 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speaker Embedding-aware Neural Diarization: an Efficient Framework for Overlapping Speech Diarization in Meeting Scenarios
Mar 31, 2022
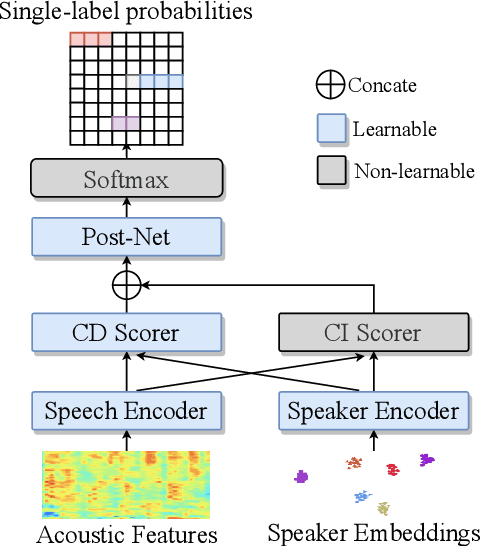
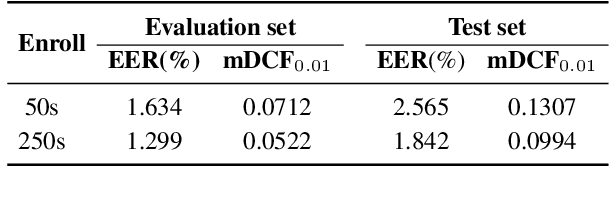
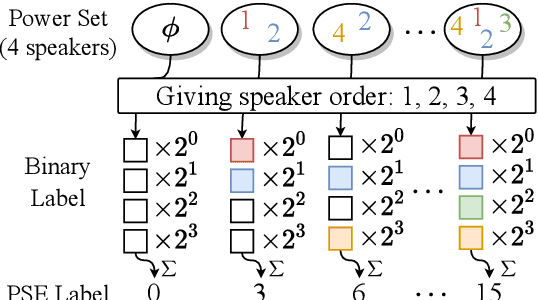
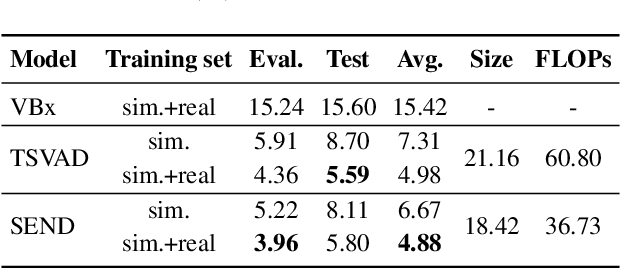
Overlapping speech diarization has been traditionally treated as a multi-label classification problem. In this paper, we reformulate this task as a single-label prediction problem by encoding multiple binary labels into a single label with the power set, which represents the possible combinations of target speakers. This formulation has two benefits. First, the overlaps of target speakers are explicitly modeled. Second, threshold selection is no longer needed. Through this formulation, we propose the speaker embedding-aware neural diarization (SEND) framework, where a speech encoder, a speaker encoder, two similarity scorers, and a post-processing network are jointly optimized to predict the encoded labels according to the similarities between speech features and speaker embeddings. Experimental results show that SEND has a stable learning process and can be trained on highly overlapped data without extra initialization. More importantly, our method achieves the state-of-the-art performance in real meeting scenarios with fewer model parameters and lower computational complexity.
U-shaped Transformer with Frequency-Band Aware Attention for Speech Enhancement
Dec 11, 2021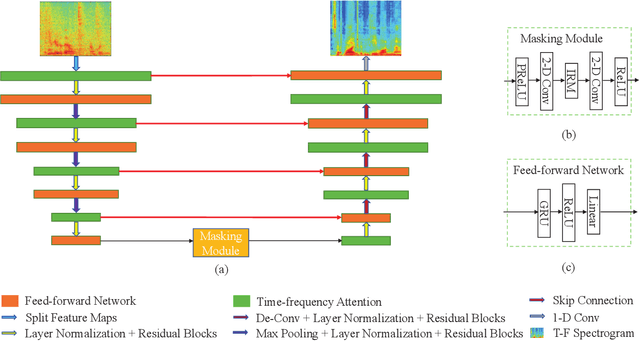
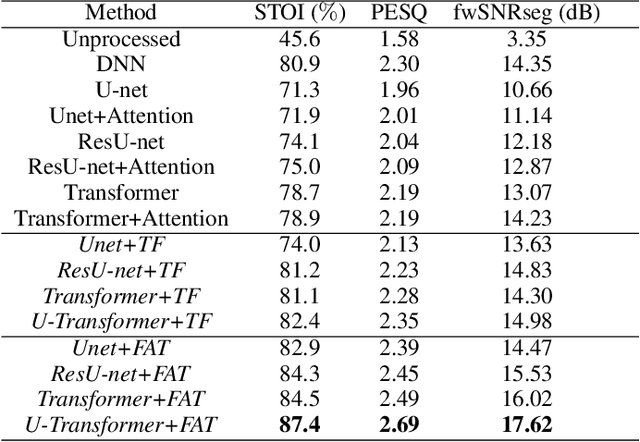
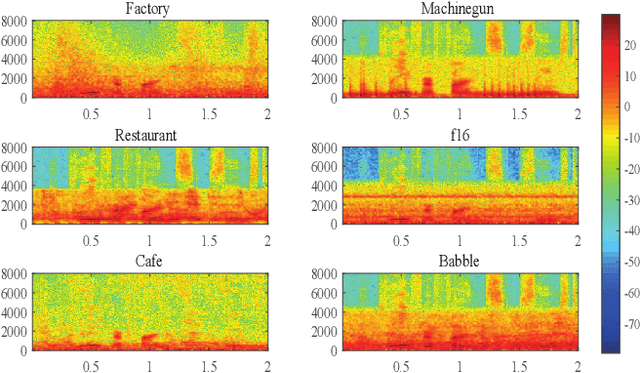
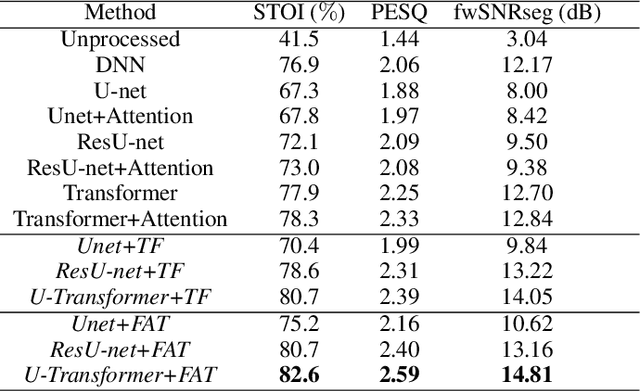
The state-of-the-art speech enhancement has limited performance in speech estimation accuracy. Recently, in deep learning, the Transformer shows the potential to exploit the long-range dependency in speech by self-attention. Therefore, it is introduced in speech enhancement to improve the speech estimation accuracy from a noise mixture. However, to address the computational cost issue in Transformer with self-attention, the axial attention is the option i.e., to split a 2D attention into two 1D attentions. Inspired by the axial attention, in the proposed method we calculate the attention map along both time- and frequency-axis to generate time and frequency sub-attention maps. Moreover, different from the axial attention, the proposed method provides two parallel multi-head attentions for time- and frequency-axis. Furthermore, it is proven in the literature that the lower frequency-band in speech, generally, contains more desired information than the higher frequency-band, in a noise mixture. Therefore, the frequency-band aware attention is proposed i.e., high frequency-band attention (HFA), and low frequency-band attention (LFA). The U-shaped Transformer is also first time introduced in the proposed method to further improve the speech estimation accuracy. The extensive evaluations over four public datasets, confirm the efficacy of the proposed method.
Predicting score distribution to improve non-intrusive speech quality estimation
Apr 13, 2022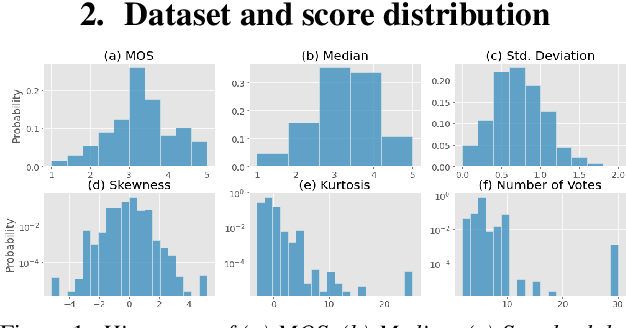
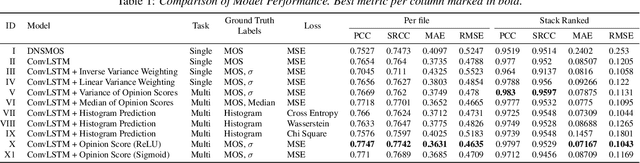
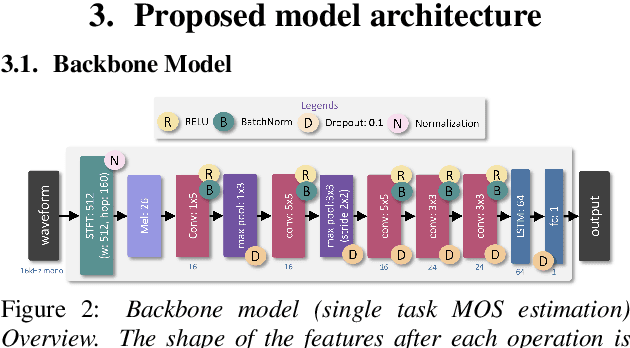
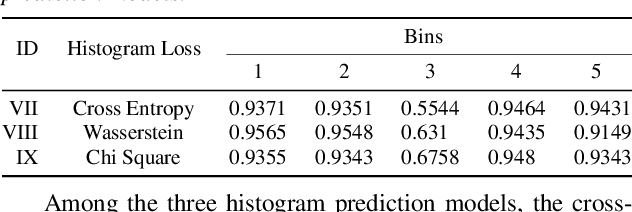
Deep noise suppressors (DNS) have become an attractive solution to remove background noise, reverberation, and distortions from speech and are widely used in telephony/voice applications. They are also occasionally prone to introducing artifacts and lowering the perceptual quality of the speech. Subjective listening tests that use multiple human judges to derive a mean opinion score (MOS) are a popular way to measure these models' performance. Deep neural network based non-intrusive MOS estimation models have recently emerged as a popular cost-efficient alternative to these tests. These models are trained with only the MOS labels, often discarding the secondary statistics of the opinion scores. In this paper, we investigate several ways to integrate the distribution of opinion scores (e.g. variance, histogram information) to improve the MOS estimation performance. Our model is trained on a corpus of 419K denoised samples by 320 different DNS models and model variations and evaluated on 18K test samples from DNSMOS. We show that with very minor modification of a single task MOS estimation pipeline, these freely available labels can provide up to a 0.016 RMSE and 1% SRCC improvement.
Can we still use PEAQ? A Performance Analysis of the ITU Standard for the Objective Assessment of Perceived Audio Quality
Dec 02, 2022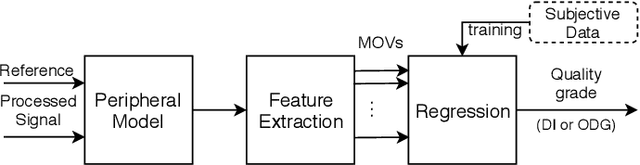
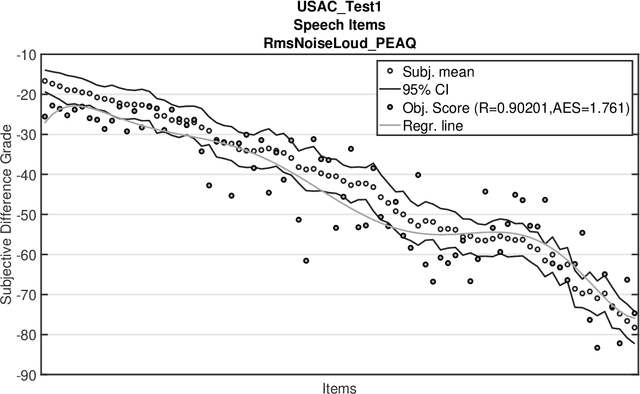
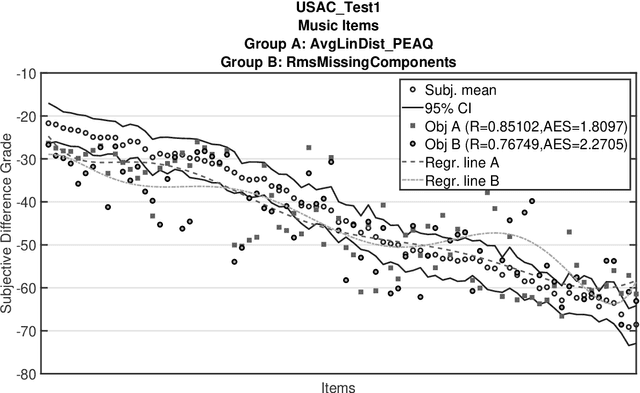
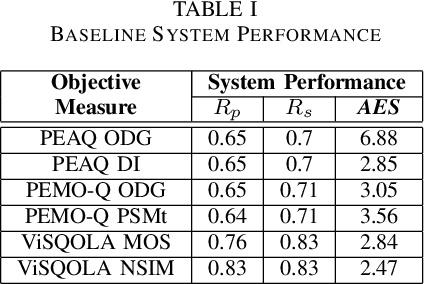
The Perceptual Evaluation of Audio Quality (PEAQ) method as described in the International Telecommunication Union (ITU) recommendation ITU-R BS.1387 has been widely used for computationally estimating the quality of perceptually coded audio signals without the need for extensive subjective listening tests. However, many reports have highlighted clear limitations of the scheme after the end of its standardization, particularly involving signals coded with newer technologies such as bandwidth extension or parametric multi-channel coding. Until now, no other method for measuring the quality of both speech and audio signals has been standardized by the ITU. Therefore, a further investigation of the causes for these limitations would be beneficial to a possible update of said scheme. Our experimental results indicate that the performance of PEAQ's model of disturbance loudness is still as good as (and sometimes superior to) other state-of-the-art objective measures, albeit with varying performance depending on the type of degraded signal content (i.e. speech or music). This finding evidences the need for an improved cognitive model. In addition, results indicate that an updated mapping of Model Output Values (MOVs) to PEAQ's Distortion Index (DI) based on newer training data can greatly improve performance. Finally, some suggestions for the improvement of PEAQ are provided based on the reported results and comparison to other systems.
* Accepter manuscript for 2020 Twelfth International Conference on Quality of Multimedia Experience (QoMEX 2020)
SOMOS: The Samsung Open MOS Dataset for the Evaluation of Neural Text-to-Speech Synthesis
Apr 06, 2022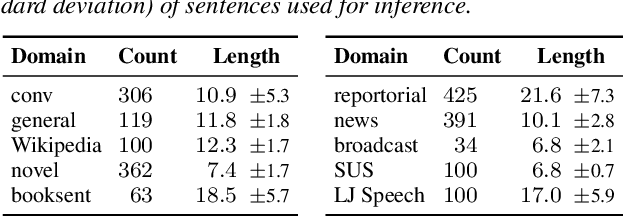
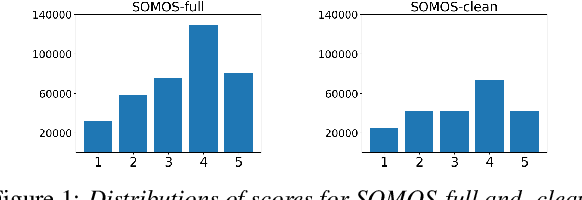
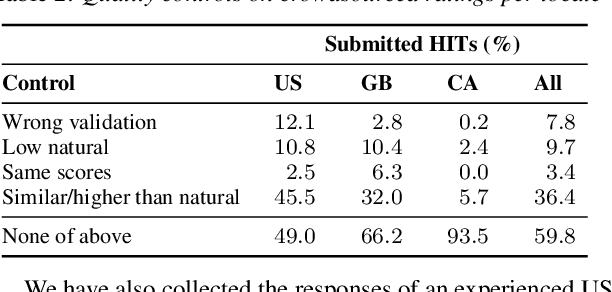
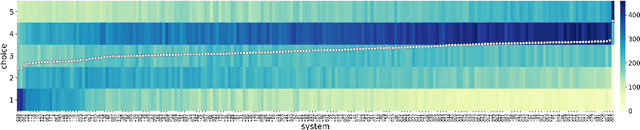
In this work, we present the SOMOS dataset, the first large-scale mean opinion scores (MOS) dataset consisting of solely neural text-to-speech (TTS) samples. It can be employed to train automatic MOS prediction systems focused on the assessment of modern synthesizers, and can stimulate advancements in acoustic model evaluation. It consists of 20K synthetic utterances of the LJ Speech voice, a public domain speech dataset which is a common benchmark for building neural acoustic models and vocoders. Utterances are generated from 200 TTS systems including vanilla neural acoustic models as well as models which allow prosodic variations. An LPCNet vocoder is used for all systems, so that the samples' variation depends only on the acoustic models. The synthesized utterances provide balanced and adequate domain and length coverage. We collect MOS naturalness evaluations on 3 English Amazon Mechanical Turk locales and share practices leading to reliable crowdsourced annotations for this task. Baseline results of state-of-the-art MOS prediction models on the SOMOS dataset are presented, while we show the challenges that such models face when assigned to evaluate synthetic utterances.
Speech and the n-Back task as a lens into depression. How combining both may allow us to isolate different core symptoms of depression
Mar 30, 2022
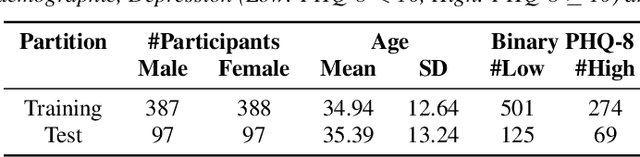
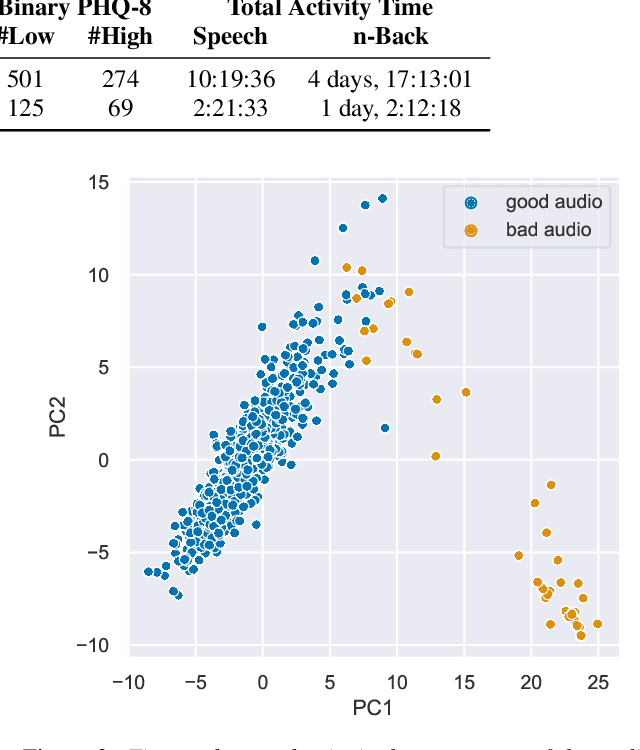
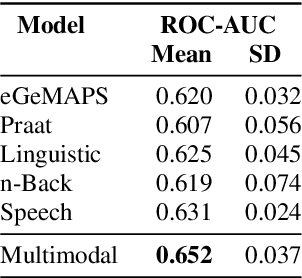
Embedded in any speech signal is a rich combination of cognitive, neuromuscular and physiological information. This richness makes speech a powerful signal in relation to a range of different health conditions, including major depressive disorders (MDD). One pivotal issue in speech-depression research is the assumption that depressive severity is the dominant measurable effect. However, given the heterogeneous clinical profile of MDD, it may actually be the case that speech alterations are more strongly associated with subsets of key depression symptoms. This paper presents strong evidence in support of this argument. First, we present a novel large, cross-sectional, multi-modal dataset collected at Thymia. We then present a set of machine learning experiments that demonstrate that combining speech with features from an n-Back working memory assessment improves classifier performance when predicting the popular eight-item Patient Health Questionnaire depression scale (PHQ-8). Finally, we present a set of experiments that highlight the association between different speech and n-Back markers at the PHQ-8 item level. Specifically, we observe that somatic and psychomotor symptoms are more strongly associated with n-Back performance scores, whilst the other items: anhedonia, depressed mood, change in appetite, feelings of worthlessness and trouble concentrating are more strongly associated with speech changes.
Text Enhancement for Paragraph Processing in End-to-End Code-switching TTS
Oct 20, 2022Current end-to-end code-switching Text-to-Speech (TTS) can already generate high quality two languages speech in the same utterance with single speaker bilingual corpora. When the speakers of the bilingual corpora are different, the naturalness and consistency of the code-switching TTS will be poor. The cross-lingual embedding layers structure we proposed makes similar syllables in different languages relevant, thus improving the naturalness and consistency of generated speech. In the end-to-end code-switching TTS, there exists problem of prosody instability when synthesizing paragraph text. The text enhancement method we proposed makes the input contain prosodic information and sentence-level context information, thus improving the prosody stability of paragraph text. Experimental results demonstrate the effectiveness of the proposed methods in the naturalness, consistency, and prosody stability. In addition to Mandarin and English, we also apply these methods to Shanghaiese and Cantonese corpora, proving that the methods we proposed can be extended to other languages to build end-to-end code-switching TTS system.
EEG-Transformer: Self-attention from Transformer Architecture for Decoding EEG of Imagined Speech
Dec 15, 2021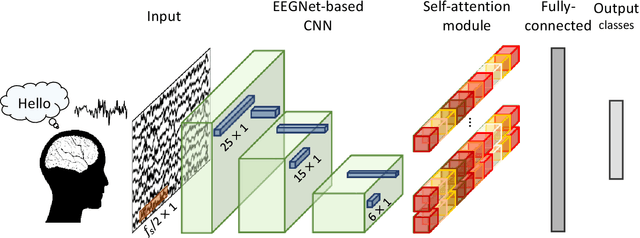
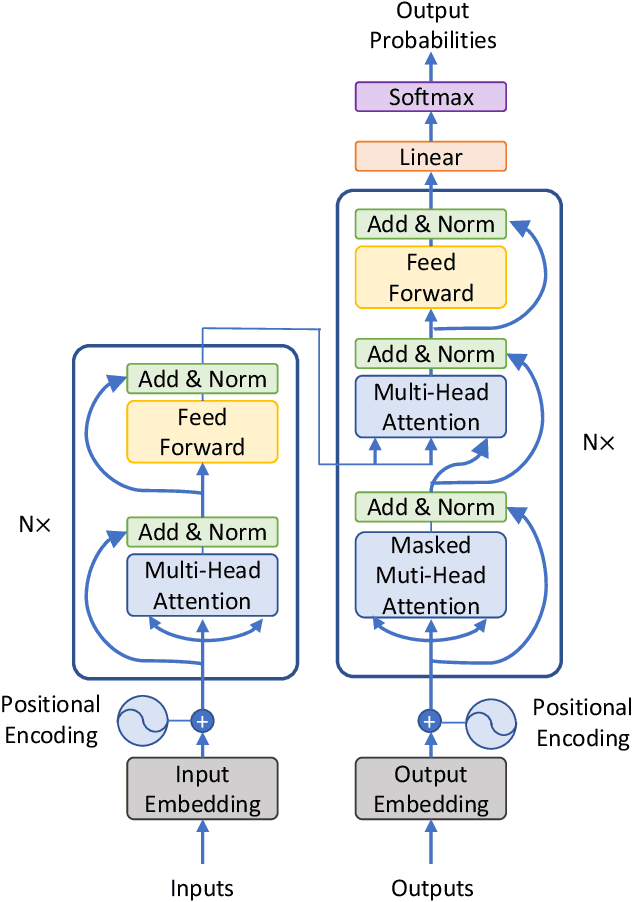
Transformers are groundbreaking architectures that have changed a flow of deep learning, and many high-performance models are developing based on transformer architectures. Transformers implemented only with attention with encoder-decoder structure following seq2seq without using RNN, but had better performance than RNN. Herein, we investigate the decoding technique for electroencephalography (EEG) composed of self-attention module from transformer architecture during imagined speech and overt speech. We performed classification of nine subjects using convolutional neural network based on EEGNet that captures temporal-spectral-spatial features from EEG of imagined speech and overt speech. Furthermore, we applied the self-attention module to decoding EEG to improve the performance and lower the number of parameters. Our results demonstrate the possibility of decoding brain activities of imagined speech and overt speech using attention modules. Also, only single channel EEG or ear-EEG can be used to decode the imagined speech for practical BCIs.
Confidence Score Based Conformer Speaker Adaptation for Speech Recognition
Jun 24, 2022
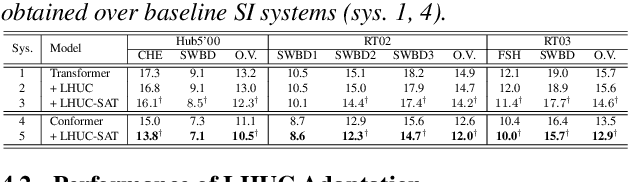
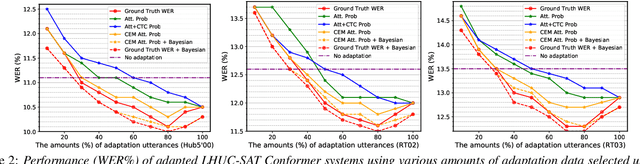

A key challenge for automatic speech recognition (ASR) systems is to model the speaker level variability. In this paper, compact speaker dependent learning hidden unit contributions (LHUC) are used to facilitate both speaker adaptive training (SAT) and test time unsupervised speaker adaptation for state-of-the-art Conformer based end-to-end ASR systems. The sensitivity during adaptation to supervision error rate is reduced using confidence score based selection of the more "trustworthy" subset of speaker specific data. A confidence estimation module is used to smooth the over-confident Conformer decoder output probabilities before serving as confidence scores. The increased data sparsity due to speaker level data selection is addressed using Bayesian estimation of LHUC parameters. Experiments on the 300-hour Switchboard corpus suggest that the proposed LHUC-SAT Conformer with confidence score based test time unsupervised adaptation outperformed the baseline speaker independent and i-vector adapted Conformer systems by up to 1.0%, 1.0%, and 1.2% absolute (9.0%, 7.9%, and 8.9% relative) word error rate (WER) reductions on the NIST Hub5'00, RT02, and RT03 evaluation sets respectively. Consistent performance improvements were retained after external Transformer and LSTM language models were used for rescoring.
EMGSE: Acoustic/EMG Fusion for Multimodal Speech Enhancement
Feb 14, 2022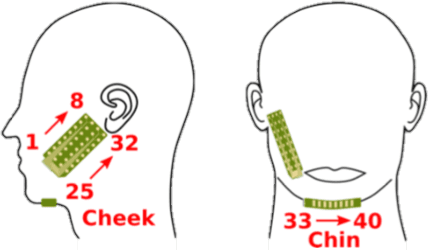
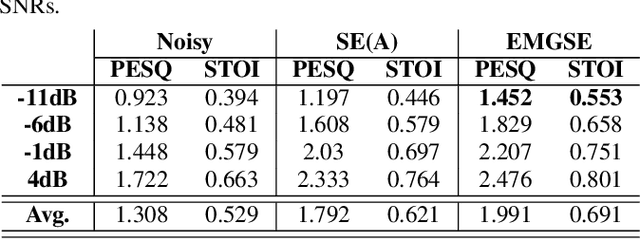
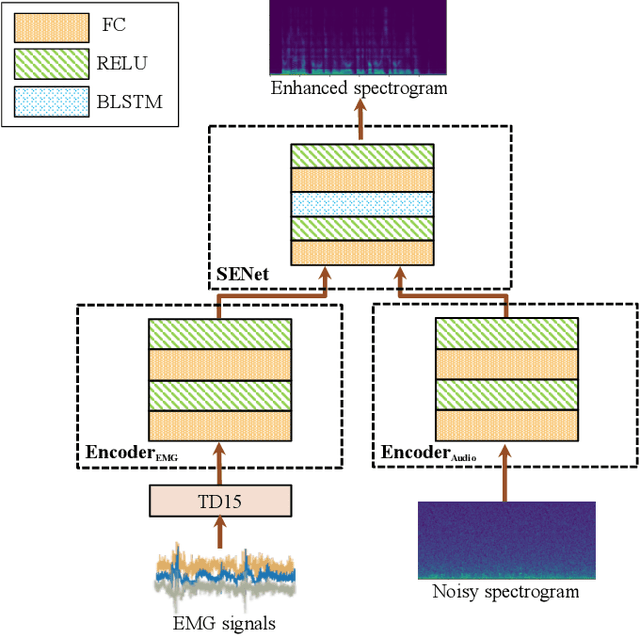
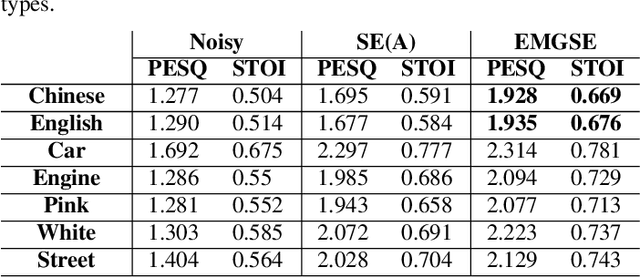
Multimodal learning has been proven to be an effective method to improve speech enhancement (SE) performance, especially in challenging situations such as low signal-to-noise ratios, speech noise, or unseen noise types. In previous studies, several types of auxiliary data have been used to construct multimodal SE systems, such as lip images, electropalatography, or electromagnetic midsagittal articulography. In this paper, we propose a novel EMGSE framework for multimodal SE, which integrates audio and facial electromyography (EMG) signals. Facial EMG is a biological signal containing articulatory movement information, which can be measured in a non-invasive way. Experimental results show that the proposed EMGSE system can achieve better performance than the audio-only SE system. The benefits of fusing EMG signals with acoustic signals for SE are notable under challenging circumstances. Furthermore, this study reveals that cheek EMG is sufficient for SE.