 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Cognitive Coding of Speech
Oct 08, 2021
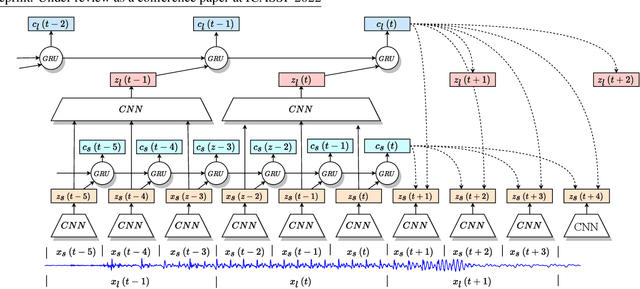
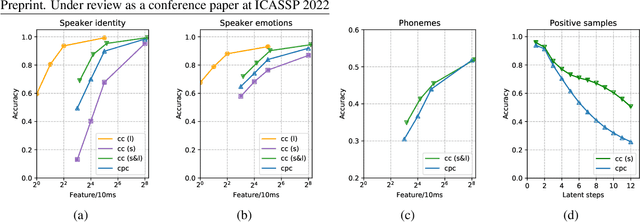
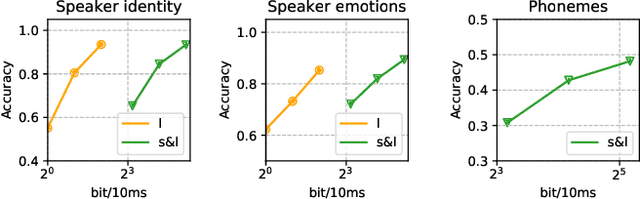
We propose an approach for cognitive coding of speech by unsupervised extraction of contextual representations in two hierarchical levels of abstraction. Speech attributes such as phoneme identity that last one hundred milliseconds or less are captured in the lower level of abstraction, while speech attributes such as speaker identity and emotion that persist up to one second are captured in the higher level of abstraction. This decomposition is achieved by a two-stage neural network, with a lower and an upper stage operating at different time scales. Both stages are trained to predict the content of the signal in their respective latent spaces. A top-down pathway between stages further improves the predictive capability of the network. With an application in speech compression in mind, we investigate the effect of dimensionality reduction and low bitrate quantization on the extracted representations. The performance measured on the LibriSpeech and EmoV-DB datasets reaches, and for some speech attributes even exceeds, that of state-of-the-art approaches.
Language Agnostic Data-Driven Inverse Text Normalization
Jan 24, 2023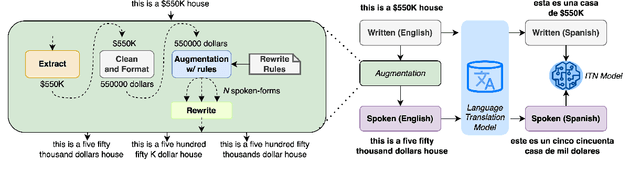
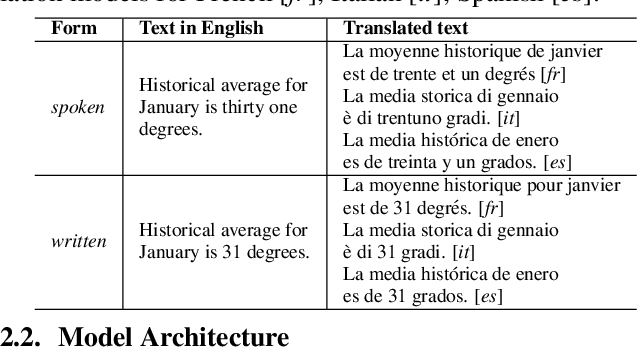
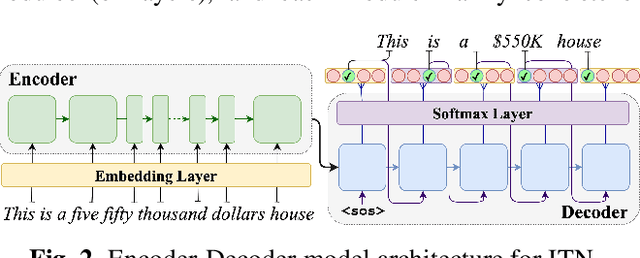
With the emergence of automatic speech recognition (ASR) models, converting the spoken form text (from ASR) to the written form is in urgent need. This inverse text normalization (ITN) problem attracts the attention of researchers from various fields. Recently, several works show that data-driven ITN methods can output high-quality written form text. Due to the scarcity of labeled spoken-written datasets, the studies on non-English data-driven ITN are quite limited. In this work, we propose a language-agnostic data-driven ITN framework to fill this gap. Specifically, we leverage the data augmentation in conjunction with neural machine translated data for low resource languages. Moreover, we design an evaluation method for language agnostic ITN model when only English data is available. Our empirical evaluation shows this language agnostic modeling approach is effective for low resource languages while preserving the performance for high resource languages.
Fearless Steps Challenge Phase-1 Evaluation Plan
Nov 03, 2022
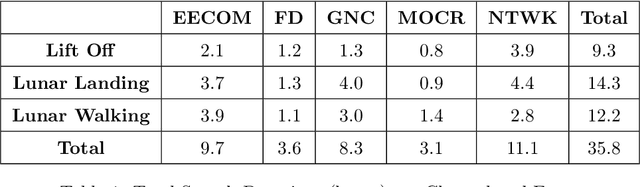
The Fearless Steps Challenge 2019 Phase-1 (FSC-P1) is the inaugural Challenge of the Fearless Steps Initiative hosted by the Center for Robust Speech Systems (CRSS) at the University of Texas at Dallas. The goal of this Challenge is to evaluate the performance of state-of-the-art speech and language systems for large task-oriented teams with naturalistic audio in challenging environments. Researchers may select to participate in any single or multiple of these challenge tasks. Researchers may also choose to employ the FEARLESS STEPS corpus for other related speech applications. All participants are encouraged to submit their solutions and results for consideration in the ISCA INTERSPEECH-2019 special session.
Hearing voices at the National Library -- a speech corpus and acoustic model for the Swedish language
May 06, 2022
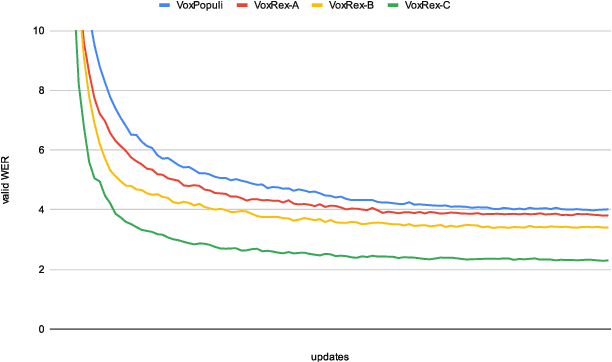
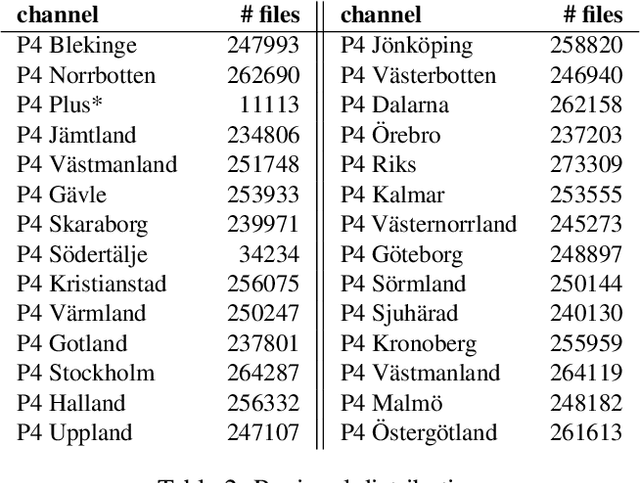
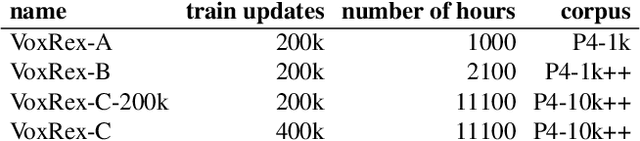
This paper explains our work in developing new acoustic models for automated speech recognition (ASR) at KBLab, the infrastructure for data-driven research at the National Library of Sweden (KB). We evaluate different approaches for a viable speech-to-text pipeline for audiovisual resources in Swedish, using the wav2vec 2.0 architecture in combination with speech corpuses created from KB's collections. These approaches include pretraining an acoustic model for Swedish from the ground up, and fine-tuning existing monolingual and multilingual models. The collections-based corpuses we use have been sampled from millions of hours of speech, with a conscious attempt to balance regional dialects to produce a more representative, and thus more democratic, model. The acoustic model this enabled, "VoxRex", outperforms existing models for Swedish ASR. We also evaluate combining this model with various pretrained language models, which further enhanced performance. We conclude by highlighting the potential of such technology for cultural heritage institutions with vast collections of previously unlabelled audiovisual data. Our models are released for further exploration and research here: https://huggingface.co/KBLab.
A Novel Speech Intelligibility Enhancement Model based on CanonicalCorrelation and Deep Learning
Feb 11, 2022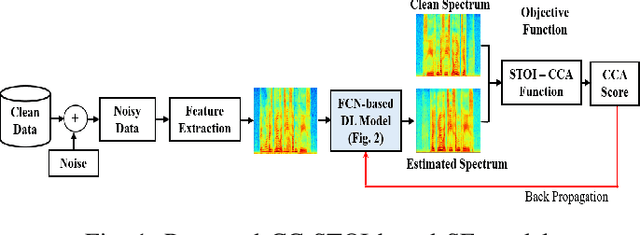
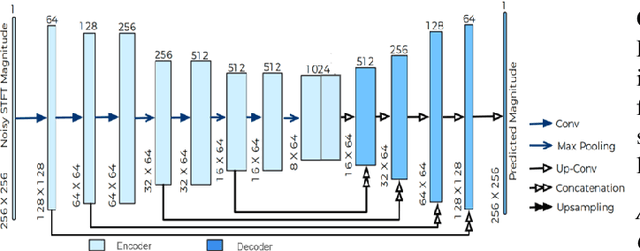
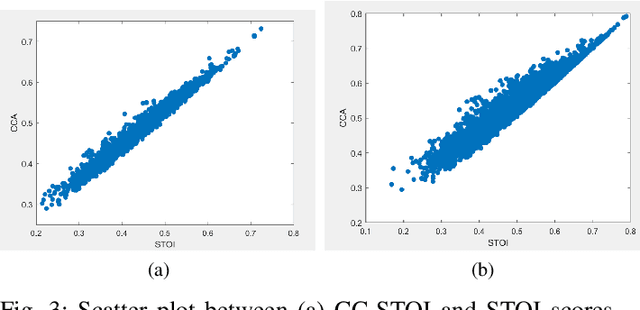
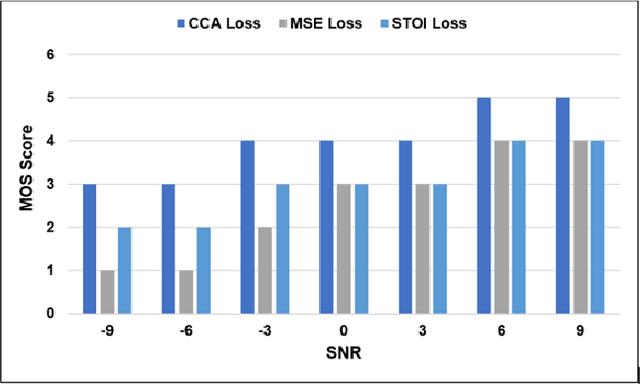
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are often trained to minimise the feature distance between noise-free speech and enhanced speech signals. Despite improving the speech quality, such approaches do not deliver required levels of speech intelligibility in everyday noisy environments . Intelligibility-oriented (I-O) loss functions have recently been developed to train DL approaches for robust speech enhancement. Here, we formulate, for the first time, a novel canonical correlation based I-O loss function to more effectively train DL algorithms. Specifically, we present a canonical-correlation based short-time objective intelligibility (CC-STOI) cost function to train a fully convolutional neural network (FCN) model. We carry out comparative simulation experiments to show that our CC-STOI based speech enhancement framework outperforms state-of-the-art DL models trained with conventional distance-based and STOI-based loss functions, using objective and subjective evaluation measures for case of both unseen speakers and noises. Ongoing future work is evaluating the proposed approach for design of robust hearing-assistive technology.
Bidirectional Representations for Low Resource Spoken Language Understanding
Nov 24, 2022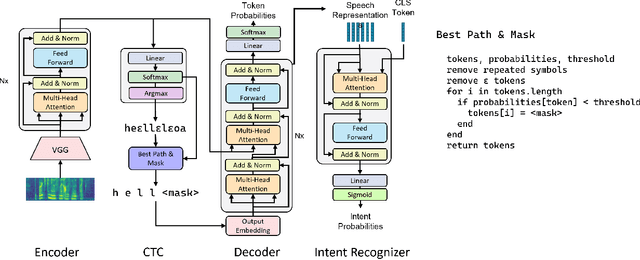


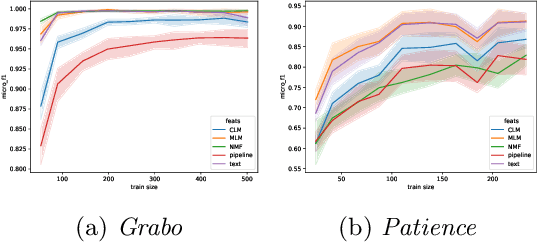
Most spoken language understanding systems use a pipeline approach composed of an automatic speech recognition interface and a natural language understanding module. This approach forces hard decisions when converting continuous inputs into discrete language symbols. Instead, we propose a representation model to encode speech in rich bidirectional encodings that can be used for downstream tasks such as intent prediction. The approach uses a masked language modelling objective to learn the representations, and thus benefits from both the left and right contexts. We show that the performance of the resulting encodings before fine-tuning is better than comparable models on multiple datasets, and that fine-tuning the top layers of the representation model improves the current state of the art on the Fluent Speech Command dataset, also in a low-data regime, when a limited amount of labelled data is used for training. Furthermore, we propose class attention as a spoken language understanding module, efficient both in terms of speed and number of parameters. Class attention can be used to visually explain the predictions of our model, which goes a long way in understanding how the model makes predictions. We perform experiments in English and in Dutch.
Differentiable Duration Modeling for End-to-End Text-to-Speech
Mar 21, 2022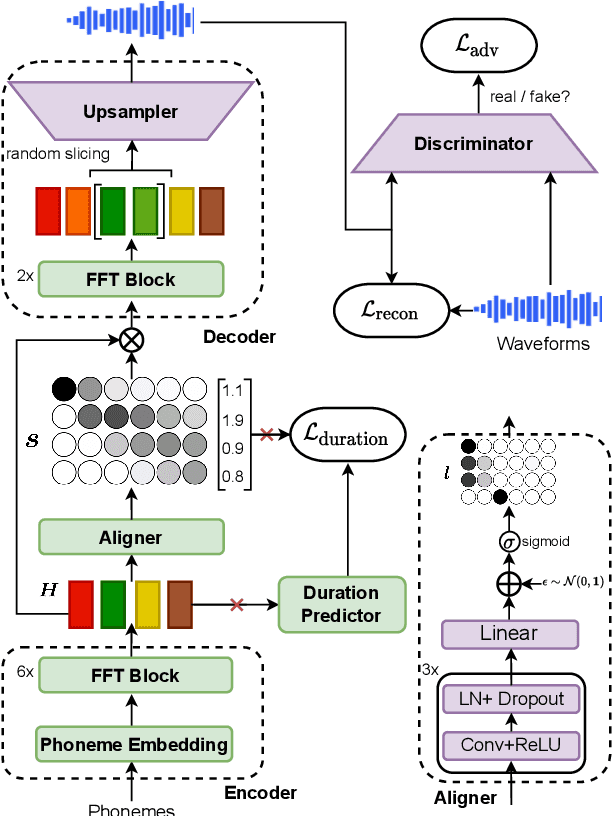
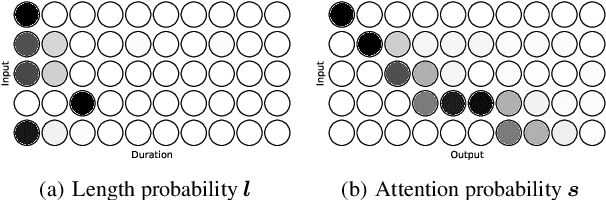
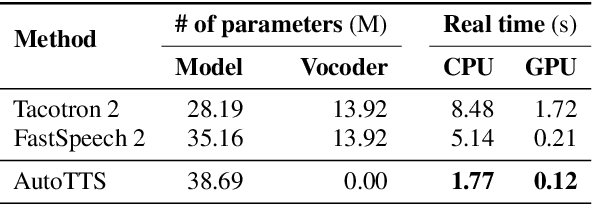
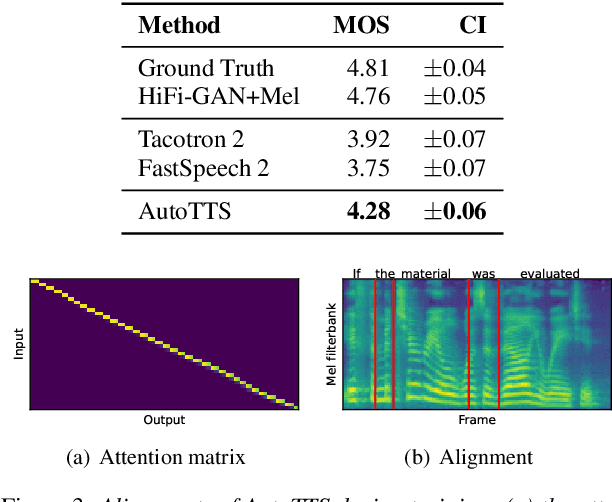
Parallel text-to-speech (TTS) models have recently enabled fast and highly-natural speech synthesis. However, such models typically require external alignment models, which are not necessarily optimized for the decoder as they are not jointly trained. In this paper, we propose a differentiable duration method for learning monotonic alignments between input and output sequences. Our method is based on a soft-duration mechanism that optimizes a stochastic process in expectation. Using this differentiable duration method, a direct text to waveform TTS model is introduced to produce raw audio as output instead of performing neural vocoding. Our model learns to perform high-fidelity speech synthesis through a combination of adversarial training and matching the total ground-truth duration. Experimental results show that our model obtains competitive results while enjoying a much simpler training pipeline. Audio samples are available online.
Discourse and conversation impairments in patients with dementia
Dec 03, 2022Neurodegeneration characterizes individuals with different dementia subtypes (e.g., individuals with Alzheimer's Disease, Primary Progressive Aphasia, and Parkinson's Disease), leading to progressive decline in cognitive, linguistic, and social functioning. Speech and language impairments are early symptoms in individuals with focal forms of neurodegenerative conditions, coupled with deficits in cognitive, social, and behavioral domains. This paper reviews the findings on language and communication deficits and identifies the effects of dementia on the production and perception of discourse. It discusses findings concerning (i) language function, cognitive representation, and impairment, (ii) communicative competence, emotions, empathy, and theory-of-mind, and (iii) speech-in-interaction. It argues that clinical discourse analysis can provide a comprehensive assessment of language and communication skills in individuals, which complements the existing neurolinguistic evaluation for (differential) diagnosis, prognosis, and treatment efficacy evaluation.
Sotto Voce: Federated Speech Recognition with Differential Privacy Guarantees
Jul 16, 2022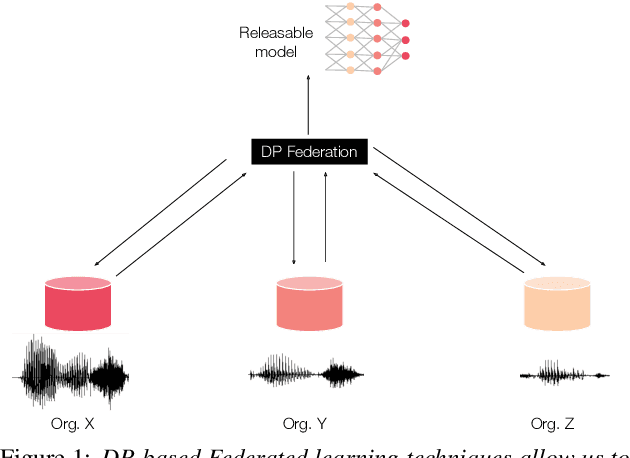
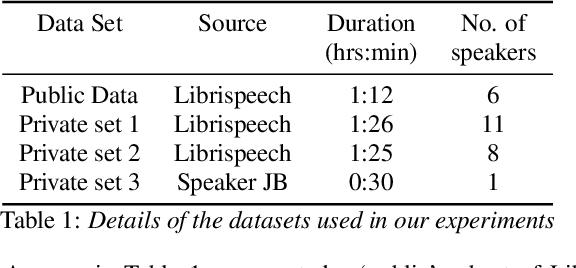
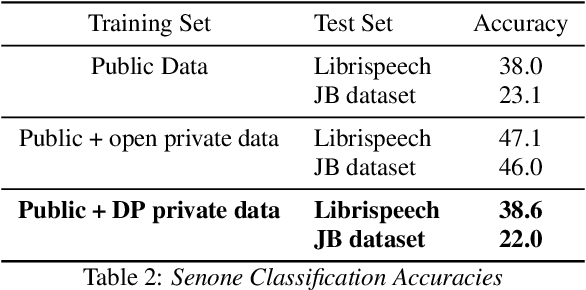
Speech data is expensive to collect, and incredibly sensitive to its sources. It is often the case that organizations independently collect small datasets for their own use, but often these are not performant for the demands of machine learning. Organizations could pool these datasets together and jointly build a strong ASR system; sharing data in the clear, however, comes with tremendous risk, in terms of intellectual property loss as well as loss of privacy of the individuals who exist in the dataset. In this paper, we offer a potential solution for learning an ML model across multiple organizations where we can provide mathematical guarantees limiting privacy loss. We use a Federated Learning approach built on a strong foundation of Differential Privacy techniques. We apply these to a senone classification prototype and demonstrate that the model improves with the addition of private data while still respecting privacy.
Censer: Curriculum Semi-supervised Learning for Speech Recognition Based on Self-supervised Pre-training
Jun 27, 2022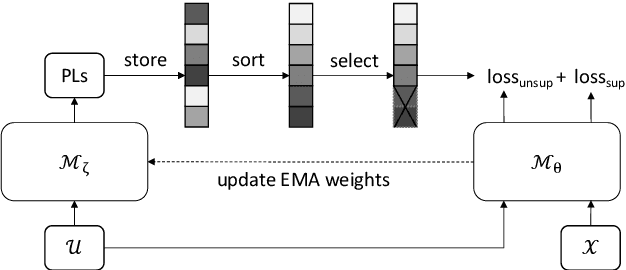

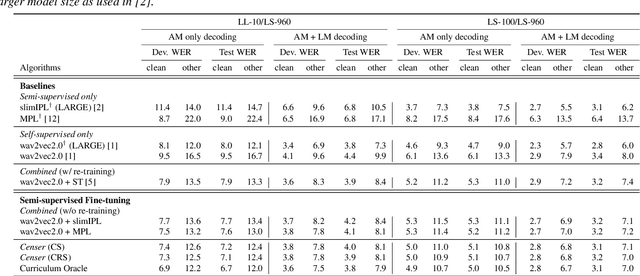
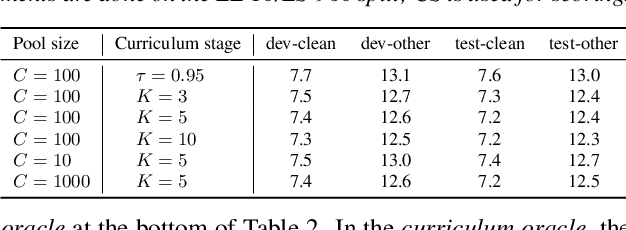
Recent studies have shown that the benefits provided by self-supervised pre-training and self-training (pseudo-labeling) are complementary. Semi-supervised fine-tuning strategies under the pre-training framework, however, remain insufficiently studied. Besides, modern semi-supervised speech recognition algorithms either treat unlabeled data indiscriminately or filter out noisy samples with a confidence threshold. The dissimilarities among different unlabeled data are often ignored. In this paper, we propose Censer, a semi-supervised speech recognition algorithm based on self-supervised pre-training to maximize the utilization of unlabeled data. The pre-training stage of Censer adopts wav2vec2.0 and the fine-tuning stage employs an improved semi-supervised learning algorithm from slimIPL, which leverages unlabeled data progressively according to their pseudo labels' qualities. We also incorporate a temporal pseudo label pool and an exponential moving average to control the pseudo labels' update frequency and to avoid model divergence. Experimental results on Libri-Light and LibriSpeech datasets manifest our proposed method achieves better performance compared to existing approaches while being more unified.