 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
GIST-AiTeR System for the Diarization Task of the 2022 VoxCeleb Speaker Recognition Challenge
Oct 06, 2022
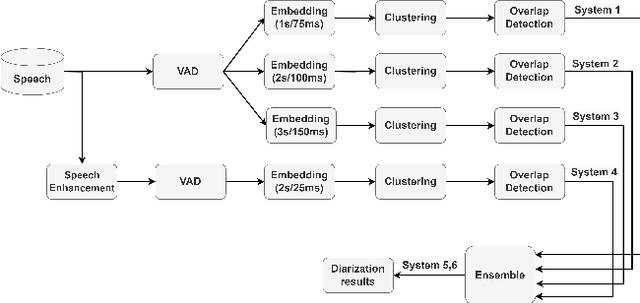
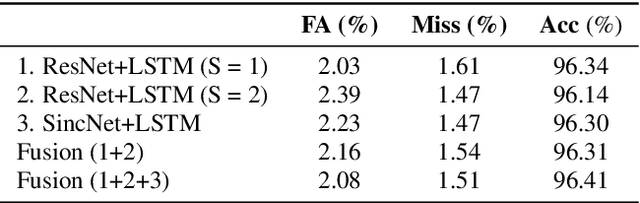
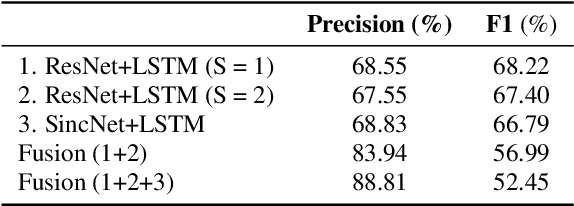
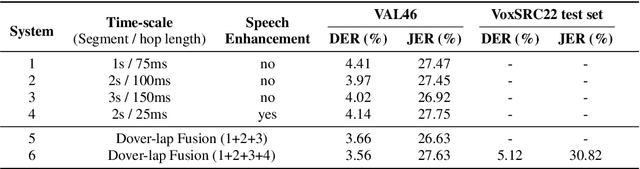
This report describes the submission system of the GIST-AiTeR team at the 2022 VoxCeleb Speaker Recognition Challenge (VoxSRC) Track 4. Our system mainly includes speech enhancement, voice activity detection , multi-scaled speaker embedding, probabilistic linear discriminant analysis-based speaker clustering, and overlapped speech detection models. We first construct four different diarization systems according to different model combinations with the best experimental efforts. Our final submission is an ensemble system of all the four systems and achieves a diarization error rate of 5.12% on the challenge evaluation set, ranked third at the diarization track of the challenge.
SpeechEQ: Speech Emotion Recognition based on Multi-scale Unified Datasets and Multitask Learning
Jun 27, 2022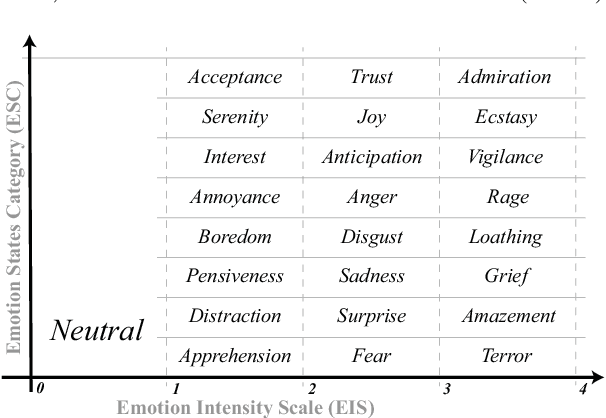

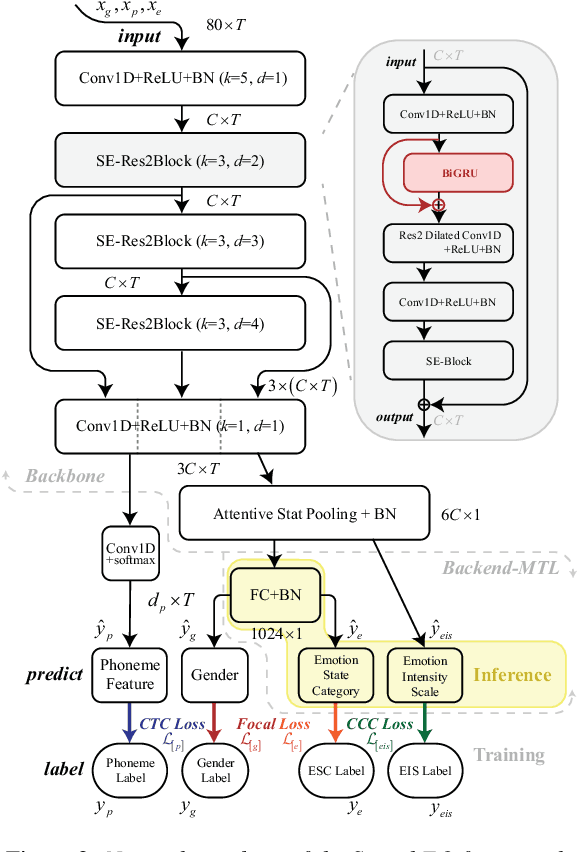
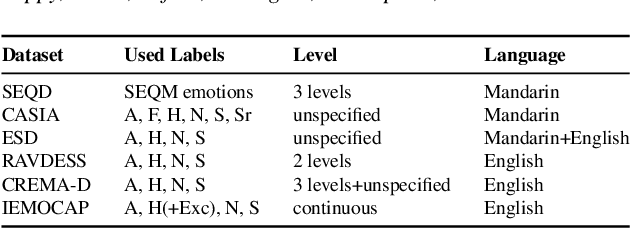
Speech emotion recognition (SER) has many challenges, but one of the main challenges is that each framework does not have a unified standard. In this paper, we propose SpeechEQ, a framework for unifying SER tasks based on a multi-scale unified metric. This metric can be trained by Multitask Learning (MTL), which includes two emotion recognition tasks of Emotion States Category (EIS) and Emotion Intensity Scale (EIS), and two auxiliary tasks of phoneme recognition and gender recognition. For this framework, we build a Mandarin SER dataset - SpeechEQ Dataset (SEQD). We conducted experiments on the public CASIA and ESD datasets in Mandarin, which exhibit that our method outperforms baseline methods by a relatively large margin, yielding 8.0\% and 6.5\% improvement in accuracy respectively. Additional experiments on IEMOCAP with four emotion categories (i.e., angry, happy, sad, and neutral) also show the proposed method achieves a state-of-the-art of both weighted accuracy (WA) of 78.16% and unweighted accuracy (UA) of 77.47%.
Hybrid Handcrafted and Learnable Audio Representation for Analysis of Speech Under Cognitive and Physical Load
Mar 30, 2022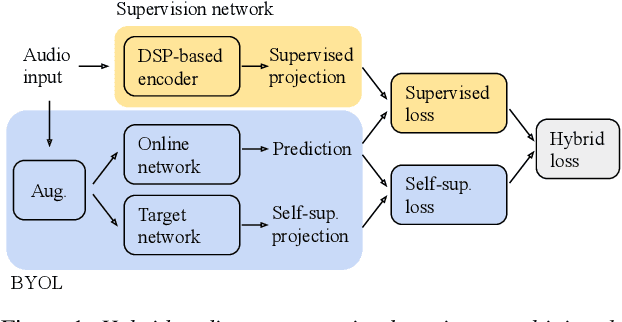

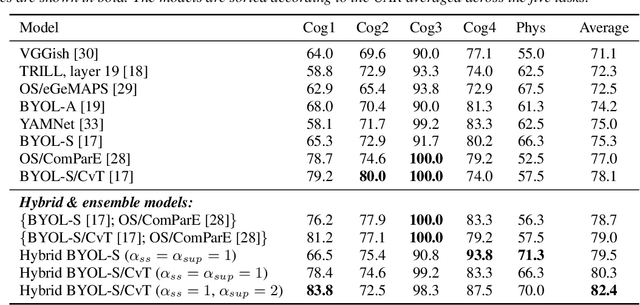
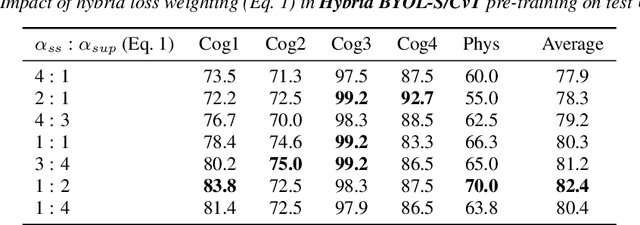
As a neurophysiological response to threat or adverse conditions, stress can affect cognition, emotion and behaviour with potentially detrimental effects on health in the case of sustained exposure. Since the affective content of speech is inherently modulated by an individual's physical and mental state, a substantial body of research has been devoted to the study of paralinguistic correlates of stress-inducing task load. Historically, voice stress analysis (VSA) has been conducted using conventional digital signal processing (DSP) techniques. Despite the development of modern methods based on deep neural networks (DNNs), accurately detecting stress in speech remains difficult due to the wide variety of stressors and considerable variability in the individual stress perception. To that end, we introduce a set of five datasets for task load detection in speech. The voice recordings were collected as either cognitive or physical stress was induced in the cohort of volunteers, with a cumulative number of more than a hundred speakers. We used the datasets to design and evaluate a novel self-supervised audio representation that leverages the effectiveness of handcrafted features (DSP-based) and the complexity of data-driven DNN representations. Notably, the proposed approach outperformed both extensive handcrafted feature sets and novel DNN-based audio representation learning approaches.
High-resolution embedding extractor for speaker diarisation
Nov 08, 2022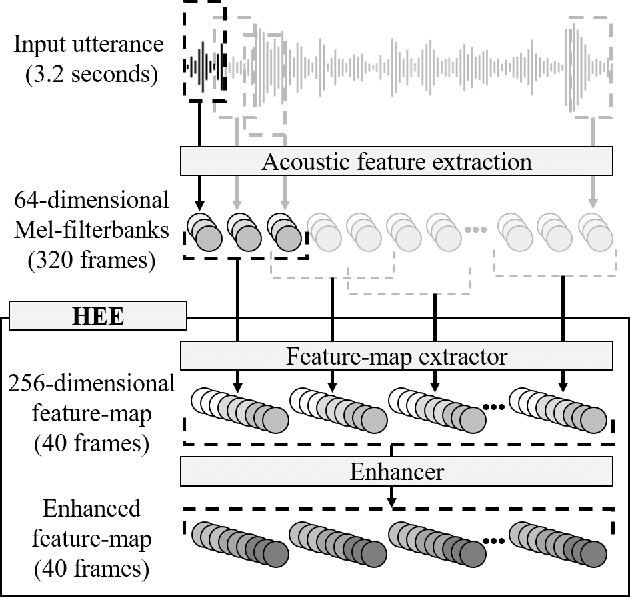
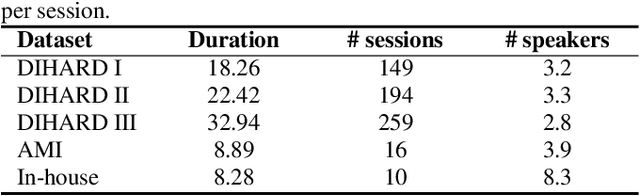
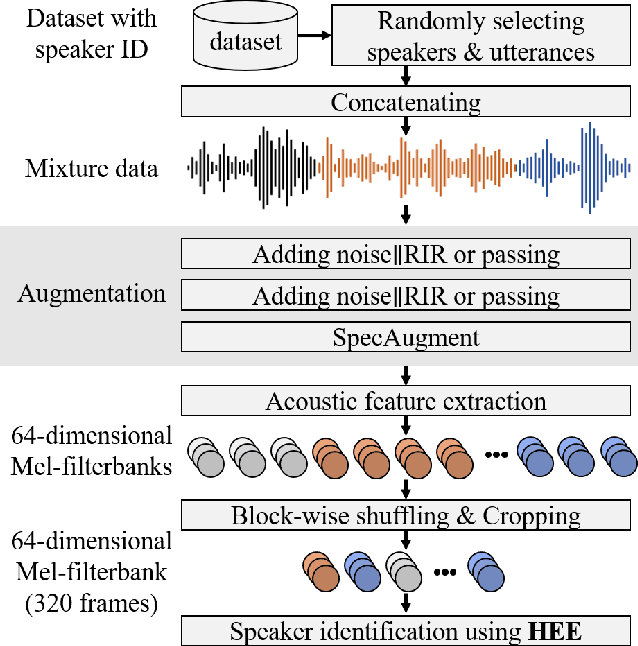
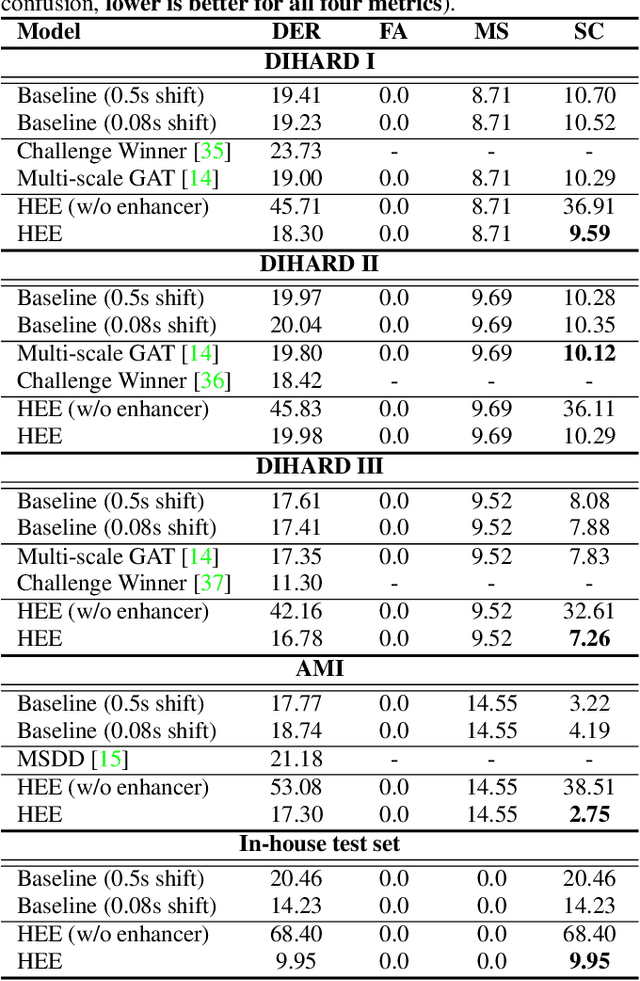
Speaker embedding extractors significantly influence the performance of clustering-based speaker diarisation systems. Conventionally, only one embedding is extracted from each speech segment. However, because of the sliding window approach, a segment easily includes two or more speakers owing to speaker change points. This study proposes a novel embedding extractor architecture, referred to as a high-resolution embedding extractor (HEE), which extracts multiple high-resolution embeddings from each speech segment. Hee consists of a feature-map extractor and an enhancer, where the enhancer with the self-attention mechanism is the key to success. The enhancer of HEE replaces the aggregation process; instead of a global pooling layer, the enhancer combines relative information to each frame via attention leveraging the global context. Extracted dense frame-level embeddings can each represent a speaker. Thus, multiple speakers can be represented by different frame-level features in each segment. We also propose an artificially generating mixture data training framework to train the proposed HEE. Through experiments on five evaluation sets, including four public datasets, the proposed HEE demonstrates at least 10% improvement on each evaluation set, except for one dataset, which we analyse that rapid speaker changes less exist.
Extracting linguistic speech patterns of Japanese fictional characters using subword units
Mar 05, 2022
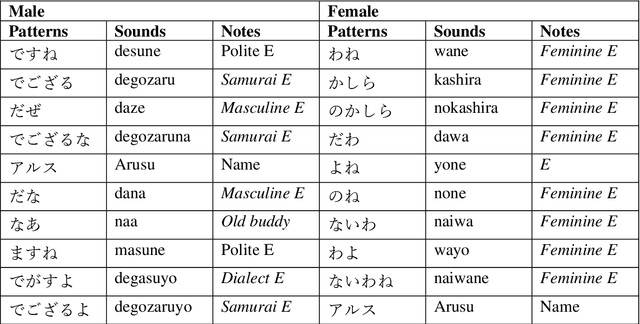
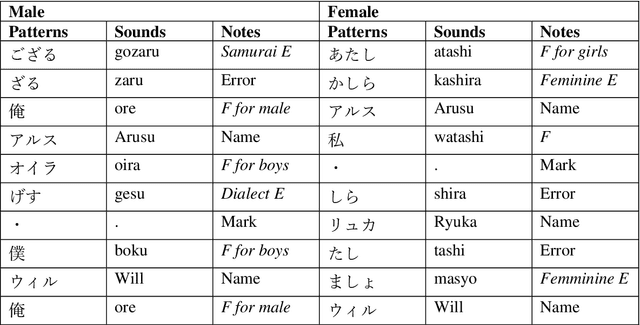
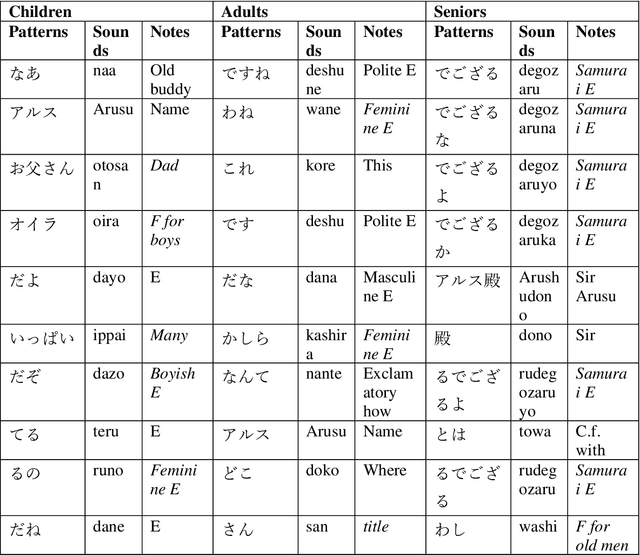
This study extracted and analyzed the linguistic speech patterns that characterize Japanese anime or game characters. Conventional morphological analyzers, such as MeCab, segment words with high performance, but they are unable to segment broken expressions or utterance endings that are not listed in the dictionary, which often appears in lines of anime or game characters. To overcome this challenge, we propose segmenting lines of Japanese anime or game characters using subword units that were proposed mainly for deep learning, and extracting frequently occurring strings to obtain expressions that characterize their utterances. We analyzed the subword units weighted by TF/IDF according to gender, age, and each anime character and show that they are linguistic speech patterns that are specific for each feature. Additionally, a classification experiment shows that the model with subword units outperformed that with the conventional method.
USC: An Open-Source Uzbek Speech Corpus and Initial Speech Recognition Experiments
Jul 30, 2021
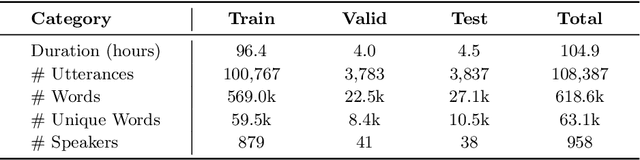
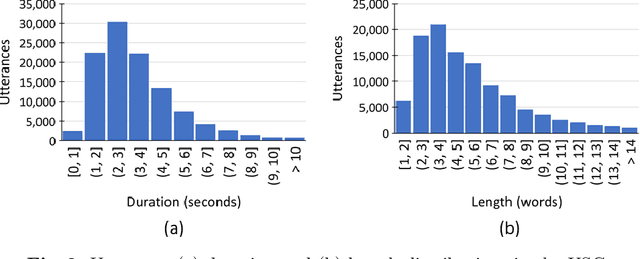
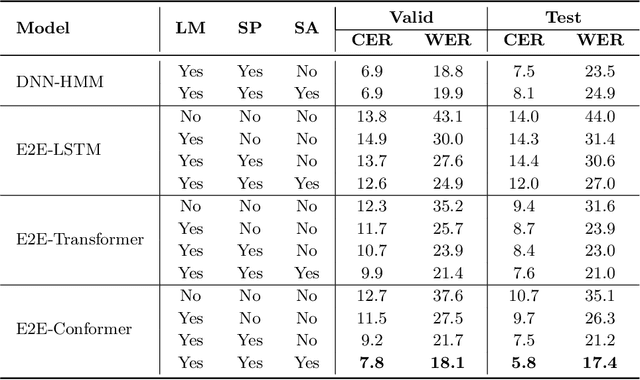
We present a freely available speech corpus for the Uzbek language and report preliminary automatic speech recognition (ASR) results using both the deep neural network hidden Markov model (DNN-HMM) and end-to-end (E2E) architectures. The Uzbek speech corpus (USC) comprises 958 different speakers with a total of 105 hours of transcribed audio recordings. To the best of our knowledge, this is the first open-source Uzbek speech corpus dedicated to the ASR task. To ensure high quality, the USC has been manually checked by native speakers. We first describe the design and development procedures of the USC, and then explain the conducted ASR experiments in detail. The experimental results demonstrate promising results for the applicability of the USC for ASR. Specifically, 18.1% and 17.4% word error rates were achieved on the validation and test sets, respectively. To enable experiment reproducibility, we share the USC dataset, pre-trained models, and training recipes in our GitHub repository.
Unify and Conquer: How Phonetic Feature Representation Affects Polyglot Text-To-Speech (TTS)
Jul 04, 2022
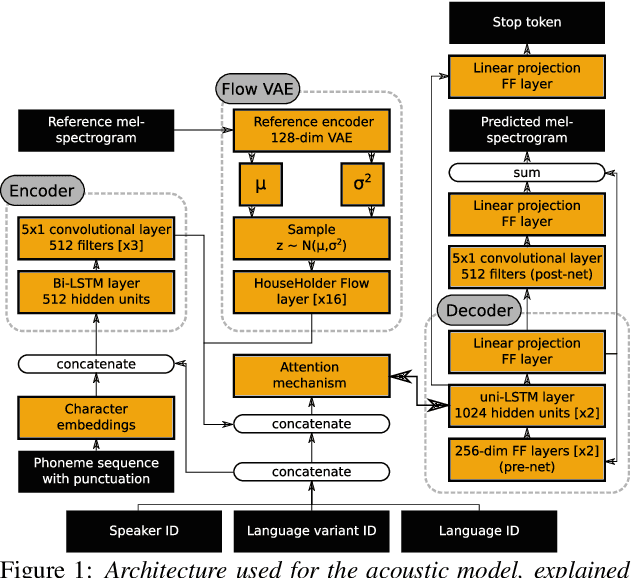
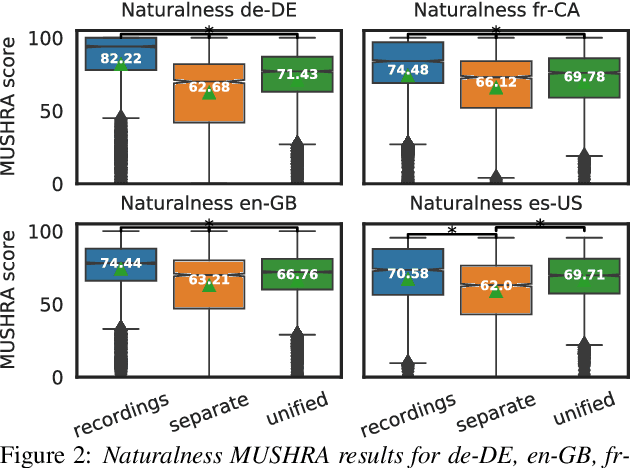
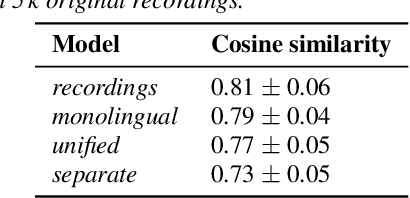
An essential design decision for multilingual Neural Text-To-Speech (NTTS) systems is how to represent input linguistic features within the model. Looking at the wide variety of approaches in the literature, two main paradigms emerge, unified and separate representations. The former uses a shared set of phonetic tokens across languages, whereas the latter uses unique phonetic tokens for each language. In this paper, we conduct a comprehensive study comparing multilingual NTTS systems models trained with both representations. Our results reveal that the unified approach consistently achieves better cross-lingual synthesis with respect to both naturalness and accent. Separate representations tend to have an order of magnitude more tokens than unified ones, which may affect model capacity. For this reason, we carry out an ablation study to understand the interaction of the representation type with the size of the token embedding. We find that the difference between the two paradigms only emerges above a certain threshold embedding size. This study provides strong evidence that unified representations should be the preferred paradigm when building multilingual NTTS systems.
A Novel Exploitative and Explorative GWO-SVM Algorithm for Smart Emotion Recognition
Jan 05, 2023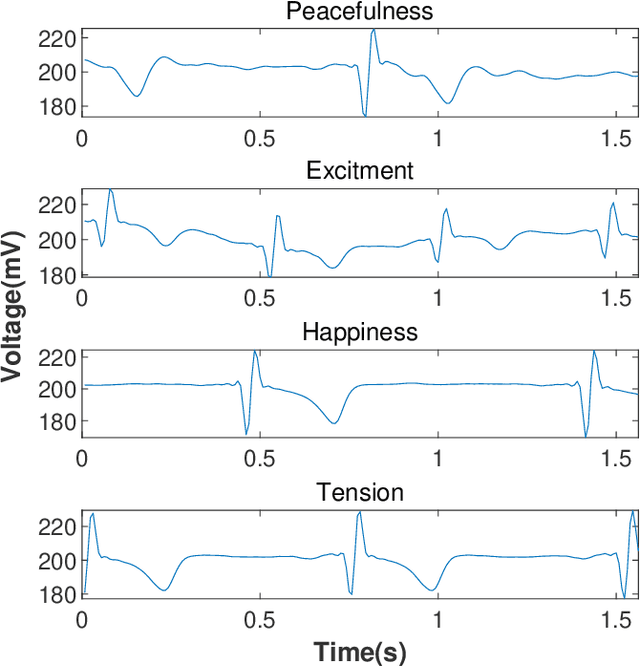
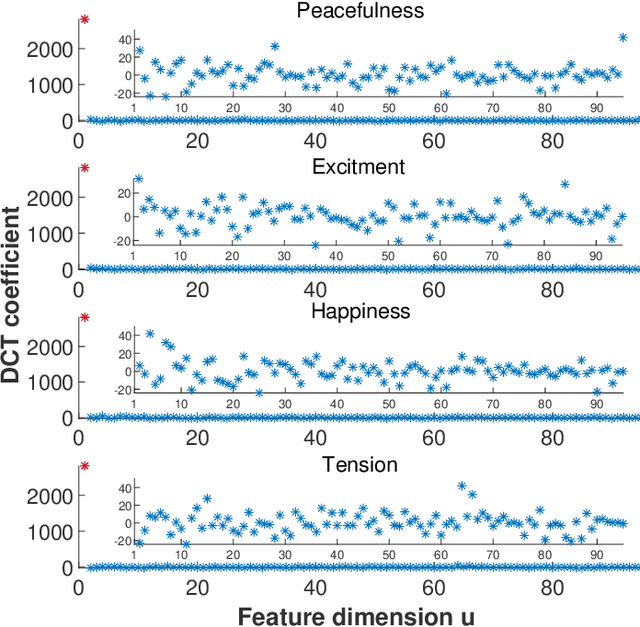
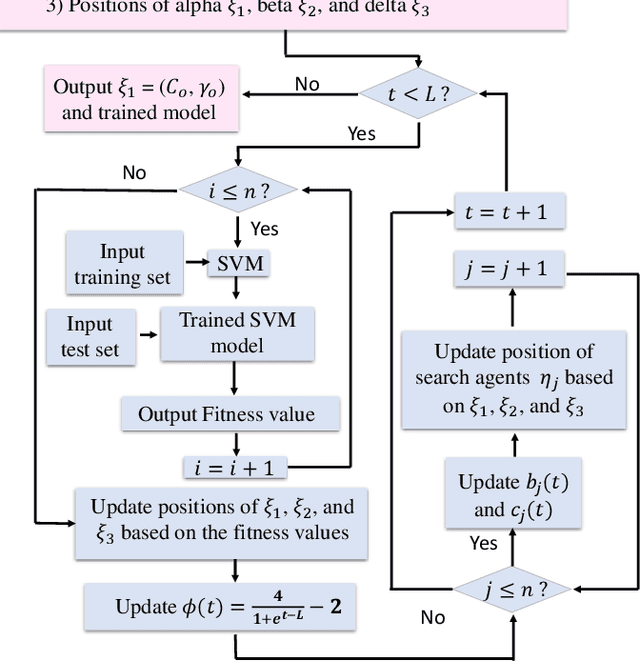
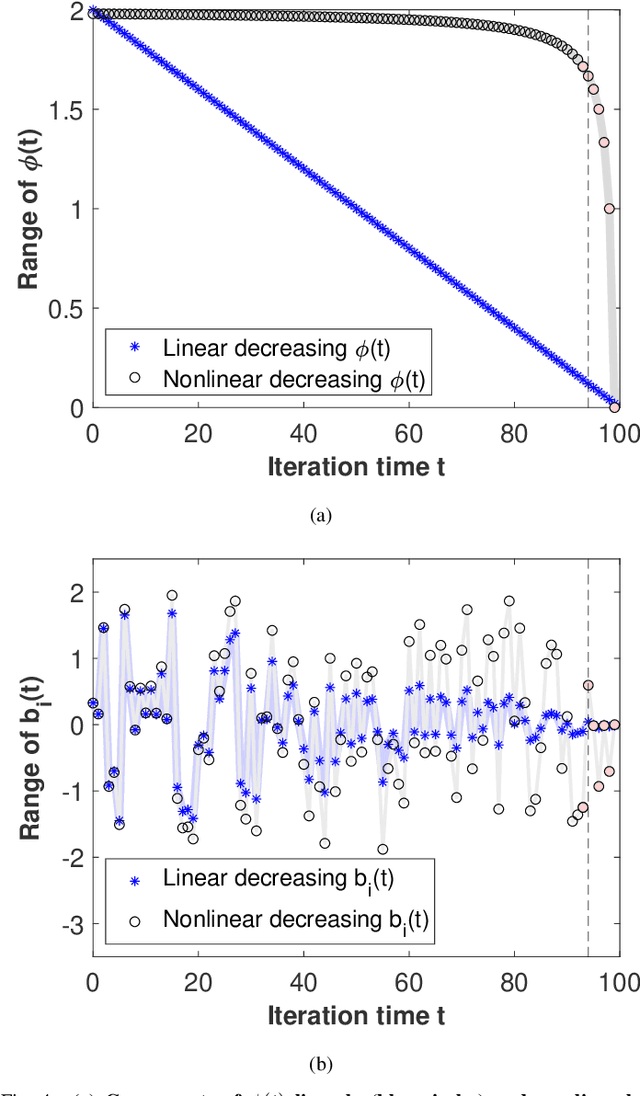
Emotion recognition or detection is broadly utilized in patient-doctor interactions for diseases such as schizophrenia and autism and the most typical techniques are speech detection and facial recognition. However, features extracted from these behavior-based emotion recognitions are not reliable since humans can disguise their emotions. Recording voices or tracking facial expressions for a long term is also not efficient. Therefore, our aim is to find a reliable and efficient emotion recognition scheme, which can be used for non-behavior-based emotion recognition in real-time. This can be solved by implementing a single-channel electrocardiogram (ECG) based emotion recognition scheme in a lightweight embedded system. However, existing schemes have relatively low accuracy. Therefore, we propose a reliable and efficient emotion recognition scheme - exploitative and explorative grey wolf optimizer based SVM (X - GWO - SVM) for ECG-based emotion recognition. Two datasets, one raw self-collected iRealcare dataset, and the widely-used benchmark WESAD dataset are used in the X - GWO - SVM algorithm for emotion recognition. This work demonstrates that the X - GWO - SVM algorithm can be used for emotion recognition and the algorithm exhibits superior performance in reliability compared to the use of other supervised machine learning methods in earlier works. It can be implemented in a lightweight embedded system, which is much more efficient than existing solutions based on deep neural networks.
Cross-Lingual Text-to-Speech Using Multi-Task Learning and Speaker Classifier Joint Training
Jan 20, 2022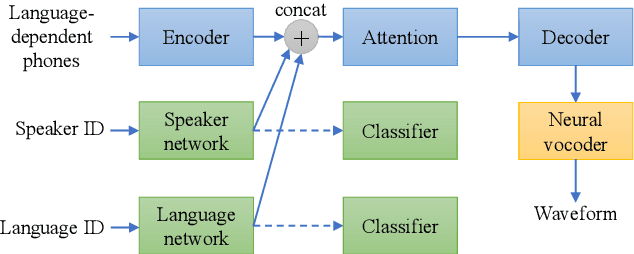
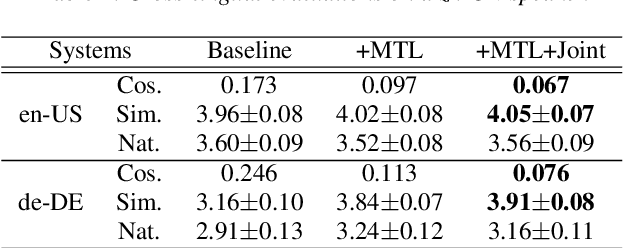
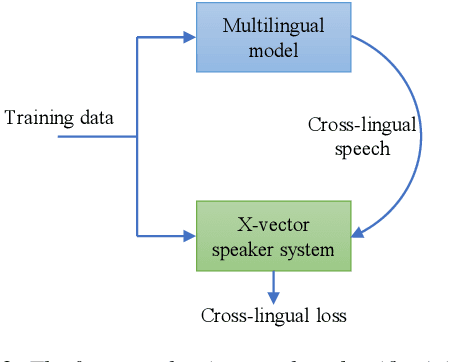
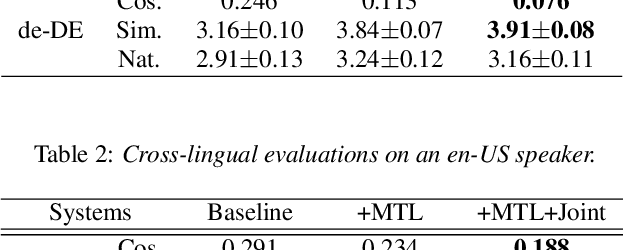
In cross-lingual speech synthesis, the speech in various languages can be synthesized for a monoglot speaker. Normally, only the data of monoglot speakers are available for model training, thus the speaker similarity is relatively low between the synthesized cross-lingual speech and the native language recordings. Based on the multilingual transformer text-to-speech model, this paper studies a multi-task learning framework to improve the cross-lingual speaker similarity. To further improve the speaker similarity, joint training with a speaker classifier is proposed. Here, a scheme similar to parallel scheduled sampling is proposed to train the transformer model efficiently to avoid breaking the parallel training mechanism when introducing joint training. By using multi-task learning and speaker classifier joint training, in subjective and objective evaluations, the cross-lingual speaker similarity can be consistently improved for both the seen and unseen speakers in the training set.
Visual Speech Recognition for Multiple Languages in the Wild
Feb 26, 2022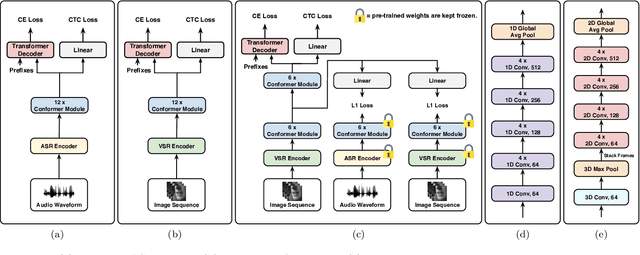
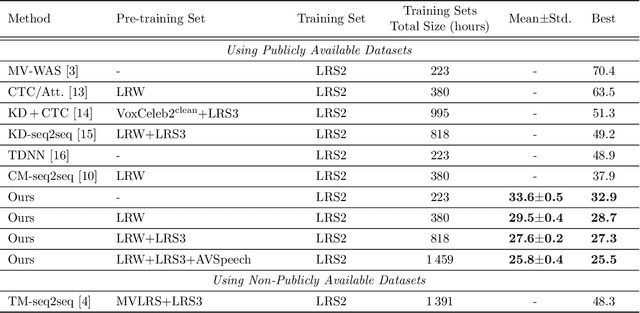
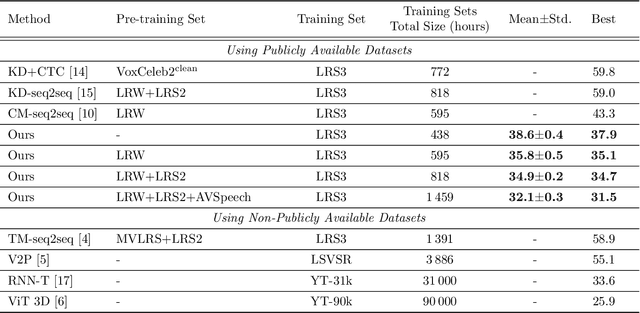
Visual speech recognition (VSR) aims to recognise the content of speech based on the lip movements without relying on the audio stream. Advances in deep learning and the availability of large audio-visual datasets have led to the development of much more accurate and robust VSR models than ever before. However, these advances are usually due to larger training sets rather than the model design. In this work, we demonstrate that designing better models is equally important to using larger training sets. We propose the addition of prediction-based auxiliary tasks to a VSR model and highlight the importance of hyper-parameter optimisation and appropriate data augmentations. We show that such model works for different languages and outperforms all previous methods trained on publicly available datasets by a large margin. It even outperforms models that were trained on non-publicly available datasets containing up to to 21 times more data. We show furthermore that using additional training data, even in other languages or with automatically generated transcriptions, results in further improvement.