 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Listen only to me! How well can target speech extraction handle false alarms?
Apr 11, 2022
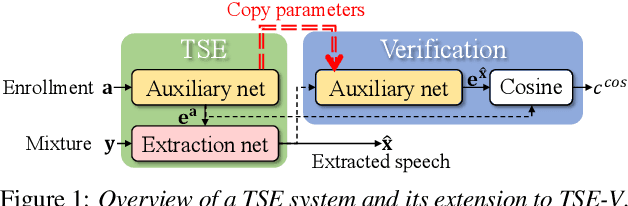
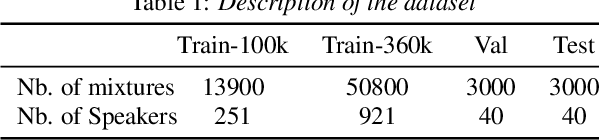
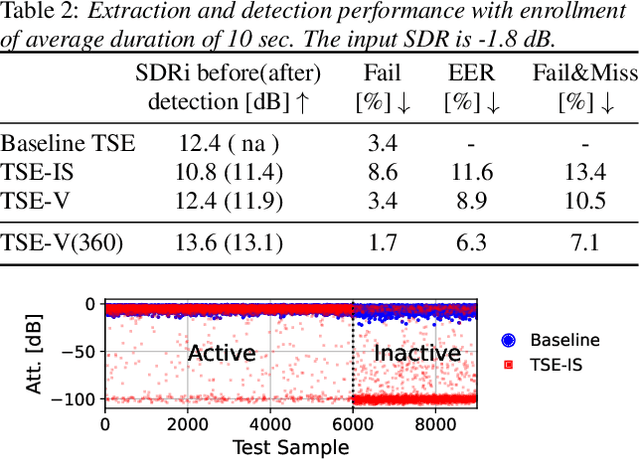
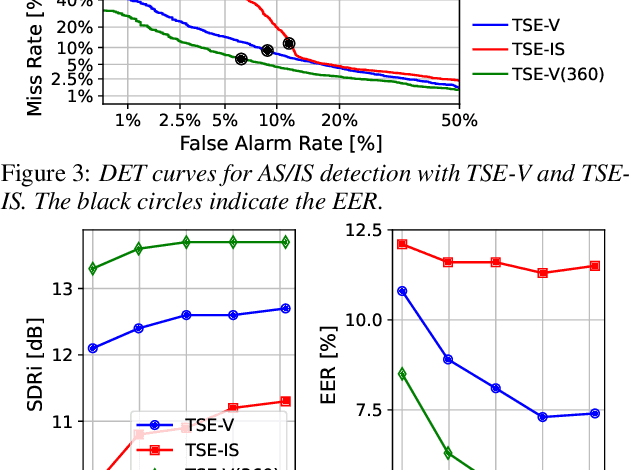
Target speech extraction (TSE) extracts the speech of a target speaker in a mixture given auxiliary clues characterizing the speaker, such as an enrollment utterance. TSE addresses thus the challenging problem of simultaneously performing separation and speaker identification. There has been much progress in extraction performance following the recent development of neural networks for speech enhancement and separation. Most studies have focused on processing mixtures where the target speaker is actively speaking. However, the target speaker is sometimes silent in practice, i.e., inactive speaker (IS). A typical TSE system will tend to output a signal in IS cases, causing false alarms. This is a severe problem for the practical deployment of TSE systems. This paper aims at understanding better how well TSE systems can handle IS cases. We consider two approaches to deal with IS, (1) training a system to directly output zero signals or (2) detecting IS with an extra speaker verification module. We perform an extensive experimental comparison of these schemes in terms of extraction performance and IS detection using the LibriMix dataset and reveal their pros and cons.
Alignment Entropy Regularization
Dec 22, 2022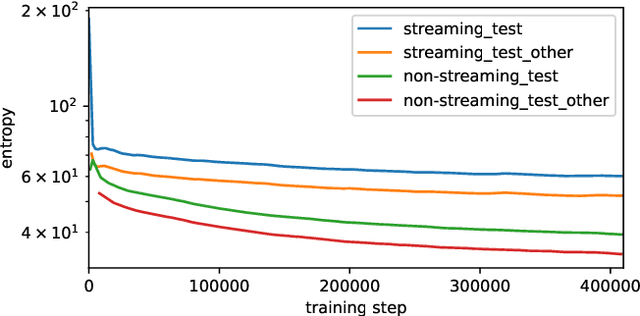
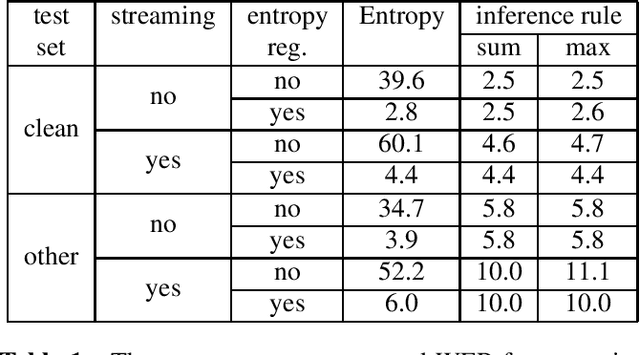
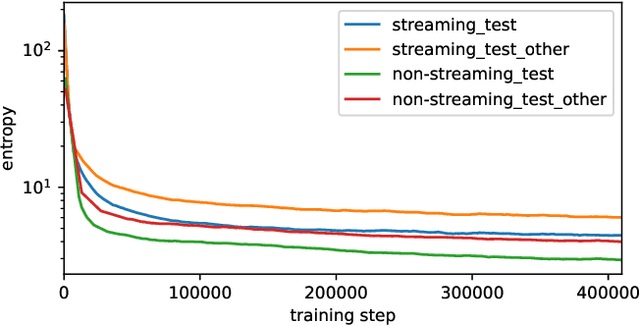
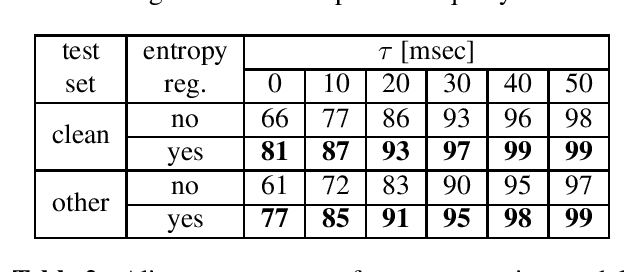
Existing training criteria in automatic speech recognition(ASR) permit the model to freely explore more than one time alignments between the feature and label sequences. In this paper, we use entropy to measure a model's uncertainty, i.e. how it chooses to distribute the probability mass over the set of allowed alignments. Furthermore, we evaluate the effect of entropy regularization in encouraging the model to distribute the probability mass only on a smaller subset of allowed alignments. Experiments show that entropy regularization enables a much simpler decoding method without sacrificing word error rate, and provides better time alignment quality.
Korean Tokenization for Beam Search Rescoring in Speech Recognition
Feb 22, 2022
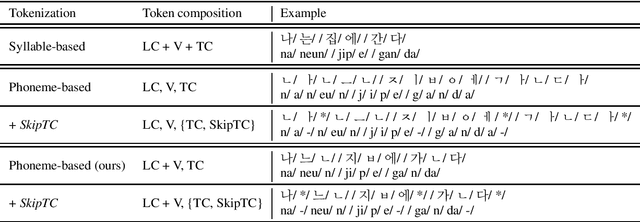
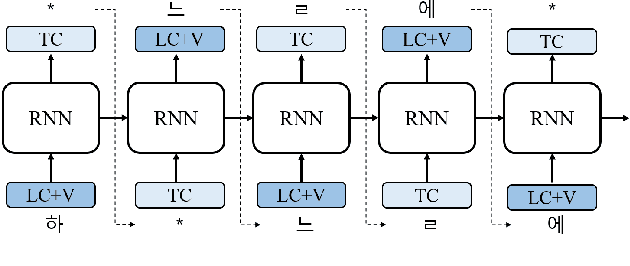
The performance of automatic speech recognition (ASR) models can be greatly improved by proper beam-search decoding with external language model (LM). There has been an increasing interest in Korean speech recognition, but not many studies have been focused on the decoding procedure. In this paper, we propose a Korean tokenization method for neural network-based LM used for Korean ASR. Although the common approach is to use the same tokenization method for external LM as the ASR model, we show that it may not be the best choice for Korean. We propose a new tokenization method that inserts a special token, SkipTC, when there is no trailing consonant in a Korean syllable. By utilizing the proposed SkipTC token, the input sequence for LM becomes very regularly patterned so that the LM can better learn the linguistic characteristics. Our experiments show that the proposed approach achieves a lower word error rate compared to the same LM model without SkipTC. In addition, we are the first to report the ASR performance for the recently introduced large-scale 7,600h Korean speech dataset.
VoiceFixer: Toward General Speech Restoration with Neural Vocoder
Oct 05, 2021
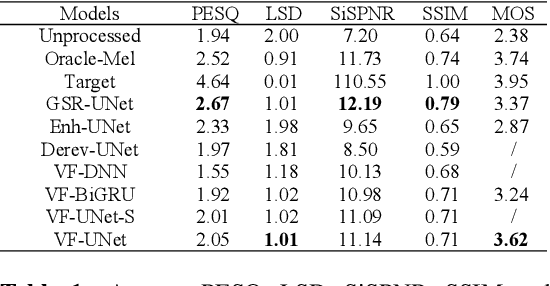
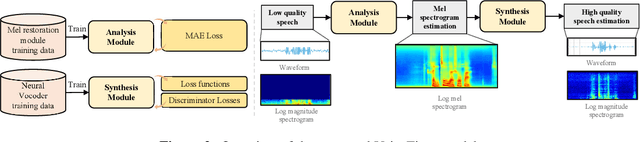
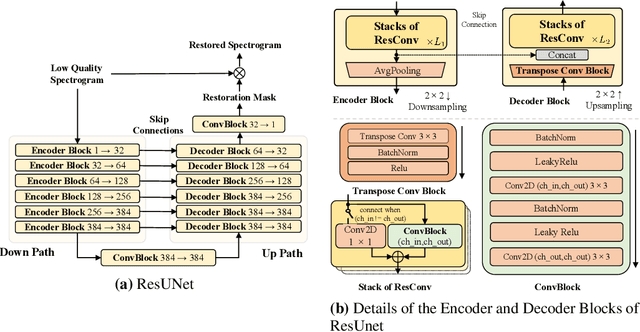
Speech restoration aims to remove distortions in speech signals. Prior methods mainly focus on single-task speech restoration (SSR), such as speech denoising or speech declipping. However, SSR systems only focus on one task and do not address the general speech restoration problem. In addition, previous SSR systems show limited performance in some speech restoration tasks such as speech super-resolution. To overcome those limitations, we propose a general speech restoration (GSR) task that attempts to remove multiple distortions simultaneously. Furthermore, we propose VoiceFixer, a generative framework to address the GSR task. VoiceFixer consists of an analysis stage and a synthesis stage to mimic the speech analysis and comprehension of the human auditory system. We employ a ResUNet to model the analysis stage and a neural vocoder to model the synthesis stage. We evaluate VoiceFixer with additive noise, room reverberation, low-resolution, and clipping distortions. Our baseline GSR model achieves a 0.499 higher mean opinion score (MOS) than the speech enhancement SSR model. VoiceFixer further surpasses the GSR baseline model on the MOS score by 0.256. Moreover, we observe that VoiceFixer generalizes well to severely degraded real speech recordings, indicating its potential in restoring old movies and historical speeches. The source code is available at https://github.com/haoheliu/voicefixer_main.
Overlapping Word Removal is All You Need: Revisiting Data Imbalance in Hope Speech Detection
Apr 12, 2022
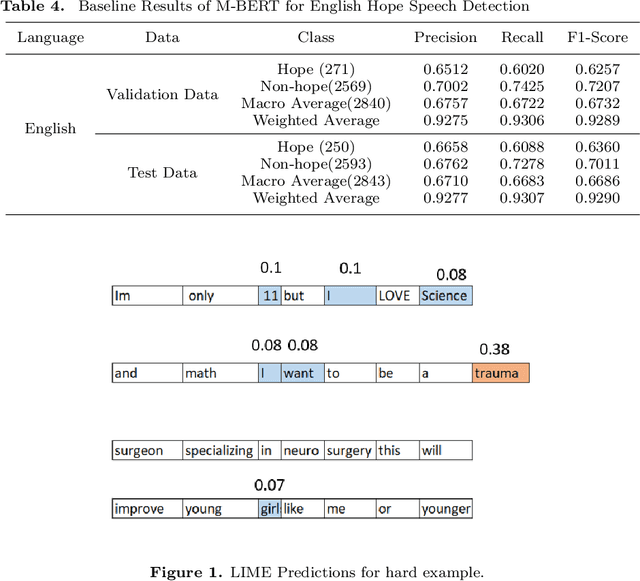
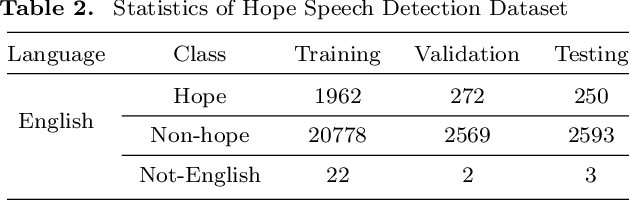

Hope Speech Detection, a task of recognizing positive expressions, has made significant strides recently. However, much of the current works focus on model development without considering the issue of inherent imbalance in the data. Our work revisits this issue in hope-speech detection by introducing focal loss, data augmentation, and pre-processing strategies. Accordingly, we find that introducing focal loss as part of Multilingual-BERT's (M-BERT) training process mitigates the effect of class imbalance and improves overall F1-Macro by 0.11. At the same time, contextual and back-translation-based word augmentation with M-BERT improves results by 0.10 over baseline despite imbalance. Finally, we show that overlapping word removal based on pre-processing, though simple, improves F1-Macro by 0.28. In due process, we present detailed studies depicting various behaviors of each of these strategies and summarize key findings from our empirical results for those interested in getting the most out of M-BERT for hope speech detection under real-world conditions of data imbalance.
AERO: Audio Super Resolution in the Spectral Domain
Nov 22, 2022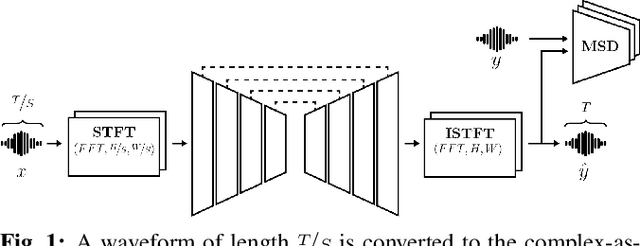
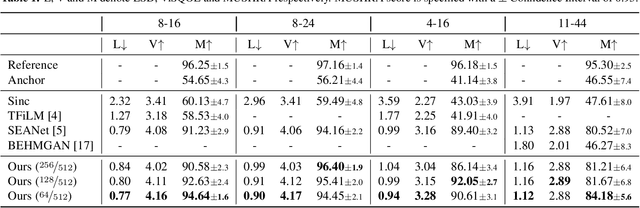
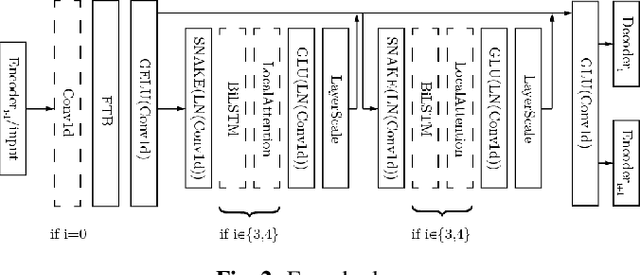
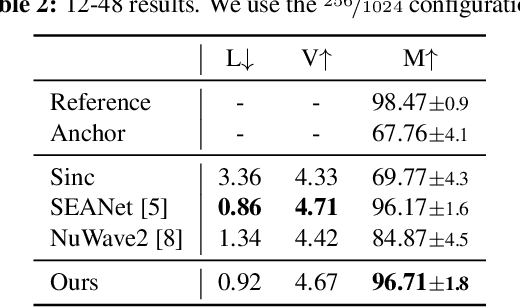
We present AERO, a audio super-resolution model that processes speech and music signals in the spectral domain. AERO is based on an encoder-decoder architecture with U-Net like skip connections. We optimize the model using both time and frequency domain loss functions. Specifically, we consider a set of reconstruction losses together with perceptual ones in the form of adversarial and feature discriminator loss functions. To better handle phase information the proposed method operates over the complex-valued spectrogram using two separate channels. Unlike prior work which mainly considers low and high frequency concatenation for audio super-resolution, the proposed method directly predicts the full frequency range. We demonstrate high performance across a wide range of sample rates considering both speech and music. AERO outperforms the evaluated baselines considering Log-Spectral Distance, ViSQOL, and the subjective MUSHRA test. Audio samples and code are available at https://pages.cs.huji.ac.il/adiyoss-lab/aero
EEND-SS: Joint End-to-End Neural Speaker Diarization and Speech Separation for Flexible Number of Speakers
Mar 31, 2022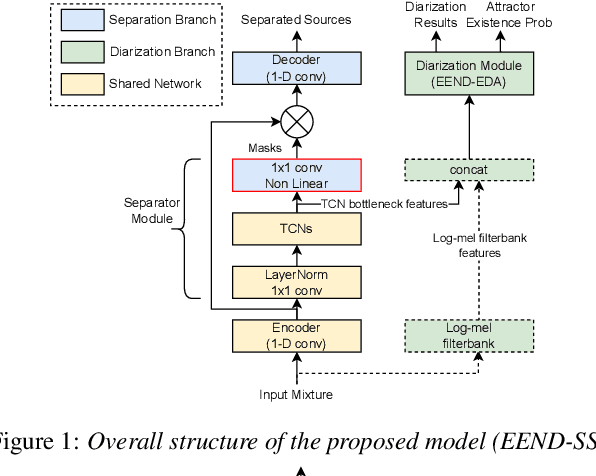
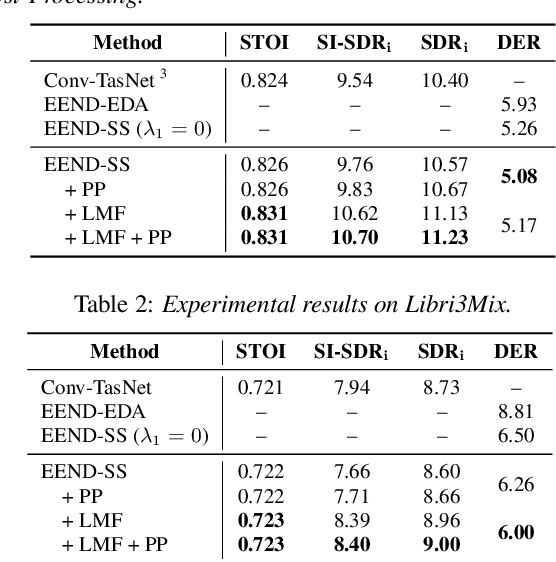

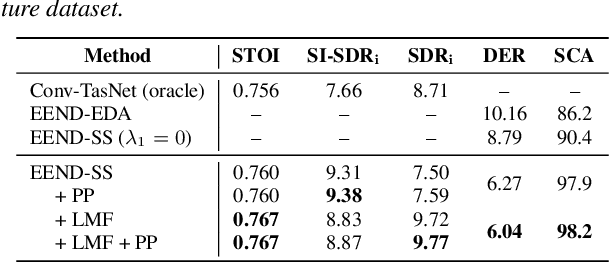
In this paper, we present a novel framework that jointly performs speaker diarization, speech separation, and speaker counting. Our proposed method combines end-to-end speaker diarization and speech separation methods, namely, End-to-End Neural Speaker Diarization with Encoder-Decoder-based Attractor calculation (EEND-EDA) and the Convolutional Time-domain Audio Separation Network (ConvTasNet) as multi-tasking joint model. We also propose the multiple 1x1 convolutional layer architecture for estimating the separation masks corresponding to the number of speakers, and a post-processing technique for refining the separated speech signal with speech activity. Experiments using LibriMix dataset show that our proposed method outperforms the baselines in terms of diarization and separation performance for both fixed and flexible numbers of speakers, as well as speaker counting performance for flexible numbers of speakers. All materials will be open-sourced and reproducible in ESPnet toolkit.
Voice Filter: Few-shot text-to-speech speaker adaptation using voice conversion as a post-processing module
Feb 16, 2022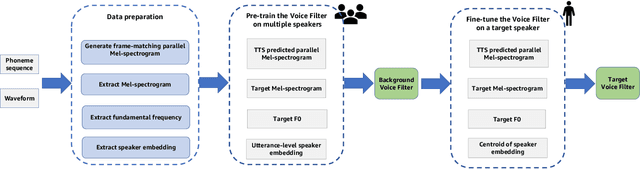

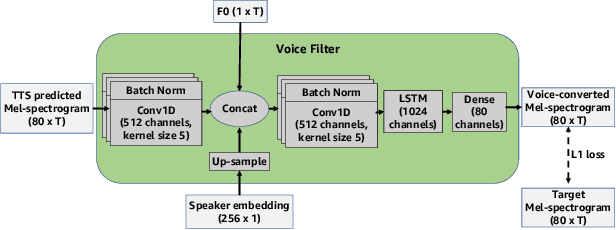

State-of-the-art text-to-speech (TTS) systems require several hours of recorded speech data to generate high-quality synthetic speech. When using reduced amounts of training data, standard TTS models suffer from speech quality and intelligibility degradations, making training low-resource TTS systems problematic. In this paper, we propose a novel extremely low-resource TTS method called Voice Filter that uses as little as one minute of speech from a target speaker. It uses voice conversion (VC) as a post-processing module appended to a pre-existing high-quality TTS system and marks a conceptual shift in the existing TTS paradigm, framing the few-shot TTS problem as a VC task. Furthermore, we propose to use a duration-controllable TTS system to create a parallel speech corpus to facilitate the VC task. Results show that the Voice Filter outperforms state-of-the-art few-shot speech synthesis techniques in terms of objective and subjective metrics on one minute of speech on a diverse set of voices, while being competitive against a TTS model built on 30 times more data.
On-device neural speech synthesis
Sep 17, 2021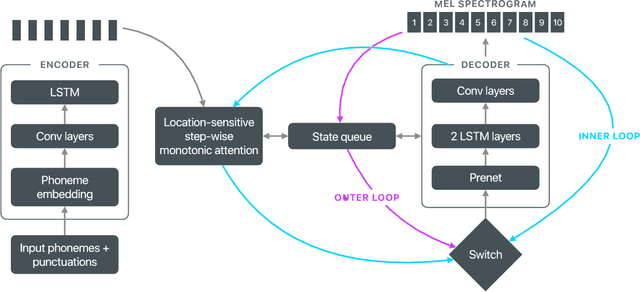

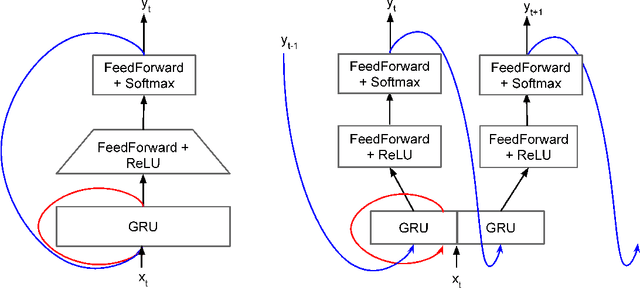
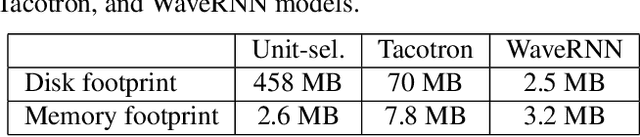
Recent advances in text-to-speech (TTS) synthesis, such as Tacotron and WaveRNN, have made it possible to construct a fully neural network based TTS system, by coupling the two components together. Such a system is conceptually simple as it only takes grapheme or phoneme input, uses Mel-spectrogram as an intermediate feature, and directly generates speech samples. The system achieves quality equal or close to natural speech. However, the high computational cost of the system and issues with robustness have limited their usage in real-world speech synthesis applications and products. In this paper, we present key modeling improvements and optimization strategies that enable deploying these models, not only on GPU servers, but also on mobile devices. The proposed system can generate high-quality 24 kHz speech at 5x faster than real time on server and 3x faster than real time on mobile devices.
Arabic Text-To-Speech (TTS) Data Preparation
Apr 07, 2022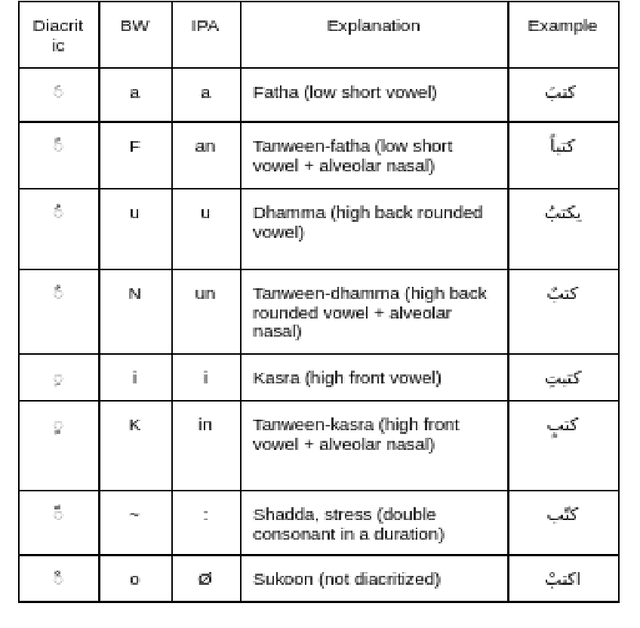
People may be puzzled by the fact that voice over recordings data sets exist in addition to Text-to-Speech (TTS), Synthesis system advancements, albeit this is not the case. The goal of this study is to explain the relevance of TTS as well as the data preparation procedures. TTS relies heavily on recorded data since it can have a substantial influence on the outcomes of TTS modules. Furthermore, whether the domain is specialized or general, appropriate data should be developed to address all predicted language variants and domains. Different recording methodologies, taking into account quality and behavior, may also be advantageous in the development of the module. In light of the lack of Arabic language in present synthesizing systems, numerous variables that impact the flow of recorded utterances are being considered in order to manipulate an Arabic TTS module. In this study, two viewpoints will be discussed: linguistics and the creation of high-quality recordings for TTS. The purpose of this work is to offer light on how ground-truth utterances may influence the evolution of speech systems in terms of naturalness, intelligibility, and understanding. Well provide voice actor specs as well as data specs that will assist both voice actors and voice coaches in the studio as well as the annotators who will be evaluating the audios.