 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Accelerating RNN-based Speech Enhancement on a Multi-Core MCU with Mixed FP16-INT8 Post-Training Quantization
Oct 14, 2022
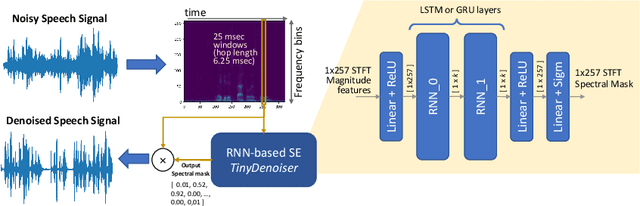

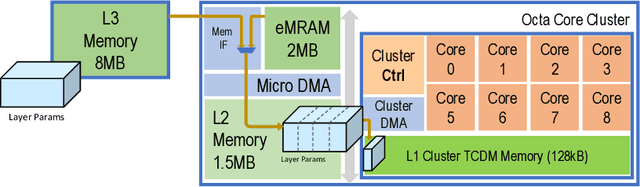
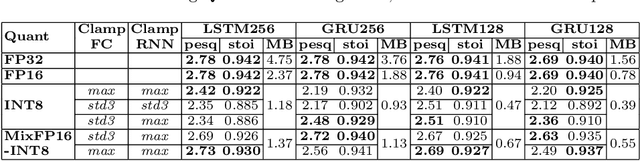
This paper presents an optimized methodology to design and deploy Speech Enhancement (SE) algorithms based on Recurrent Neural Networks (RNNs) on a state-of-the-art MicroController Unit (MCU), with 1+8 general-purpose RISC-V cores. To achieve low-latency execution, we propose an optimized software pipeline interleaving parallel computation of LSTM or GRU recurrent blocks, featuring vectorized 8-bit integer (INT8) and 16-bit floating-point (FP16) compute units, with manually-managed memory transfers of model parameters. To ensure minimal accuracy degradation with respect to the full-precision models, we propose a novel FP16-INT8 Mixed-Precision Post-Training Quantization (PTQ) scheme that compresses the recurrent layers to 8-bit while the bit precision of remaining layers is kept to FP16. Experiments are conducted on multiple LSTM and GRU based SE models trained on the Valentini dataset, featuring up to 1.24M parameters. Thanks to the proposed approaches, we speed-up the computation by up to 4x with respect to the lossless FP16 baselines. Differently from a uniform 8-bit quantization that degrades the PESQ score by 0.3 on average, the Mixed-Precision PTQ scheme leads to a low-degradation of only 0.06, while achieving a 1.4-1.7x memory saving. Thanks to this compression, we cut the power cost of the external memory by fitting the large models on the limited on-chip non-volatile memory and we gain a MCU power saving of up to 2.5x by reducing the supply voltage from 0.8V to 0.65V while still matching the real-time constraints. Our design results 10x more energy efficient than state-of-the-art SE solutions deployed on single-core MCUs that make use of smaller models and quantization-aware training.
Quantifying How Hateful Communities Radicalize Online Users
Sep 19, 2022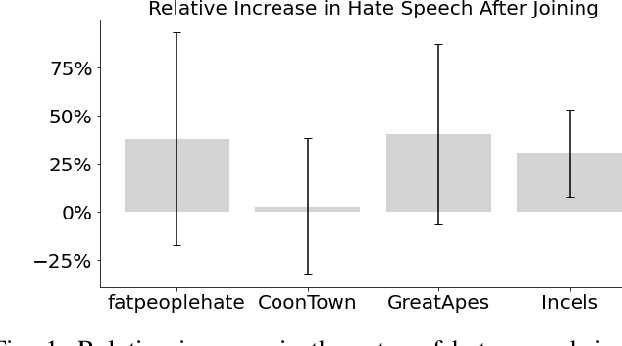
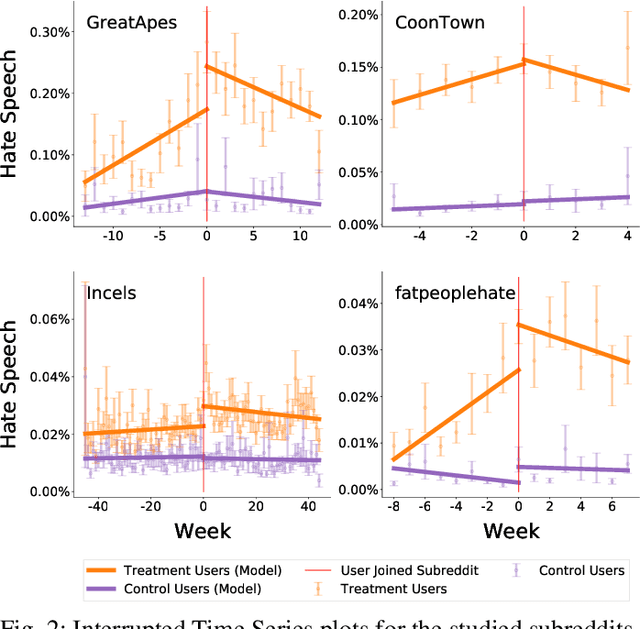
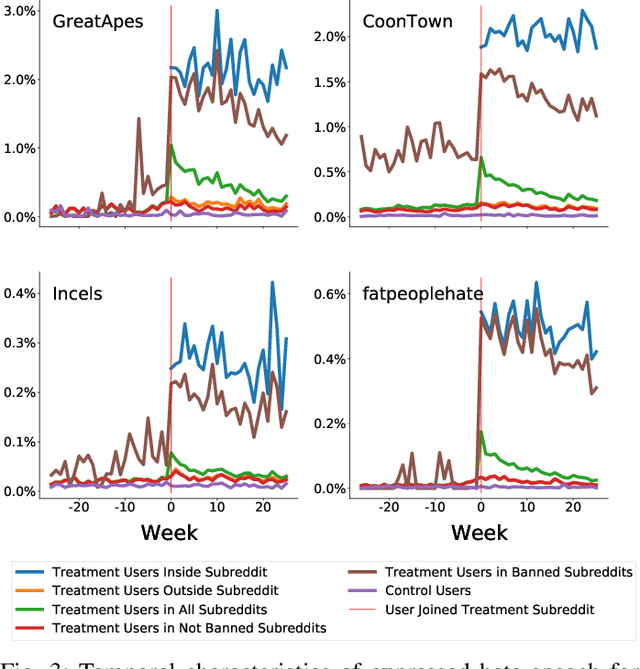
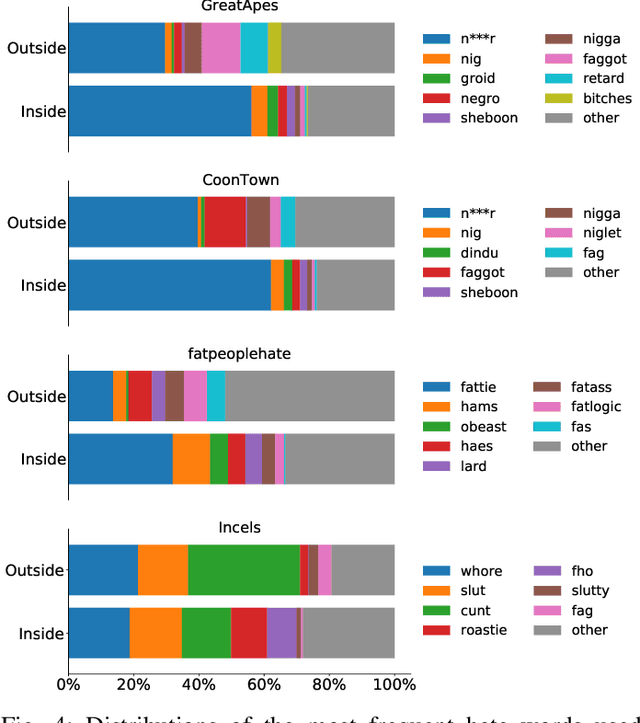
While online social media offers a way for ignored or stifled voices to be heard, it also allows users a platform to spread hateful speech. Such speech usually originates in fringe communities, yet it can spill over into mainstream channels. In this paper, we measure the impact of joining fringe hateful communities in terms of hate speech propagated to the rest of the social network. We leverage data from Reddit to assess the effect of joining one type of echo chamber: a digital community of like-minded users exhibiting hateful behavior. We measure members' usage of hate speech outside the studied community before and after they become active participants. Using Interrupted Time Series (ITS) analysis as a causal inference method, we gauge the spillover effect, in which hateful language from within a certain community can spread outside that community by using the level of out-of-community hate word usage as a proxy for learned hate. We investigate four different Reddit sub-communities (subreddits) covering three areas of hate speech: racism, misogyny and fat-shaming. In all three cases we find an increase in hate speech outside the originating community, implying that joining such community leads to a spread of hate speech throughout the platform. Moreover, users are found to pick up this new hateful speech for months after initially joining the community. We show that the harmful speech does not remain contained within the community. Our results provide new evidence of the harmful effects of echo chambers and the potential benefit of moderating them to reduce adoption of hateful speech.
Speech Toxicity Analysis: A New Spoken Language Processing Task
Nov 06, 2021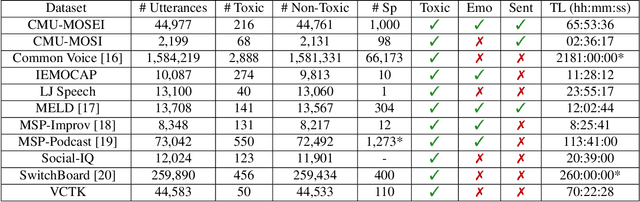
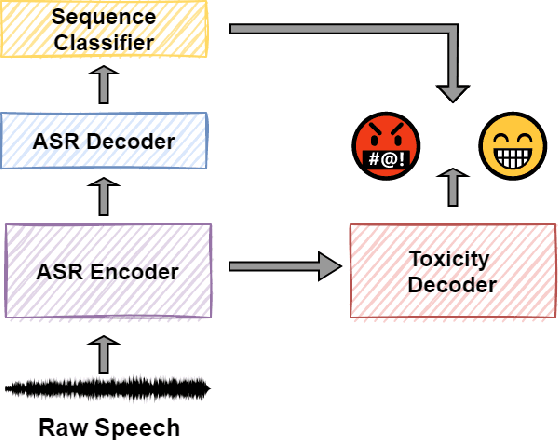
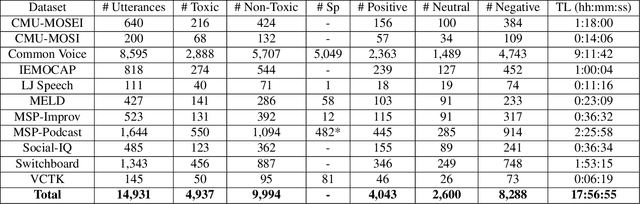
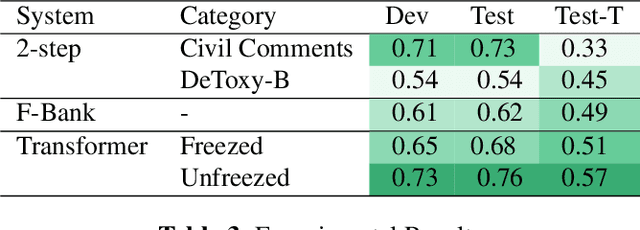
Toxic speech, also known as hate speech, is regarded as one of the crucial issues plaguing online social media today. Most recent work on toxic speech detection is constrained to the modality of text with no existing work on toxicity detection from spoken utterances. In this paper, we propose a new Spoken Language Processing task of detecting toxicity from spoken speech. We introduce DeToxy, the first publicly available toxicity annotated dataset for English speech, sourced from various openly available speech databases, consisting of over 2 million utterances. Finally, we also provide analysis on how a spoken speech corpus annotated for toxicity can help facilitate the development of E2E models which better capture various prosodic cues in speech, thereby boosting toxicity classification on spoken utterances.
Efficient Adapter Transfer of Self-Supervised Speech Models for Automatic Speech Recognition
Feb 07, 2022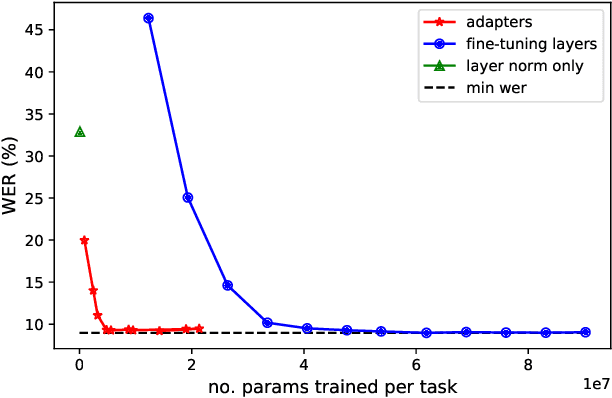
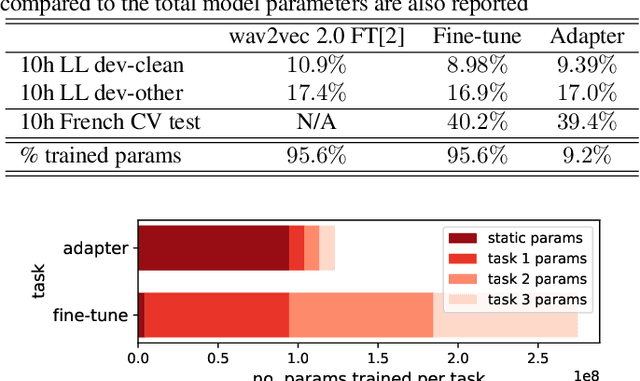

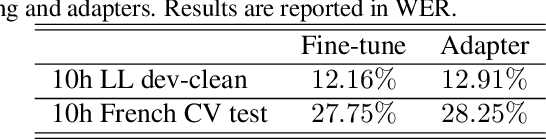
Self-supervised learning (SSL) is a powerful tool that allows learning of underlying representations from unlabeled data. Transformer based models such as wav2vec 2.0 and HuBERT are leading the field in the speech domain. Generally these models are fine-tuned on a small amount of labeled data for a downstream task such as Automatic Speech Recognition (ASR). This involves re-training the majority of the model for each task. Adapters are small lightweight modules which are commonly used in Natural Language Processing (NLP) to adapt pre-trained models to new tasks. In this paper we propose applying adapters to wav2vec 2.0 to reduce the number of parameters required for downstream ASR tasks, and increase scalability of the model to multiple tasks or languages. Using adapters we can perform ASR while training fewer than 10% of parameters per task compared to full fine-tuning with little degradation of performance. Ablations show that applying adapters into just the top few layers of the pre-trained network gives similar performance to full transfer, supporting the theory that higher pre-trained layers encode more phonemic information, and further optimizing efficiency.
Multitask Learning for Low Resource Spoken Language Understanding
Nov 24, 2022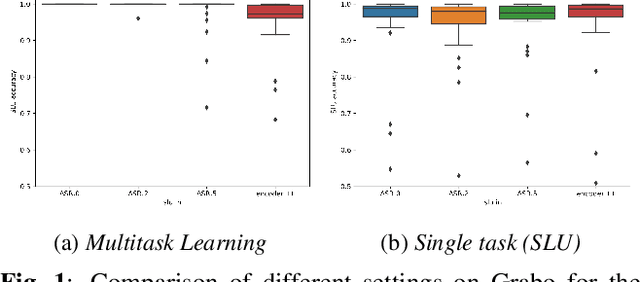
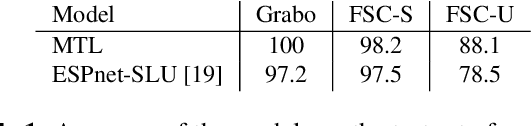
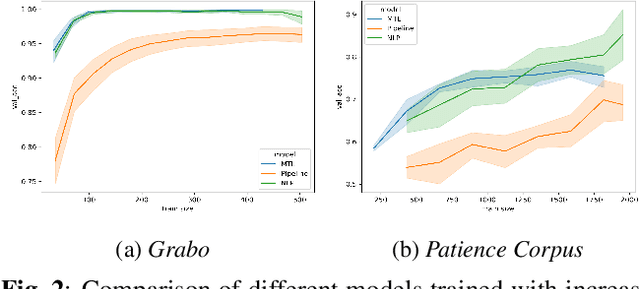
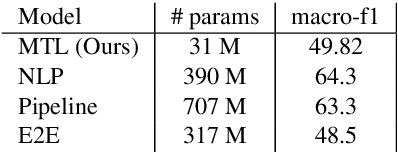
We explore the benefits that multitask learning offer to speech processing as we train models on dual objectives with automatic speech recognition and intent classification or sentiment classification. Our models, although being of modest size, show improvements over models trained end-to-end on intent classification. We compare different settings to find the optimal disposition of each task module compared to one another. Finally, we study the performance of the models in low-resource scenario by training the models with as few as one example per class. We show that multitask learning in these scenarios compete with a baseline model trained on text features and performs considerably better than a pipeline model. On sentiment classification, we match the performance of an end-to-end model with ten times as many parameters. We consider 4 tasks and 4 datasets in Dutch and English.
Adaptive multilingual speech recognition with pretrained models
May 24, 2022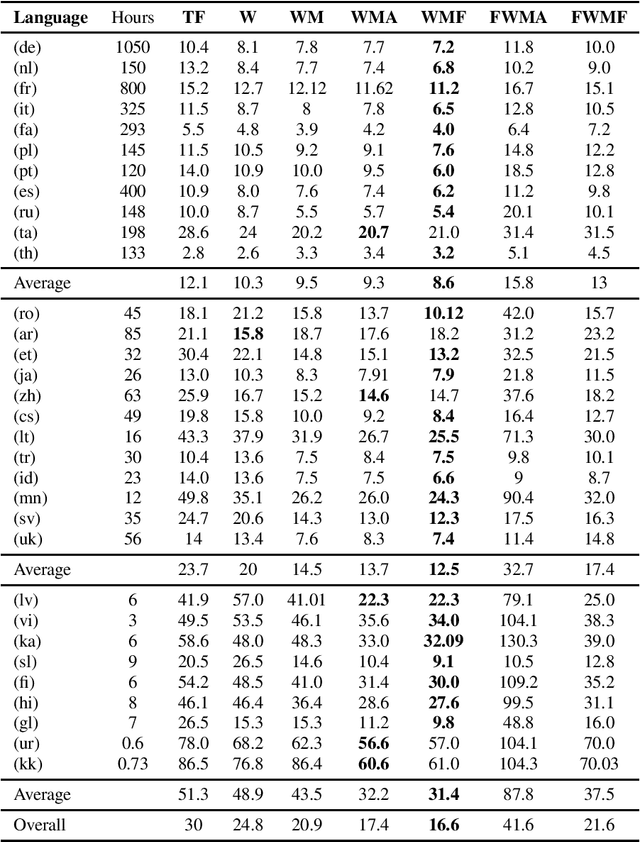
Multilingual speech recognition with supervised learning has achieved great results as reflected in recent research. With the development of pretraining methods on audio and text data, it is imperative to transfer the knowledge from unsupervised multilingual models to facilitate recognition, especially in many languages with limited data. Our work investigated the effectiveness of using two pretrained models for two modalities: wav2vec 2.0 for audio and MBART50 for text, together with the adaptive weight techniques to massively improve the recognition quality on the public datasets containing CommonVoice and Europarl. Overall, we noticed an 44% improvement over purely supervised learning, and more importantly, each technique provides a different reinforcement in different languages. We also explore other possibilities to potentially obtain the best model by slightly adding either depth or relative attention to the architecture.
Beyond Statistical Similarity: Rethinking Metrics for Deep Generative Models in Engineering Design
Feb 11, 2023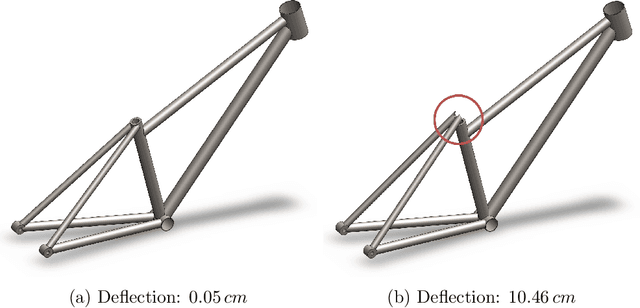
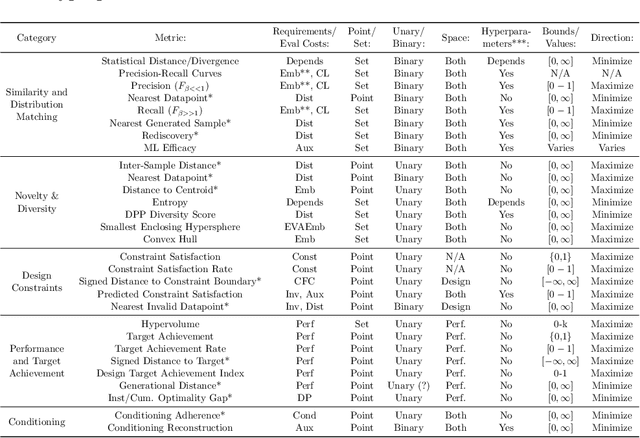
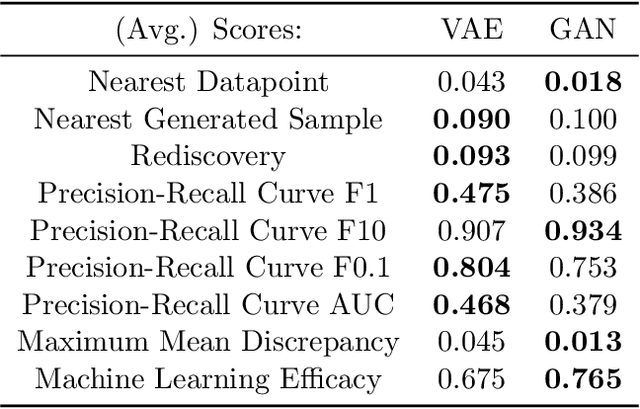
Deep generative models, such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), Diffusion Models, and Transformers, have shown great promise in a variety of applications, including image and speech synthesis, natural language processing, and drug discovery. However, when applied to engineering design problems, evaluating the performance of these models can be challenging, as traditional statistical metrics based on likelihood may not fully capture the requirements of engineering applications. This paper doubles as a review and a practical guide to evaluation metrics for deep generative models (DGMs) in engineering design. We first summarize well-accepted `classic' evaluation metrics for deep generative models grounded in machine learning theory and typical computer science applications. Using case studies, we then highlight why these metrics seldom translate well to design problems but see frequent use due to the lack of established alternatives. Next, we curate a set of design-specific metrics which have been proposed across different research communities and can be used for evaluating deep generative models. These metrics focus on unique requirements in design and engineering, such as constraint satisfaction, functional performance, novelty, and conditioning. We structure our review and discussion as a set of practical selection criteria and usage guidelines. Throughout our discussion, we apply the metrics to models trained on simple 2-dimensional example problems. Finally, to illustrate the selection process and classic usage of the presented metrics, we evaluate three deep generative models on a multifaceted bicycle frame design problem considering performance target achievement, design novelty, and geometric constraints. We publicly release the code for the datasets, models, and metrics used throughout the paper at decode.mit.edu/projects/metrics/.
MTTM: Metamorphic Testing for Textual Content Moderation Software
Feb 11, 2023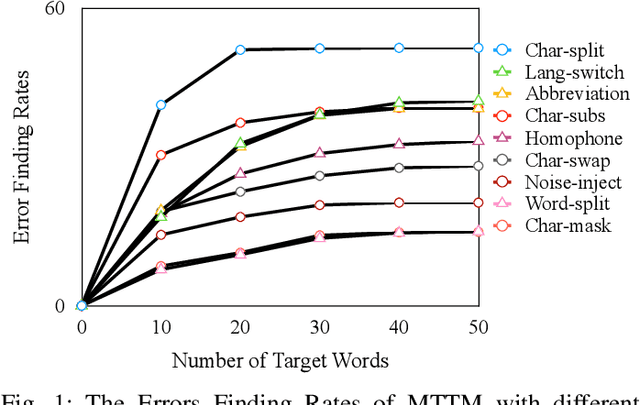
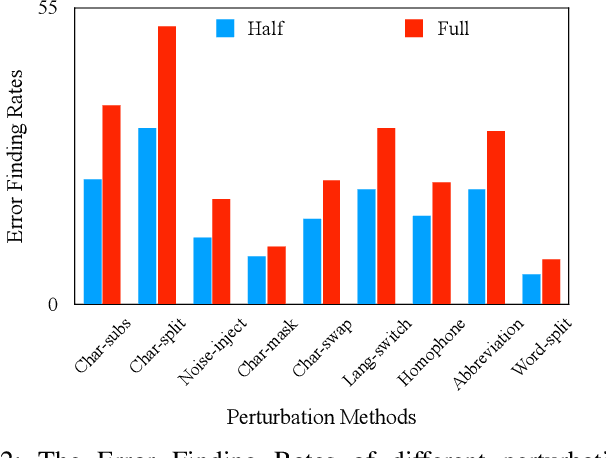
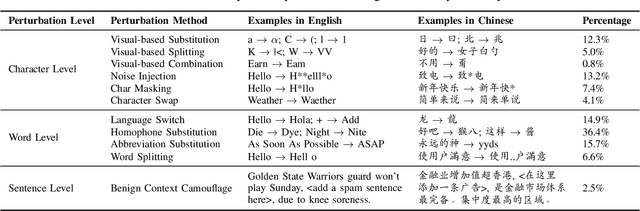
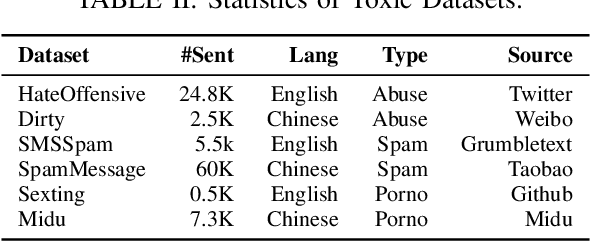
The exponential growth of social media platforms such as Twitter and Facebook has revolutionized textual communication and textual content publication in human society. However, they have been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisement, and pornography, which can lead to highly negative impacts (e.g., harmful effects on teen mental health). Researchers and practitioners have been enthusiastically developing and extensively deploying textual content moderation software to address this problem. However, we find that malicious users can evade moderation by changing only a few words in the toxic content. Moreover, modern content moderation software performance against malicious inputs remains underexplored. To this end, we propose MTTM, a Metamorphic Testing framework for Textual content Moderation software. Specifically, we conduct a pilot study on 2,000 text messages collected from real users and summarize eleven metamorphic relations across three perturbation levels: character, word, and sentence. MTTM employs these metamorphic relations on toxic textual contents to generate test cases, which are still toxic yet likely to evade moderation. In our evaluation, we employ MTTM to test three commercial textual content moderation software and two state-of-the-art moderation algorithms against three kinds of toxic content. The results show that MTTM achieves up to 83.9%, 51%, and 82.5% error finding rates (EFR) when testing commercial moderation software provided by Google, Baidu, and Huawei, respectively, and it obtains up to 91.2% EFR when testing the state-of-the-art algorithms from the academy. In addition, we leverage the test cases generated by MTTM to retrain the model we explored, which largely improves model robustness (0% to 5.9% EFR) while maintaining the accuracy on the original test set.
Combination of Time-domain, Frequency-domain, and Cepstral-domain Acoustic Features for Speech Commands Classification
Mar 30, 2022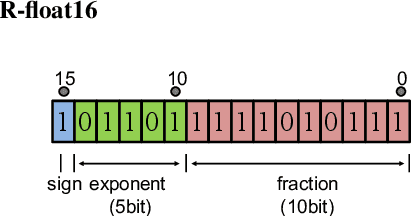
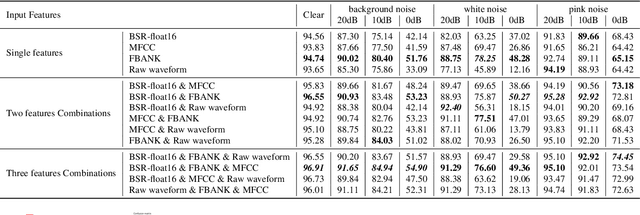
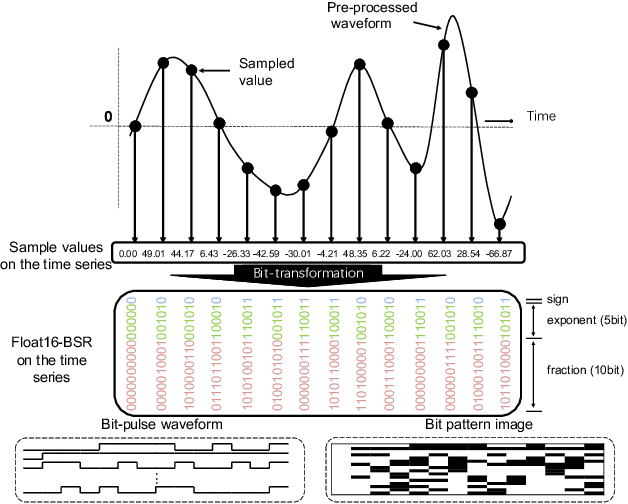
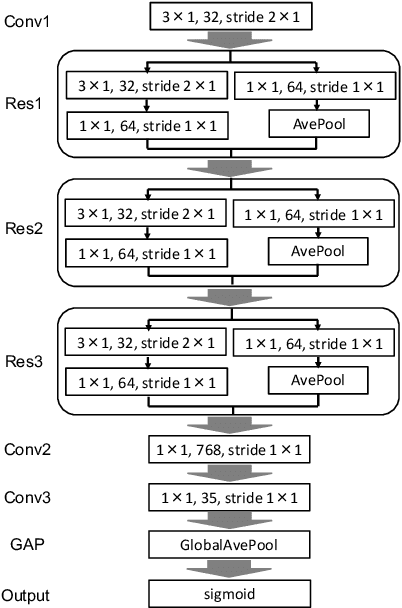
In speech-related classification tasks, frequency-domain acoustic features such as logarithmic Mel-filter bank coefficients (FBANK) and cepstral-domain acoustic features such as Mel-frequency cepstral coefficients (MFCC) are often used. However, time-domain features perform more effectively in some sound classification tasks which contain non-vocal or weakly speech-related sounds. We previously proposed a feature called bit sequence representation (BSR), which is a time-domain binary acoustic feature based on the raw waveform. Compared with MFCC, BSR performed better in environmental sound detection and showed comparable accuracy performance in limited-vocabulary speech recognition tasks. In this paper, we propose a novel improvement BSR feature called BSR-float16 to represent floating-point values more precisely. We experimentally demonstrated the complementarity among time-domain, frequency-domain, and cepstral-domain features using a dataset called Speech Commands proposed by Google. Therefore, we used a simple back-end score fusion method to improve the final classification accuracy. The fusion results also showed better noise robustness.
Exploring the influence of fine-tuning data on wav2vec 2.0 model for blind speech quality prediction
Apr 05, 2022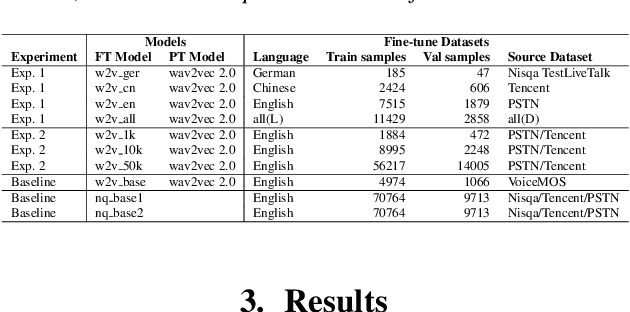
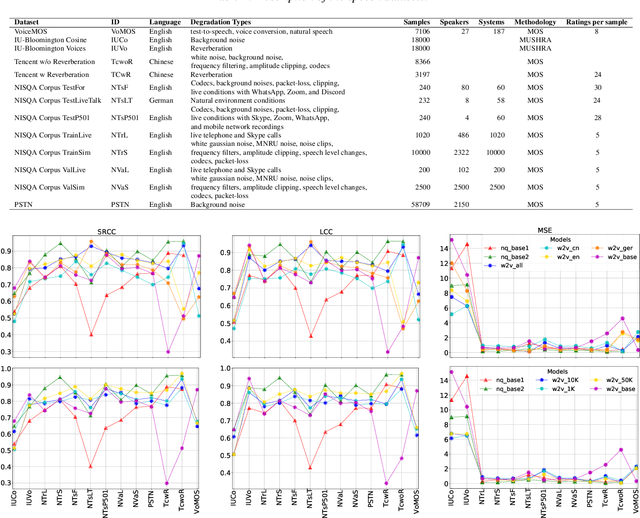
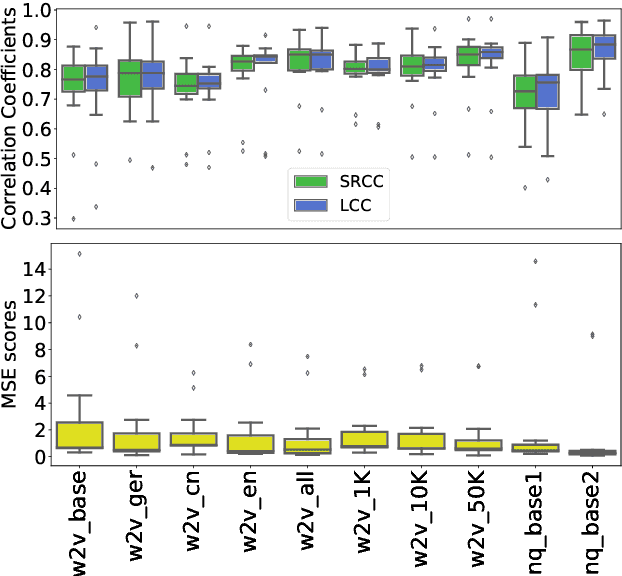
Recent studies have shown how self-supervised models can produce accurate speech quality predictions. Speech representations generated by the pre-trained wav2vec 2.0 model allows constructing robust predicting models using small amounts of annotated data. This opens the possibility of developing strong models in scenarios where labelled data is scarce. It is known that fine-tuning improves the model's performance; however, it is unclear how the data (e.g., language, amount of samples) used for fine-tuning is influencing that performance. In this paper, we explore how using different speech corpus to fine-tune the wav2vec 2.0 can influence its performance. We took four speech datasets containing degradations found in common conferencing applications and fine-tuned wav2vec 2.0 targeting different languages and data size scenarios. The fine-tuned models were tested across all four conferencing datasets plus an additional dataset containing synthetic speech and they were compared against three external baseline models. Results showed that fine-tuned models were able to compete with baseline models. Larger fine-tune data guarantee better performance; meanwhile, diversity in language helped the models deal with specific languages. Further research is needed to evaluate other wav2vec 2.0 models pre-trained with multi-lingual datasets and to develop prediction models that are more resilient to language diversity.