 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Unsupervised word-level prosody tagging for controllable speech synthesis
Feb 16, 2022
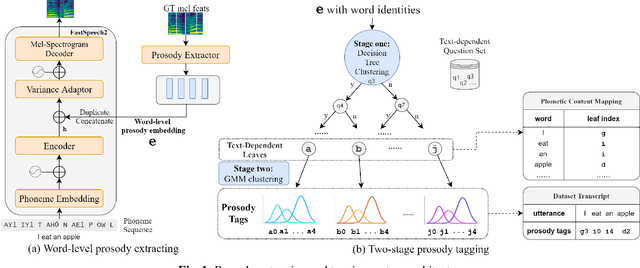
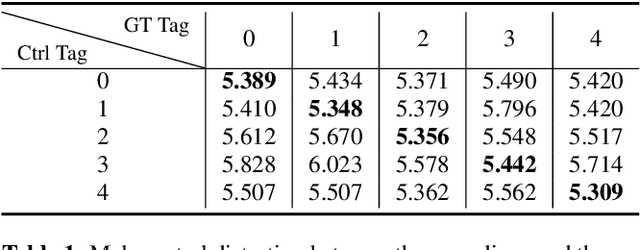
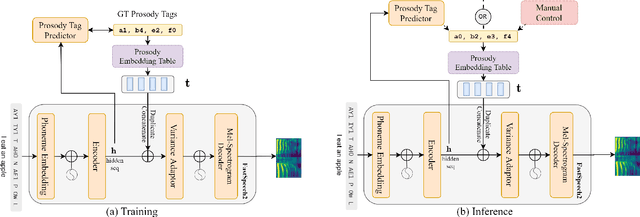
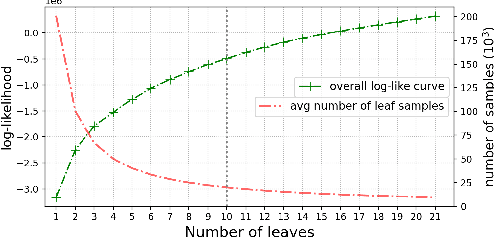
Although word-level prosody modeling in neural text-to-speech (TTS) has been investigated in recent research for diverse speech synthesis, it is still challenging to control speech synthesis manually without a specific reference. This is largely due to lack of word-level prosody tags. In this work, we propose a novel approach for unsupervised word-level prosody tagging with two stages, where we first group the words into different types with a decision tree according to their phonetic content and then cluster the prosodies using GMM within each type of words separately. This design is based on the assumption that the prosodies of different type of words, such as long or short words, should be tagged with different label sets. Furthermore, a TTS system with the derived word-level prosody tags is trained for controllable speech synthesis. Experiments on LJSpeech show that the TTS model trained with word-level prosody tags not only achieves better naturalness than a typical FastSpeech2 model, but also gains the ability to manipulate word-level prosody.
Robust Self-Supervised Audio-Visual Speech Recognition
Jan 05, 2022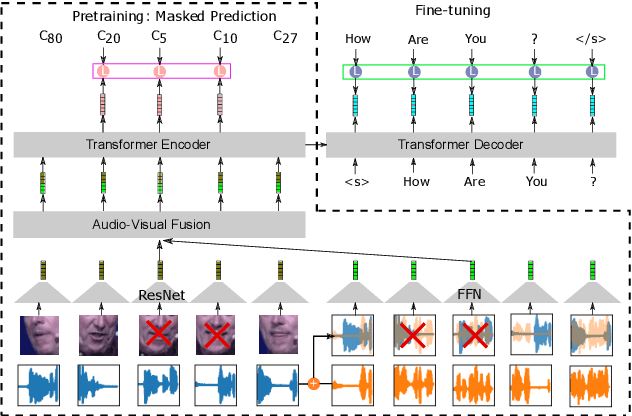

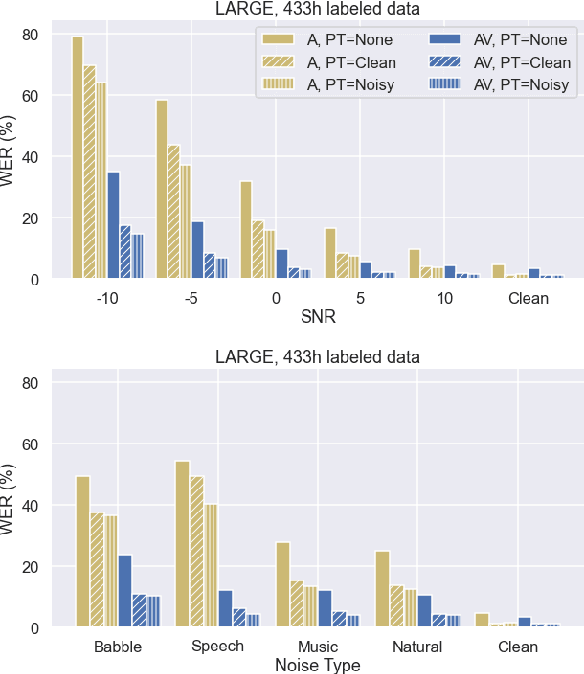
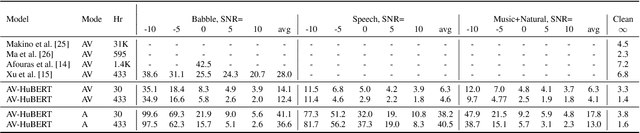
Audio-based automatic speech recognition (ASR) degrades significantly in noisy environments and is particularly vulnerable to interfering speech, as the model cannot determine which speaker to transcribe. Audio-visual speech recognition (AVSR) systems improve robustness by complementing the audio stream with the visual information that is invariant to noise and helps the model focus on the desired speaker. However, previous AVSR work focused solely on the supervised learning setup; hence the progress was hindered by the amount of labeled data available. In this work, we present a self-supervised AVSR framework built upon Audio-Visual HuBERT (AV-HuBERT), a state-of-the-art audio-visual speech representation learning model. On the largest available AVSR benchmark dataset LRS3, our approach outperforms prior state-of-the-art by ~50% (28.0% vs. 14.1%) using less than 10% of labeled data (433hr vs. 30hr) in the presence of babble noise, while reducing the WER of an audio-based model by over 75% (25.8% vs. 5.8%) on average.
JETS: Jointly Training FastSpeech2 and HiFi-GAN for End to End Text to Speech
Mar 31, 2022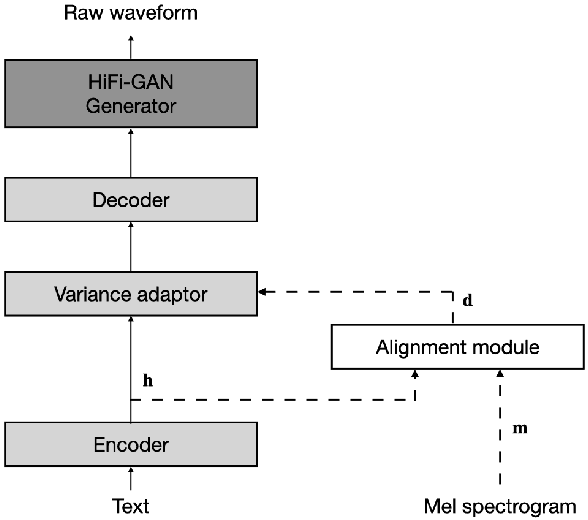
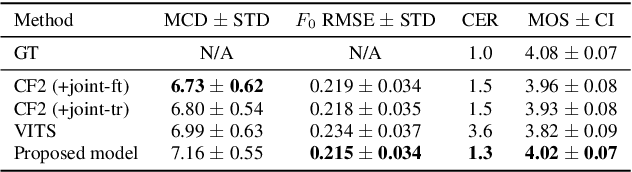
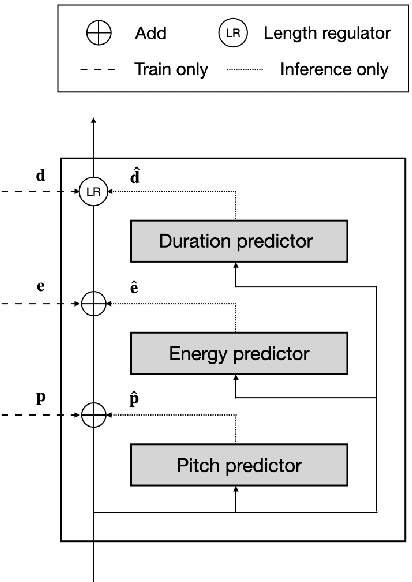
In neural text-to-speech (TTS), two-stage system or a cascade of separately learned models have shown synthesis quality close to human speech. For example, FastSpeech2 transforms an input text to a mel-spectrogram and then HiFi-GAN generates a raw waveform from a mel-spectogram where they are called an acoustic feature generator and a neural vocoder respectively. However, their training pipeline is somewhat cumbersome in that it requires a fine-tuning and an accurate speech-text alignment for optimal performance. In this work, we present end-to-end text-to-speech (E2E-TTS) model which has a simplified training pipeline and outperforms a cascade of separately learned models. Specifically, our proposed model is jointly trained FastSpeech2 and HiFi-GAN with an alignment module. Since there is no acoustic feature mismatch between training and inference, it does not requires fine-tuning. Furthermore, we remove dependency on an external speech-text alignment tool by adopting an alignment learning objective in our joint training framework. Experiments on LJSpeech corpus shows that the proposed model outperforms publicly available, state-of-the-art implementations of ESPNet2-TTS on subjective evaluation (MOS) and some objective evaluations.
Low-latency Monaural Speech Enhancement with Deep Filter-bank Equalizer
Feb 14, 2022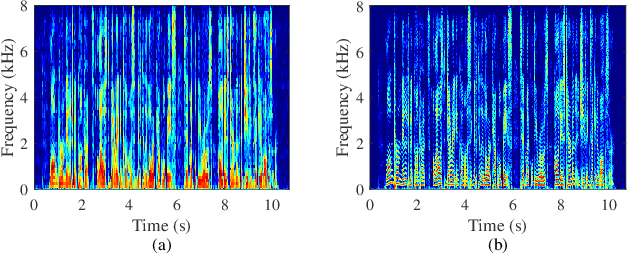

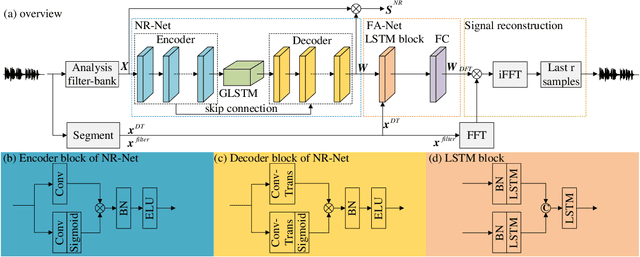
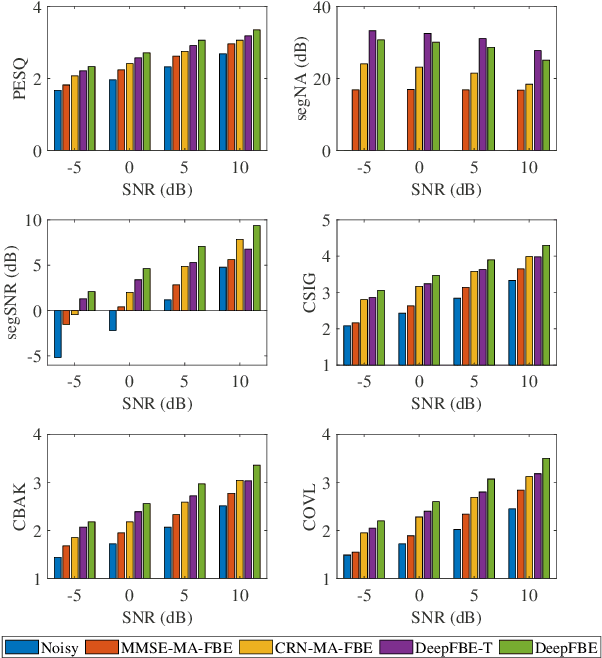
It is highly desirable that speech enhancement algorithms can achieve good performance while keeping low latency for many applications, such as digital hearing aids, acoustically transparent hearing devices, and public address systems. To improve the performance of traditional low-latency speech enhancement algorithms, a deep filter-bank equalizer (FBE) framework was proposed, which integrated a deep learning-based subband noise reduction network with a deep learning-based shortened digital filter mapping network. In the first network, a deep learning model was trained with a controllable small frame shift to satisfy the low-latency demand, i.e., $\le$ 4 ms, so as to obtain (complex) subband gains, which could be regarded as an adaptive digital filter in each frame. In the second network, to reduce the latency, this adaptive digital filter was implicitly shortened by a deep learning-based framework, and was then applied to noisy speech to reconstruct the enhanced speech without the overlap-add method. Experimental results on the WSJ0-SI84 corpus indicated that the proposed deep FBE with only 4-ms latency achieved much better performance than traditional low-latency speech enhancement algorithms in terms of the indices such as PESQ, STOI, and the amount of noise reduction.
On the Design and Training Strategies for RNN-based Online Neural Speech Separation Systems
Jun 15, 2022
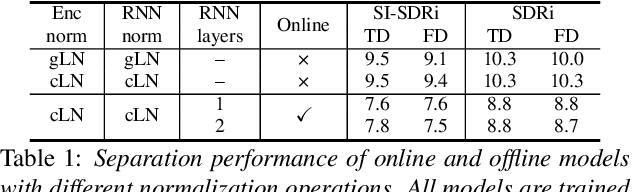
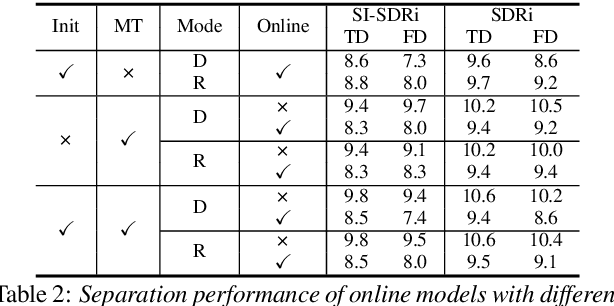
While the performance of offline neural speech separation systems has been greatly advanced by the recent development of novel neural network architectures, there is typically an inevitable performance gap between the systems and their online variants. In this paper, we investigate how RNN-based offline neural speech separation systems can be changed into their online counterparts while mitigating the performance degradation. We decompose or reorganize the forward and backward RNN layers in a bidirectional RNN layer to form an online path and an offline path, which enables the model to perform both online and offline processing with a same set of model parameters. We further introduce two training strategies for improving the online model via either a pretrained offline model or a multitask training objective. Experiment results show that compared to the online models that are trained from scratch, the proposed layer decomposition and reorganization schemes and training strategies can effectively mitigate the performance gap between two RNN-based offline separation models and their online variants.
ON-TRAC Consortium Systems for the IWSLT 2022 Dialect and Low-resource Speech Translation Tasks
May 04, 2022

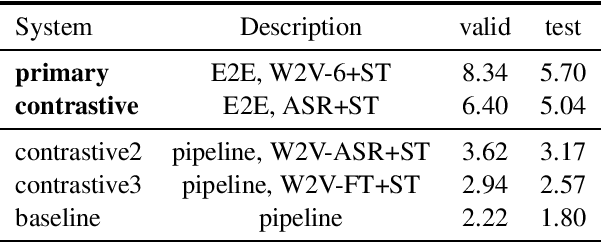

This paper describes the ON-TRAC Consortium translation systems developed for two challenge tracks featured in the Evaluation Campaign of IWSLT 2022: low-resource and dialect speech translation. For the Tunisian Arabic-English dataset (low-resource and dialect tracks), we build an end-to-end model as our joint primary submission, and compare it against cascaded models that leverage a large fine-tuned wav2vec 2.0 model for ASR. Our results show that in our settings pipeline approaches are still very competitive, and that with the use of transfer learning, they can outperform end-to-end models for speech translation (ST). For the Tamasheq-French dataset (low-resource track) our primary submission leverages intermediate representations from a wav2vec 2.0 model trained on 234 hours of Tamasheq audio, while our contrastive model uses a French phonetic transcription of the Tamasheq audio as input in a Conformer speech translation architecture jointly trained on automatic speech recognition, ST and machine translation losses. Our results highlight that self-supervised models trained on smaller sets of target data are more effective to low-resource end-to-end ST fine-tuning, compared to large off-the-shelf models. Results also illustrate that even approximate phonetic transcriptions can improve ST scores.
A Conformer-based ASR Frontend for Joint Acoustic Echo Cancellation, Speech Enhancement and Speech Separation
Nov 18, 2021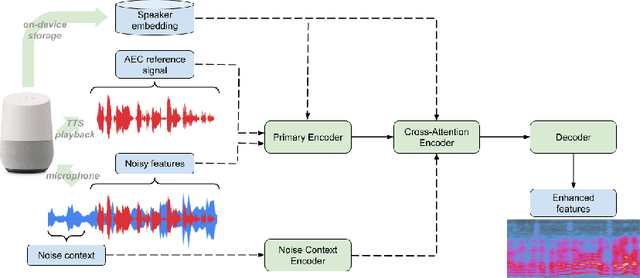
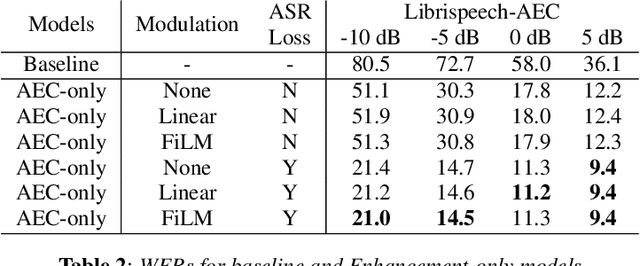
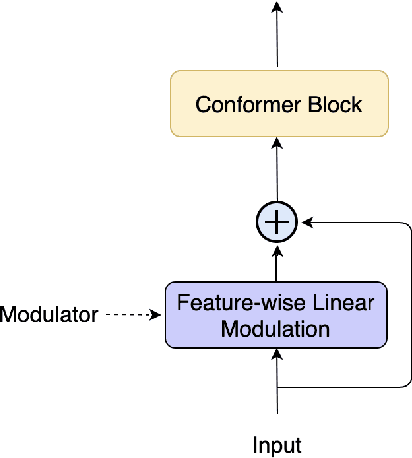
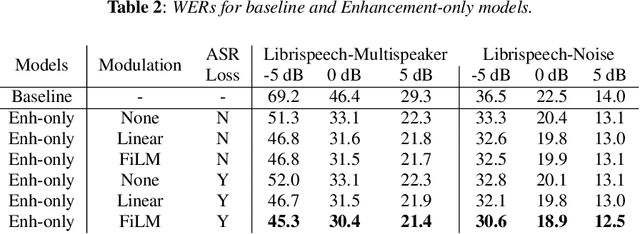
We present a frontend for improving robustness of automatic speech recognition (ASR), that jointly implements three modules within a single model: acoustic echo cancellation, speech enhancement, and speech separation. This is achieved by using a contextual enhancement neural network that can optionally make use of different types of side inputs: (1) a reference signal of the playback audio, which is necessary for echo cancellation; (2) a noise context, which is useful for speech enhancement; and (3) an embedding vector representing the voice characteristic of the target speaker of interest, which is not only critical in speech separation, but also helpful for echo cancellation and speech enhancement. We present detailed evaluations to show that the joint model performs almost as well as the task-specific models, and significantly reduces word error rate in noisy conditions even when using a large-scale state-of-the-art ASR model. Compared to the noisy baseline, the joint model reduces the word error rate in low signal-to-noise ratio conditions by at least 71% on our echo cancellation dataset, 10% on our noisy dataset, and 26% on our multi-speaker dataset. Compared to task-specific models, the joint model performs within 10% on our echo cancellation dataset, 2% on the noisy dataset, and 3% on the multi-speaker dataset.
Learning a Dual-Mode Speech Recognition Model via Self-Pruning
Jul 25, 2022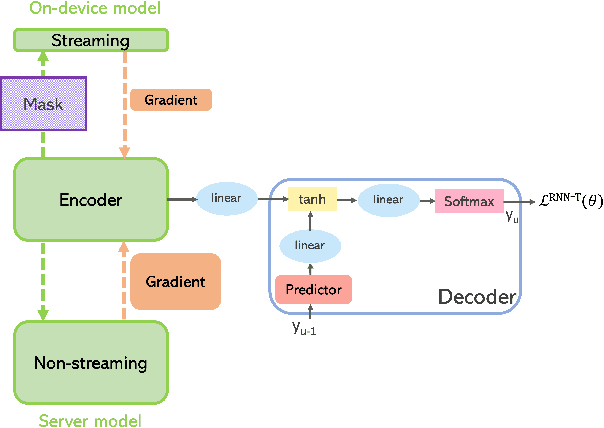

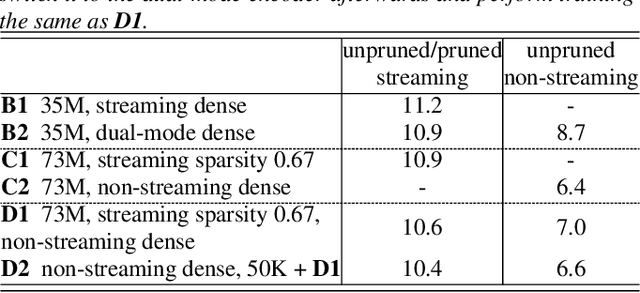

There is growing interest in unifying the streaming and full-context automatic speech recognition (ASR) networks into a single end-to-end ASR model to simplify the model training and deployment for both use cases. While in real-world ASR applications, the streaming ASR models typically operate under more storage and computational constraints - e.g., on embedded devices - than any server-side full-context models. Motivated by the recent progress in Omni-sparsity supernet training, where multiple subnetworks are jointly optimized in one single model, this work aims to jointly learn a compact sparse on-device streaming ASR model, and a large dense server non-streaming model, in a single supernet. Next, we present that, performing supernet training on both wav2vec 2.0 self-supervised learning and supervised ASR fine-tuning can not only substantially improve the large non-streaming model as shown in prior works, and also be able to improve the compact sparse streaming model.
DSPGAN: a GAN-based universal vocoder for high-fidelity TTS by time-frequency domain supervision from DSP
Nov 02, 2022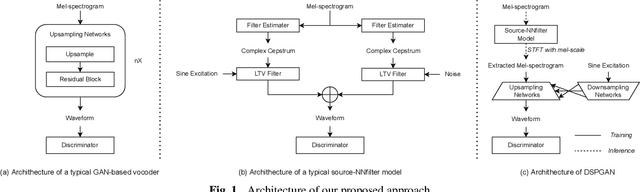
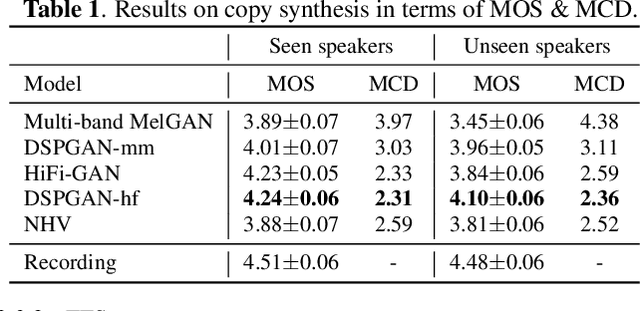
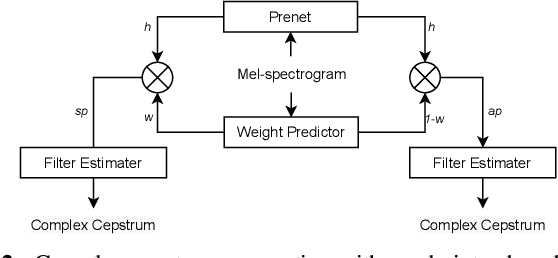

Recent development of neural vocoders based on the generative adversarial neural network (GAN) has shown their advantages of generating raw waveform conditioned on mel-spectrogram with fast inference speed and lightweight networks. Whereas, it is still challenging to train a universal neural vocoder that can synthesize high-fidelity speech from various scenarios with unseen speakers, languages, and speaking styles. In this paper, we propose DSPGAN, a GAN-based universal vocoder for high-fidelity speech synthesis by applying the time-frequency domain supervision from digital signal processing (DSP). To eliminate the mismatch problem caused by the ground-truth spectrograms in training phase and the predicted spectrograms in inference phase, we leverage the mel-spectrogram extracted from the waveform generated by a DSP module, rather than the predicted mel-spectrogram from the Text-to-Speech (TTS) acoustic model, as the time-frequency domain supervision to the GAN-based vocoder. We also utilize sine excitation as the time-domain supervision to improve the harmonic modeling and eliminate various artifacts of the GAN-based vocoder. Experimental results show that DSPGAN significantly outperforms the compared approaches and can generate high-fidelity speech based on diverse data in TTS.
Knowledge-driven Subword Grammar Modeling for Automatic Speech Recognition in Tamil and Kannada
Jul 27, 2022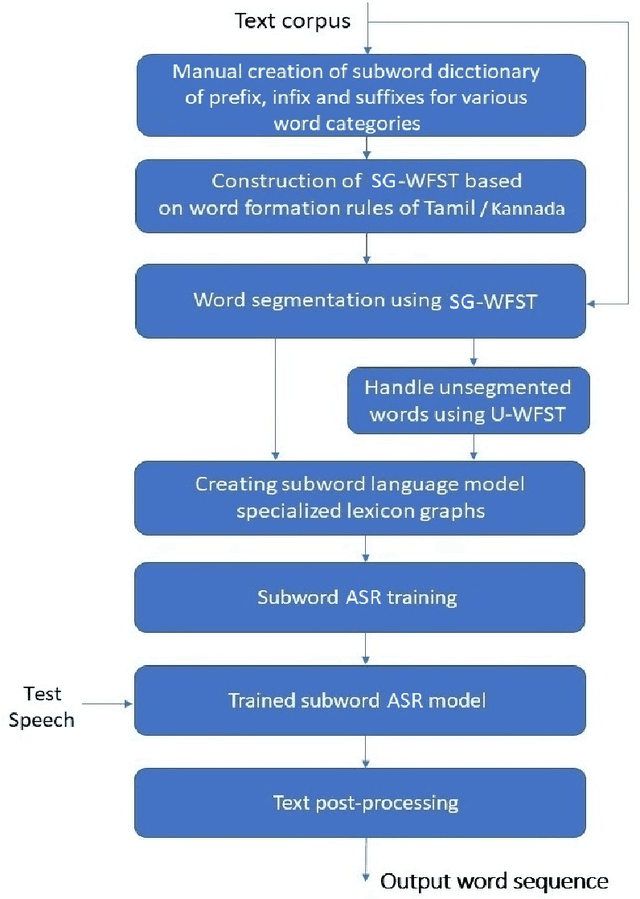
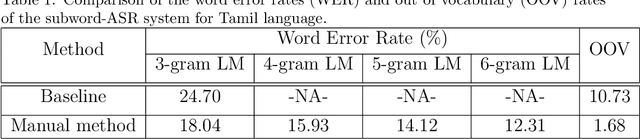
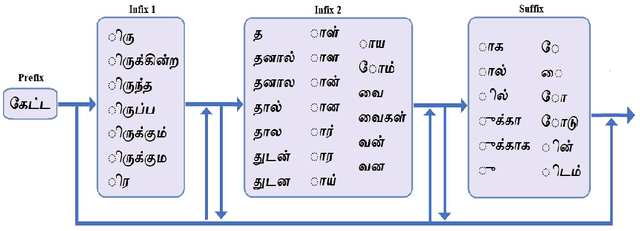
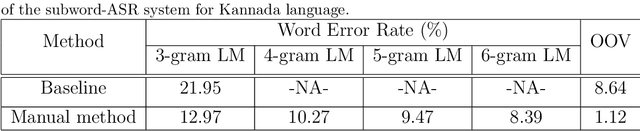
In this paper, we present specially designed automatic speech recognition (ASR) systems for the highly agglutinative and inflective languages of Tamil and Kannada that can recognize unlimited vocabulary of words. We use subwords as the basic lexical units for recognition and construct subword grammar weighted finite state transducer (SG-WFST) graphs for word segmentation that captures most of the complex word formation rules of the languages. We have identified the following category of words (i) verbs, (ii) nouns, (ii) pronouns, and (iv) numbers. The prefix, infix and suffix lists of subwords are created for each of these categories and are used to design the SG-WFST graphs. We also present a heuristic segmentation algorithm that can even segment exceptional words that do not follow the rules encapsulated in the SG-WFST graph. Most of the data-driven subword dictionary creation algorithms are computation driven, and hence do not guarantee morpheme-like units and so we have used the linguistic knowledge of the languages and manually created the subword dictionaries and the graphs. Finally, we train a deep neural network acoustic model and combine it with the pronunciation lexicon of the subword dictionary and the SG-WFST graph to build the subword-ASR systems. Since the subword-ASR produces subword sequences as output for a given test speech, we post-process its output to get the final word sequence, so that the actual number of words that can be recognized is much higher. Upon experimenting the subword-ASR system with the IISc-MILE Tamil and Kannada ASR corpora, we observe an absolute word error rate reduction of 12.39% and 13.56% over the baseline word-based ASR systems for Tamil and Kannada, respectively.