 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speaker Normalization for Self-supervised Speech Emotion Recognition
Feb 02, 2022
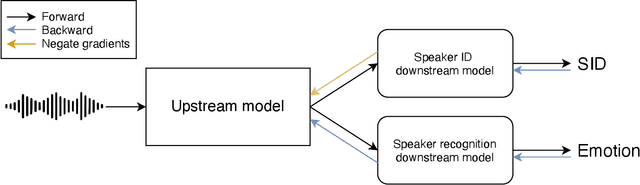
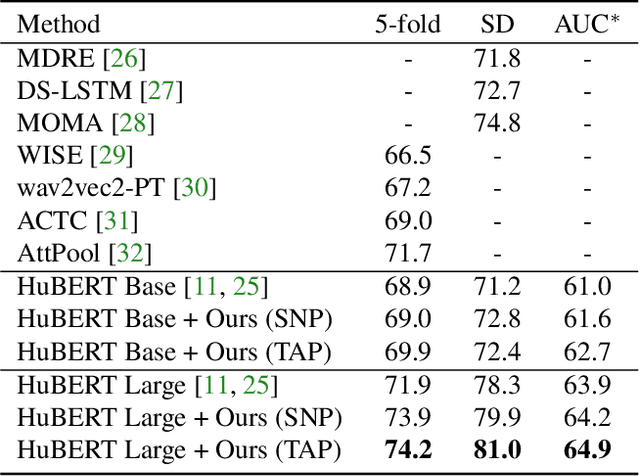
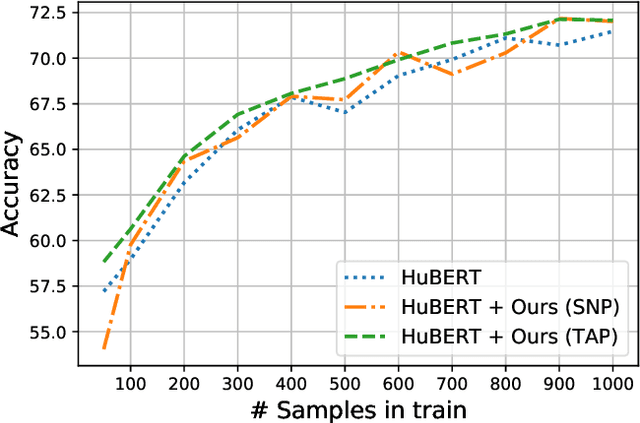
Large speech emotion recognition datasets are hard to obtain, and small datasets may contain biases. Deep-net-based classifiers, in turn, are prone to exploit those biases and find shortcuts such as speaker characteristics. These shortcuts usually harm a model's ability to generalize. To address this challenge, we propose a gradient-based adversary learning framework that learns a speech emotion recognition task while normalizing speaker characteristics from the feature representation. We demonstrate the efficacy of our method on both speaker-independent and speaker-dependent settings and obtain new state-of-the-art results on the challenging IEMOCAP dataset.
Necessity and Sufficiency for Explaining Text Classifiers: A Case Study in Hate Speech Detection
May 06, 2022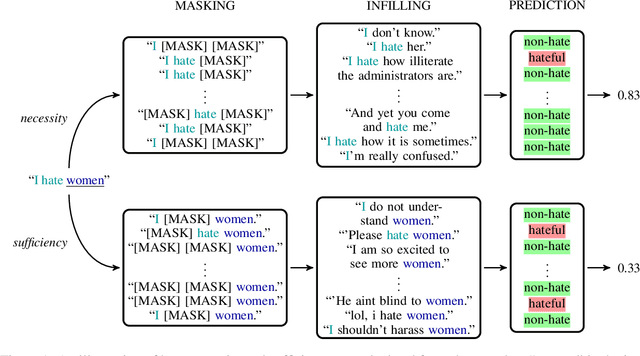

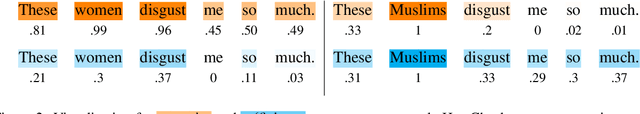
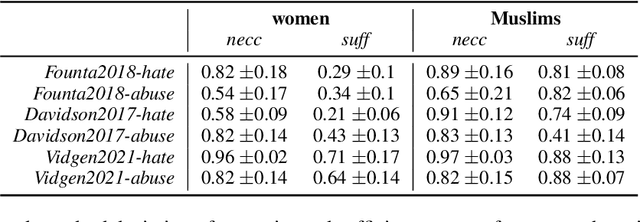
We present a novel feature attribution method for explaining text classifiers, and analyze it in the context of hate speech detection. Although feature attribution models usually provide a single importance score for each token, we instead provide two complementary and theoretically-grounded scores -- necessity and sufficiency -- resulting in more informative explanations. We propose a transparent method that calculates these values by generating explicit perturbations of the input text, allowing the importance scores themselves to be explainable. We employ our method to explain the predictions of different hate speech detection models on the same set of curated examples from a test suite, and show that different values of necessity and sufficiency for identity terms correspond to different kinds of false positive errors, exposing sources of classifier bias against marginalized groups.
TFCN: Temporal-Frequential Convolutional Network for Single-Channel Speech Enhancement
Jan 03, 2022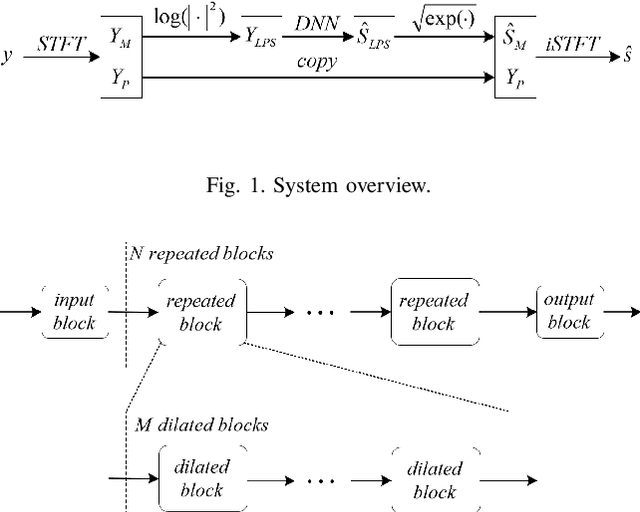
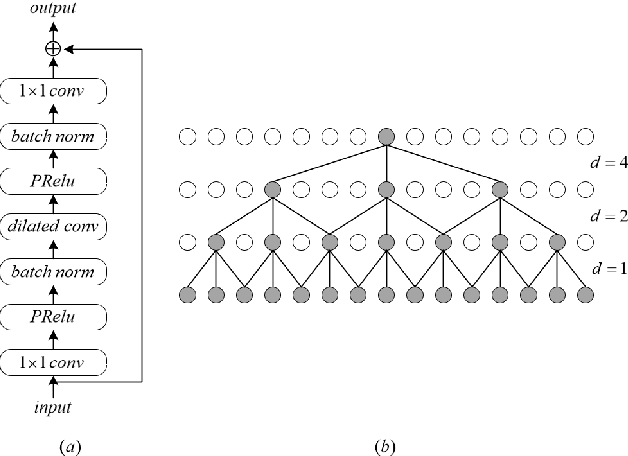
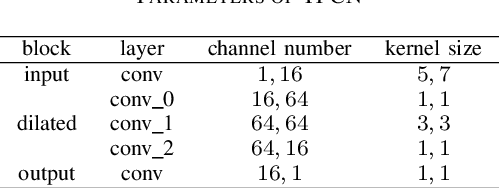
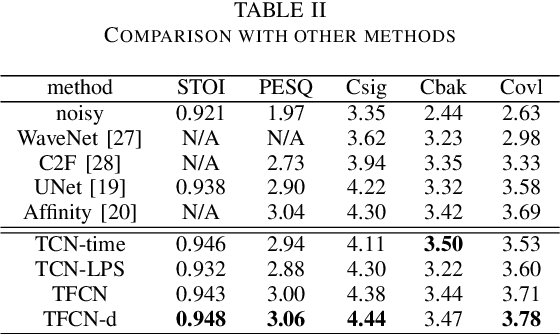
Deep learning based single-channel speech enhancement tries to train a neural network model for the prediction of clean speech signal. There are a variety of popular network structures for single-channel speech enhancement, such as TCNN, UNet, WaveNet, etc. However, these structures usually contain millions of parameters, which is an obstacle for mobile applications. In this work, we proposed a light weight neural network for speech enhancement named TFCN. It is a temporal-frequential convolutional network constructed of dilated convolutions and depth-separable convolutions. We evaluate the performance of TFCN in terms of Short-Time Objective Intelligibility (STOI), perceptual evaluation of speech quality (PESQ) and a series of composite metrics named Csig, Cbak and Covl. Experimental results show that compared with TCN and several other state-of-the-art algorithms, the proposed structure achieves a comparable performance with only 93,000 parameters. Further improvement can be achieved at the cost of more parameters, by introducing dense connections and depth-separable convolutions with normal ones. Experiments also show that the proposed structure can work well both in causal and non-causal situations.
Towards Intelligibility-Oriented Audio-Visual Speech Enhancement
Nov 18, 2021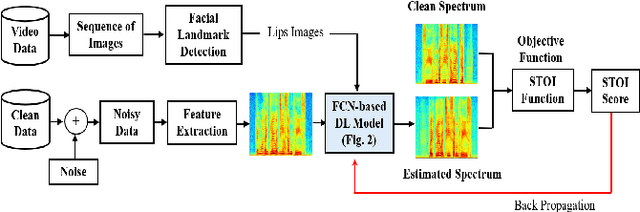
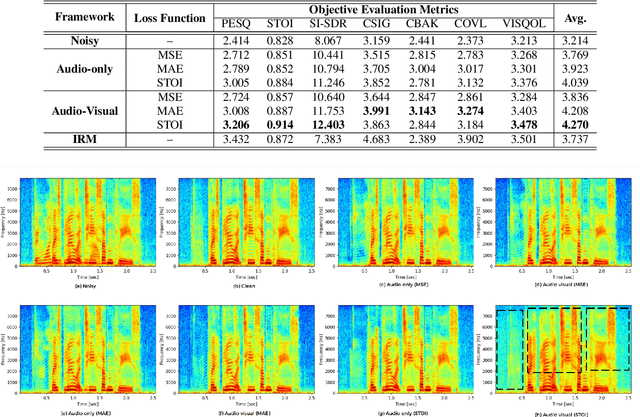
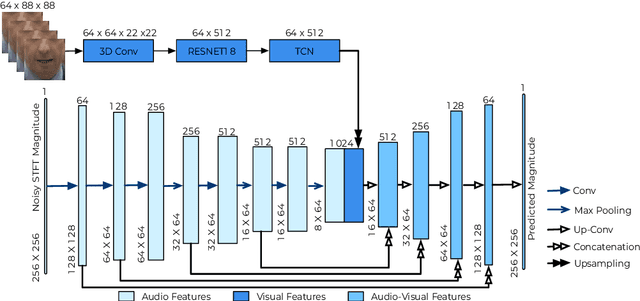
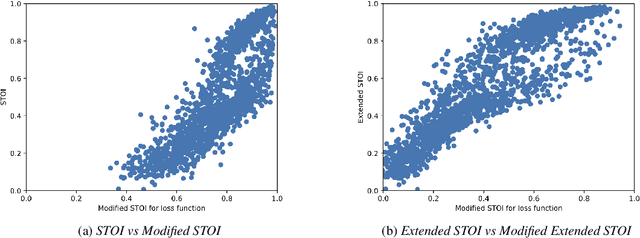
Existing deep learning (DL) based speech enhancement approaches are generally optimised to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in real noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions and integration of audio-visual (AV) information for more robust speech enhancement (SE). In this paper, we introduce DL based I-O SE algorithms exploiting AV information, which is a novel and previously unexplored research direction. Specifically, we present a fully convolutional AV SE model that uses a modified short-time objective intelligibility (STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of AV modalities with an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed I-O AV SE framework outperforms audio-only (AO) and AV models trained with conventional distance-based loss functions, in terms of standard objective evaluation measures when dealing with unseen speakers and noises.
Predicting Affective Vocal Bursts with Finetuned wav2vec 2.0
Sep 27, 2022


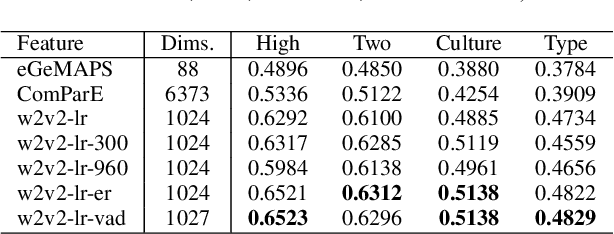
The studies of predicting affective states from human voices have relied heavily on speech. This study, indeed, explores the recognition of humans' affective state from their vocal burst, a short non-verbal vocalization. Borrowing the idea from the recent success of wav2vec 2.0, we evaluated finetuned wav2vec 2.0 models from different datasets to predict the affective state of the speaker from their vocal burst. The finetuned wav2vec 2.0 models are then trained on the vocal burst data. The results show that the finetuned wav2vec 2.0 models, particularly on an affective speech dataset, outperform the baseline model, which is handcrafted acoustic features. However, there is no large gap between the model finetuned on non-affective speech dataset and affective speech dataset.
Large-Scale Hate Speech Detection with Cross-Domain Transfer
Mar 02, 2022



The performance of hate speech detection models relies on the datasets on which the models are trained. Existing datasets are mostly prepared with a limited number of instances or hate domains that define hate topics. This hinders large-scale analysis and transfer learning with respect to hate domains. In this study, we construct large-scale tweet datasets for hate speech detection in English and a low-resource language, Turkish, consisting of human-labeled 100k tweets per each. Our datasets are designed to have equal number of tweets distributed over five domains. The experimental results supported by statistical tests show that Transformer-based language models outperform conventional bag-of-words and neural models by at least 5% in English and 10% in Turkish for large-scale hate speech detection. The performance is also scalable to different training sizes, such that 98% of performance in English, and 97% in Turkish, are recovered when 20% of training instances are used. We further examine the generalization ability of cross-domain transfer among hate domains. We show that 96% of the performance of a target domain in average is recovered by other domains for English, and 92% for Turkish. Gender and religion are more successful to generalize to other domains, while sports fail most.
Code Switched and Code Mixed Speech Recognition for Indic languages
Mar 30, 2022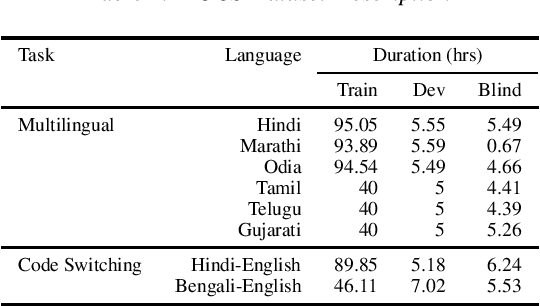

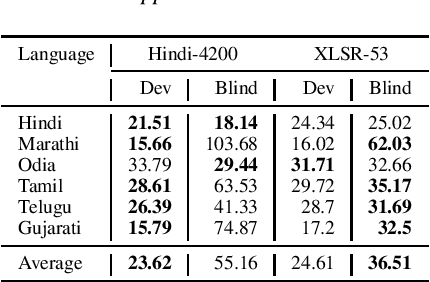
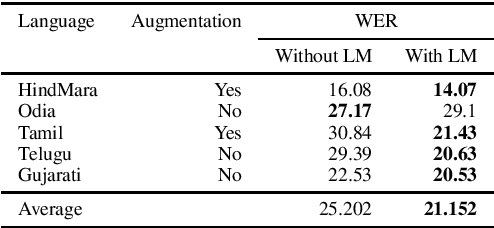
Training multilingual automatic speech recognition (ASR) systems is challenging because acoustic and lexical information is typically language specific. Training multilingual system for Indic languages is even more tougher due to lack of open source datasets and results on different approaches. We compare the performance of end to end multilingual speech recognition system to the performance of monolingual models conditioned on language identification (LID). The decoding information from a multilingual model is used for language identification and then combined with monolingual models to get an improvement of 50% WER across languages. We also propose a similar technique to solve the Code Switched problem and achieve a WER of 21.77 and 28.27 over Hindi-English and Bengali-English respectively. Our work talks on how transformer based ASR especially wav2vec 2.0 can be applied in developing multilingual ASR and code switched ASR for Indic languages.
SHAS: Approaching optimal Segmentation for End-to-End Speech Translation
Feb 09, 2022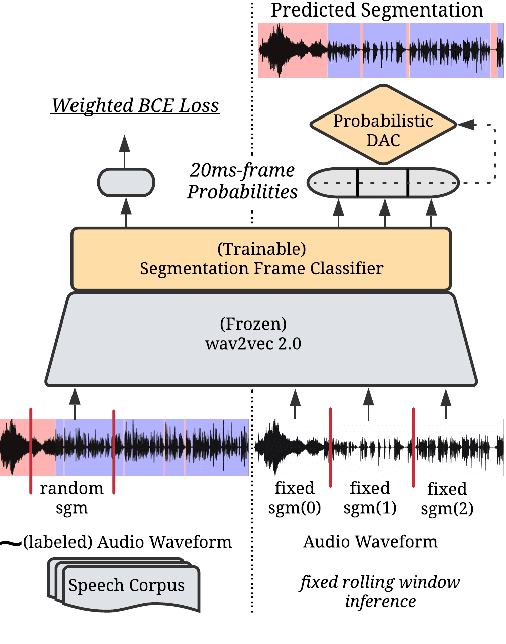
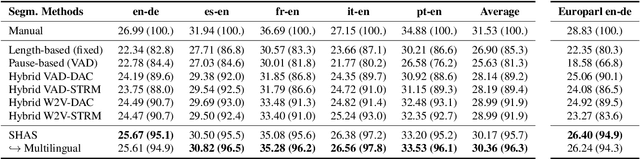
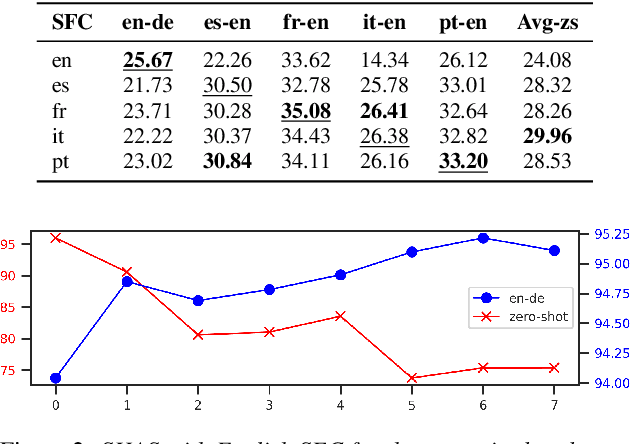
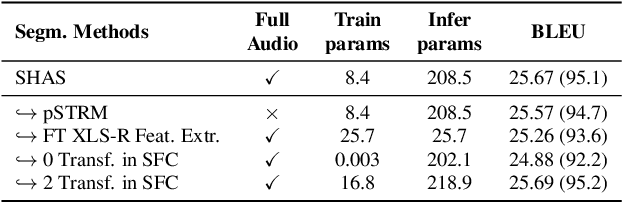
Speech translation models are unable to directly process long audios, like TED talks, which have to be split into shorter segments. Speech translation datasets provide manual segmentations of the audios, which are not available in real-world scenarios, and existing segmentation methods usually significantly reduce translation quality at inference time. To bridge the gap between the manual segmentation of training and the automatic one at inference, we propose Supervised Hybrid Audio Segmentation (SHAS), a method that can effectively learn the optimal segmentation from any manually segmented speech corpus. First, we train a classifier to identify the included frames in a segmentation, using speech representations from a pre-trained wav2vec 2.0. The optimal splitting points are then found by a probabilistic Divide-and-Conquer algorithm that progressively splits at the frame of lowest probability until all segments are below a pre-specified length. Experiments on MuST-C and mTEDx show that the translation of the segments produced by our method approaches the quality of the manual segmentation on 5 languages pairs. Namely, SHAS retains 95-98% of the manual segmentation's BLEU score, compared to the 87-93% of the best existing methods. Our method is additionally generalizable to different domains and achieves high zero-shot performance in unseen languages.
Probing Statistical Representations For End-To-End ASR
Nov 03, 2022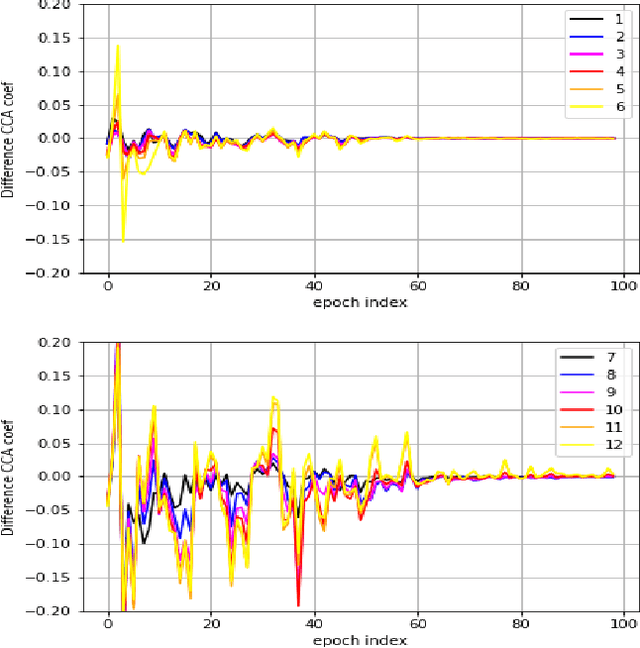
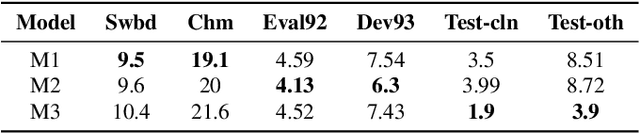
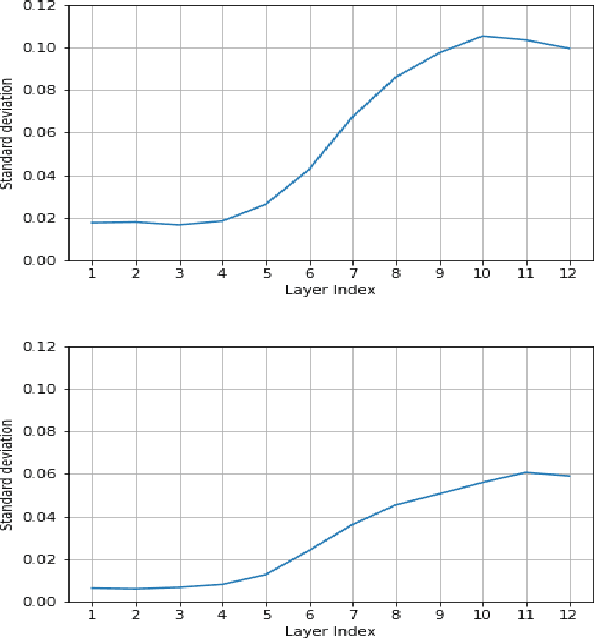
End-to-End automatic speech recognition (ASR) models aim to learn a generalised speech representation to perform recognition. In this domain there is little research to analyse internal representation dependencies and their relationship to modelling approaches. This paper investigates cross-domain language model dependencies within transformer architectures using SVCCA and uses these insights to exploit modelling approaches. It was found that specific neural representations within the transformer layers exhibit correlated behaviour which impacts recognition performance. Altogether, this work provides analysis of the modelling approaches affecting contextual dependencies and ASR performance, and can be used to create or adapt better performing End-to-End ASR models and also for downstream tasks.
Conversational Speech Separation: an Evaluation Study for Streaming Applications
May 31, 2022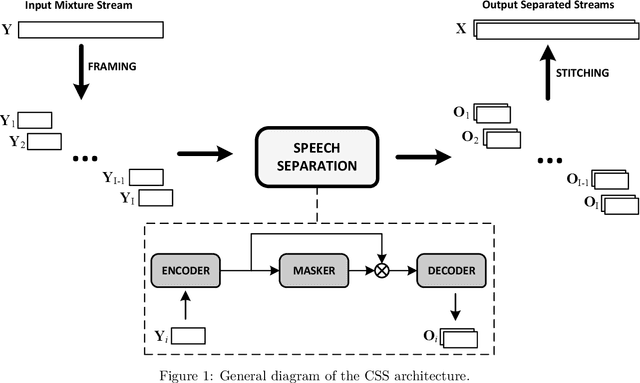
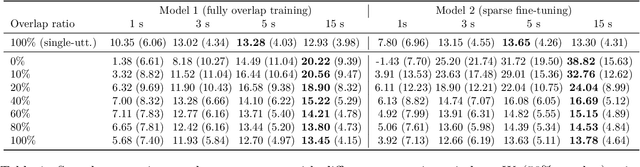
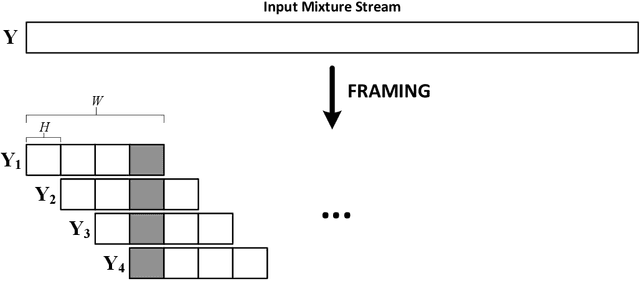
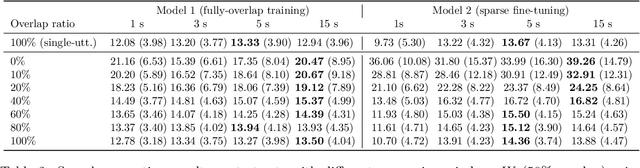
Continuous speech separation (CSS) is a recently proposed framework which aims at separating each speaker from an input mixture signal in a streaming fashion. Hereafter we perform an evaluation study on practical design considerations for a CSS system, addressing important aspects which have been neglected in recent works. In particular, we focus on the trade-off between separation performance, computational requirements and output latency showing how an offline separation algorithm can be used to perform CSS with a desired latency. We carry out an extensive analysis on the choice of CSS processing window size and hop size on sparsely overlapped data. We find out that the best trade-off between computational burden and performance is obtained for a window of 5 s.