 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Beyond Statistical Similarity: Rethinking Metrics for Deep Generative Models in Engineering Design
Feb 11, 2023
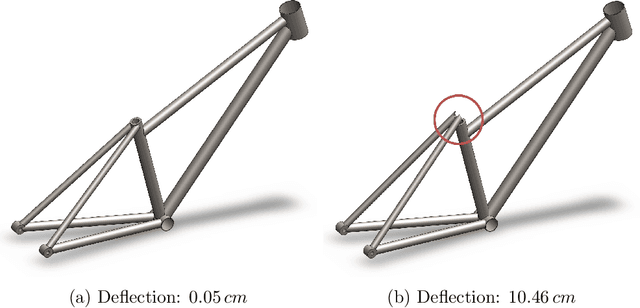
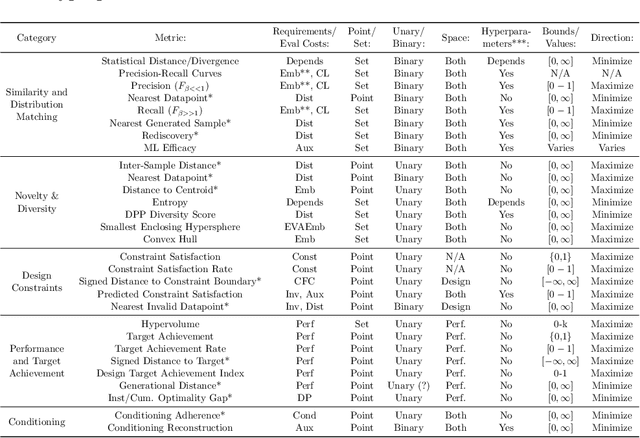
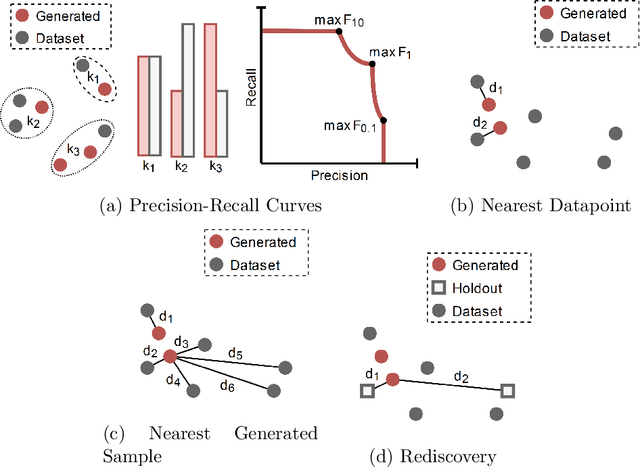
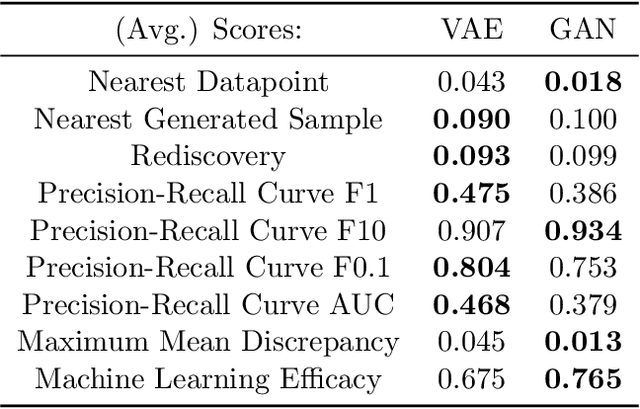
Deep generative models, such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), Diffusion Models, and Transformers, have shown great promise in a variety of applications, including image and speech synthesis, natural language processing, and drug discovery. However, when applied to engineering design problems, evaluating the performance of these models can be challenging, as traditional statistical metrics based on likelihood may not fully capture the requirements of engineering applications. This paper doubles as a review and a practical guide to evaluation metrics for deep generative models (DGMs) in engineering design. We first summarize well-accepted `classic' evaluation metrics for deep generative models grounded in machine learning theory and typical computer science applications. Using case studies, we then highlight why these metrics seldom translate well to design problems but see frequent use due to the lack of established alternatives. Next, we curate a set of design-specific metrics which have been proposed across different research communities and can be used for evaluating deep generative models. These metrics focus on unique requirements in design and engineering, such as constraint satisfaction, functional performance, novelty, and conditioning. We structure our review and discussion as a set of practical selection criteria and usage guidelines. Throughout our discussion, we apply the metrics to models trained on simple 2-dimensional example problems. Finally, to illustrate the selection process and classic usage of the presented metrics, we evaluate three deep generative models on a multifaceted bicycle frame design problem considering performance target achievement, design novelty, and geometric constraints. We publicly release the code for the datasets, models, and metrics used throughout the paper at decode.mit.edu/projects/metrics/.
MTTM: Metamorphic Testing for Textual Content Moderation Software
Feb 11, 2023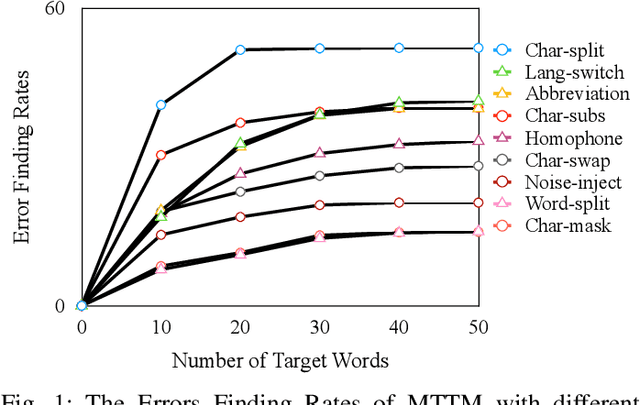
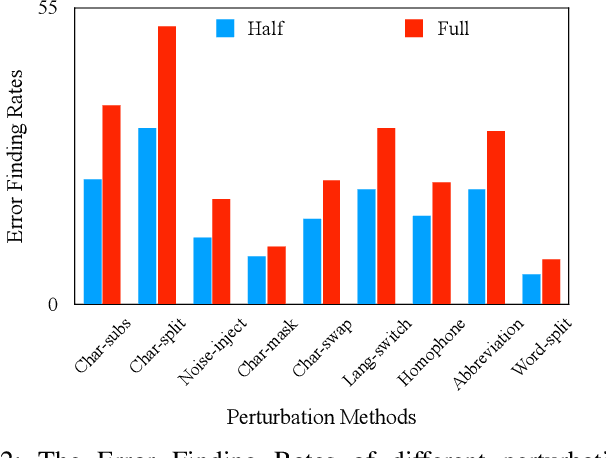
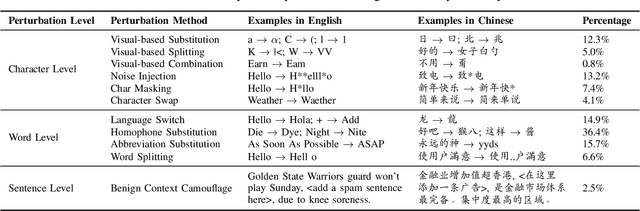
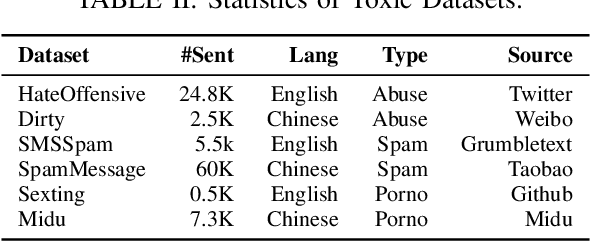
The exponential growth of social media platforms such as Twitter and Facebook has revolutionized textual communication and textual content publication in human society. However, they have been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisement, and pornography, which can lead to highly negative impacts (e.g., harmful effects on teen mental health). Researchers and practitioners have been enthusiastically developing and extensively deploying textual content moderation software to address this problem. However, we find that malicious users can evade moderation by changing only a few words in the toxic content. Moreover, modern content moderation software performance against malicious inputs remains underexplored. To this end, we propose MTTM, a Metamorphic Testing framework for Textual content Moderation software. Specifically, we conduct a pilot study on 2,000 text messages collected from real users and summarize eleven metamorphic relations across three perturbation levels: character, word, and sentence. MTTM employs these metamorphic relations on toxic textual contents to generate test cases, which are still toxic yet likely to evade moderation. In our evaluation, we employ MTTM to test three commercial textual content moderation software and two state-of-the-art moderation algorithms against three kinds of toxic content. The results show that MTTM achieves up to 83.9%, 51%, and 82.5% error finding rates (EFR) when testing commercial moderation software provided by Google, Baidu, and Huawei, respectively, and it obtains up to 91.2% EFR when testing the state-of-the-art algorithms from the academy. In addition, we leverage the test cases generated by MTTM to retrain the model we explored, which largely improves model robustness (0% to 5.9% EFR) while maintaining the accuracy on the original test set.
Self-critical Sequence Training for Automatic Speech Recognition
Apr 13, 2022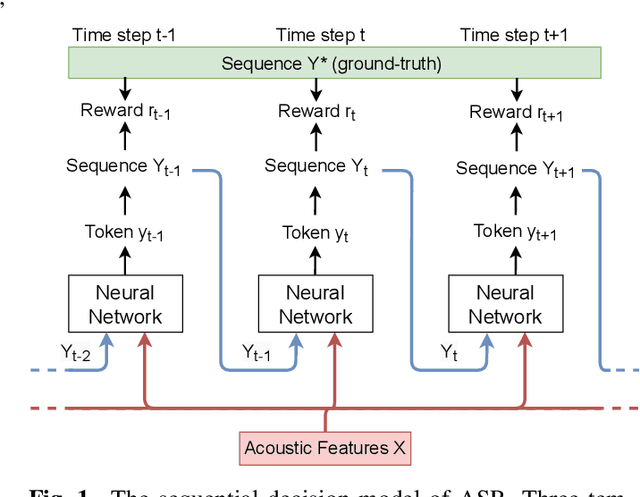
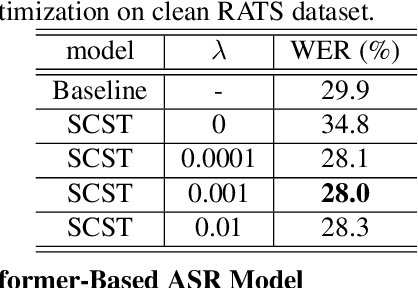
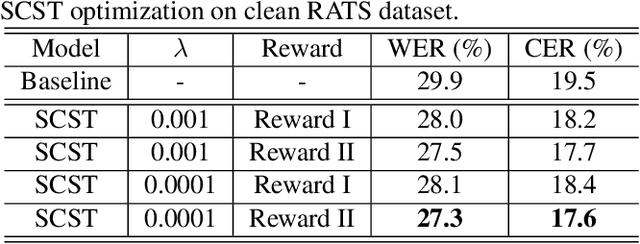
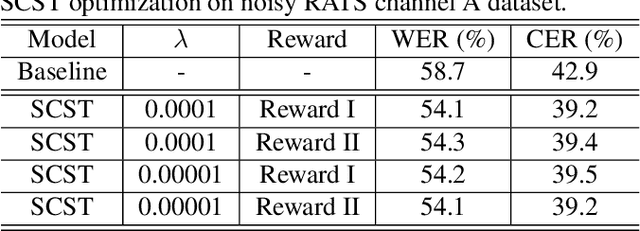
Although automatic speech recognition (ASR) task has gained remarkable success by sequence-to-sequence models, there are two main mismatches between its training and testing that might lead to performance degradation: 1) The typically used cross-entropy criterion aims to maximize log-likelihood of the training data, while the performance is evaluated by word error rate (WER), not log-likelihood; 2) The teacher-forcing method leads to the dependence on ground truth during training, which means that model has never been exposed to its own prediction before testing. In this paper, we propose an optimization method called self-critical sequence training (SCST) to make the training procedure much closer to the testing phase. As a reinforcement learning (RL) based method, SCST utilizes a customized reward function to associate the training criterion and WER. Furthermore, it removes the reliance on teacher-forcing and harmonizes the model with respect to its inference procedure. We conducted experiments on both clean and noisy speech datasets, and the results show that the proposed SCST respectively achieves 8.7% and 7.8% relative improvements over the baseline in terms of WER.
Acoustically-Driven Phoneme Removal That Preserves Vocal Affect Cues
Oct 26, 2022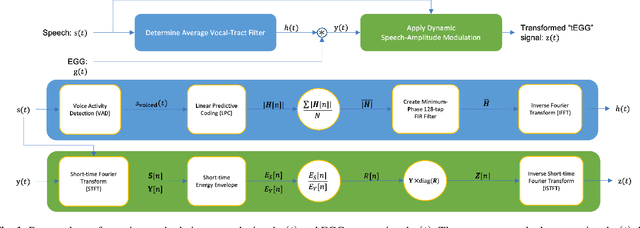
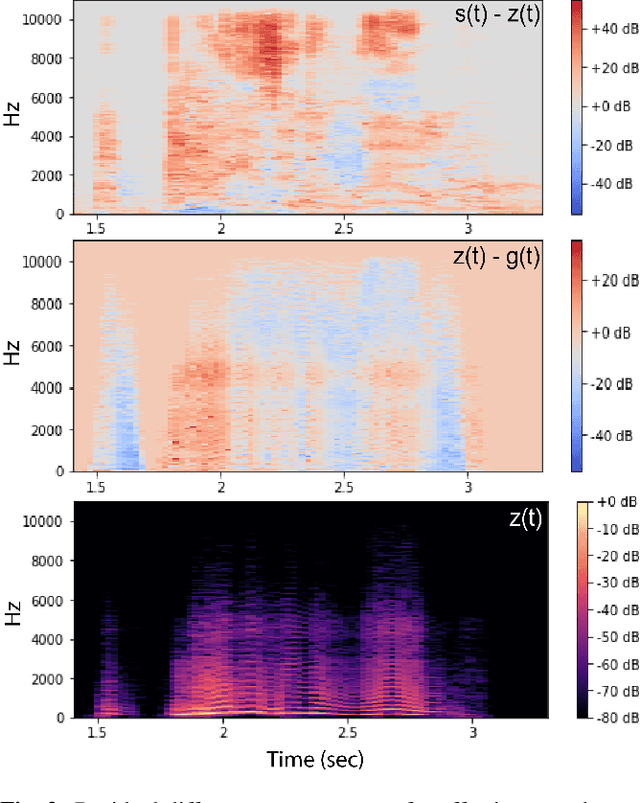
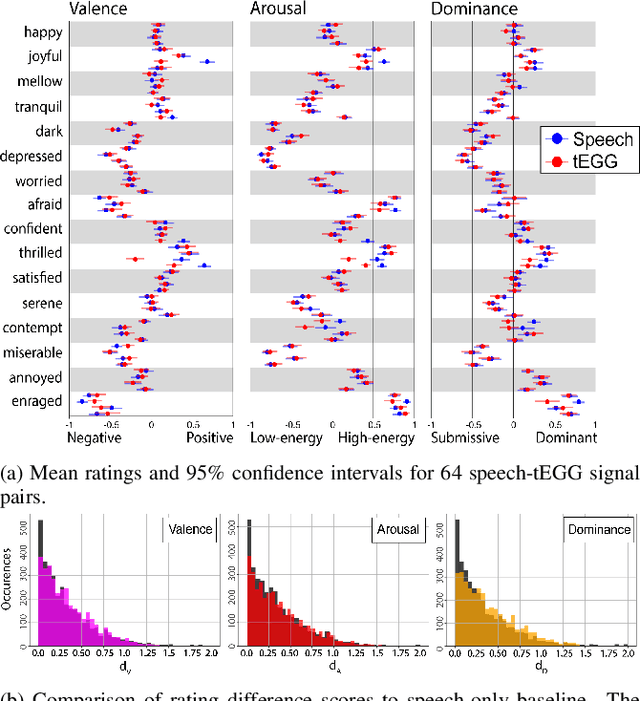
In this paper, we propose a method for removing linguistic information from speech for the purpose of isolating paralinguistic indicators of affect. The immediate utility of this method lies in clinical tests of sensitivity to vocal affect that are not confounded by language, which is impaired in a variety of clinical populations. The method is based on simultaneous recordings of speech audio and electroglottographic (EGG) signals. The speech audio signal is used to estimate the average vocal tract filter response and amplitude envelop. The EGG signal supplies a direct correlate of voice source activity that is mostly independent of phonetic articulation. These signals are used to create a third signal designed to capture as much paralinguistic information from the vocal production system as possible -- maximizing the retention of bioacoustic cues to affect -- while eliminating phonetic cues to verbal meaning. To evaluate the success of this method, we studied the perception of corresponding speech audio and transformed EGG signals in an affect rating experiment with online listeners. The results show a high degree of similarity in the perceived affect of matched signals, indicating that our method is effective.
Non-Parametric Domain Adaptation for End-to-End Speech Translation
May 23, 2022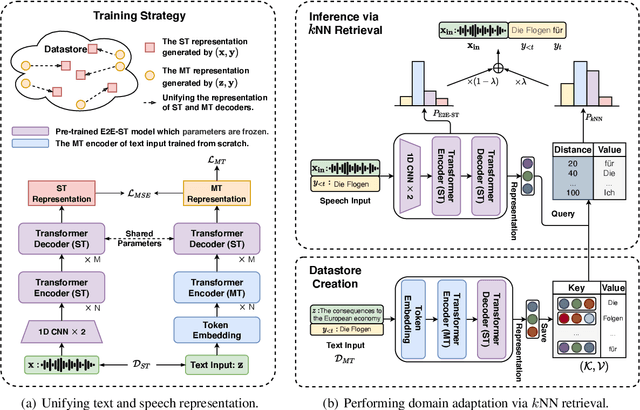
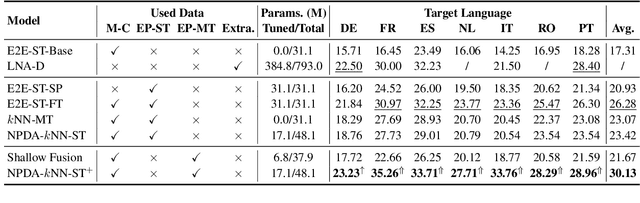
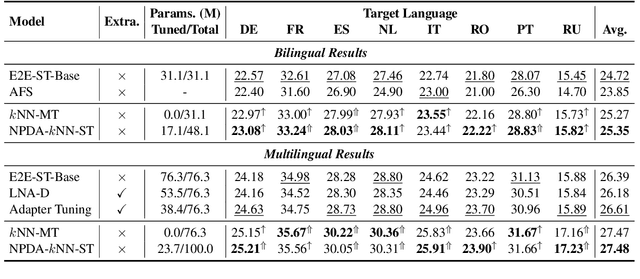
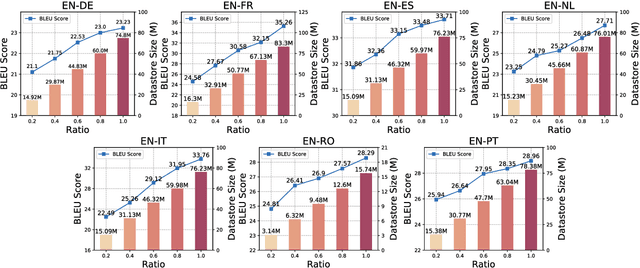
End-to-End Speech Translation (E2E-ST) has received increasing attention due to the potential of its less error propagation, lower latency, and fewer parameters. However, the effectiveness of neural-based approaches to this task is severely limited by the available training corpus, especially for domain adaptation where in-domain triplet training data is scarce or nonexistent. In this paper, we propose a novel non-parametric method that leverages domain-specific text translation corpus to achieve domain adaptation for the E2E-ST system. To this end, we first incorporate an additional encoder into the pre-trained E2E-ST model to realize text translation modelling, and then unify the decoder's output representation for text and speech translation tasks by reducing the correspondent representation mismatch in available triplet training data. During domain adaptation, a k-nearest-neighbor (kNN) classifier is introduced to produce the final translation distribution using the external datastore built by the domain-specific text translation corpus, while the universal output representation is adopted to perform a similarity search. Experiments on the Europarl-ST benchmark demonstrate that when in-domain text translation data is involved only, our proposed approach significantly improves baseline by 12.82 BLEU on average in all translation directions, even outperforming the strong in-domain fine-tuning method.
An Empirical Analysis on the Vulnerabilities of End-to-End Speech Segregation Models
Jun 20, 2022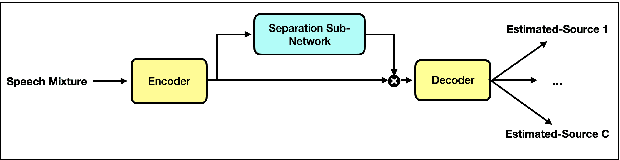
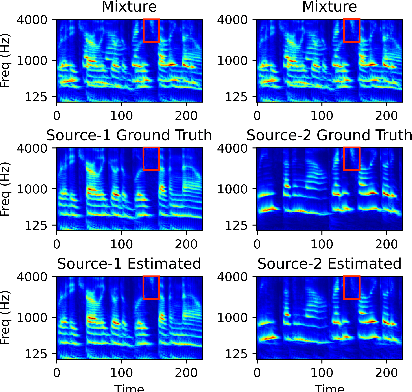
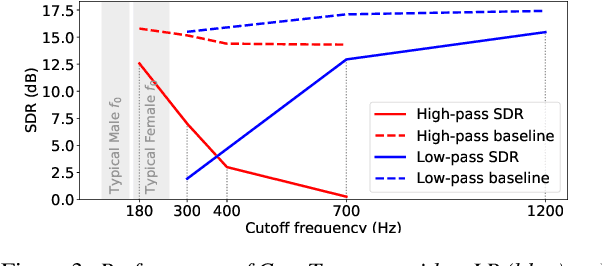
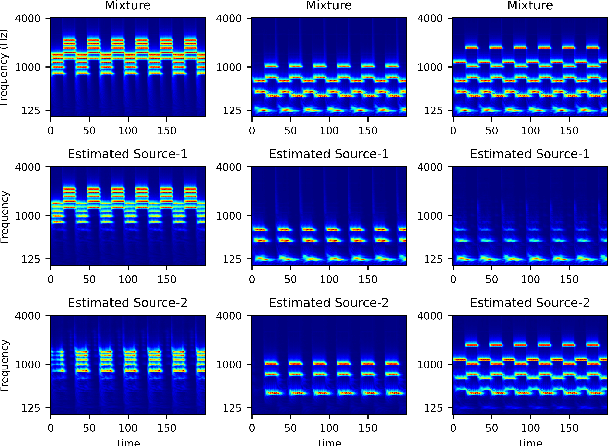
End-to-end learning models have demonstrated a remarkable capability in performing speech segregation. Despite their wide-scope of real-world applications, little is known about the mechanisms they employ to group and consequently segregate individual speakers. Knowing that harmonicity is a critical cue for these networks to group sources, in this work, we perform a thorough investigation on ConvTasnet and DPT-Net to analyze how they perform a harmonic analysis of the input mixture. We perform ablation studies where we apply low-pass, high-pass, and band-stop filters of varying pass-bands to empirically analyze the harmonics most critical for segregation. We also investigate how these networks decide which output channel to assign to an estimated source by introducing discontinuities in synthetic mixtures. We find that end-to-end networks are highly unstable, and perform poorly when confronted with deformations which are imperceptible to humans. Replacing the encoder in these networks with a spectrogram leads to lower overall performance, but much higher stability. This work helps us to understand what information these network rely on for speech segregation, and exposes two sources of generalization-errors. It also pinpoints the encoder as the part of the network responsible for these errors, allowing for a redesign with expert knowledge or transfer learning.
SLICER: Learning universal audio representations using low-resource self-supervised pre-training
Nov 02, 2022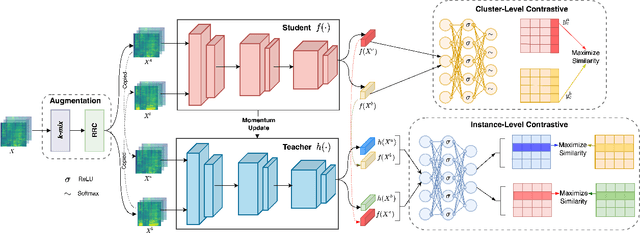
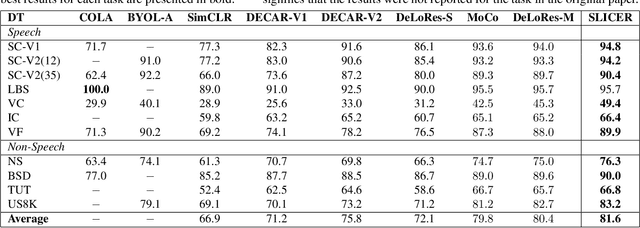
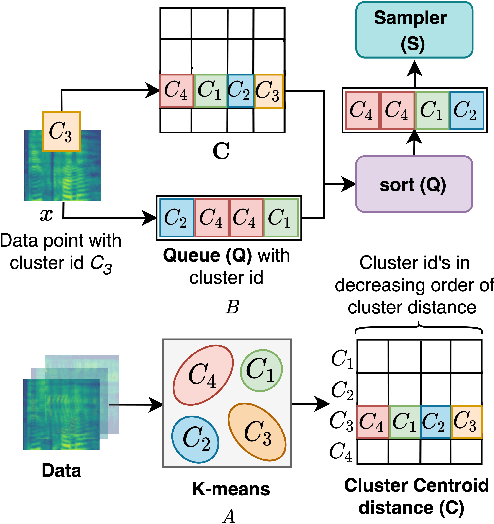

We present a new Self-Supervised Learning (SSL) approach to pre-train encoders on unlabeled audio data that reduces the need for large amounts of labeled data for audio and speech classification. Our primary aim is to learn audio representations that can generalize across a large variety of speech and non-speech tasks in a low-resource un-labeled audio pre-training setting. Inspired by the recent success of clustering and contrasting learning paradigms for SSL-based speech representation learning, we propose SLICER (Symmetrical Learning of Instance and Cluster-level Efficient Representations), which brings together the best of both clustering and contrasting learning paradigms. We use a symmetric loss between latent representations from student and teacher encoders and simultaneously solve instance and cluster-level contrastive learning tasks. We obtain cluster representations online by just projecting the input spectrogram into an output subspace with dimensions equal to the number of clusters. In addition, we propose a novel mel-spectrogram augmentation procedure, k-mix, based on mixup, which does not require labels and aids unsupervised representation learning for audio. Overall, SLICER achieves state-of-the-art results on the LAPE Benchmark \cite{9868132}, significantly outperforming DeLoRes-M and other prior approaches, which are pre-trained on $10\times$ larger of unsupervised data. We will make all our codes available on GitHub.
MDNet: Learning Monaural Speech Enhancement from Deep Prior Gradient
Mar 16, 2022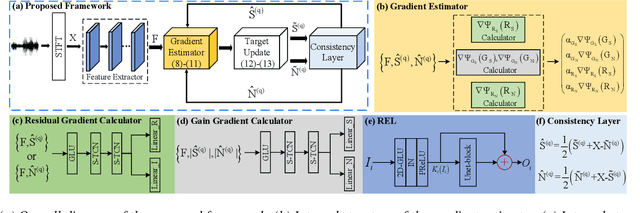
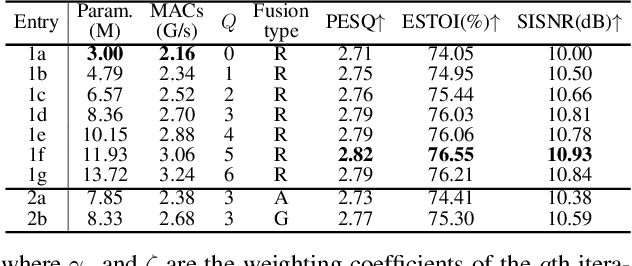
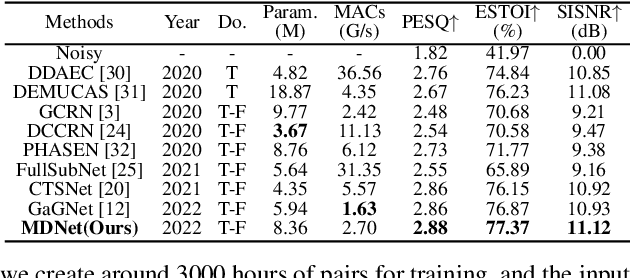
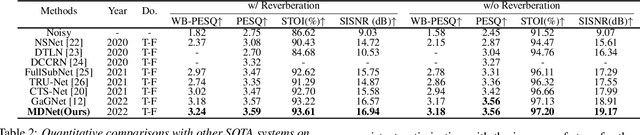
While traditional statistical signal processing model-based methods can derive the optimal estimators relying on specific statistical assumptions, current learning-based methods further promote the performance upper bound via deep neural networks but at the expense of high encapsulation and lack adequate interpretability. Standing upon the intersection between traditional model-based methods and learning-based methods, we propose a model-driven approach based on the maximum a posteriori (MAP) framework, termed as MDNet, for single-channel speech enhancement. Specifically, the original problem is formulated into the joint posterior estimation w.r.t. speech and noise components. Different from the manual assumption toward the prior terms, we propose to model the prior distribution via networks and thus can learn from training data. The framework takes the unfolding structure and in each step, the target parameters can be progressively estimated through explicit gradient descent operations. Besides, another network serves as the fusion module to further refine the previous speech estimation. The experiments are conducted on the WSJ0-SI84 and Interspeech2020 DNS-Challenge datasets, and quantitative results show that the proposed approach outshines previous state-of-the-art baselines.
Autodecompose: A generative self-supervised model for semantic decomposition
Feb 13, 2023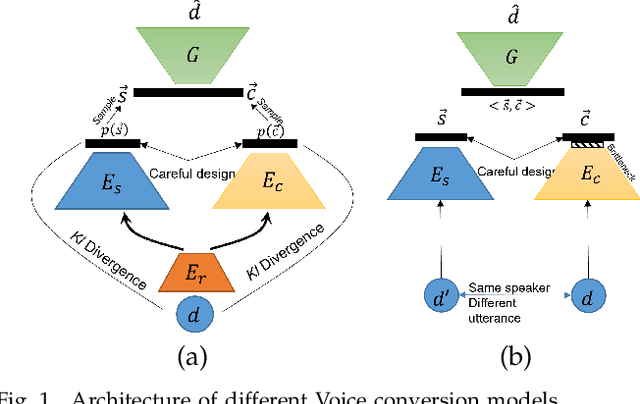

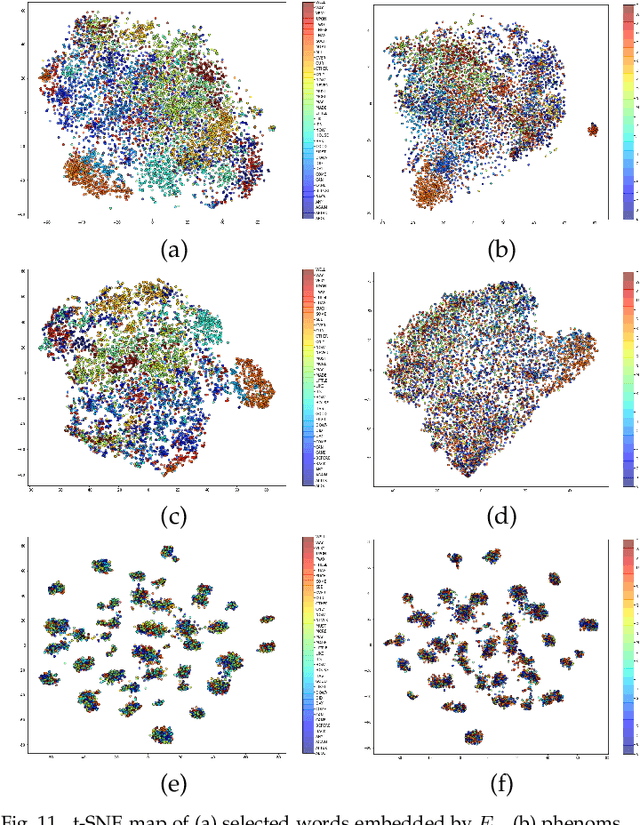
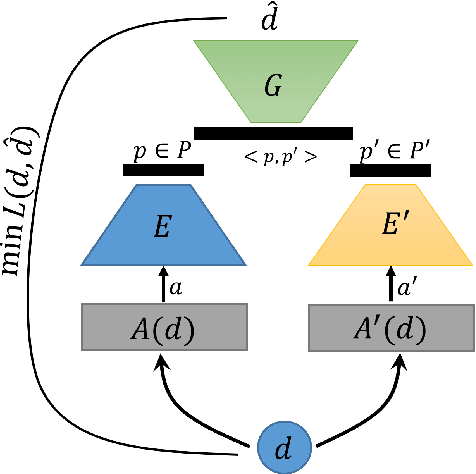
We introduce Autodecompose, a novel self-supervised generative model that decomposes data into two semantically independent properties: the desired property, which captures a specific aspect of the data (e.g. the voice in an audio signal), and the context property, which aggregates all other information (e.g. the content of the audio signal), without any labels given. Autodecompose uses two complementary augmentations, one that manipulates the context while preserving the desired property and the other that manipulates the desired property while preserving the context. The augmented variants of the data are encoded by two encoders and reconstructed by a decoder. We prove that one of the encoders embeds the desired property while the other embeds the context property. We apply Autodecompose to audio signals to encode sound source (human voice) and content. We pre-trained the model on YouTube and LibriSpeech datasets and fine-tuned in a self-supervised manner without exposing the labels. Our results showed that, using the sound source encoder of pre-trained Autodecompose, a linear classifier achieves F1 score of 97.6\% in recognizing the voice of 30 speakers using only 10 seconds of labeled samples, compared to 95.7\% for supervised models. Additionally, our experiments showed that Autodecompose is robust against overfitting even when a large model is pre-trained on a small dataset. A large Autodecompose model was pre-trained from scratch on 60 seconds of audio from 3 speakers achieved over 98.5\% F1 score in recognizing those three speakers in other unseen utterances. We finally show that the context encoder embeds information about the content of the speech and ignores the sound source information. Our sample code for training the model, as well as examples for using the pre-trained models are available here: \url{https://github.com/rezabonyadi/autodecompose}
Enhancing Speech Recognition Decoding via Layer Aggregation
Apr 05, 2022
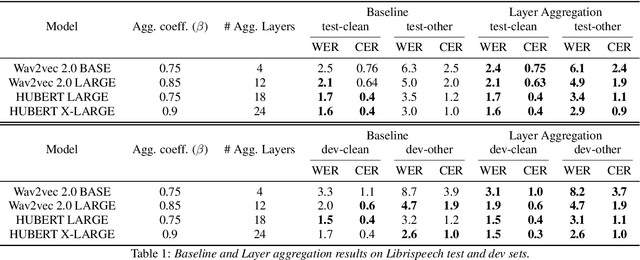
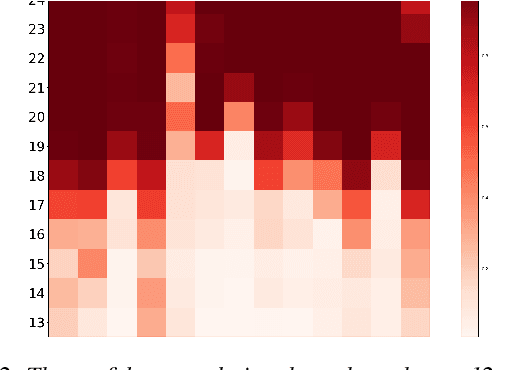
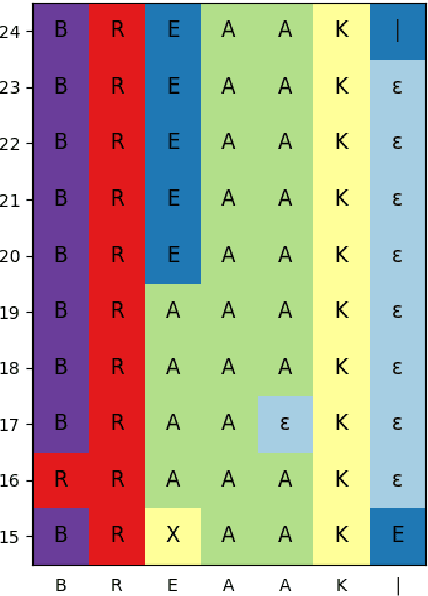
Recently proposed speech recognition systems are designed to predict using representations generated by their top layers, employing greedy decoding which isolates each timestep from the rest of the sequence. Aiming for improved performance, a beam search algorithm is frequently utilized and a language model is incorporated to assist with ranking the top candidates. In this work, we experiment with several speech recognition models and find that logits predicted using the top layers may hamper beam search from achieving optimal results. Specifically, we show that fined-tuned Wav2Vec 2.0 and HuBERT yield highly confident predictions, and hypothesize that the predictions are based on local information and may not take full advantage of the information encoded in intermediate layers. To this end, we perform a layer analysis to reveal and visualize how predictions evolve throughout the inference flow. We then propose a prediction method that aggregates the top M layers, potentially leveraging useful information encoded in intermediate layers and relaxing model confidence. We showcase the effectiveness of our approach via beam search decoding, conducting our experiments on Librispeech test and dev sets and achieving WER, and CER reduction of up to 10% and 22%, respectively.