 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Visual Speech Recognition for Multiple Languages in the Wild
Feb 26, 2022
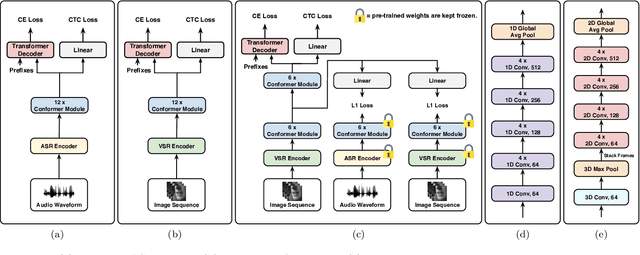
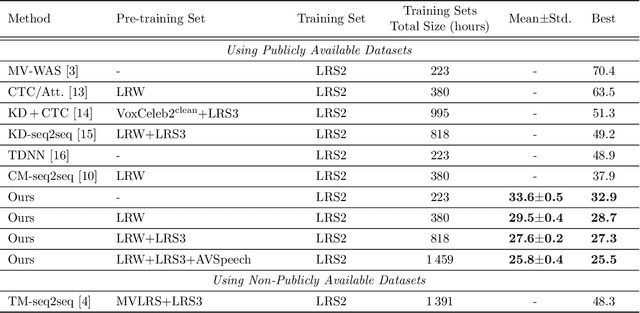
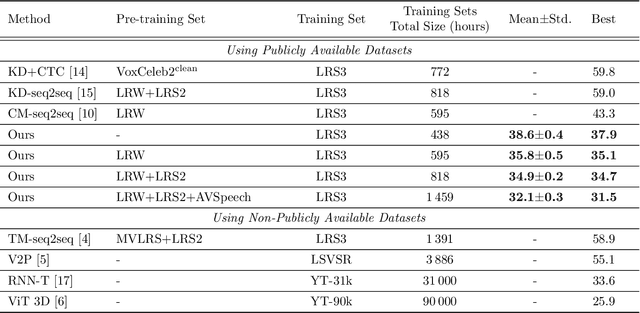
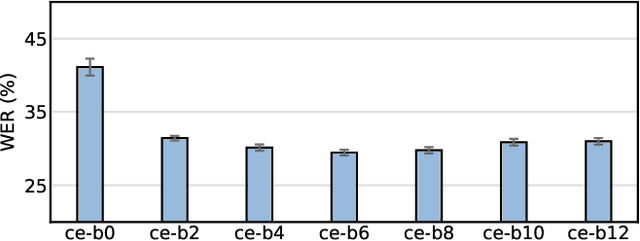
Visual speech recognition (VSR) aims to recognise the content of speech based on the lip movements without relying on the audio stream. Advances in deep learning and the availability of large audio-visual datasets have led to the development of much more accurate and robust VSR models than ever before. However, these advances are usually due to larger training sets rather than the model design. In this work, we demonstrate that designing better models is equally important to using larger training sets. We propose the addition of prediction-based auxiliary tasks to a VSR model and highlight the importance of hyper-parameter optimisation and appropriate data augmentations. We show that such model works for different languages and outperforms all previous methods trained on publicly available datasets by a large margin. It even outperforms models that were trained on non-publicly available datasets containing up to to 21 times more data. We show furthermore that using additional training data, even in other languages or with automatically generated transcriptions, results in further improvement.
Advances in Speech Vocoding for Text-to-Speech with Continuous Parameters
Jun 19, 2021
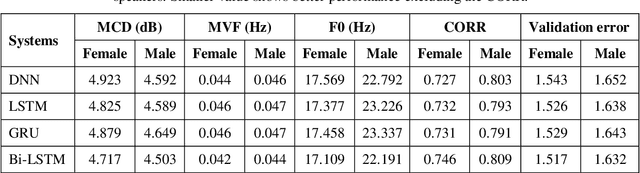
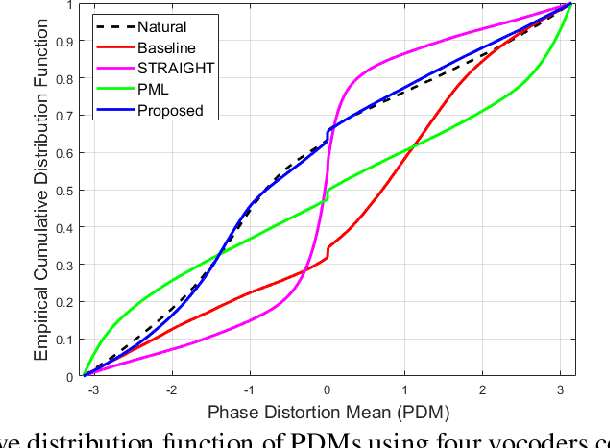
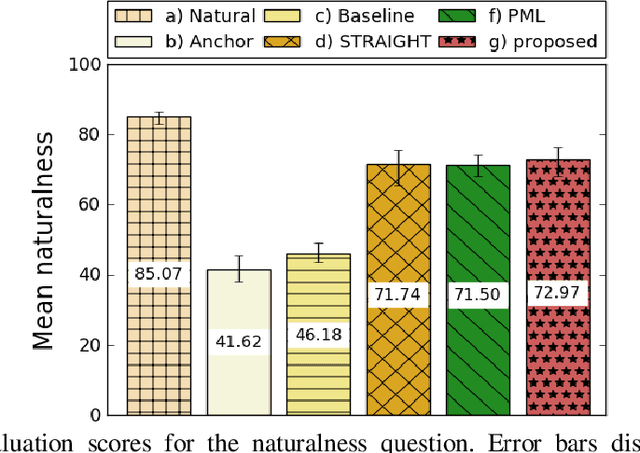
Vocoders received renewed attention as main components in statistical parametric text-to-speech (TTS) synthesis and speech transformation systems. Even though there are vocoding techniques give almost accepted synthesized speech, their high computational complexity and irregular structures are still considered challenging concerns, which yield a variety of voice quality degradation. Therefore, this paper presents new techniques in a continuous vocoder, that is all features are continuous and presents a flexible speech synthesis system. First, a new continuous noise masking based on the phase distortion is proposed to eliminate the perceptual impact of the residual noise and letting an accurate reconstruction of noise characteristics. Second, we addressed the need of neural sequence to sequence modeling approach for the task of TTS based on recurrent networks. Bidirectional long short-term memory (LSTM) and gated recurrent unit (GRU) are studied and applied to model continuous parameters for more natural-sounding like a human. The evaluation results proved that the proposed model achieves the state-of-the-art performance of the speech synthesis compared with the other traditional methods.
Optimizing Shoulder to Shoulder: A Coordinated Sub-Band Fusion Model for Real-Time Full-Band Speech Enhancement
Mar 30, 2022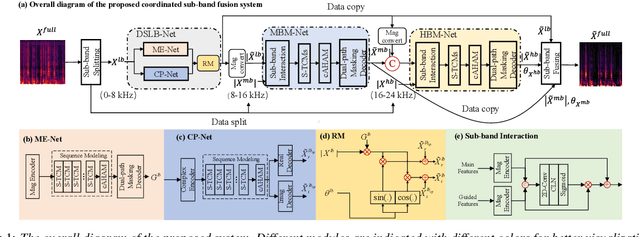
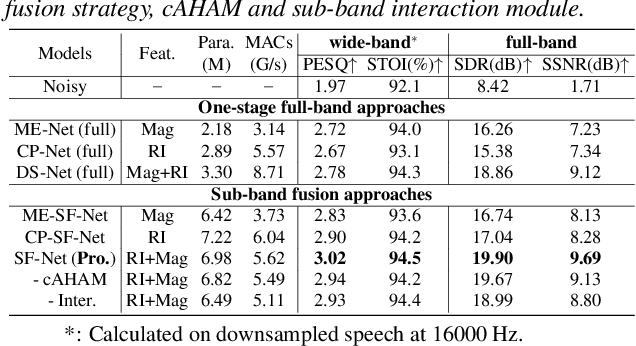
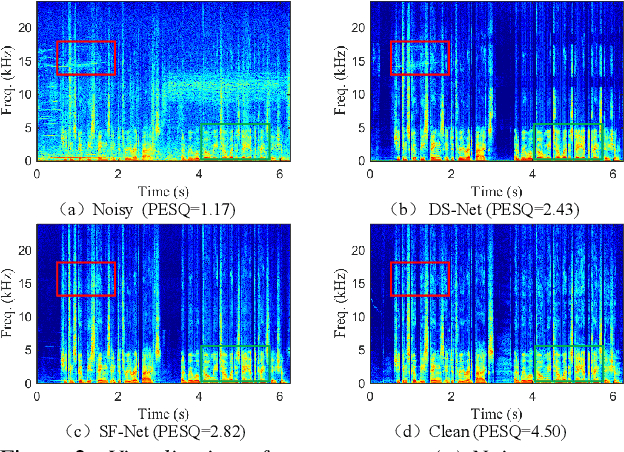
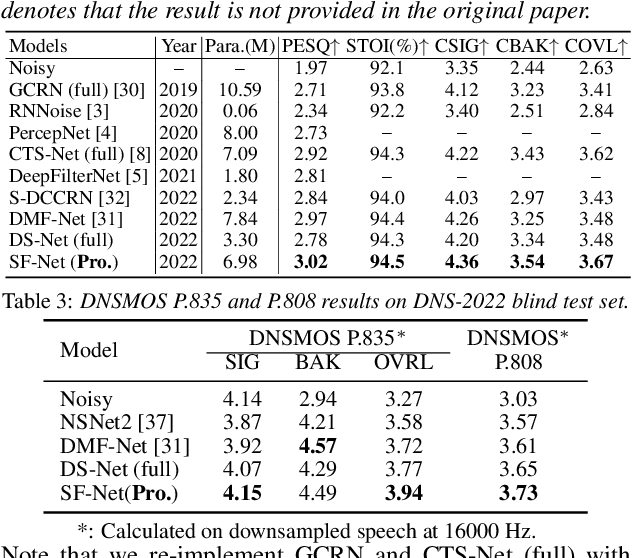
Due to the high computational complexity to model more frequency bands, it is still intractable to conduct real-time full-band speech enhancement based on deep neural networks. Recent studies typically utilize the compressed perceptually motivated features with relatively low frequency resolution to filter the full-band spectrum by one-stage networks, leading to limited speech quality improvements. In this paper, we propose a coordinated sub-band fusion network for full-band speech enhancement, which aims to recover the low- (0-8 kHz), middle- (8-16 kHz), and high-band (16-24 kHz) in a step-wise manner. Specifically, a dual-stream network is first pretrained to recover the low-band complex spectrum, and another two sub-networks are designed as the middle- and high-band noise suppressors in the magnitude-only domain. To fully capitalize on the information intercommunication, we employ a sub-band interaction module to provide external knowledge guidance across different frequency bands. Extensive experiments show that the proposed method yields consistent performance advantages over state-of-the-art full-band baselines.
Wide band sub-band speech coding using nonlinear prediction
Mar 24, 2022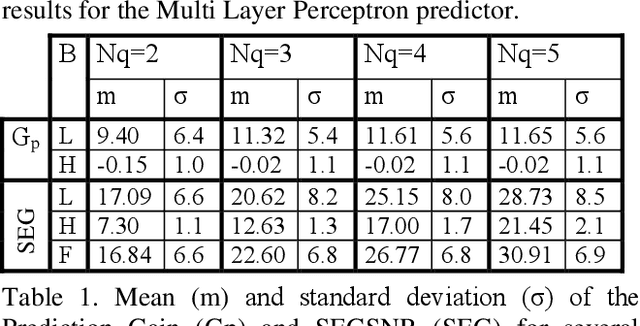
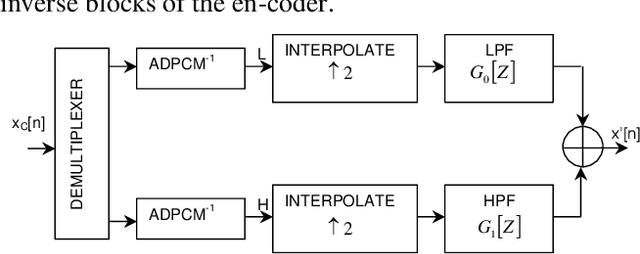
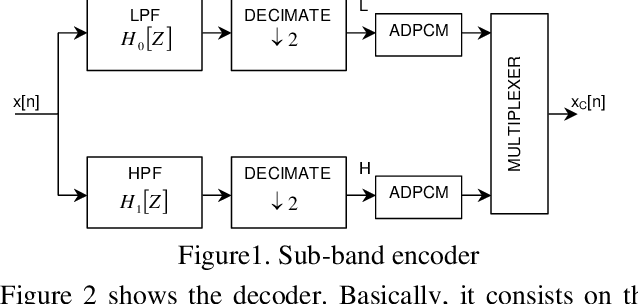
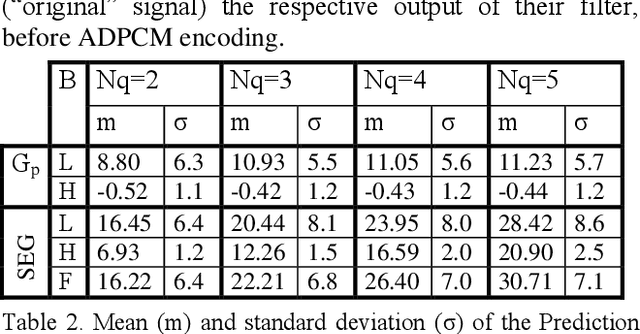
We compare a wide band sub-band speech coder using ADPCM schemes with linear prediction against the same scheme with nonlinear prediction based on multi-layer perceptrons. Exhaustive results are presented in each band, and the full signal. Our proposed scheme with non-linear neural net prediction outperforms the linear scheme up to 2 dB in SEGSNR. In addition, we propose a simple method based on a non-linearity in order to obtain a synthetic wide band signal from a narrow band signal.
* 4 pages, published in 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings. (ICASSP '03) Hong Kong, China
Phoneme Segmentation Using Self-Supervised Speech Models
Nov 02, 2022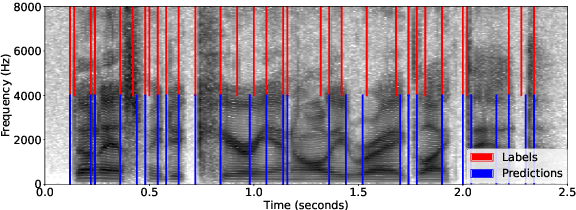
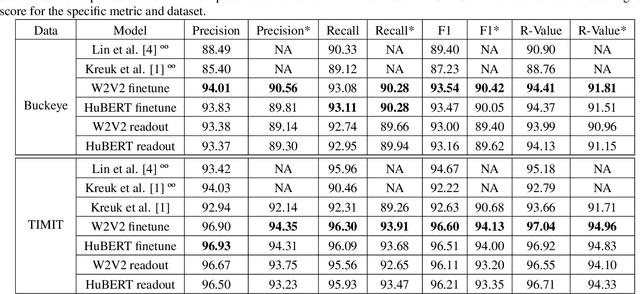
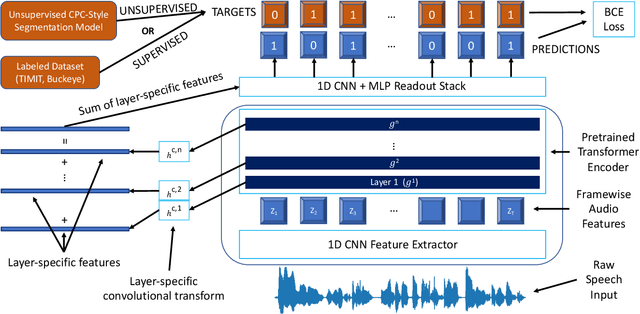
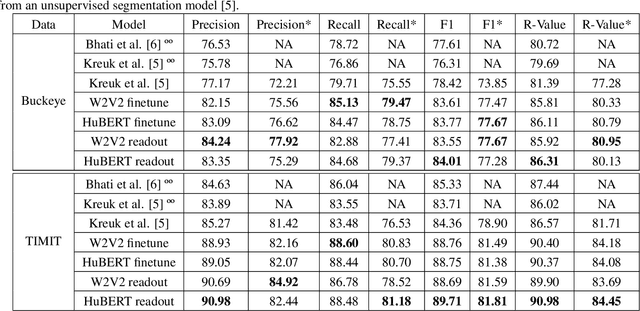
We apply transfer learning to the task of phoneme segmentation and demonstrate the utility of representations learned in self-supervised pre-training for the task. Our model extends transformer-style encoders with strategically placed convolutions that manipulate features learned in pre-training. Using the TIMIT and Buckeye corpora we train and test the model in the supervised and unsupervised settings. The latter case is accomplished by furnishing a noisy label-set with the predictions of a separate model, it having been trained in an unsupervised fashion. Results indicate our model eclipses previous state-of-the-art performance in both settings and on both datasets. Finally, following observations during published code review and attempts to reproduce past segmentation results, we find a need to disambiguate the definition and implementation of widely-used evaluation metrics. We resolve this ambiguity by delineating two distinct evaluation schemes and describing their nuances.
Handling Bias in Toxic Speech Detection: A Survey
Feb 02, 2022
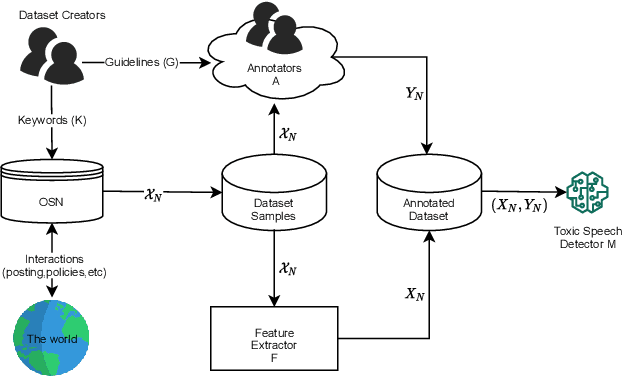
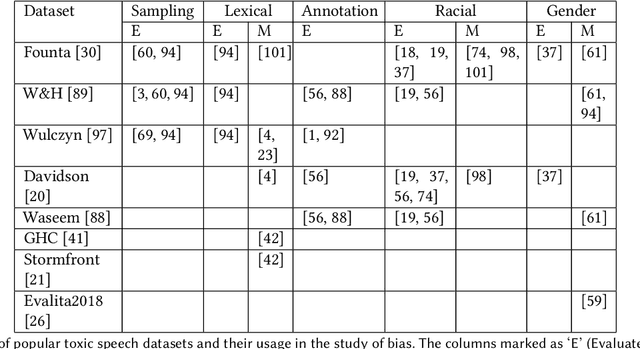
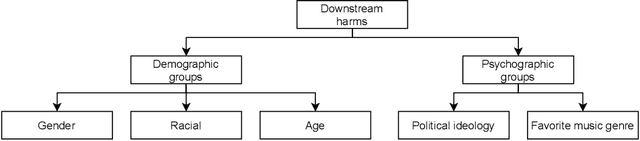
The massive growth of social media usage has witnessed a tsunami of online toxicity in teams of hate speech, abusive posts, cyberbullying, etc. Detecting online toxicity is challenging due to its inherent subjectivity. Factors such as the context of the speech, geography, socio-political climate, and background of the producers and consumers of the posts play a crucial role in determining if the content can be flagged as toxic. Adoption of automated toxicity detection models in production can lead to a sidelining of the various demographic and psychographic groups they aim to help in the first place. It has piqued researchers' interest in examining unintended biases and their mitigation. Due to the nascent and multi-faceted nature of the work, complete literature is chaotic in its terminologies, techniques, and findings. In this paper, we put together a systematic study to discuss the limitations and challenges of existing methods. We start by developing a taxonomy for categorising various unintended biases and a suite of evaluation metrics proposed to quantify such biases. We take a closer look at each proposed method for evaluating and mitigating bias in toxic speech detection. To examine the limitations of existing methods, we also conduct a case study to introduce the concept of bias shift due to knowledge-based bias mitigation methods. The survey concludes with an overview of the critical challenges, research gaps and future directions. While reducing toxicity on online platforms continues to be an active area of research, a systematic study of various biases and their mitigation strategies will help the research community produce robust and fair models.
TRScore: A Novel GPT-based Readability Scorer for ASR Segmentation and Punctuation model evaluation and selection
Oct 27, 2022
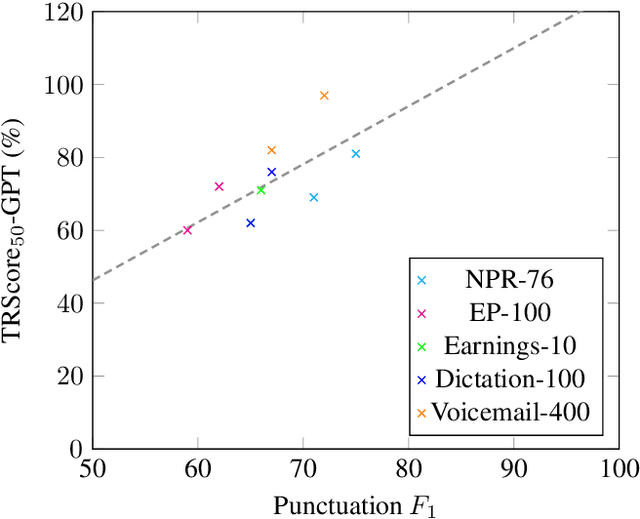
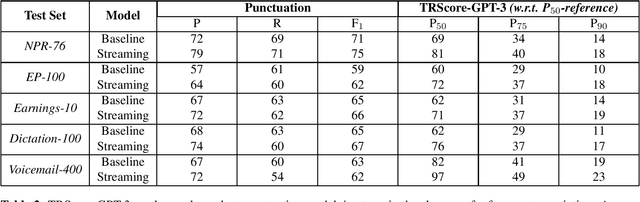
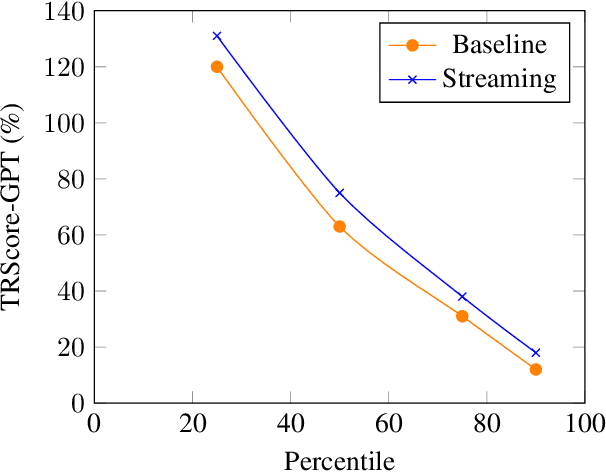
Punctuation and Segmentation are key to readability in Automatic Speech Recognition (ASR), often evaluated using F1 scores that require high-quality human transcripts and do not reflect readability well. Human evaluation is expensive, time-consuming, and suffers from large inter-observer variability, especially in conversational speech devoid of strict grammatical structures. Large pre-trained models capture a notion of grammatical structure. We present TRScore, a novel readability measure using the GPT model to evaluate different segmentation and punctuation systems. We validate our approach with human experts. Additionally, our approach enables quantitative assessment of text post-processing techniques such as capitalization, inverse text normalization (ITN), and disfluency on overall readability, which traditional word error rate (WER) and slot error rate (SER) metrics fail to capture. TRScore is strongly correlated to traditional F1 and human readability scores, with Pearson's correlation coefficients of 0.67 and 0.98, respectively. It also eliminates the need for human transcriptions for model selection.
SAN: a robust end-to-end ASR model architecture
Oct 27, 2022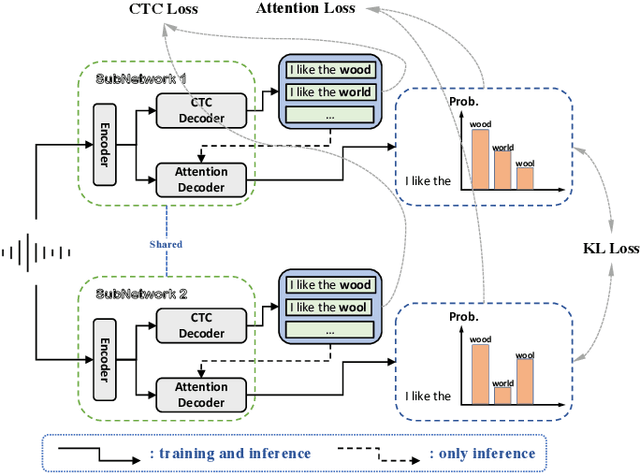
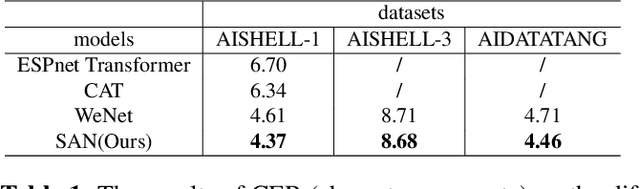


In this paper, we propose a novel Siamese Adversarial Network (SAN) architecture for automatic speech recognition, which aims at solving the difficulty of fuzzy audio recognition. Specifically, SAN constructs two sub-networks to differentiate the audio feature input and then introduces a loss to unify the output distribution of these sub-networks. Adversarial learning enables the network to capture more essential acoustic features and helps the models achieve better performance when encountering fuzzy audio input. We conduct numerical experiments with the SAN model on several datasets for the automatic speech recognition task. All experimental results show that the siamese adversarial nets significantly reduce the character error rate (CER). Specifically, we achieve a new state of art 4.37 CER without language model on the AISHELL-1 dataset, which leads to around 5% relative CER reduction. To reveal the generality of the siamese adversarial net, we also conduct experiments on the phoneme recognition task, which also shows the superiority of the siamese adversarial network.
Text Independent Speaker Identification System for Access Control
Sep 26, 2022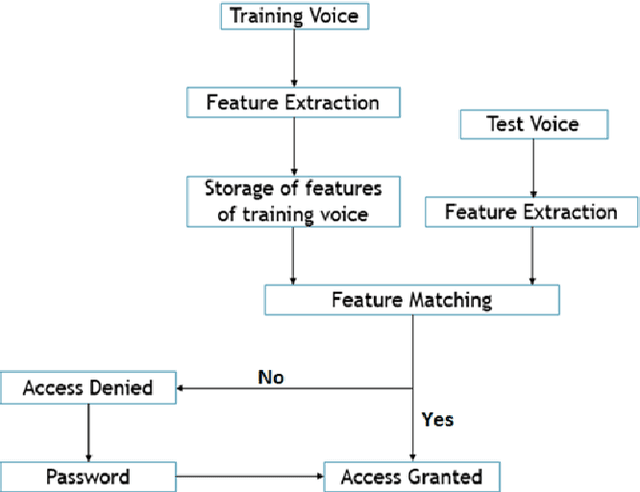
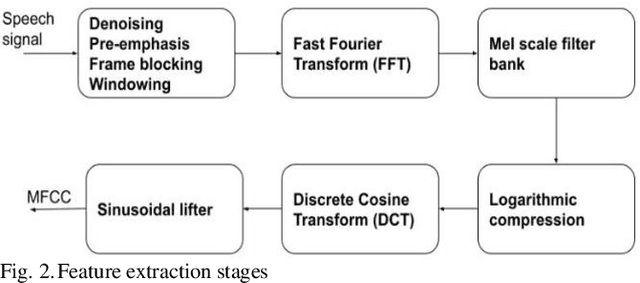
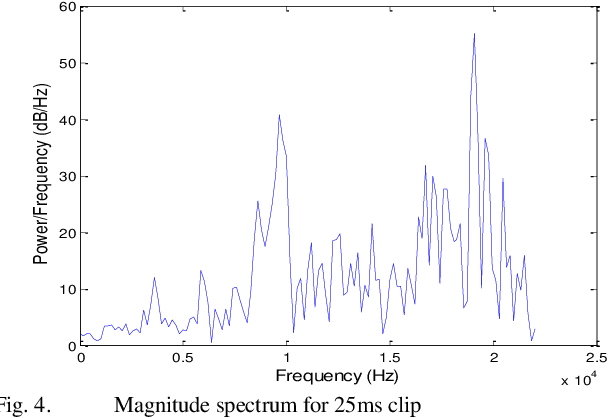
Even human intelligence system fails to offer 100% accuracy in identifying speeches from a specific individual. Machine intelligence is trying to mimic humans in speaker identification problems through various approaches to speech feature extraction and speech modeling techniques. This paper presents a text-independent speaker identification system that employs Mel Frequency Cepstral Coefficients (MFCC) for feature extraction and k-Nearest Neighbor (kNN) for classification. The maximum cross-validation accuracy obtained was 60%. This will be improved upon in subsequent research.
Disappeared Command: Spoofing Attack On Automatic Speech Recognition Systems with Sound Masking
Apr 19, 2022

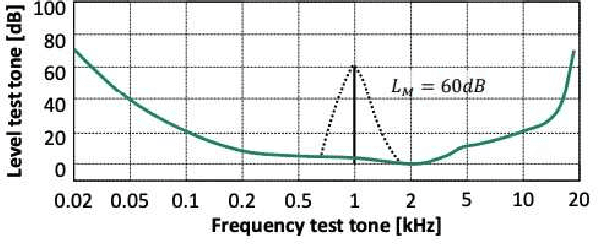
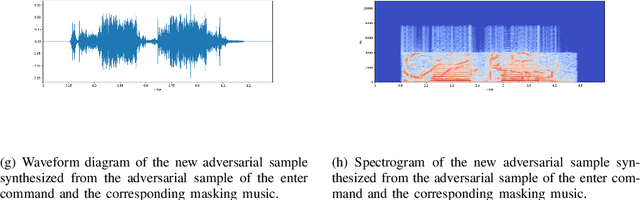
The development of deep learning technology has greatly promoted the performance improvement of automatic speech recognition (ASR) technology, which has demonstrated an ability comparable to human hearing in many tasks. Voice interfaces are becoming more and more widely used as input for many applications and smart devices. However, existing research has shown that DNN is easily disturbed by slight disturbances and makes false recognition, which is extremely dangerous for intelligent voice applications controlled by voice.