 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Attention-based Multi-hypothesis Fusion for Speech Summarization
Nov 16, 2021
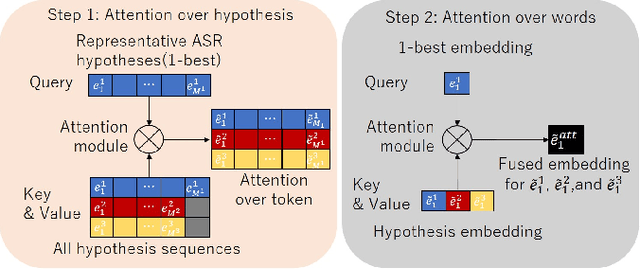

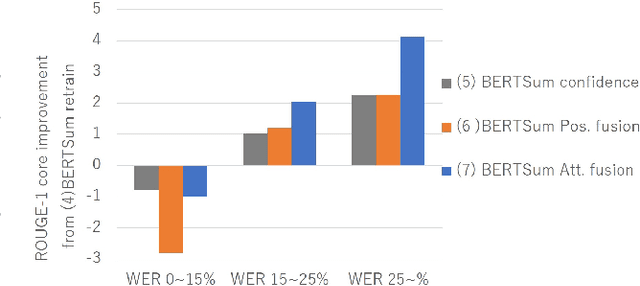

Speech summarization, which generates a text summary from speech, can be achieved by combining automatic speech recognition (ASR) and text summarization (TS). With this cascade approach, we can exploit state-of-the-art models and large training datasets for both subtasks, i.e., Transformer for ASR and Bidirectional Encoder Representations from Transformers (BERT) for TS. However, ASR errors directly affect the quality of the output summary in the cascade approach. We propose a cascade speech summarization model that is robust to ASR errors and that exploits multiple hypotheses generated by ASR to attenuate the effect of ASR errors on the summary. We investigate several schemes to combine ASR hypotheses. First, we propose using the sum of sub-word embedding vectors weighted by their posterior values provided by an ASR system as an input to a BERT-based TS system. Then, we introduce a more general scheme that uses an attention-based fusion module added to a pre-trained BERT module to align and combine several ASR hypotheses. Finally, we perform speech summarization experiments on the How2 dataset and a newly assembled TED-based dataset that we will release with this paper. These experiments show that retraining the BERT-based TS system with these schemes can improve summarization performance and that the attention-based fusion module is particularly effective.
Tree-constrained Pointer Generator with Graph Neural Network Encodings for Contextual Speech Recognition
Jul 02, 2022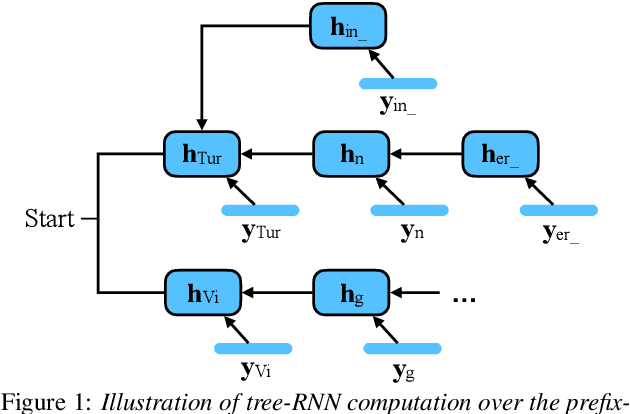
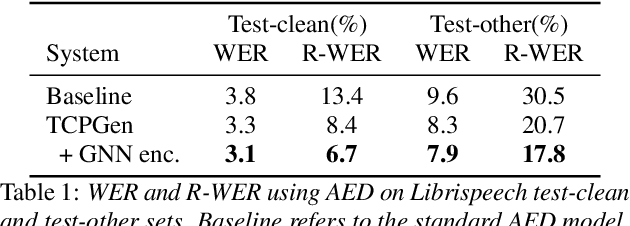
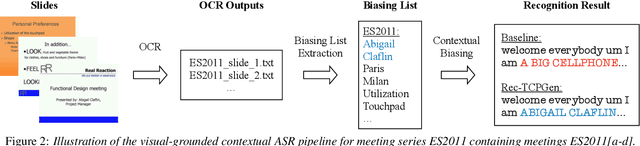
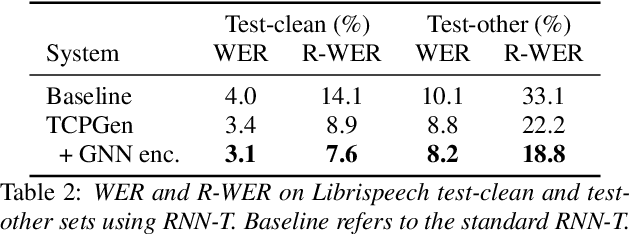
Incorporating biasing words obtained as contextual knowledge is critical for many automatic speech recognition (ASR) applications. This paper proposes the use of graph neural network (GNN) encodings in a tree-constrained pointer generator (TCPGen) component for end-to-end contextual ASR. By encoding the biasing words in the prefix-tree with a tree-based GNN, lookahead for future wordpieces in end-to-end ASR decoding is achieved at each tree node by incorporating information about all wordpieces on the tree branches rooted from it, which allows a more accurate prediction of the generation probability of the biasing words. Systems were evaluated on the Librispeech corpus using simulated biasing tasks, and on the AMI corpus by proposing a novel visual-grounded contextual ASR pipeline that extracts biasing words from slides alongside each meeting. Results showed that TCPGen with GNN encodings achieved about a further 15% relative WER reduction on the biasing words compared to the original TCPGen, with a negligible increase in the computation cost for decoding.
Silence is Sweeter Than Speech: Self-Supervised Model Using Silence to Store Speaker Information
May 08, 2022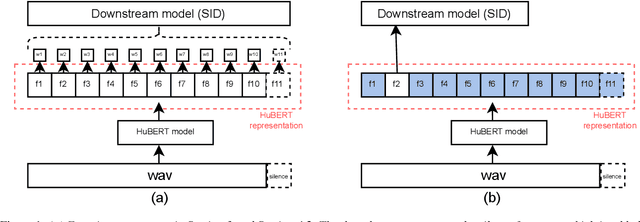
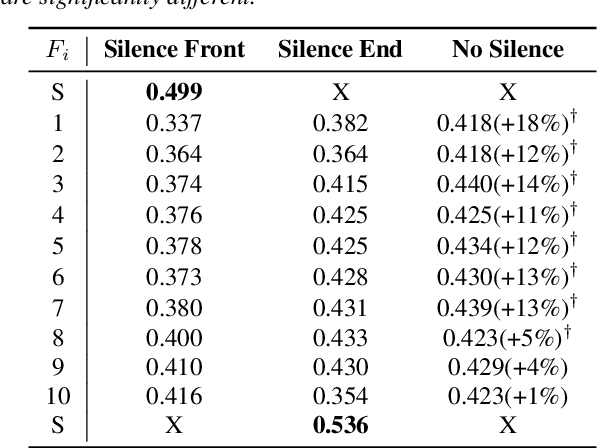
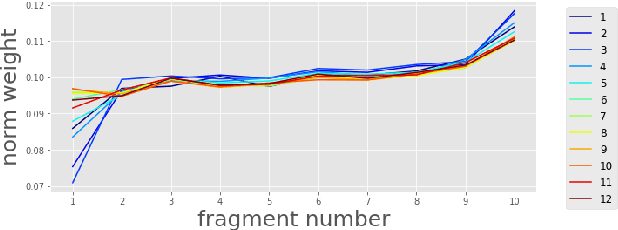
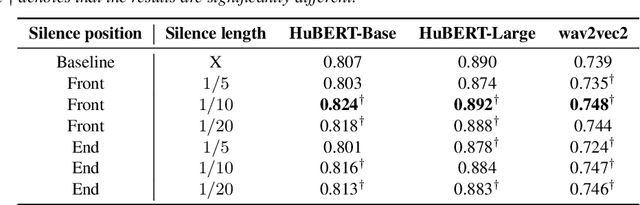
Self-Supervised Learning (SSL) has made great strides recently. SSL speech models achieve decent performance on a wide range of downstream tasks, suggesting that they extract different aspects of information from speech. However, how SSL models store various information in hidden representations without interfering is still poorly understood. Taking the recently successful SSL model, HuBERT, as an example, we explore how the SSL model processes and stores speaker information in the representation. We found that HuBERT stores speaker information in representations whose positions correspond to silences in a waveform. There are several pieces of evidence. (1) We find that the utterances with more silent parts in the waveforms have better Speaker Identification (SID) accuracy. (2) If we use the whole utterances for SID, the silence part always contributes more to the SID task. (3) If we only use the representation of a part of the utterance for SID, the silenced part has higher accuracy than the other parts. Our findings not only contribute to a better understanding of SSL models but also improve performance. By simply adding silence to the original waveform, HuBERT improved its accuracy on SID by nearly 2%.
Technology Pipeline for Large Scale Cross-Lingual Dubbing of Lecture Videos into Multiple Indian Languages
Nov 01, 2022

Cross-lingual dubbing of lecture videos requires the transcription of the original audio, correction and removal of disfluencies, domain term discovery, text-to-text translation into the target language, chunking of text using target language rhythm, text-to-speech synthesis followed by isochronous lipsyncing to the original video. This task becomes challenging when the source and target languages belong to different language families, resulting in differences in generated audio duration. This is further compounded by the original speaker's rhythm, especially for extempore speech. This paper describes the challenges in regenerating English lecture videos in Indian languages semi-automatically. A prototype is developed for dubbing lectures into 9 Indian languages. A mean-opinion-score (MOS) is obtained for two languages, Hindi and Tamil, on two different courses. The output video is compared with the original video in terms of MOS (1-5) and lip synchronisation with scores of 4.09 and 3.74, respectively. The human effort also reduces by 75%.
MMS-MSG: A Multi-purpose Multi-Speaker Mixture Signal Generator
Sep 23, 2022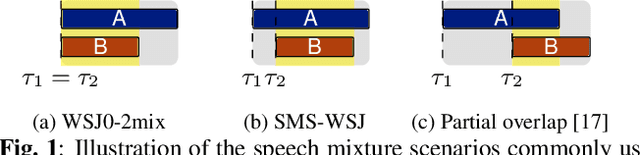
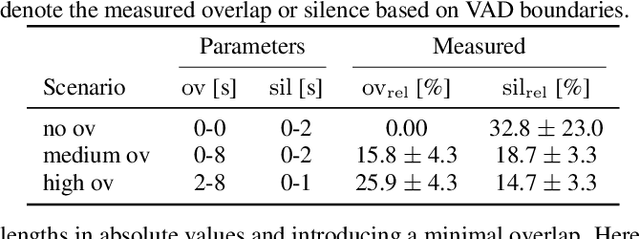
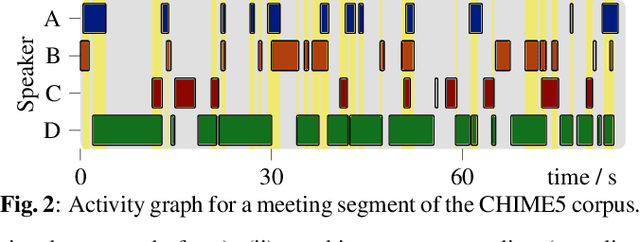
The scope of speech enhancement has changed from a monolithic view of single, independent tasks, to a joint processing of complex conversational speech recordings. Training and evaluation of these single tasks requires synthetic data with access to intermediate signals that is as close as possible to the evaluation scenario. As such data often is not available, many works instead use specialized databases for the training of each system component, e.g WSJ0-mix for source separation. We present a Multi-purpose Multi-Speaker Mixture Signal Generator (MMS-MSG) for generating a variety of speech mixture signals based on any speech corpus, ranging from classical anechoic mixtures (e.g., WSJ0-mix) over reverberant mixtures (e.g., SMS-WSJ) to meeting-style data. Its highly modular and flexible structure allows for the simulation of diverse environments and dynamic mixing, while simultaneously enabling an easy extension and modification to generate new scenarios and mixture types. These meetings can be used for prototyping, evaluation, or training purposes. We provide example evaluation data and baseline results for meetings based on the WSJ corpus. Further, we demonstrate the usefulness for realistic scenarios by using MMS-MSG to provide training data for the LibriCSS database.
The NPU-ASLP System for The ISCSLP 2022 Magichub Code-Swiching ASR Challenge
Oct 26, 2022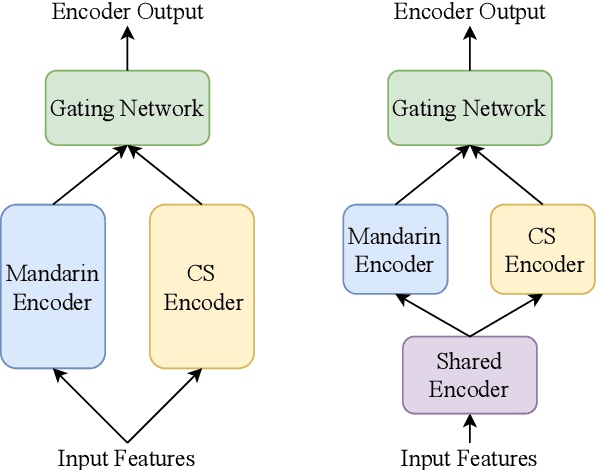

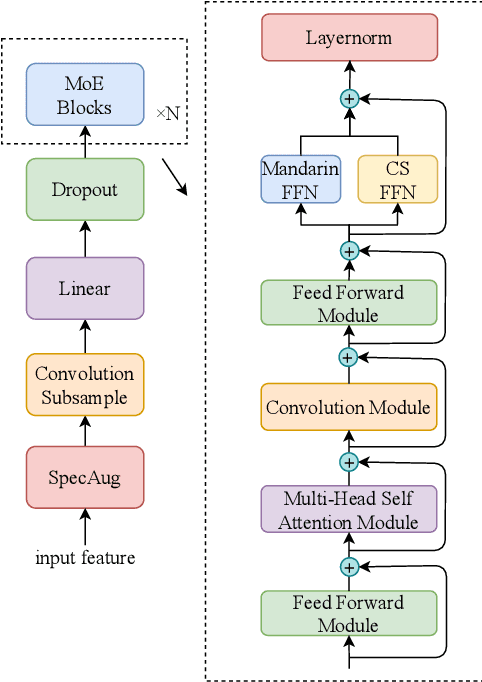
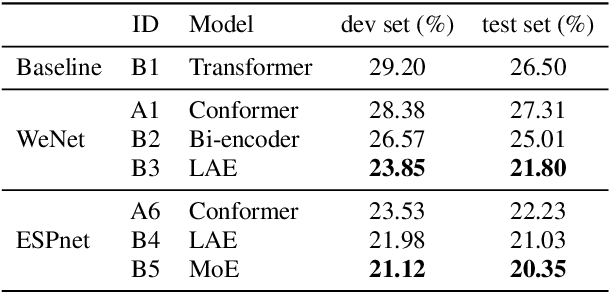
This paper describes our NPU-ASLP system submitted to the ISCSLP 2022 Magichub Code-Switching ASR Challenge. In this challenge, we first explore several popular end-to-end ASR architectures and training strategies, including bi-encoder, language-aware encoder (LAE) and mixture of experts (MoE). To improve our system's language modeling ability, we further attempt the internal language model as well as the long context language model. Given the limited training data in the challenge, we further investigate the effects of data augmentation, including speed perturbation, pitch shifting, speech codec, SpecAugment and synthetic data from text-to-speech (TTS). Finally, we explore ROVER-based score fusion to make full use of complementary hypotheses from different models. Our submitted system achieves 16.87% on mix error rate (MER) on the test set and comes to the 2nd place in the challenge ranking.
The People's Speech: A Large-Scale Diverse English Speech Recognition Dataset for Commercial Usage
Nov 17, 2021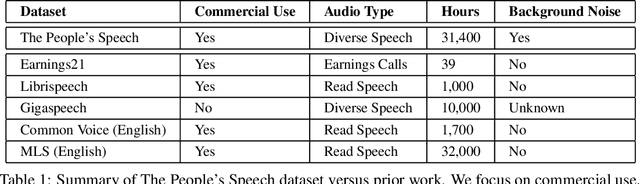
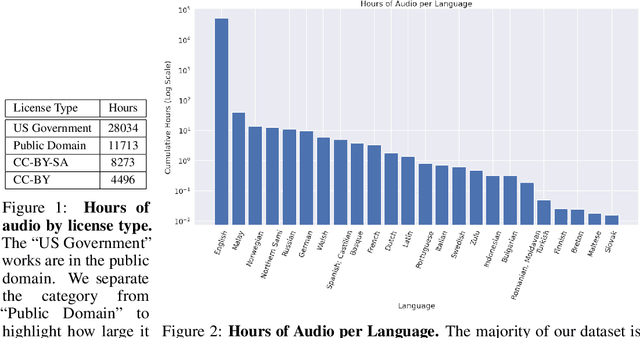

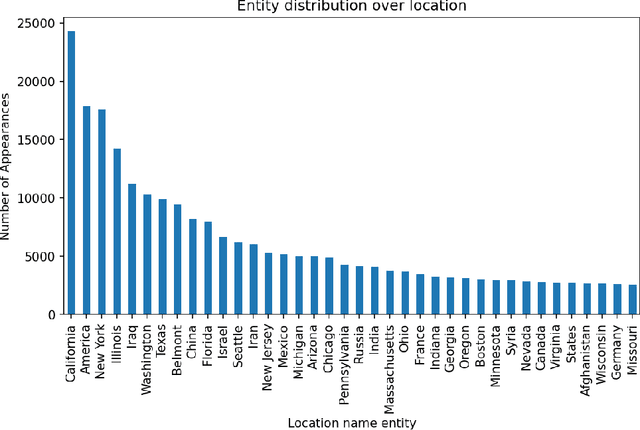
The People's Speech is a free-to-download 30,000-hour and growing supervised conversational English speech recognition dataset licensed for academic and commercial usage under CC-BY-SA (with a CC-BY subset). The data is collected via searching the Internet for appropriately licensed audio data with existing transcriptions. We describe our data collection methodology and release our data collection system under the Apache 2.0 license. We show that a model trained on this dataset achieves a 9.98% word error rate on Librispeech's test-clean test set.Finally, we discuss the legal and ethical issues surrounding the creation of a sizable machine learning corpora and plans for continued maintenance of the project under MLCommons's sponsorship.
Neural Architecture Search for Speech Emotion Recognition
Mar 31, 2022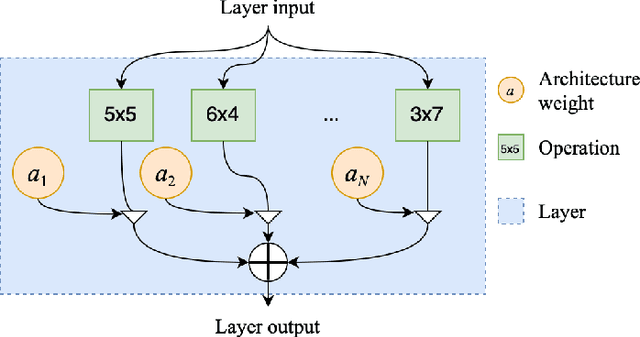
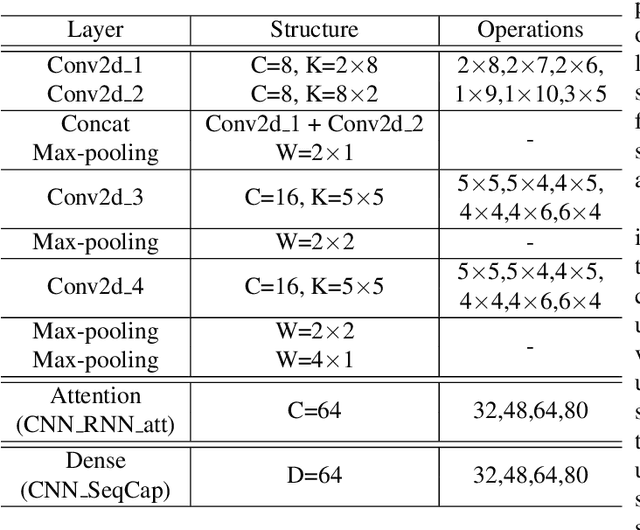
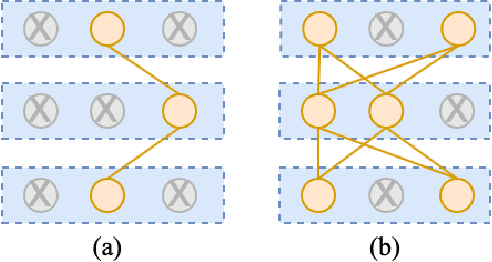
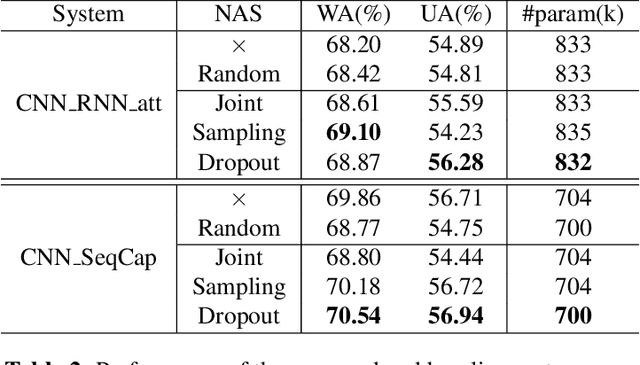
Deep neural networks have brought significant advancements to speech emotion recognition (SER). However, the architecture design in SER is mainly based on expert knowledge and empirical (trial-and-error) evaluations, which is time-consuming and resource intensive. In this paper, we propose to apply neural architecture search (NAS) techniques to automatically configure the SER models. To accelerate the candidate architecture optimization, we propose a uniform path dropout strategy to encourage all candidate architecture operations to be equally optimized. Experimental results of two different neural structures on IEMOCAP show that NAS can improve SER performance (54.89\% to 56.28\%) while maintaining model parameter sizes. The proposed dropout strategy also shows superiority over the previous approaches.
SceneFake: An Initial Dataset and Benchmarks for Scene Fake Audio Detection
Nov 11, 2022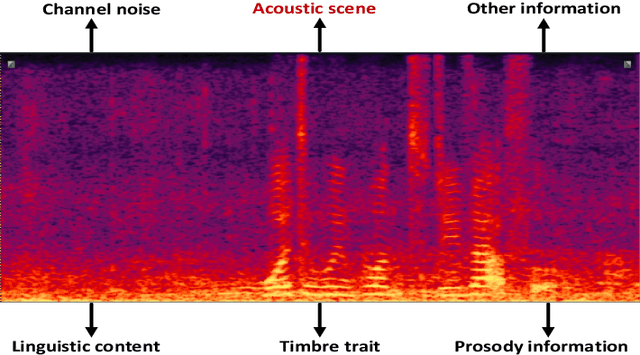
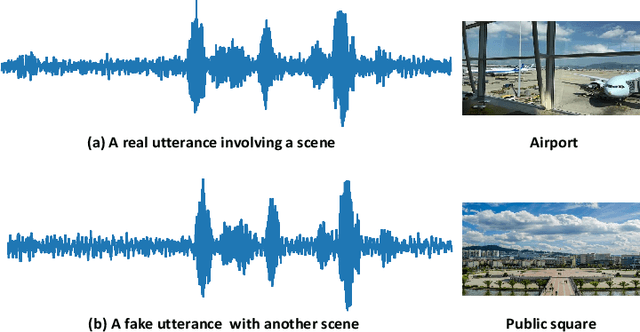
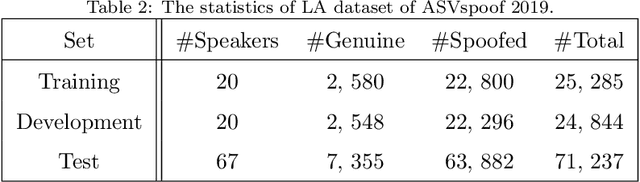
Previous databases have been designed to further the development of fake audio detection. However, fake utterances are mostly generated by altering timbre, prosody, linguistic content or channel noise of original audios. They ignore a fake situation, in which the attacker manipulates an acoustic scene of the original audio with another forgery one. It will pose a major threat to our society if some people misuse the manipulated audio with malicious purpose. Therefore, this motivates us to fill in the gap. This paper designs such a dataset for scene fake audio detection (SceneFake). A manipulated audio in the SceneFake dataset involves only tampering the acoustic scene of an utterance by using speech enhancement technologies. We can not only detect fake utterances on a seen test set but also evaluate the generalization of fake detection models to unseen manipulation attacks. Some benchmark results are described on the SceneFake dataset. Besides, an analysis of fake attacks with different speech enhancement technologies and signal-to-noise ratios are presented on the dataset. The results show that scene manipulated utterances can not be detected reliably by the existing baseline models of ASVspoof 2019. Furthermore, the detection of unseen scene manipulation audio is still challenging.
Knowledge Transfer from Large-scale Pretrained Language Models to End-to-end Speech Recognizers
Feb 16, 2022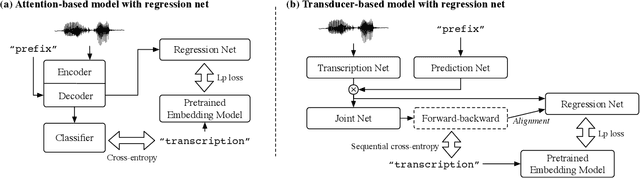
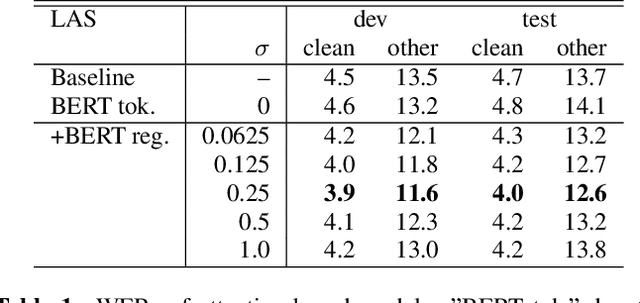
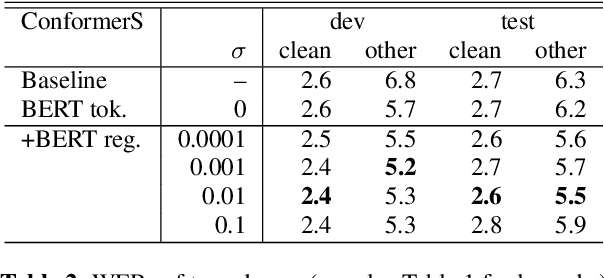
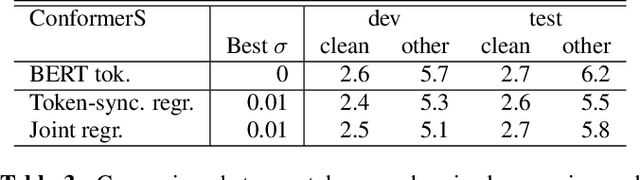
End-to-end speech recognition is a promising technology for enabling compact automatic speech recognition (ASR) systems since it can unify the acoustic and language model into a single neural network. However, as a drawback, training of end-to-end speech recognizers always requires transcribed utterances. Since end-to-end models are also known to be severely data hungry, this constraint is crucial especially because obtaining transcribed utterances is costly and can possibly be impractical or impossible. This paper proposes a method for alleviating this issue by transferring knowledge from a language model neural network that can be pretrained with text-only data. Specifically, this paper attempts to transfer semantic knowledge acquired in embedding vectors of large-scale language models. Since embedding vectors can be assumed as implicit representations of linguistic information such as part-of-speech, intent, and so on, those are also expected to be useful modeling cues for ASR decoders. This paper extends two types of ASR decoders, attention-based decoders and neural transducers, by modifying training loss functions to include embedding prediction terms. The proposed systems were shown to be effective for error rate reduction without incurring extra computational costs in the decoding phase.