 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
APEACH: Attacking Pejorative Expressions with Analysis on Crowd-Generated Hate Speech Evaluation Datasets
Feb 25, 2022
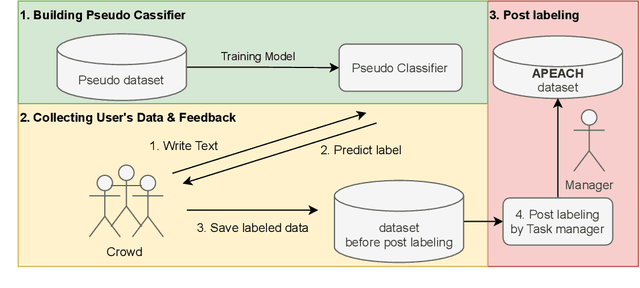
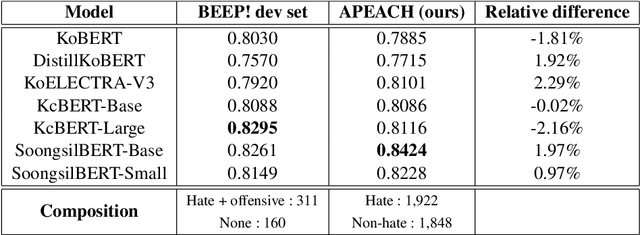
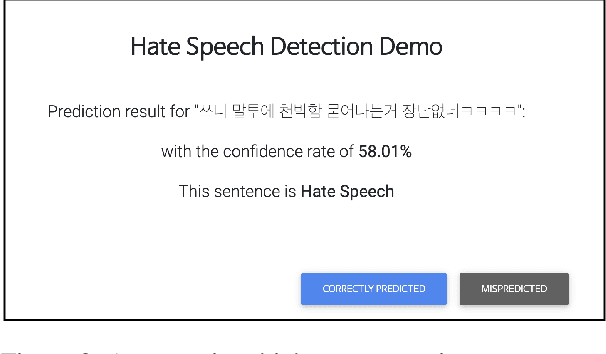
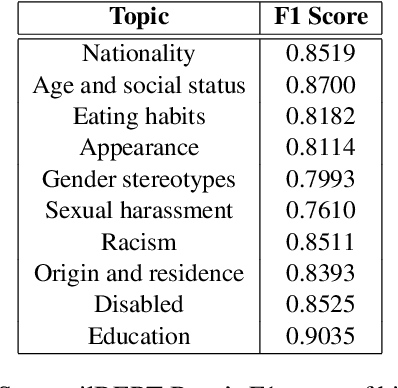
Detecting toxic or pejorative expressions in online communities has become one of the main concerns for preventing the users' mental harm. This led to the development of large-scale hate speech detection datasets of various domains, which are mainly built upon web-crawled texts with labels by crowd workers. However, for languages other than English, researchers might have to rely on only a small-sized corpus due to the lack of data-driven research of hate speech detection. This sometimes misleads the evaluation of prevalently used pretrained language models (PLMs) such as BERT, given that PLMs often share the domain of pretraining corpus with the evaluation set, resulting in over-representation of the detection performance. Also, the scope of pejorative expressions might be restricted if the dataset is built on a single domain text. To alleviate the above problems in Korean hate speech detection, we propose APEACH,a method that allows the collection of hate speech generated by unspecified users. By controlling the crowd-generation of hate speech and adding only a minimum post-labeling, we create a corpus that enables the generalizable and fair evaluation of hate speech detection regarding text domain and topic. We Compare our outcome with prior work on an annotation-based toxic news comment dataset using publicly available PLMs. We check that our dataset is less sensitive to the lexical overlap between the evaluation set and pretraining corpus of PLMs, showing that it helps mitigate the unexpected under/over-representation of model performance. We distribute our dataset publicly online to further facilitate the general-domain hate speech detection in Korean.
Speech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates
Aug 18, 2021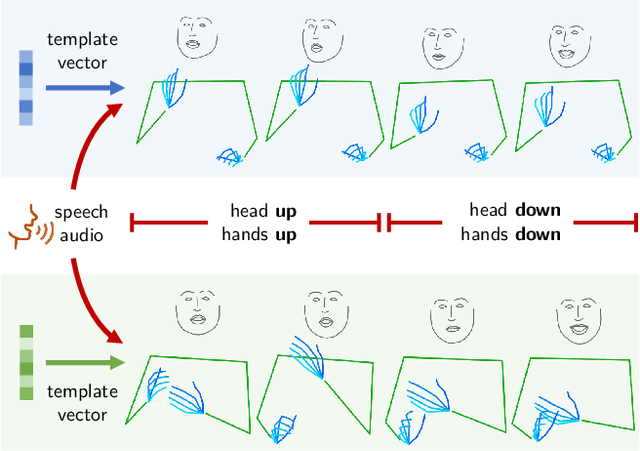
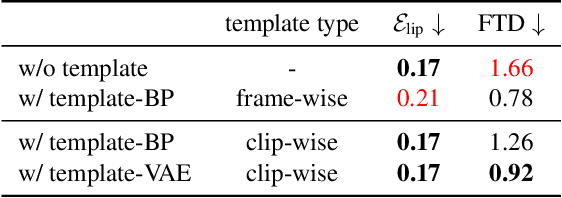
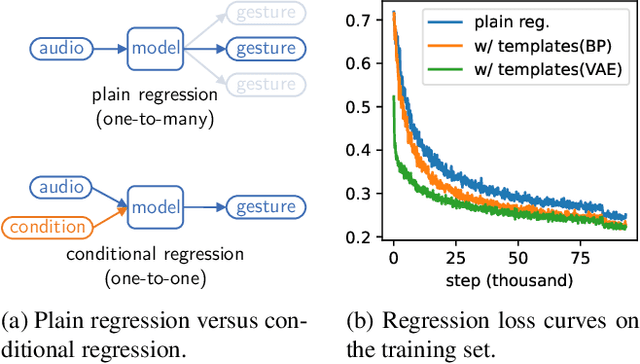

Co-speech gesture generation is to synthesize a gesture sequence that not only looks real but also matches with the input speech audio. Our method generates the movements of a complete upper body, including arms, hands, and the head. Although recent data-driven methods achieve great success, challenges still exist, such as limited variety, poor fidelity, and lack of objective metrics. Motivated by the fact that the speech cannot fully determine the gesture, we design a method that learns a set of gesture template vectors to model the latent conditions, which relieve the ambiguity. For our method, the template vector determines the general appearance of a generated gesture sequence, while the speech audio drives subtle movements of the body, both indispensable for synthesizing a realistic gesture sequence. Due to the intractability of an objective metric for gesture-speech synchronization, we adopt the lip-sync error as a proxy metric to tune and evaluate the synchronization ability of our model. Extensive experiments show the superiority of our method in both objective and subjective evaluations on fidelity and synchronization.
Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction
Jan 05, 2022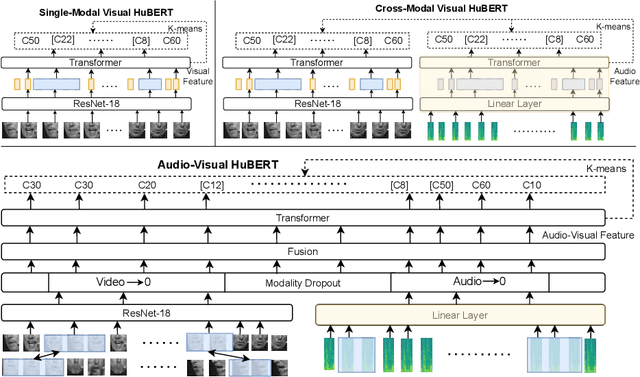
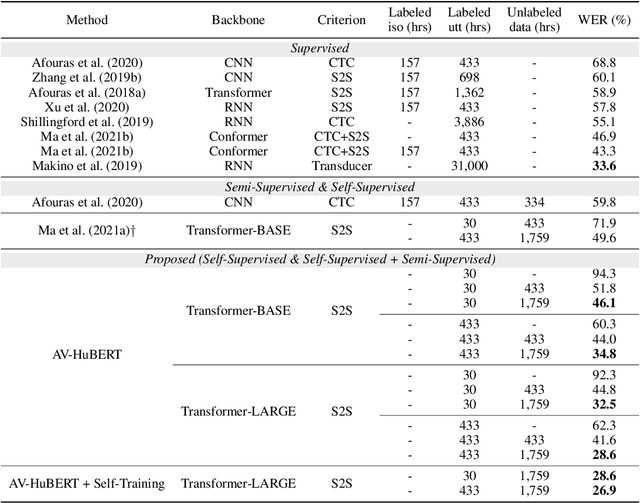


Video recordings of speech contain correlated audio and visual information, providing a strong signal for speech representation learning from the speaker's lip movements and the produced sound. We introduce Audio-Visual Hidden Unit BERT (AV-HuBERT), a self-supervised representation learning framework for audio-visual speech, which masks multi-stream video input and predicts automatically discovered and iteratively refined multimodal hidden units. AV-HuBERT learns powerful audio-visual speech representation benefiting both lip-reading and automatic speech recognition. On the largest public lip-reading benchmark LRS3 (433 hours), AV-HuBERT achieves 32.5% WER with only 30 hours of labeled data, outperforming the former state-of-the-art approach (33.6%) trained with a thousand times more transcribed video data (31K hours). The lip-reading WER is further reduced to 26.9% when using all 433 hours of labeled data from LRS3 and combined with self-training. Using our audio-visual representation on the same benchmark for audio-only speech recognition leads to a 40% relative WER reduction over the state-of-the-art performance (1.3% vs 2.3%). Our code and models are available at https://github.com/facebookresearch/av_hubert
Speech Denoising in the Waveform Domain with Self-Attention
Feb 15, 2022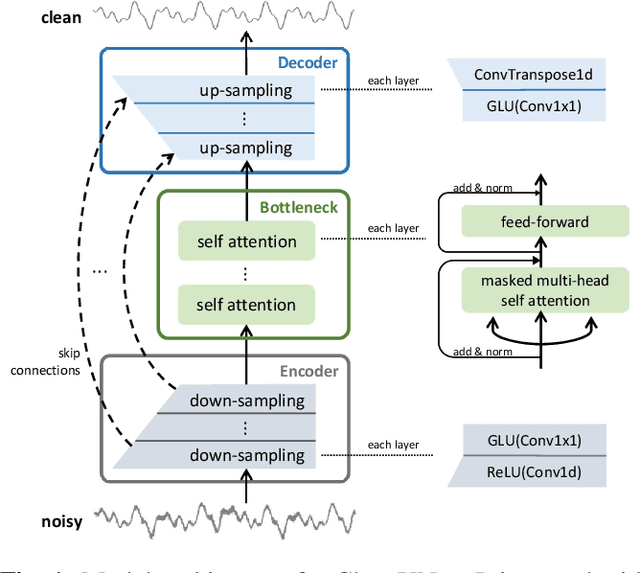
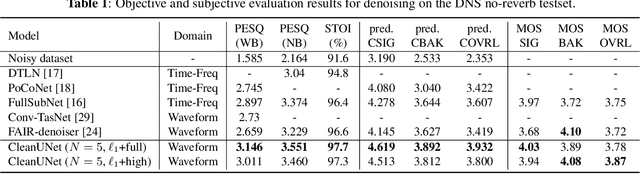
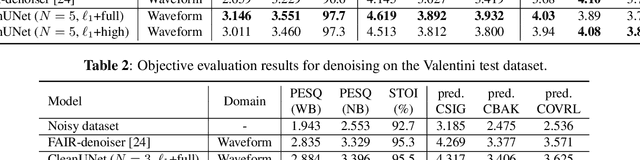

In this work, we present CleanUNet, a causal speech denoising model on the raw waveform. The proposed model is based on an encoder-decoder architecture combined with several self-attention blocks to refine its bottleneck representations, which is crucial to obtain good results. The model is optimized through a set of losses defined over both waveform and multi-resolution spectrograms. The proposed method outperforms the state-of-the-art models in terms of denoised speech quality from various objective and subjective evaluation metrics.
Self-supervised models of audio effectively explain human cortical responses to speech
May 27, 2022

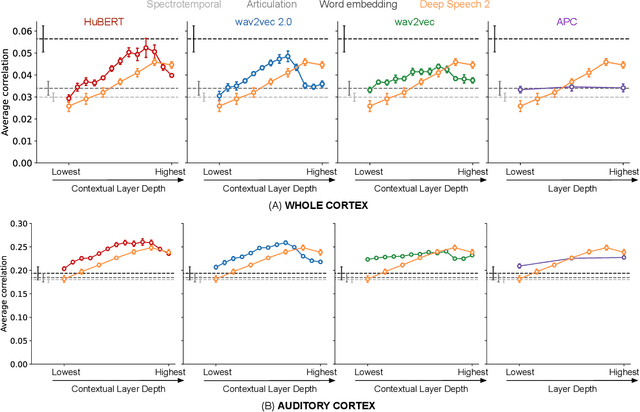
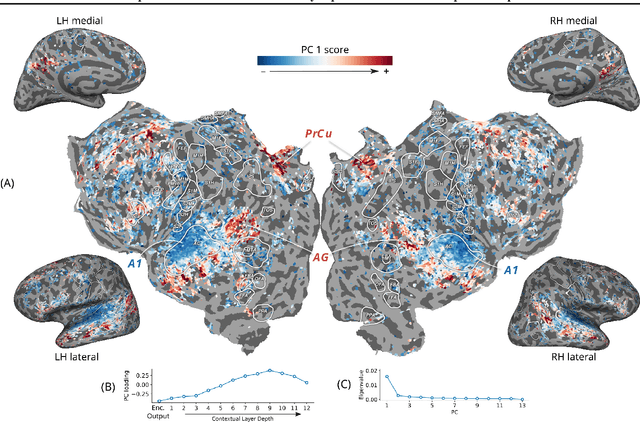
Self-supervised language models are very effective at predicting high-level cortical responses during language comprehension. However, the best current models of lower-level auditory processing in the human brain rely on either hand-constructed acoustic filters or representations from supervised audio neural networks. In this work, we capitalize on the progress of self-supervised speech representation learning (SSL) to create new state-of-the-art models of the human auditory system. Compared against acoustic baselines, phonemic features, and supervised models, representations from the middle layers of self-supervised models (APC, wav2vec, wav2vec 2.0, and HuBERT) consistently yield the best prediction performance for fMRI recordings within the auditory cortex (AC). Brain areas involved in low-level auditory processing exhibit a preference for earlier SSL model layers, whereas higher-level semantic areas prefer later layers. We show that these trends are due to the models' ability to encode information at multiple linguistic levels (acoustic, phonetic, and lexical) along their representation depth. Overall, these results show that self-supervised models effectively capture the hierarchy of information relevant to different stages of speech processing in human cortex.
A novel multimodal dynamic fusion network for disfluency detection in spoken utterances
Nov 27, 2022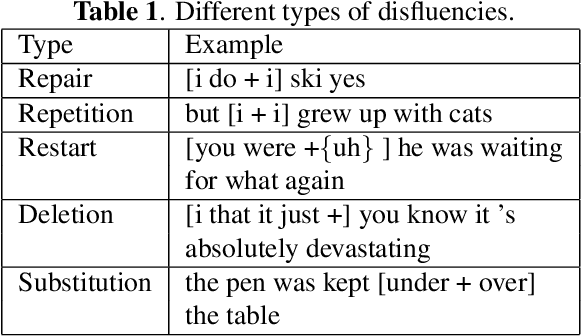
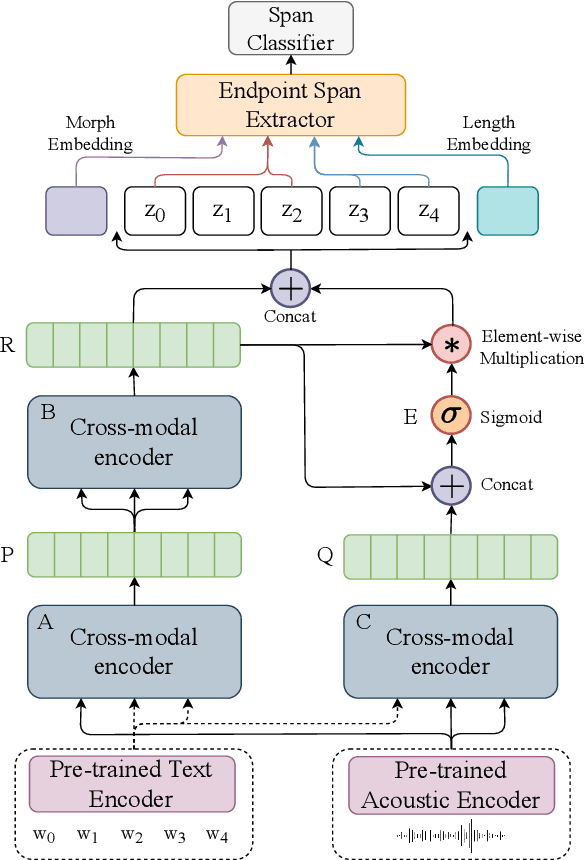
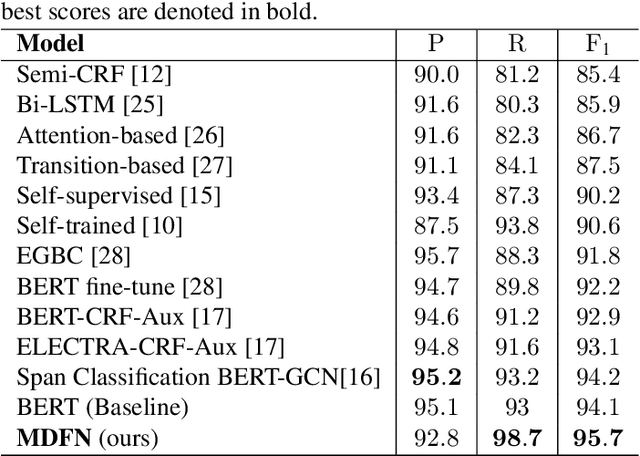
Disfluency, though originating from human spoken utterances, is primarily studied as a uni-modal text-based Natural Language Processing (NLP) task. Based on early-fusion and self-attention-based multimodal interaction between text and acoustic modalities, in this paper, we propose a novel multimodal architecture for disfluency detection from individual utterances. Our architecture leverages a multimodal dynamic fusion network that adds minimal parameters over an existing text encoder commonly used in prior art to leverage the prosodic and acoustic cues hidden in speech. Through experiments, we show that our proposed model achieves state-of-the-art results on the widely used English Switchboard for disfluency detection and outperforms prior unimodal and multimodal systems in literature by a significant margin. In addition, we make a thorough qualitative analysis and show that, unlike text-only systems, which suffer from spurious correlations in the data, our system overcomes this problem through additional cues from speech signals. We make all our codes publicly available on GitHub.
Adversarial Attacks on Speech Recognition Systems for Mission-Critical Applications: A Survey
Feb 22, 2022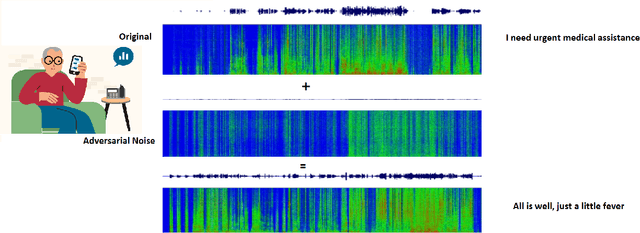
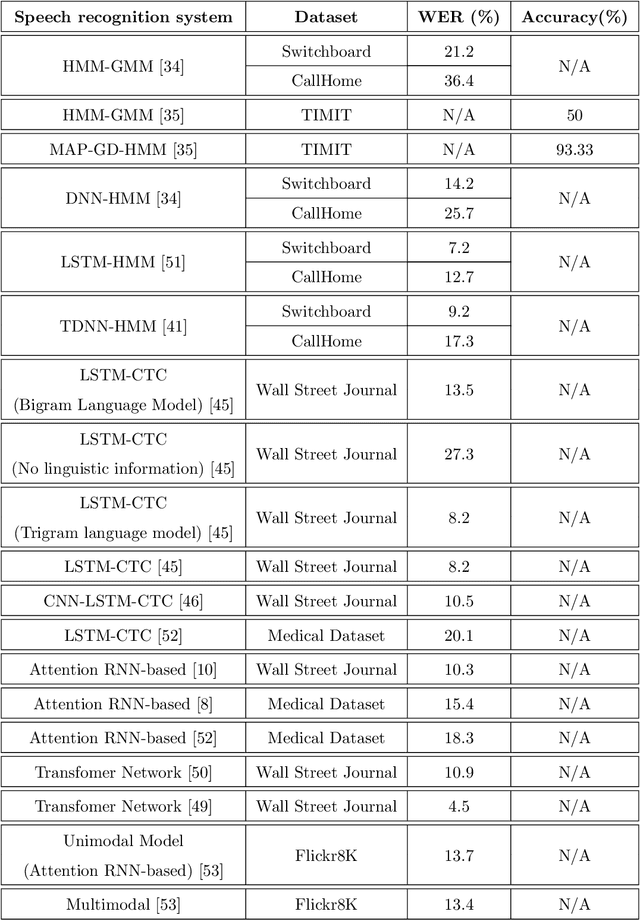
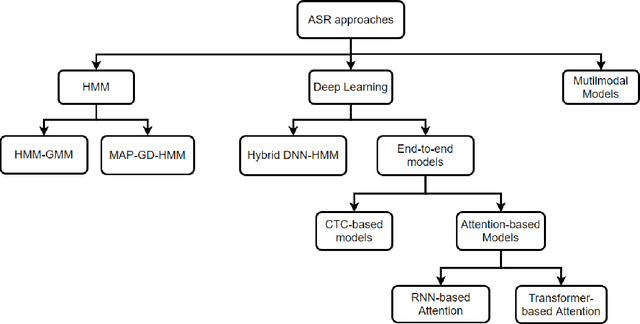
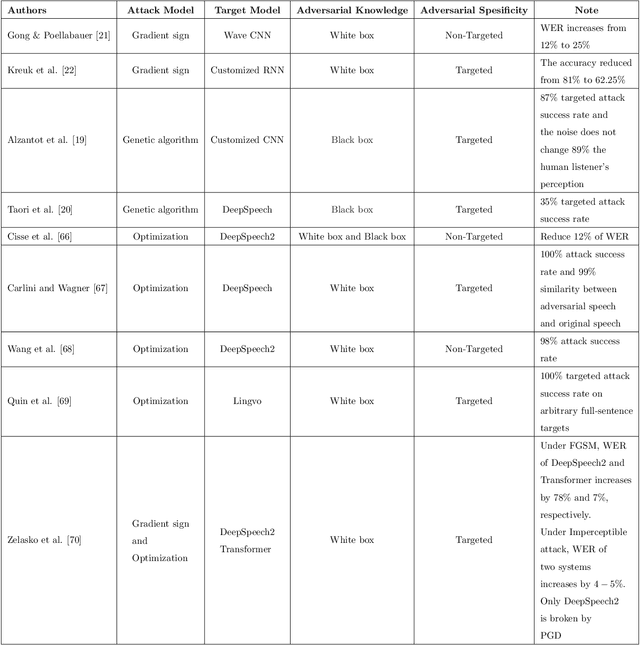
A Machine-Critical Application is a system that is fundamentally necessary to the success of specific and sensitive operations such as search and recovery, rescue, military, and emergency management actions. Recent advances in Machine Learning, Natural Language Processing, voice recognition, and speech processing technologies have naturally allowed the development and deployment of speech-based conversational interfaces to interact with various machine-critical applications. While these conversational interfaces have allowed users to give voice commands to carry out strategic and critical activities, their robustness to adversarial attacks remains uncertain and unclear. Indeed, Adversarial Artificial Intelligence (AI) which refers to a set of techniques that attempt to fool machine learning models with deceptive data, is a growing threat in the AI and machine learning research community, in particular for machine-critical applications. The most common reason of adversarial attacks is to cause a malfunction in a machine learning model. An adversarial attack might entail presenting a model with inaccurate or fabricated samples as it's training data, or introducing maliciously designed data to deceive an already trained model. While focusing on speech recognition for machine-critical applications, in this paper, we first review existing speech recognition techniques, then, we investigate the effectiveness of adversarial attacks and defenses against these systems, before outlining research challenges, defense recommendations, and future work. This paper is expected to serve researchers and practitioners as a reference to help them in understanding the challenges, position themselves and, ultimately, help them to improve existing models of speech recognition for mission-critical applications. Keywords: Mission-Critical Applications, Adversarial AI, Speech Recognition Systems.
Dict-TTS: Learning to Pronounce with Prior Dictionary Knowledge for Text-to-Speech
Jun 05, 2022

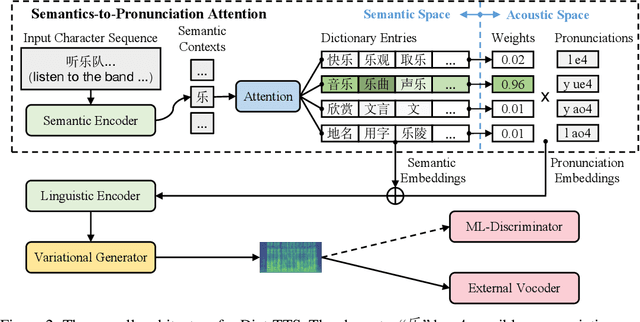
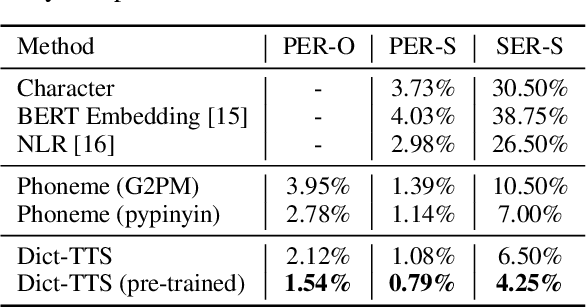
Polyphone disambiguation aims to capture accurate pronunciation knowledge from natural text sequences for reliable Text-to-speech (TTS) systems. However, previous approaches require substantial annotated training data and additional efforts from language experts, making it difficult to extend high-quality neural TTS systems to out-of-domain daily conversations and countless languages worldwide. This paper tackles the polyphone disambiguation problem from a concise and novel perspective: we propose Dict-TTS, a semantic-aware generative text-to-speech model with an online website dictionary (the existing prior information in the natural language). Specifically, we design a semantics-to-pronunciation attention (S2PA) module to match the semantic patterns between the input text sequence and the prior semantics in the dictionary and obtain the corresponding pronunciations; The S2PA module can be easily trained with the end-to-end TTS model without any annotated phoneme labels. Experimental results in three languages show that our model outperforms several strong baseline models in terms of pronunciation accuracy and improves the prosody modeling of TTS systems. Further extensive analyses with different linguistic encoders demonstrate that each design in Dict-TTS is effective. Audio samples are available at \url{https://dicttts.github.io/DictTTS-Demo/}.
Blind Restoration of Real-World Audio by 1D Operational GANs
Dec 30, 2022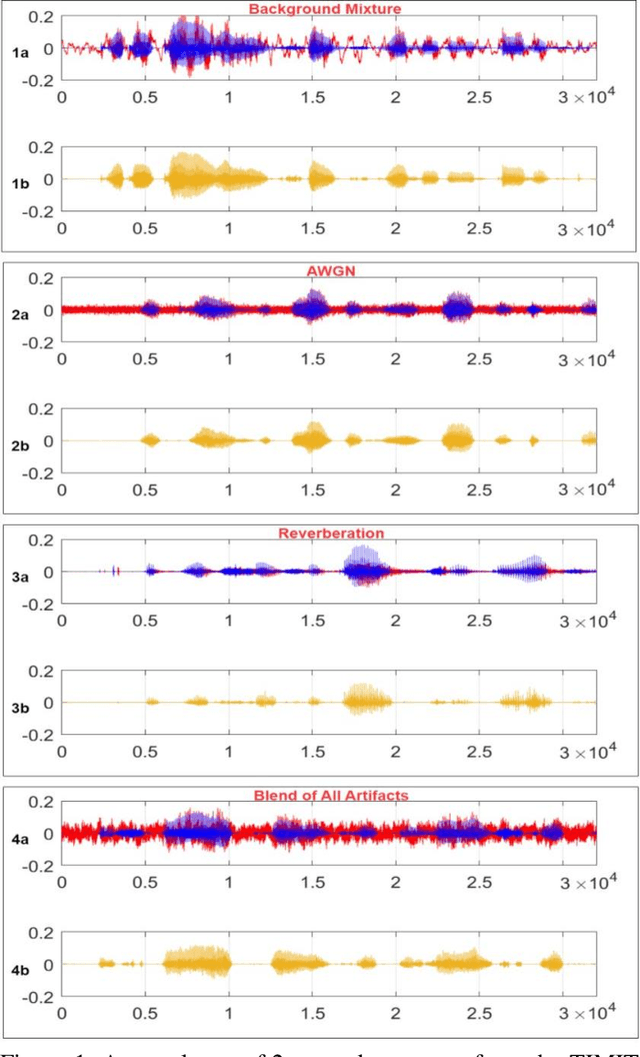
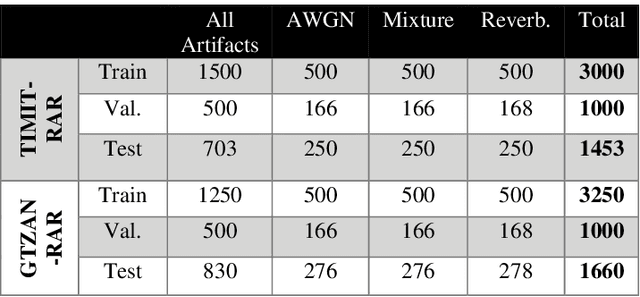
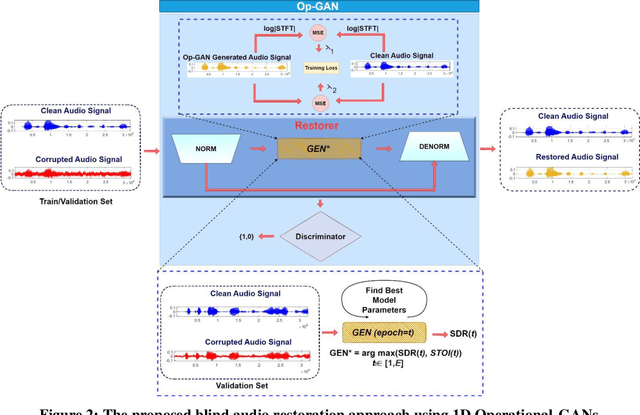
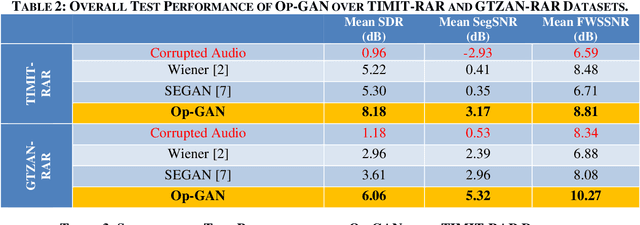
Objective: Despite numerous studies proposed for audio restoration in the literature, most of them focus on an isolated restoration problem such as denoising or dereverberation, ignoring other artifacts. Moreover, assuming a noisy or reverberant environment with limited number of fixed signal-to-distortion ratio (SDR) levels is a common practice. However, real-world audio is often corrupted by a blend of artifacts such as reverberation, sensor noise, and background audio mixture with varying types, severities, and duration. In this study, we propose a novel approach for blind restoration of real-world audio signals by Operational Generative Adversarial Networks (Op-GANs) with temporal and spectral objective metrics to enhance the quality of restored audio signal regardless of the type and severity of each artifact corrupting it. Methods: 1D Operational-GANs are used with generative neuron model optimized for blind restoration of any corrupted audio signal. Results: The proposed approach has been evaluated extensively over the benchmark TIMIT-RAR (speech) and GTZAN-RAR (non-speech) datasets corrupted with a random blend of artifacts each with a random severity to mimic real-world audio signals. Average SDR improvements of over 7.2 dB and 4.9 dB are achieved, respectively, which are substantial when compared with the baseline methods. Significance: This is a pioneer study in blind audio restoration with the unique capability of direct (time-domain) restoration of real-world audio whilst achieving an unprecedented level of performance for a wide SDR range and artifact types. Conclusion: 1D Op-GANs can achieve robust and computationally effective real-world audio restoration with significantly improved performance. The source codes and the generated real-world audio datasets are shared publicly with the research community in a dedicated GitHub repository1.
On Using Transformers for Speech-Separation
Feb 06, 2022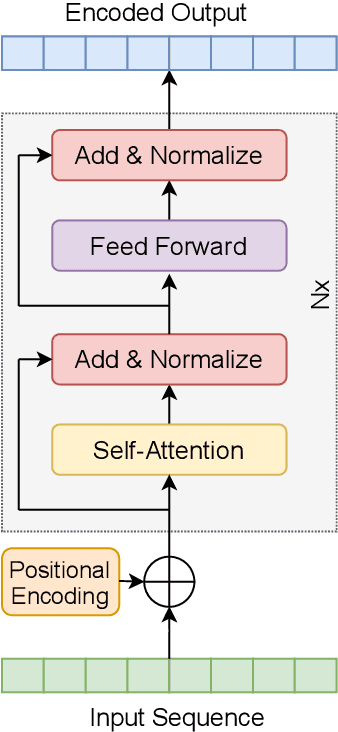
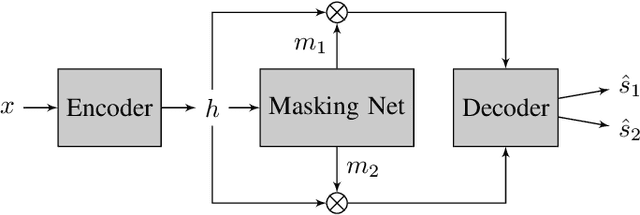
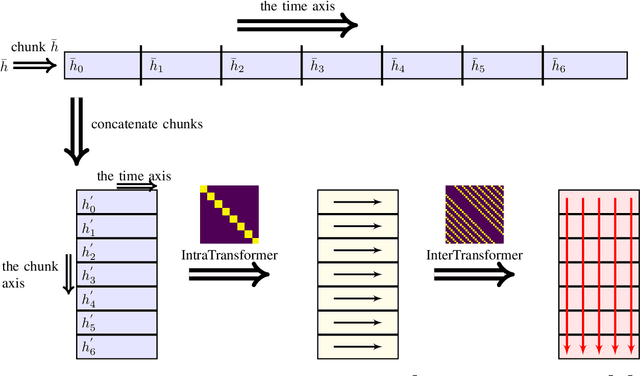
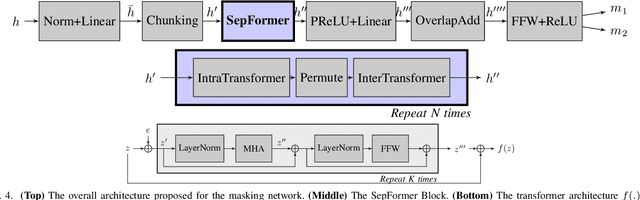
Transformers have enabled major improvements in deep learning. They often outperform recurrent and convolutional models in many tasks while taking advantage of parallel processing. Recently, we have proposed SepFormer, which uses self-attention and obtains state-of-the art results on WSJ0-2/3 Mix datasets for speech separation. In this paper, we extend our previous work by providing results on more datasets including LibriMix, and WHAM!, WHAMR! which include noisy and noisy-reverberant conditions. Moreover we provide denoising, and denoising+dereverberation results in the context of speech enhancement, respectively on WHAM! and WHAMR! datasets. We also investigate incorporating recently proposed efficient self-attention mechanisms inside the SepFormer model, and show that by using efficient self-attention mechanisms it is possible to reduce the memory requirements significantly while performing better than the popular convtasnet model on WSJ0-2Mix dataset.