 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speaker Diarization Based on Multi-channel Microphone Array in Small-scale Meeting
Oct 26, 2022
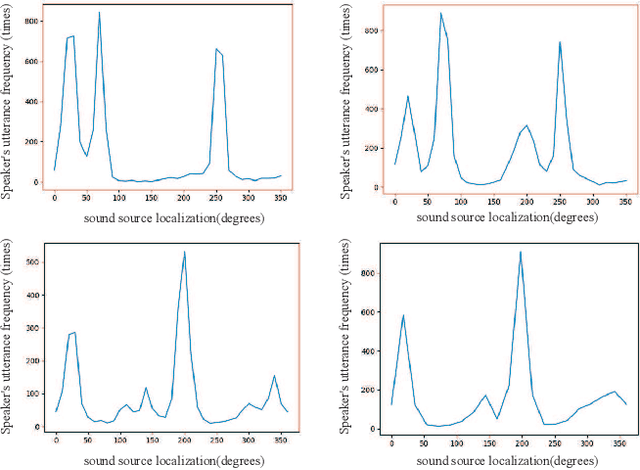
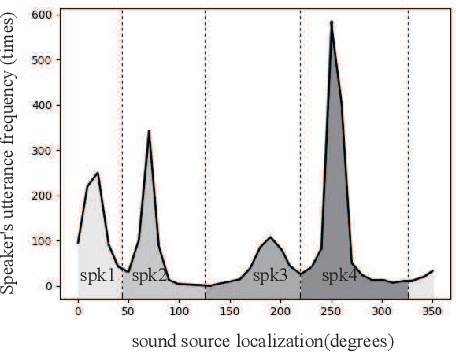
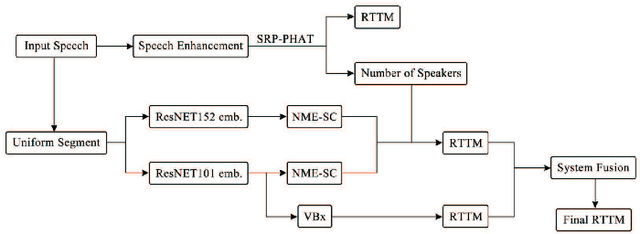

In the task of speaker diarization, the number of small-scale meetings accounts for a large proportion. When microphone arrays are employed as a recording device, its spatial information is usually ignored by most researchers. In this paper, inspired by the clustering method combining d-vector and microphone array spatial vector, we proposed a diarization method which using multi-channel microphone arrays for a meeting with no more than 4 speakers. We utilize speech enhancement to preprocess the audio from the microphone array. The Steered-Response Power Phase Transform (SRP-PHAT) algorithm are employed to get more accurate speakers, and apply the number of speakers to recluster the speech segments to achieve better performance. Finally, we fuse our system by DOVER-LAP to get the best result. We evaluated our system on the AMI corpus. Compared with the best experimental results so far, our system has achieved largely improvement in the diarization error rate (DER).
StyleTalk: One-shot Talking Head Generation with Controllable Speaking Styles
Jan 03, 2023
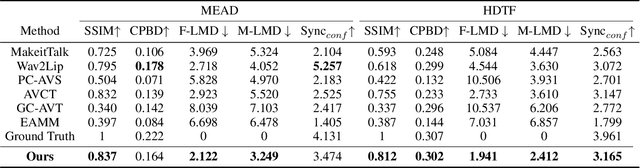
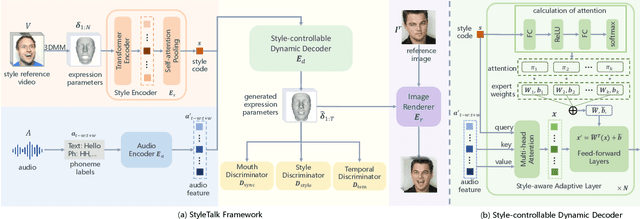
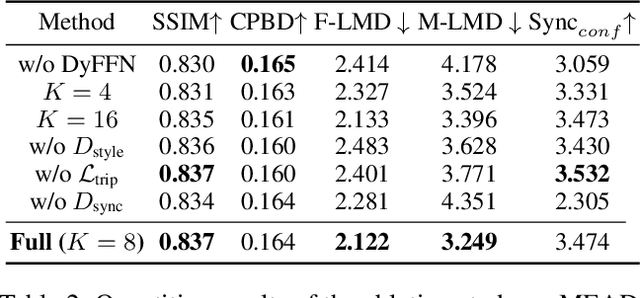
Different people speak with diverse personalized speaking styles. Although existing one-shot talking head methods have made significant progress in lip sync, natural facial expressions, and stable head motions, they still cannot generate diverse speaking styles in the final talking head videos. To tackle this problem, we propose a one-shot style-controllable talking face generation framework. In a nutshell, we aim to attain a speaking style from an arbitrary reference speaking video and then drive the one-shot portrait to speak with the reference speaking style and another piece of audio. Specifically, we first develop a style encoder to extract dynamic facial motion patterns of a style reference video and then encode them into a style code. Afterward, we introduce a style-controllable decoder to synthesize stylized facial animations from the speech content and style code. In order to integrate the reference speaking style into generated videos, we design a style-aware adaptive transformer, which enables the encoded style code to adjust the weights of the feed-forward layers accordingly. Thanks to the style-aware adaptation mechanism, the reference speaking style can be better embedded into synthesized videos during decoding. Extensive experiments demonstrate that our method is capable of generating talking head videos with diverse speaking styles from only one portrait image and an audio clip while achieving authentic visual effects. Project Page: https://github.com/FuxiVirtualHuman/styletalk.
Effectiveness of Text, Acoustic, and Lattice-based representations in Spoken Language Understanding tasks
Dec 16, 2022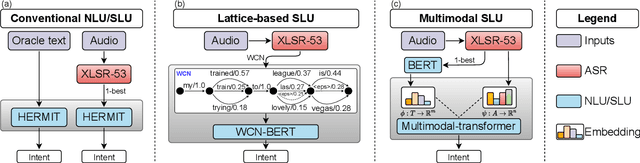
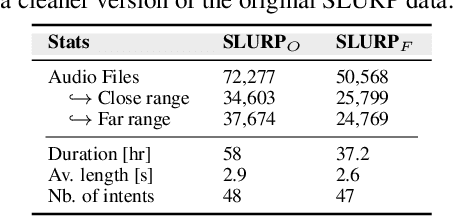
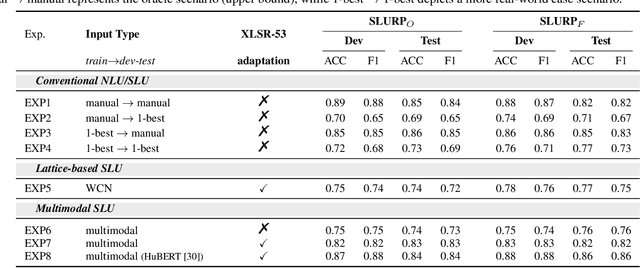

In this paper, we perform an exhaustive evaluation of different representations to address the intent classification problem in a Spoken Language Understanding (SLU) setup. We benchmark three types of systems to perform the SLU intent detection task: 1) text-based, 2) lattice-based, and a novel 3) multimodal approach. Our work provides a comprehensive analysis of what could be the achievable performance of different state-of-the-art SLU systems under different circumstances, e.g., automatically- vs. manually-generated transcripts. We evaluate the systems on the publicly available SLURP spoken language resource corpus. Our results indicate that using richer forms of Automatic Speech Recognition (ASR) outputs allows SLU systems to improve in comparison to the 1-best setup (4% relative improvement). However, crossmodal approaches, i.e., learning from acoustic and text embeddings, obtains performance similar to the oracle setup, and a relative improvement of 18% over the 1-best configuration. Thus, crossmodal architectures represent a good alternative to overcome the limitations of working purely automatically generated textual data.
Disappeared Command: Spoofing Attack On Automatic Speech Recognition Systems with Sound Masking
Apr 19, 2022

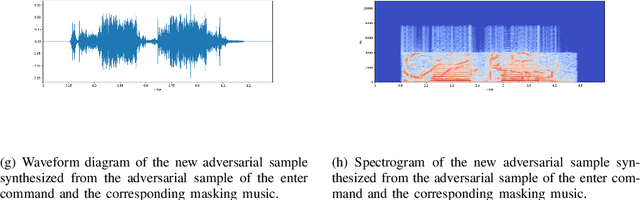
The development of deep learning technology has greatly promoted the performance improvement of automatic speech recognition (ASR) technology, which has demonstrated an ability comparable to human hearing in many tasks. Voice interfaces are becoming more and more widely used as input for many applications and smart devices. However, existing research has shown that DNN is easily disturbed by slight disturbances and makes false recognition, which is extremely dangerous for intelligent voice applications controlled by voice.
Handling Bias in Toxic Speech Detection: A Survey
Feb 02, 2022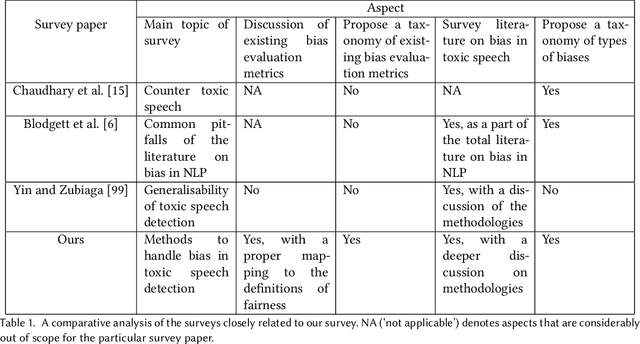
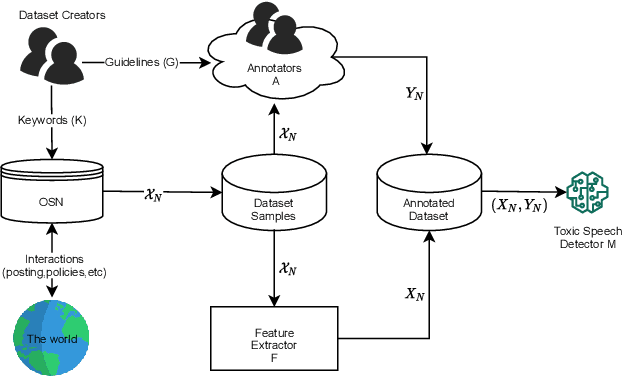
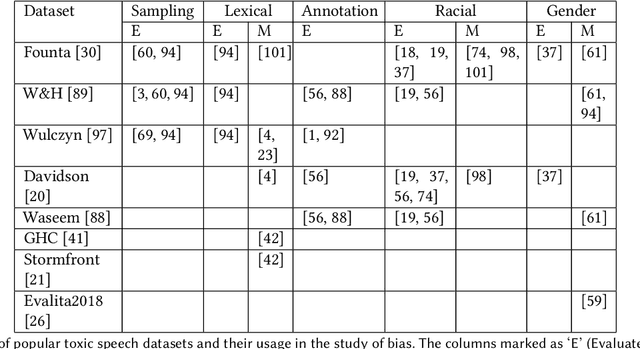
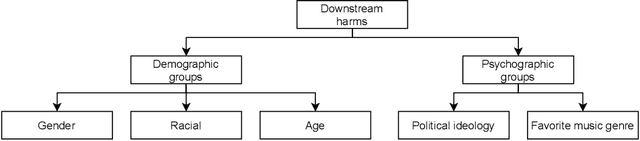
The massive growth of social media usage has witnessed a tsunami of online toxicity in teams of hate speech, abusive posts, cyberbullying, etc. Detecting online toxicity is challenging due to its inherent subjectivity. Factors such as the context of the speech, geography, socio-political climate, and background of the producers and consumers of the posts play a crucial role in determining if the content can be flagged as toxic. Adoption of automated toxicity detection models in production can lead to a sidelining of the various demographic and psychographic groups they aim to help in the first place. It has piqued researchers' interest in examining unintended biases and their mitigation. Due to the nascent and multi-faceted nature of the work, complete literature is chaotic in its terminologies, techniques, and findings. In this paper, we put together a systematic study to discuss the limitations and challenges of existing methods. We start by developing a taxonomy for categorising various unintended biases and a suite of evaluation metrics proposed to quantify such biases. We take a closer look at each proposed method for evaluating and mitigating bias in toxic speech detection. To examine the limitations of existing methods, we also conduct a case study to introduce the concept of bias shift due to knowledge-based bias mitigation methods. The survey concludes with an overview of the critical challenges, research gaps and future directions. While reducing toxicity on online platforms continues to be an active area of research, a systematic study of various biases and their mitigation strategies will help the research community produce robust and fair models.
Predicting Knowledge Gain for MOOC Video Consumption
Dec 13, 2022Informal learning on the Web using search engines as well as more structured learning on MOOC platforms have become very popular in recent years. As a result of the vast amount of available learning resources, intelligent retrieval and recommendation methods are indispensable -- this is true also for MOOC videos. However, the automatic assessment of this content with regard to predicting (potential) knowledge gain has not been addressed by previous work yet. In this paper, we investigate whether we can predict learning success after MOOC video consumption using 1) multimodal features covering slide and speech content, and 2) a wide range of text-based features describing the content of the video. In a comprehensive experimental setting, we test four different classifiers and various feature subset combinations. We conduct a detailed feature importance analysis to gain insights in which modality benefits knowledge gain prediction the most.
* 13 pages, 1 figure, 3 tables
Advances in Speech Vocoding for Text-to-Speech with Continuous Parameters
Jun 19, 2021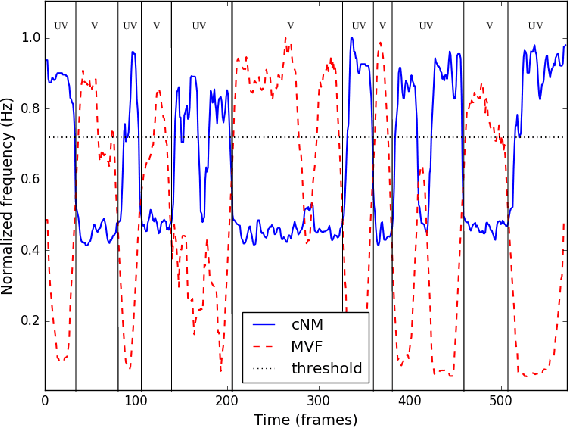
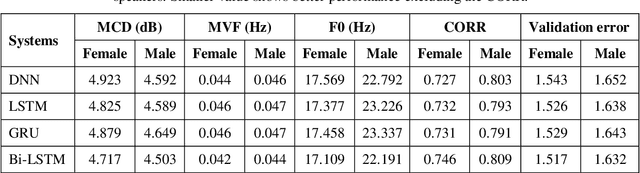
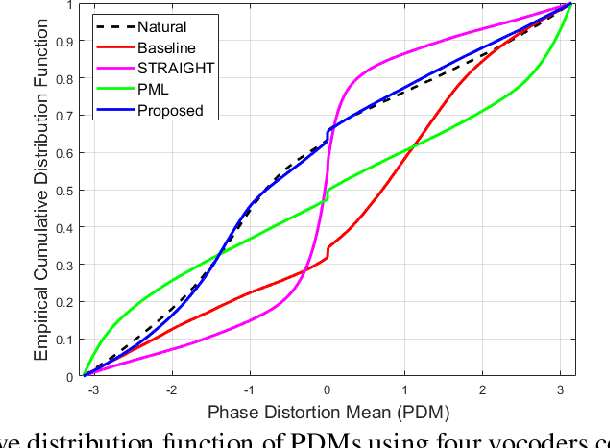
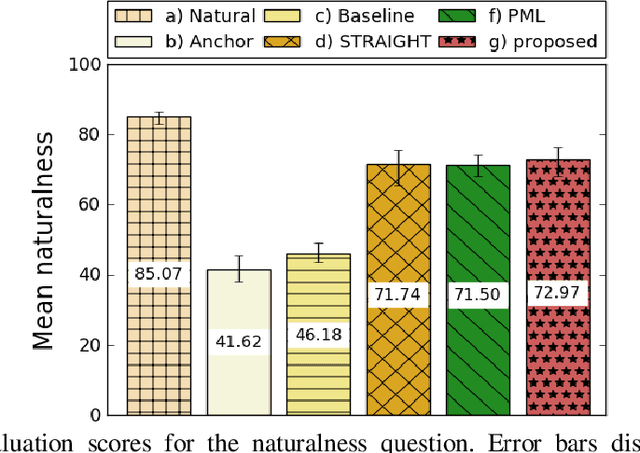
Vocoders received renewed attention as main components in statistical parametric text-to-speech (TTS) synthesis and speech transformation systems. Even though there are vocoding techniques give almost accepted synthesized speech, their high computational complexity and irregular structures are still considered challenging concerns, which yield a variety of voice quality degradation. Therefore, this paper presents new techniques in a continuous vocoder, that is all features are continuous and presents a flexible speech synthesis system. First, a new continuous noise masking based on the phase distortion is proposed to eliminate the perceptual impact of the residual noise and letting an accurate reconstruction of noise characteristics. Second, we addressed the need of neural sequence to sequence modeling approach for the task of TTS based on recurrent networks. Bidirectional long short-term memory (LSTM) and gated recurrent unit (GRU) are studied and applied to model continuous parameters for more natural-sounding like a human. The evaluation results proved that the proposed model achieves the state-of-the-art performance of the speech synthesis compared with the other traditional methods.
data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
Feb 07, 2022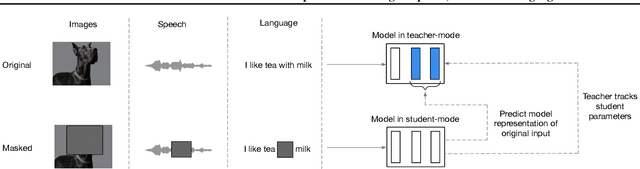
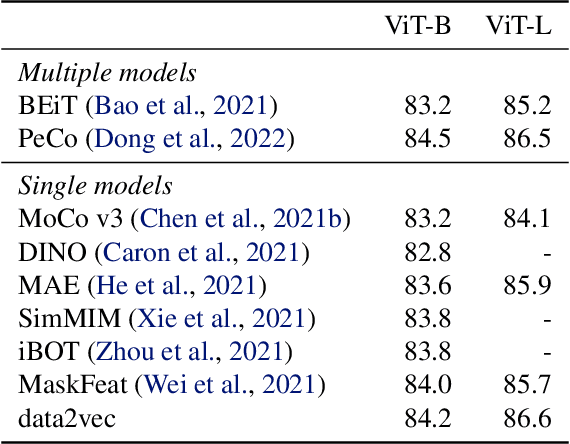
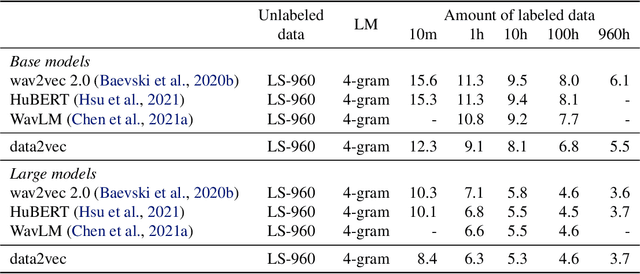
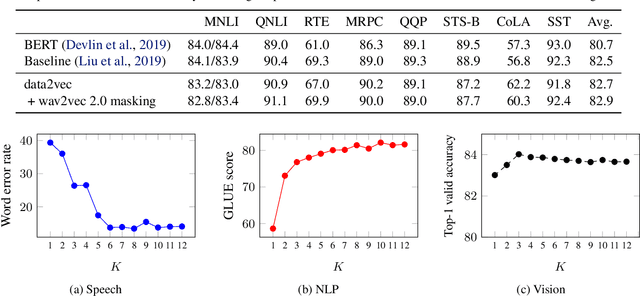
While the general idea of self-supervised learning is identical across modalities, the actual algorithms and objectives differ widely because they were developed with a single modality in mind. To get us closer to general self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech, NLP or computer vision. The core idea is to predict latent representations of the full input data based on a masked view of the input in a self-distillation setup using a standard Transformer architecture. Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which are local in nature, data2vec predicts contextualized latent representations that contain information from the entire input. Experiments on the major benchmarks of speech recognition, image classification, and natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
Are word boundaries useful for unsupervised language learning?
Oct 06, 2022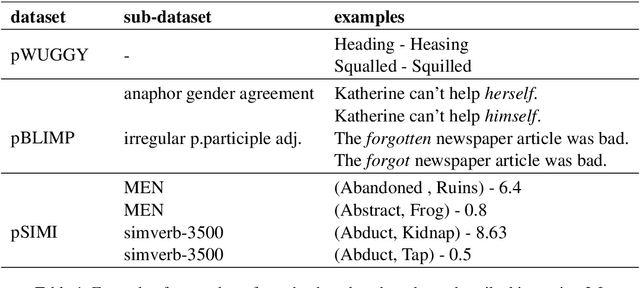
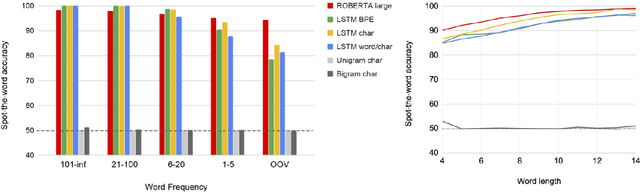
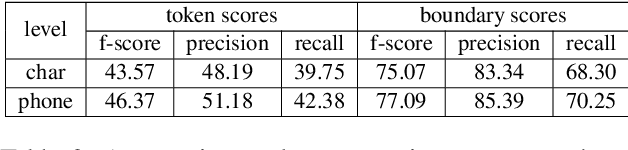
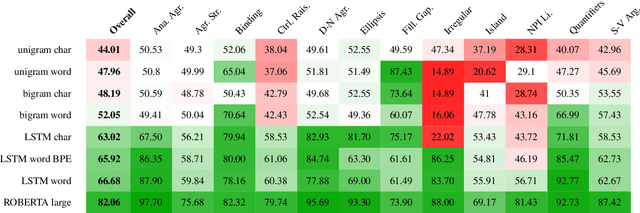
Word or word-fragment based Language Models (LM) are typically preferred over character-based ones in many downstream applications. This may not be surprising as words seem more linguistically relevant units than characters. Words provide at least two kinds of relevant information: boundary information and meaningful units. However, word boundary information may be absent or unreliable in the case of speech input (word boundaries are not marked explicitly in the speech stream). Here, we systematically compare LSTMs as a function of the input unit (character, phoneme, word, word part), with or without gold boundary information. We probe linguistic knowledge in the networks at the lexical, syntactic and semantic levels using three speech-adapted black box NLP psycholinguistically-inpired benchmarks (pWUGGY, pBLIMP, pSIMI). We find that the absence of boundaries costs between 2\% and 28\% in relative performance depending on the task. We show that gold boundaries can be replaced by automatically found ones obtained with an unsupervised segmentation algorithm, and that even modest segmentation performance gives a gain in performance on two of the three tasks compared to basic character/phone based models without boundary information.
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
Nov 19, 2021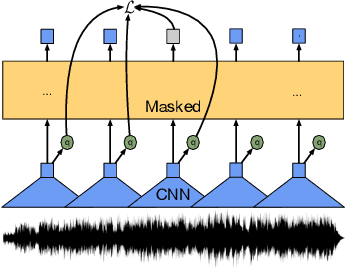
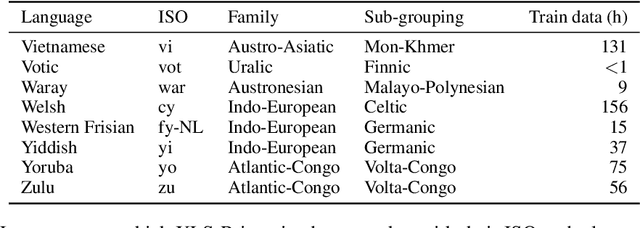
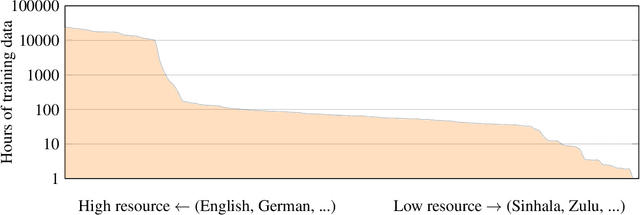

This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. We train models with up to 2B parameters on nearly half a million hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 14-34% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform English-only pretraining when translating English speech into other languages, a setting which favors monolingual pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.