 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SceneFake: An Initial Dataset and Benchmarks for Scene Fake Audio Detection
Nov 11, 2022
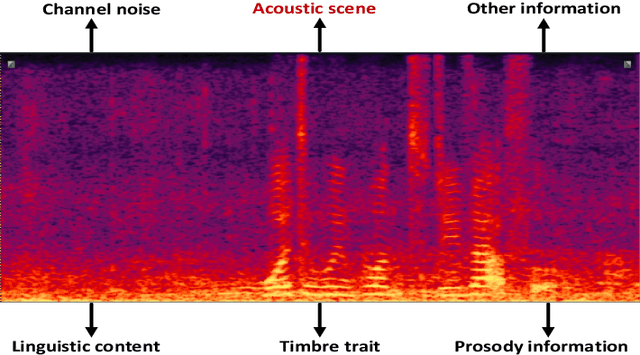
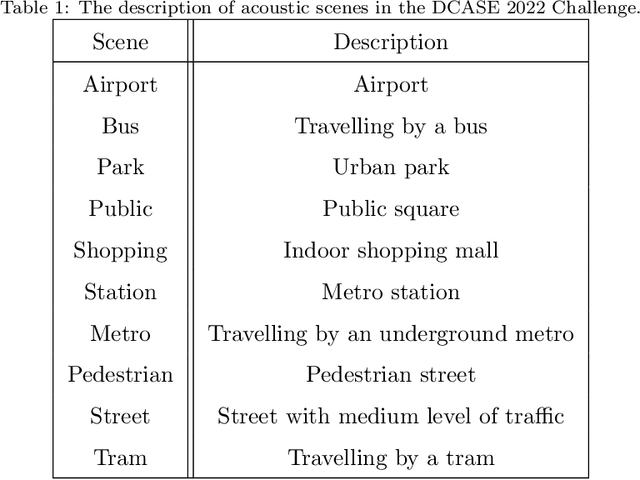
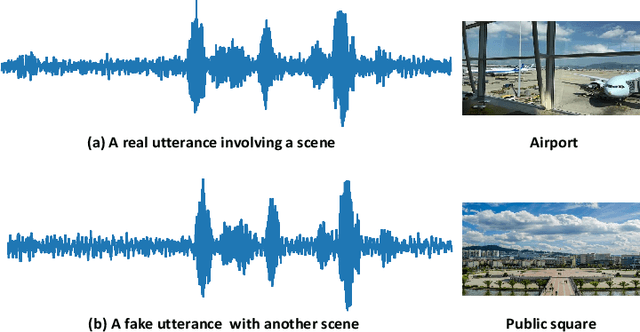
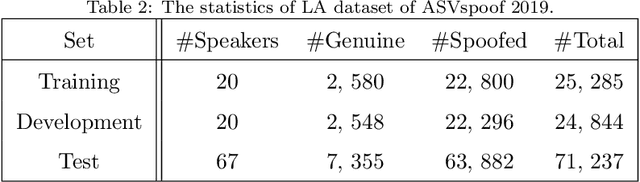
Previous databases have been designed to further the development of fake audio detection. However, fake utterances are mostly generated by altering timbre, prosody, linguistic content or channel noise of original audios. They ignore a fake situation, in which the attacker manipulates an acoustic scene of the original audio with another forgery one. It will pose a major threat to our society if some people misuse the manipulated audio with malicious purpose. Therefore, this motivates us to fill in the gap. This paper designs such a dataset for scene fake audio detection (SceneFake). A manipulated audio in the SceneFake dataset involves only tampering the acoustic scene of an utterance by using speech enhancement technologies. We can not only detect fake utterances on a seen test set but also evaluate the generalization of fake detection models to unseen manipulation attacks. Some benchmark results are described on the SceneFake dataset. Besides, an analysis of fake attacks with different speech enhancement technologies and signal-to-noise ratios are presented on the dataset. The results show that scene manipulated utterances can not be detected reliably by the existing baseline models of ASVspoof 2019. Furthermore, the detection of unseen scene manipulation audio is still challenging.
Automated Sex Classification of Children's Voices and Changes in Differentiating Factors with Age
Sep 27, 2022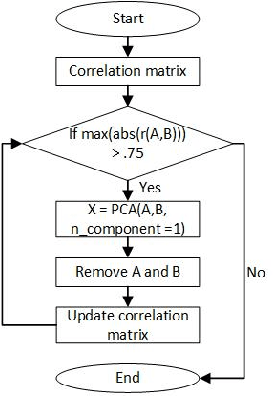
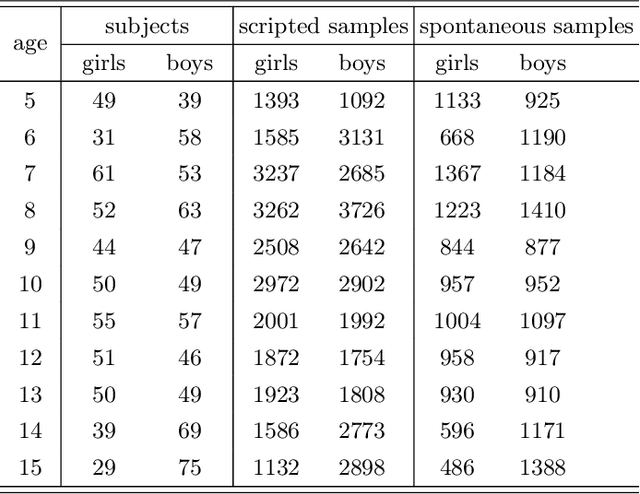
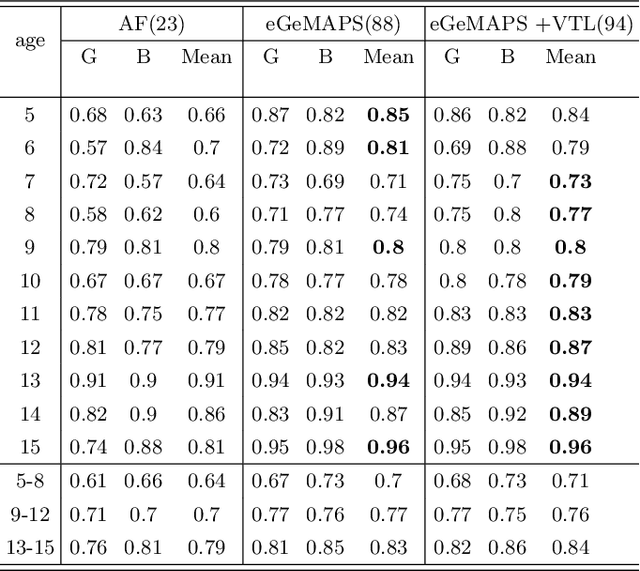
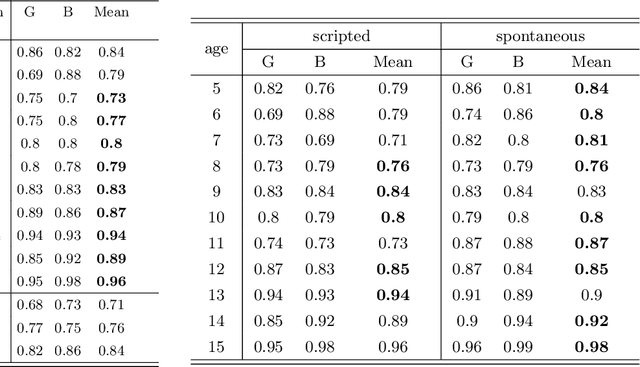
Sex classification of children's voices allows for an investigation of the development of secondary sex characteristics which has been a key interest in the field of speech analysis. This research investigated a broad range of acoustic features from scripted and spontaneous speech and applied a hierarchical clustering-based machine learning model to distinguish the sex of children aged between 5 and 15 years. We proposed an optimal feature set and our modelling achieved an average F1 score (the harmonic mean of the precision and recall) of 0.84 across all ages. Our results suggest that the sex classification is generally more accurate when a model is developed for each year group rather than for children in 4-year age bands, with classification accuracy being better for older age groups. We found that spontaneous speech could provide more helpful cues in sex classification than scripted speech, especially for children younger than 7 years. For younger age groups, a broad range of acoustic factors contributed evenly to sex classification, while for older age groups, F0-related acoustic factors were found to be the most critical predictors generally. Other important acoustic factors for older age groups include vocal tract length estimators, spectral flux, loudness and unvoiced features.
Cross-lingual Transfer for Speech Processing using Acoustic Language Similarity
Nov 02, 2021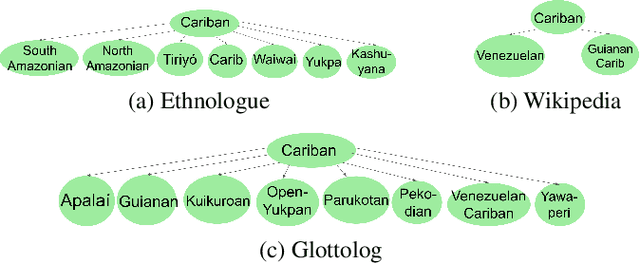
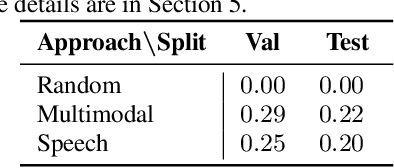
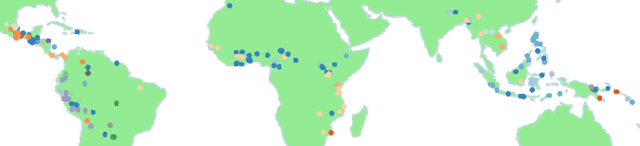
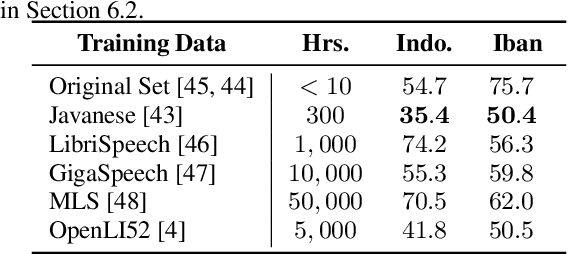
Speech processing systems currently do not support the vast majority of languages, in part due to the lack of data in low-resource languages. Cross-lingual transfer offers a compelling way to help bridge this digital divide by incorporating high-resource data into low-resource systems. Current cross-lingual algorithms have shown success in text-based tasks and speech-related tasks over some low-resource languages. However, scaling up speech systems to support hundreds of low-resource languages remains unsolved. To help bridge this gap, we propose a language similarity approach that can efficiently identify acoustic cross-lingual transfer pairs across hundreds of languages. We demonstrate the effectiveness of our approach in language family classification, speech recognition, and speech synthesis tasks.
DAL: Feature Learning from Overt Speech to Decode Imagined Speech-based EEG Signals with Convolutional Autoencoder
Jul 15, 2021
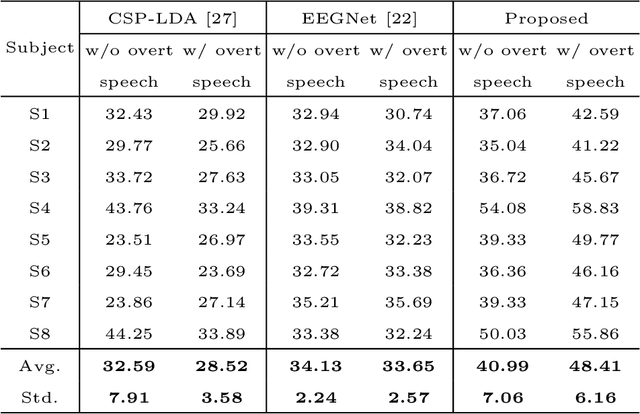
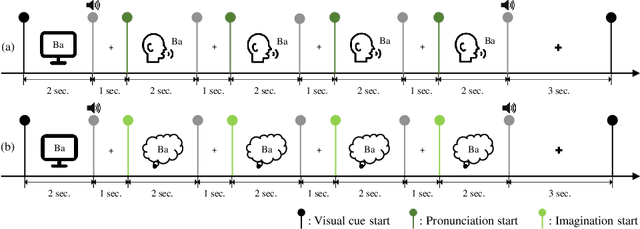
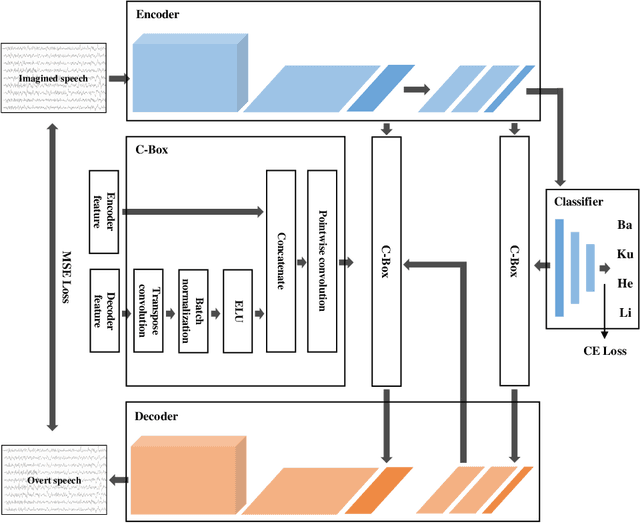
Brain-computer interface (BCI) is one of the tools which enables the communication between humans and devices by reflecting intention and status of humans. With the development of artificial intelligence, the interest in communication between humans and drones using electroencephalogram (EEG) is increased. Especially, in the case of controlling drone swarms such as direction or formation, there are many advantages compared with controlling a drone unit. Imagined speech is one of the endogenous BCI paradigms, which can identify intentions of users. When conducting imagined speech, the users imagine the pronunciation as if actually speaking. In contrast, overt speech is a task in which the users directly pronounce the words. When controlling drone swarms using imagined speech, complex commands can be delivered more intuitively, but decoding performance is lower than that of other endogenous BCI paradigms. We proposed the Deep-autoleaner (DAL) to learn EEG features of overt speech for imagined speech-based EEG signals classification. To the best of our knowledge, this study is the first attempt to use EEG features of overt speech to decode imagined speech-based EEG signals with an autoencoder. A total of eight subjects participated in the experiment. When classifying four words, the average accuracy of the DAL was 48.41%. In addition, when comparing the performance between w/o and w/ EEG features of overt speech, there was a performance improvement of 7.42% when including EEG features of overt speech. Hence, we demonstrated that EEG features of overt speech could improve the decoding performance of imagined speech.
Unsupervised Instance Discriminative Learning for Depression Detection from Speech Signals
Jun 27, 2022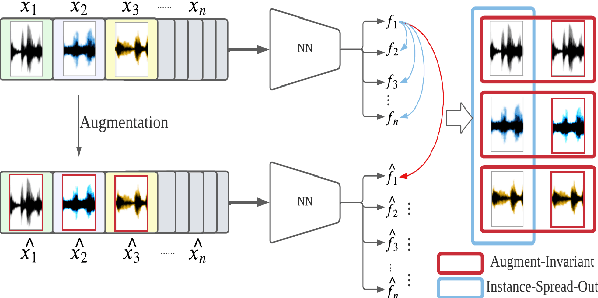
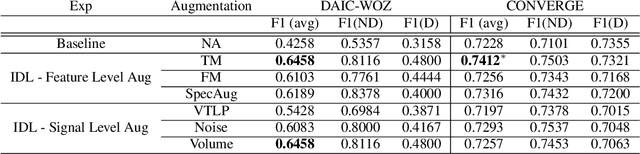
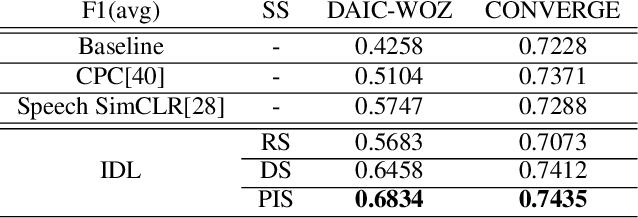
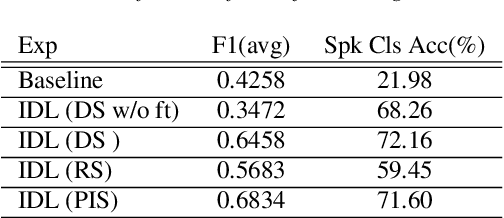
Major Depressive Disorder (MDD) is a severe illness that affects millions of people, and it is critical to diagnose this disorder as early as possible. Detecting depression from voice signals can be of great help to physicians and can be done without any invasive procedure. Since relevant labelled data are scarce, we propose a modified Instance Discriminative Learning (IDL) method, an unsupervised pre-training technique, to extract augment-invariant and instance-spread-out embeddings. In terms of learning augment-invariant embeddings, various data augmentation methods for speech are investigated, and time-masking yields the best performance. To learn instance-spread-out embeddings, we explore methods for sampling instances for a training batch (distinct speaker-based and random sampling). It is found that the distinct speaker-based sampling provides better performance than the random one, and we hypothesize that this result is because relevant speaker information is preserved in the embedding. Additionally, we propose a novel sampling strategy, Pseudo Instance-based Sampling (PIS), based on clustering algorithms, to enhance spread-out characteristics of the embeddings. Experiments are conducted with DepAudioNet on DAIC-WOZ (English) and CONVERGE (Mandarin) datasets, and statistically significant improvements, with p-value 0.0015 and 0.05, respectively, are observed using PIS in the detection of MDD relative to the baseline without pre-training.
QASR: QCRI Aljazeera Speech Resource -- A Large Scale Annotated Arabic Speech Corpus
Jun 24, 2021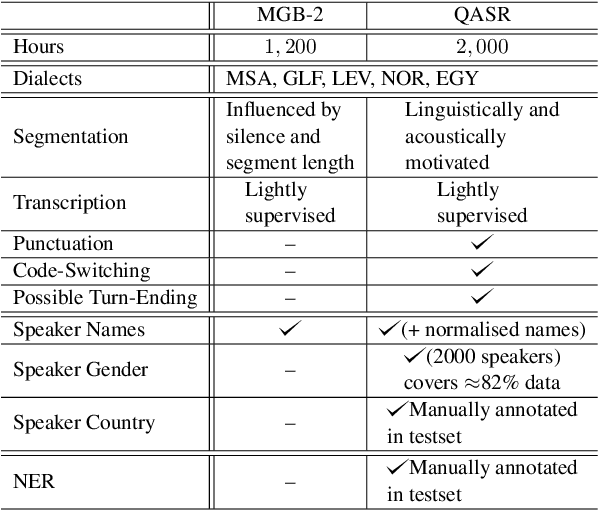

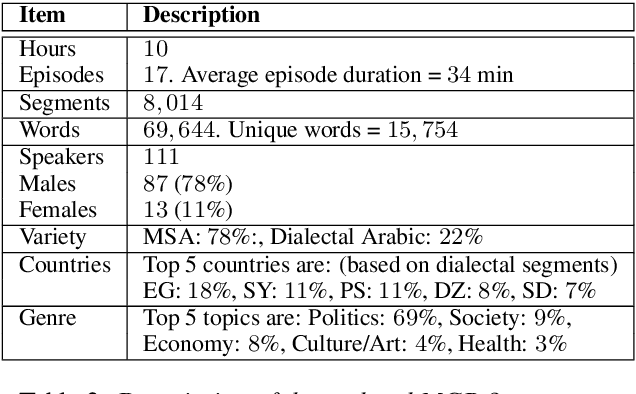
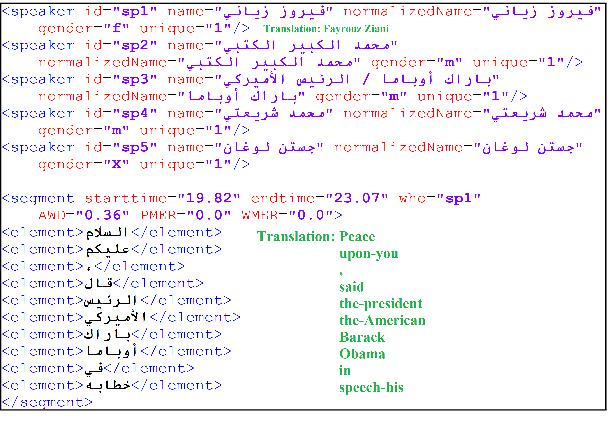
We introduce the largest transcribed Arabic speech corpus, QASR, collected from the broadcast domain. This multi-dialect speech dataset contains 2,000 hours of speech sampled at 16kHz crawled from Aljazeera news channel. The dataset is released with lightly supervised transcriptions, aligned with the audio segments. Unlike previous datasets, QASR contains linguistically motivated segmentation, punctuation, speaker information among others. QASR is suitable for training and evaluating speech recognition systems, acoustics- and/or linguistics- based Arabic dialect identification, punctuation restoration, speaker identification, speaker linking, and potentially other NLP modules for spoken data. In addition to QASR transcription, we release a dataset of 130M words to aid in designing and training a better language model. We show that end-to-end automatic speech recognition trained on QASR reports a competitive word error rate compared to the previous MGB-2 corpus. We report baseline results for downstream natural language processing tasks such as named entity recognition using speech transcript. We also report the first baseline for Arabic punctuation restoration. We make the corpus available for the research community.
Efficient yet Competitive Speech Translation: FBK@IWSLT2022
May 05, 2022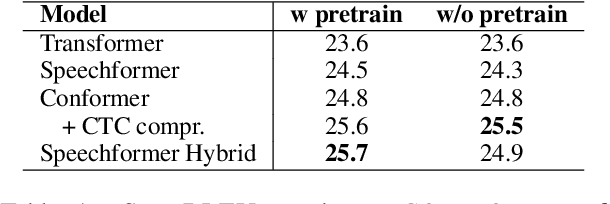
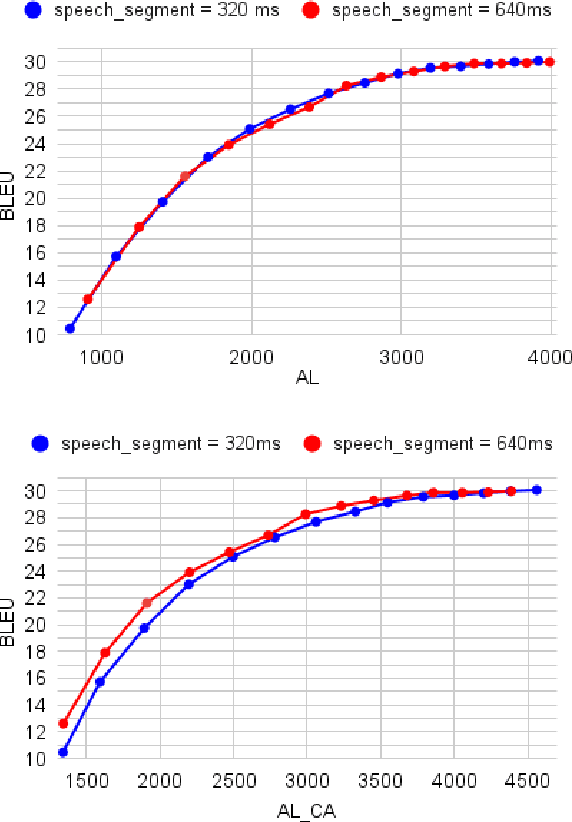
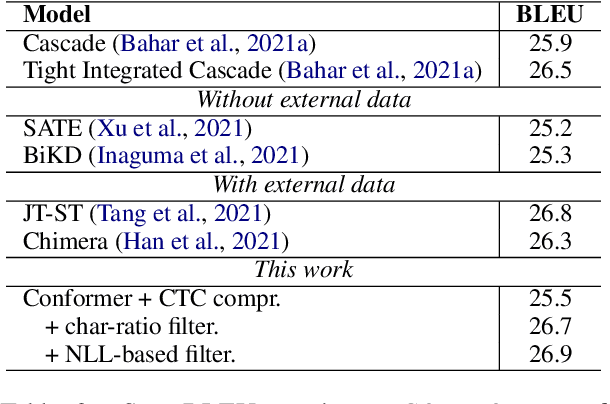
The primary goal of this FBK's systems submission to the IWSLT 2022 offline and simultaneous speech translation tasks is to reduce model training costs without sacrificing translation quality. As such, we first question the need of ASR pre-training, showing that it is not essential to achieve competitive results. Second, we focus on data filtering, showing that a simple method that looks at the ratio between source and target characters yields a quality improvement of 1 BLEU. Third, we compare different methods to reduce the detrimental effect of the audio segmentation mismatch between training data manually segmented at sentence level and inference data that is automatically segmented. Towards the same goal of training cost reduction, we participate in the simultaneous task with the same model trained for offline ST. The effectiveness of our lightweight training strategy is shown by the high score obtained on the MuST-C en-de corpus (26.7 BLEU) and is confirmed in high-resource data conditions by a 1.6 BLEU improvement on the IWSLT2020 test set over last year's winning system.
Finstreder: Simple and fast Spoken Language Understanding with Finite State Transducers using modern Speech-to-Text models
Jun 29, 2022
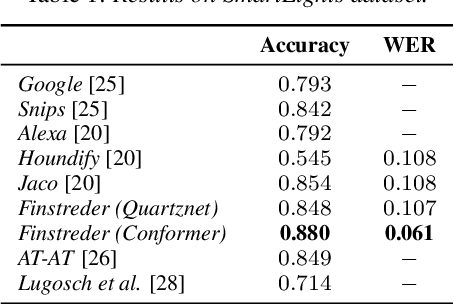
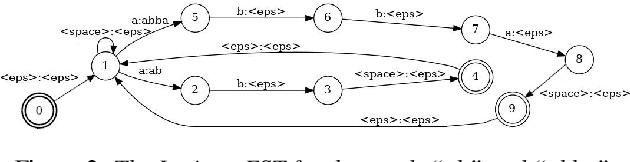
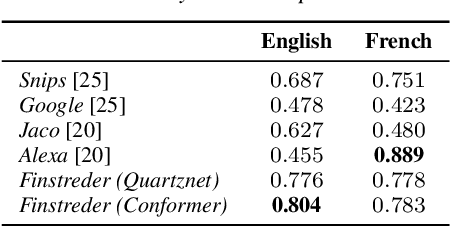
In Spoken Language Understanding (SLU) the task is to extract important information from audio commands, like the intent of what a user wants the system to do and special entities like locations or numbers. This paper presents a simple method for embedding intents and entities into Finite State Transducers, and, in combination with a pretrained general-purpose Speech-to-Text model, allows building SLU-models without any additional training. Building those models is very fast and only takes a few seconds. It is also completely language independent. With a comparison on different benchmarks it is shown that this method can outperform multiple other, more resource demanding SLU approaches.
RemixIT: Continual self-training of speech enhancement models via bootstrapped remixing
Feb 22, 2022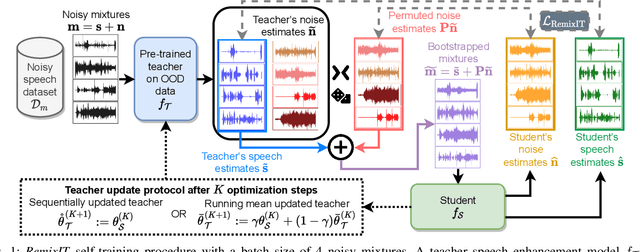
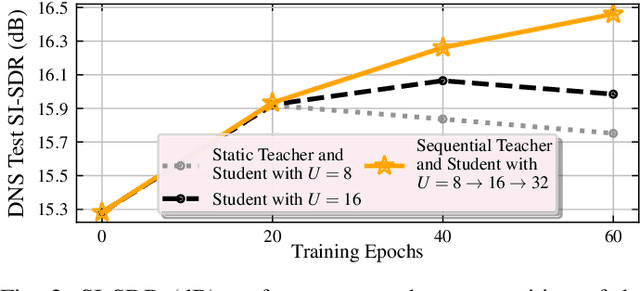
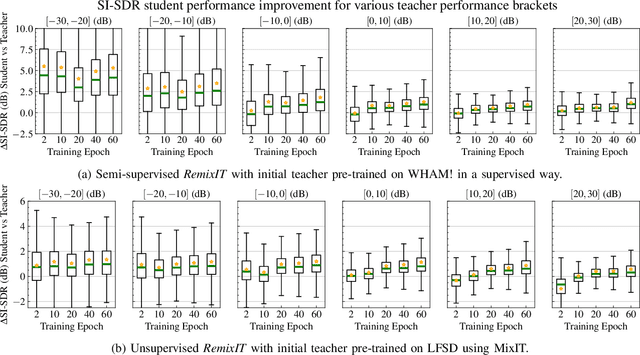
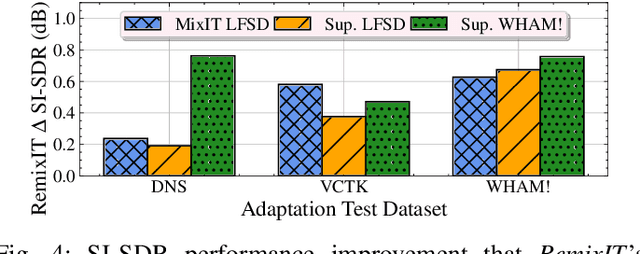
We present RemixIT, a simple yet effective self-supervised method for training speech enhancement without the need of a single isolated in-domain speech nor a noise waveform. Our approach overcomes limitations of previous methods which make them dependent on clean in-domain target signals and thus, sensitive to any domain mismatch between train and test samples. RemixIT is based on a continuous self-training scheme in which a pre-trained teacher model on out-of-domain data infers estimated pseudo-target signals for in-domain mixtures. Then, by permuting the estimated clean and noise signals and remixing them together, we generate a new set of bootstrapped mixtures and corresponding pseudo-targets which are used to train the student network. Vice-versa, the teacher periodically refines its estimates using the updated parameters of the latest student models. Experimental results on multiple speech enhancement datasets and tasks not only show the superiority of our method over prior approaches but also showcase that RemixIT can be combined with any separation model as well as be applied towards any semi-supervised and unsupervised domain adaptation task. Our analysis, paired with empirical evidence, sheds light on the inside functioning of our self-training scheme wherein the student model keeps obtaining better performance while observing severely degraded pseudo-targets.
DUAL: Textless Spoken Question Answering with Speech Discrete Unit Adaptive Learning
Mar 09, 2022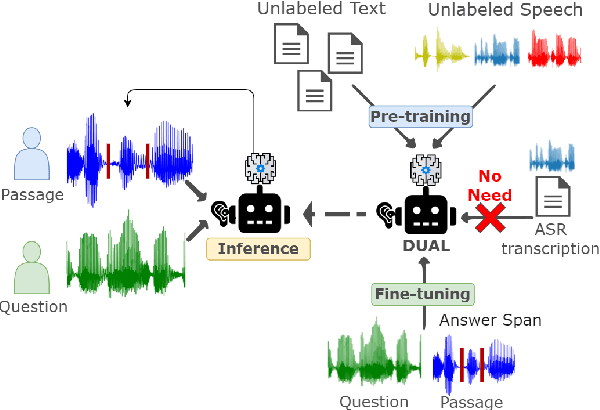
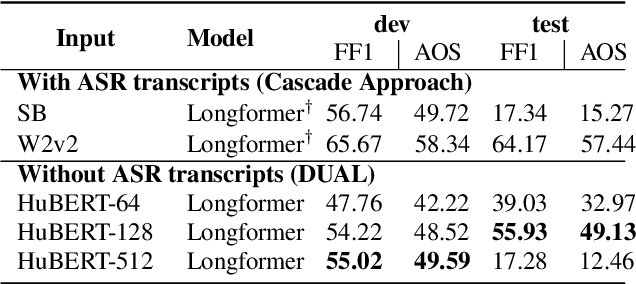
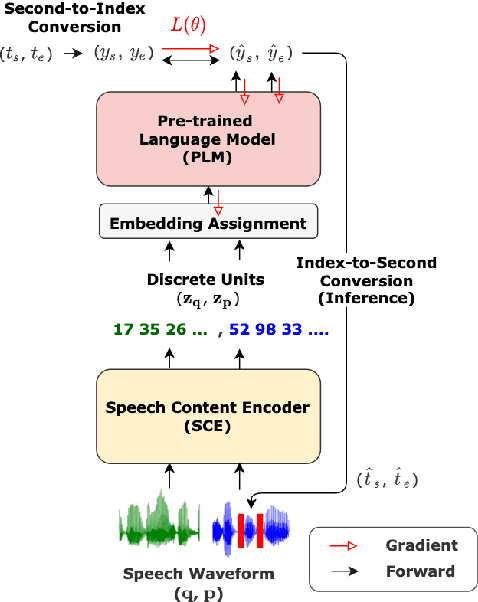
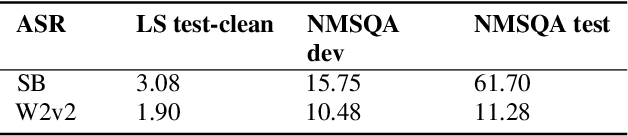
Spoken Question Answering (SQA) has gained research attention and made remarkable progress in recent years. However, existing SQA methods rely on Automatic Speech Recognition (ASR) transcripts, which are time and cost-prohibitive to collect. This work proposes an ASR transcript-free SQA framework named Discrete Unit Adaptive Learning (DUAL), which leverages unlabeled data for pre-training and is fine-tuned by the SQA downstream task. DAUL can directly predict the time interval of the spoken answer from the spoken document. We also release a new SQA benchmark corpus Natural Multi-speaker Spoken Question Answering (NMSQA) for testing SQA in realistic scenarios. The experimental results show that DUAL performs competitively with the cascade approach (ASR + text QA), and DUAL is robust to real-world speech. We will open-source our code and model to inspire more SQA innovations from the community