 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
CycleGAN-Based Unpaired Speech Dereverberation
Mar 29, 2022
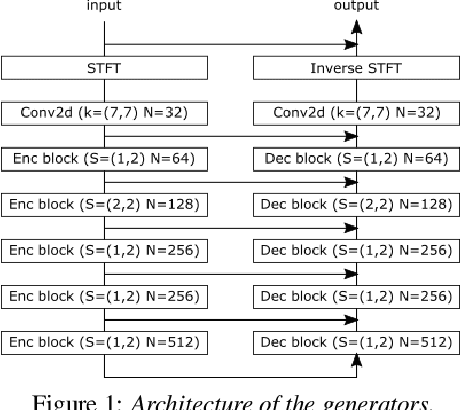

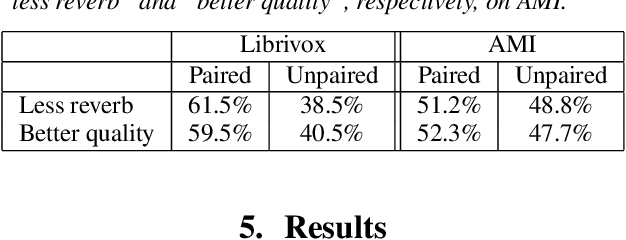
Typically, neural network-based speech dereverberation models are trained on paired data, composed of a dry utterance and its corresponding reverberant utterance. The main limitation of this approach is that such models can only be trained on large amounts of data and a variety of room impulse responses when the data is synthetically reverberated, since acquiring real paired data is costly. In this paper we propose a CycleGAN-based approach that enables dereverberation models to be trained on unpaired data. We quantify the impact of using unpaired data by comparing the proposed unpaired model to a paired model with the same architecture and trained on the paired version of the same dataset. We show that the performance of the unpaired model is comparable to the performance of the paired model on two different datasets, according to objective evaluation metrics. Furthermore, we run two subjective evaluations and show that both models achieve comparable subjective quality on the AMI dataset, which was not seen during training.
Tackling data scarcity in speech translation using zero-shot multilingual machine translation techniques
Jan 26, 2022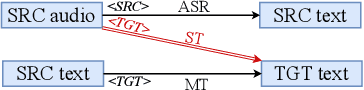
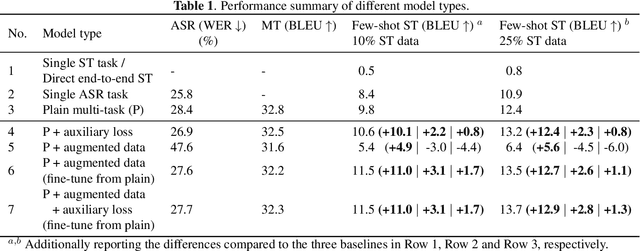
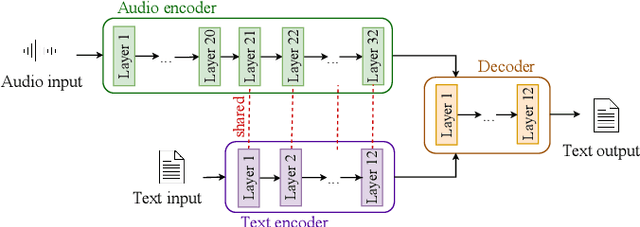

Recently, end-to-end speech translation (ST) has gained significant attention as it avoids error propagation. However, the approach suffers from data scarcity. It heavily depends on direct ST data and is less efficient in making use of speech transcription and text translation data, which is often more easily available. In the related field of multilingual text translation, several techniques have been proposed for zero-shot translation. A main idea is to increase the similarity of semantically similar sentences in different languages. We investigate whether these ideas can be applied to speech translation, by building ST models trained on speech transcription and text translation data. We investigate the effects of data augmentation and auxiliary loss function. The techniques were successfully applied to few-shot ST using limited ST data, with improvements of up to +12.9 BLEU points compared to direct end-to-end ST and +3.1 BLEU points compared to ST models fine-tuned from ASR model.
Speech Decomposition Based on a Hybrid Speech Model and Optimal Segmentation
May 04, 2021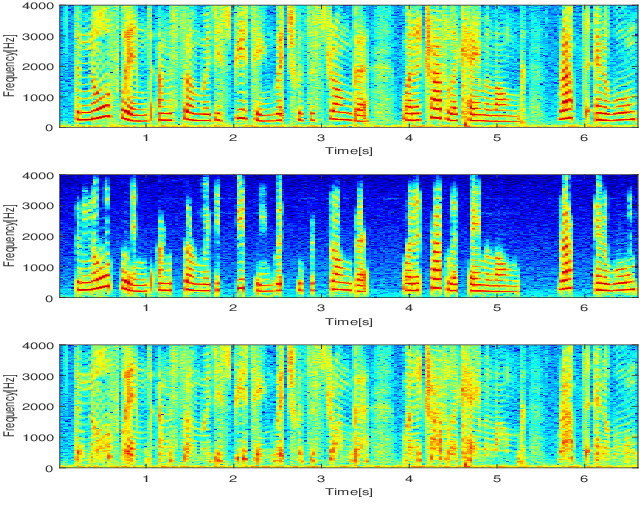
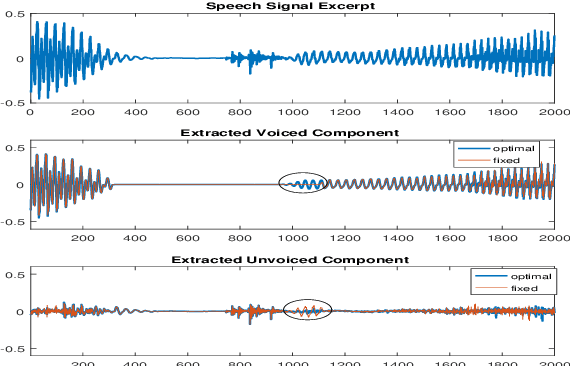
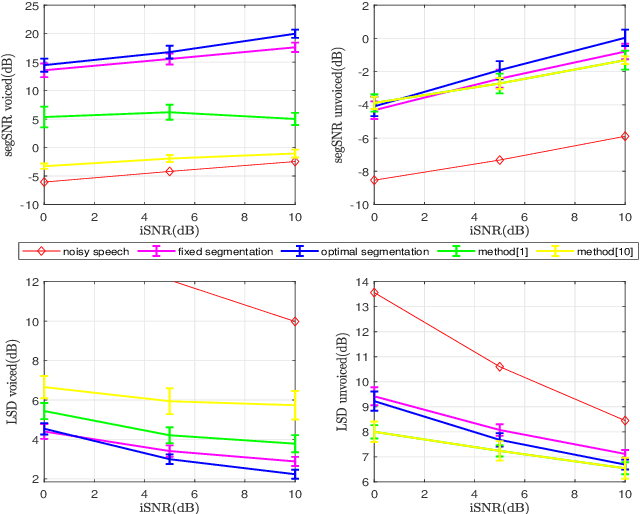
In a hybrid speech model, both voiced and unvoiced components can coexist in a segment. Often, the voiced speech is regarded as the deterministic component, and the unvoiced speech and additive noise are the stochastic components. Typically, the speech signal is considered stationary within fixed segments of 20-40 ms, but the degree of stationarity varies over time. For decomposing noisy speech into its voiced and unvoiced components, a fixed segmentation may be too crude, and we here propose to adapt the segment length according to the signal local characteristics. The segmentation relies on parameter estimates of a hybrid speech model and the maximum a posteriori (MAP) and log-likelihood criteria as rules for model selection among the possible segment lengths, for voiced and unvoiced speech, respectively. Given the optimal segmentation markers and the estimated statistics, both components are estimated using linear filtering. A codebook-based approach differentiates between unvoiced speech and noise. A better extraction of the components is possible by taking into account the adaptive segmentation, compared to a fixed one. Also, a lower distortion for voiced speech and higher segSNR for both components is possible, as compared to other decomposition methods.
Improved Meta Learning for Low Resource Speech Recognition
May 11, 2022
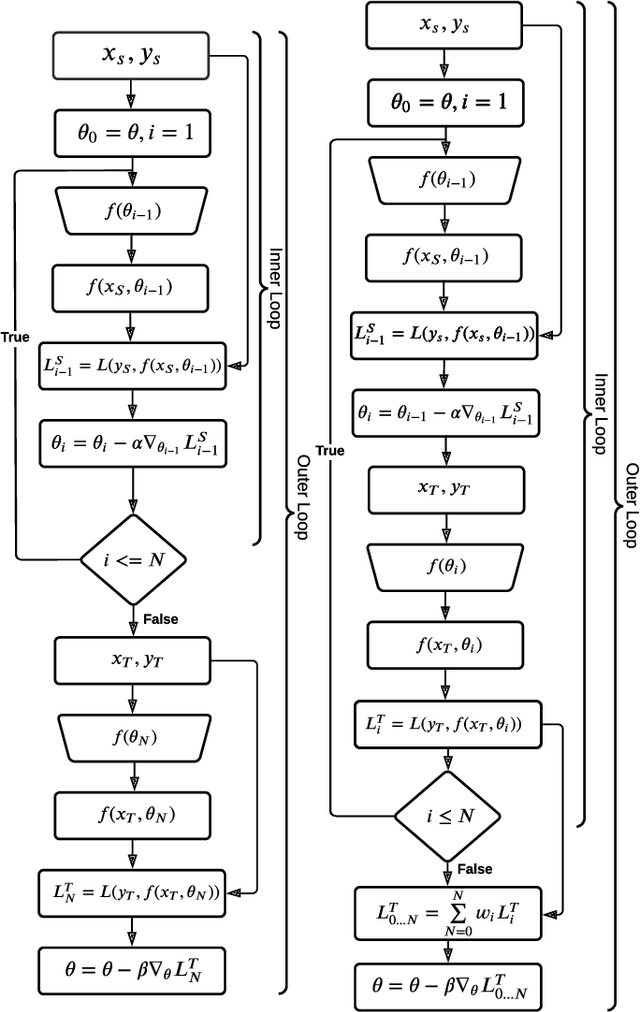

We propose a new meta learning based framework for low resource speech recognition that improves the previous model agnostic meta learning (MAML) approach. The MAML is a simple yet powerful meta learning approach. However, the MAML presents some core deficiencies such as training instabilities and slower convergence speed. To address these issues, we adopt multi-step loss (MSL). The MSL aims to calculate losses at every step of the inner loop of MAML and then combines them with a weighted importance vector. The importance vector ensures that the loss at the last step has more importance than the previous steps. Our empirical evaluation shows that MSL significantly improves the stability of the training procedure and it thus also improves the accuracy of the overall system. Our proposed system outperforms MAML based low resource ASR system on various languages in terms of character error rates and stable training behavior.
* Published in IEEE ICASSP 2022
Dubbing in Practice: A Large Scale Study of Human Localization With Insights for Automatic Dubbing
Dec 23, 2022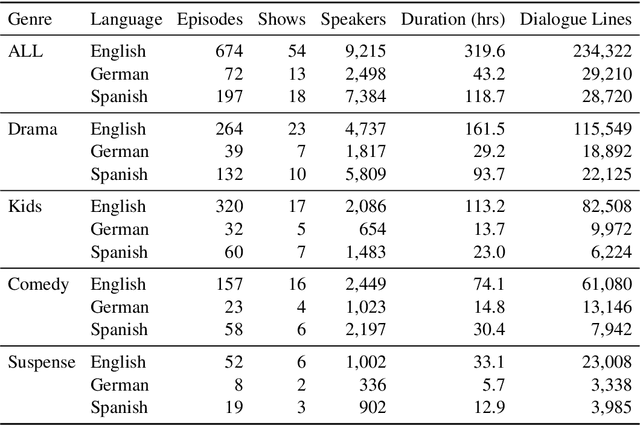
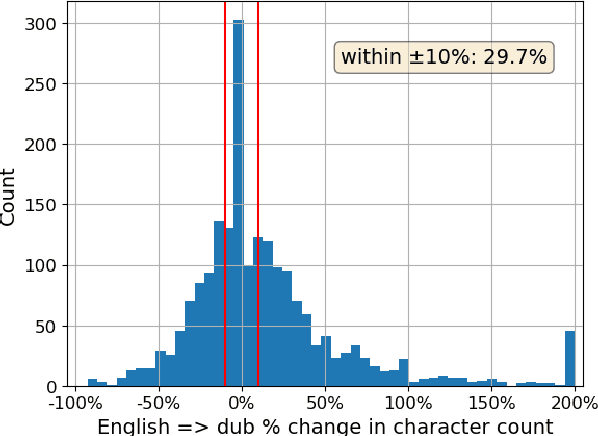
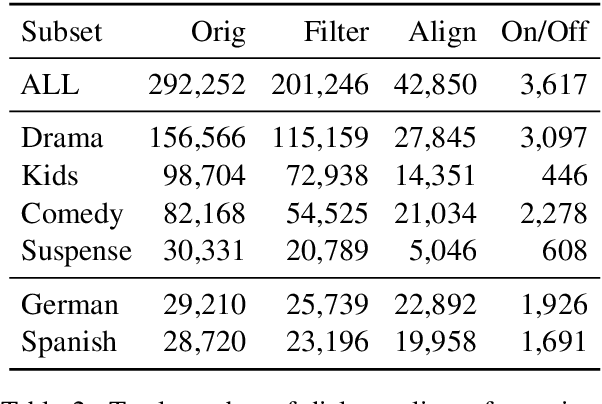
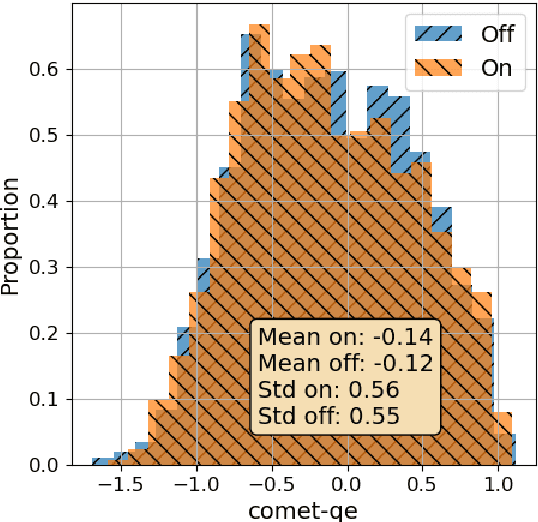
We investigate how humans perform the task of dubbing video content from one language into another, leveraging a novel corpus of 319.57 hours of video from 54 professionally produced titles. This is the first such large-scale study we are aware of. The results challenge a number of assumptions commonly made in both qualitative literature on human dubbing and machine-learning literature on automatic dubbing, arguing for the importance of vocal naturalness and translation quality over commonly emphasized isometric (character length) and lip-sync constraints, and for a more qualified view of the importance of isochronic (timing) constraints. We also find substantial influence of the source-side audio on human dubs through channels other than the words of the translation, pointing to the need for research on ways to preserve speech characteristics, as well as semantic transfer such as emphasis/emotion, in automatic dubbing systems.
Content-Dependent Fine-Grained Speaker Embedding for Zero-Shot Speaker Adaptation in Text-to-Speech Synthesis
Apr 03, 2022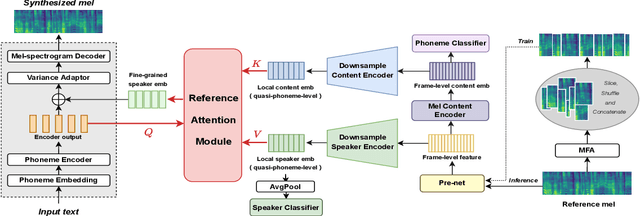
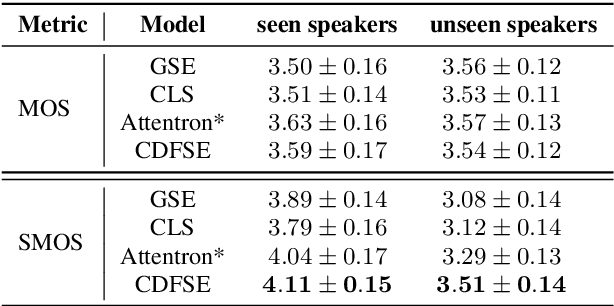
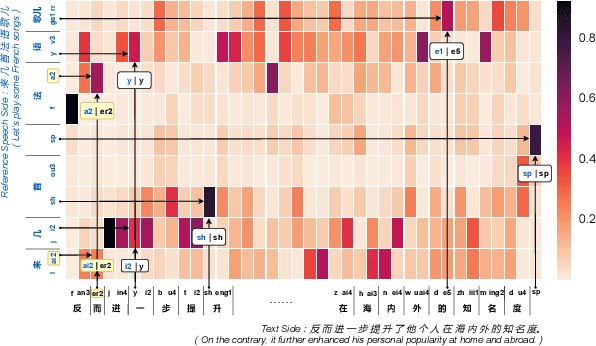
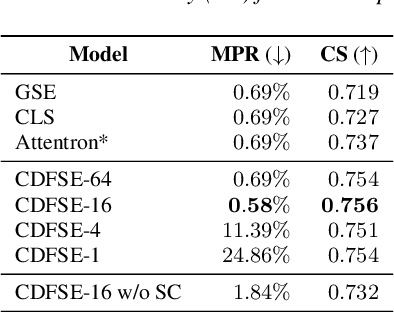
Zero-shot speaker adaptation aims to clone an unseen speaker's voice without any adaptation time and parameters. Previous researches usually use a speaker encoder to extract a global fixed speaker embedding from reference speech, and several attempts have tried variable-length speaker embedding. However, they neglect to transfer the personal pronunciation characteristics related to phoneme content, leading to poor speaker similarity in terms of detailed speaking styles and pronunciation habits. To improve the ability of the speaker encoder to model personal pronunciation characteristics, we propose content-dependent fine-grained speaker embedding for zero-shot speaker adaptation. The corresponding local content embeddings and speaker embeddings are extracted from a reference speech, respectively. Instead of modeling the temporal relations, a reference attention module is introduced to model the content relevance between the reference speech and the input text, and to generate the fine-grained speaker embedding for each phoneme encoder output. The experimental results show that our proposed method can improve speaker similarity of synthesized speeches, especially for unseen speakers.
Mutual Learning of Single- and Multi-Channel End-to-End Neural Diarization
Oct 07, 2022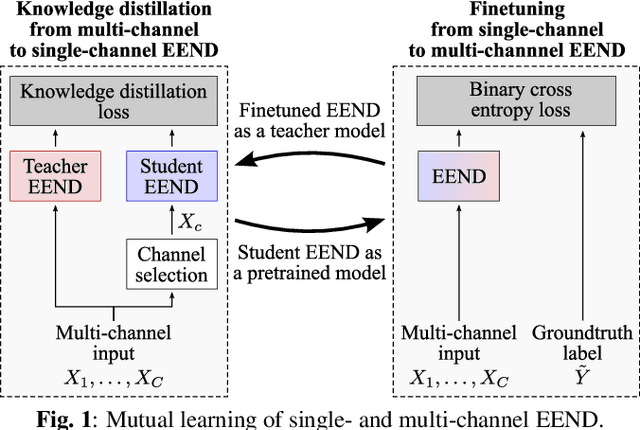
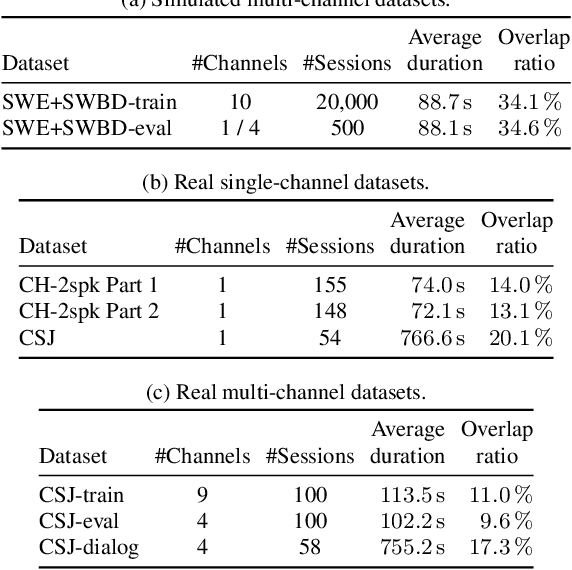
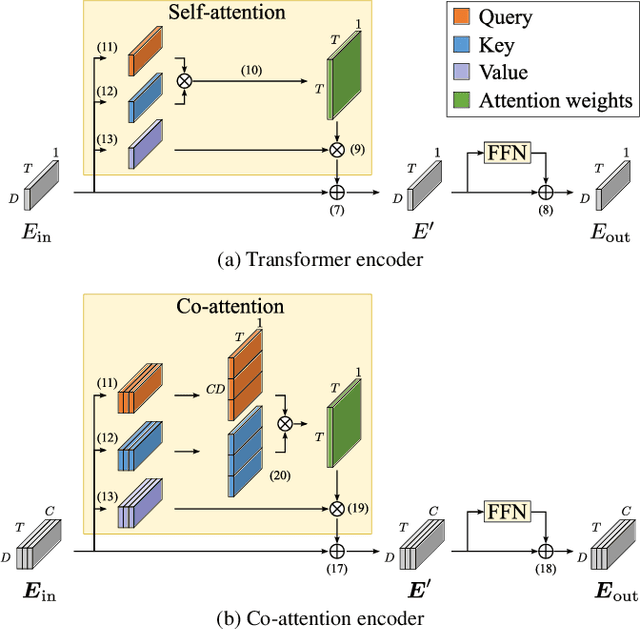
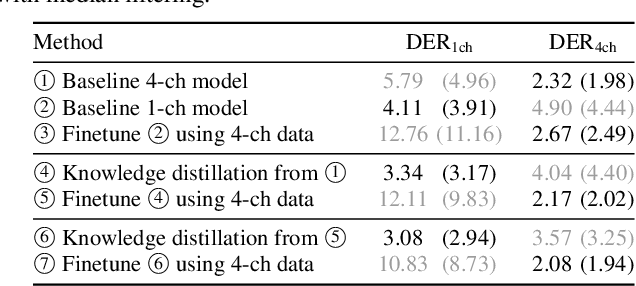
Due to the high performance of multi-channel speech processing, we can use the outputs from a multi-channel model as teacher labels when training a single-channel model with knowledge distillation. To the contrary, it is also known that single-channel speech data can benefit multi-channel models by mixing it with multi-channel speech data during training or by using it for model pretraining. This paper focuses on speaker diarization and proposes to conduct the above bi-directional knowledge transfer alternately. We first introduce an end-to-end neural diarization model that can handle both single- and multi-channel inputs. Using this model, we alternately conduct i) knowledge distillation from a multi-channel model to a single-channel model and ii) finetuning from the distilled single-channel model to a multi-channel model. Experimental results on two-speaker data show that the proposed method mutually improved single- and multi-channel speaker diarization performances.
Improving Dual-Microphone Speech Enhancement by Learning Cross-Channel Features with Multi-Head Attention
May 03, 2022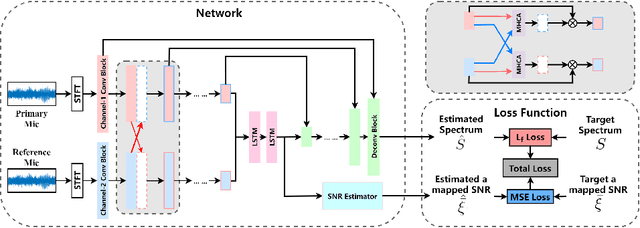
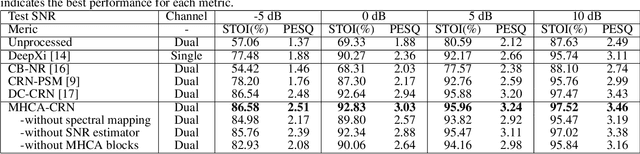
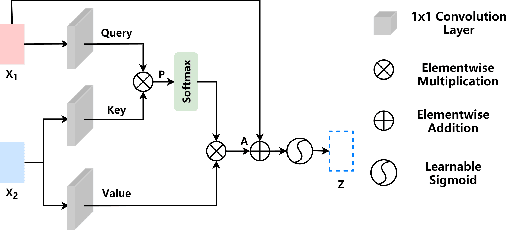
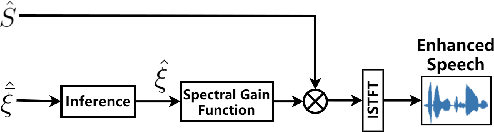
Hand-crafted spatial features, such as inter-channel intensity difference (IID) and inter-channel phase difference (IPD), play a fundamental role in recent deep learning based dual-microphone speech enhancement (DMSE) systems. However, learning the mutual relationship between artificially designed spatial and spectral features is hard in the end-to-end DMSE. In this work, a novel architecture for DMSE using a multi-head cross-attention based convolutional recurrent network (MHCA-CRN) is presented. The proposed MHCA-CRN model includes a channel-wise encoding structure for preserving intra-channel features and a multi-head cross-attention mechanism for fully exploiting cross-channel features. In addition, the proposed approach specifically formulates the decoder with an extra SNR estimator to estimate frame-level SNR under a multi-task learning framework, which is expected to avoid speech distortion led by end-to-end DMSE module. Finally, a spectral gain function is adopted to further suppress the unnatural residual noise. Experiment results demonstrated superior performance of the proposed model against several state-of-the-art models.
Are disentangled representations all you need to build speaker anonymization systems?
Aug 24, 2022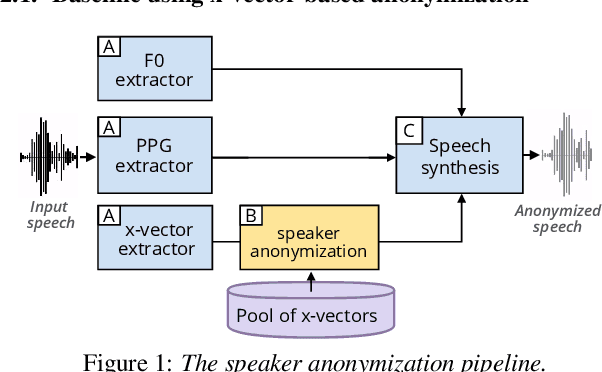
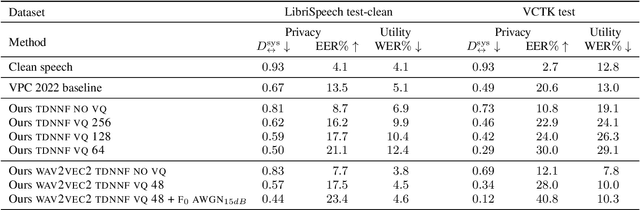
Speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns when speech data get collected. Speaker anonymization aims to transform a speech signal to remove the source speaker's identity while leaving the spoken content unchanged. Current methods perform the transformation by relying on content/speaker disentanglement and voice conversion. Usually, an acoustic model from an automatic speech recognition system extracts the content representation while an x-vector system extracts the speaker representation. Prior work has shown that the extracted features are not perfectly disentangled. This paper tackles how to improve features disentanglement, and thus the converted anonymized speech. We propose enhancing the disentanglement by removing speaker information from the acoustic model using vector quantization. Evaluation done using the VoicePrivacy 2022 toolkit showed that vector quantization helps conceal the original speaker identity while maintaining utility for speech recognition.
Selecting and combining complementary feature representations and classifiers for hate speech detection
Jan 18, 2022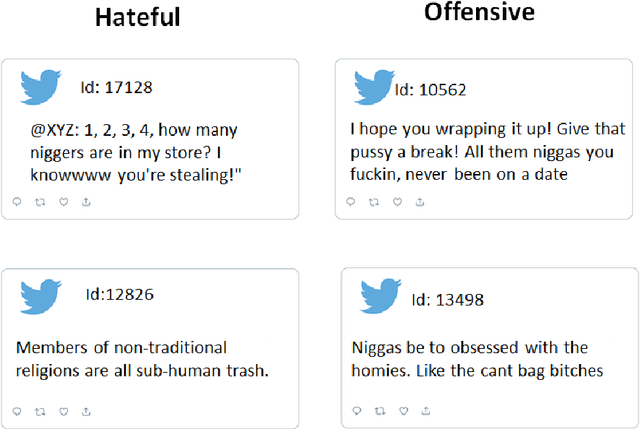
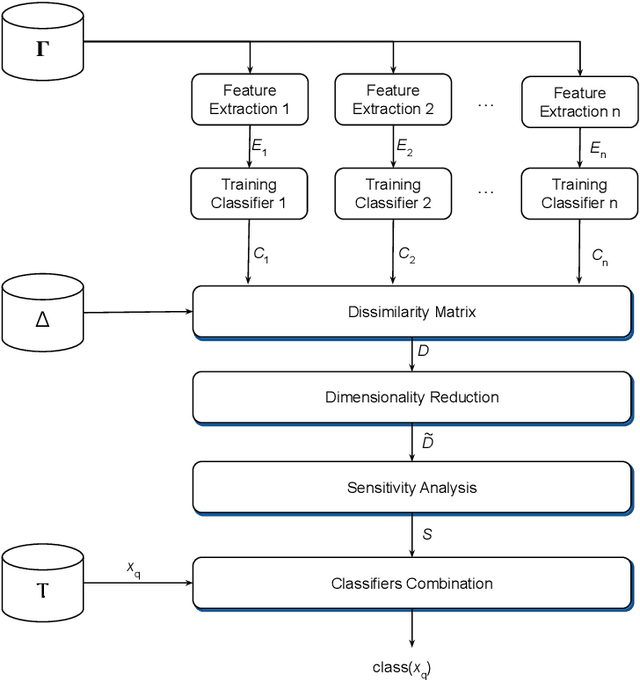
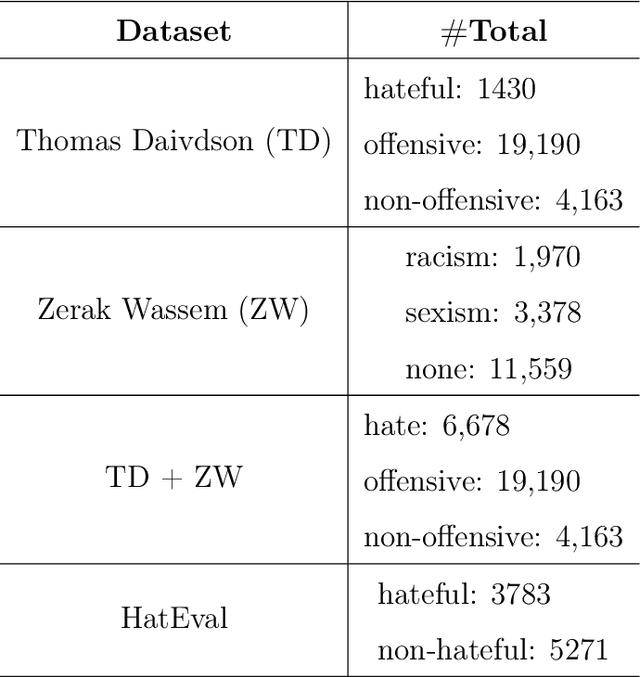

Hate speech is a major issue in social networks due to the high volume of data generated daily. Recent works demonstrate the usefulness of machine learning (ML) in dealing with the nuances required to distinguish between hateful posts from just sarcasm or offensive language. Many ML solutions for hate speech detection have been proposed by either changing how features are extracted from the text or the classification algorithm employed. However, most works consider only one type of feature extraction and classification algorithm. This work argues that a combination of multiple feature extraction techniques and different classification models is needed. We propose a framework to analyze the relationship between multiple feature extraction and classification techniques to understand how they complement each other. The framework is used to select a subset of complementary techniques to compose a robust multiple classifiers system (MCS) for hate speech detection. The experimental study considering four hate speech classification datasets demonstrates that the proposed framework is a promising methodology for analyzing and designing high-performing MCS for this task. MCS system obtained using the proposed framework significantly outperforms the combination of all models and the homogeneous and heterogeneous selection heuristics, demonstrating the importance of having a proper selection scheme. Source code, figures, and dataset splits can be found in the GitHub repository: https://github.com/Menelau/Hate-Speech-MCS.