 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improving And Analyzing Neural Speaker Embeddings for ASR
Jan 11, 2023
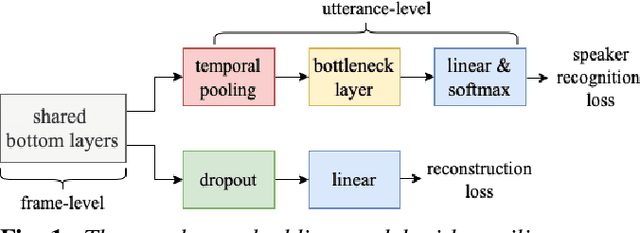
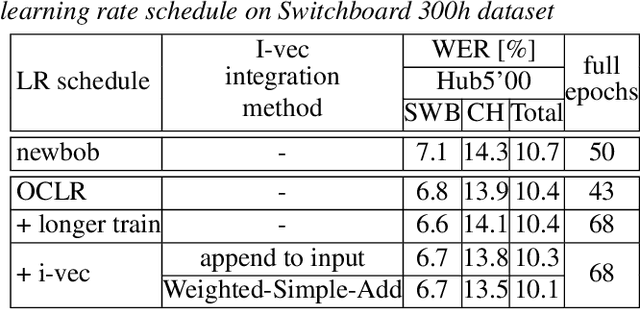
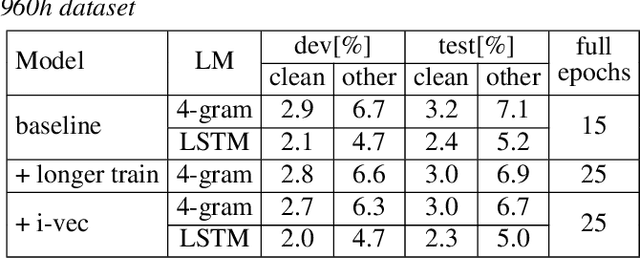
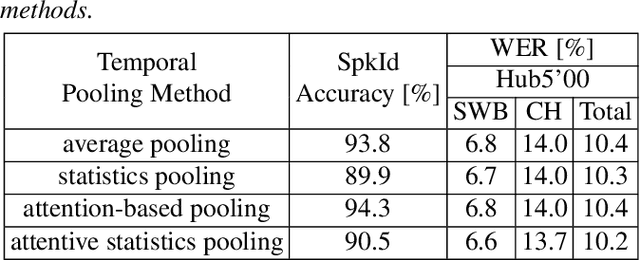
Neural speaker embeddings encode the speaker's speech characteristics through a DNN model and are prevalent for speaker verification tasks. However, few studies have investigated the usage of neural speaker embeddings for an ASR system. In this work, we present our efforts w.r.t integrating neural speaker embeddings into a conformer based hybrid HMM ASR system. For ASR, our improved embedding extraction pipeline in combination with the Weighted-Simple-Add integration method results in x-vector and c-vector reaching on par performance with i-vectors. We further compare and analyze different speaker embeddings. We present our acoustic model improvements obtained by switching from newbob learning rate schedule to one cycle learning schedule resulting in a ~3% relative WER reduction on Switchboard, additionally reducing the overall training time by 17%. By further adding neural speaker embeddings, we gain additional ~3% relative WER improvement on Hub5'00. Our best Conformer-based hybrid ASR system with speaker embeddings achieves 9.0% WER on Hub5'00 and Hub5'01 with training on SWB 300h.
Arabic Text-To-Speech (TTS) Data Preparation
Apr 07, 2022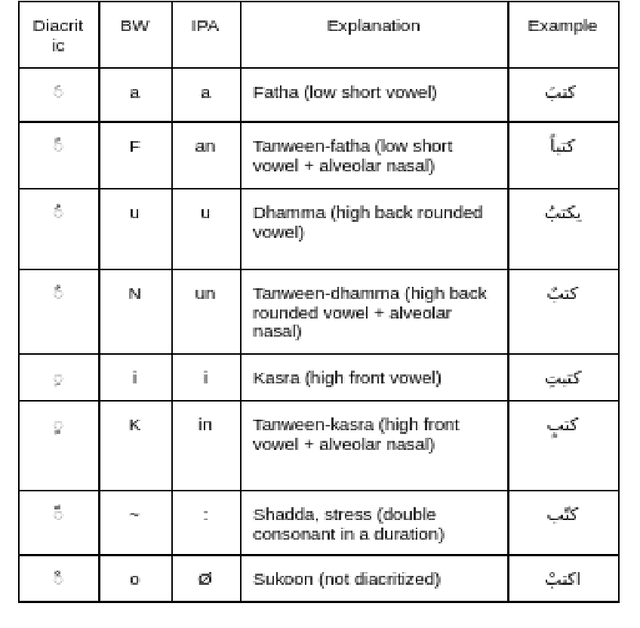
People may be puzzled by the fact that voice over recordings data sets exist in addition to Text-to-Speech (TTS), Synthesis system advancements, albeit this is not the case. The goal of this study is to explain the relevance of TTS as well as the data preparation procedures. TTS relies heavily on recorded data since it can have a substantial influence on the outcomes of TTS modules. Furthermore, whether the domain is specialized or general, appropriate data should be developed to address all predicted language variants and domains. Different recording methodologies, taking into account quality and behavior, may also be advantageous in the development of the module. In light of the lack of Arabic language in present synthesizing systems, numerous variables that impact the flow of recorded utterances are being considered in order to manipulate an Arabic TTS module. In this study, two viewpoints will be discussed: linguistics and the creation of high-quality recordings for TTS. The purpose of this work is to offer light on how ground-truth utterances may influence the evolution of speech systems in terms of naturalness, intelligibility, and understanding. Well provide voice actor specs as well as data specs that will assist both voice actors and voice coaches in the studio as well as the annotators who will be evaluating the audios.
A Comparison of Temporal Encoders for Neuromorphic Keyword Spotting with Few Neurons
Jan 24, 2023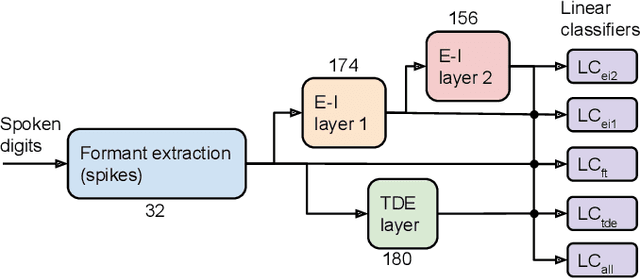
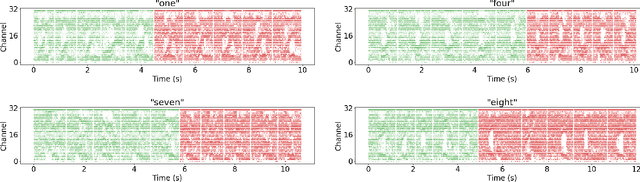
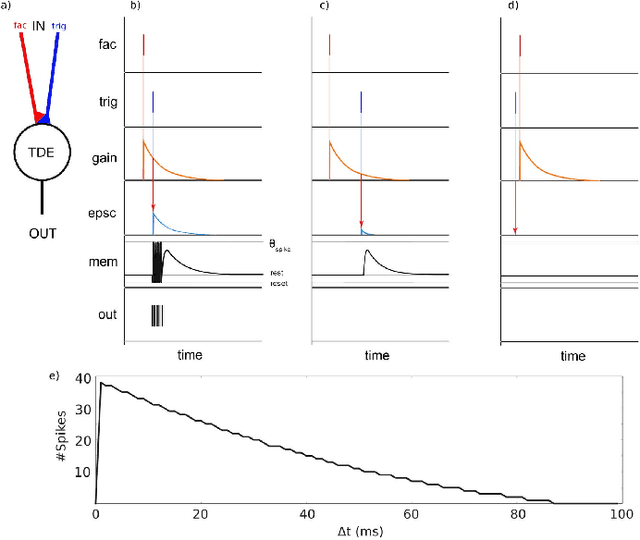
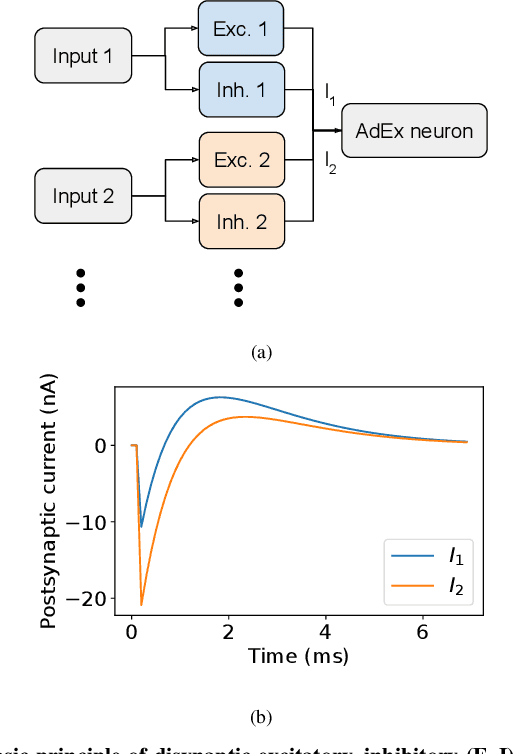
With the expansion of AI-powered virtual assistants, there is a need for low-power keyword spotting systems providing a "wake-up" mechanism for subsequent computationally expensive speech recognition. One promising approach is the use of neuromorphic sensors and spiking neural networks (SNNs) implemented in neuromorphic processors for sparse event-driven sensing. However, this requires resource-efficient SNN mechanisms for temporal encoding, which need to consider that these systems process information in a streaming manner, with physical time being an intrinsic property of their operation. In this work, two candidate neurocomputational elements for temporal encoding and feature extraction in SNNs described in recent literature - the spiking time-difference encoder (TDE) and disynaptic excitatory-inhibitory (E-I) elements - are comparatively investigated in a keyword-spotting task on formants computed from spoken digits in the TIDIGITS dataset. While both encoders improve performance over direct classification of the formant features in the training data, enabling a complete binary classification with a logistic regression model, they show no clear improvements on the test set. Resource-efficient keyword spotting applications may benefit from the use of these encoders, but further work on methods for learning the time constants and weights is required to investigate their full potential.
On Out-of-Distribution Detection for Audio with Deep Nearest Neighbors
Oct 27, 2022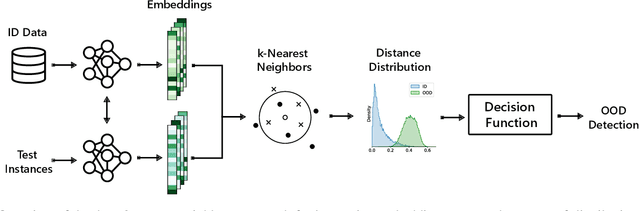
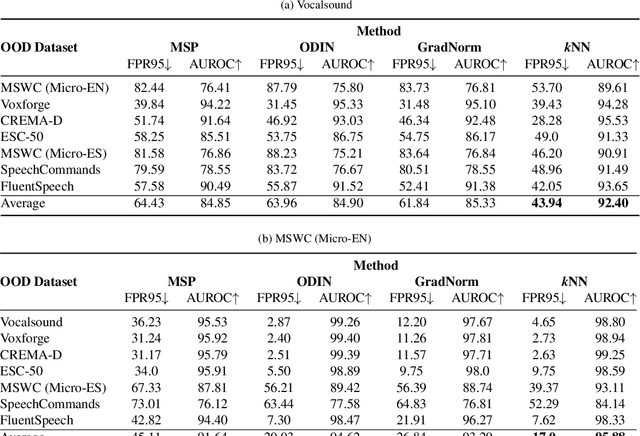
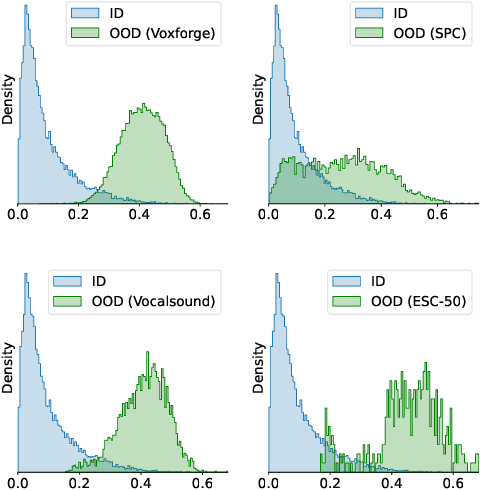
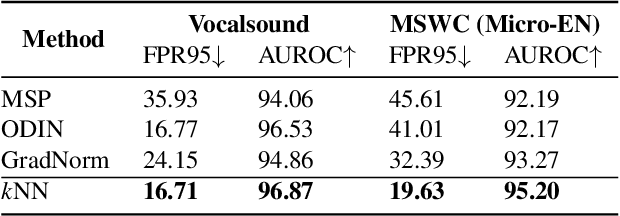
Out-of-distribution (OOD) detection is concerned with identifying data points that do not belong to the same distribution as the model's training data. For the safe deployment of predictive models in a real-world environment, it is critical to avoid making confident predictions on OOD inputs as it can lead to potentially dangerous consequences. However, OOD detection largely remains an under-explored area in the audio (and speech) domain. This is despite the fact that audio is a central modality for many tasks, such as speaker diarization, automatic speech recognition, and sound event detection. To address this, we propose to leverage feature-space of the model with deep k-nearest neighbors to detect OOD samples. We show that this simple and flexible method effectively detects OOD inputs across a broad category of audio (and speech) datasets. Specifically, it improves the false positive rate (FPR@TPR95) by 17% and the AUROC score by 7% than other prior techniques.
A review of discourse and conversation impairments in patients with dementia
Nov 15, 2022Neurodegeneration characterizes patients with different dementia subtypes (e.g., patients with Alzheimer's Disease, Primary Progressive Aphasia, and Parkinson's Disease), leading to progressive decline in cognitive, linguistic, and social functioning. Speech and language impairments are early symptoms in patients with focal forms of neurodegenerative conditions, coupled with deficits in cognitive, social, and behavioral domains. This paper reviews the findings on language and communication deficits and identifies the effects of dementia on the production and perception of discourse. It discusses findings concerning (i) language function, cognitive representation, and impairment , (ii) communicative competence, emotions, empathy, and theory-of-mind, and (iii) speech-in-interaction. It argues that clinical discourse analysis can provide a comprehensive assessment of language and communication skills in patients, which complements the existing neurolinguistic evaluation for (differential) diagnosis, prognosis, and treatment efficacy evaluation.
Pronunciation Modeling of Foreign Words for Mandarin ASR by Considering the Effect of Language Transfer
Oct 07, 2022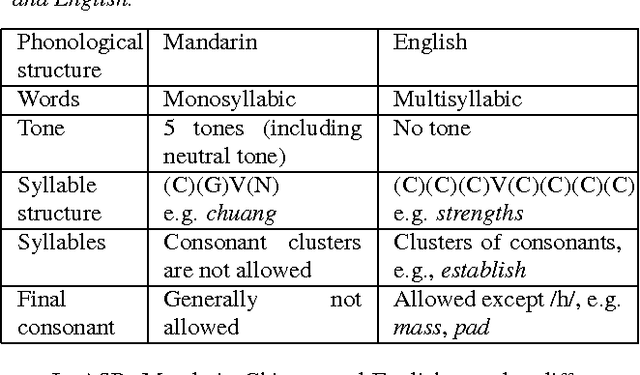
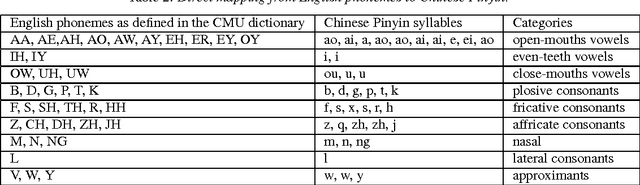

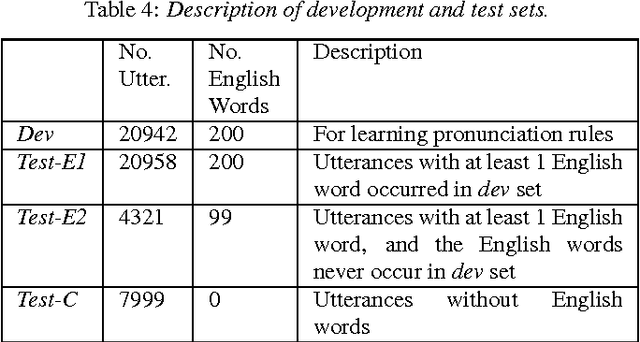
One of the challenges in automatic speech recognition is foreign words recognition. It is observed that a speaker's pronunciation of a foreign word is influenced by his native language knowledge, and such phenomenon is known as the effect of language transfer. This paper focuses on examining the phonetic effect of language transfer in automatic speech recognition. A set of lexical rules is proposed to convert an English word into Mandarin phonetic representation. In this way, a Mandarin lexicon can be augmented by including English words. Hence, the Mandarin ASR system becomes capable to recognize English words without retraining or re-estimation of the acoustic model parameters. Using the lexicon that derived from the proposed rules, the ASR performance of Mandarin English mixed speech is improved without harming the accuracy of Mandarin only speech. The proposed lexical rules are generalized and they can be directly applied to unseen English words.
Speech intelligibility of simulated hearing loss sounds and its prediction using the Gammachirp Envelope Similarity Index (GESI)
Jun 14, 2022
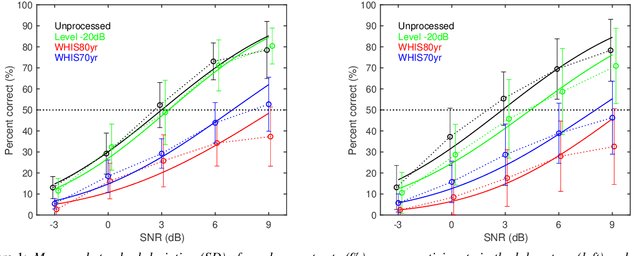
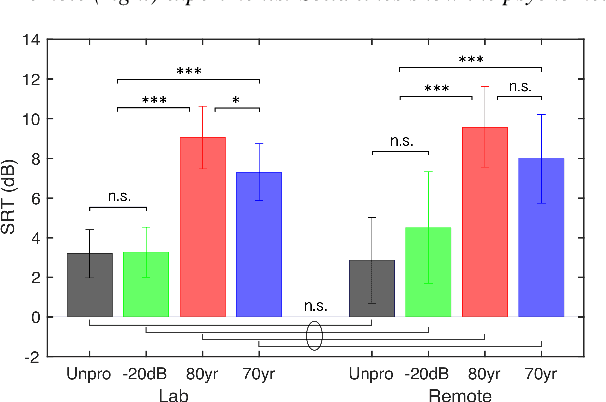
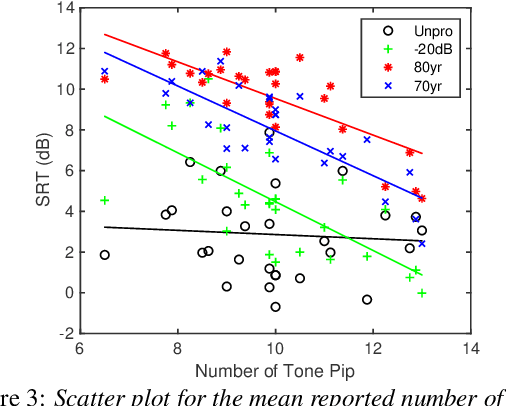
In the present study, speech intelligibility (SI) experiments were performed using simulated hearing loss (HL) sounds in laboratory and remote environments to clarify the effects of peripheral dysfunction. Noisy speech sounds were processed to simulate the average HL of 70- and 80-year-olds using Wadai Hearing Impairment Simulator (WHIS). These sounds were presented to normal hearing (NH) listeners whose cognitive function could be assumed to be normal. The results showed that the divergence was larger in the remote experiments than in the laboratory ones. However, the remote results could be equalized to the laboratory ones, mostly through data screening using the results of tone pip tests prepared on the experimental web page. In addition, a newly proposed objective intelligibility measure (OIM) called the Gammachirp Envelope Similarity Index (GESI) explained the psychometric functions in the laboratory and remote experiments fairly well. GESI has the potential to explain the SI of HI listeners by properly setting HL parameters.
Dual-Path Style Learning for End-to-End Noise-Robust Speech Recognition
Mar 28, 2022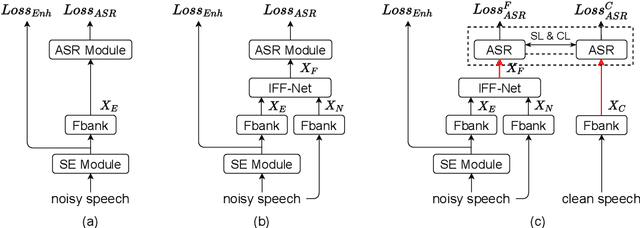

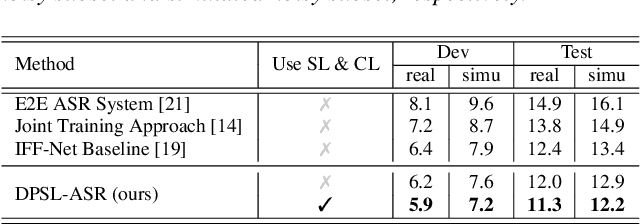
Noise-robust automatic speech recognition degrades significantly in face of over-suppression problem, which usually exists in the front-end speech enhancement module. To alleviate such issue, we propose novel dual-path style learning for end-to-end noise-robust automatic speech recognition (DPSL-ASR). Specifically, the proposed DPSL-ASR approach introduces clean feature along with fused feature by the IFF-Net as dual-path inputs to recover the over-suppressed information. Furthermore, we propose style learning to learn abundant details and latent information by mapping fused feature to clean feature. Besides, we also utilize the consistency loss to minimize the distance of decoded embeddings between two paths. Experimental results show that the proposed DPSL-ASR approach achieves relative word error rate (WER) reductions of 10.6% and 8.6%, on RATS Channel-A dataset and CHiME-4 1-Channel Track dataset, respectively. The visualizations of intermediate embeddings also indicate that the proposed DPSL-ASR can learn more details than the best baseline. Our code implementation is available at Github: https://github.com/YUCHEN005/DPSL-ASR.
Beyond Statistical Similarity: Rethinking Metrics for Deep Generative Models in Engineering Design
Feb 06, 2023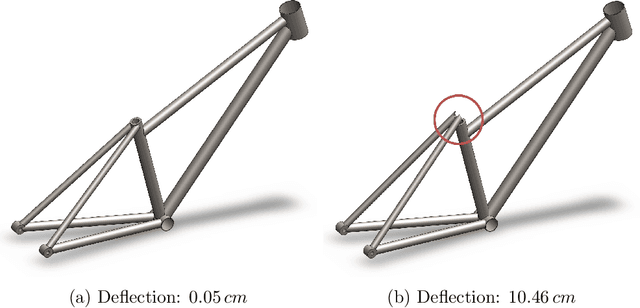
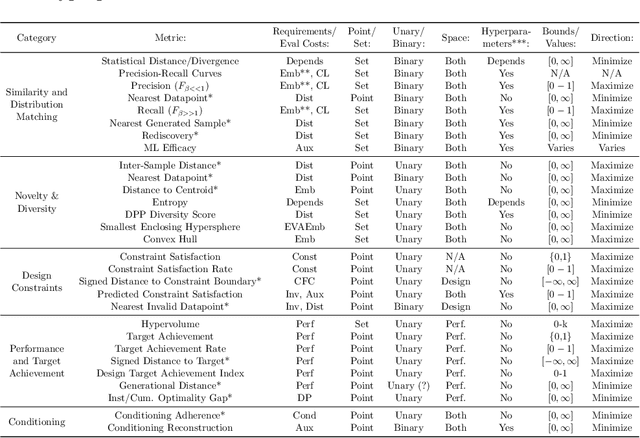
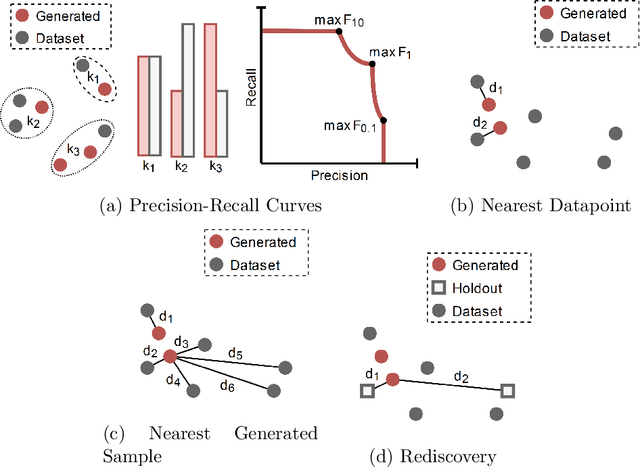
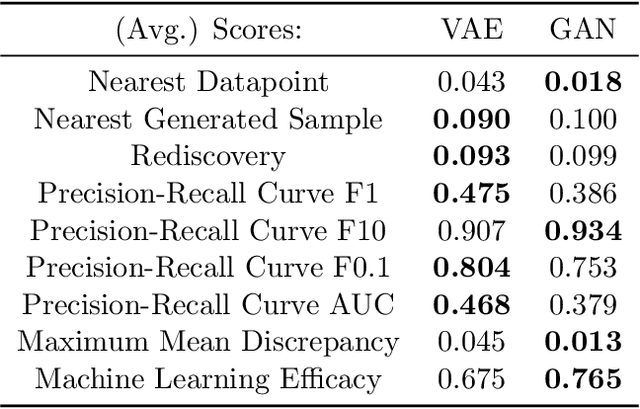
Deep generative models, such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), Diffusion Models, and Transformers, have shown great promise in a variety of applications, including image and speech synthesis, natural language processing, and drug discovery. However, when applied to engineering design problems, evaluating the performance of these models can be challenging, as traditional statistical metrics based on likelihood may not fully capture the requirements of engineering applications. This paper doubles as a review and a practical guide to evaluation metrics for deep generative models (DGMs) in engineering design. We first summarize well-accepted `classic' evaluation metrics for deep generative models grounded in machine learning theory and typical computer science applications. Using case studies, we then highlight why these metrics seldom translate well to design problems but see frequent use due to the lack of established alternatives. Next, we curate a set of design-specific metrics which have been proposed across different research communities and can be used for evaluating deep generative models. These metrics focus on unique requirements in design and engineering, such as constraint satisfaction, functional performance, novelty, and conditioning. We structure our review and discussion as a set of practical selection criteria and usage guidelines. Throughout our discussion, we apply the metrics to models trained on simple 2-dimensional example problems. Finally, to illustrate the selection process and classic usage of the presented metrics, we evaluate three deep generative models on a multifaceted bicycle frame design problem considering performance target achievement, design novelty, and geometric constraints. We publicly release the code for the datasets, models, and metrics used throughout the paper at decode.mit.edu/projects/metrics/.
VCSE: Time-Domain Visual-Contextual Speaker Extraction Network
Oct 09, 2022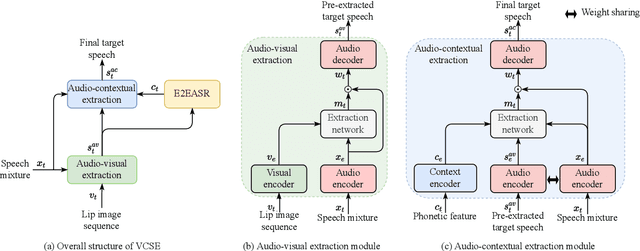
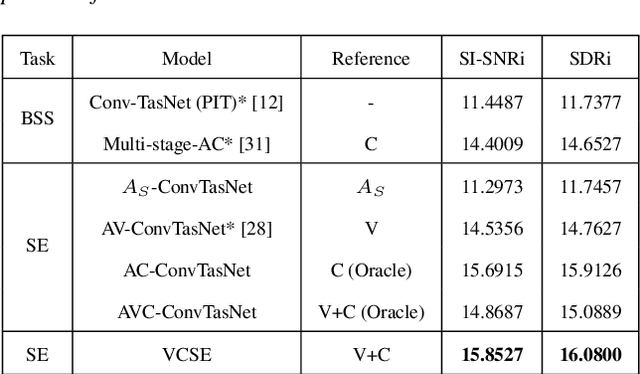
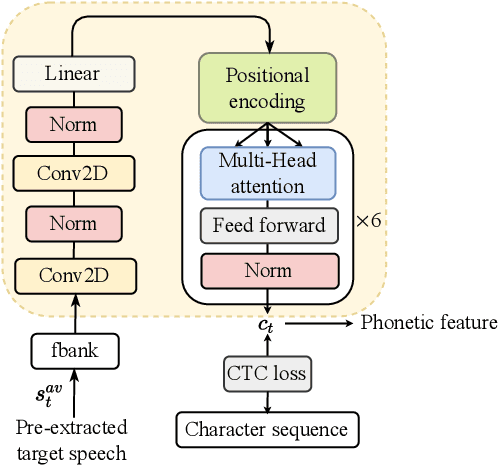
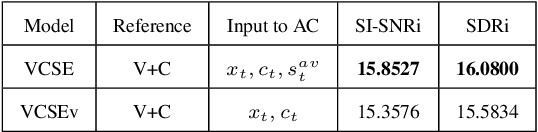
Speaker extraction seeks to extract the target speech in a multi-talker scenario given an auxiliary reference. Such reference can be auditory, i.e., a pre-recorded speech, visual, i.e., lip movements, or contextual, i.e., phonetic sequence. References in different modalities provide distinct and complementary information that could be fused to form top-down attention on the target speaker. Previous studies have introduced visual and contextual modalities in a single model. In this paper, we propose a two-stage time-domain visual-contextual speaker extraction network named VCSE, which incorporates visual and self-enrolled contextual cues stage by stage to take full advantage of every modality. In the first stage, we pre-extract a target speech with visual cues and estimate the underlying phonetic sequence. In the second stage, we refine the pre-extracted target speech with the self-enrolled contextual cues. Experimental results on the real-world Lip Reading Sentences 3 (LRS3) database demonstrate that our proposed VCSE network consistently outperforms other state-of-the-art baselines.