 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Multi-Label Training for Text-Independent Speaker Identification
Nov 14, 2022
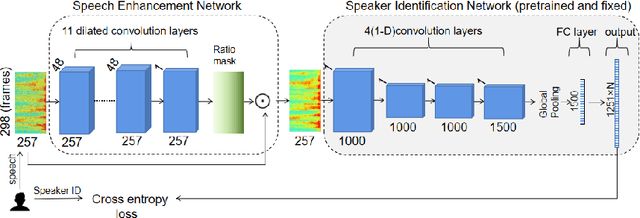


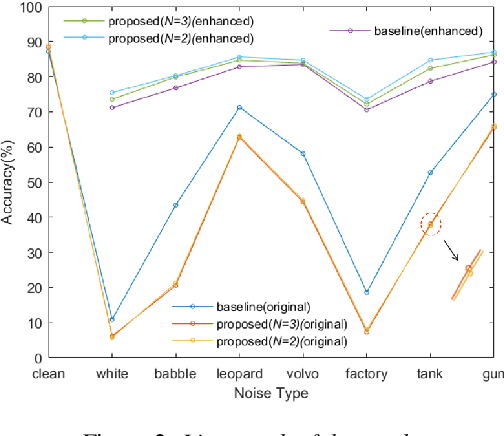
In this paper, we propose a novel strategy for text-independent speaker identification system: Multi-Label Training (MLT). Instead of the commonly used one-to-one correspondence between the speech and the speaker label, we divide all the speeches of each speaker into several subgroups, with each subgroup assigned a different set of labels. During the identification process, a specific speaker is identified as long as the predicted label is the same as one of his/her corresponding labels. We found that this method can force the model to distinguish the data more accurately, and somehow takes advantages of ensemble learning, while avoiding the significant increase of computation and storage burden. In the experiments, we found that not only in clean conditions, but also in noisy conditions with speech enhancement, Multi-Label Training can still achieve better identification performance than commom methods. It should be noted that the proposed strategy can be easily applied to almost all current text-independent speaker identification models to achieve further improvements.
NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
May 10, 2022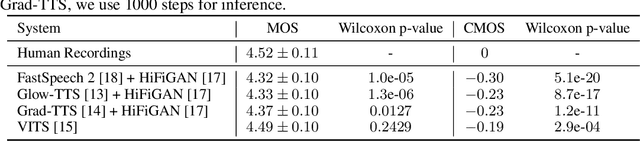
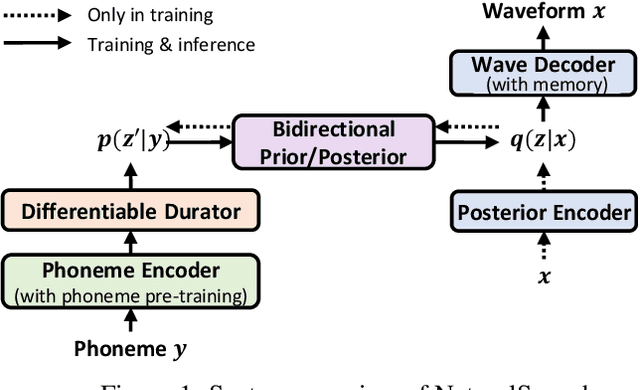
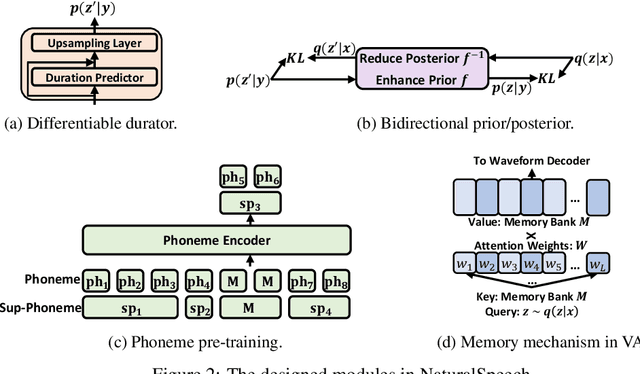
Text to speech (TTS) has made rapid progress in both academia and industry in recent years. Some questions naturally arise that whether a TTS system can achieve human-level quality, how to define/judge that quality and how to achieve it. In this paper, we answer these questions by first defining the human-level quality based on the statistical significance of subjective measure and introducing appropriate guidelines to judge it, and then developing a TTS system called NaturalSpeech that achieves human-level quality on a benchmark dataset. Specifically, we leverage a variational autoencoder (VAE) for end-to-end text to waveform generation, with several key modules to enhance the capacity of the prior from text and reduce the complexity of the posterior from speech, including phoneme pre-training, differentiable duration modeling, bidirectional prior/posterior modeling, and a memory mechanism in VAE. Experiment evaluations on popular LJSpeech dataset show that our proposed NaturalSpeech achieves -0.01 CMOS (comparative mean opinion score) to human recordings at the sentence level, with Wilcoxon signed rank test at p-level p >> 0.05, which demonstrates no statistically significant difference from human recordings for the first time on this dataset.
Conversational Speech Recognition By Learning Conversation-level Characteristics
Feb 17, 2022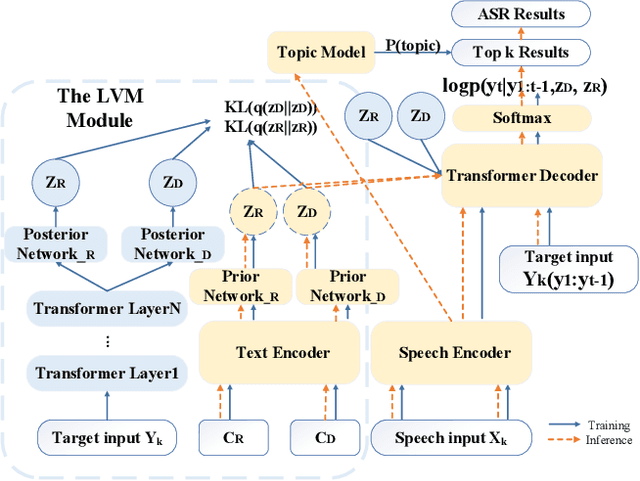

Conversational automatic speech recognition (ASR) is a task to recognize conversational speech including multiple speakers. Unlike sentence-level ASR, conversational ASR can naturally take advantages from specific characteristics of conversation, such as role preference and topical coherence. This paper proposes a conversational ASR model which explicitly learns conversation-level characteristics under the prevalent end-to-end neural framework. The highlights of the proposed model are twofold. First, a latent variational module (LVM) is attached to a conformer-based encoder-decoder ASR backbone to learn role preference and topical coherence. Second, a topic model is specifically adopted to bias the outputs of the decoder to words in the predicted topics. Experiments on two Mandarin conversational ASR tasks show that the proposed model achieves a maximum 12% relative character error rate (CER) reduction.
Improved two-stage hate speech classification for twitter based on Deep Neural Networks
Jun 08, 2022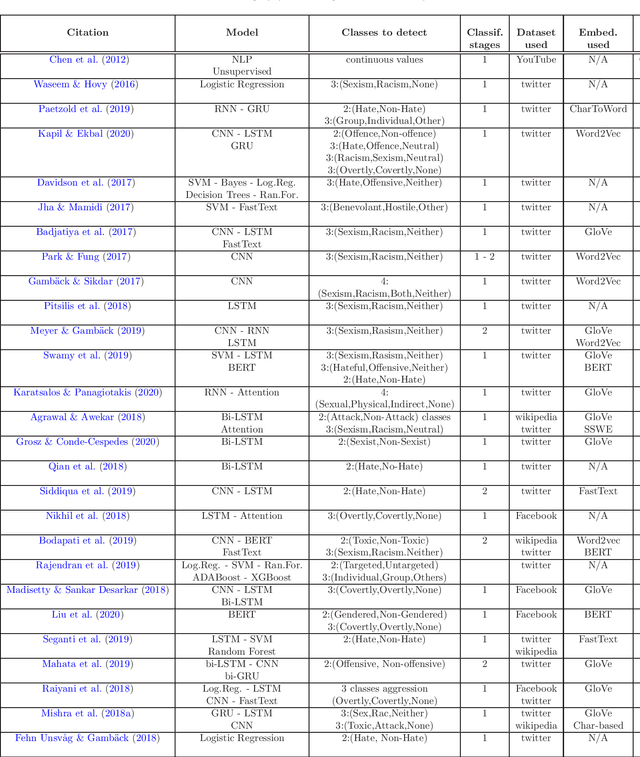
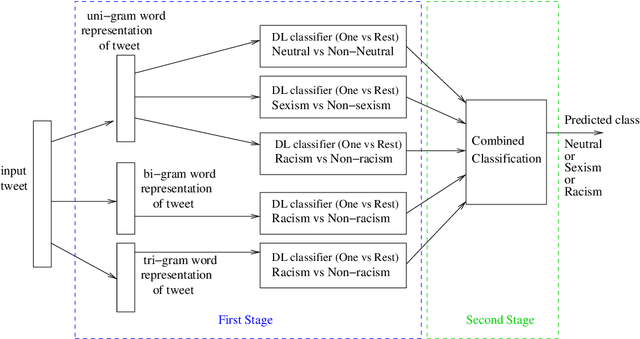
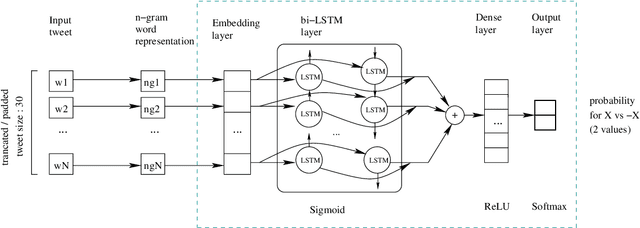
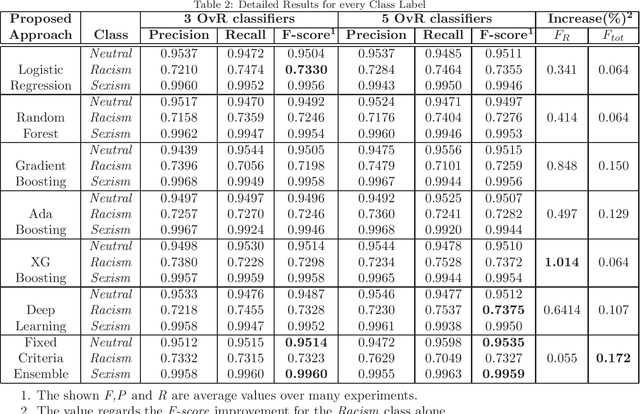
Hate speech is a form of online harassment that involves the use of abusive language, and it is commonly seen in social media posts. This sort of harassment mainly focuses on specific group characteristics such as religion, gender, ethnicity, etc and it has both societal and economic consequences nowadays. The automatic detection of abusive language in text postings has always been a difficult task, but it is lately receiving much interest from the scientific community. This paper addresses the important problem of discerning hateful content in social media. The model we propose in this work is an extension of an existing approach based on LSTM neural network architectures, which we appropriately enhanced and fine-tuned to detect certain forms of hatred language, such as racism or sexism, in a short text. The most significant enhancement is the conversion to a two-stage scheme consisting of Recurrent Neural Network (RNN) classifiers. The output of all One-vs-Rest (OvR) classifiers from the first stage are combined and used to train the second stage classifier, which finally determines the type of harassment. Our study includes a performance comparison of several proposed alternative methods for the second stage evaluated on a public corpus of 16k tweets, followed by a generalization study on another dataset. The reported results show the superior classification quality of the proposed scheme in the task of hate speech detection as compared to the current state-of-the-art.
DMF-Net: A decoupling-style multi-band fusion model for real-time full-band speech enhancement
Mar 02, 2022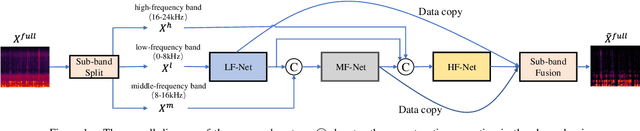
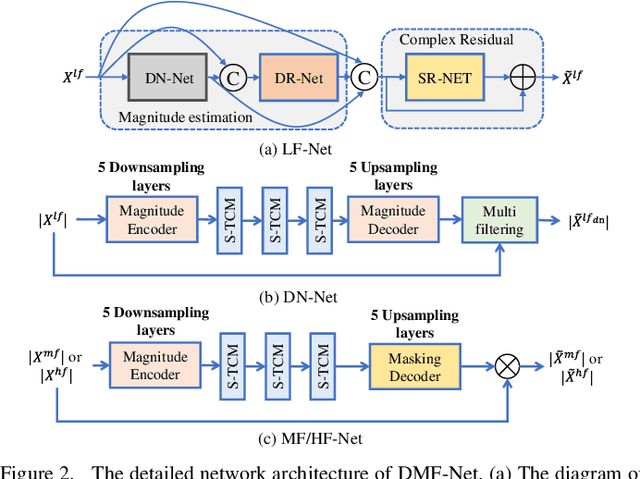
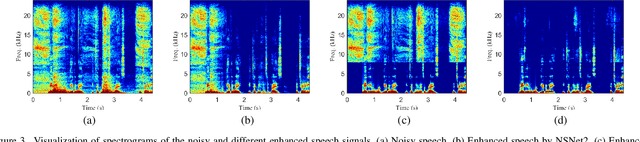
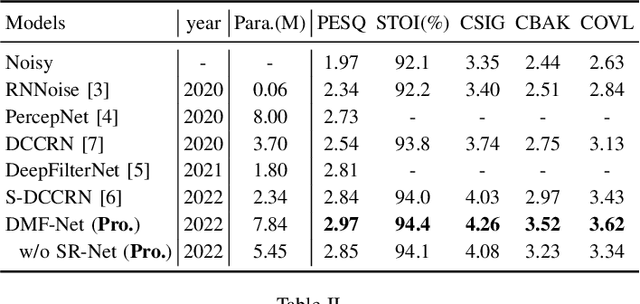
Full-band speech enhancement based on deep neural networks is still challenging for the difficulty of modeling more frequency bands and real-time implementation. Previous studies usually adopt compressed full-band speech features in Bark and ERB scale with relatively low frequency resolution, leading to degraded performance, especially in the high-frequency region. In this paper, we propose a decoupling-style multi-band fusion model to perform full-band speech denoising and dereverberation. Instead of optimizing the full-band speech by a single network structure, we decompose the full-band target into multi sub bands and then employ a multi-stage chain optimization strategy to estimate clean spectrum stage by stage. Specifically, the low- (0-8 kHz), middle- (8-16 kHz), and high-frequency (16-24 kHz) regions are mapped by three separate sub-networks and are then fused to obtain the full-band clean target STFT spectrum. Comprehensive experiments on two public datasets demonstrate that the proposed method outperforms previous advanced systems and yields promising performance in terms of speech quality and intelligibility in real complex scenarios.
Comparison of Speech Representations for the MOS Prediction System
Jun 28, 2022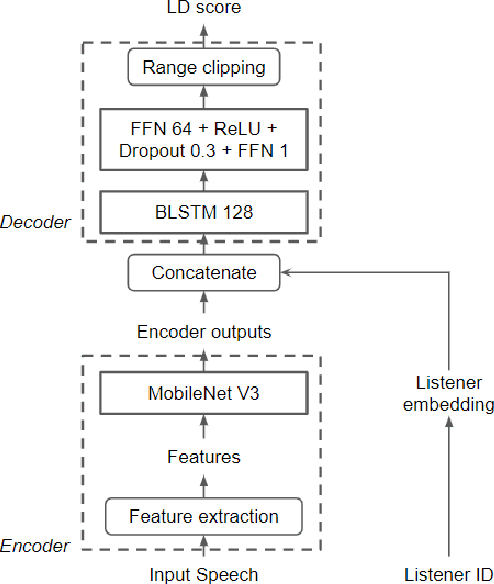
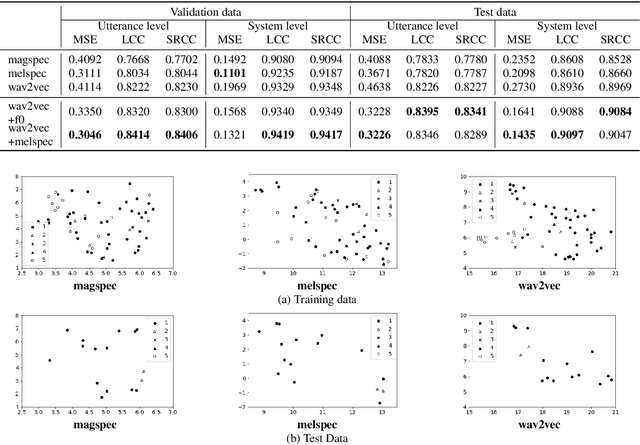
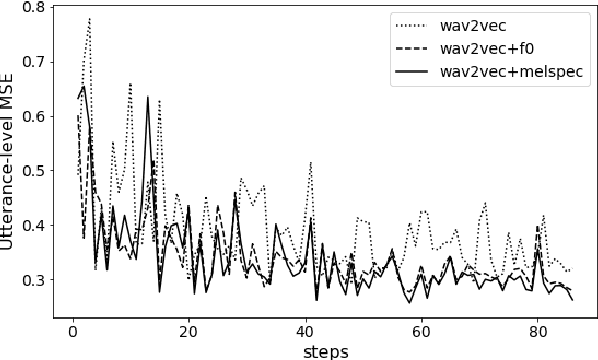
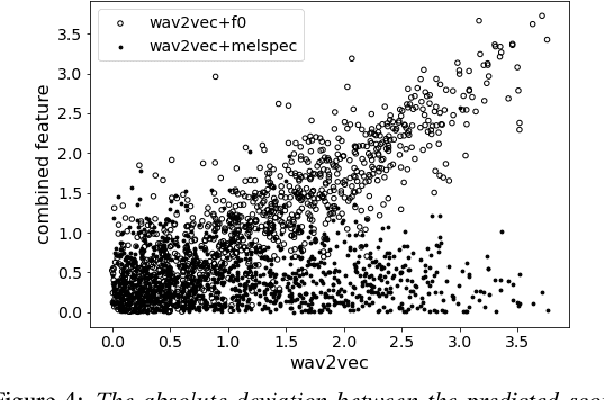
Automatic methods to predict Mean Opinion Score (MOS) of listeners have been researched to assure the quality of Text-to-Speech systems. Many previous studies focus on architectural advances (e.g. MBNet, LDNet, etc.) to capture relations between spectral features and MOS in a more effective way and achieved high accuracy. However, the optimal representation in terms of generalization capability still largely remains unknown. To this end, we compare the performance of Self-Supervised Learning (SSL) features obtained by the wav2vec framework to that of spectral features such as magnitude of spectrogram and melspectrogram. Moreover, we propose to combine the SSL features and features which we believe to retain essential information to the automatic MOS to compensate each other for their drawbacks. We conduct comprehensive experiments on a large-scale listening test corpus collected from past Blizzard and Voice Conversion Challenges. We found that the wav2vec feature set showed the best generalization even though the given ground-truth was not always reliable. Furthermore, we found that the combinations performed the best and analyzed how they bridged the gap between spectral and the wav2vec feature sets.
Integrated Speech and Gesture Synthesis
Aug 25, 2021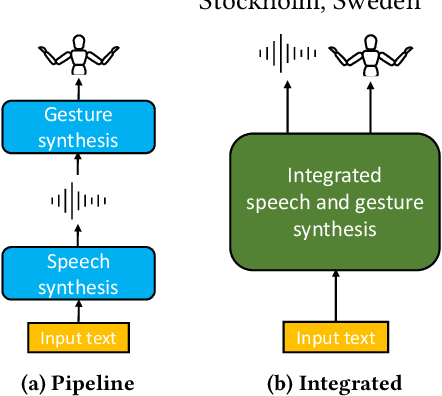

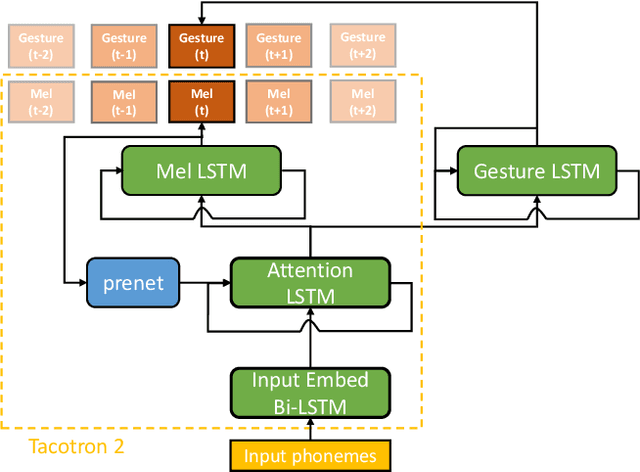
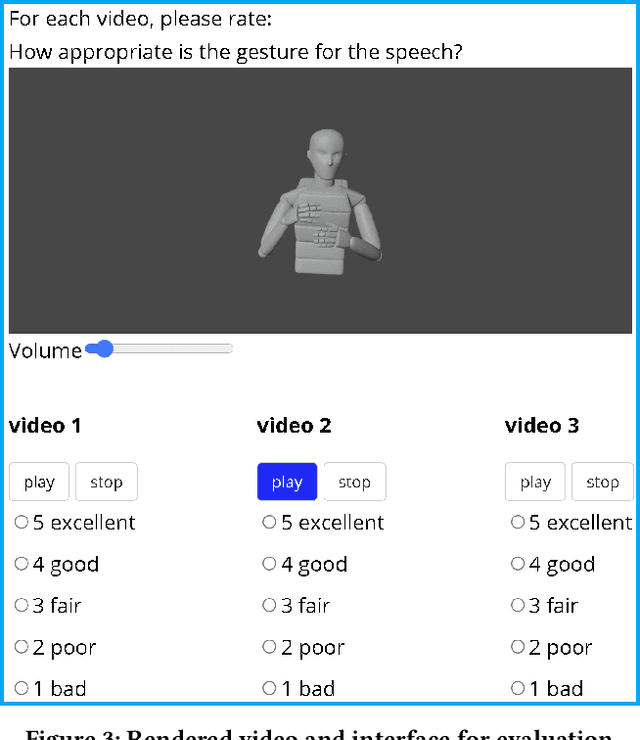
Text-to-speech and co-speech gesture synthesis have until now been treated as separate areas by two different research communities, and applications merely stack the two technologies using a simple system-level pipeline. This can lead to modeling inefficiencies and may introduce inconsistencies that limit the achievable naturalness. We propose to instead synthesize the two modalities in a single model, a new problem we call integrated speech and gesture synthesis (ISG). We also propose a set of models modified from state-of-the-art neural speech-synthesis engines to achieve this goal. We evaluate the models in three carefully-designed user studies, two of which evaluate the synthesized speech and gesture in isolation, plus a combined study that evaluates the models like they will be used in real-world applications -- speech and gesture presented together. The results show that participants rate one of the proposed integrated synthesis models as being as good as the state-of-the-art pipeline system we compare against, in all three tests. The model is able to achieve this with faster synthesis time and greatly reduced parameter count compared to the pipeline system, illustrating some of the potential benefits of treating speech and gesture synthesis together as a single, unified problem. Videos and code are available on our project page at https://swatsw.github.io/isg_icmi21/
Can we still use PEAQ? A Performance Analysis of the ITU Standard for the Objective Assessment of Perceived Audio Quality
Dec 02, 2022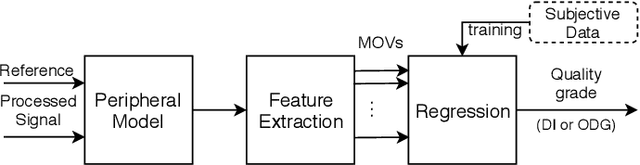
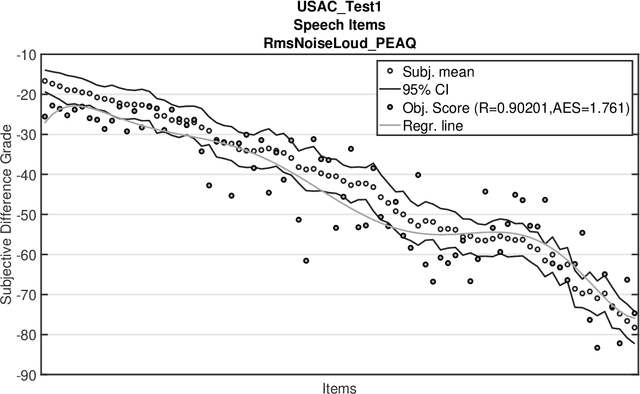
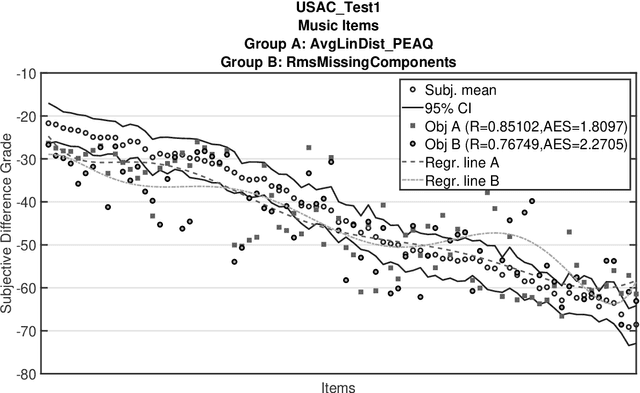
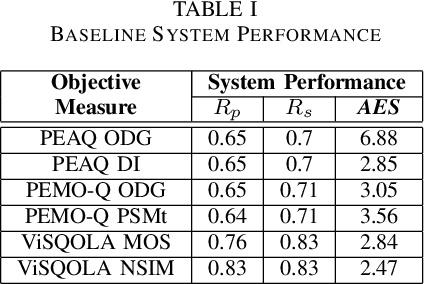
The Perceptual Evaluation of Audio Quality (PEAQ) method as described in the International Telecommunication Union (ITU) recommendation ITU-R BS.1387 has been widely used for computationally estimating the quality of perceptually coded audio signals without the need for extensive subjective listening tests. However, many reports have highlighted clear limitations of the scheme after the end of its standardization, particularly involving signals coded with newer technologies such as bandwidth extension or parametric multi-channel coding. Until now, no other method for measuring the quality of both speech and audio signals has been standardized by the ITU. Therefore, a further investigation of the causes for these limitations would be beneficial to a possible update of said scheme. Our experimental results indicate that the performance of PEAQ's model of disturbance loudness is still as good as (and sometimes superior to) other state-of-the-art objective measures, albeit with varying performance depending on the type of degraded signal content (i.e. speech or music). This finding evidences the need for an improved cognitive model. In addition, results indicate that an updated mapping of Model Output Values (MOVs) to PEAQ's Distortion Index (DI) based on newer training data can greatly improve performance. Finally, some suggestions for the improvement of PEAQ are provided based on the reported results and comparison to other systems.
* Accepter manuscript for 2020 Twelfth International Conference on Quality of Multimedia Experience (QoMEX 2020)
Over-Generation Cannot Be Rewarded: Length-Adaptive Average Lagging for Simultaneous Speech Translation
Jun 20, 2022
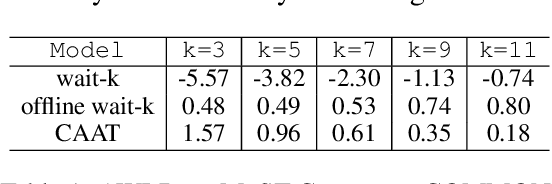
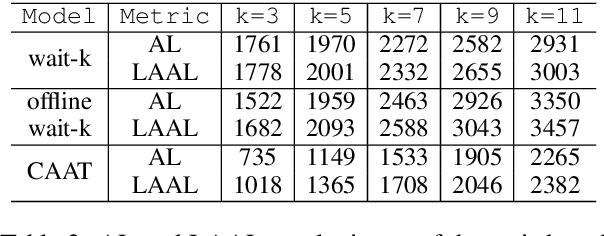
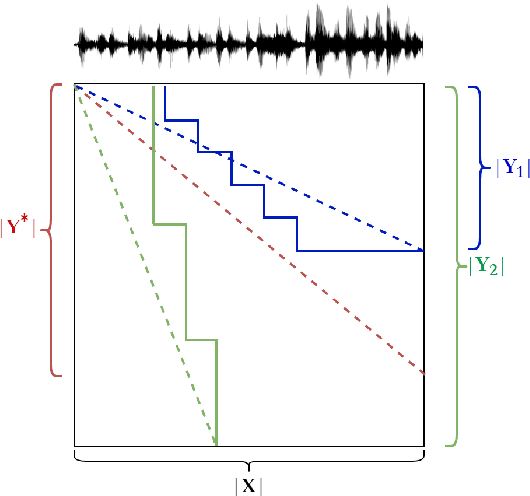
Simultaneous speech translation (SimulST) systems aim at generating their output with the lowest possible latency, which is normally computed in terms of Average Lagging (AL). In this paper we highlight that, despite its widespread adoption, AL provides underestimated scores for systems that generate longer predictions compared to the corresponding references. We also show that this problem has practical relevance, as recent SimulST systems have indeed a tendency to over-generate. As a solution, we propose LAAL (Length-Adaptive Average Lagging), a modified version of the metric that takes into account the over-generation phenomenon and allows for unbiased evaluation of both under-/over-generating systems.
On the Role of Spatial, Spectral, and Temporal Processing for DNN-based Non-linear Multi-channel Speech Enhancement
Jun 22, 2022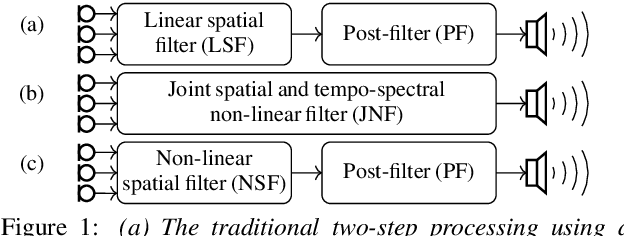
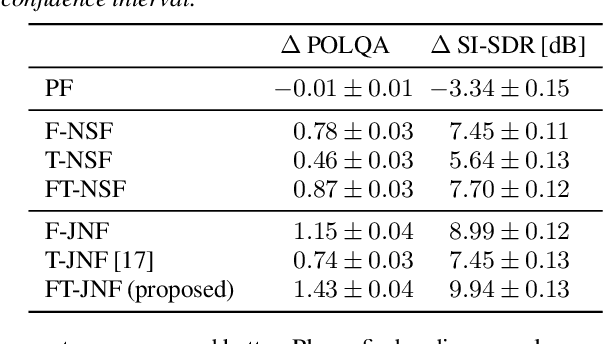
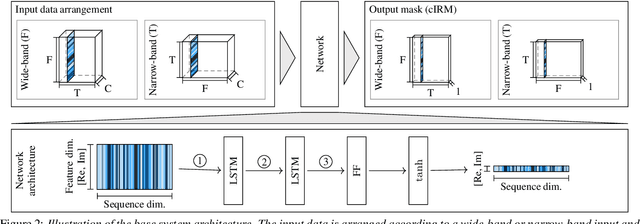
Employing deep neural networks (DNNs) to directly learn filters for multi-channel speech enhancement has potentially two key advantages over a traditional approach combining a linear spatial filter with an independent tempo-spectral post-filter: 1) non-linear spatial filtering allows to overcome potential restrictions originating from a linear processing model and 2) joint processing of spatial and tempo-spectral information allows to exploit interdependencies between different sources of information. A variety of DNN-based non-linear filters have been proposed recently, for which good enhancement performance is reported. However, little is known about the internal mechanisms which turns network architecture design into a game of chance. Therefore, in this paper, we perform experiments to better understand the internal processing of spatial, spectral and temporal information by DNN-based non-linear filters. On the one hand, our experiments in a difficult speech extraction scenario confirm the importance of non-linear spatial filtering, which outperforms an oracle linear spatial filter by 0.24 POLQA score. On the other hand, we demonstrate that joint processing results in a large performance gap of 0.4 POLQA score between network architectures exploiting spectral versus temporal information besides spatial information.