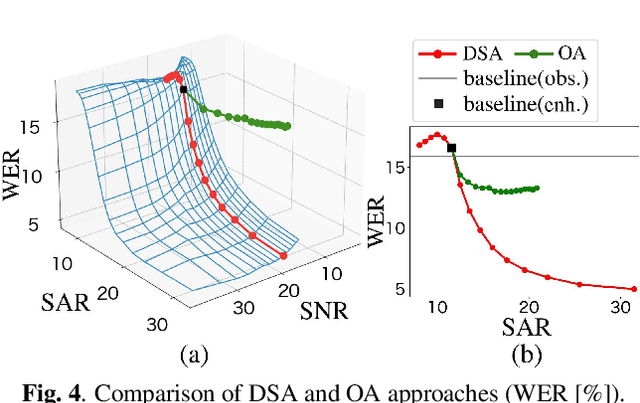
It is challenging to improve automatic speech recognition (ASR) performance in noisy conditions with single-channel speech enhancement (SE). In this paper, we investigate the causes of ASR performance degradation by decomposing the SE errors using orthogonal projection-based decomposition (OPD). OPD decomposes the SE errors into noise and artifact components. The artifact component is defined as the SE error signal that cannot be represented as a linear combination of speech and noise sources. We propose manually scaling the error components to analyze their impact on ASR. We experimentally identify the artifact component as the main cause of performance degradation, and we find that mitigating the artifact can greatly improve ASR performance. Furthermore, we demonstrate that the simple observation adding (OA) technique (i.e., adding a scaled version of the observed signal to the enhanced speech) can monotonically increase the signal-to-artifact ratio under a mild condition. Accordingly, we experimentally confirm that OA improves ASR performance for both simulated and real recordings. The findings of this paper provide a better understanding of the influence of SE errors on ASR and open the door to future research on novel approaches for designing effective single-channel SE front-ends for ASR.
Foundation Transformers
Oct 19, 2022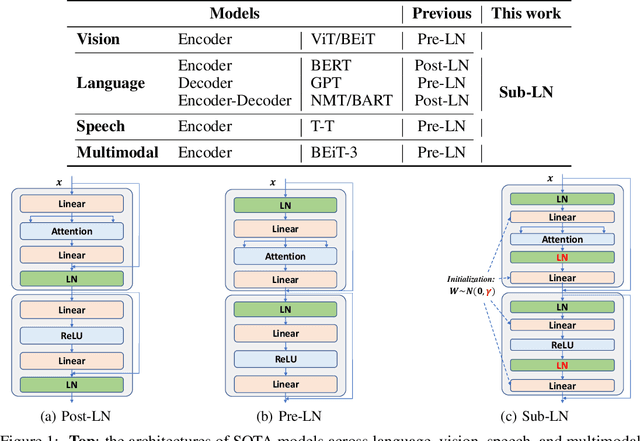
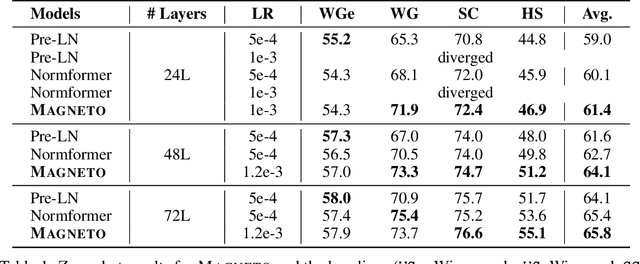
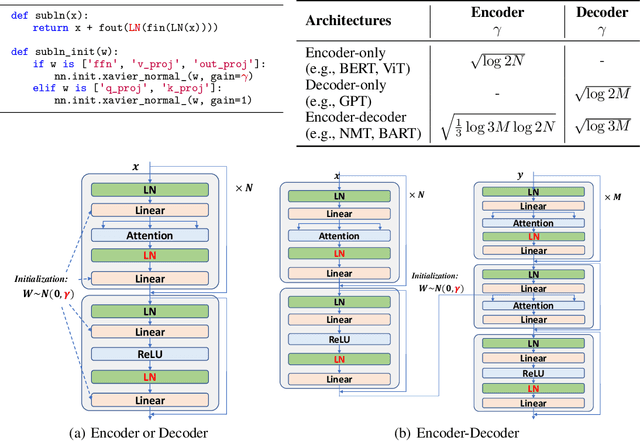
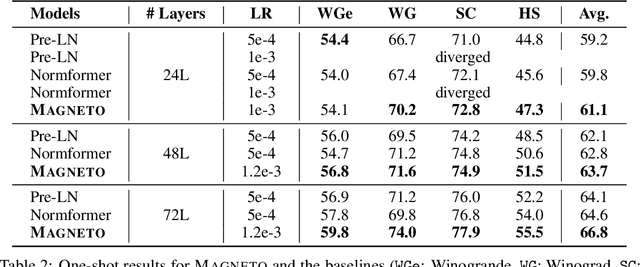
A big convergence of model architectures across language, vision, speech, and multimodal is emerging. However, under the same name "Transformers", the above areas use different implementations for better performance, e.g., Post-LayerNorm for BERT, and Pre-LayerNorm for GPT and vision Transformers. We call for the development of Foundation Transformer for true general-purpose modeling, which serves as a go-to architecture for various tasks and modalities with guaranteed training stability. In this work, we introduce a Transformer variant, named Magneto, to fulfill the goal. Specifically, we propose Sub-LayerNorm for good expressivity, and the initialization strategy theoretically derived from DeepNet for stable scaling up. Extensive experiments demonstrate its superior performance and better stability than the de facto Transformer variants designed for various applications, including language modeling (i.e., BERT, and GPT), machine translation, vision pretraining (i.e., BEiT), speech recognition, and multimodal pretraining (i.e., BEiT-3).
More than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech
Nov 19, 2021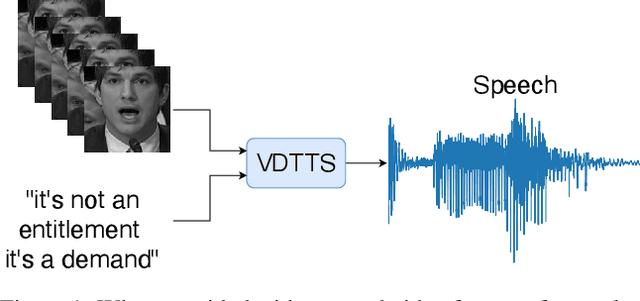
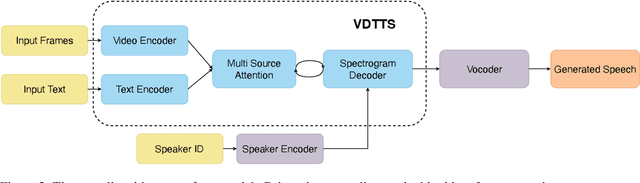
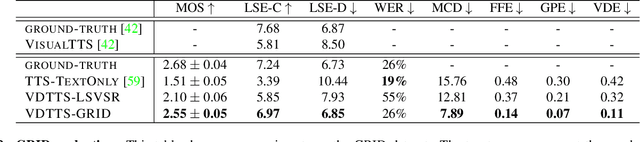
In this paper we present VDTTS, a Visually-Driven Text-to-Speech model. Motivated by dubbing, VDTTS takes advantage of video frames as an additional input alongside text, and generates speech that matches the video signal. We demonstrate how this allows VDTTS to, unlike plain TTS models, generate speech that not only has prosodic variations like natural pauses and pitch, but is also synchronized to the input video. Experimentally, we show our model produces well synchronized outputs, approaching the video-speech synchronization quality of the ground-truth, on several challenging benchmarks including "in-the-wild" content from VoxCeleb2. We encourage the reader to view the demo videos demonstrating video-speech synchronization, robustness to speaker ID swapping, and prosody.
Annealing Double-Head: An Architecture for Online Calibration of Deep Neural Networks
Dec 27, 2022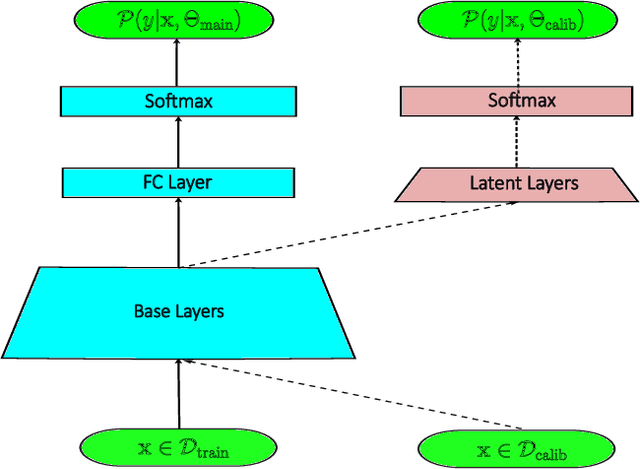
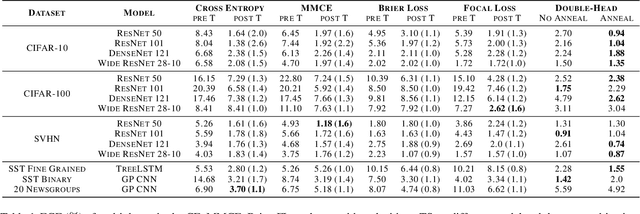
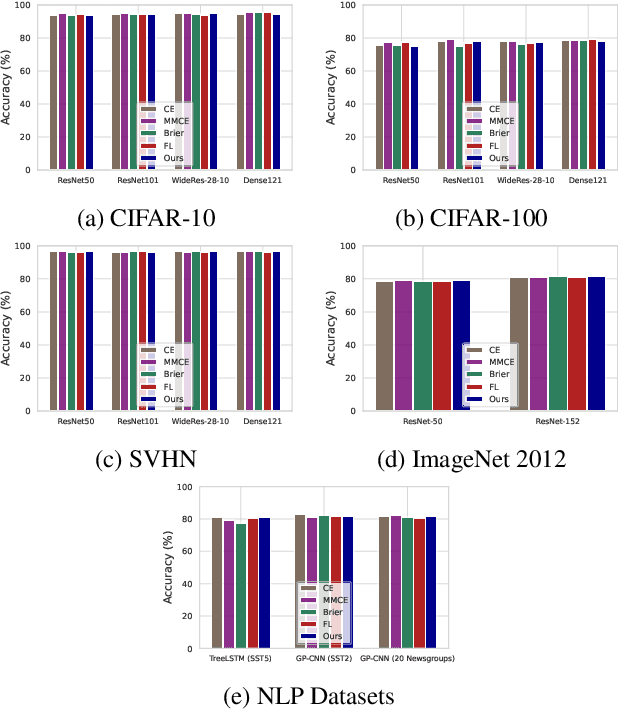

Model calibration, which is concerned with how frequently the model predicts correctly, not only plays a vital part in statistical model design, but also has substantial practical applications, such as optimal decision-making in the real world. However, it has been discovered that modern deep neural networks are generally poorly calibrated due to the overestimation (or underestimation) of predictive confidence, which is closely related to overfitting. In this paper, we propose Annealing Double-Head, a simple-to-implement but highly effective architecture for calibrating the DNN during training. To be precise, we construct an additional calibration head-a shallow neural network that typically has one latent layer-on top of the last latent layer in the normal model to map the logits to the aligned confidence. Furthermore, a simple Annealing technique that dynamically scales the logits by calibration head in training procedure is developed to improve its performance. Under both the in-distribution and distributional shift circumstances, we exhaustively evaluate our Annealing Double-Head architecture on multiple pairs of contemporary DNN architectures and vision and speech datasets. We demonstrate that our method achieves state-of-the-art model calibration performance without post-processing while simultaneously providing comparable predictive accuracy in comparison to other recently proposed calibration methods on a range of learning tasks.