 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
An Experimental Investigation of Part-Of-Speech Taggers for Vietnamese
Jun 14, 2022

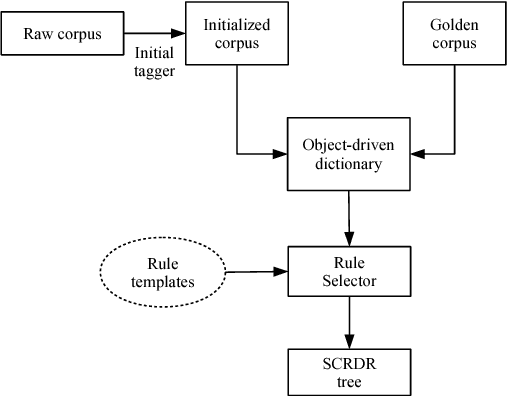

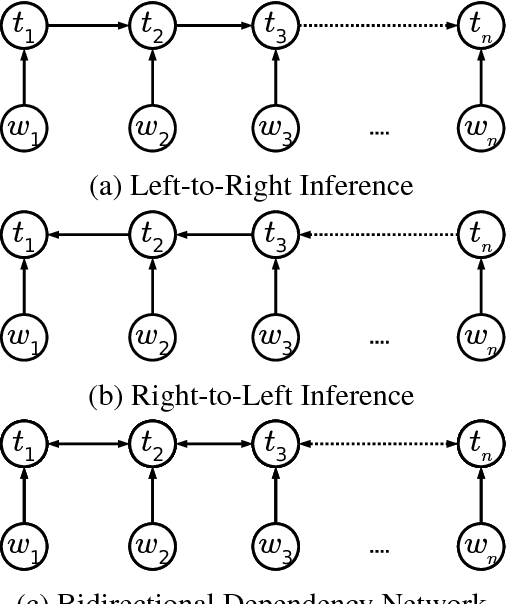
Part-of-speech (POS) tagging plays an important role in Natural Language Processing (NLP). Its applications can be found in many NLP tasks such as named entity recognition, syntactic parsing, dependency parsing and text chunking. In the investigation conducted in this paper, we utilize the technologies of two widely-used toolkits, ClearNLP and Stanford POS Tagger, as well as develop two new POS taggers for Vietnamese, then compare them to three well-known Vietnamese taggers, namely JVnTagger, vnTagger and RDRPOSTagger. We make a systematic comparison to find out the tagger having the best performance. We also design a new feature set to measure the performance of the statistical taggers. Our new taggers built from Stanford Tagger and ClearNLP with the new feature set can outperform all other current Vietnamese taggers in term of tagging accuracy. Moreover, we also analyze the affection of some features to the performance of statistical taggers. Lastly, the experimental results also reveal that the transformation-based tagger, RDRPOSTagger, can run significantly faster than any other statistical tagger.
InterMulti:Multi-view Multimodal Interactions with Text-dominated Hierarchical High-order Fusion for Emotion Analysis
Dec 20, 2022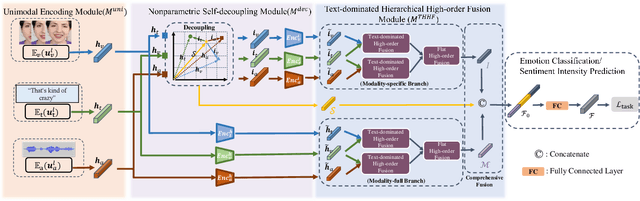
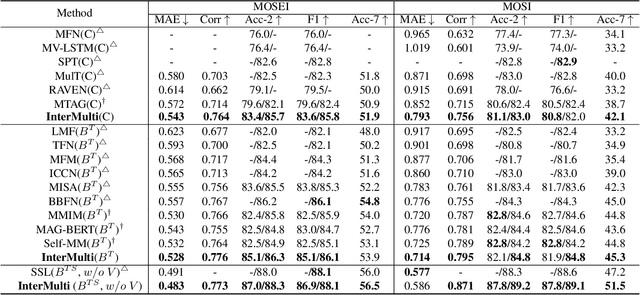
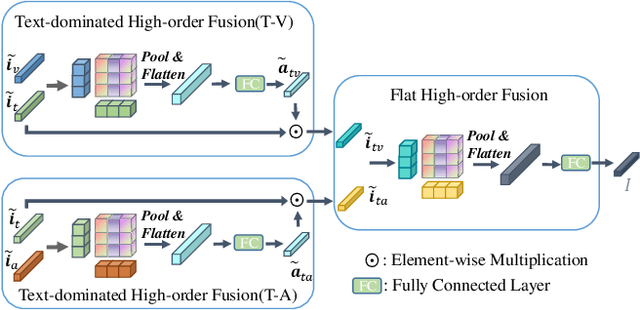
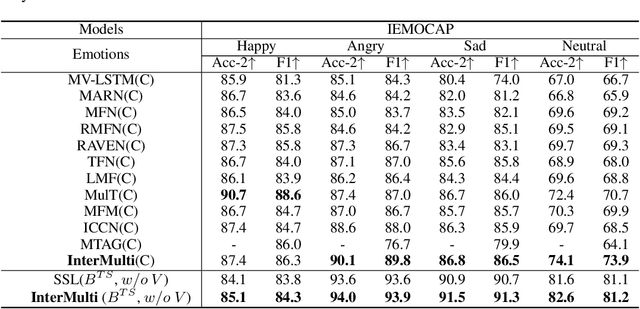
Humans are sophisticated at reading interlocutors' emotions from multimodal signals, such as speech contents, voice tones and facial expressions. However, machines might struggle to understand various emotions due to the difficulty of effectively decoding emotions from the complex interactions between multimodal signals. In this paper, we propose a multimodal emotion analysis framework, InterMulti, to capture complex multimodal interactions from different views and identify emotions from multimodal signals. Our proposed framework decomposes signals of different modalities into three kinds of multimodal interaction representations, including a modality-full interaction representation, a modality-shared interaction representation, and three modality-specific interaction representations. Additionally, to balance the contribution of different modalities and learn a more informative latent interaction representation, we developed a novel Text-dominated Hierarchical High-order Fusion(THHF) module. THHF module reasonably integrates the above three kinds of representations into a comprehensive multimodal interaction representation. Extensive experimental results on widely used datasets, (i.e.) MOSEI, MOSI and IEMOCAP, demonstrate that our method outperforms the state-of-the-art.
Layer-wise Fast Adaptation for End-to-End Multi-Accent Speech Recognition
Apr 21, 2022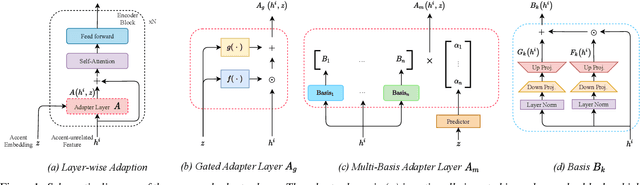
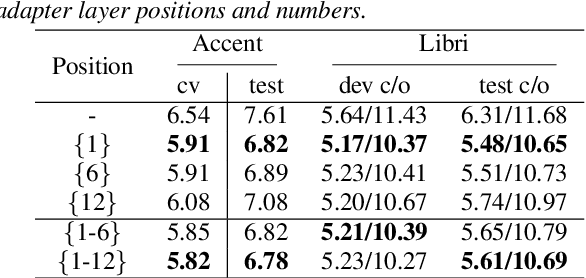
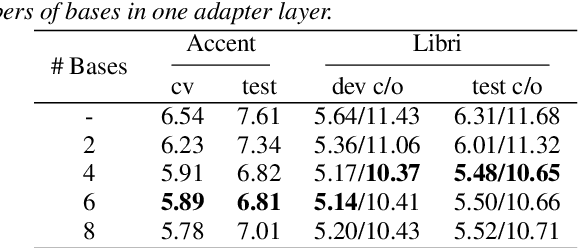
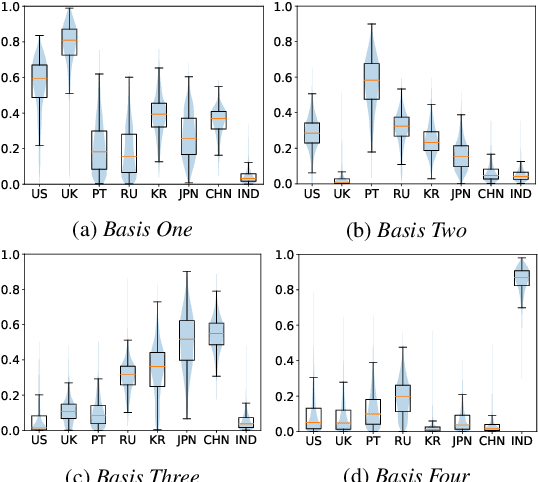
Accent variability has posed a huge challenge to automatic speech recognition~(ASR) modeling. Although one-hot accent vector based adaptation systems are commonly used, they require prior knowledge about the target accent and cannot handle unseen accents. Furthermore, simply concatenating accent embeddings does not make good use of accent knowledge, which has limited improvements. In this work, we aim to tackle these problems with a novel layer-wise adaptation structure injected into the E2E ASR model encoder. The adapter layer encodes an arbitrary accent in the accent space and assists the ASR model in recognizing accented speech. Given an utterance, the adaptation structure extracts the corresponding accent information and transforms the input acoustic feature into an accent-related feature through the linear combination of all accent bases. We further explore the injection position of the adaptation layer, the number of accent bases, and different types of accent bases to achieve better accent adaptation. Experimental results show that the proposed adaptation structure brings 12\% and 10\% relative word error rate~(WER) reduction on the AESRC2020 accent dataset and the Librispeech dataset, respectively, compared to the baseline.
* Accepted by Interspeech2021
A Speech Intelligibility Enhancement Model based on Canonical Correlation and Deep Learning for Hearing-Assistive Technologies
Feb 15, 2022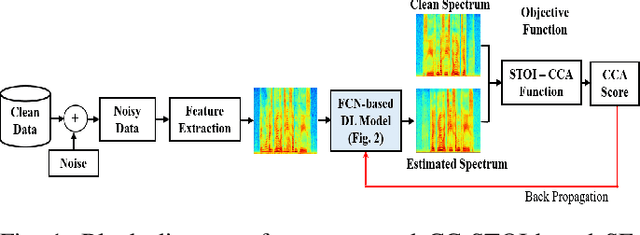
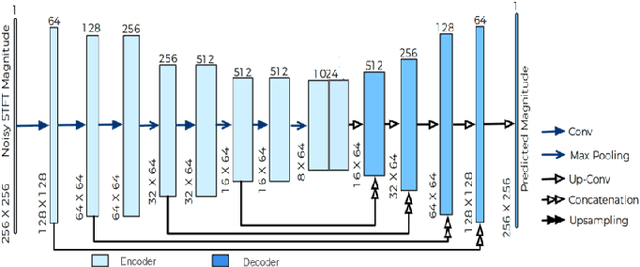
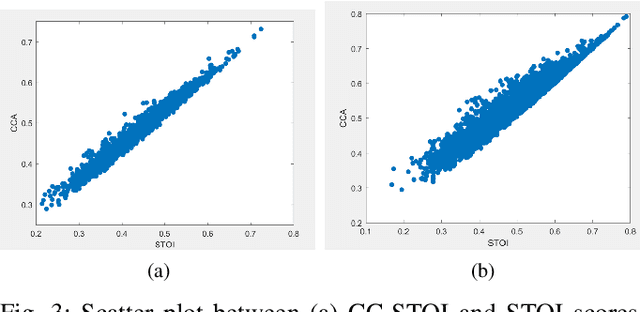
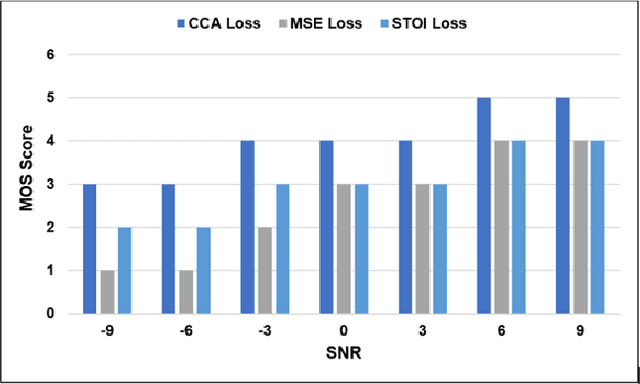
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are generally trained to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in everyday noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions to train DL approaches for robust speech enhancement (SE). In this paper, we formulate a novel canonical correlation-based I-O loss function to more effectively train DL algorithms. Specifically, we present a fully convolutional SE model that uses a modified canonical-correlation based short-time objective intelligibility (CC-STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of canonical correlation in an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed CC-STOI based SE framework outperforms DL models trained with conventional STOI and distance-based loss functions, in terms of both standard objective and subjective evaluation measures when dealing with unseen speakers and noises.
Automated Sex Classification of Children's Voices and Changes in Differentiating Factors with Age
Sep 27, 2022
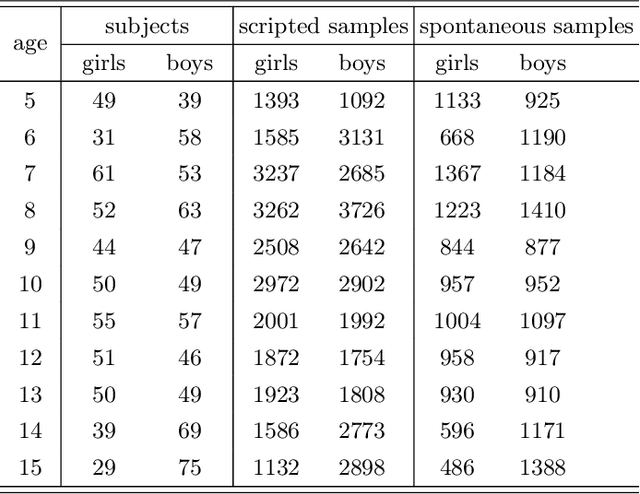
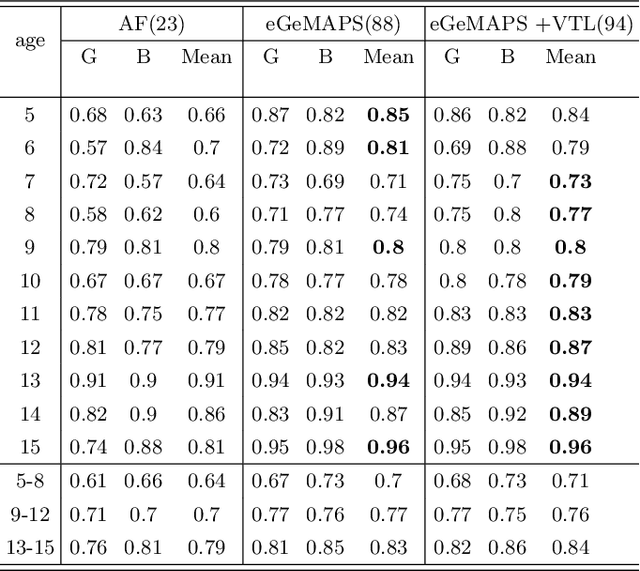
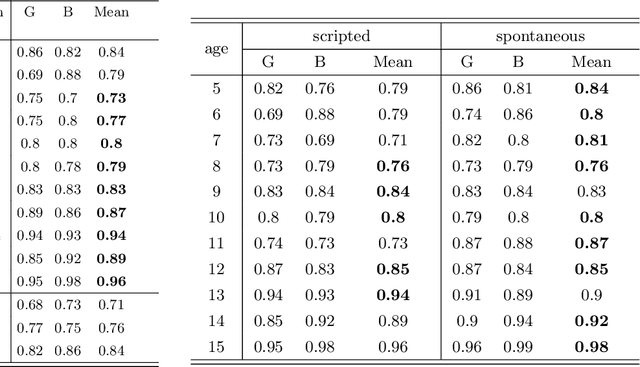
Sex classification of children's voices allows for an investigation of the development of secondary sex characteristics which has been a key interest in the field of speech analysis. This research investigated a broad range of acoustic features from scripted and spontaneous speech and applied a hierarchical clustering-based machine learning model to distinguish the sex of children aged between 5 and 15 years. We proposed an optimal feature set and our modelling achieved an average F1 score (the harmonic mean of the precision and recall) of 0.84 across all ages. Our results suggest that the sex classification is generally more accurate when a model is developed for each year group rather than for children in 4-year age bands, with classification accuracy being better for older age groups. We found that spontaneous speech could provide more helpful cues in sex classification than scripted speech, especially for children younger than 7 years. For younger age groups, a broad range of acoustic factors contributed evenly to sex classification, while for older age groups, F0-related acoustic factors were found to be the most critical predictors generally. Other important acoustic factors for older age groups include vocal tract length estimators, spectral flux, loudness and unvoiced features.
Tree-constrained Pointer Generator with Graph Neural Network Encodings for Contextual Speech Recognition
Jul 02, 2022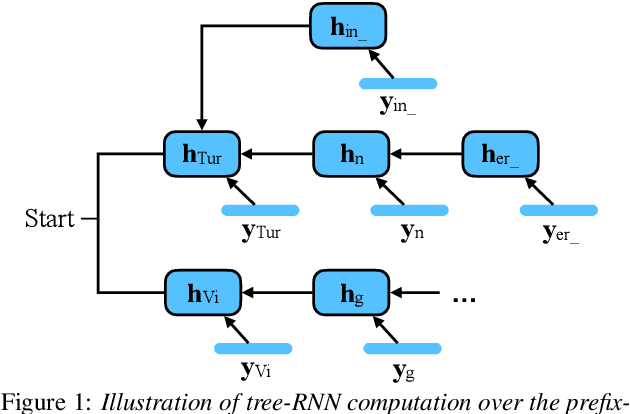
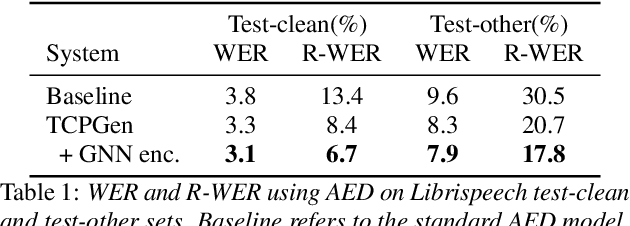
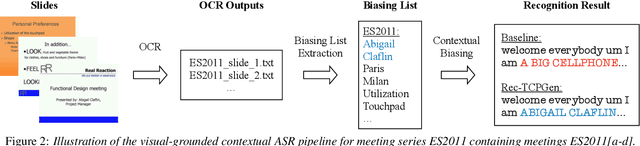
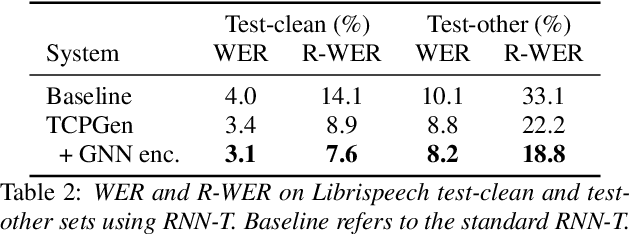
Incorporating biasing words obtained as contextual knowledge is critical for many automatic speech recognition (ASR) applications. This paper proposes the use of graph neural network (GNN) encodings in a tree-constrained pointer generator (TCPGen) component for end-to-end contextual ASR. By encoding the biasing words in the prefix-tree with a tree-based GNN, lookahead for future wordpieces in end-to-end ASR decoding is achieved at each tree node by incorporating information about all wordpieces on the tree branches rooted from it, which allows a more accurate prediction of the generation probability of the biasing words. Systems were evaluated on the Librispeech corpus using simulated biasing tasks, and on the AMI corpus by proposing a novel visual-grounded contextual ASR pipeline that extracts biasing words from slides alongside each meeting. Results showed that TCPGen with GNN encodings achieved about a further 15% relative WER reduction on the biasing words compared to the original TCPGen, with a negligible increase in the computation cost for decoding.
Selecting and combining complementary feature representations and classifiers for hate speech detection
Jan 18, 2022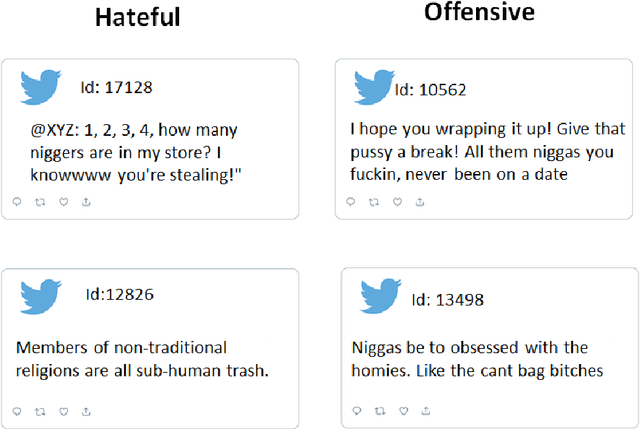
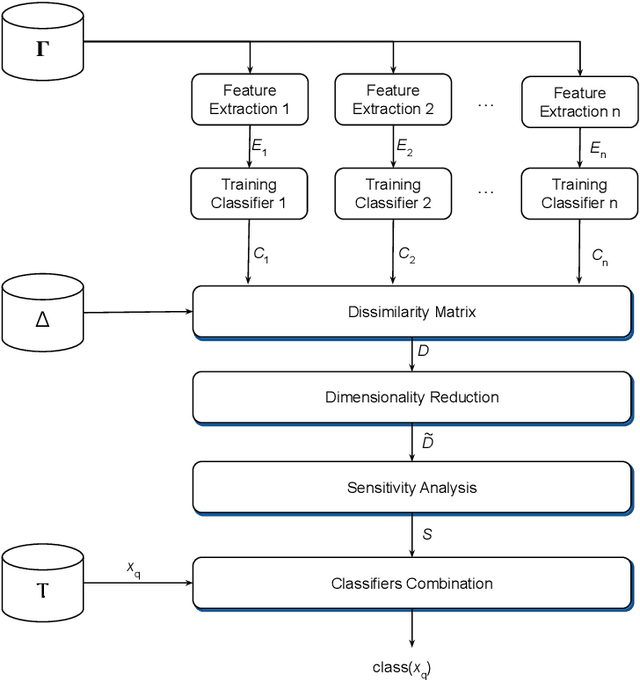
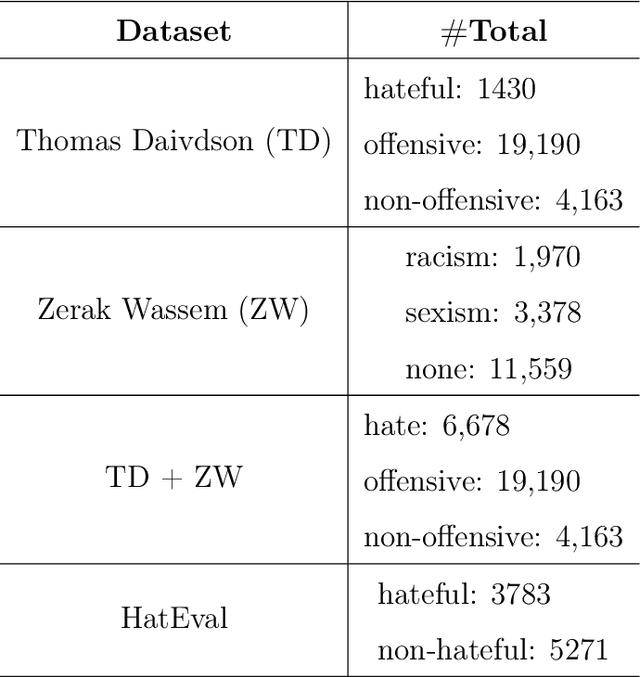

Hate speech is a major issue in social networks due to the high volume of data generated daily. Recent works demonstrate the usefulness of machine learning (ML) in dealing with the nuances required to distinguish between hateful posts from just sarcasm or offensive language. Many ML solutions for hate speech detection have been proposed by either changing how features are extracted from the text or the classification algorithm employed. However, most works consider only one type of feature extraction and classification algorithm. This work argues that a combination of multiple feature extraction techniques and different classification models is needed. We propose a framework to analyze the relationship between multiple feature extraction and classification techniques to understand how they complement each other. The framework is used to select a subset of complementary techniques to compose a robust multiple classifiers system (MCS) for hate speech detection. The experimental study considering four hate speech classification datasets demonstrates that the proposed framework is a promising methodology for analyzing and designing high-performing MCS for this task. MCS system obtained using the proposed framework significantly outperforms the combination of all models and the homogeneous and heterogeneous selection heuristics, demonstrating the importance of having a proper selection scheme. Source code, figures, and dataset splits can be found in the GitHub repository: https://github.com/Menelau/Hate-Speech-MCS.
Hate Speech Classifiers Learn Human-Like Social Stereotypes
Oct 28, 2021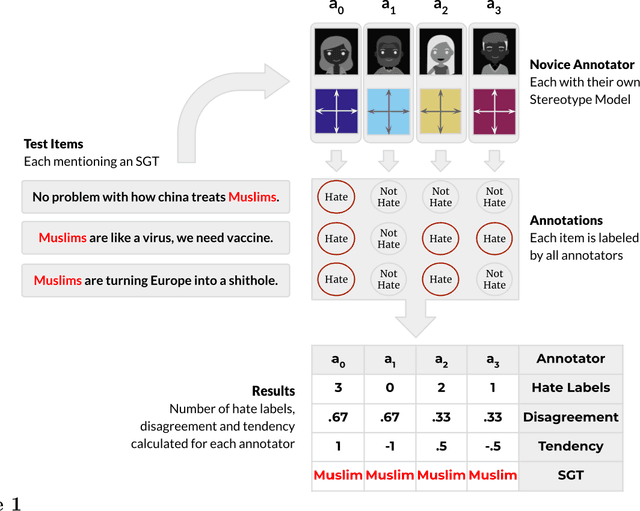
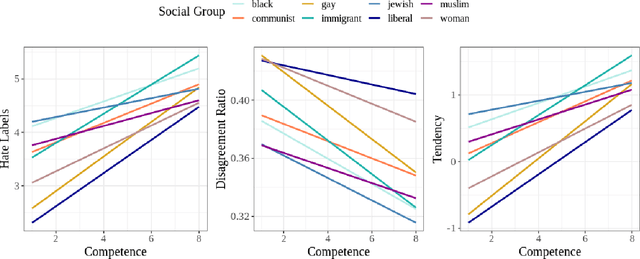
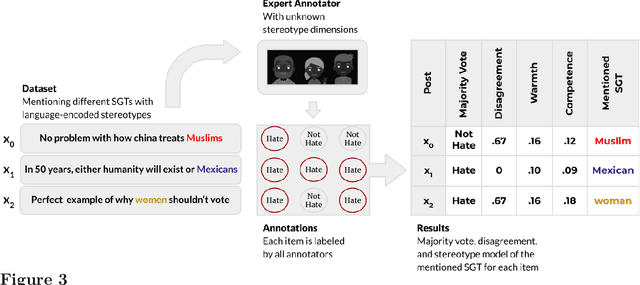
Social stereotypes negatively impact individuals' judgements about different groups and may have a critical role in how people understand language directed toward minority social groups. Here, we assess the role of social stereotypes in the automated detection of hateful language by examining the relation between individual annotator biases and erroneous classification of texts by hate speech classifiers. Specifically, in Study 1 we investigate the impact of novice annotators' stereotypes on their hate-speech-annotation behavior. In Study 2 we examine the effect of language-embedded stereotypes on expert annotators' aggregated judgements in a large annotated corpus. Finally, in Study 3 we demonstrate how language-embedded stereotypes are associated with systematic prediction errors in a neural-network hate speech classifier. Our results demonstrate that hate speech classifiers learn human-like biases which can further perpetuate social inequalities when propagated at scale. This framework, combining social psychological and computational linguistic methods, provides insights into additional sources of bias in hate speech moderation, informing ongoing debates regarding fairness in machine learning.
Speech Emotion Recognition with Global-Aware Fusion on Multi-scale Feature Representation
Apr 12, 2022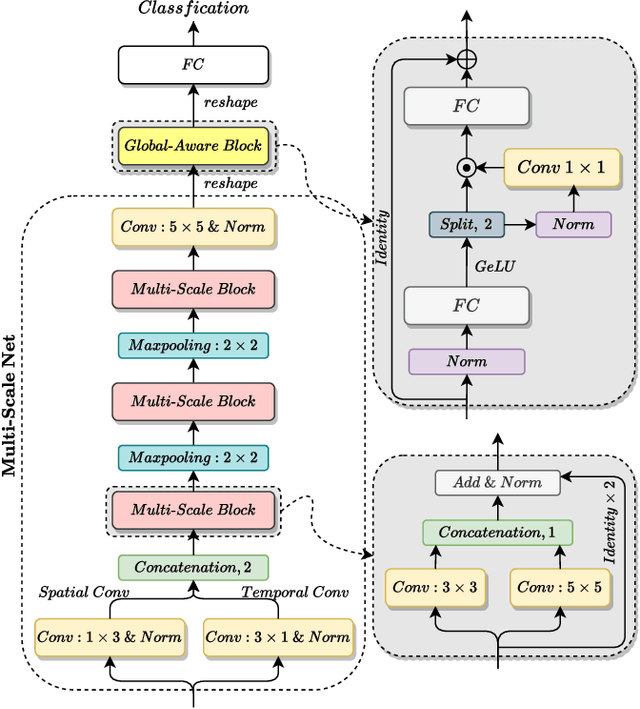
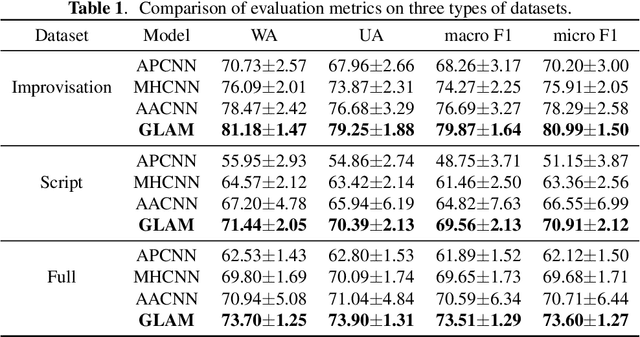
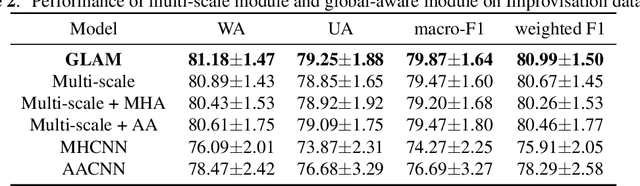
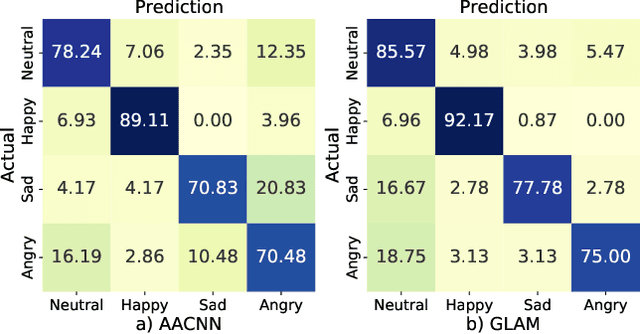
Speech Emotion Recognition (SER) is a fundamental task to predict the emotion label from speech data. Recent works mostly focus on using convolutional neural networks~(CNNs) to learn local attention map on fixed-scale feature representation by viewing time-varied spectral features as images. However, rich emotional feature at different scales and important global information are not able to be well captured due to the limits of existing CNNs for SER. In this paper, we propose a novel GLobal-Aware Multi-scale (GLAM) neural network (The code is available at https://github.com/lixiangucas01/GLAM) to learn multi-scale feature representation with global-aware fusion module to attend emotional information. Specifically, GLAM iteratively utilizes multiple convolutional kernels with different scales to learn multiple feature representation. Then, instead of using attention-based methods, a simple but effective global-aware fusion module is applied to grab most important emotional information globally. Experiments on the benchmark corpus IEMOCAP over four emotions demonstrates the superiority of our proposed model with 2.5% to 4.5% improvements on four common metrics compared to previous state-of-the-art approaches.
Audio-visual speech separation based on joint feature representation with cross-modal attention
Mar 05, 2022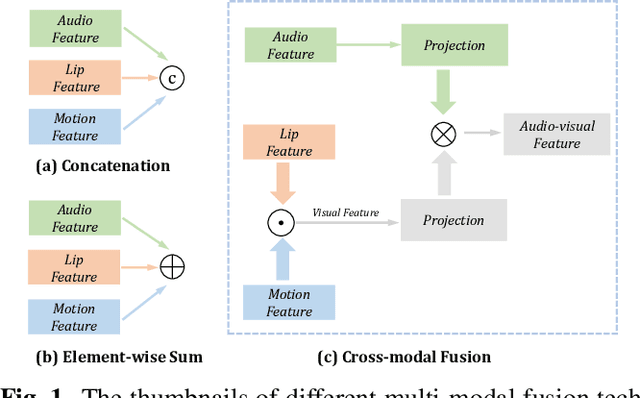
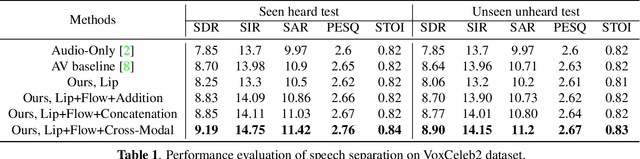
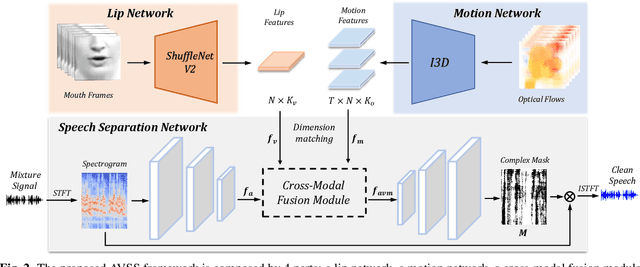
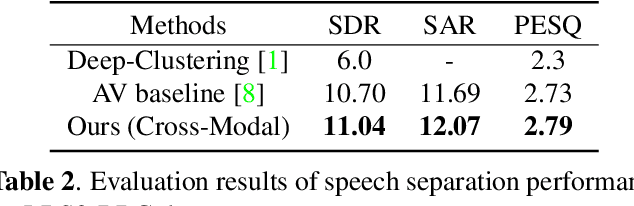
Multi-modal based speech separation has exhibited a specific advantage on isolating the target character in multi-talker noisy environments. Unfortunately, most of current separation strategies prefer a straightforward fusion based on feature learning of each single modality, which is far from sufficient consideration of inter-relationships between modalites. Inspired by learning joint feature representations from audio and visual streams with attention mechanism, in this study, a novel cross-modal fusion strategy is proposed to benefit the whole framework with semantic correlations between different modalities. To further improve audio-visual speech separation, the dense optical flow of lip motion is incorporated to strengthen the robustness of visual representation. The evaluation of the proposed work is performed on two public audio-visual speech separation benchmark datasets. The overall improvement of the performance has demonstrated that the additional motion network effectively enhances the visual representation of the combined lip images and audio signal, as well as outperforming the baseline in terms of all metrics with the proposed cross-modal fusion.