 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Autodecompose: A generative self-supervised model for semantic decomposition
Feb 06, 2023
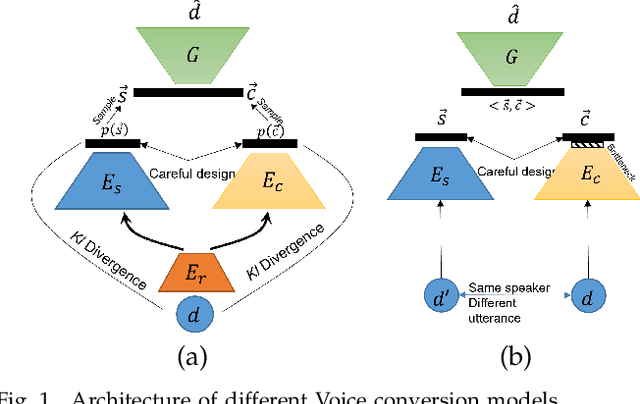

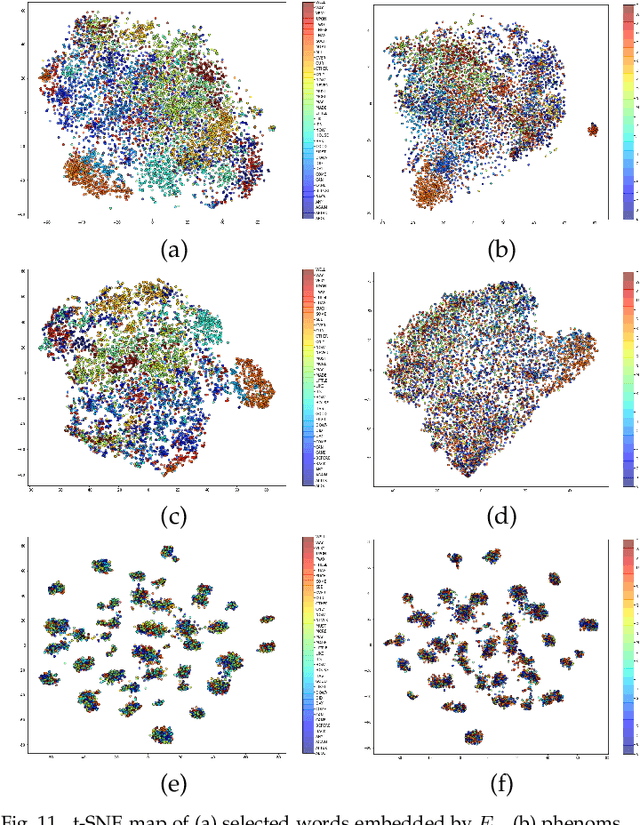
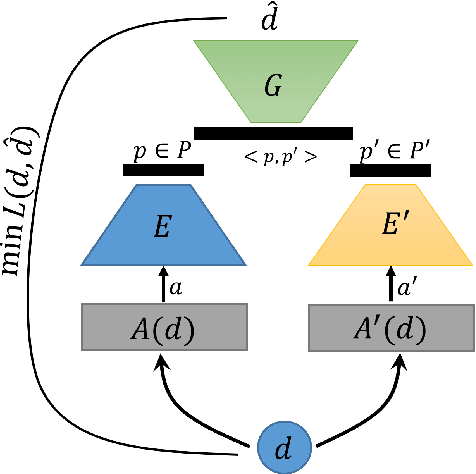
We introduce Autodecompose, a novel self-supervised generative model that decomposes data into two semantically independent properties: the desired property, which captures a specific aspect of the data (e.g. the voice in an audio signal), and the context property, which aggregates all other information (e.g. the content of the audio signal), without any labels given. Autodecompose uses two complementary augmentations, one that manipulates the context while preserving the desired property and the other that manipulates the desired property while preserving the context. The augmented variants of the data are encoded by two encoders and reconstructed by a decoder. We prove that one of the encoders embeds the desired property while the other embeds the context property. We apply Autodecompose to audio signals to encode sound source (human voice) and content. We pre-trained the model on YouTube and LibriSpeech datasets and fine-tuned in a self-supervised manner without exposing the labels. Our results showed that, using the sound source encoder of pre-trained Autodecompose, a linear classifier achieves F1 score of 97.6\% in recognizing the voice of 30 speakers using only 10 seconds of labeled samples, compared to 95.7\% for supervised models. Additionally, our experiments showed that Autodecompose is robust against overfitting even when a large model is pre-trained on a small dataset. A large Autodecompose model was pre-trained from scratch on 60 seconds of audio from 3 speakers achieved over 98.5\% F1 score in recognizing those three speakers in other unseen utterances. We finally show that the context encoder embeds information about the content of the speech and ignores the sound source information. Our sample code for training the model, as well as examples for using the pre-trained models are available here: \url{https://github.com/rezabonyadi/autodecompose}
Dual-Path Style Learning for End-to-End Noise-Robust Speech Recognition
Mar 28, 2022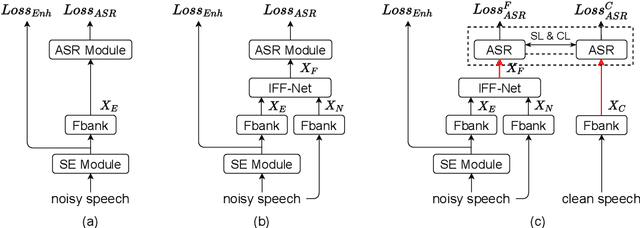

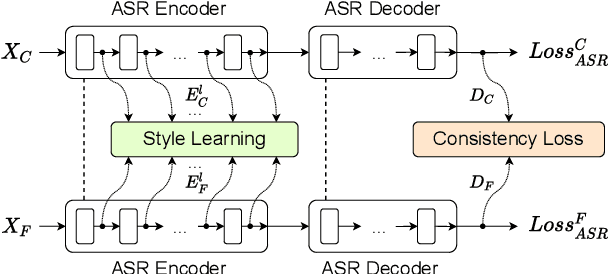
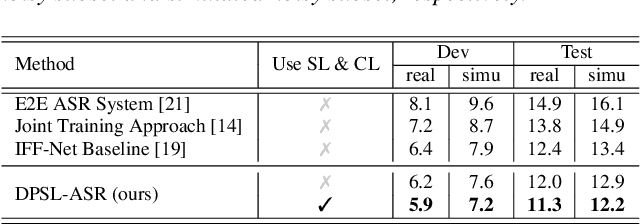
Noise-robust automatic speech recognition degrades significantly in face of over-suppression problem, which usually exists in the front-end speech enhancement module. To alleviate such issue, we propose novel dual-path style learning for end-to-end noise-robust automatic speech recognition (DPSL-ASR). Specifically, the proposed DPSL-ASR approach introduces clean feature along with fused feature by the IFF-Net as dual-path inputs to recover the over-suppressed information. Furthermore, we propose style learning to learn abundant details and latent information by mapping fused feature to clean feature. Besides, we also utilize the consistency loss to minimize the distance of decoded embeddings between two paths. Experimental results show that the proposed DPSL-ASR approach achieves relative word error rate (WER) reductions of 10.6% and 8.6%, on RATS Channel-A dataset and CHiME-4 1-Channel Track dataset, respectively. The visualizations of intermediate embeddings also indicate that the proposed DPSL-ASR can learn more details than the best baseline. Our code implementation is available at Github: https://github.com/YUCHEN005/DPSL-ASR.
Probing Statistical Representations For End-To-End ASR
Nov 03, 2022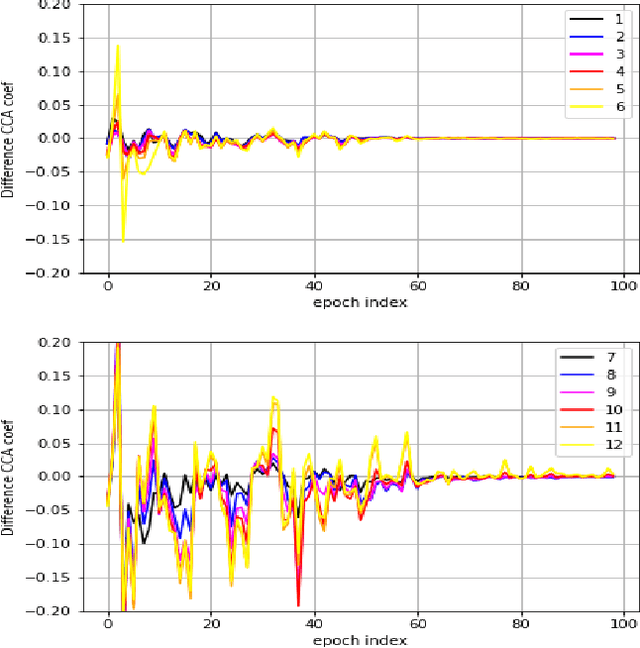
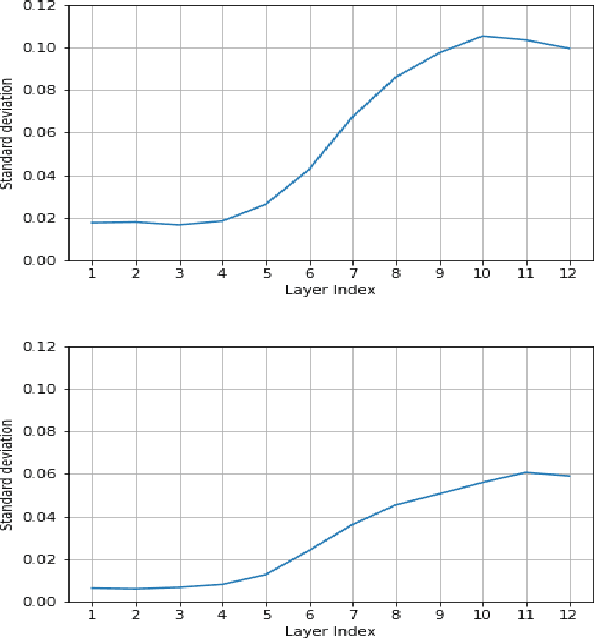
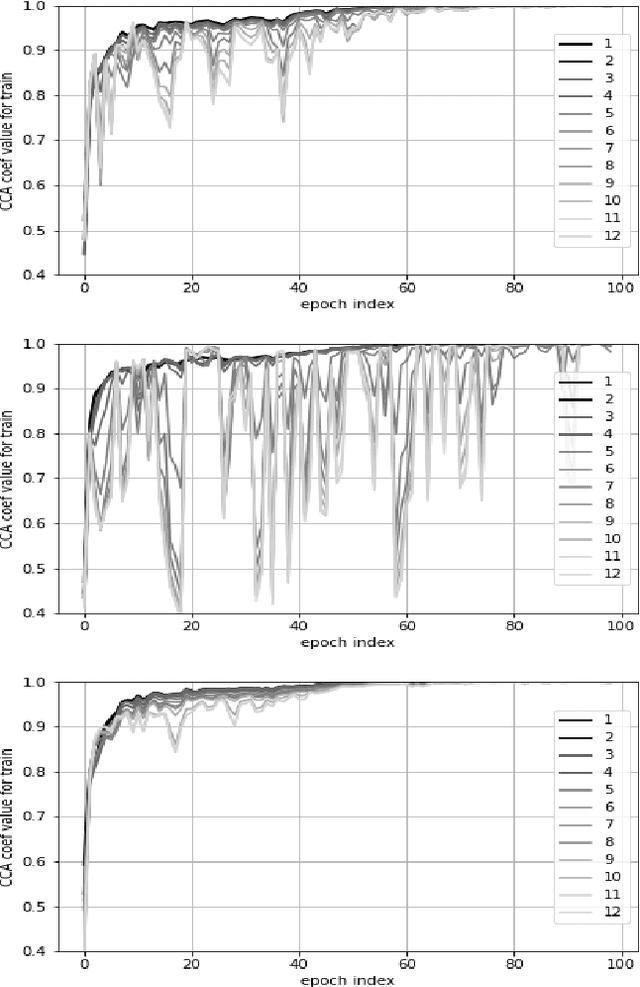
End-to-End automatic speech recognition (ASR) models aim to learn a generalised speech representation to perform recognition. In this domain there is little research to analyse internal representation dependencies and their relationship to modelling approaches. This paper investigates cross-domain language model dependencies within transformer architectures using SVCCA and uses these insights to exploit modelling approaches. It was found that specific neural representations within the transformer layers exhibit correlated behaviour which impacts recognition performance. Altogether, this work provides analysis of the modelling approaches affecting contextual dependencies and ASR performance, and can be used to create or adapt better performing End-to-End ASR models and also for downstream tasks.
On-device neural speech synthesis
Sep 17, 2021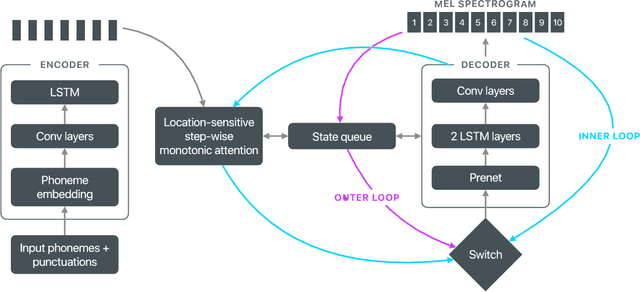

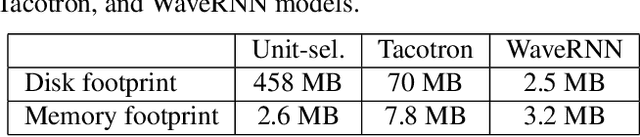
Recent advances in text-to-speech (TTS) synthesis, such as Tacotron and WaveRNN, have made it possible to construct a fully neural network based TTS system, by coupling the two components together. Such a system is conceptually simple as it only takes grapheme or phoneme input, uses Mel-spectrogram as an intermediate feature, and directly generates speech samples. The system achieves quality equal or close to natural speech. However, the high computational cost of the system and issues with robustness have limited their usage in real-world speech synthesis applications and products. In this paper, we present key modeling improvements and optimization strategies that enable deploying these models, not only on GPU servers, but also on mobile devices. The proposed system can generate high-quality 24 kHz speech at 5x faster than real time on server and 3x faster than real time on mobile devices.
Remix-cycle-consistent Learning on Adversarially Learned Separator for Accurate and Stable Unsupervised Speech Separation
Mar 26, 2022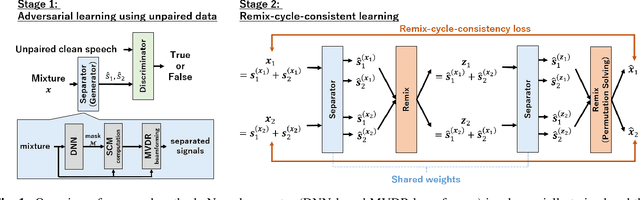
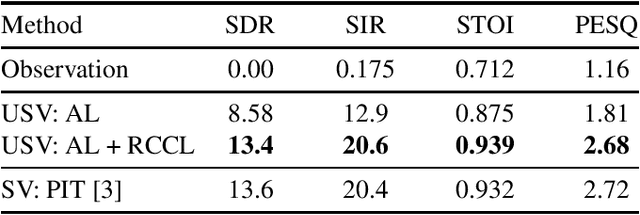

A new learning algorithm for speech separation networks is designed to explicitly reduce residual noise and artifacts in the separated signal in an unsupervised manner. Generative adversarial networks are known to be effective in constructing separation networks when the ground truth for the observed signal is inaccessible. Still, weak objectives aimed at distribution-to-distribution mapping make the learning unstable and limit their performance. This study introduces the remix-cycle-consistency loss as a more appropriate objective function and uses it to fine-tune adversarially learned source separation models. The remix-cycle-consistency loss is defined as the difference between the mixed speech observed at microphones and the pseudo-mixed speech obtained by alternating the process of separating the mixed sound and remixing its outputs with another combination. The minimization of this loss leads to an explicit reduction in the distortions in the output of the separation network. Experimental comparisons with multichannel speech separation demonstrated that the proposed method achieved high separation accuracy and learning stability comparable to supervised learning.
Predicting Affective Vocal Bursts with Finetuned wav2vec 2.0
Sep 27, 2022


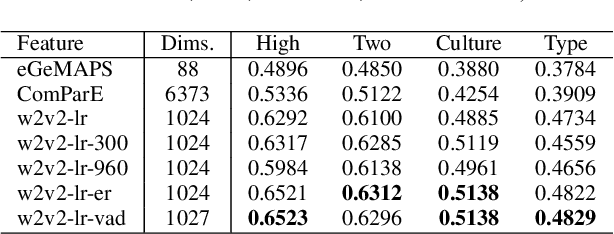
The studies of predicting affective states from human voices have relied heavily on speech. This study, indeed, explores the recognition of humans' affective state from their vocal burst, a short non-verbal vocalization. Borrowing the idea from the recent success of wav2vec 2.0, we evaluated finetuned wav2vec 2.0 models from different datasets to predict the affective state of the speaker from their vocal burst. The finetuned wav2vec 2.0 models are then trained on the vocal burst data. The results show that the finetuned wav2vec 2.0 models, particularly on an affective speech dataset, outperform the baseline model, which is handcrafted acoustic features. However, there is no large gap between the model finetuned on non-affective speech dataset and affective speech dataset.
Defense Against Adversarial Attacks on Audio DeepFake Detection
Dec 30, 2022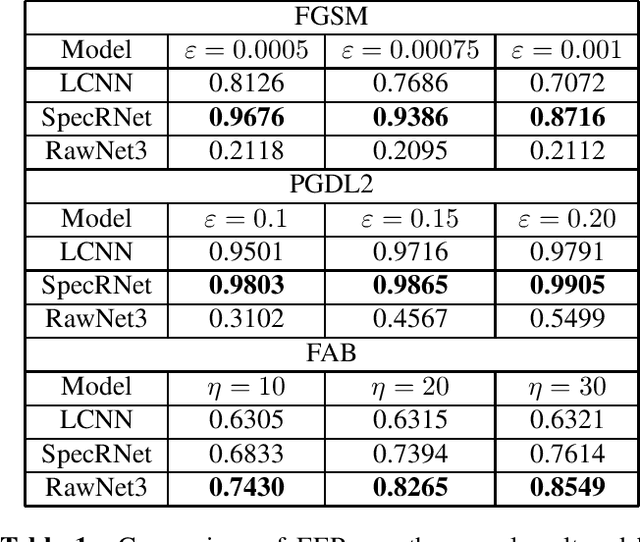
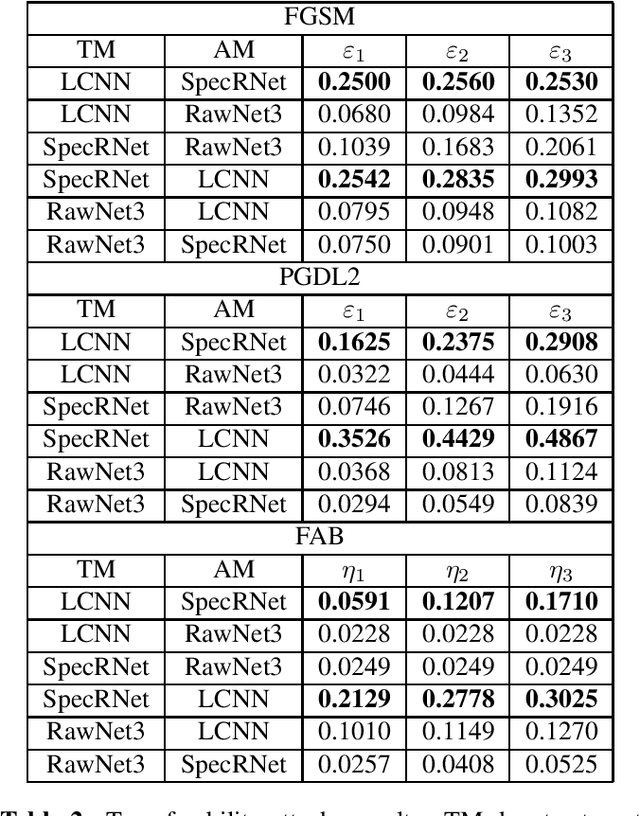
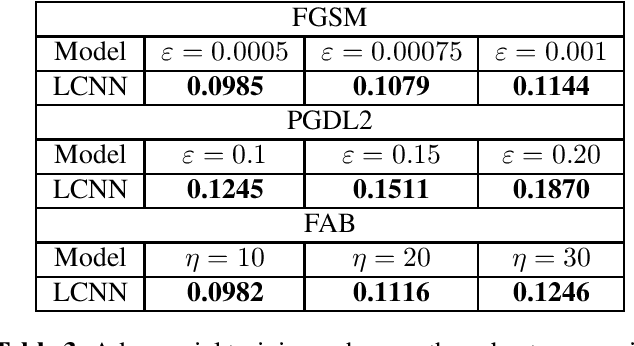
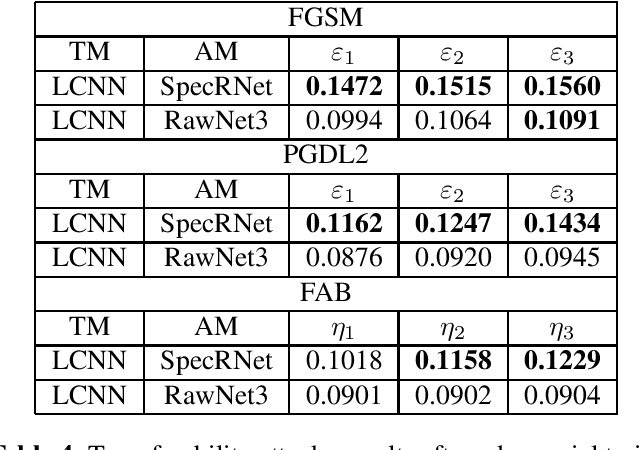
Audio DeepFakes are artificially generated utterances created using deep learning methods with the main aim to fool the listeners, most of such audio is highly convincing. Their quality is sufficient to pose a serious threat in terms of security and privacy, such as the reliability of news or defamation. To prevent the threats, multiple neural networks-based methods to detect generated speech have been proposed. In this work, we cover the topic of adversarial attacks, which decrease the performance of detectors by adding superficial (difficult to spot by a human) changes to input data. Our contribution contains evaluating the robustness of 3 detection architectures against adversarial attacks in two scenarios (white-box and using transferability mechanism) and enhancing it later by the use of adversarial training performed by our novel adaptive training method.
Conversation-oriented ASR with multi-look-ahead CBS architecture
Nov 02, 2022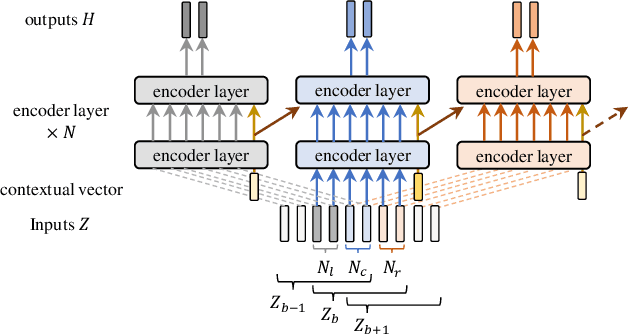
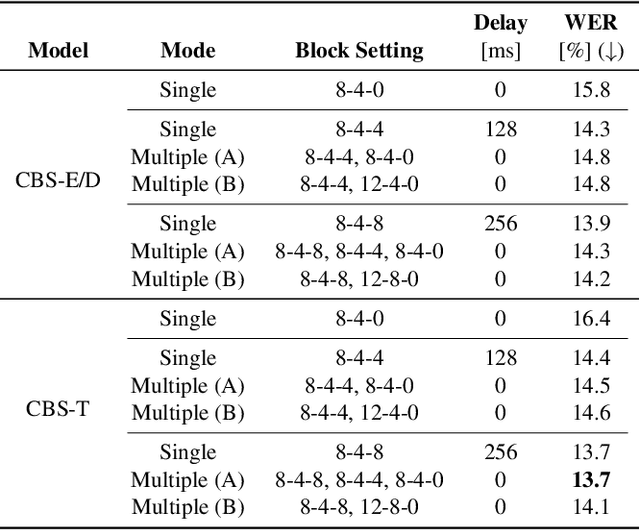
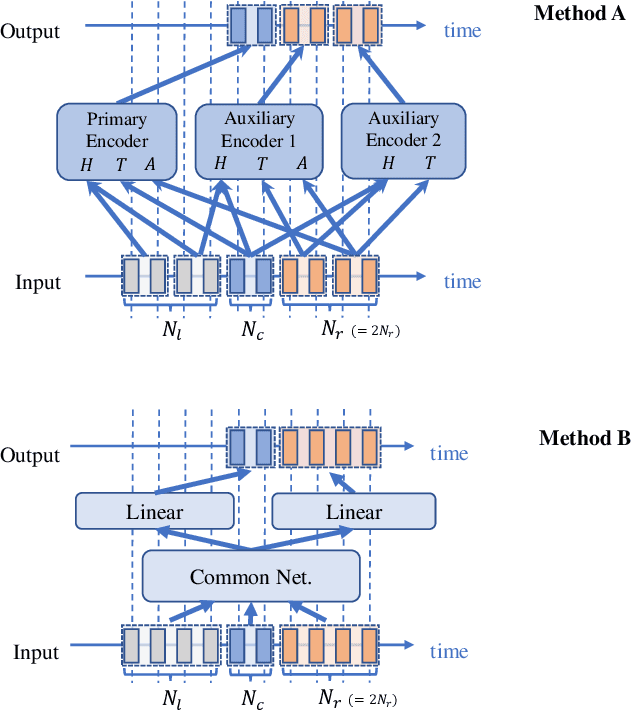
During conversations, humans are capable of inferring the intention of the speaker at any point of the speech to prepare the following action promptly. Such ability is also the key for conversational systems to achieve rhythmic and natural conversation. To perform this, the automatic speech recognition (ASR) used for transcribing the speech in real-time must achieve high accuracy without delay. In streaming ASR, high accuracy is assured by attending to look-ahead frames, which leads to delay increments. To tackle this trade-off issue, we propose a multiple latency streaming ASR to achieve high accuracy with zero look-ahead. The proposed system contains two encoders that operate in parallel, where a primary encoder generates accurate outputs utilizing look-ahead frames, and the auxiliary encoder recognizes the look-ahead portion of the primary encoder without look-ahead. The proposed system is constructed based on contextual block streaming (CBS) architecture, which leverages block processing and has a high affinity for the multiple latency architecture. Various methods are also studied for architecting the system, including shifting the network to perform as different encoders; as well as generating both encoders' outputs in one encoding pass.
Speaker Adaption with Intuitive Prosodic Features for Statistical Parametric Speech Synthesis
Mar 02, 2022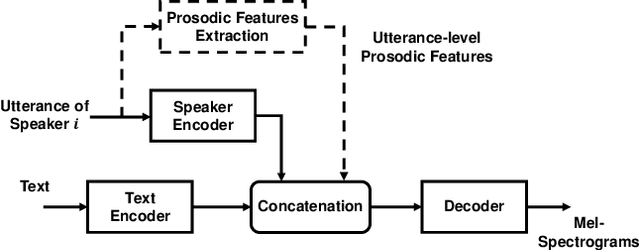
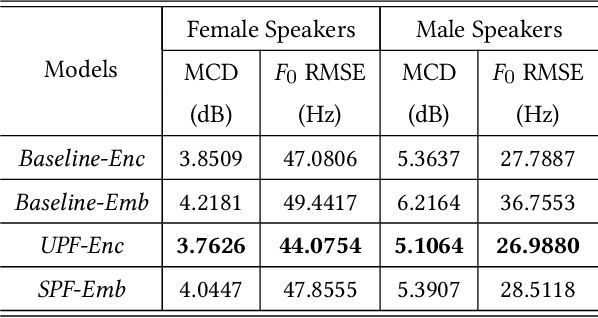
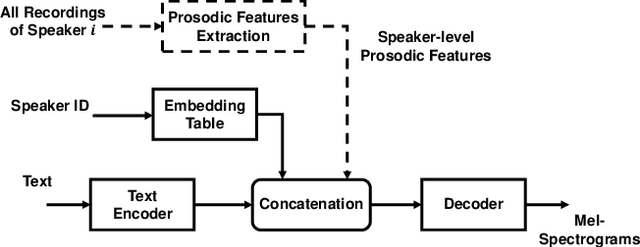
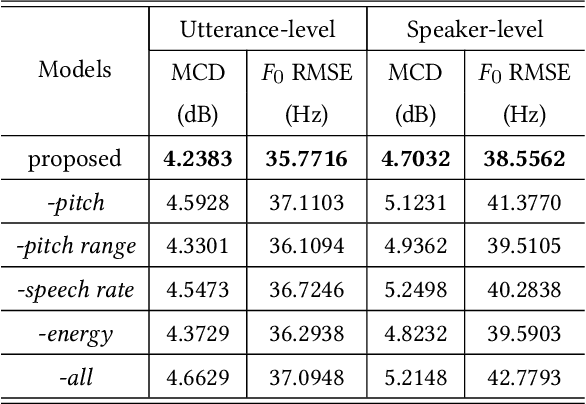
In this paper, we propose a method of speaker adaption with intuitive prosodic features for statistical parametric speech synthesis. The intuitive prosodic features employed in this method include pitch, pitch range, speech rate and energy considering that they are directly related with the overall prosodic characteristics of different speakers. The intuitive prosodic features are extracted at utterance-level or speaker-level, and are further integrated into the existing speaker-encoding-based and speaker-embedding-based adaptation frameworks respectively. The acoustic models are sequence-to-sequence ones based on Tacotron2. Intuitive prosodic features are concatenated with text encoder outputs and speaker vectors for decoding acoustic features.Experimental results have demonstrated that our proposed methods can achieve better objective and subjective performance than the baseline methods without intuitive prosodic features. Besides, the proposed speaker adaption method with utterance-level prosodic features has achieved the best similarity of synthetic speech among all compared methods.
Whose Emotion Matters? Speaker Detection without Prior Knowledge
Dec 08, 2022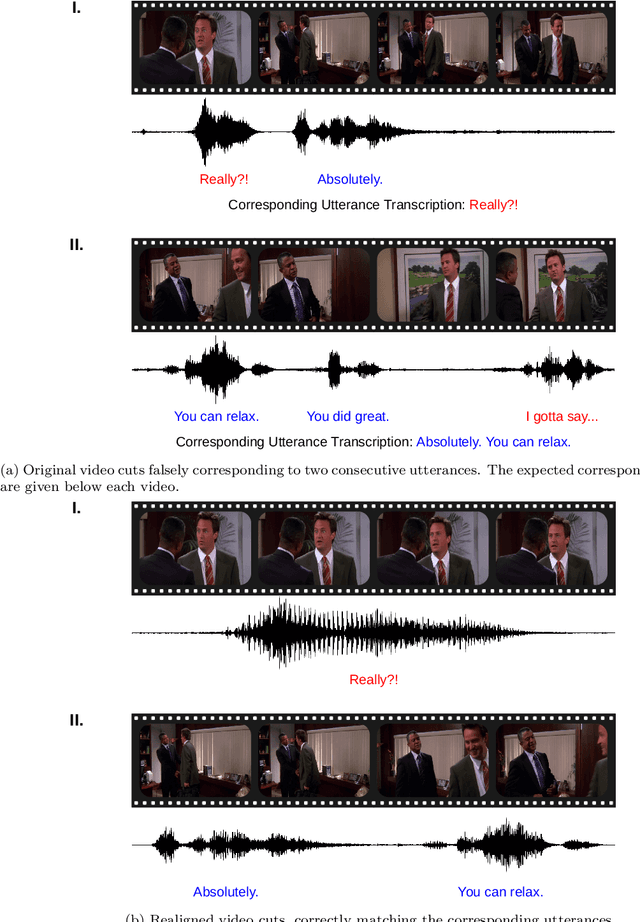

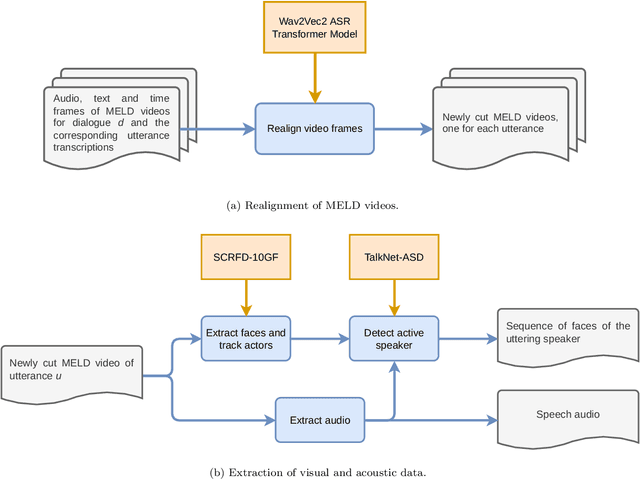
The task of emotion recognition in conversations (ERC) benefits from the availability of multiple modalities, as offered, for example, in the video-based MELD dataset. However, only a few research approaches use both acoustic and visual information from the MELD videos. There are two reasons for this: First, label-to-video alignments in MELD are noisy, making those videos an unreliable source of emotional speech data. Second, conversations can involve several people in the same scene, which requires the detection of the person speaking the utterance. In this paper we demonstrate that by using recent automatic speech recognition and active speaker detection models, we are able to realign the videos of MELD, and capture the facial expressions from uttering speakers in 96.92% of the utterances provided in MELD. Experiments with a self-supervised voice recognition model indicate that the realigned MELD videos more closely match the corresponding utterances offered in the dataset. Finally, we devise a model for emotion recognition in conversations trained on the face and audio information of the MELD realigned videos, which outperforms state-of-the-art models for ERC based on vision alone. This indicates that active speaker detection is indeed effective for extracting facial expressions from the uttering speakers, and that faces provide more informative visual cues than the visual features state-of-the-art models have been using so far.