 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
ExploreADV: Towards exploratory attack for Neural Networks
Jan 01, 2023
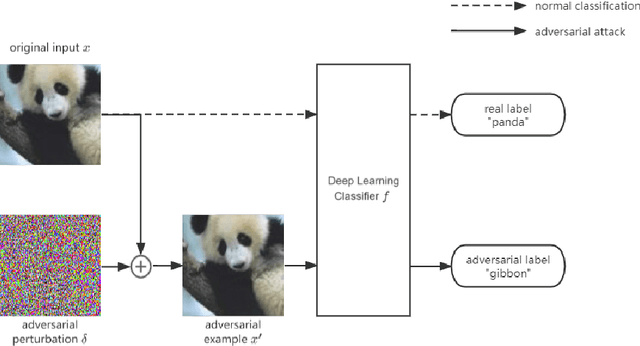


Although deep learning has made remarkable progress in processing various types of data such as images, text and speech, they are known to be susceptible to adversarial perturbations: perturbations specifically designed and added to the input to make the target model produce erroneous output. Most of the existing studies on generating adversarial perturbations attempt to perturb the entire input indiscriminately. In this paper, we propose ExploreADV, a general and flexible adversarial attack system that is capable of modeling regional and imperceptible attacks, allowing users to explore various kinds of adversarial examples as needed. We adapt and combine two existing boundary attack methods, DeepFool and Brendel\&Bethge Attack, and propose a mask-constrained adversarial attack system, which generates minimal adversarial perturbations under the pixel-level constraints, namely ``mask-constraints''. We study different ways of generating such mask-constraints considering the variance and importance of the input features, and show that our adversarial attack system offers users good flexibility to focus on sub-regions of inputs, explore imperceptible perturbations and understand the vulnerability of pixels/regions to adversarial attacks. We demonstrate our system to be effective based on extensive experiments and user study.
AVATAR submission to the Ego4D AV Transcription Challenge
Nov 18, 2022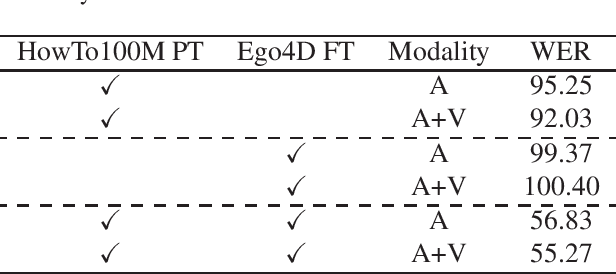
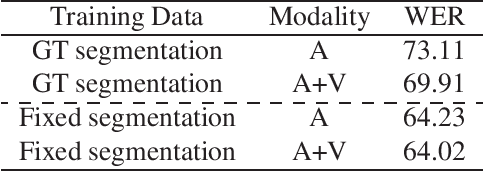
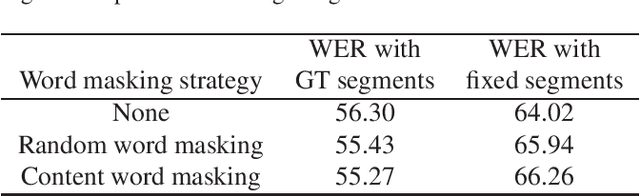

In this report, we describe our submission to the Ego4D AudioVisual (AV) Speech Transcription Challenge 2022. Our pipeline is based on AVATAR, a state of the art encoder-decoder model for AV-ASR that performs early fusion of spectrograms and RGB images. We describe the datasets, experimental settings and ablations. Our final method achieves a WER of 68.40 on the challenge test set, outperforming the baseline by 43.7%, and winning the challenge.
CycleGAN-Based Unpaired Speech Dereverberation
Mar 29, 2022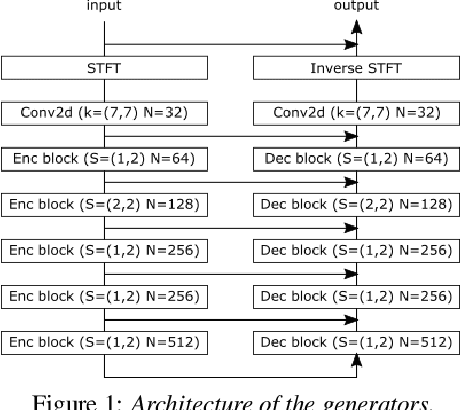

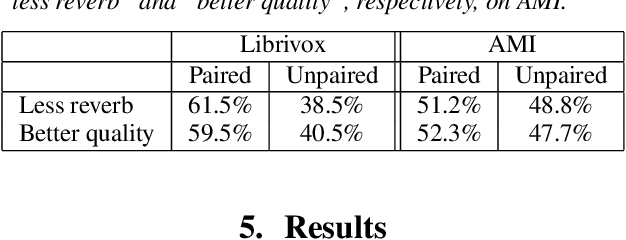
Typically, neural network-based speech dereverberation models are trained on paired data, composed of a dry utterance and its corresponding reverberant utterance. The main limitation of this approach is that such models can only be trained on large amounts of data and a variety of room impulse responses when the data is synthetically reverberated, since acquiring real paired data is costly. In this paper we propose a CycleGAN-based approach that enables dereverberation models to be trained on unpaired data. We quantify the impact of using unpaired data by comparing the proposed unpaired model to a paired model with the same architecture and trained on the paired version of the same dataset. We show that the performance of the unpaired model is comparable to the performance of the paired model on two different datasets, according to objective evaluation metrics. Furthermore, we run two subjective evaluations and show that both models achieve comparable subjective quality on the AMI dataset, which was not seen during training.
Facial Landmark Predictions with Applications to Metaverse
Sep 29, 2022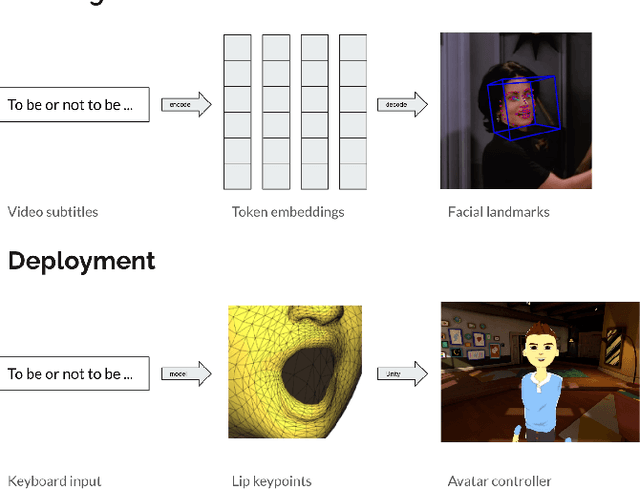
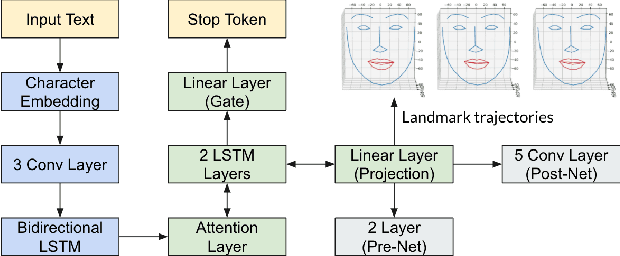
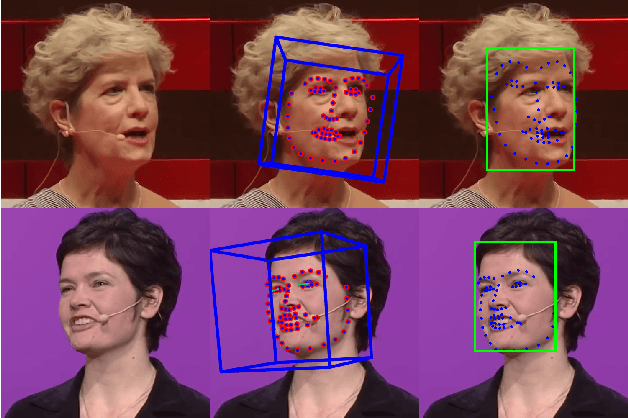
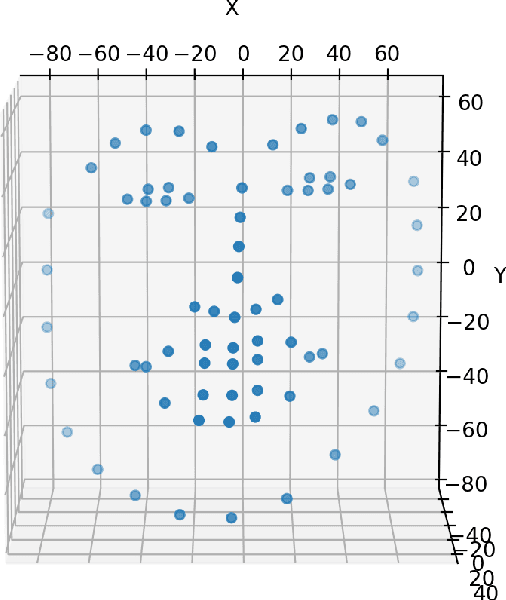
This research aims to make metaverse characters more realistic by adding lip animations learnt from videos in the wild. To achieve this, our approach is to extend Tacotron 2 text-to-speech synthesizer to generate lip movements together with mel spectrogram in one pass. The encoder and gate layer weights are pre-trained on LJ Speech 1.1 data set while the decoder is retrained on 93 clips of TED talk videos extracted from LRS 3 data set. Our novel decoder predicts displacement in 20 lip landmark positions across time, using labels automatically extracted by OpenFace 2.0 landmark predictor. Training converged in 7 hours using less than 5 minutes of video. We conducted ablation study for Pre/Post-Net and pre-trained encoder weights to demonstrate the effectiveness of transfer learning between audio and visual speech data.
Improving Dual-Microphone Speech Enhancement by Learning Cross-Channel Features with Multi-Head Attention
May 03, 2022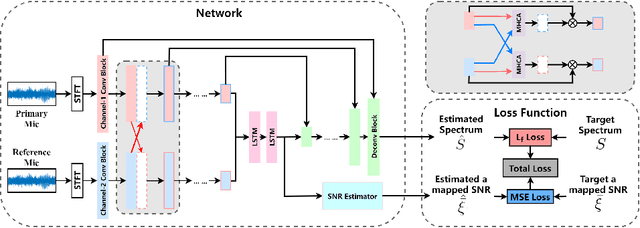
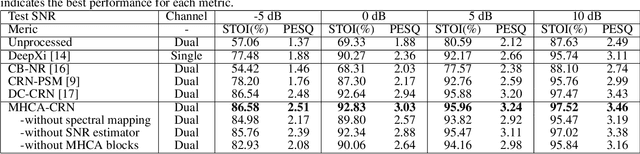
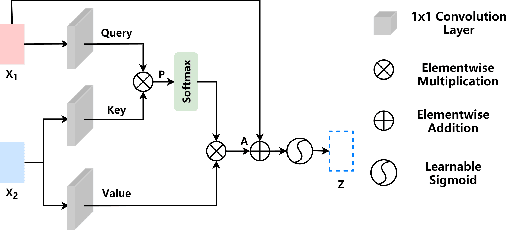
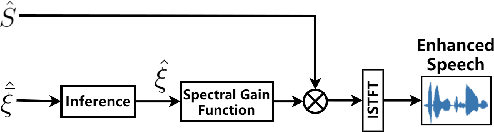
Hand-crafted spatial features, such as inter-channel intensity difference (IID) and inter-channel phase difference (IPD), play a fundamental role in recent deep learning based dual-microphone speech enhancement (DMSE) systems. However, learning the mutual relationship between artificially designed spatial and spectral features is hard in the end-to-end DMSE. In this work, a novel architecture for DMSE using a multi-head cross-attention based convolutional recurrent network (MHCA-CRN) is presented. The proposed MHCA-CRN model includes a channel-wise encoding structure for preserving intra-channel features and a multi-head cross-attention mechanism for fully exploiting cross-channel features. In addition, the proposed approach specifically formulates the decoder with an extra SNR estimator to estimate frame-level SNR under a multi-task learning framework, which is expected to avoid speech distortion led by end-to-end DMSE module. Finally, a spectral gain function is adopted to further suppress the unnatural residual noise. Experiment results demonstrated superior performance of the proposed model against several state-of-the-art models.
ConvNext Based Neural Network for Anti-Spoofing
Sep 15, 2022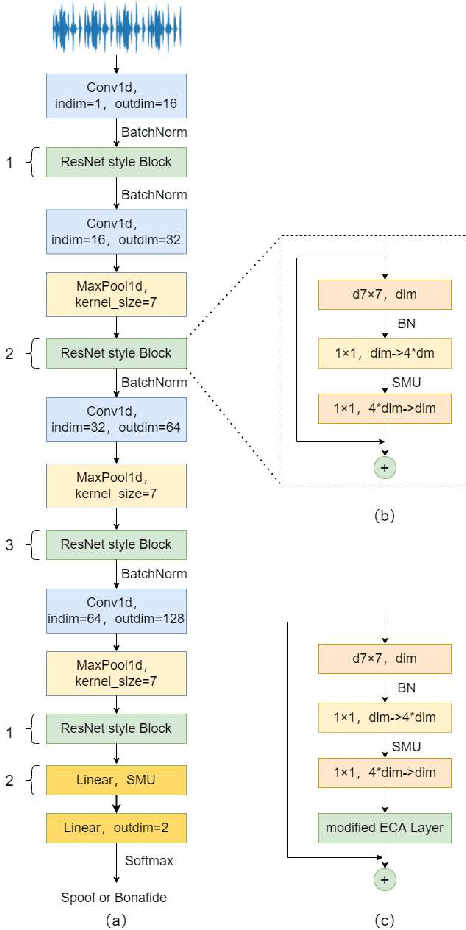
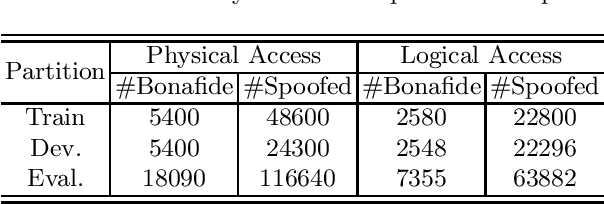
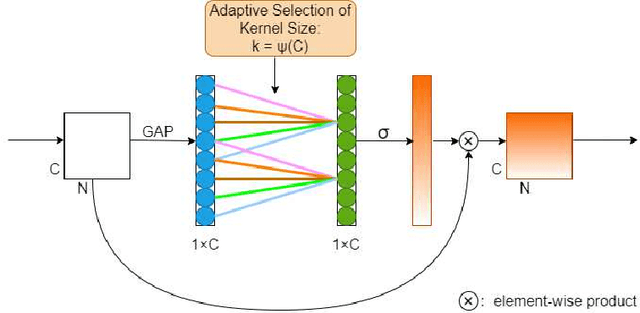
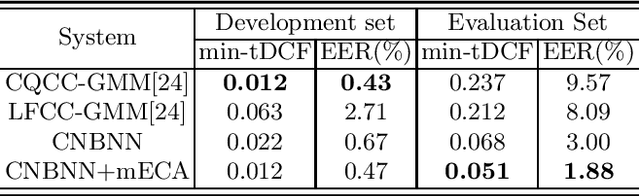
Automatic speaker verification (ASV) has been widely used in the real life for identity authentication. However, with the rapid development of speech conversion, speech synthesis algorithms and the improvement of the quality of recording devices, ASV systems are vulnerable for spoof attacks. In recent years, there have many works about synthetic and replay speech detection, researchers had proposed a number of anti-spoofing methods based on hand-crafted features to improve the accuracy and robustness of synthetic and replay speech detection system. However, using hand-crafted features rather than raw waveform would lose certain information for anti-spoofing, which will reduce the detection performance of the system. Inspired by the promising performance of ConvNext in image classification tasks, we extend the ConvNext network architecture accordingly for spoof attacks detection task and propose an end-to-end anti-spoofing model. By integrating the extended architecture with the channel attention block, the proposed model can focus on the most informative sub-bands of speech representations to improve the anti-spoofing performance. Experiments show that our proposed best single system could achieve an equal error rate of 1.88% and 2.79% for the ASVSpoof 2019 LA evaluation dataset and PA evaluation dataset respectively, which demonstrate the model's capacity for anti-spoofing.
Content-Dependent Fine-Grained Speaker Embedding for Zero-Shot Speaker Adaptation in Text-to-Speech Synthesis
Apr 03, 2022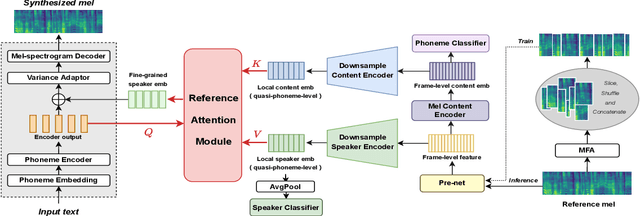
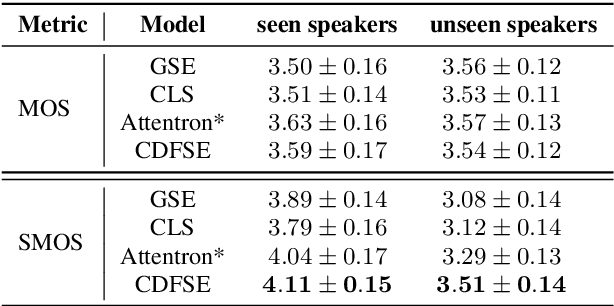
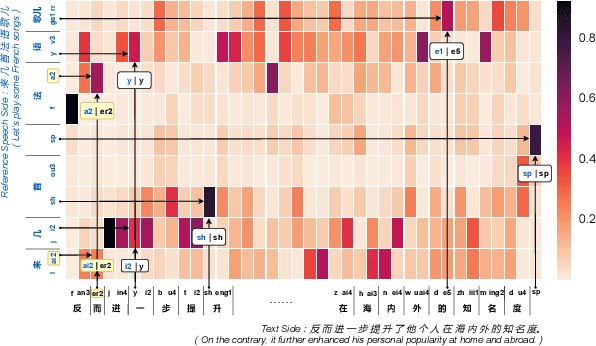
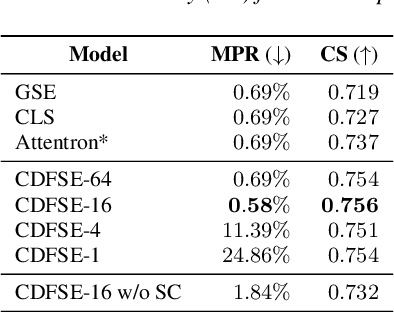
Zero-shot speaker adaptation aims to clone an unseen speaker's voice without any adaptation time and parameters. Previous researches usually use a speaker encoder to extract a global fixed speaker embedding from reference speech, and several attempts have tried variable-length speaker embedding. However, they neglect to transfer the personal pronunciation characteristics related to phoneme content, leading to poor speaker similarity in terms of detailed speaking styles and pronunciation habits. To improve the ability of the speaker encoder to model personal pronunciation characteristics, we propose content-dependent fine-grained speaker embedding for zero-shot speaker adaptation. The corresponding local content embeddings and speaker embeddings are extracted from a reference speech, respectively. Instead of modeling the temporal relations, a reference attention module is introduced to model the content relevance between the reference speech and the input text, and to generate the fine-grained speaker embedding for each phoneme encoder output. The experimental results show that our proposed method can improve speaker similarity of synthesized speeches, especially for unseen speakers.
Comparative Study of Speech Analysis Methods to Predict Parkinson's Disease
Nov 15, 2021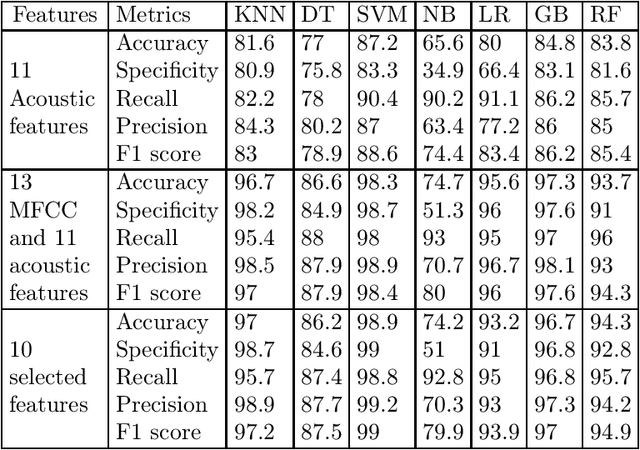
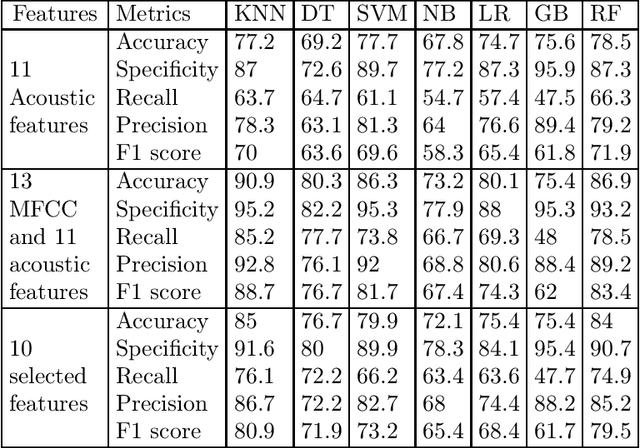
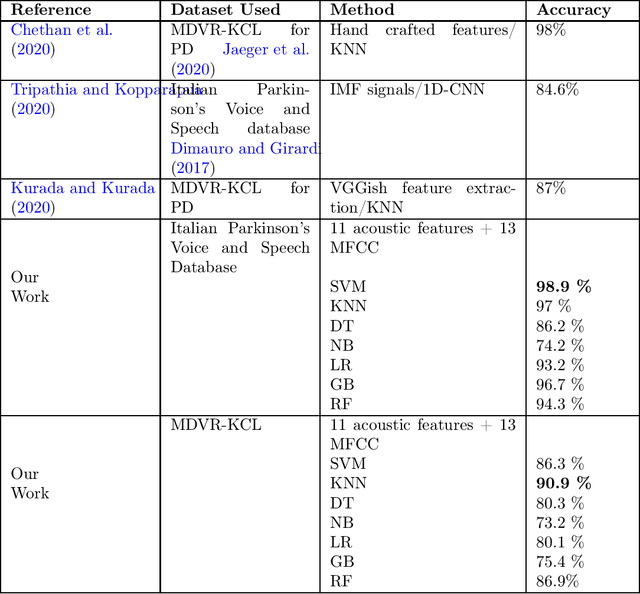
One of the symptoms observed in the early stages of Parkinson's Disease (PD) is speech impairment. Speech disorders can be used to detect this disease before it degenerates. This work analyzes speech features and machine learning approaches to predict PD. Acoustic features such as shimmer and jitter variants, and Mel Frequency Cepstral Coefficients (MFCC) are extracted from speech signals. We use two datasets in this work: the MDVR-KCL and the Italian Parkinson's Voice and Speech database. To separate PD and non-PD speech signals, seven classification models were implemented: K-Nearest Neighbor, Decision Trees, Support Vector Machines, Naive Bayes, Logistic Regression, Gradient Boosting, Random Forests. Three feature sets were used for each of the models: (a) Acoustic features only, (b) All the acoustic features and MFCC, (c) Selected subset of features from acoustic features and MFCC. Using all the acoustic features and MFCC, together with SVM produced the highest performance with an accuracy of 98% and F1-Score of 99%. When compared with prior art, this shows a better performance. Our code and related documentation is available in a public domain repository.
A CTC Triggered Siamese Network with Spatial-Temporal Dropout for Speech Recognition
Jun 22, 2022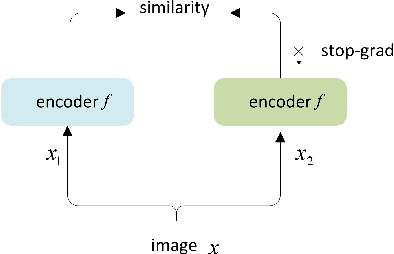
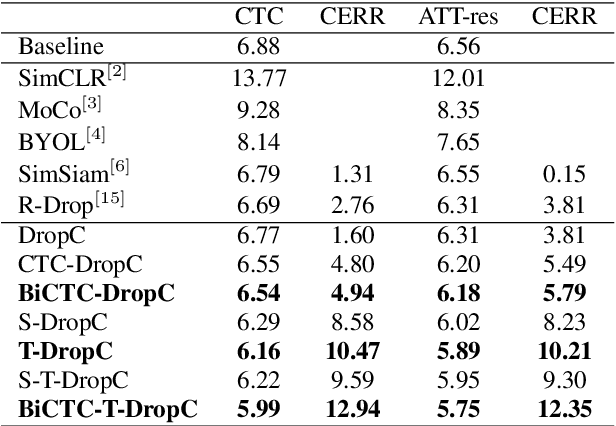
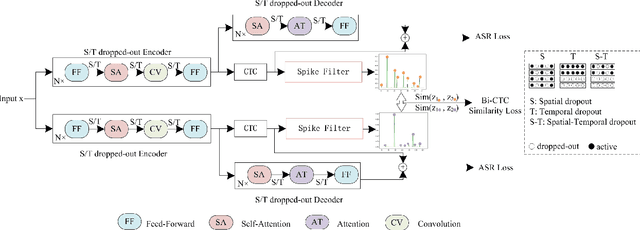
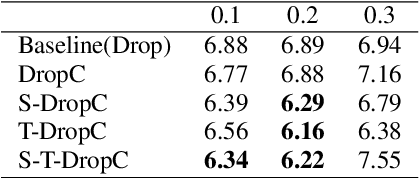
Siamese networks have shown effective results in unsupervised visual representation learning. These models are designed to learn an invariant representation of two augmentations for one input by maximizing their similarity. In this paper, we propose an effective Siamese network to improve the robustness of End-to-End automatic speech recognition (ASR). We introduce spatial-temporal dropout to support a more violent disturbance for Siamese-ASR framework. Besides, we also relax the similarity regularization to maximize the similarities of distributions on the frames that connectionist temporal classification (CTC) spikes occur rather than on all of them. The efficiency of the proposed architecture is evaluated on two benchmarks, AISHELL-1 and Librispeech, resulting in 7.13% and 6.59% relative character error rate (CER) and word error rate (WER) reductions respectively. Analysis shows that our proposed approach brings a better uniformity for the trained model and enlarges the CTC spikes obviously.
Training Integer-Only Deep Recurrent Neural Networks
Dec 22, 2022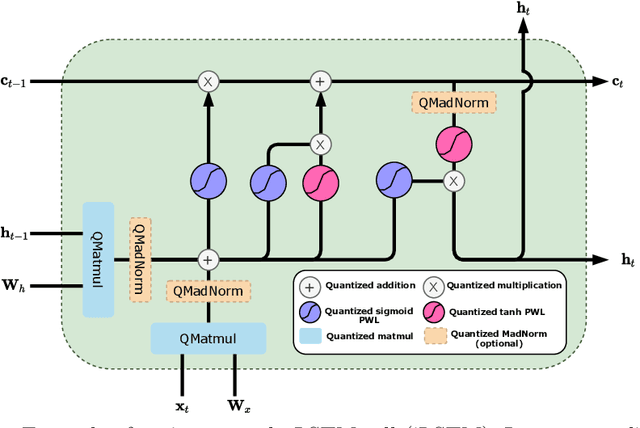

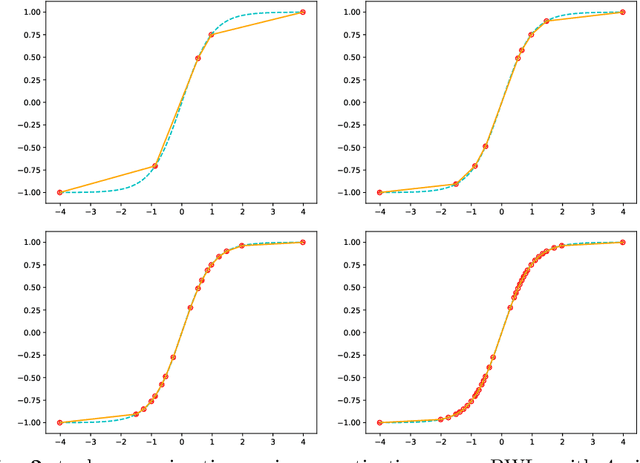

Recurrent neural networks (RNN) are the backbone of many text and speech applications. These architectures are typically made up of several computationally complex components such as; non-linear activation functions, normalization, bi-directional dependence and attention. In order to maintain good accuracy, these components are frequently run using full-precision floating-point computation, making them slow, inefficient and difficult to deploy on edge devices. In addition, the complex nature of these operations makes them challenging to quantize using standard quantization methods without a significant performance drop. We present a quantization-aware training method for obtaining a highly accurate integer-only recurrent neural network (iRNN). Our approach supports layer normalization, attention, and an adaptive piecewise linear (PWL) approximation of activation functions, to serve a wide range of state-of-the-art RNNs. The proposed method enables RNN-based language models to run on edge devices with $2\times$ improvement in runtime, and $4\times$ reduction in model size while maintaining similar accuracy as its full-precision counterpart.