 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
From stage to page: language independent bootstrap measures of distinctiveness in fictional speech
Jan 13, 2023
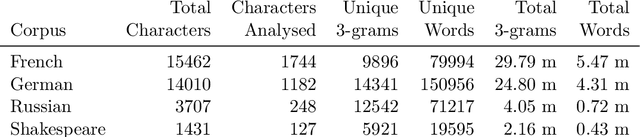
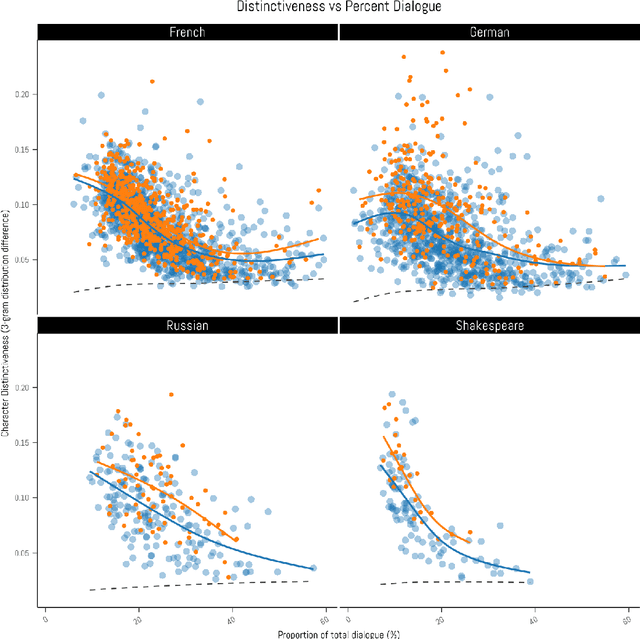
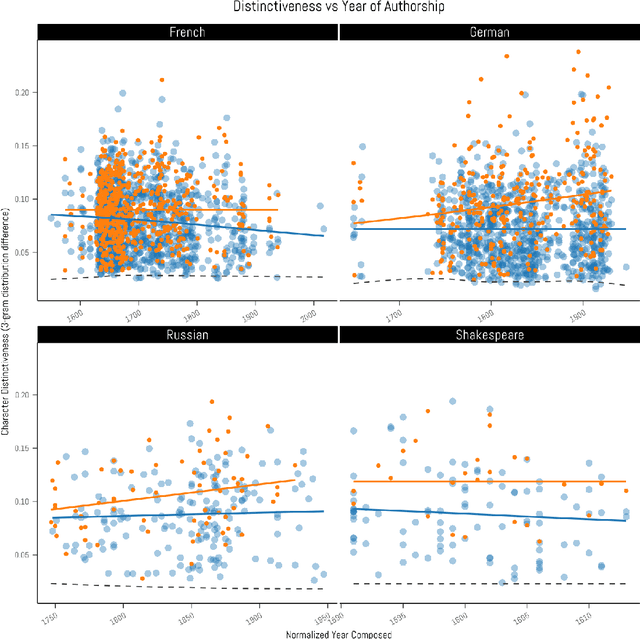
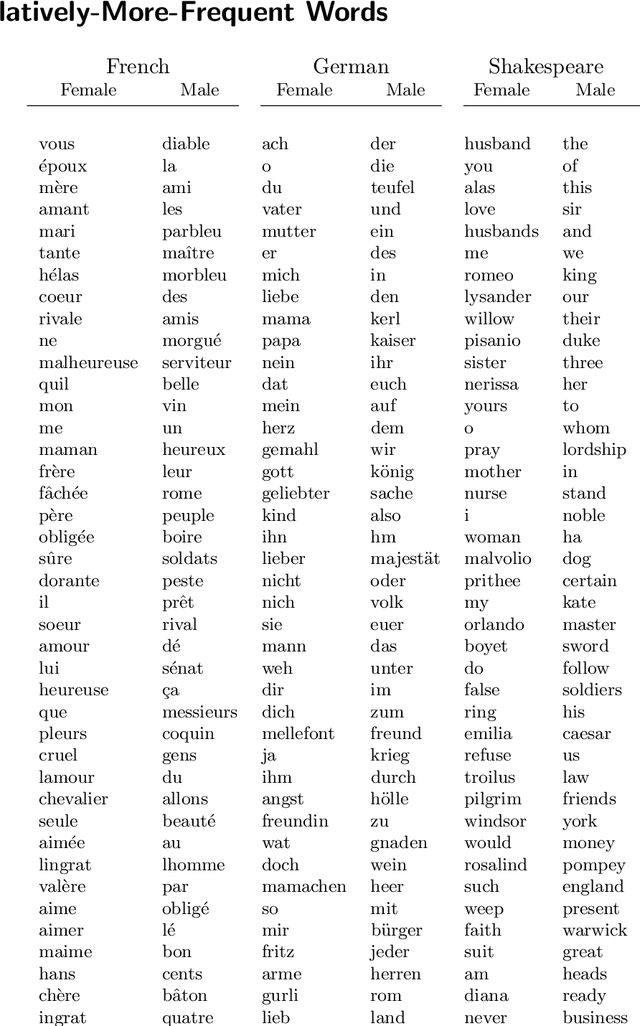
Stylometry is mostly applied to authorial style. Recently, researchers have begun investigating the style of characters, finding that the variation remains within authorial bounds. We address the stylistic distinctiveness of characters in drama. Our primary contribution is methodological; we introduce and evaluate two non-parametric methods to produce a summary statistic for character distinctiveness that can be usefully applied and compared across languages and times. Our first method is based on bootstrap distances between 3-gram probability distributions, the second (reminiscent of 'unmasking' techniques) on word keyness curves. Both methods are validated and explored by applying them to a reasonably large corpus (a subset of DraCor): we analyse 3301 characters drawn from 2324 works, covering five centuries and four languages (French, German, Russian, and the works of Shakespeare). Both methods appear useful; the 3-gram method is statistically more powerful but the word keyness method offers rich interpretability. Both methods are able to capture phonological differences such as accent or dialect, as well as broad differences in topic and lexical richness. Based on exploratory analysis, we find that smaller characters tend to be more distinctive, and that women are cross-linguistically more distinctive than men, with this latter finding carefully interrogated using multiple regression. This greater distinctiveness stems from a historical tendency for female characters to be restricted to an 'internal narrative domain' covering mainly direct discourse and family/romantic themes. It is hoped that direct, comparable statistical measures will form a basis for more sophisticated future studies, and advances in theory.
MDNet: Learning Monaural Speech Enhancement from Deep Prior Gradient
Mar 14, 2022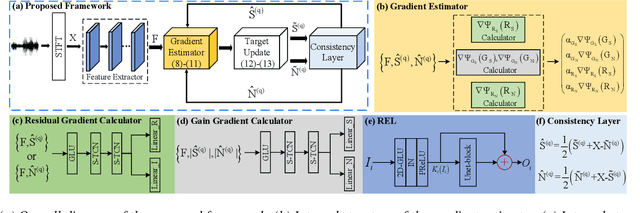
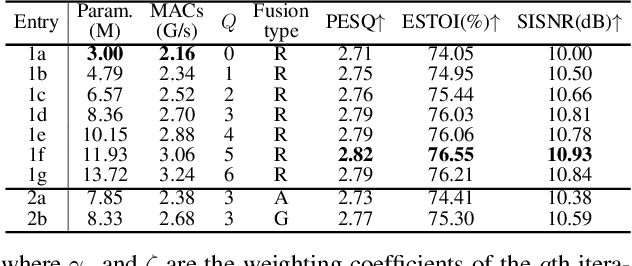
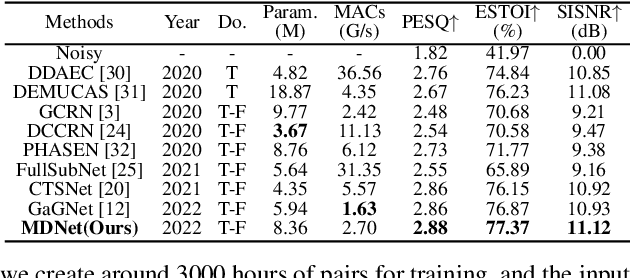
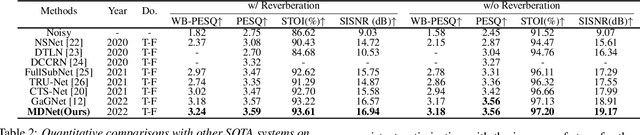
While traditional statistical signal processing model-based methods can derive the optimal estimators relying on specific statistical assumptions, current learning-based methods further promote the performance upper bound via deep neural networks but at the expense of high encapsulation and lack adequate interpretability. Standing upon the intersection between traditional model-based methods and learning-based methods, we propose a model-driven approach based on the maximum a posteriori (MAP) framework, termed as MDNet, for single-channel speech enhancement. Specifically, the original problem is formulated into the joint posterior estimation w.r.t. speech and noise components. Different from the manual assumption toward the prior terms, we propose to model the prior distribution via networks and thus can learn from training data. The framework takes the unfolding structure and in each step, the target parameters can be progressively estimated through explicit gradient descent operations. Besides, another network serves as the fusion module to further refine the previous speech estimation. The experiments are conducted on the WSJ0-SI84 and Interspeech2020 DNS-Challenge datasets, and quantitative results show that the proposed approach outshines previous state-of-the-art baselines.
Analyzing the Robustness of Unsupervised Speech Recognition
Oct 12, 2021
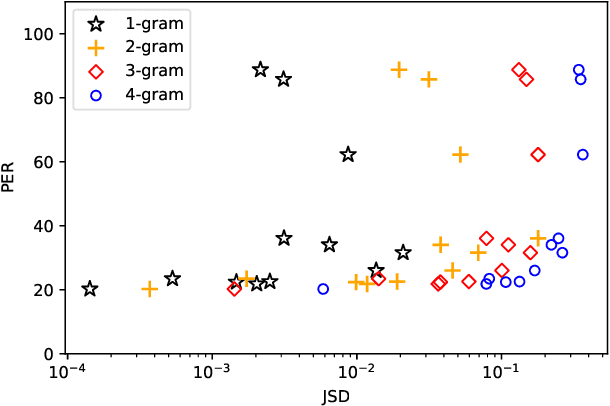
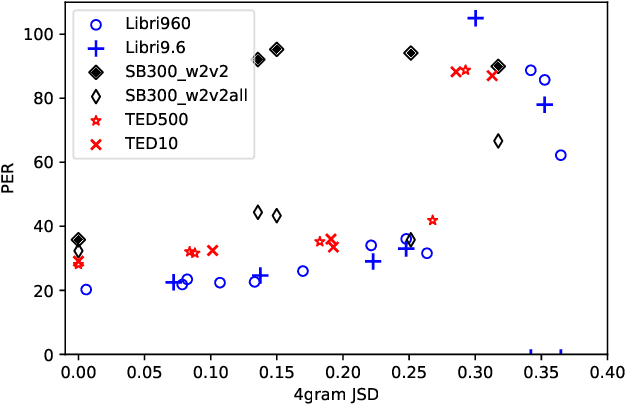
Unsupervised speech recognition (unsupervised ASR) aims to learn the ASR system with non-parallel speech and text corpus only. Wav2vec-U has shown promising results in unsupervised ASR by self-supervised speech representations coupled with Generative Adversarial Network (GAN) training, but the robustness of the unsupervised ASR framework is unknown. In this work, we further analyze the training robustness of unsupervised ASR on the domain mismatch scenarios in which the domains of unpaired speech and text are different. Three domain mismatch scenarios include: (1) using speech and text from different datasets, (2) utilizing noisy/spontaneous speech, and (3) adjusting the amount of speech and text data. We also quantify the degree of the domain mismatch by calculating the JS-divergence of phoneme n-gram between the transcription of speech and text. This metric correlates with the performance highly. Experimental results show that domain mismatch leads to inferior performance, but a self-supervised model pre-trained on the targeted speech domain can extract better representation to alleviate the performance drop.
Filter-based Discriminative Autoencoders for Children Speech Recognition
Apr 01, 2022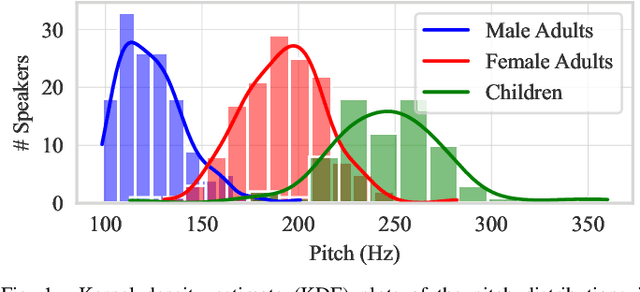
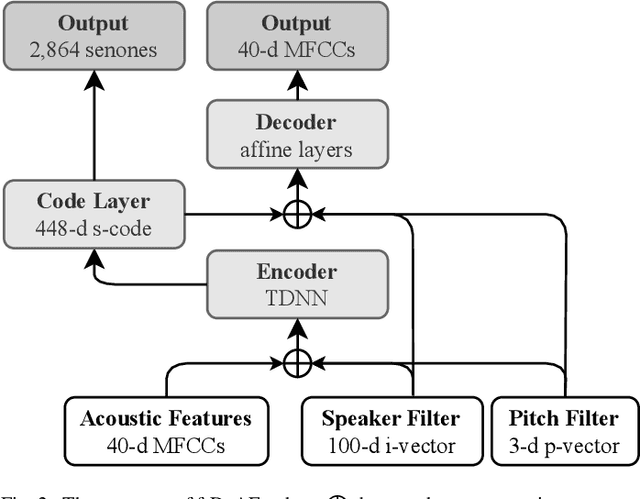
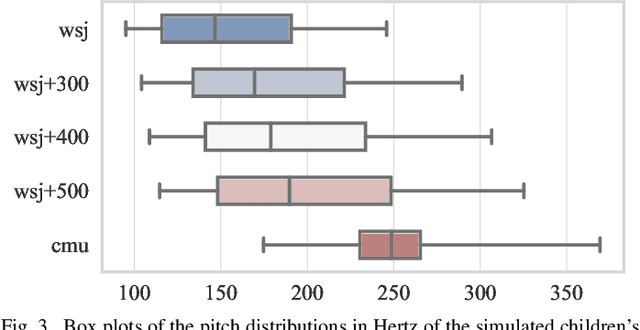
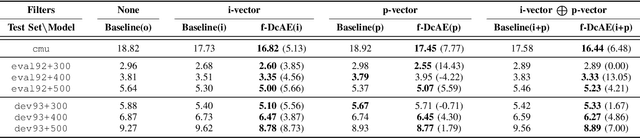
Children speech recognition is indispensable but challenging due to the diversity of children's speech. In this paper, we propose a filter-based discriminative autoencoder for acoustic modeling. To filter out the influence of various speaker types and pitches, auxiliary information of the speaker and pitch features is input into the encoder together with the acoustic features to generate phonetic embeddings. In the training phase, the decoder uses the auxiliary information and the phonetic embedding extracted by the encoder to reconstruct the input acoustic features. The autoencoder is trained by simultaneously minimizing the ASR loss and feature reconstruction error. The framework can make the phonetic embedding purer, resulting in more accurate senone (triphone-state) scores. Evaluated on the test set of the CMU Kids corpus, our system achieves a 7.8% relative WER reduction compared to the baseline system. In the domain adaptation experiment, our system also outperforms the baseline system on the British-accent PF-STAR task.
SLICER: Learning universal audio representations using low-resource self-supervised pre-training
Nov 02, 2022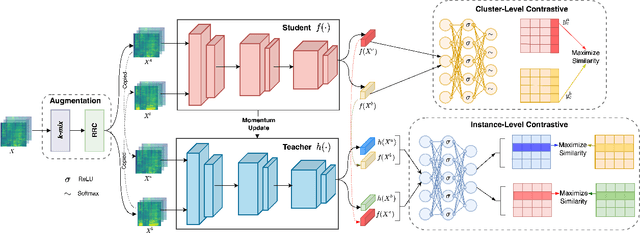
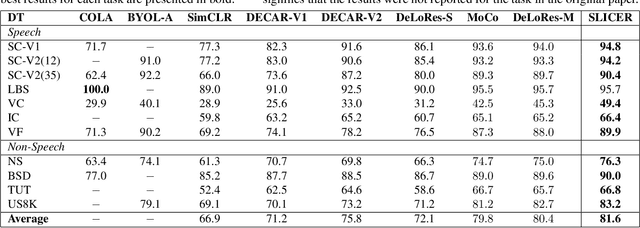
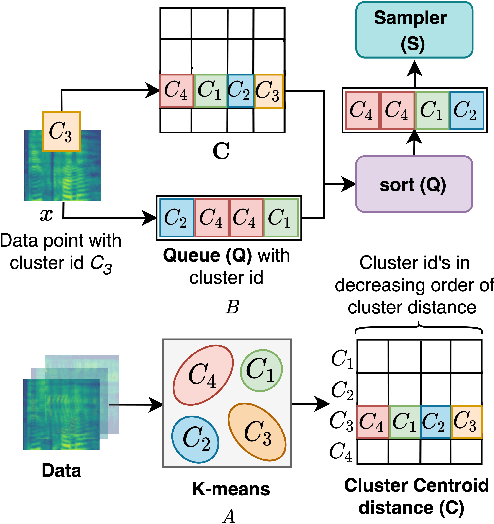

We present a new Self-Supervised Learning (SSL) approach to pre-train encoders on unlabeled audio data that reduces the need for large amounts of labeled data for audio and speech classification. Our primary aim is to learn audio representations that can generalize across a large variety of speech and non-speech tasks in a low-resource un-labeled audio pre-training setting. Inspired by the recent success of clustering and contrasting learning paradigms for SSL-based speech representation learning, we propose SLICER (Symmetrical Learning of Instance and Cluster-level Efficient Representations), which brings together the best of both clustering and contrasting learning paradigms. We use a symmetric loss between latent representations from student and teacher encoders and simultaneously solve instance and cluster-level contrastive learning tasks. We obtain cluster representations online by just projecting the input spectrogram into an output subspace with dimensions equal to the number of clusters. In addition, we propose a novel mel-spectrogram augmentation procedure, k-mix, based on mixup, which does not require labels and aids unsupervised representation learning for audio. Overall, SLICER achieves state-of-the-art results on the LAPE Benchmark \cite{9868132}, significantly outperforming DeLoRes-M and other prior approaches, which are pre-trained on $10\times$ larger of unsupervised data. We will make all our codes available on GitHub.
MsEmoTTS: Multi-scale emotion transfer, prediction, and control for emotional speech synthesis
Jan 17, 2022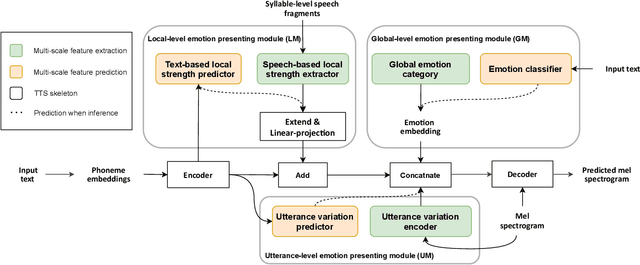
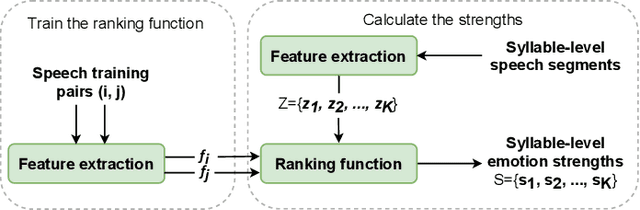
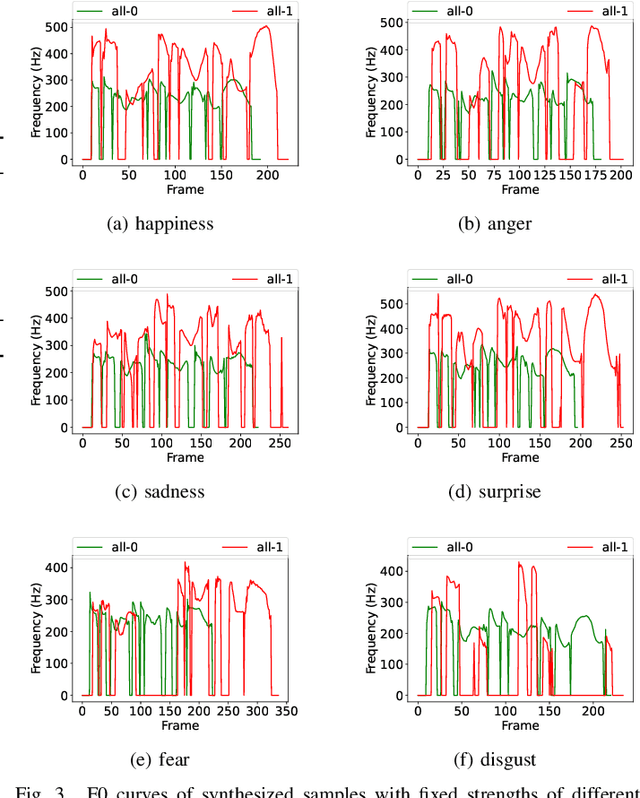
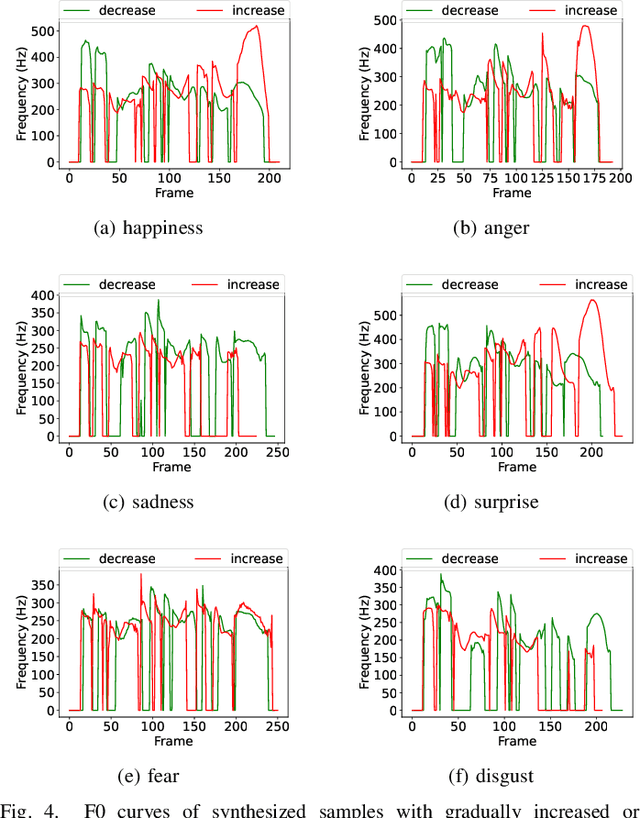
Expressive synthetic speech is essential for many human-computer interaction and audio broadcast scenarios, and thus synthesizing expressive speech has attracted much attention in recent years. Previous methods performed the expressive speech synthesis either with explicit labels or with a fixed-length style embedding extracted from reference audio, both of which can only learn an average style and thus ignores the multi-scale nature of speech prosody. In this paper, we propose MsEmoTTS, a multi-scale emotional speech synthesis framework, to model the emotion from different levels. Specifically, the proposed method is a typical attention-based sequence-to-sequence model and with proposed three modules, including global-level emotion presenting module (GM), utterance-level emotion presenting module (UM), and local-level emotion presenting module (LM), to model the global emotion category, utterance-level emotion variation, and syllable-level emotion strength, respectively. In addition to modeling the emotion from different levels, the proposed method also allows us to synthesize emotional speech in different ways, i.e., transferring the emotion from reference audio, predicting the emotion from input text, and controlling the emotion strength manually. Extensive experiments conducted on a Chinese emotional speech corpus demonstrate that the proposed method outperforms the compared reference audio-based and text-based emotional speech synthesis methods on the emotion transfer speech synthesis and text-based emotion prediction speech synthesis respectively. Besides, the experiments also show that the proposed method can control the emotion expressions flexibly. Detailed analysis shows the effectiveness of each module and the good design of the proposed method.
Harmonicity Plays a Critical Role in DNN Based Versus in Biologically-Inspired Monaural Speech Segregation Systems
Mar 08, 2022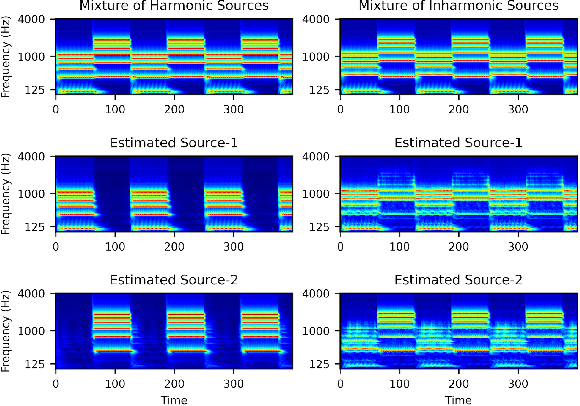
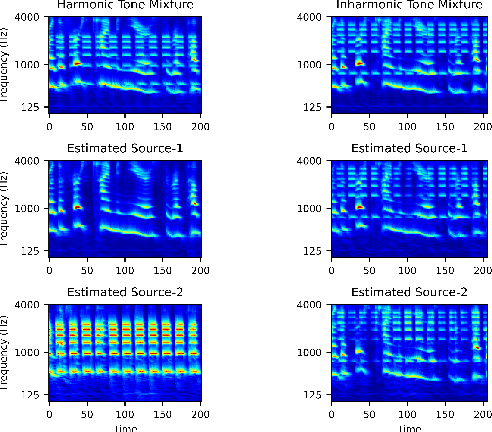
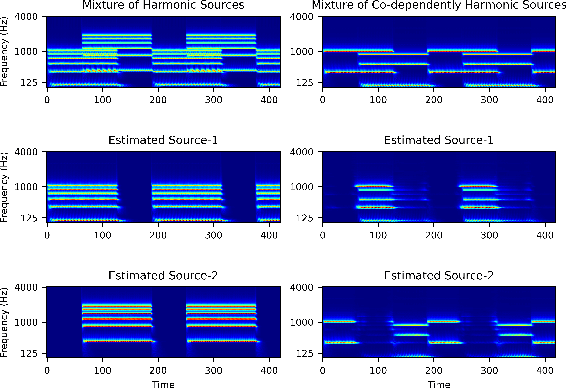
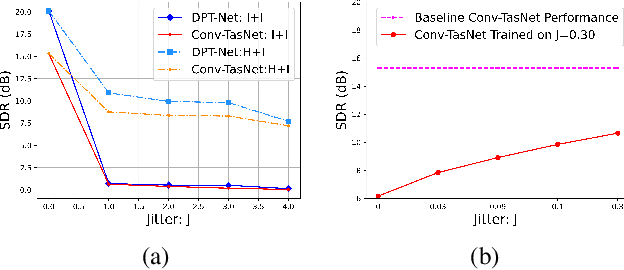
Recent advancements in deep learning have led to drastic improvements in speech segregation models. Despite their success and growing applicability, few efforts have been made to analyze the underlying principles that these networks learn to perform segregation. Here we analyze the role of harmonicity on two state-of-the-art Deep Neural Networks (DNN)-based models- Conv-TasNet and DPT-Net. We evaluate their performance with mixtures of natural speech versus slightly manipulated inharmonic speech, where harmonics are slightly frequency jittered. We find that performance deteriorates significantly if one source is even slightly harmonically jittered, e.g., an imperceptible 3% harmonic jitter degrades performance of Conv-TasNet from 15.4 dB to 0.70 dB. Training the model on inharmonic speech does not remedy this sensitivity, instead resulting in worse performance on natural speech mixtures, making inharmonicity a powerful adversarial factor in DNN models. Furthermore, additional analyses reveal that DNN algorithms deviate markedly from biologically inspired algorithms that rely primarily on timing cues and not harmonicity to segregate speech.
A Survey of Multilingual Models for Automatic Speech Recognition
Feb 25, 2022Although Automatic Speech Recognition (ASR) systems have achieved human-like performance for a few languages, the majority of the world's languages do not have usable systems due to the lack of large speech datasets to train these models. Cross-lingual transfer is an attractive solution to this problem, because low-resource languages can potentially benefit from higher-resource languages either through transfer learning, or being jointly trained in the same multilingual model. The problem of cross-lingual transfer has been well studied in ASR, however, recent advances in Self Supervised Learning are opening up avenues for unlabeled speech data to be used in multilingual ASR models, which can pave the way for improved performance on low-resource languages. In this paper, we survey the state of the art in multilingual ASR models that are built with cross-lingual transfer in mind. We present best practices for building multilingual models from research across diverse languages and techniques, discuss open questions and provide recommendations for future work.
Beyond Statistical Similarity: Rethinking Metrics for Deep Generative Models in Engineering Design
Feb 11, 2023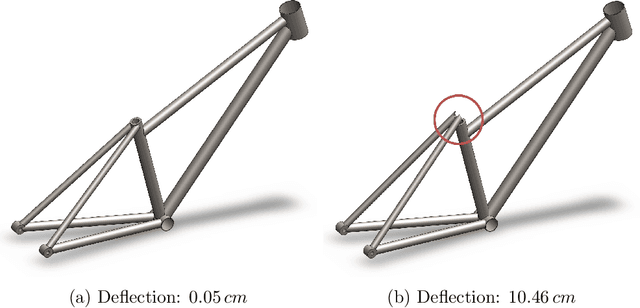
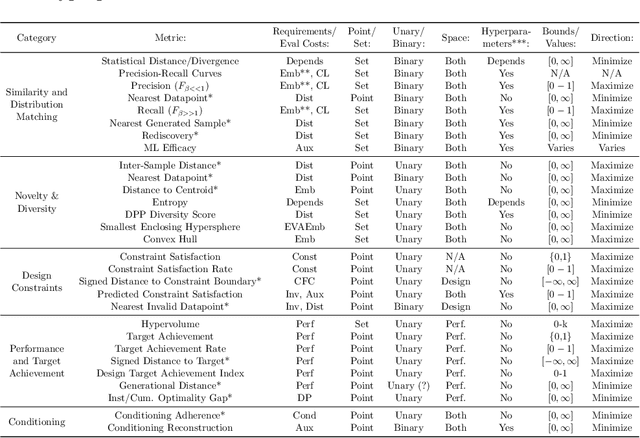
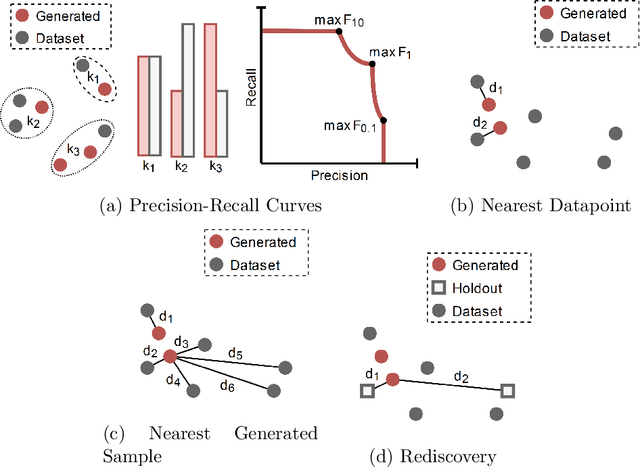
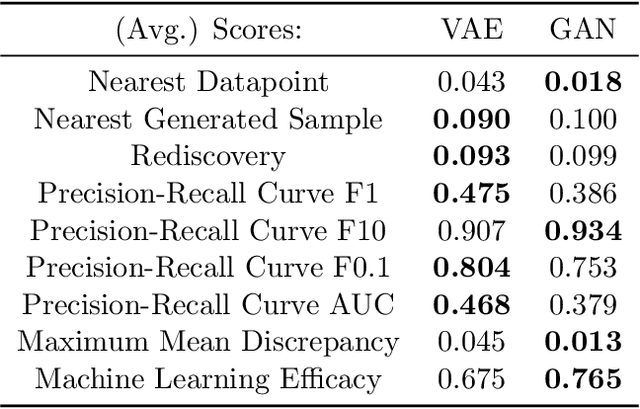
Deep generative models, such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), Diffusion Models, and Transformers, have shown great promise in a variety of applications, including image and speech synthesis, natural language processing, and drug discovery. However, when applied to engineering design problems, evaluating the performance of these models can be challenging, as traditional statistical metrics based on likelihood may not fully capture the requirements of engineering applications. This paper doubles as a review and a practical guide to evaluation metrics for deep generative models (DGMs) in engineering design. We first summarize well-accepted `classic' evaluation metrics for deep generative models grounded in machine learning theory and typical computer science applications. Using case studies, we then highlight why these metrics seldom translate well to design problems but see frequent use due to the lack of established alternatives. Next, we curate a set of design-specific metrics which have been proposed across different research communities and can be used for evaluating deep generative models. These metrics focus on unique requirements in design and engineering, such as constraint satisfaction, functional performance, novelty, and conditioning. We structure our review and discussion as a set of practical selection criteria and usage guidelines. Throughout our discussion, we apply the metrics to models trained on simple 2-dimensional example problems. Finally, to illustrate the selection process and classic usage of the presented metrics, we evaluate three deep generative models on a multifaceted bicycle frame design problem considering performance target achievement, design novelty, and geometric constraints. We publicly release the code for the datasets, models, and metrics used throughout the paper at decode.mit.edu/projects/metrics/.
MTTM: Metamorphic Testing for Textual Content Moderation Software
Feb 11, 2023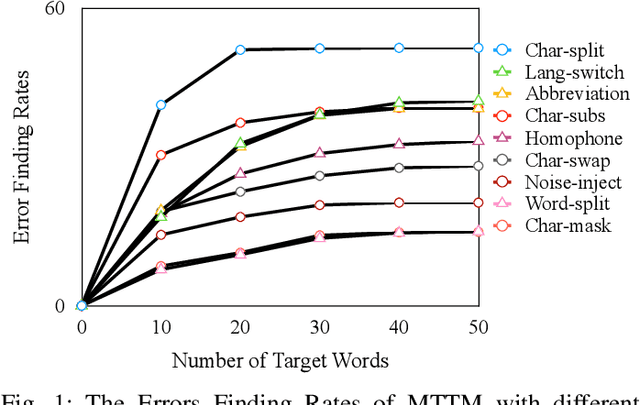
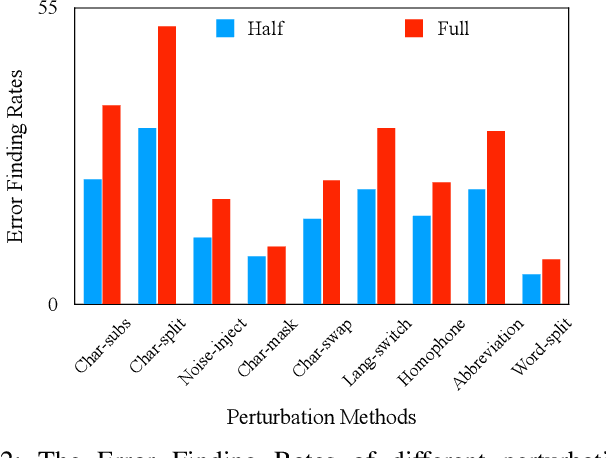
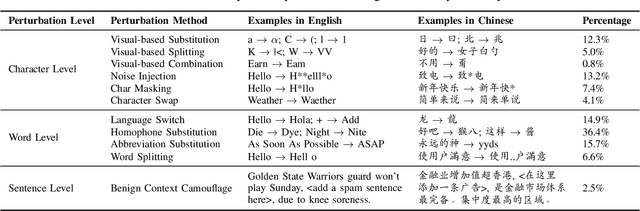
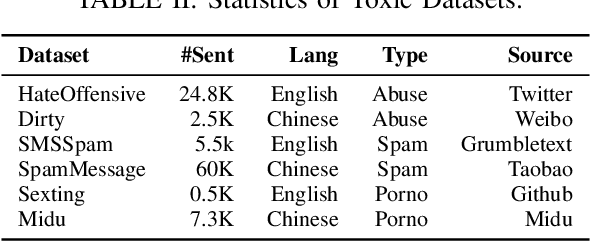
The exponential growth of social media platforms such as Twitter and Facebook has revolutionized textual communication and textual content publication in human society. However, they have been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisement, and pornography, which can lead to highly negative impacts (e.g., harmful effects on teen mental health). Researchers and practitioners have been enthusiastically developing and extensively deploying textual content moderation software to address this problem. However, we find that malicious users can evade moderation by changing only a few words in the toxic content. Moreover, modern content moderation software performance against malicious inputs remains underexplored. To this end, we propose MTTM, a Metamorphic Testing framework for Textual content Moderation software. Specifically, we conduct a pilot study on 2,000 text messages collected from real users and summarize eleven metamorphic relations across three perturbation levels: character, word, and sentence. MTTM employs these metamorphic relations on toxic textual contents to generate test cases, which are still toxic yet likely to evade moderation. In our evaluation, we employ MTTM to test three commercial textual content moderation software and two state-of-the-art moderation algorithms against three kinds of toxic content. The results show that MTTM achieves up to 83.9%, 51%, and 82.5% error finding rates (EFR) when testing commercial moderation software provided by Google, Baidu, and Huawei, respectively, and it obtains up to 91.2% EFR when testing the state-of-the-art algorithms from the academy. In addition, we leverage the test cases generated by MTTM to retrain the model we explored, which largely improves model robustness (0% to 5.9% EFR) while maintaining the accuracy on the original test set.