 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Can we still use PEAQ? A Performance Analysis of the ITU Standard for the Objective Assessment of Perceived Audio Quality
Dec 02, 2022
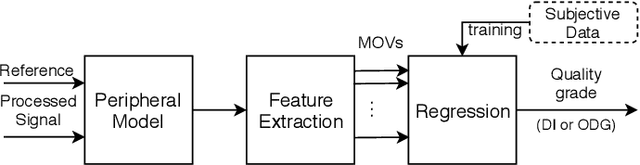
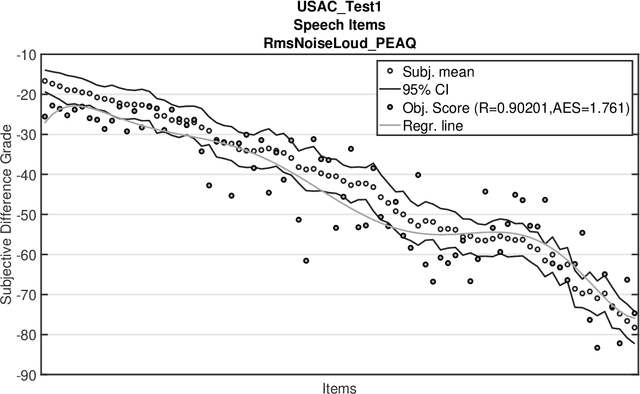
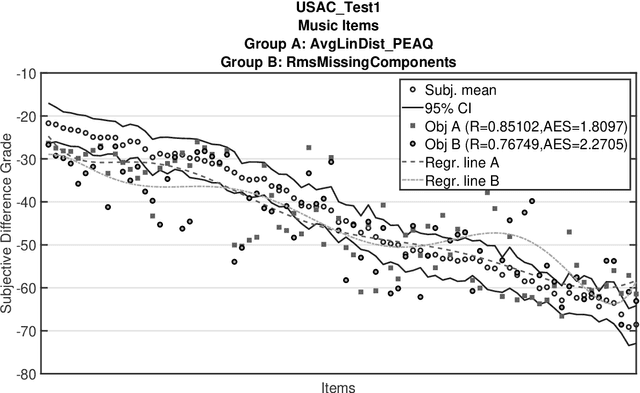
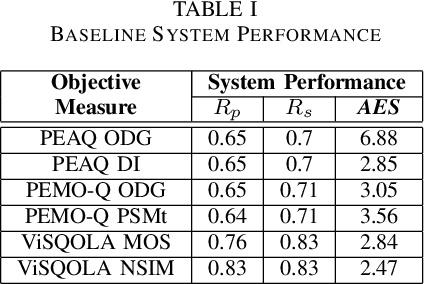
The Perceptual Evaluation of Audio Quality (PEAQ) method as described in the International Telecommunication Union (ITU) recommendation ITU-R BS.1387 has been widely used for computationally estimating the quality of perceptually coded audio signals without the need for extensive subjective listening tests. However, many reports have highlighted clear limitations of the scheme after the end of its standardization, particularly involving signals coded with newer technologies such as bandwidth extension or parametric multi-channel coding. Until now, no other method for measuring the quality of both speech and audio signals has been standardized by the ITU. Therefore, a further investigation of the causes for these limitations would be beneficial to a possible update of said scheme. Our experimental results indicate that the performance of PEAQ's model of disturbance loudness is still as good as (and sometimes superior to) other state-of-the-art objective measures, albeit with varying performance depending on the type of degraded signal content (i.e. speech or music). This finding evidences the need for an improved cognitive model. In addition, results indicate that an updated mapping of Model Output Values (MOVs) to PEAQ's Distortion Index (DI) based on newer training data can greatly improve performance. Finally, some suggestions for the improvement of PEAQ are provided based on the reported results and comparison to other systems.
* Accepter manuscript for 2020 Twelfth International Conference on Quality of Multimedia Experience (QoMEX 2020)
O-Dang! The Ontology of Dangerous Speech Messages
Jul 13, 2022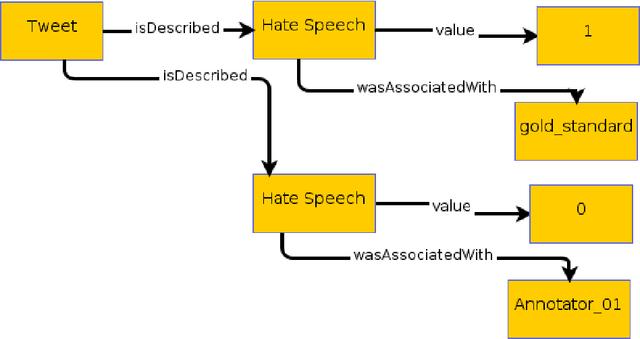
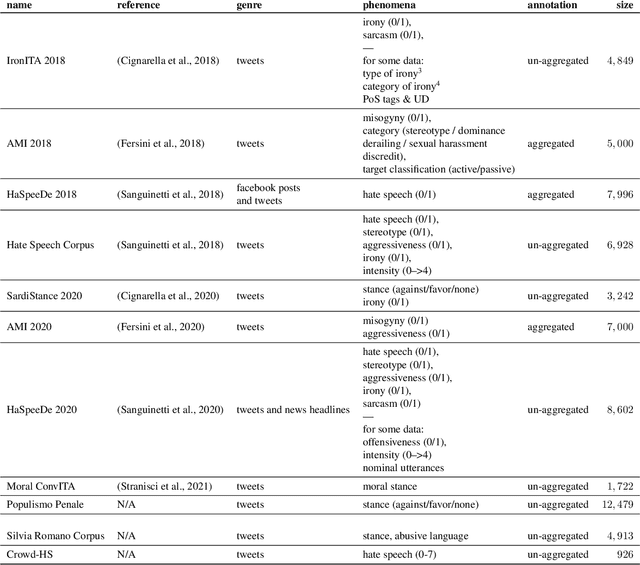
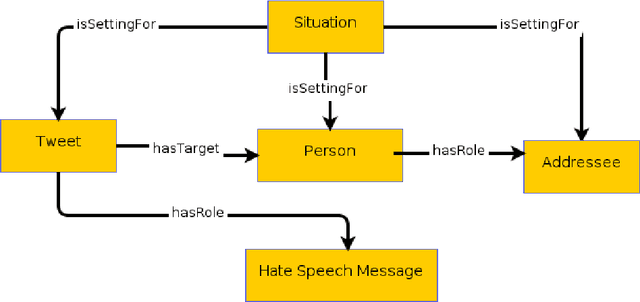
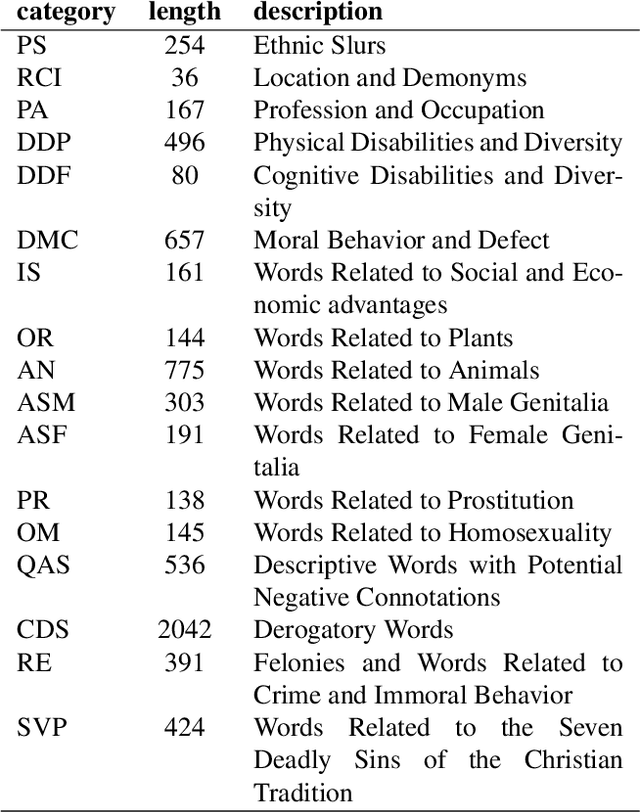
Inside the NLP community there is a considerable amount of language resources created, annotated and released every day with the aim of studying specific linguistic phenomena. Despite a variety of attempts in order to organize such resources has been carried on, a lack of systematic methods and of possible interoperability between resources are still present. Furthermore, when storing linguistic information, still nowadays, the most common practice is the concept of "gold standard", which is in contrast with recent trends in NLP that aim at stressing the importance of different subjectivities and points of view when training machine learning and deep learning methods. In this paper we present O-Dang!: The Ontology of Dangerous Speech Messages, a systematic and interoperable Knowledge Graph (KG) for the collection of linguistic annotated data. O-Dang! is designed to gather and organize Italian datasets into a structured KG, according to the principles shared within the Linguistic Linked Open Data community. The ontology has also been designed to account for a perspectivist approach, since it provides a model for encoding both gold standard and single-annotator labels in the KG. The paper is structured as follows. In Section 1 the motivations of our work are outlined. Section 2 describes the O-Dang! Ontology, that provides a common semantic model for the integration of datasets in the KG. The Ontology Population stage with information about corpora, users, and annotations is presented in Section 3. Finally, in Section 4 an analysis of offensiveness across corpora is provided as a first case study for the resource.
Separating Long-Form Speech with Group-Wise Permutation Invariant Training
Oct 27, 2021
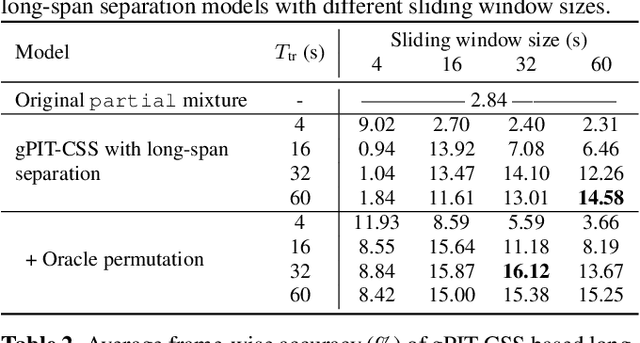
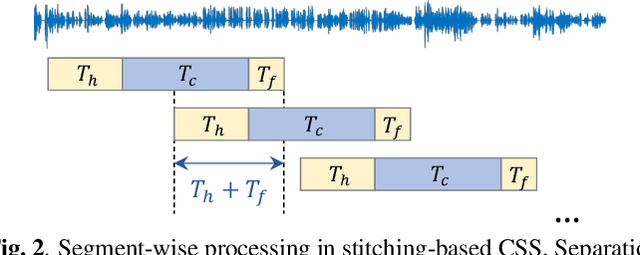
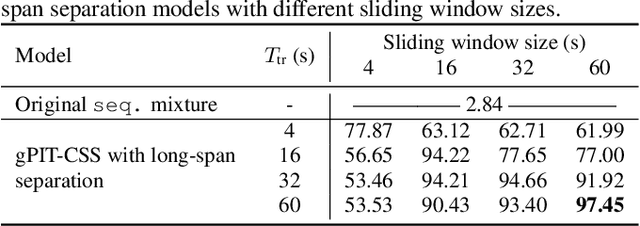
Multi-talker conversational speech processing has drawn many interests for various applications such as meeting transcription. Speech separation is often required to handle overlapped speech that is commonly observed in conversation. Although the existing utterancelevel permutation invariant training-based continuous speech separation approach has proven to be effective in various conditions, it lacks the ability to leverage the long-span relationship of utterances and is computationally inefficient due to the highly overlapped sliding windows. To overcome these drawbacks, we propose a novel training scheme named Group-PIT, which allows direct training of the speech separation models on the long-form speech with a low computational cost for label assignment. Two different speech separation approaches with Group-PIT are explored, including direct long-span speech separation and short-span speech separation with long-span tracking. The experiments on the simulated meeting-style data demonstrate the effectiveness of our proposed approaches, especially in dealing with a very long speech input.
Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain
Mar 31, 2022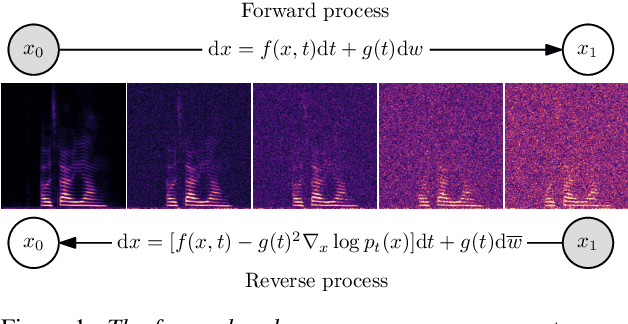
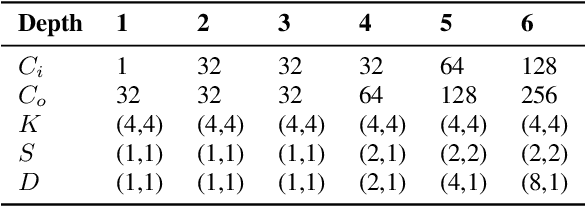
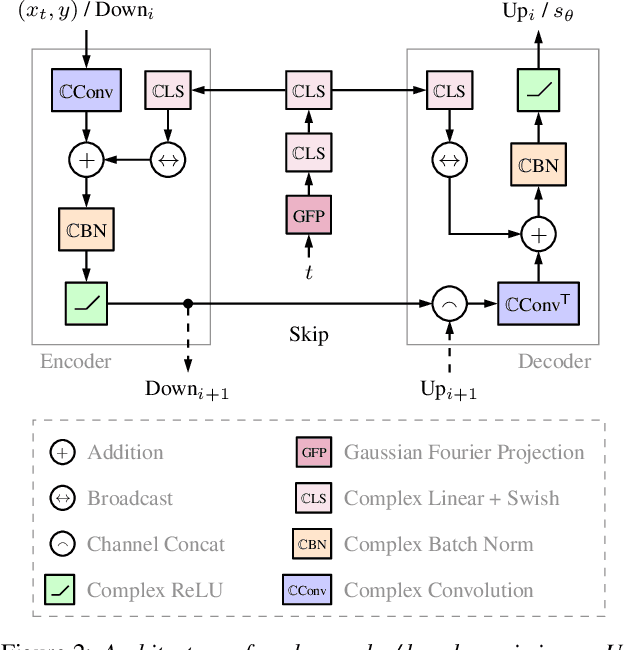
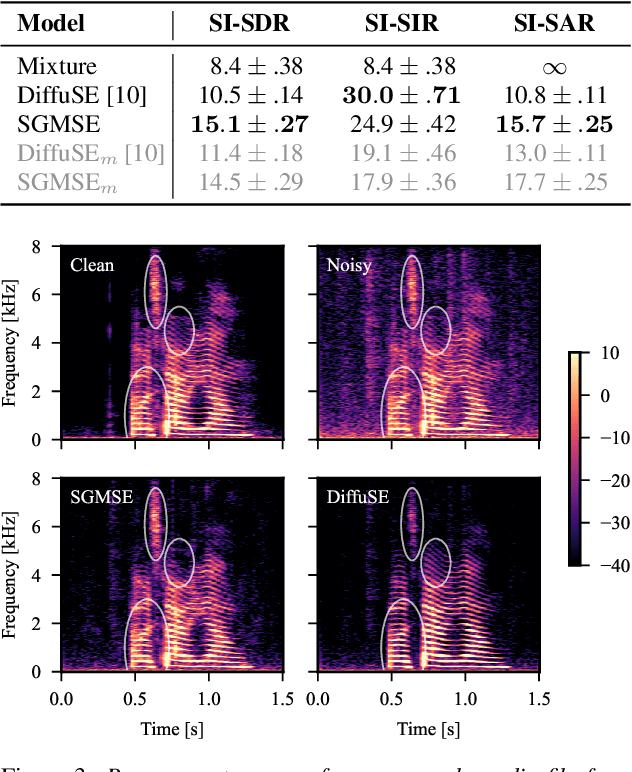
Score-based generative models (SGMs) have recently shown impressive results for difficult generative tasks such as the unconditional and conditional generation of natural images and audio signals. In this work, we extend these models to the complex short-time Fourier transform (STFT) domain, proposing a novel training task for speech enhancement using a complex-valued deep neural network. We derive this training task within the formalism of stochastic differential equations, thereby enabling the use of predictor-corrector samplers. We provide alternative formulations inspired by previous publications on using SGMs for speech enhancement, avoiding the need for any prior assumptions on the noise distribution and making the training task purely generative which, as we show, results in improved enhancement performance.
DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
Jan 28, 2022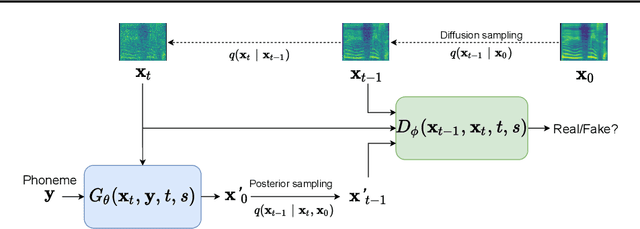
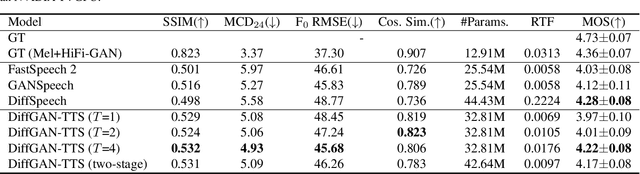
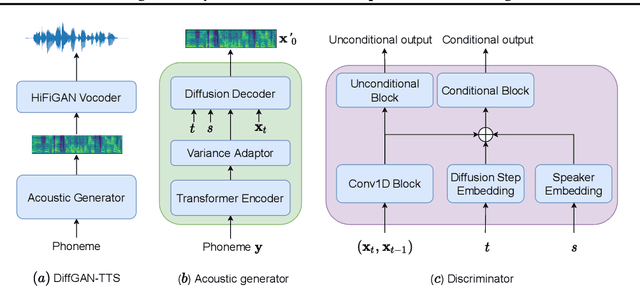
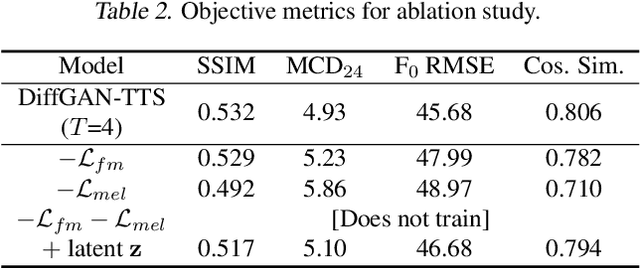
Denoising diffusion probabilistic models (DDPMs) are expressive generative models that have been used to solve a variety of speech synthesis problems. However, because of their high sampling costs, DDPMs are difficult to use in real-time speech processing applications. In this paper, we introduce DiffGAN-TTS, a novel DDPM-based text-to-speech (TTS) model achieving high-fidelity and efficient speech synthesis. DiffGAN-TTS is based on denoising diffusion generative adversarial networks (GANs), which adopt an adversarially-trained expressive model to approximate the denoising distribution. We show with multi-speaker TTS experiments that DiffGAN-TTS can generate high-fidelity speech samples within only 4 denoising steps. We present an active shallow diffusion mechanism to further speed up inference. A two-stage training scheme is proposed, with a basic TTS acoustic model trained at stage one providing valuable prior information for a DDPM trained at stage two. Our experiments show that DiffGAN-TTS can achieve high synthesis performance with only 1 denoising step.
Towards Robust Real-time Audio-Visual Speech Enhancement
Dec 16, 2021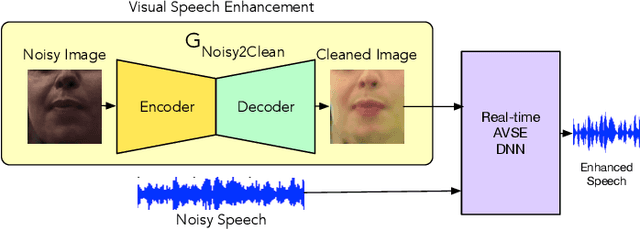
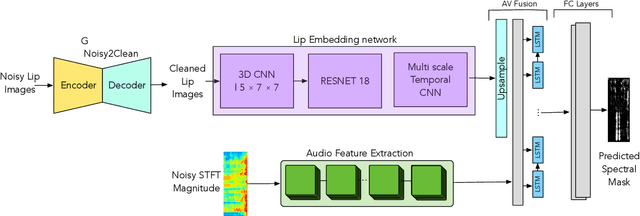

The human brain contextually exploits heterogeneous sensory information to efficiently perform cognitive tasks including vision and hearing. For example, during the cocktail party situation, the human auditory cortex contextually integrates audio-visual (AV) cues in order to better perceive speech. Recent studies have shown that AV speech enhancement (SE) models can significantly improve speech quality and intelligibility in very low signal to noise ratio (SNR) environments as compared to audio-only SE models. However, despite significant research in the area of AV SE, development of real-time processing models with low latency remains a formidable technical challenge. In this paper, we present a novel framework for low latency speaker-independent AV SE that can generalise on a range of visual and acoustic noises. In particular, a generative adversarial networks (GAN) is proposed to address the practical issue of visual imperfections in AV SE. In addition, we propose a deep neural network based real-time AV SE model that takes into account the cleaned visual speech output from GAN to deliver more robust SE. The proposed framework is evaluated on synthetic and real noisy AV corpora using objective speech quality and intelligibility metrics and subjective listing tests. Comparative simulation results show that our real time AV SE framework outperforms state-of-the-art SE approaches, including recent DNN based SE models.
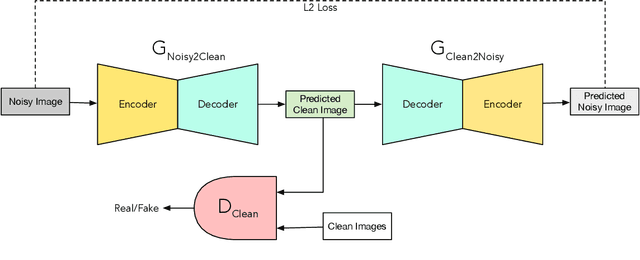
CycleGAN with Dual Adversarial Loss for Bone-Conducted Speech Enhancement
Nov 02, 2021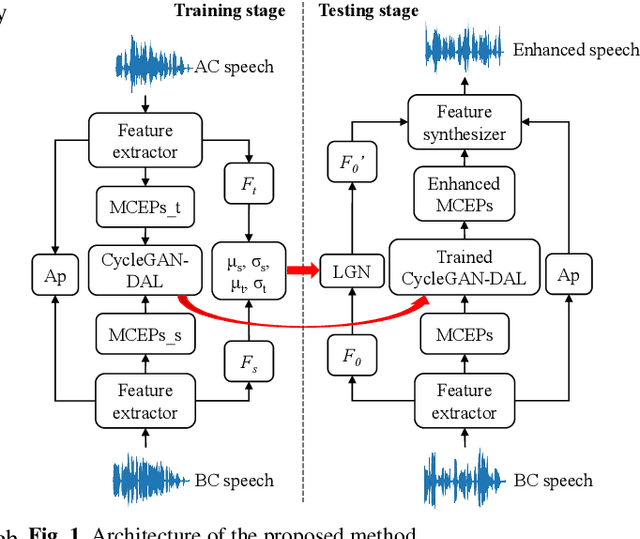
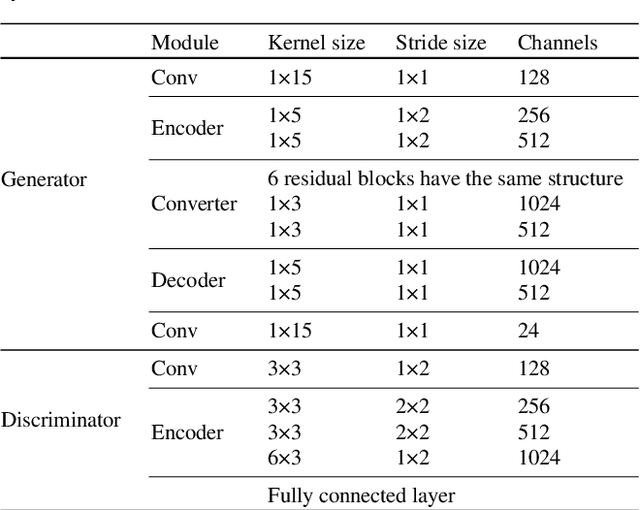
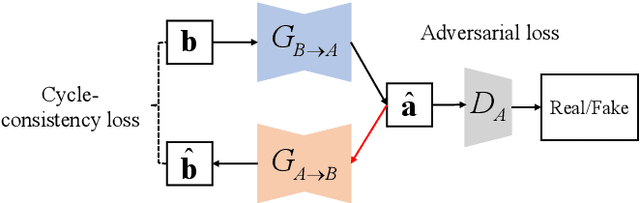

Compared with air-conducted speech, bone-conducted speech has the unique advantage of shielding background noise. Enhancement of bone-conducted speech helps to improve its quality and intelligibility. In this paper, a novel CycleGAN with dual adversarial loss (CycleGAN-DAL) is proposed for bone-conducted speech enhancement. The proposed method uses an adversarial loss and a cycle-consistent loss simultaneously to learn forward and cyclic mapping, in which the adversarial loss is replaced with the classification adversarial loss and the defect adversarial loss to consolidate the forward mapping. Compared with conventional baseline methods, it can learn feature mapping between bone-conducted speech and target speech without additional air-conducted speech assistance. Moreover, the proposed method also avoids the oversmooth problem which is occurred commonly in conventional statistical based models. Experimental results show that the proposed method outperforms baseline methods such as CycleGAN, GMM, and BLSTM. Keywords: Bone-conducted speech enhancement, dual adversarial loss, Parallel CycleGAN, high frequency speech reconstruction
Language Adaptive Cross-lingual Speech Representation Learning with Sparse Sharing Sub-networks
Mar 09, 2022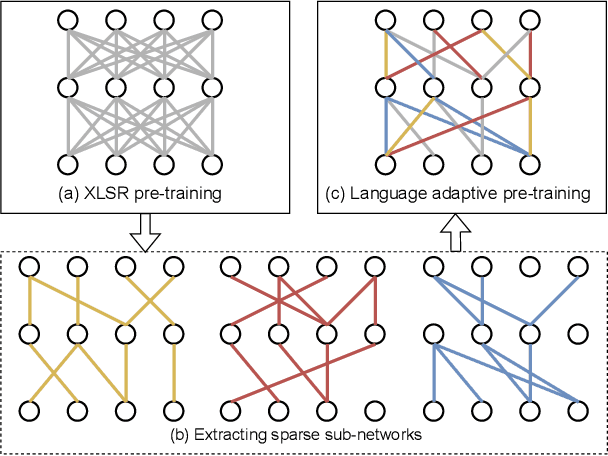
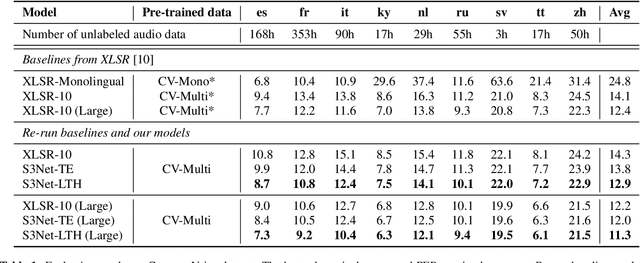
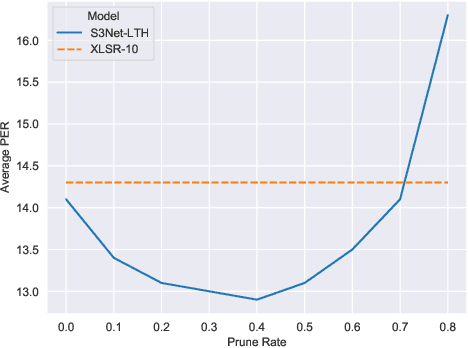
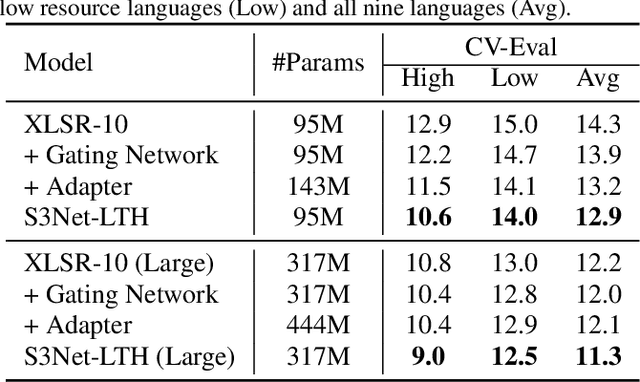
Unsupervised cross-lingual speech representation learning (XLSR) has recently shown promising results in speech recognition by leveraging vast amounts of unlabeled data across multiple languages. However, standard XLSR model suffers from language interference problem due to the lack of language specific modeling ability. In this work, we investigate language adaptive training on XLSR models. More importantly, we propose a novel language adaptive pre-training approach based on sparse sharing sub-networks. It makes room for language specific modeling by pruning out unimportant parameters for each language, without requiring any manually designed language specific component. After pruning, each language only maintains a sparse sub-network, while the sub-networks are partially shared with each other. Experimental results on a downstream multilingual speech recognition task show that our proposed method significantly outperforms baseline XLSR models on both high resource and low resource languages. Besides, our proposed method consistently outperforms other adaptation methods and requires fewer parameters.
NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
May 10, 2022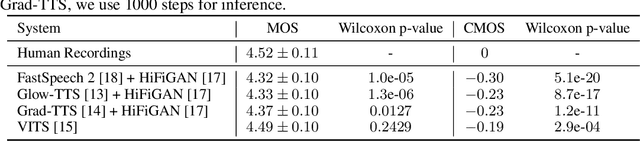
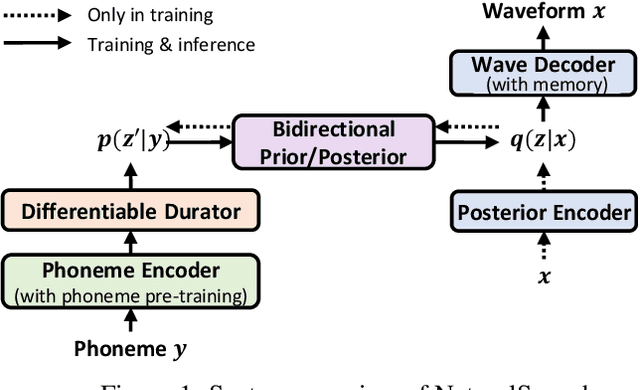
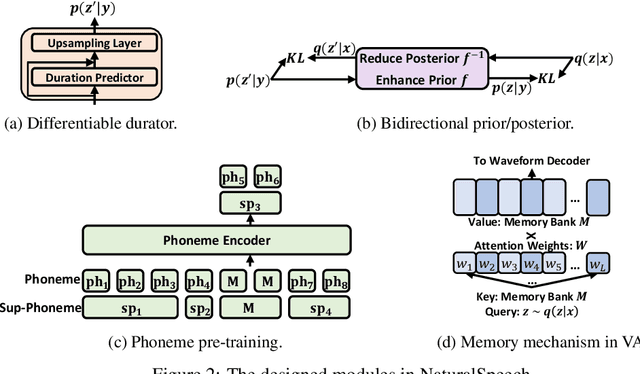
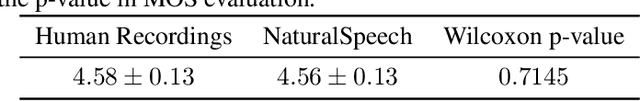
Text to speech (TTS) has made rapid progress in both academia and industry in recent years. Some questions naturally arise that whether a TTS system can achieve human-level quality, how to define/judge that quality and how to achieve it. In this paper, we answer these questions by first defining the human-level quality based on the statistical significance of subjective measure and introducing appropriate guidelines to judge it, and then developing a TTS system called NaturalSpeech that achieves human-level quality on a benchmark dataset. Specifically, we leverage a variational autoencoder (VAE) for end-to-end text to waveform generation, with several key modules to enhance the capacity of the prior from text and reduce the complexity of the posterior from speech, including phoneme pre-training, differentiable duration modeling, bidirectional prior/posterior modeling, and a memory mechanism in VAE. Experiment evaluations on popular LJSpeech dataset show that our proposed NaturalSpeech achieves -0.01 CMOS (comparative mean opinion score) to human recordings at the sentence level, with Wilcoxon signed rank test at p-level p >> 0.05, which demonstrates no statistically significant difference from human recordings for the first time on this dataset.
Speech Resources in the Tamasheq Language
Jan 14, 2022
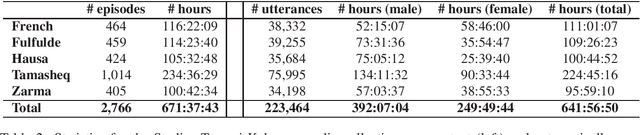

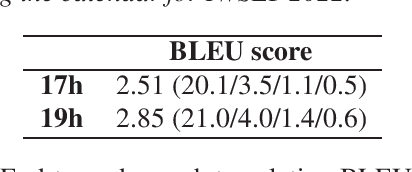
In this paper we present two datasets for Tamasheq, a developing language mainly spoken in Mali and Niger. These two datasets were made available for the IWSLT 2022 low-resource speech translation track, and they consist of collections of radio recordings from the Studio Kalangou (Niger) and Studio Tamani (Mali) daily broadcast news. We share (i) a massive amount of unlabeled audio data (671 hours) in five languages: French from Niger, Fulfulde, Hausa, Tamasheq and Zarma, and (ii) a smaller parallel corpus of audio recordings (17 hours) in Tamasheq, with utterance-level translations in the French language. All this data is shared under the Creative Commons BY-NC-ND 3.0 license. We hope these resources will inspire the speech community to develop and benchmark models using the Tamasheq language.