 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Non-Parametric Domain Adaptation for End-to-End Speech Translation
May 23, 2022
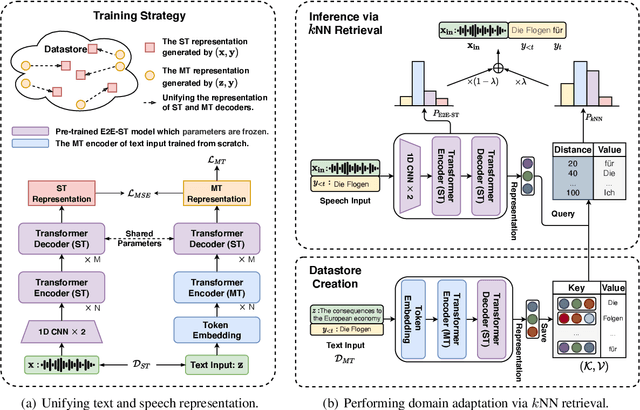
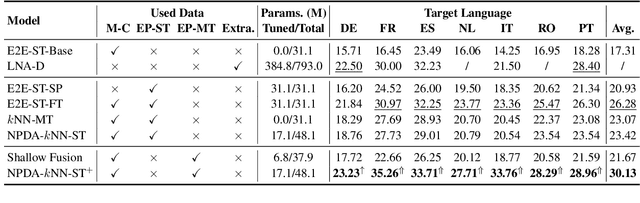
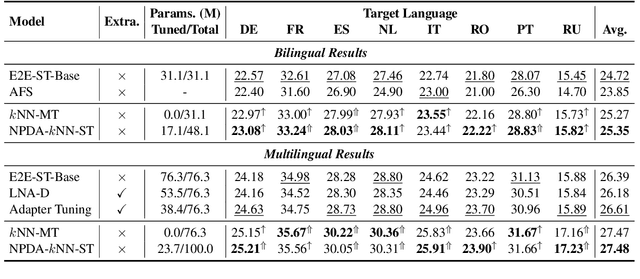
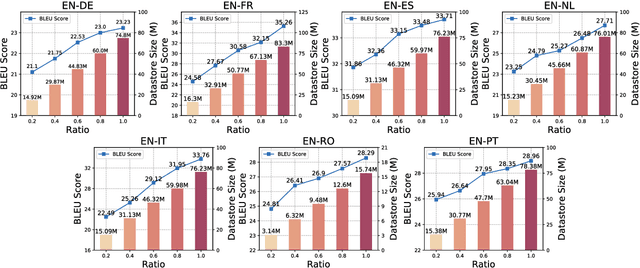
End-to-End Speech Translation (E2E-ST) has received increasing attention due to the potential of its less error propagation, lower latency, and fewer parameters. However, the effectiveness of neural-based approaches to this task is severely limited by the available training corpus, especially for domain adaptation where in-domain triplet training data is scarce or nonexistent. In this paper, we propose a novel non-parametric method that leverages domain-specific text translation corpus to achieve domain adaptation for the E2E-ST system. To this end, we first incorporate an additional encoder into the pre-trained E2E-ST model to realize text translation modelling, and then unify the decoder's output representation for text and speech translation tasks by reducing the correspondent representation mismatch in available triplet training data. During domain adaptation, a k-nearest-neighbor (kNN) classifier is introduced to produce the final translation distribution using the external datastore built by the domain-specific text translation corpus, while the universal output representation is adopted to perform a similarity search. Experiments on the Europarl-ST benchmark demonstrate that when in-domain text translation data is involved only, our proposed approach significantly improves baseline by 12.82 BLEU on average in all translation directions, even outperforming the strong in-domain fine-tuning method.
MDNet: Learning Monaural Speech Enhancement from Deep Prior Gradient
Mar 16, 2022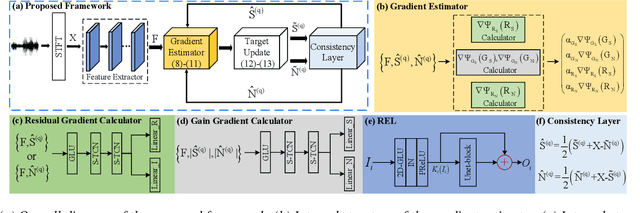
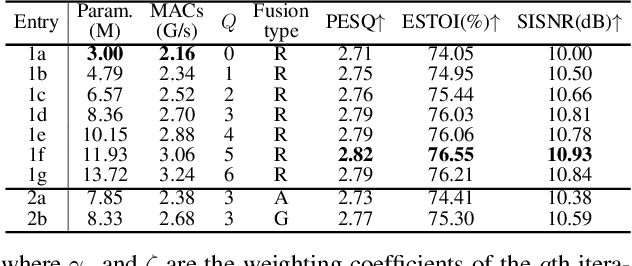
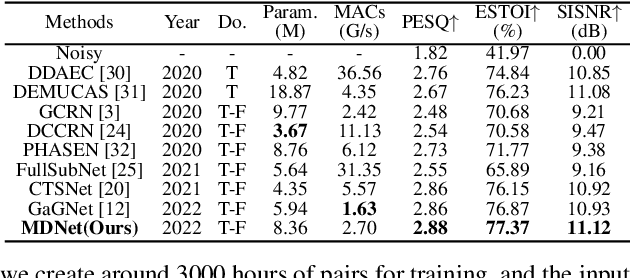
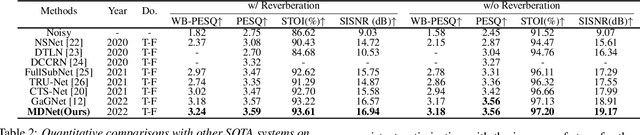
While traditional statistical signal processing model-based methods can derive the optimal estimators relying on specific statistical assumptions, current learning-based methods further promote the performance upper bound via deep neural networks but at the expense of high encapsulation and lack adequate interpretability. Standing upon the intersection between traditional model-based methods and learning-based methods, we propose a model-driven approach based on the maximum a posteriori (MAP) framework, termed as MDNet, for single-channel speech enhancement. Specifically, the original problem is formulated into the joint posterior estimation w.r.t. speech and noise components. Different from the manual assumption toward the prior terms, we propose to model the prior distribution via networks and thus can learn from training data. The framework takes the unfolding structure and in each step, the target parameters can be progressively estimated through explicit gradient descent operations. Besides, another network serves as the fusion module to further refine the previous speech estimation. The experiments are conducted on the WSJ0-SI84 and Interspeech2020 DNS-Challenge datasets, and quantitative results show that the proposed approach outshines previous state-of-the-art baselines.
Unsupervised data selection for Speech Recognition with contrastive loss ratios
Jul 25, 2022
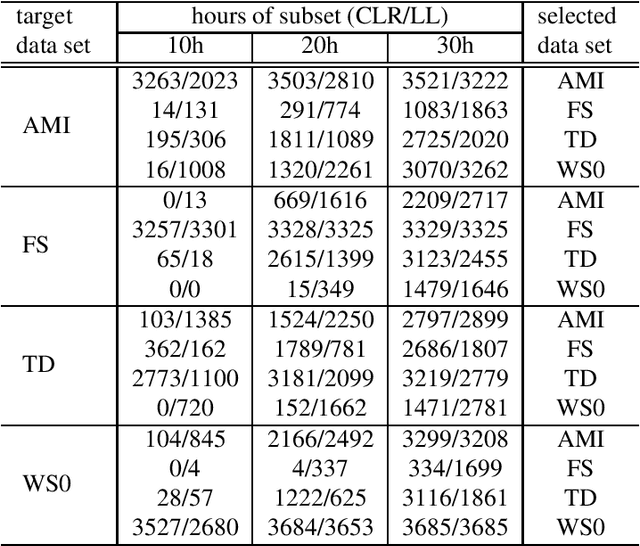
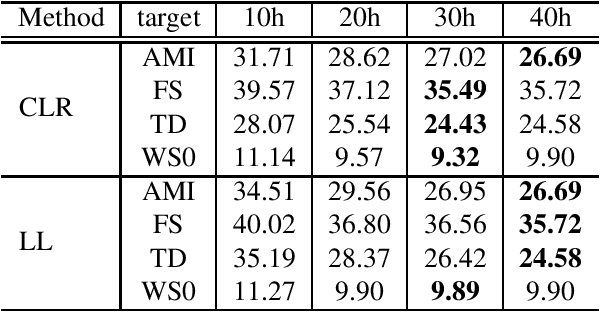
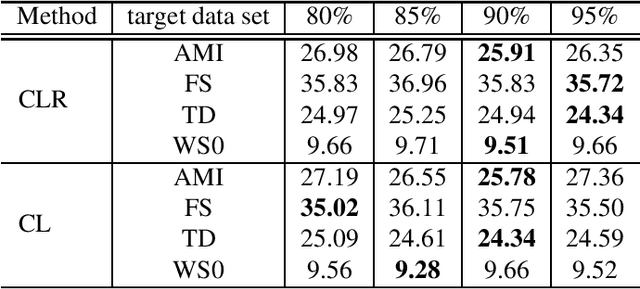
This paper proposes an unsupervised data selection method by using a submodular function based on contrastive loss ratios of target and training data sets. A model using a contrastive loss function is trained on both sets. Then the ratio of frame-level losses for each model is used by a submodular function. By using the submodular function, a training set for automatic speech recognition matching the target data set is selected. Experiments show that models trained on the data sets selected by the proposed method outperform the selection method based on log-likelihoods produced by GMM-HMM models, in terms of word error rate (WER). When selecting a fixed amount, e.g. 10 hours of data, the difference between the results of two methods on Tedtalks was 20.23% WER relative. The method can also be used to select data with the aim of minimising negative transfer, while maintaining or improving on performance of models trained on the whole training set. Results show that the WER on the WSJCAM0 data set was reduced by 6.26% relative when selecting 85% from the whole data set.
* 5 pages, accepted by ICASSP 2022
ImportantAug: a data augmentation agent for speech
Dec 14, 2021
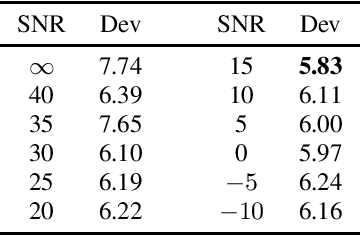


We introduce ImportantAug, a technique to augment training data for speech classification and recognition models by adding noise to unimportant regions of the speech and not to important regions. Importance is predicted for each utterance by a data augmentation agent that is trained to maximize the amount of noise it adds while minimizing its impact on recognition performance. The effectiveness of our method is illustrated on version two of the Google Speech Commands (GSC) dataset. On the standard GSC test set, it achieves a 23.3% relative error rate reduction compared to conventional noise augmentation which applies noise to speech without regard to where it might be most effective. It also provides a 25.4% error rate reduction compared to a baseline without data augmentation. Additionally, the proposed ImportantAug outperforms the conventional noise augmentation and the baseline on two test sets with additional noise added.
Efficient Encoders for Streaming Sequence Tagging
Jan 23, 2023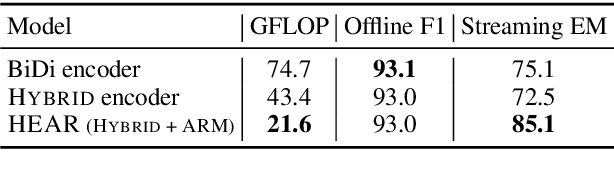
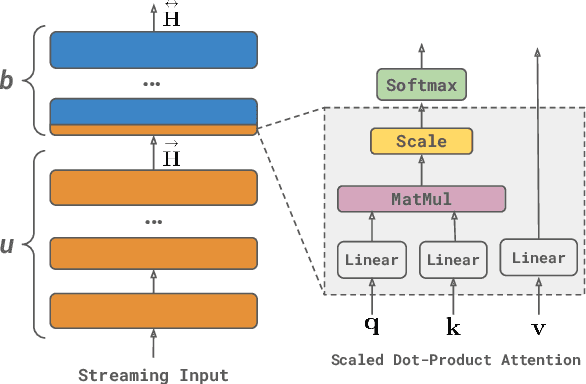

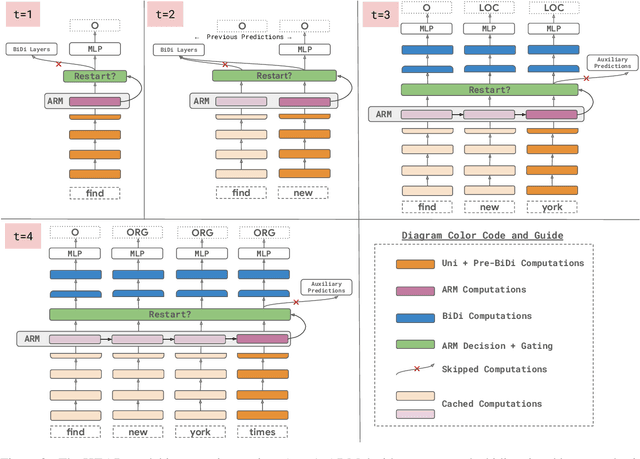
A naive application of state-of-the-art bidirectional encoders for streaming sequence tagging would require encoding each token from scratch for each new token in an incremental streaming input (like transcribed speech). The lack of re-usability of previous computation leads to a higher number of Floating Point Operations (or FLOPs) and higher number of unnecessary label flips. Increased FLOPs consequently lead to higher wall-clock time and increased label flipping leads to poorer streaming performance. In this work, we present a Hybrid Encoder with Adaptive Restart (HEAR) that addresses these issues while maintaining the performance of bidirectional encoders over the offline (or complete) inputs while improving performance on streaming (or incomplete) inputs. HEAR has a Hybrid unidirectional-bidirectional encoder architecture to perform sequence tagging, along with an Adaptive Restart Module (ARM) to selectively guide the restart of bidirectional portion of the encoder. Across four sequence tagging tasks, HEAR offers FLOP savings in streaming settings upto 71.1% and also outperforms bidirectional encoders for streaming predictions by upto +10% streaming exact match.
Enhancing Speech Recognition Decoding via Layer Aggregation
Apr 05, 2022
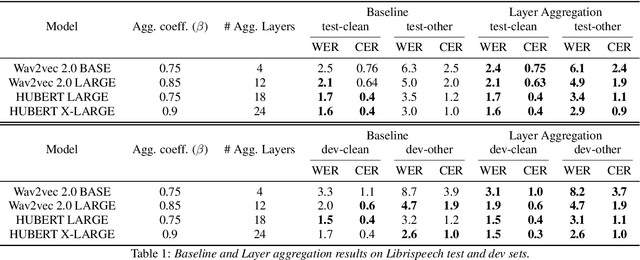
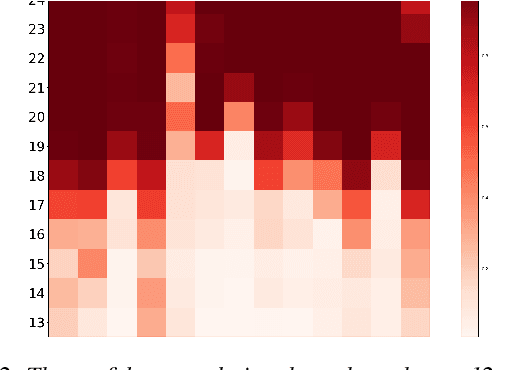
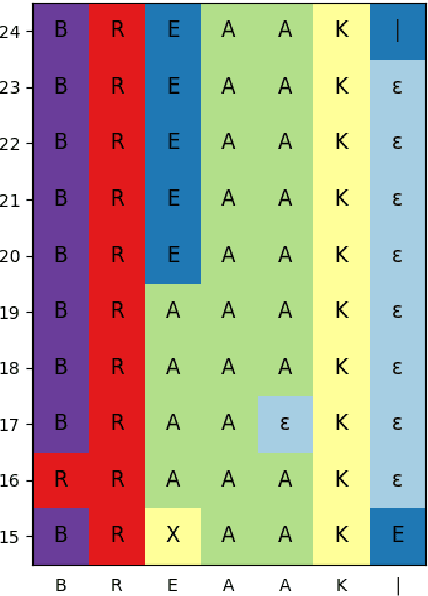
Recently proposed speech recognition systems are designed to predict using representations generated by their top layers, employing greedy decoding which isolates each timestep from the rest of the sequence. Aiming for improved performance, a beam search algorithm is frequently utilized and a language model is incorporated to assist with ranking the top candidates. In this work, we experiment with several speech recognition models and find that logits predicted using the top layers may hamper beam search from achieving optimal results. Specifically, we show that fined-tuned Wav2Vec 2.0 and HuBERT yield highly confident predictions, and hypothesize that the predictions are based on local information and may not take full advantage of the information encoded in intermediate layers. To this end, we perform a layer analysis to reveal and visualize how predictions evolve throughout the inference flow. We then propose a prediction method that aggregates the top M layers, potentially leveraging useful information encoded in intermediate layers and relaxing model confidence. We showcase the effectiveness of our approach via beam search decoding, conducting our experiments on Librispeech test and dev sets and achieving WER, and CER reduction of up to 10% and 22%, respectively.
Semi-FedSER: Semi-supervised Learning for Speech Emotion Recognition On Federated Learning using Multiview Pseudo-Labeling
Mar 15, 2022
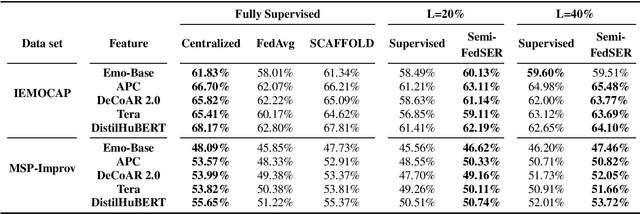
Speech Emotion Recognition (SER) application is frequently associated with privacy concerns as it often acquires and transmits speech data at the client-side to remote cloud platforms for further processing. These speech data can reveal not only speech content and affective information but the speaker's identity, demographic traits, and health status. Federated learning (FL) is a distributed machine learning algorithm that coordinates clients to train a model collaboratively without sharing local data. This algorithm shows enormous potential for SER applications as sharing raw speech or speech features from a user's device is vulnerable to privacy attacks. However, a major challenge in FL is limited availability of high-quality labeled data samples. In this work, we propose a semi-supervised federated learning framework, Semi-FedSER, that utilizes both labeled and unlabeled data samples to address the challenge of limited labeled data samples in FL. We show that our Semi-FedSER can generate desired SER performance even when the local label rate l=20 using two SER benchmark datasets: IEMOCAP and MSP-Improv.
Emotional Speech Recognition with Pre-trained Deep Visual Models
Apr 06, 2022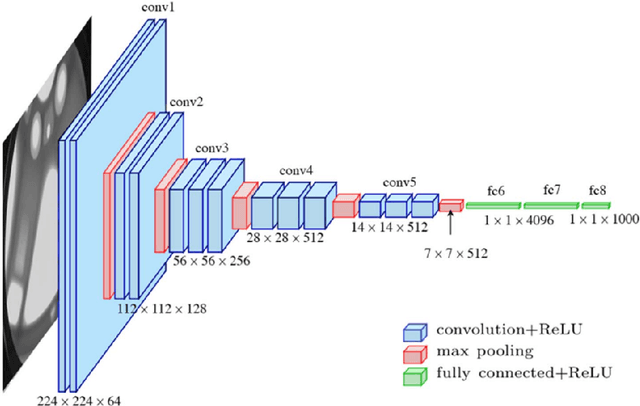

In this paper, we propose a new methodology for emotional speech recognition using visual deep neural network models. We employ the transfer learning capabilities of the pre-trained computer vision deep models to have a mandate for the emotion recognition in speech task. In order to achieve that, we propose to use a composite set of acoustic features and a procedure to convert them into images. Besides, we present a training paradigm for these models taking into consideration the different characteristics between acoustic-based images and regular ones. In our experiments, we use the pre-trained VGG-16 model and test the overall methodology on the Berlin EMO-DB dataset for speaker-independent emotion recognition. We evaluate the proposed model on the full list of the seven emotions and the results set a new state-of-the-art.
Improve Bilingual TTS Using Dynamic Language and Phonology Embedding
Dec 07, 2022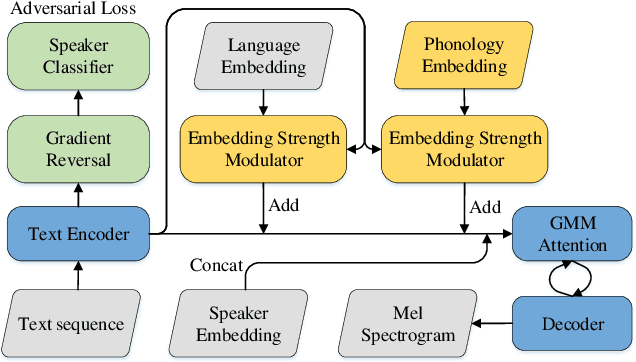
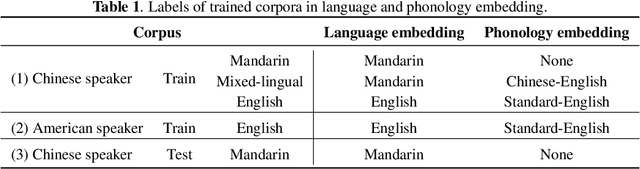
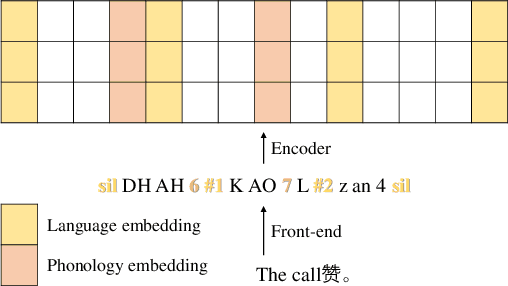
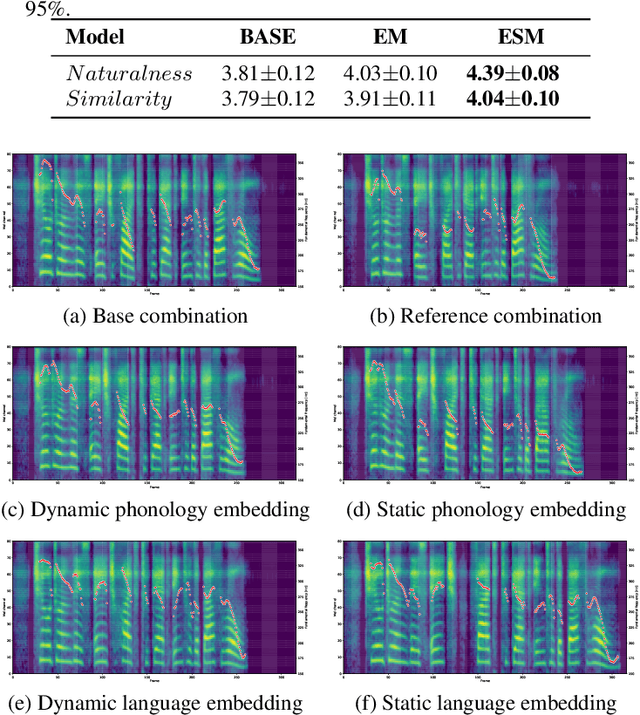
In most cases, bilingual TTS needs to handle three types of input scripts: first language only, second language only, and second language embedded in the first language. In the latter two situations, the pronunciation and intonation of the second language are usually quite different due to the influence of the first language. Therefore, it is a big challenge to accurately model the pronunciation and intonation of the second language in different contexts without mutual interference. This paper builds a Mandarin-English TTS system to acquire more standard spoken English speech from a monolingual Chinese speaker. We introduce phonology embedding to capture the English differences between different phonology. Embedding mask is applied to language embedding for distinguishing information between different languages and to phonology embedding for focusing on English expression. We specially design an embedding strength modulator to capture the dynamic strength of language and phonology. Experiments show that our approach can produce significantly more natural and standard spoken English speech of the monolingual Chinese speaker. From analysis, we find that suitable phonology control contributes to better performance in different scenarios.
Successes and critical failures of neural networks in capturing human-like speech recognition
Apr 06, 2022
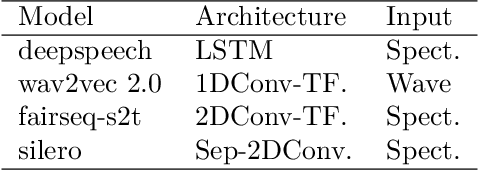
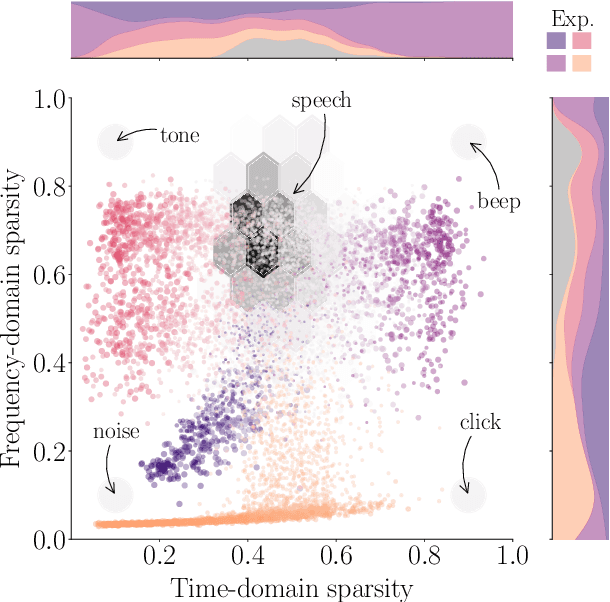
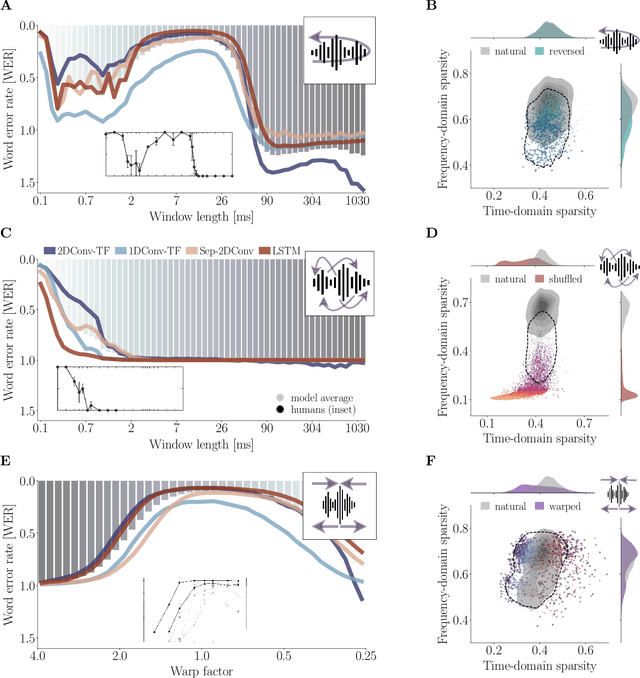
Natural and artificial audition can in principle evolve different solutions to a given problem. The constraints of the task, however, can nudge the cognitive science and engineering of audition to qualitatively converge, suggesting that a closer mutual examination would improve artificial hearing systems and process models of the mind and brain. Speech recognition - an area ripe for such exploration - is inherently robust in humans to a number transformations at various spectrotemporal granularities. To what extent are these robustness profiles accounted for by high-performing neural network systems? We bring together experiments in speech recognition under a single synthesis framework to evaluate state-of-the-art neural networks as stimulus-computable, optimized observers. In a series of experiments, we (1) clarify how influential speech manipulations in the literature relate to each other and to natural speech, (2) show the granularities at which machines exhibit out-of-distribution robustness, reproducing classical perceptual phenomena in humans, (3) identify the specific conditions where model predictions of human performance differ, and (4) demonstrate a crucial failure of all artificial systems to perceptually recover where humans do, suggesting a key specification for theory and model building. These findings encourage a tighter synergy between the cognitive science and engineering of audition.