 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Lisan: Yemenu, Irqi, Libyan, and Sudanese Arabic Dialect Copora with Morphological Annotations
Dec 13, 2022
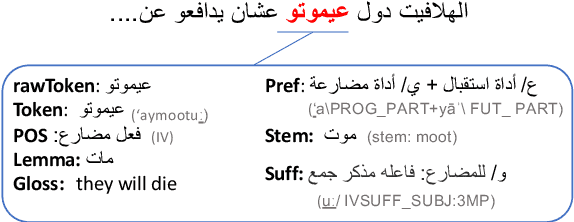
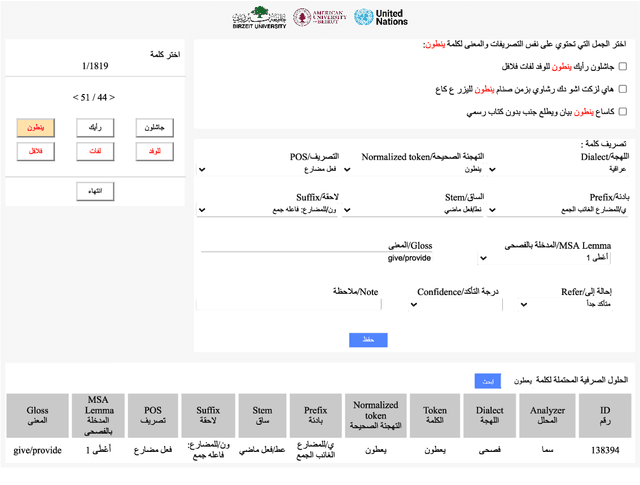
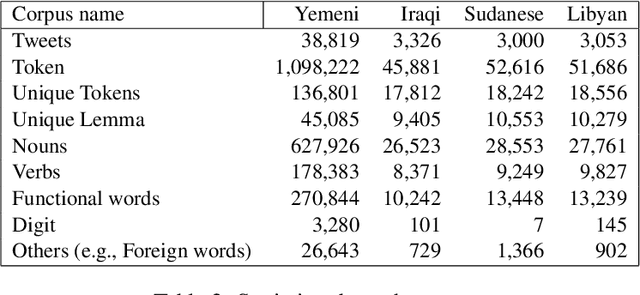
This article presents morphologically-annotated Yemeni, Sudanese, Iraqi, and Libyan Arabic dialects Lisan corpora. Lisan features around 1.2 million tokens. We collected the content of the corpora from several social media platforms. The Yemeni corpus (~ 1.05M tokens) was collected automatically from Twitter. The corpora of the other three dialects (~ 50K tokens each) came manually from Facebook and YouTube posts and comments. Thirty five (35) annotators who are native speakers of the target dialects carried out the annotations. The annotators segemented all words in the four corpora into prefixes, stems and suffixes and labeled each with different morphological features such as part of speech, lemma, and a gloss in English. An Arabic Dialect Annotation Toolkit ADAT was developped for the purpose of the annation. The annotators were trained on a set of guidelines and on how to use ADAT. We developed ADAT to assist the annotators and to ensure compatibility with SAMA and Curras tagsets. The tool is open source, and the four corpora are also available online.
FMFCC-A: A Challenging Mandarin Dataset for Synthetic Speech Detection
Oct 18, 2021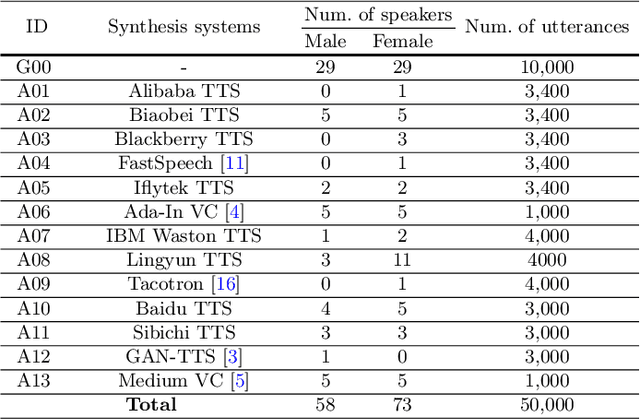
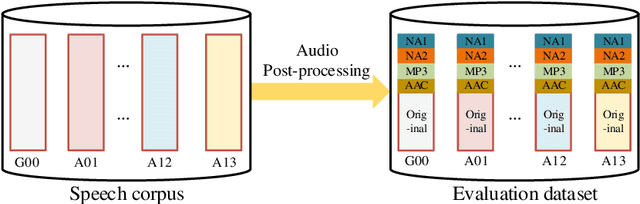

As increasing development of text-to-speech (TTS) and voice conversion (VC) technologies, the detection of synthetic speech has been suffered dramatically. In order to promote the development of synthetic speech detection model against Mandarin TTS and VC technologies, we have constructed a challenging Mandarin dataset and organized the accompanying audio track of the first fake media forensic challenge of China Society of Image and Graphics (FMFCC-A). The FMFCC-A dataset is by far the largest publicly-available Mandarin dataset for synthetic speech detection, which contains 40,000 synthesized Mandarin utterances that generated by 11 Mandarin TTS systems and two Mandarin VC systems, and 10,000 genuine Mandarin utterances collected from 58 speakers. The FMFCC-A dataset is divided into the training, development and evaluation sets, which are used for the research of detection of synthesized Mandarin speech under various previously unknown speech synthesis systems or audio post-processing operations. In addition to describing the construction of the FMFCC-A dataset, we provide a detailed analysis of two baseline methods and the top-performing submissions from the FMFCC-A, which illustrates the usefulness and challenge of FMFCC-A dataset. We hope that the FMFCC-A dataset can fill the gap of lack of Mandarin datasets for synthetic speech detection.
MAST: Multiscale Audio Spectrogram Transformers
Nov 02, 2022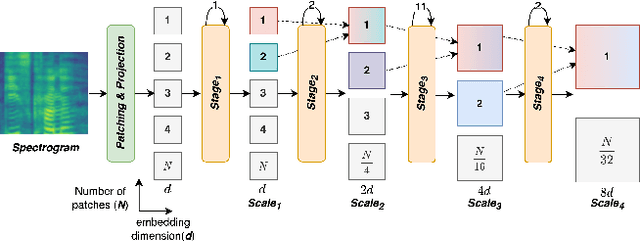
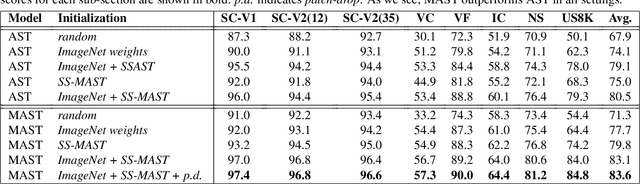
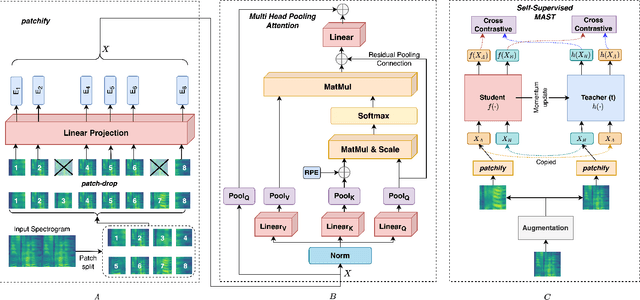
We present Multiscale Audio Spectrogram Transformer (MAST) for audio classification, which brings the concept of multiscale feature hierarchies to the Audio Spectrogram Transformer (AST). Given an input audio spectrogram we first patchify and project it into an initial temporal resolution and embedding dimension, post which the multiple stages in MAST progressively expand the embedding dimension while reducing the temporal resolution of the input. We use a pyramid structure that allows early layers of MAST operating at a high temporal resolution but low embedding space to model simple low-level acoustic information and deeper temporally coarse layers to model high-level acoustic information with high-dimensional embeddings. We also extend our approach to present a new Self-Supervised Learning (SSL) method called SS-MAST, which calculates a symmetric contrastive loss between latent representations from a student and a teacher encoder. In practice, MAST significantly outperforms AST by an average accuracy of 3.4% across 8 speech and non-speech tasks from the LAPE Benchmark. Moreover, SS-MAST achieves an absolute average improvement of 2.6% over SSAST for both AST and MAST encoders. We make all our codes available on GitHub at the time of publication.
Controllable Multichannel Speech Dereverberation based on Deep Neural Networks
Oct 16, 2021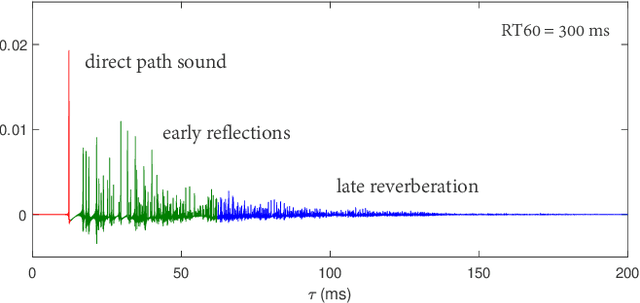
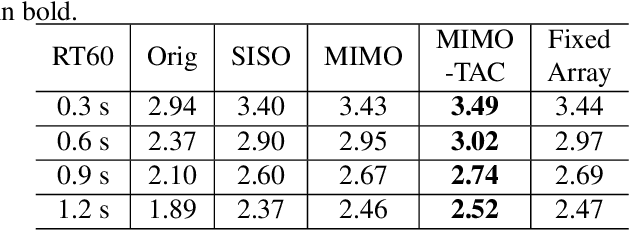
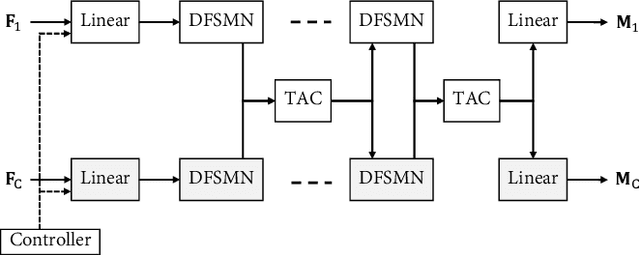
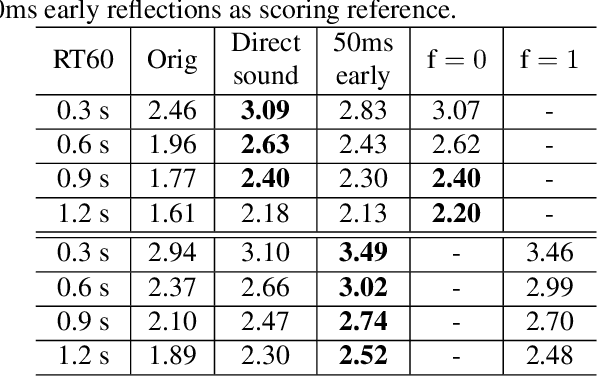
Neural network based speech dereverberation has achieved promising results in recent studies. Nevertheless, many are focused on recovery of only the direct path sound and early reflections, which could be beneficial to speech perception, are discarded. The performance of a model trained to recover clean speech degrades when evaluated on early reverberation targets, and vice versa. This paper proposes a novel deep neural network based multichannel speech dereverberation algorithm, in which the dereverberation level is controllable. This is realized by adding a simple floating-point number as target controller of the model. Experiments are conducted using spatially distributed microphones, and the efficacy of the proposed algorithm is confirmed in various simulated conditions.
Annealing Double-Head: An Architecture for Online Calibration of Deep Neural Networks
Dec 27, 2022
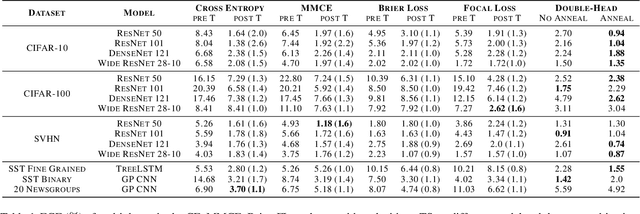
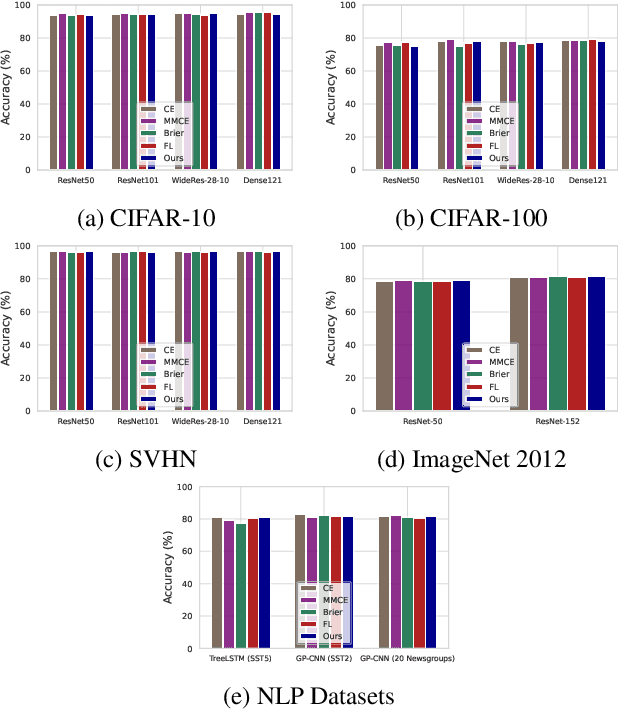

Model calibration, which is concerned with how frequently the model predicts correctly, not only plays a vital part in statistical model design, but also has substantial practical applications, such as optimal decision-making in the real world. However, it has been discovered that modern deep neural networks are generally poorly calibrated due to the overestimation (or underestimation) of predictive confidence, which is closely related to overfitting. In this paper, we propose Annealing Double-Head, a simple-to-implement but highly effective architecture for calibrating the DNN during training. To be precise, we construct an additional calibration head-a shallow neural network that typically has one latent layer-on top of the last latent layer in the normal model to map the logits to the aligned confidence. Furthermore, a simple Annealing technique that dynamically scales the logits by calibration head in training procedure is developed to improve its performance. Under both the in-distribution and distributional shift circumstances, we exhaustively evaluate our Annealing Double-Head architecture on multiple pairs of contemporary DNN architectures and vision and speech datasets. We demonstrate that our method achieves state-of-the-art model calibration performance without post-processing while simultaneously providing comparable predictive accuracy in comparison to other recently proposed calibration methods on a range of learning tasks.
Towards a Perceptual Model for Estimating the Quality of Visual Speech
Mar 24, 2022
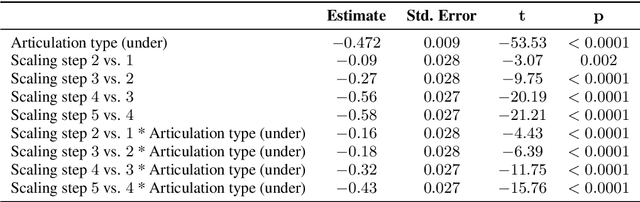
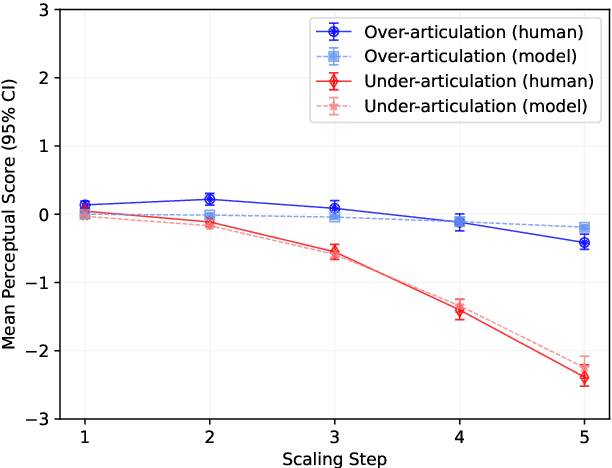
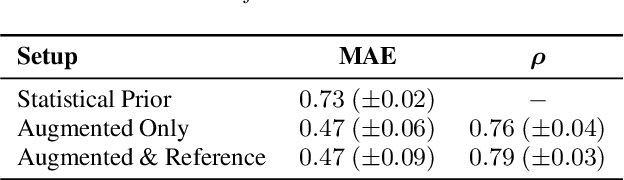
Generating realistic lip motions to simulate speech production is key for driving natural character animations from audio. Previous research has shown that traditional metrics used to optimize and assess models for generating lip motions from speech are not a good indicator of subjective opinion of animation quality. Yet, running repetitive subjective studies for assessing the quality of animations can be time-consuming and difficult to replicate. In this work, we seek to understand the relationship between perturbed lip motion and subjective opinion of lip motion quality. Specifically, we adjust the degree of articulation for lip motion sequences and run a user-study to examine how this adjustment impacts the perceived quality of lip motion. We then train a model using the scores collected from our user-study to automatically predict the subjective quality of an animated sequence. Our results show that (1) users score lip motions with slight over-articulation the highest in terms of perceptual quality; (2) under-articulation had a more detrimental effect on perceived quality of lip motion compared to the effect of over-articulation; and (3) we can automatically estimate the subjective perceptual score for a given lip motion sequences with low error rates.
Interpretable Acoustic Representation Learning on Breathing and Speech Signals for COVID-19 Detection
Jun 27, 2022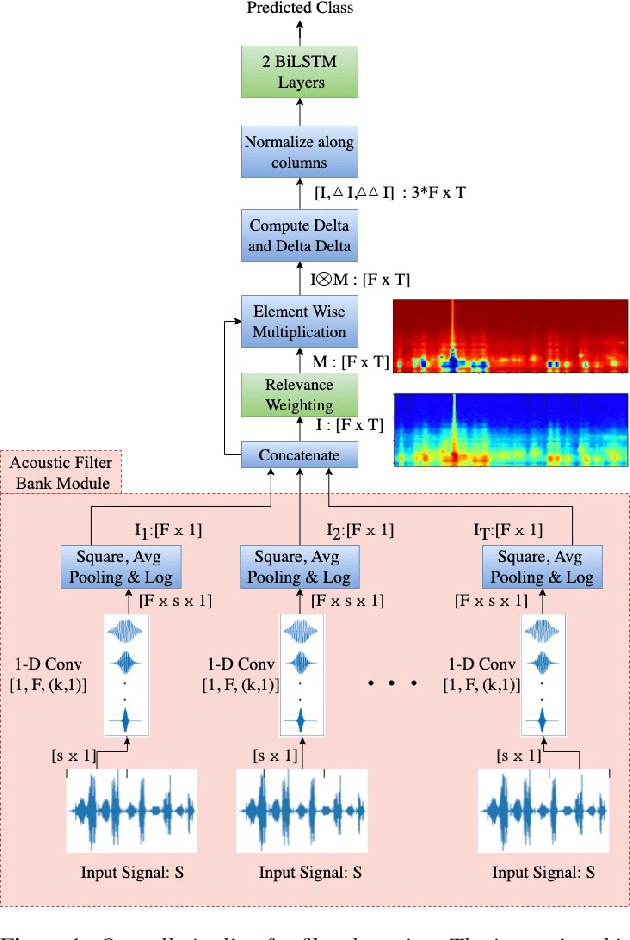
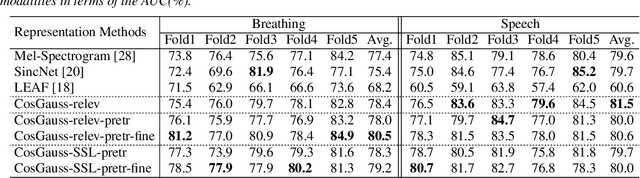
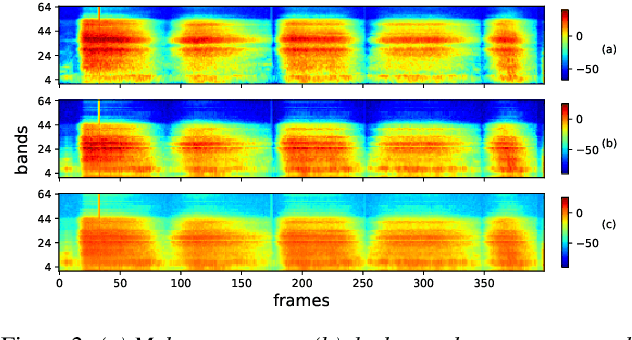
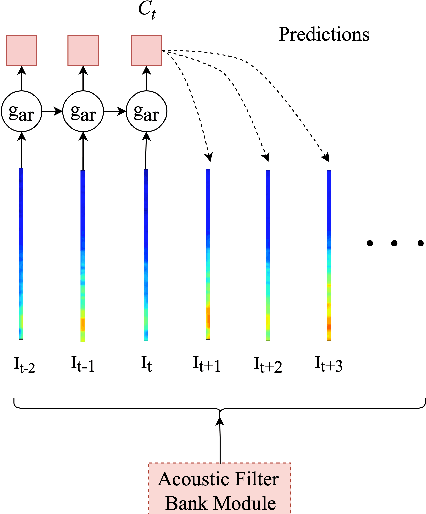
In this paper, we describe an approach for representation learning of audio signals for the task of COVID-19 detection. The raw audio samples are processed with a bank of 1-D convolutional filters that are parameterized as cosine modulated Gaussian functions. The choice of these kernels allows the interpretation of the filterbanks as smooth band-pass filters. The filtered outputs are pooled, log-compressed and used in a self-attention based relevance weighting mechanism. The relevance weighting emphasizes the key regions of the time-frequency decomposition that are important for the downstream task. The subsequent layers of the model consist of a recurrent architecture and the models are trained for a COVID-19 detection task. In our experiments on the Coswara data set, we show that the proposed model achieves significant performance improvements over the baseline system as well as other representation learning approaches. Further, the approach proposed is shown to be uniformly applicable for speech and breathing signals and for transfer learning from a larger data set.
Counter Hate Speech in Social Media: A Survey
Feb 21, 2022With the high prevalence of offensive language against minorities in social media, counter-hate speeches (CHS) generation is considered an automatic way of tackling this challenge. The CHS is supposed to appear as a third voice to educate people and keep the social [red lines bold] without limiting the principles of freedom of speech. In this paper, we review the most important research in the past and present with a main focus on methodologies, collected datasets and statistical analysis CHS's impact on social media. The CHS generation is based on the optimistic assumption that any attempt to intervene the hate speech in social media can play a positive role in this context. Beyond that, previous works ignored the investigation of the sequence of comments before and after the CHS. However, the positive impact is not guaranteed, as shown in some previous works. To the best of our knowledge, no attempt has been made to survey the related work to compare the past research in terms of CHS's impact on social media. We take the first step in this direction by providing a comprehensive review on related works and categorizing them based on different factors including impact, methodology, data source, etc.
Multi-Dialect Arabic Speech Recognition
Dec 25, 2021
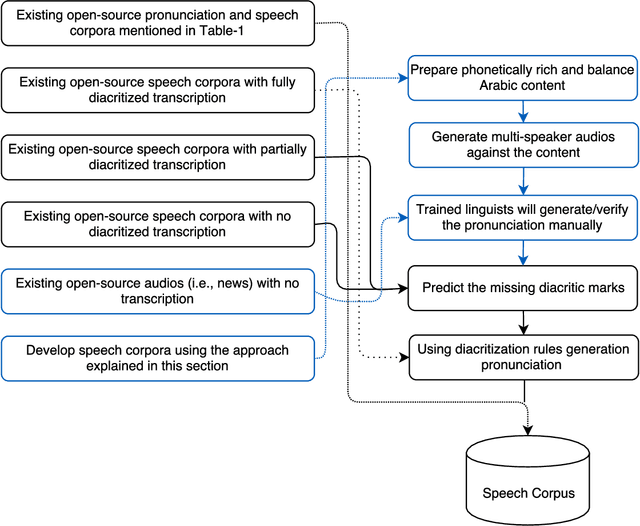
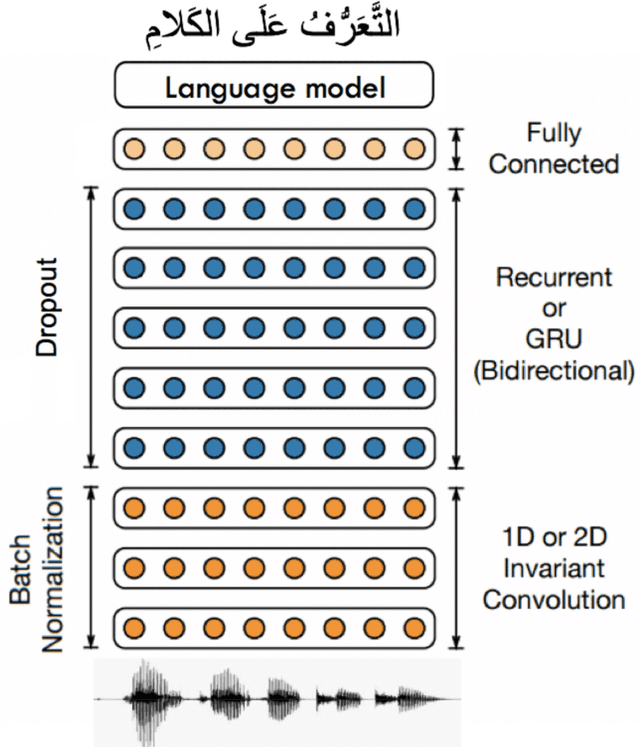

This paper presents the design and development of multi-dialect automatic speech recognition for Arabic. Deep neural networks are becoming an effective tool to solve sequential data problems, particularly, adopting an end-to-end training of the system. Arabic speech recognition is a complex task because of the existence of multiple dialects, non-availability of large corpora, and missing vocalization. Thus, the first contribution of this work is the development of a large multi-dialectal corpus with either full or at least partially vocalized transcription. Additionally, the open-source corpus has been gathered from multiple sources that bring non-standard Arabic alphabets in transcription which are normalized by defining a common character-set. The second contribution is the development of a framework to train an acoustic model achieving state-of-the-art performance. The network architecture comprises of a combination of convolutional and recurrent layers. The spectrogram features of the audio data are extracted in the frequency vs time domain and fed in the network. The output frames, produced by the recurrent model, are further trained to align the audio features with its corresponding transcription sequences. The sequence alignment is performed using a beam search decoder with a tetra-gram language model. The proposed system achieved a 14% error rate which outperforms previous systems.
Fast-Slow Transformer for Visually Grounding Speech
Sep 16, 2021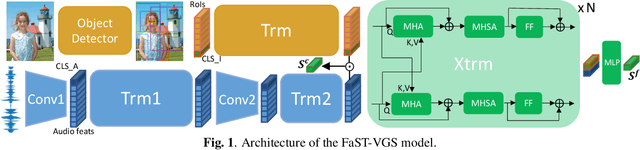
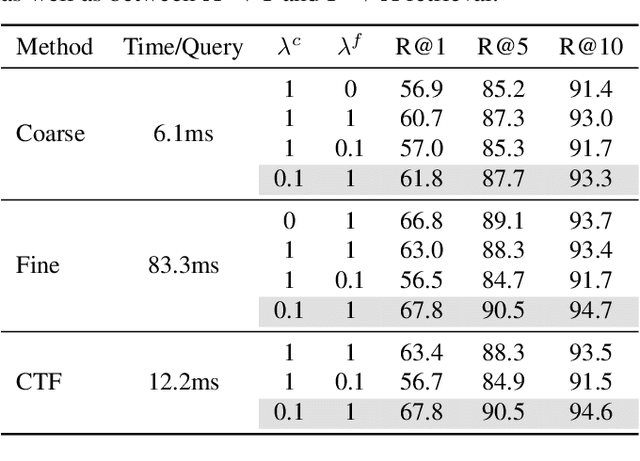
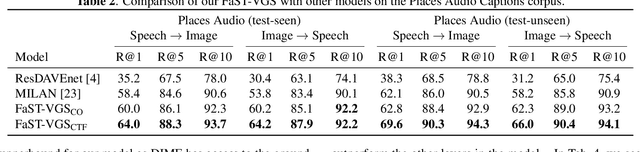
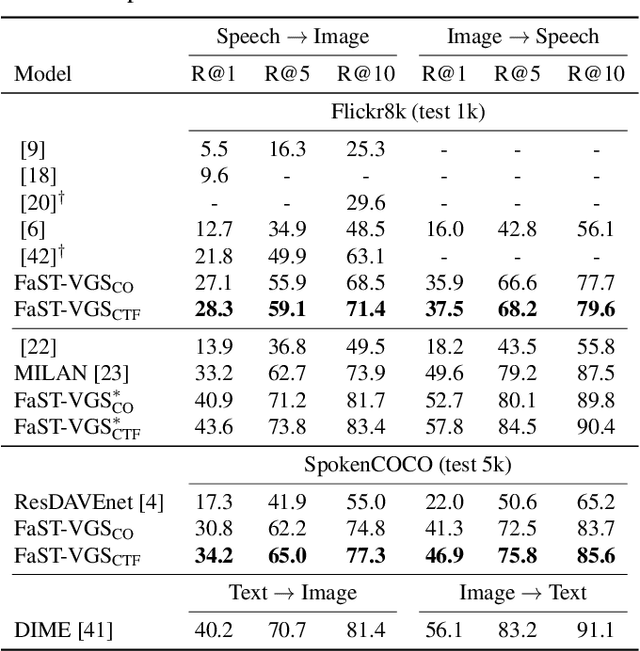
We present Fast-Slow Transformer for Visually Grounding Speech, or FaST-VGS. FaST-VGS is a Transformer-based model for learning the associations between raw speech waveforms and visual images. The model unifies dual-encoder and cross-attention architectures into a single model, reaping the superior retrieval speed of the former along with the accuracy of the latter. FaST-VGS achieves state-of-the-art speech-image retrieval accuracy on benchmark datasets, and its learned representations exhibit strong performance on the ZeroSpeech 2021 phonetic and semantic tasks.