 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Conformer-Based Self-Supervised Learning for Non-Speech Audio Tasks
Nov 10, 2021
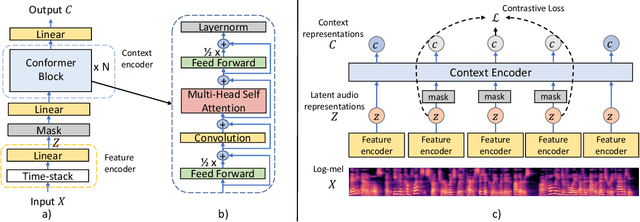
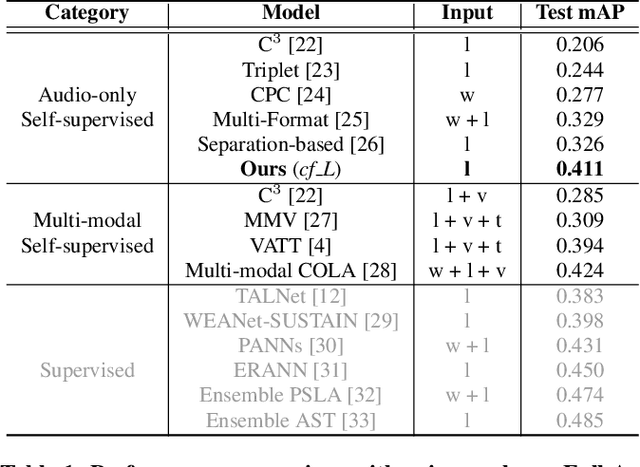

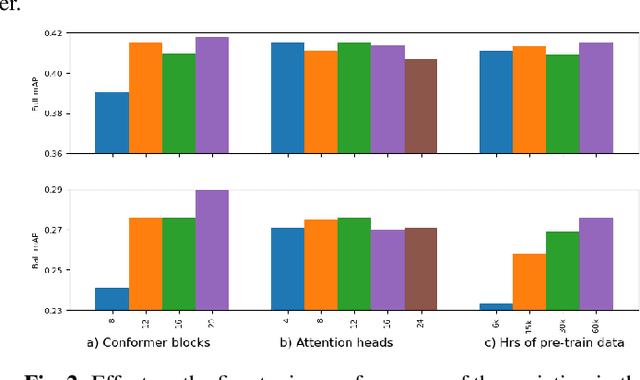
Representation learning from unlabeled data has been of major interest in artificial intelligence research. While self-supervised speech representation learning has been popular in the speech research community, very few works have comprehensively analyzed audio representation learning for non-speech audio tasks. In this paper, we propose a self-supervised audio representation learning method and apply it to a variety of downstream non-speech audio tasks. We combine the well-known wav2vec 2.0 framework, which has shown success in self-supervised learning for speech tasks, with parameter-efficient conformer architectures. Our self-supervised pre-training can reduce the need for labeled data by two-thirds. On the AudioSet benchmark, we achieve a mean average precision (mAP) score of 0.415, which is a new state-of-the-art on this dataset through audio-only self-supervised learning. Our fine-tuned conformers also surpass or match the performance of previous systems pre-trained in a supervised way on several downstream tasks. We further discuss the important design considerations for both pre-training and fine-tuning.
Lisan: Yemeni, Iraqi, Libyan, and Sudanese Arabic Dialect Copora with Morphological Annotations
Dec 17, 2022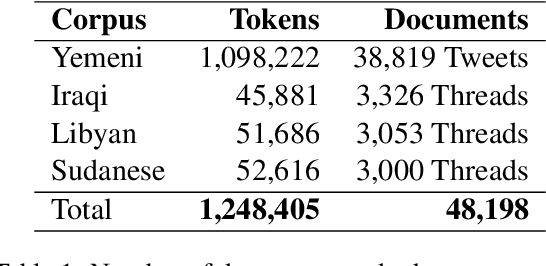
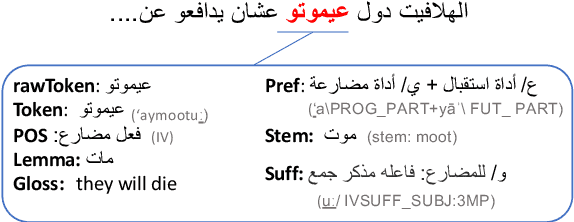
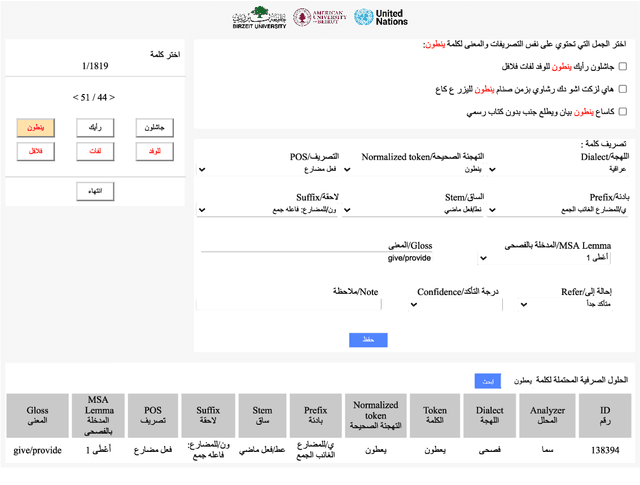
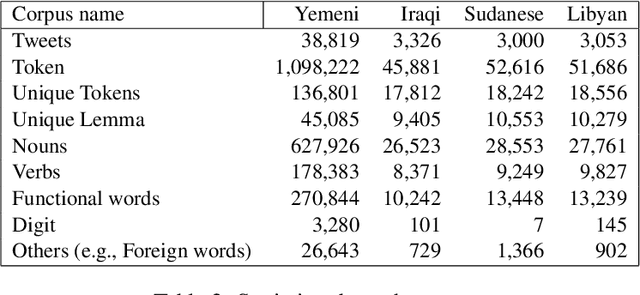
This article presents morphologically-annotated Yemeni, Sudanese, Iraqi, and Libyan Arabic dialects Lisan corpora. Lisan features around 1.2 million tokens. We collected the content of the corpora from several social media platforms. The Yemeni corpus (~ 1.05M tokens) was collected automatically from Twitter. The corpora of the other three dialects (~ 50K tokens each) came manually from Facebook and YouTube posts and comments. Thirty five (35) annotators who are native speakers of the target dialects carried out the annotations. The annotators segemented all words in the four corpora into prefixes, stems and suffixes and labeled each with different morphological features such as part of speech, lemma, and a gloss in English. An Arabic Dialect Annotation Toolkit ADAT was developped for the purpose of the annation. The annotators were trained on a set of guidelines and on how to use ADAT. We developed ADAT to assist the annotators and to ensure compatibility with SAMA and Curras tagsets. The tool is open source, and the four corpora are also available online.
Efficient Use of Large Pre-Trained Models for Low Resource ASR
Oct 26, 2022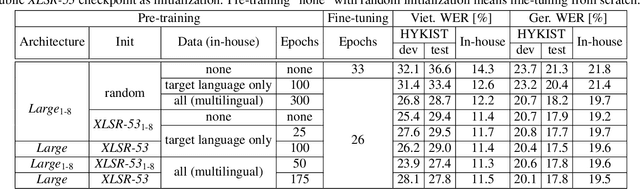
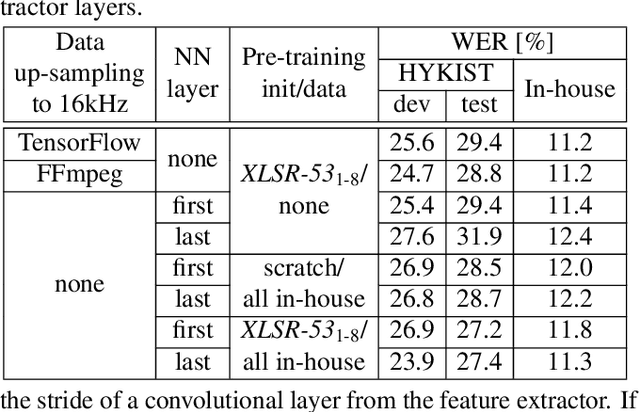
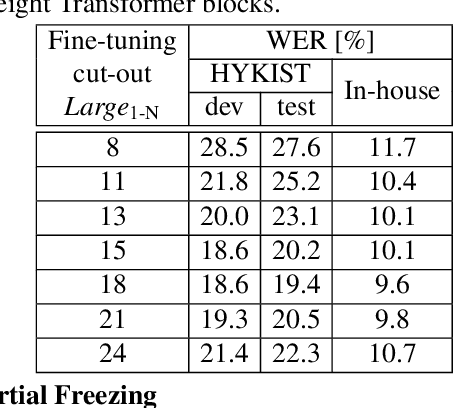
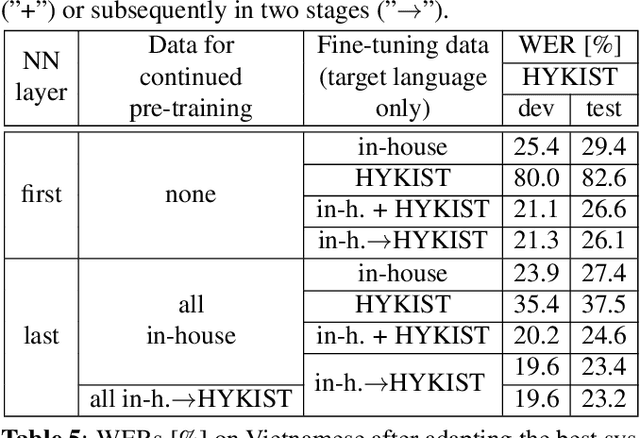
Automatic speech recognition (ASR) has been established as a well-performing technique for many scenarios where lots of labeled data is available. Additionally, unsupervised representation learning recently helped to tackle tasks with limited data. Following this, hardware limitations and applications give rise to the question how to efficiently take advantage of large pretrained models and reduce their complexity for downstream tasks. In this work, we study a challenging low resource conversational telephony speech corpus from the medical domain in Vietnamese and German. We show the benefits of using unsupervised techniques beyond simple fine-tuning of large pre-trained models, discuss how to adapt them to a practical telephony task including bandwidth transfer and investigate different data conditions for pre-training and fine-tuning. We outperform the project baselines by 22% relative using pretraining techniques. Further gains of 29% can be achieved by refinements of architecture and training and 6% by adding 0.8 h of in-domain adaptation data.
Speaker Diarization Based on Multi-channel Microphone Array in Small-scale Meeting
Oct 26, 2022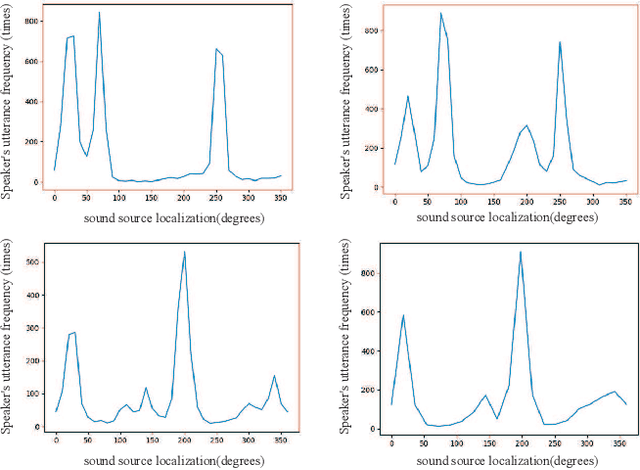
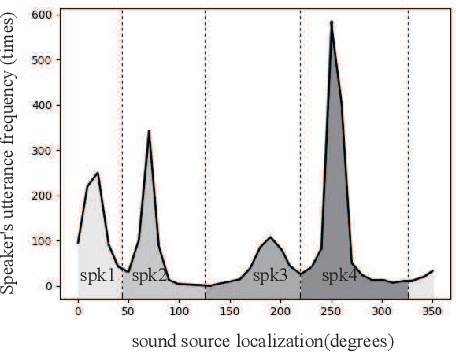
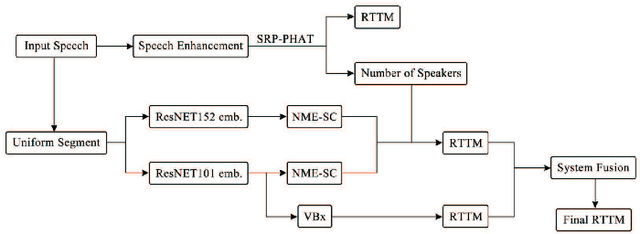

In the task of speaker diarization, the number of small-scale meetings accounts for a large proportion. When microphone arrays are employed as a recording device, its spatial information is usually ignored by most researchers. In this paper, inspired by the clustering method combining d-vector and microphone array spatial vector, we proposed a diarization method which using multi-channel microphone arrays for a meeting with no more than 4 speakers. We utilize speech enhancement to preprocess the audio from the microphone array. The Steered-Response Power Phase Transform (SRP-PHAT) algorithm are employed to get more accurate speakers, and apply the number of speakers to recluster the speech segments to achieve better performance. Finally, we fuse our system by DOVER-LAP to get the best result. We evaluated our system on the AMI corpus. Compared with the best experimental results so far, our system has achieved largely improvement in the diarization error rate (DER).
Squeezeformer: An Efficient Transformer for Automatic Speech Recognition
Jun 02, 2022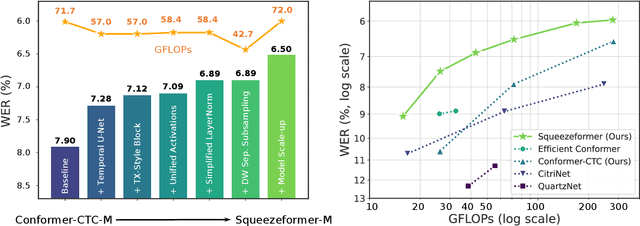
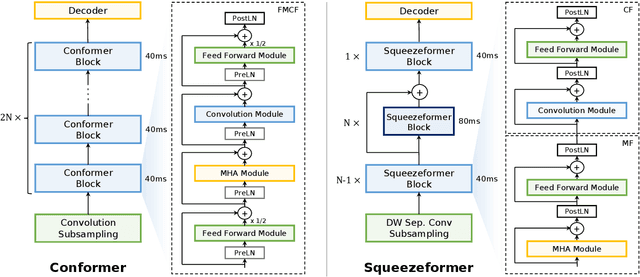
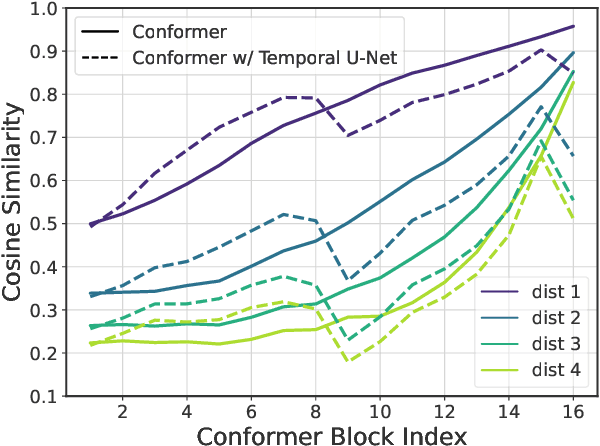
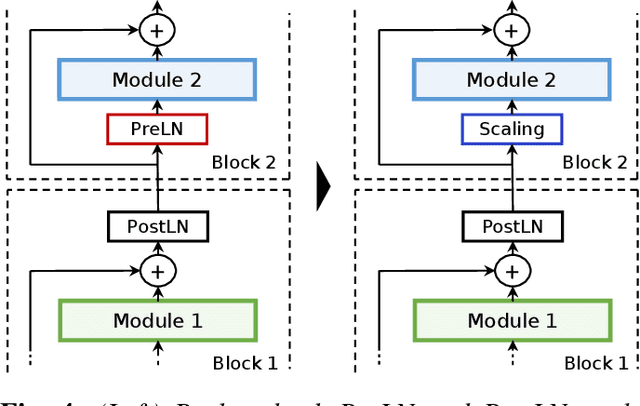
The recently proposed Conformer model has become the de facto backbone model for various downstream speech tasks based on its hybrid attention-convolution architecture that captures both local and global features. However, through a series of systematic studies, we find that the Conformer architecture's design choices are not optimal. After reexamining the design choices for both the macro and micro-architecture of Conformer, we propose the Squeezeformer model, which consistently outperforms the state-of-the-art ASR models under the same training schemes. In particular, for the macro-architecture, Squeezeformer incorporates (i) the Temporal U-Net structure, which reduces the cost of the multi-head attention modules on long sequences, and (ii) a simpler block structure of feed-forward module, followed up by multi-head attention or convolution modules, instead of the Macaron structure proposed in Conformer. Furthermore, for the micro-architecture, Squeezeformer (i) simplifies the activations in the convolutional block, (ii) removes redundant Layer Normalization operations, and (iii) incorporates an efficient depth-wise downsampling layer to efficiently sub-sample the input signal. Squeezeformer achieves state-of-the-art results of 7.5%, 6.5%, and 6.0% word-error-rate on Librispeech test-other without external language models. This is 3.1%, 1.4%, and 0.6% better than Conformer-CTC with the same number of FLOPs. Our code is open-sourced and available online.
FMFCC-A: A Challenging Mandarin Dataset for Synthetic Speech Detection
Oct 18, 2021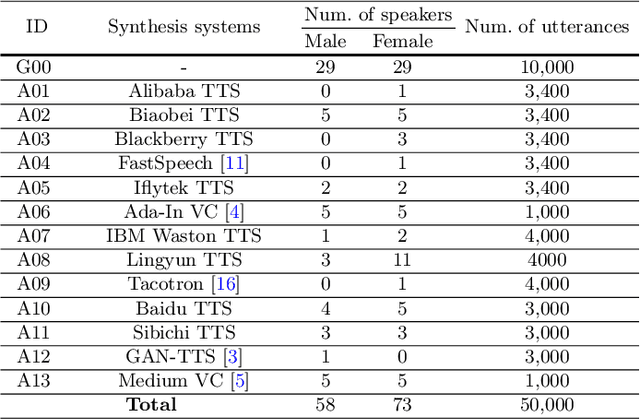
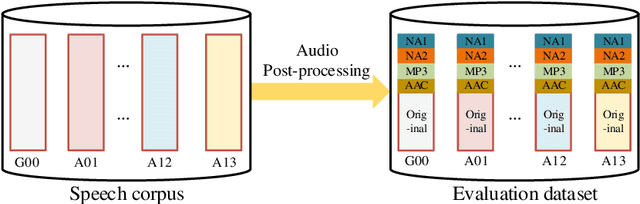

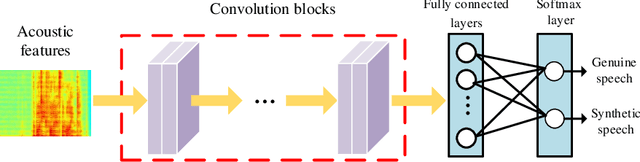
As increasing development of text-to-speech (TTS) and voice conversion (VC) technologies, the detection of synthetic speech has been suffered dramatically. In order to promote the development of synthetic speech detection model against Mandarin TTS and VC technologies, we have constructed a challenging Mandarin dataset and organized the accompanying audio track of the first fake media forensic challenge of China Society of Image and Graphics (FMFCC-A). The FMFCC-A dataset is by far the largest publicly-available Mandarin dataset for synthetic speech detection, which contains 40,000 synthesized Mandarin utterances that generated by 11 Mandarin TTS systems and two Mandarin VC systems, and 10,000 genuine Mandarin utterances collected from 58 speakers. The FMFCC-A dataset is divided into the training, development and evaluation sets, which are used for the research of detection of synthesized Mandarin speech under various previously unknown speech synthesis systems or audio post-processing operations. In addition to describing the construction of the FMFCC-A dataset, we provide a detailed analysis of two baseline methods and the top-performing submissions from the FMFCC-A, which illustrates the usefulness and challenge of FMFCC-A dataset. We hope that the FMFCC-A dataset can fill the gap of lack of Mandarin datasets for synthetic speech detection.
Controllable Multichannel Speech Dereverberation based on Deep Neural Networks
Oct 16, 2021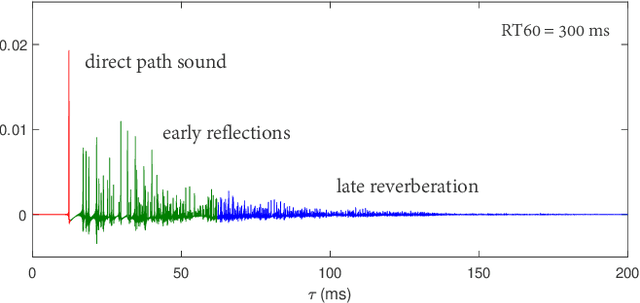
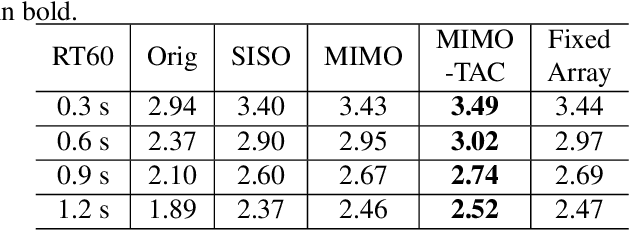
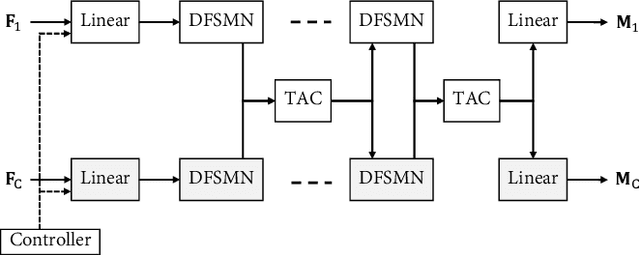
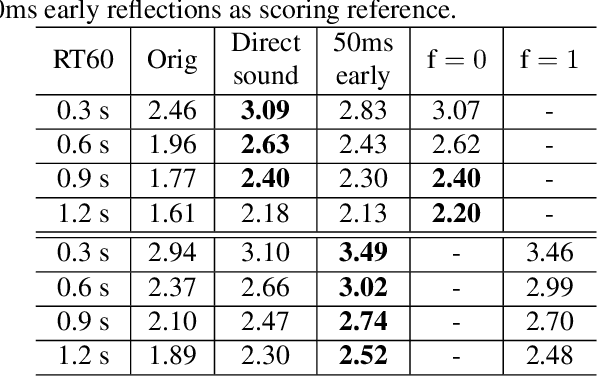
Neural network based speech dereverberation has achieved promising results in recent studies. Nevertheless, many are focused on recovery of only the direct path sound and early reflections, which could be beneficial to speech perception, are discarded. The performance of a model trained to recover clean speech degrades when evaluated on early reverberation targets, and vice versa. This paper proposes a novel deep neural network based multichannel speech dereverberation algorithm, in which the dereverberation level is controllable. This is realized by adding a simple floating-point number as target controller of the model. Experiments are conducted using spatially distributed microphones, and the efficacy of the proposed algorithm is confirmed in various simulated conditions.
Fast-Slow Transformer for Visually Grounding Speech
Sep 16, 2021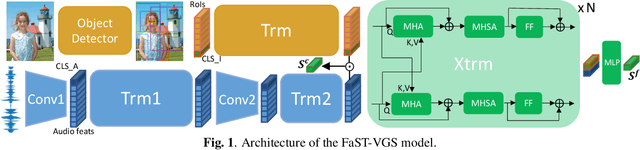
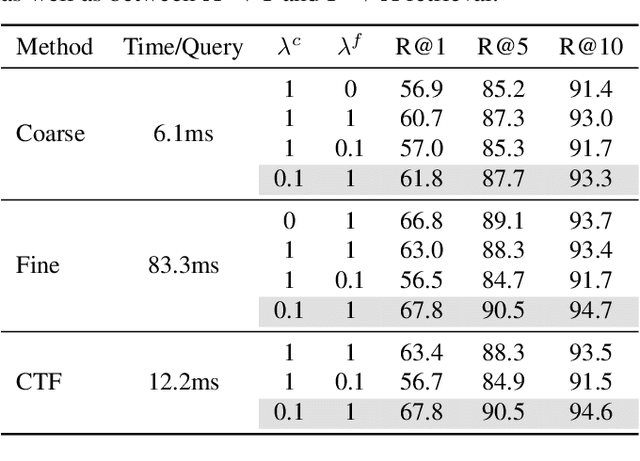
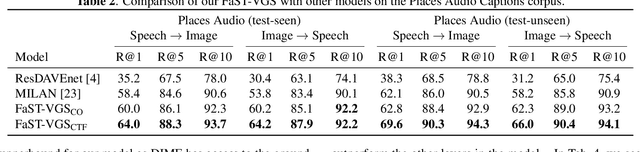
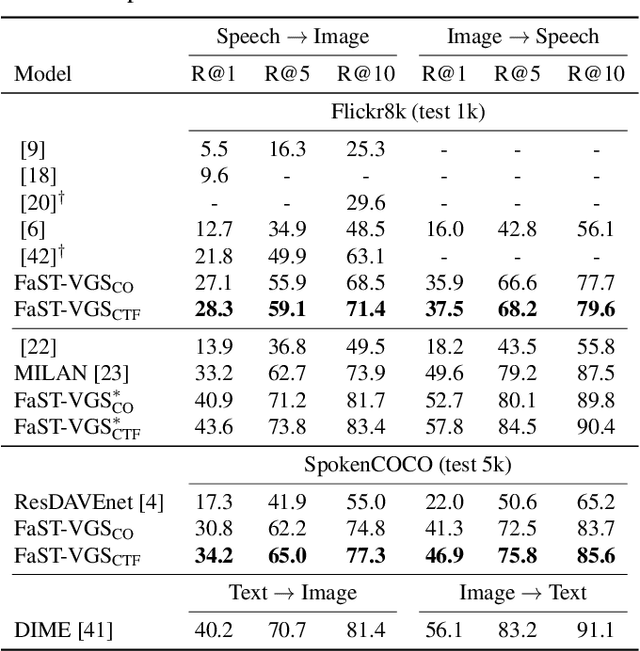
We present Fast-Slow Transformer for Visually Grounding Speech, or FaST-VGS. FaST-VGS is a Transformer-based model for learning the associations between raw speech waveforms and visual images. The model unifies dual-encoder and cross-attention architectures into a single model, reaping the superior retrieval speed of the former along with the accuracy of the latter. FaST-VGS achieves state-of-the-art speech-image retrieval accuracy on benchmark datasets, and its learned representations exhibit strong performance on the ZeroSpeech 2021 phonetic and semantic tasks.
Are word boundaries useful for unsupervised language learning?
Oct 06, 2022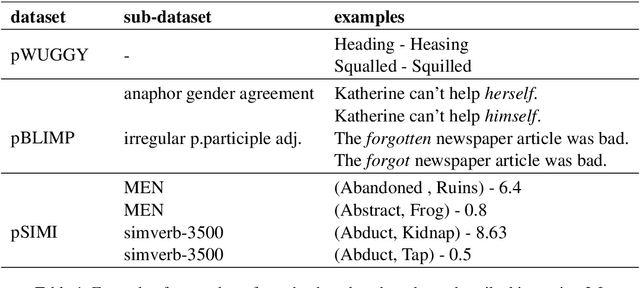
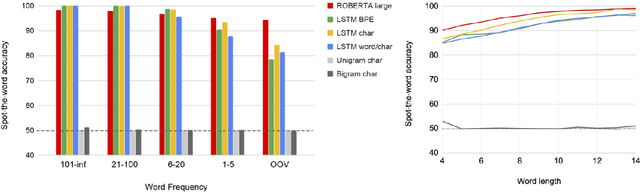
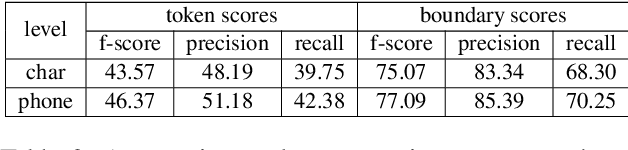
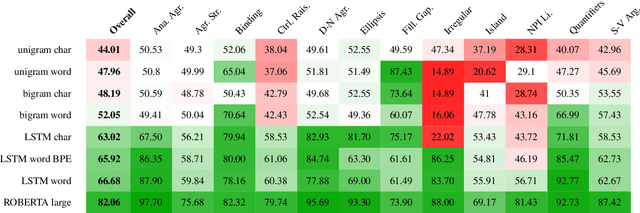
Word or word-fragment based Language Models (LM) are typically preferred over character-based ones in many downstream applications. This may not be surprising as words seem more linguistically relevant units than characters. Words provide at least two kinds of relevant information: boundary information and meaningful units. However, word boundary information may be absent or unreliable in the case of speech input (word boundaries are not marked explicitly in the speech stream). Here, we systematically compare LSTMs as a function of the input unit (character, phoneme, word, word part), with or without gold boundary information. We probe linguistic knowledge in the networks at the lexical, syntactic and semantic levels using three speech-adapted black box NLP psycholinguistically-inpired benchmarks (pWUGGY, pBLIMP, pSIMI). We find that the absence of boundaries costs between 2\% and 28\% in relative performance depending on the task. We show that gold boundaries can be replaced by automatically found ones obtained with an unsupervised segmentation algorithm, and that even modest segmentation performance gives a gain in performance on two of the three tasks compared to basic character/phone based models without boundary information.
VCVTS: Multi-speaker Video-to-Speech synthesis via cross-modal knowledge transfer from voice conversion
Feb 18, 2022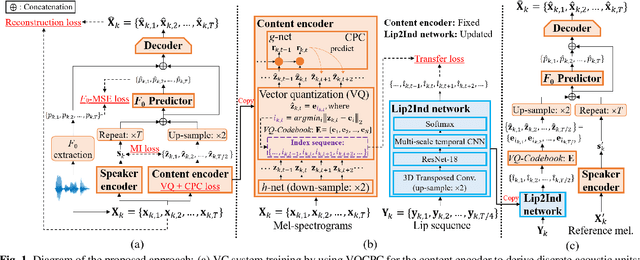
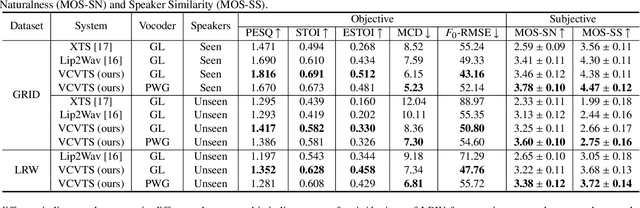
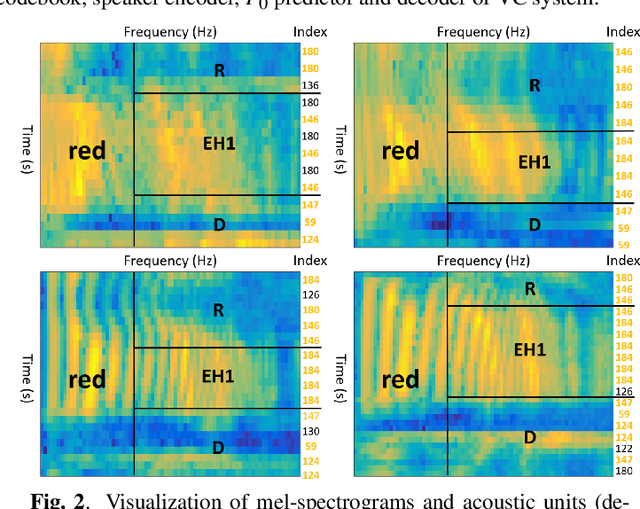
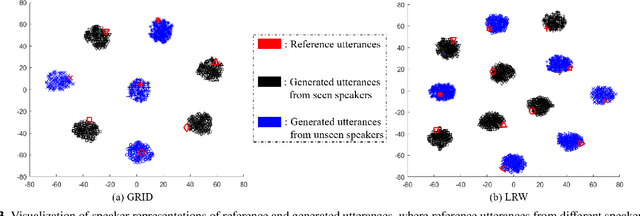
Though significant progress has been made for speaker-dependent Video-to-Speech (VTS) synthesis, little attention is devoted to multi-speaker VTS that can map silent video to speech, while allowing flexible control of speaker identity, all in a single system. This paper proposes a novel multi-speaker VTS system based on cross-modal knowledge transfer from voice conversion (VC), where vector quantization with contrastive predictive coding (VQCPC) is used for the content encoder of VC to derive discrete phoneme-like acoustic units, which are transferred to a Lip-to-Index (Lip2Ind) network to infer the index sequence of acoustic units. The Lip2Ind network can then substitute the content encoder of VC to form a multi-speaker VTS system to convert silent video to acoustic units for reconstructing accurate spoken content. The VTS system also inherits the advantages of VC by using a speaker encoder to produce speaker representations to effectively control the speaker identity of generated speech. Extensive evaluations verify the effectiveness of proposed approach, which can be applied in both constrained vocabulary and open vocabulary conditions, achieving state-of-the-art performance in generating high-quality speech with high naturalness, intelligibility and speaker similarity. Our demo page is released here: https://wendison.github.io/VCVTS-demo/