 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Graph Isomorphism Network with Weighted Multiple Aggregators for Speech Emotion Recognition
Jul 03, 2022
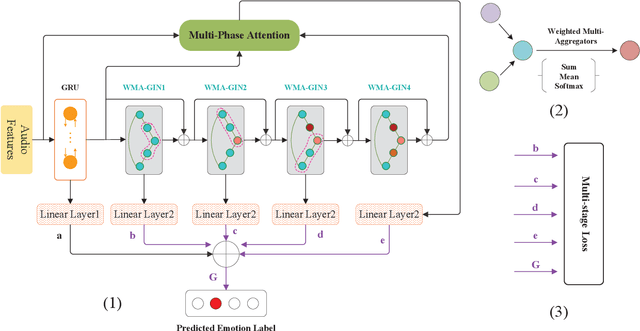

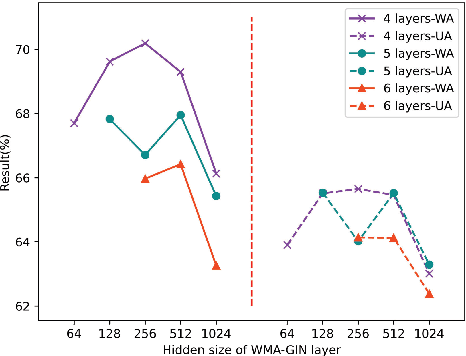
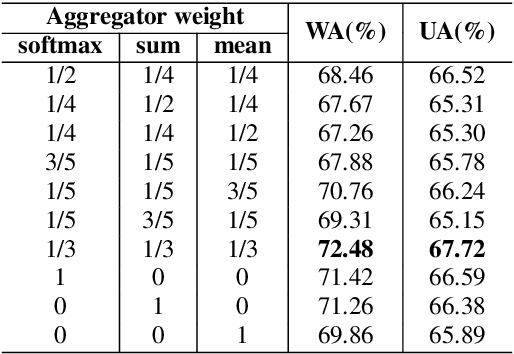
Speech emotion recognition (SER) is an essential part of human-computer interaction. In this paper, we propose an SER network based on a Graph Isomorphism Network with Weighted Multiple Aggregators (WMA-GIN), which can effectively handle the problem of information confusion when neighbour nodes' features are aggregated together in GIN structure. Moreover, a Full-Adjacent (FA) layer is adopted for alleviating the over-squashing problem, which is existed in all Graph Neural Network (GNN) structures, including GIN. Furthermore, a multi-phase attention mechanism and multi-loss training strategy are employed to avoid missing the useful emotional information in the stacked WMA-GIN layers. We evaluated the performance of our proposed WMA-GIN on the popular IEMOCAP dataset. The experimental results show that WMA-GIN outperforms other GNN-based methods and is comparable to some advanced non-graph-based methods by achieving 72.48% of weighted accuracy (WA) and 67.72% of unweighted accuracy (UA).
Neural Speech Synthesis on a Shoestring: Improving the Efficiency of LPCNet
Feb 22, 2022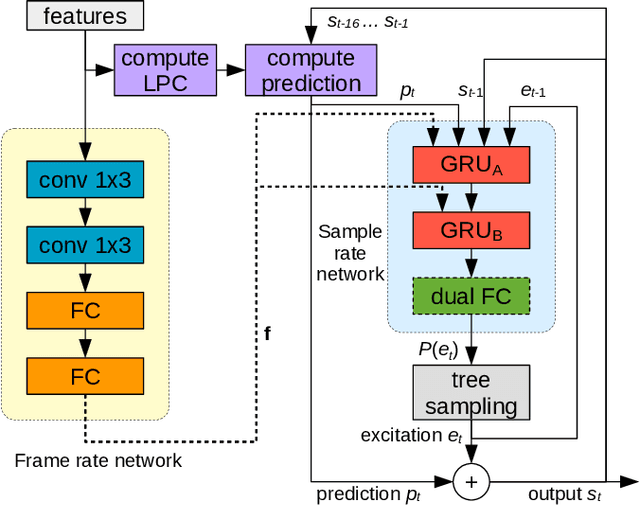
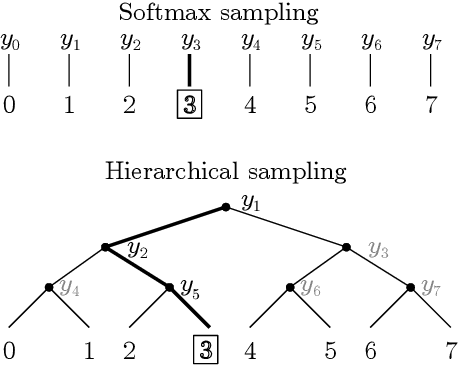
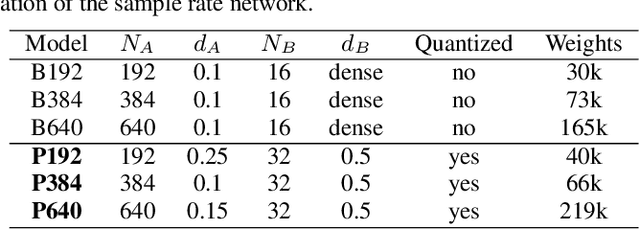
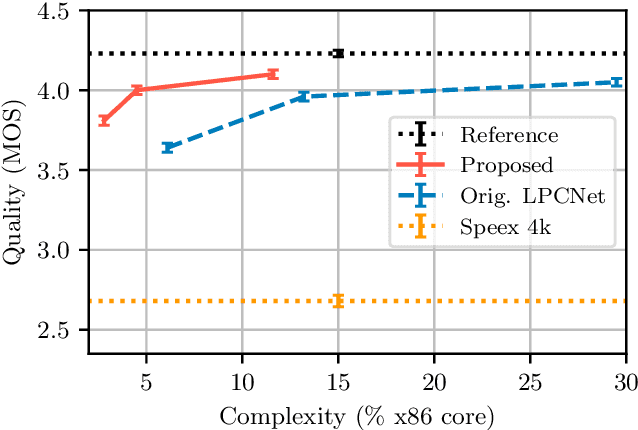
Neural speech synthesis models can synthesize high quality speech but typically require a high computational complexity to do so. In previous work, we introduced LPCNet, which uses linear prediction to significantly reduce the complexity of neural synthesis. In this work, we further improve the efficiency of LPCNet -- targeting both algorithmic and computational improvements -- to make it usable on a wide variety of devices. We demonstrate an improvement in synthesis quality while operating 2.5x faster. The resulting open-source LPCNet algorithm can perform real-time neural synthesis on most existing phones and is even usable in some embedded devices.
Shennong: a Python toolbox for audio speech features extraction
Dec 10, 2021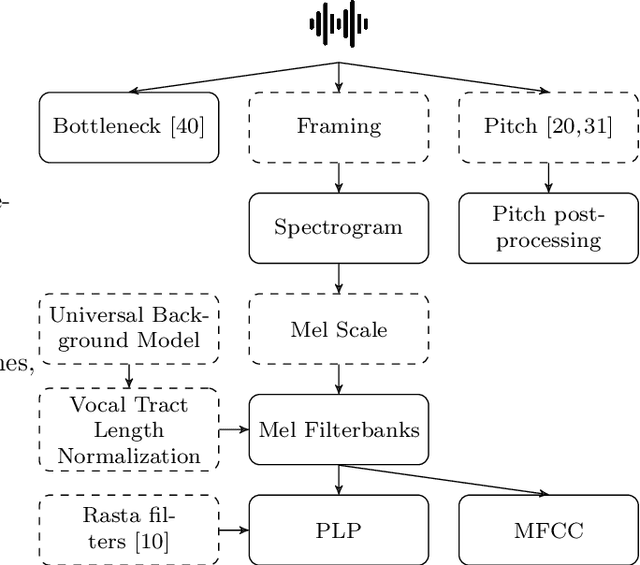

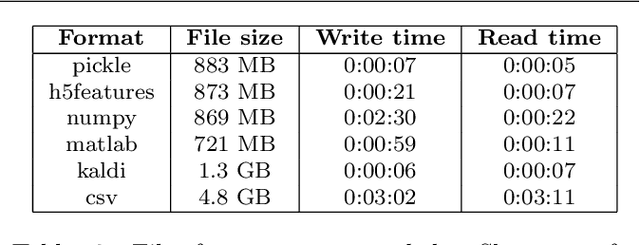
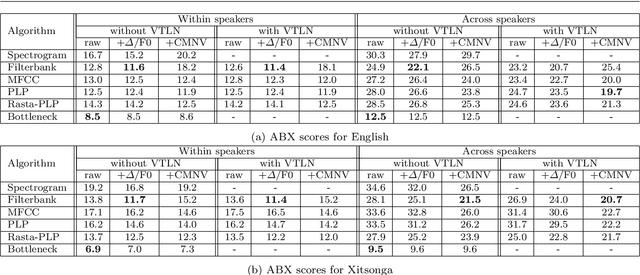
We introduce Shennong, a Python toolbox and command-line utility for speech features extraction. It implements a wide range of well-established state of art algorithms including spectro-temporal filters such as Mel-Frequency Cepstral Filterbanks or Predictive Linear Filters, pre-trained neural networks, pitch estimators as well as speaker normalization methods and post-processing algorithms. Shennong is an open source, easy-to-use, reliable and extensible framework. The use of Python makes the integration to others speech modeling and machine learning tools easy. It aims to replace or complement several heterogeneous software, such as Kaldi or Praat. After describing the Shennong software architecture, its core components and implemented algorithms, this paper illustrates its use on three applications: a comparison of speech features performances on a phones discrimination task, an analysis of a Vocal Tract Length Normalization model as a function of the speech duration used for training and a comparison of pitch estimation algorithms under various noise conditions.
Real-time Speech Emotion Recognition Based on Syllable-Level Feature Extraction
Apr 26, 2022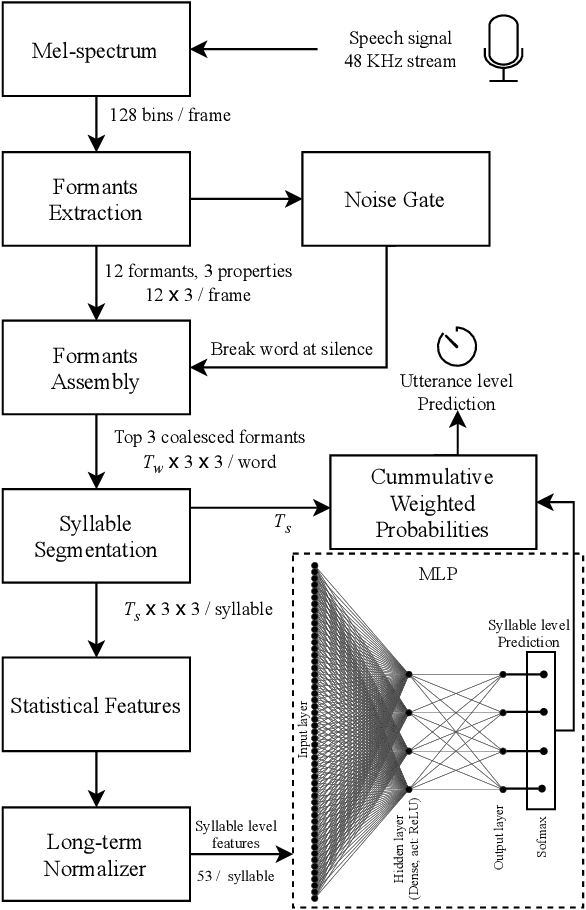
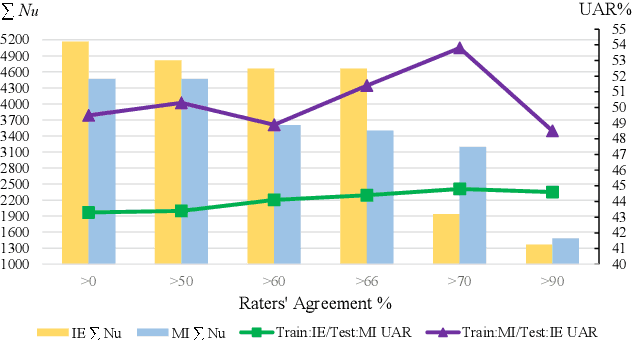
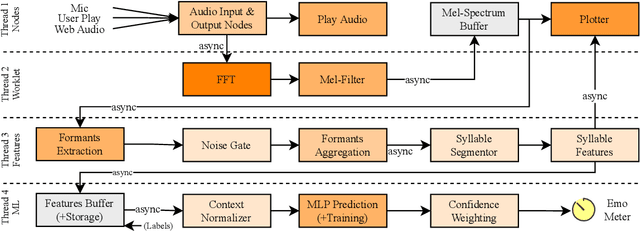
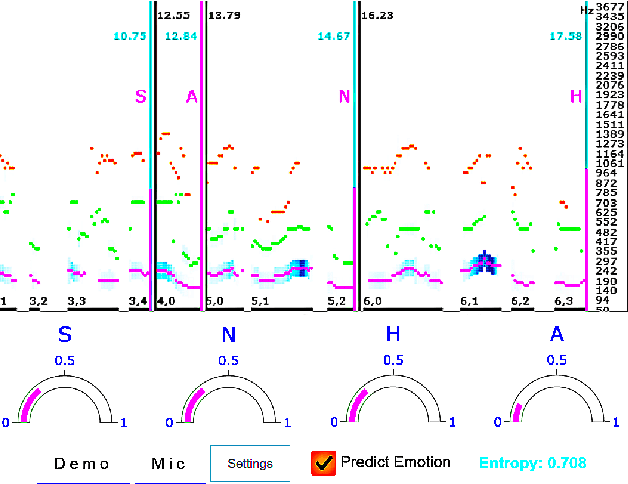
Speech emotion recognition systems have high prediction latency because of the high computational requirements for deep learning models and low generalizability mainly because of the poor reliability of emotional measurements across multiple corpora. To solve these problems, we present a speech emotion recognition system based on a reductionist approach of decomposing and analyzing syllable-level features. Mel-spectrogram of an audio stream is decomposed into syllable-level components, which are then analyzed to extract statistical features. The proposed method uses formant attention, noise-gate filtering, and rolling normalization contexts to increase feature processing speed and tolerance to adversity. A set of syllable-level formant features is extracted and fed into a single hidden layer neural network that makes predictions for each syllable as opposed to the conventional approach of using a sophisticated deep learner to make sentence-wide predictions. The syllable level predictions help to achieve the real-time latency and lower the aggregated error in utterance level cross-corpus predictions. The experiments on IEMOCAP (IE), MSP-Improv (MI), and RAVDESS (RA) databases show that the method archives real-time latency while predicting with state-of-the-art cross-corpus unweighted accuracy of 47.6% for IE to MI and 56.2% for MI to IE.
A combined approach to the analysis of speech conversations in a contact center domain
Mar 12, 2022
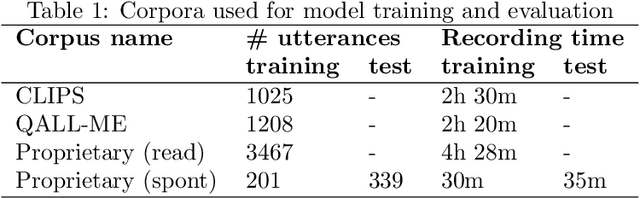
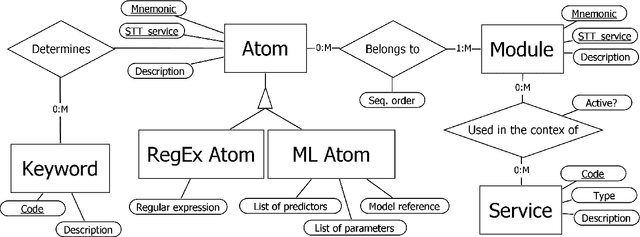

The ever more accurate search for deep analysis in customer data is a really strong technological trend nowadays, quite appealing to both private and public companies. This is particularly true in the contact center domain, where speech analytics is an extremely powerful methodology for gaining insights from unstructured data, coming from customer and human agent conversations. In this work, we describe an experimentation with a speech analytics process for an Italian contact center, that deals with call recordings extracted from inbound or outbound flows. First, we illustrate in detail the development of an in-house speech-to-text solution, based on Kaldi framework, and evaluate its performance (and compare it to Google Cloud Speech API). Then, we evaluate and compare different approaches to the semantic tagging of call transcripts, ranging from classic regular expressions to machine learning models based on ngrams and logistic regression, and propose a combination of them, which is shown to provide a consistent benefit. Finally, a decision tree inducer, called J48S, is applied to the problem of tagging. Such an algorithm is natively capable of exploiting sequential data, such as texts, for classification purposes. The solution is compared with the other approaches and is shown to provide competitive classification performances, while generating highly interpretable models and reducing the complexity of the data preparation phase. The potential operational impact of the whole process is thoroughly examined.
COVYT: Introducing the Coronavirus YouTube and TikTok speech dataset featuring the same speakers with and without infection
Jun 20, 2022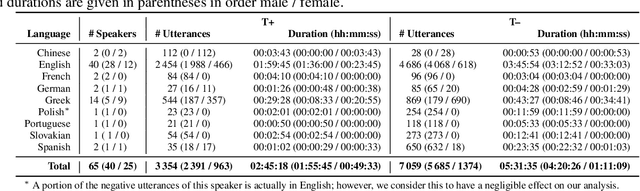
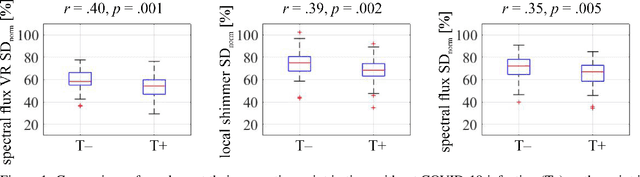
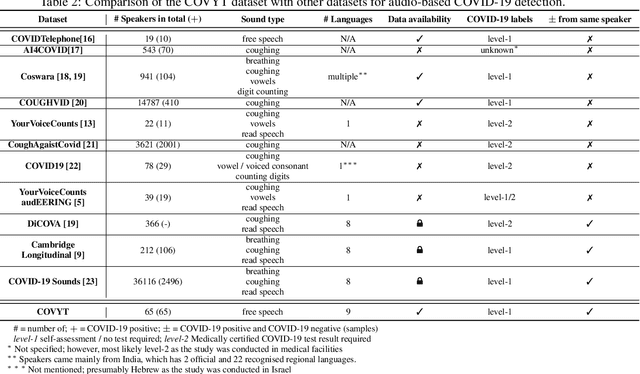
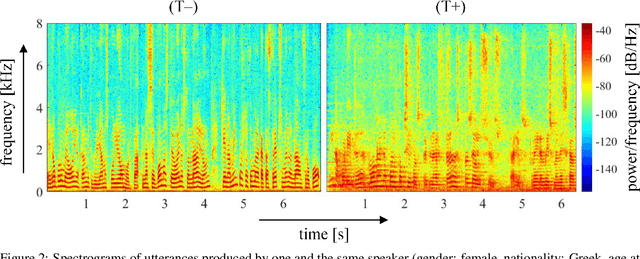
More than two years after its outbreak, the COVID-19 pandemic continues to plague medical systems around the world, putting a strain on scarce resources, and claiming human lives. From the very beginning, various AI-based COVID-19 detection and monitoring tools have been pursued in an attempt to stem the tide of infections through timely diagnosis. In particular, computer audition has been suggested as a non-invasive, cost-efficient, and eco-friendly alternative for detecting COVID-19 infections through vocal sounds. However, like all AI methods, also computer audition is heavily dependent on the quantity and quality of available data, and large-scale COVID-19 sound datasets are difficult to acquire -- amongst other reasons -- due to the sensitive nature of such data. To that end, we introduce the COVYT dataset -- a novel COVID-19 dataset collected from public sources containing more than 8 hours of speech from 65 speakers. As compared to other existing COVID-19 sound datasets, the unique feature of the COVYT dataset is that it comprises both COVID-19 positive and negative samples from all 65 speakers. We analyse the acoustic manifestation of COVID-19 on the basis of these perfectly speaker characteristic balanced `in-the-wild' data using interpretable audio descriptors, and investigate several classification scenarios that shed light into proper partitioning strategies for a fair speech-based COVID-19 detection.
Listen, denoise, action! Audio-driven motion synthesis with diffusion models
Nov 17, 2022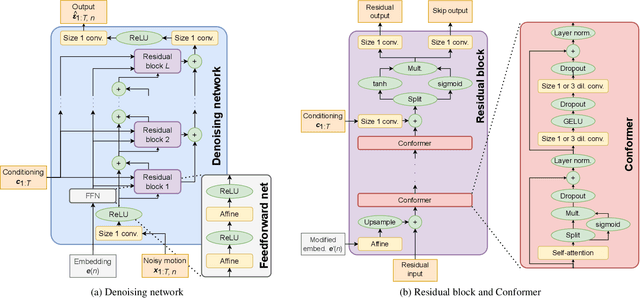
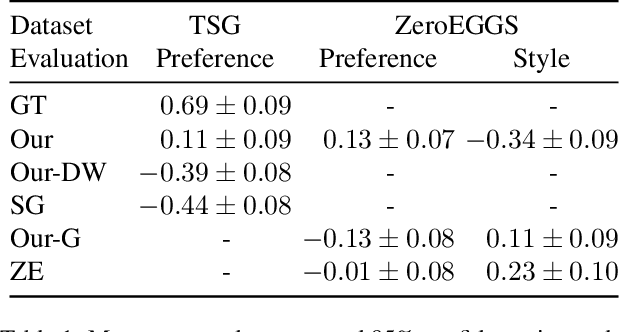

Diffusion models have experienced a surge of interest as highly expressive yet efficiently trainable probabilistic models. We show that these models are an excellent fit for synthesising human motion that co-occurs with audio, for example co-speech gesticulation, since motion is complex and highly ambiguous given audio, calling for a probabilistic description. Specifically, we adapt the DiffWave architecture to model 3D pose sequences, putting Conformers in place of dilated convolutions for improved accuracy. We also demonstrate control over motion style, using classifier-free guidance to adjust the strength of the stylistic expression. Gesture-generation experiments on the Trinity Speech-Gesture and ZeroEGGS datasets confirm that the proposed method achieves top-of-the-line motion quality, with distinctive styles whose expression can be made more or less pronounced. We also synthesise dance motion and path-driven locomotion using the same model architecture. Finally, we extend the guidance procedure to perform style interpolation in a manner that is appealing for synthesis tasks and has connections to product-of-experts models, a contribution we believe is of independent interest. Video examples are available at https://www.speech.kth.se/research/listen-denoise-action/
Data Augmentation for Speech Recognition in Maltese: A Low-Resource Perspective
Nov 15, 2021


Developing speech technologies is a challenge for low-resource languages for which both annotated and raw speech data is sparse. Maltese is one such language. Recent years have seen an increased interest in the computational processing of Maltese, including speech technologies, but resources for the latter remain sparse. In this paper, we consider data augmentation techniques for improving speech recognition for such languages, focusing on Maltese as a test case. We consider three different types of data augmentation: unsupervised training, multilingual training and the use of synthesized speech as training data. The goal is to determine which of these techniques, or combination of them, is the most effective to improve speech recognition for languages where the starting point is a small corpus of approximately 7 hours of transcribed speech. Our results show that combining the three data augmentation techniques studied here lead us to an absolute WER improvement of 15% without the use of a language model.
FullStop:Punctuation and Segmentation Prediction for Dutch with Transformers
Jan 09, 2023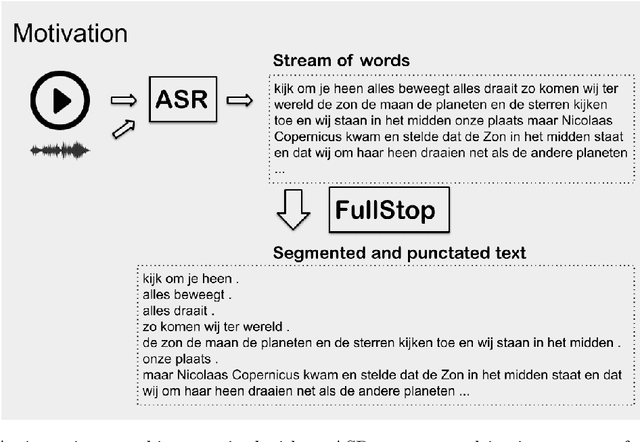


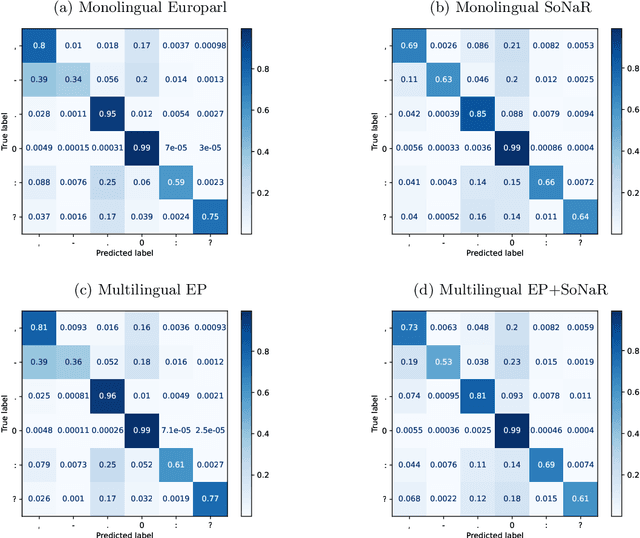
When applying automated speech recognition (ASR) for Belgian Dutch (Van Dyck et al. 2021), the output consists of an unsegmented stream of words, without any punctuation. A next step is to perform segmentation and insert punctuation, making the ASR output more readable and easy to manually correct. As far as we know there is no publicly available punctuation insertion system for Dutch that functions at a usable level. The model we present here is an extension of the models of Guhr et al. (2021) for Dutch and is made publicly available. We trained a sequence classification model, based on the Dutch language model RobBERT (Delobelle et al. 2020). For every word in the input sequence, the models predicts a punctuation marker that follows the word. We have also extended a multilingual model, for cases where the language is unknown or where code switching applies. When performing the task of segmentation, the application of the best models onto out of domain test data, a sliding window of 200 words of the ASR output stream is sent to the classifier, and segmentation is applied when the system predicts a segmenting punctuation sign with a ratio above threshold. Results show to be much better than a machine translation baseline approach.
LightHuBERT: Lightweight and Configurable Speech Representation Learning with Once-for-All Hidden-Unit BERT
Mar 29, 2022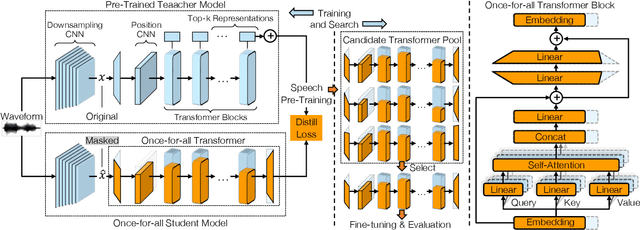
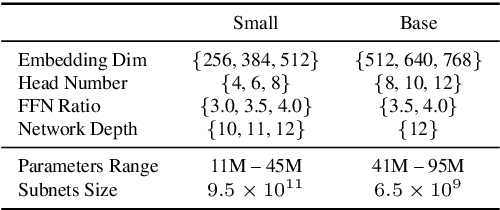

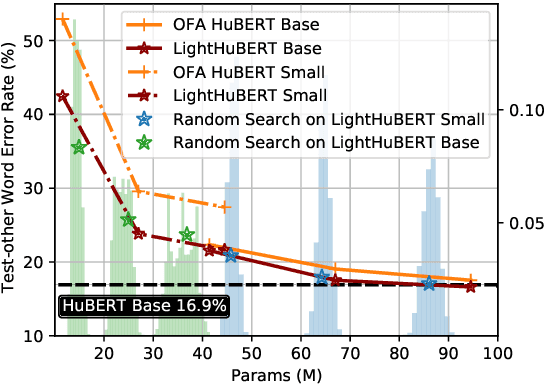
Self-supervised speech representation learning has shown promising results in various speech processing tasks. However, the pre-trained models, e.g., HuBERT, are storage-intensive Transformers, limiting their scope of applications under low-resource settings. To this end, we propose LightHuBERT, a once-for-all Transformer compression framework, to find the desired architectures automatically by pruning structured parameters. More precisely, we create a Transformer-based supernet that is nested with thousands of weight-sharing subnets and design a two-stage distillation strategy to leverage the contextualized latent representations from HuBERT. Experiments on automatic speech recognition (ASR) and the SUPERB benchmark show the proposed LightHuBERT enables over $10^9$ architectures concerning the embedding dimension, attention dimension, head number, feed-forward network ratio, and network depth. LightHuBERT outperforms the original HuBERT on ASR and five SUPERB tasks with the HuBERT size, achieves comparable performance to the teacher model in most tasks with a reduction of 29% parameters, and obtains a $3.5\times$ compression ratio in three SUPERB tasks, e.g., automatic speaker verification, keyword spotting, and intent classification, with a slight accuracy loss. The code and pre-trained models are available at https://github.com/mechanicalsea/lighthubert.