 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Generative Data Augmentation Guided by Triplet Loss for Speech Emotion Recognition
Aug 09, 2022
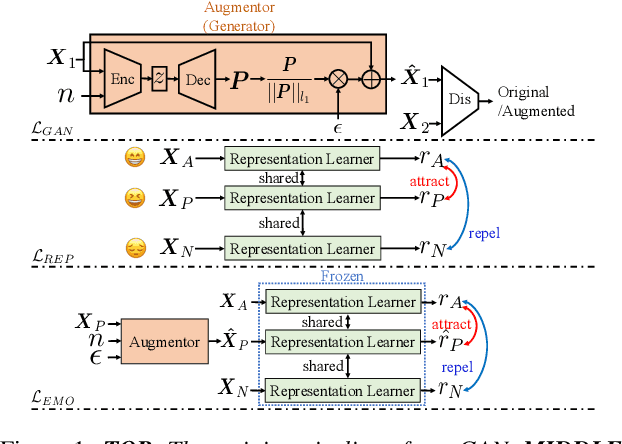
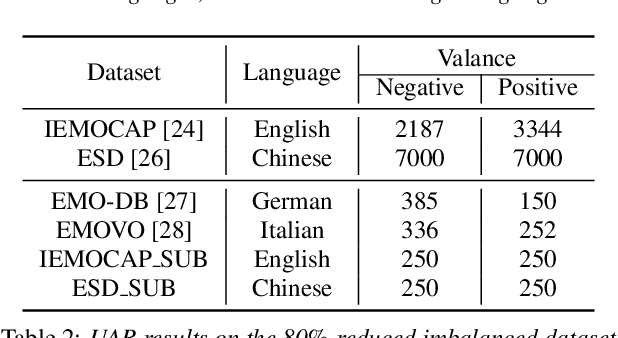
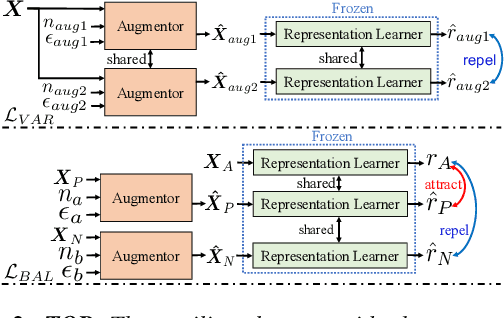
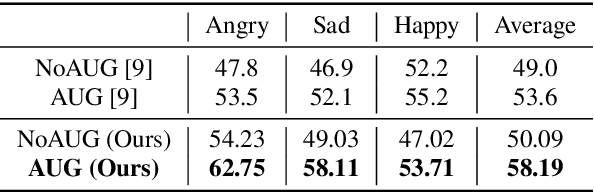
Speech Emotion Recognition (SER) is crucial for human-computer interaction but still remains a challenging problem because of two major obstacles: data scarcity and imbalance. Many datasets for SER are substantially imbalanced, where data utterances of one class (most often Neutral) are much more frequent than those of other classes. Furthermore, only a few data resources are available for many existing spoken languages. To address these problems, we exploit a GAN-based augmentation model guided by a triplet network, to improve SER performance given imbalanced and insufficient training data. We conduct experiments and demonstrate: 1) With a highly imbalanced dataset, our augmentation strategy significantly improves the SER performance (+8% recall score compared with the baseline). 2) Moreover, in a cross-lingual benchmark, where we train a model with enough source language utterances but very few target language utterances (around 50 in our experiments), our augmentation strategy brings benefits for the SER performance of all three target languages.
Improving Noise Robustness of Contrastive Speech Representation Learning with Speech Reconstruction
Oct 28, 2021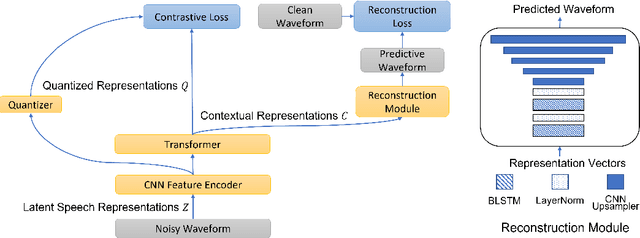
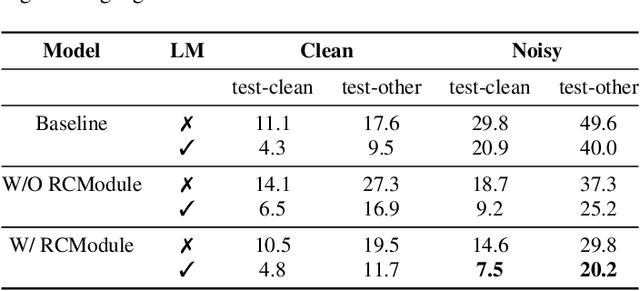
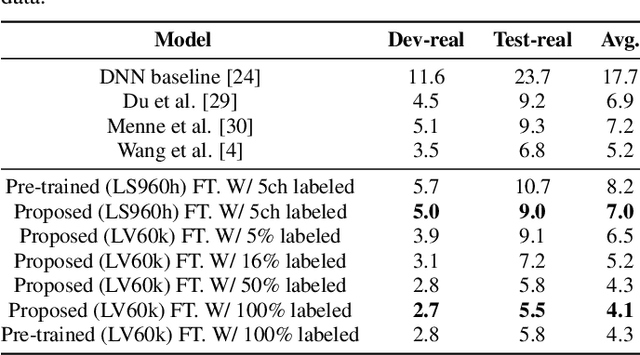
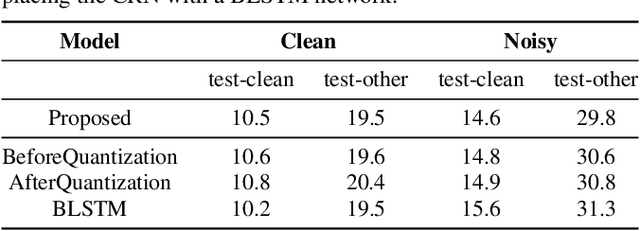
Noise robustness is essential for deploying automatic speech recognition (ASR) systems in real-world environments. One way to reduce the effect of noise interference is to employ a preprocessing module that conducts speech enhancement, and then feed the enhanced speech to an ASR backend. In this work, instead of suppressing background noise with a conventional cascaded pipeline, we employ a noise-robust representation learned by a refined self-supervised framework for noisy speech recognition. We propose to combine a reconstruction module with contrastive learning and perform multi-task continual pre-training on noisy data. The reconstruction module is used for auxiliary learning to improve the noise robustness of the learned representation and thus is not required during inference. Experiments demonstrate the effectiveness of our proposed method. Our model substantially reduces the word error rate (WER) for the synthesized noisy LibriSpeech test sets, and yields around 4.1/7.5% WER reduction on noisy clean/other test sets compared to data augmentation. For the real-world noisy speech from the CHiME-4 challenge (1-channel track), we have obtained the state of the art ASR performance without any denoising front-end. Moreover, we achieve comparable performance to the best supervised approach reported with only 16% of labeled data.
ConferencingSpeech 2022 Challenge: Non-intrusive Objective Speech Quality Assessment (NISQA) Challenge for Online Conferencing Applications
Apr 01, 2022
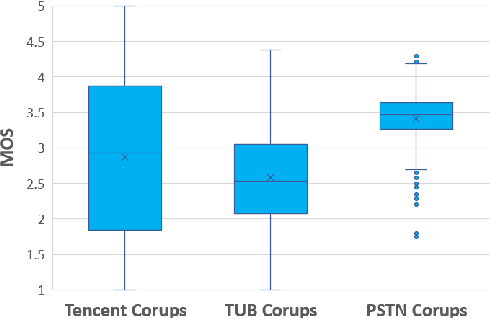

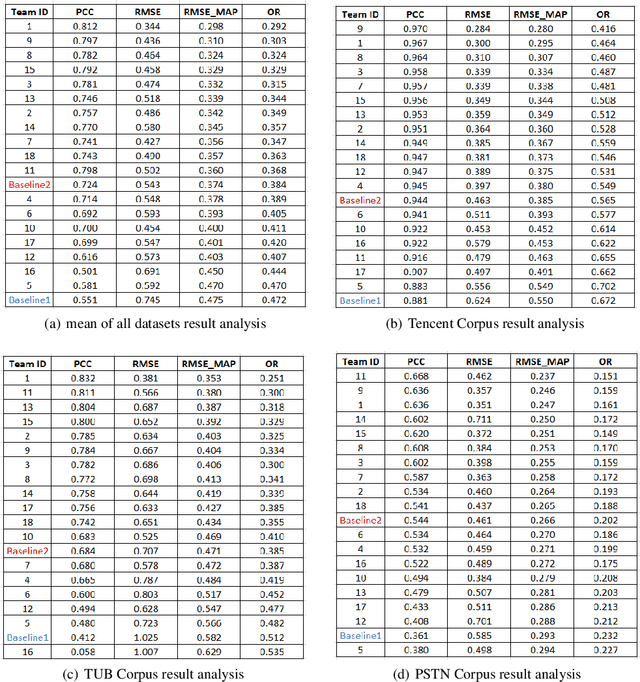
With the advances in speech communication systems such as online conferencing applications, we can seamlessly work with people regardless of where they are. However, during online meetings, speech quality can be significantly affected by background noise, reverberation, packet loss, network jitter, etc. Because of its nature, speech quality is traditionally assessed in subjective tests in laboratories and lately also in crowdsourcing following the international standards from ITU-T Rec. P.800 series. However, those approaches are costly and cannot be applied to customer data. Therefore, an effective objective assessment approach is needed to evaluate or monitor the speech quality of the ongoing conversation. The ConferencingSpeech 2022 challenge targets the non-intrusive deep neural network models for the speech quality assessment task. We open-sourced a training corpus with more than 86K speech clips in different languages, with a wide range of synthesized and live degradations and their corresponding subjective quality scores through crowdsourcing. 18 teams submitted their models for evaluation in this challenge. The blind test sets included about 4300 clips from wide ranges of degradations. This paper describes the challenge, the datasets, and the evaluation methods and reports the final results.
STFT-Domain Neural Speech Enhancement with Very Low Algorithmic Latency
Apr 21, 2022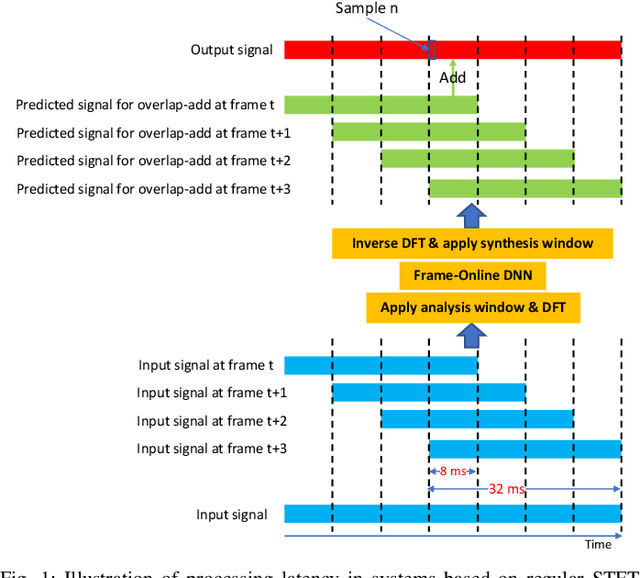
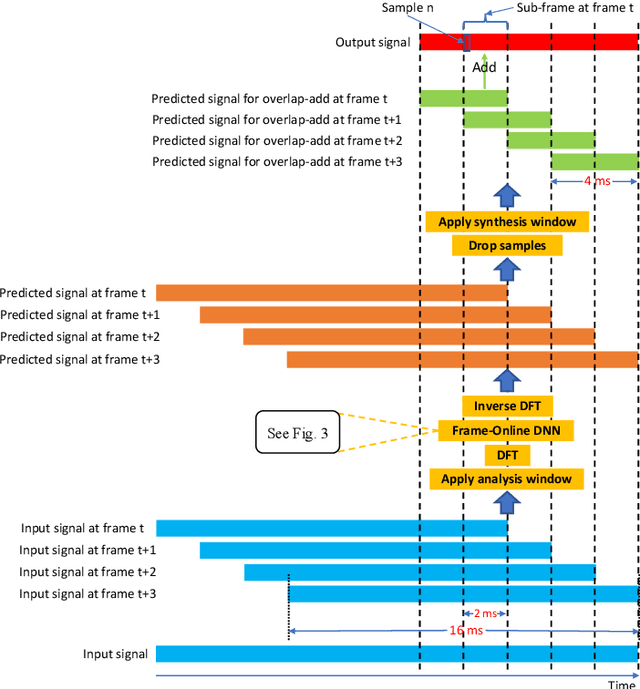
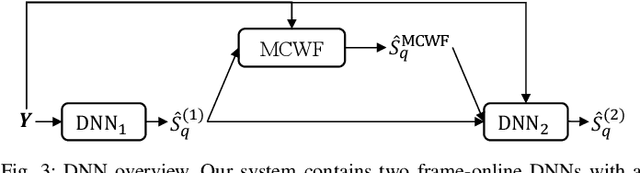
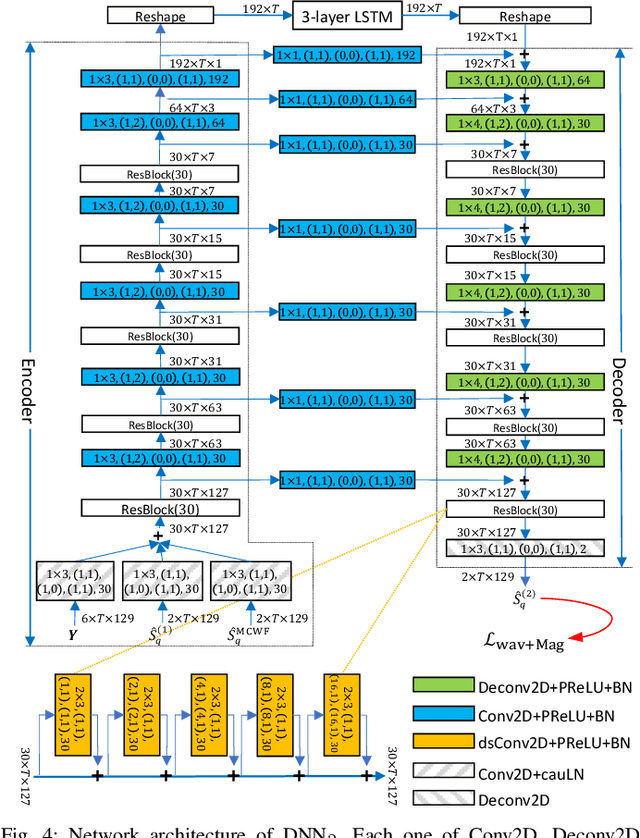
Deep learning based speech enhancement in the short-term Fourier transform (STFT) domain typically uses a large window length such as 32 ms. A larger window contains more samples and the frequency resolution can be higher for potentially better enhancement. This however incurs an algorithmic latency of 32 ms in an online setup, because the overlap-add algorithm used in the inverse STFT (iSTFT) is also performed based on the same 32 ms window size. To reduce this inherent latency, we adapt a conventional dual window size approach, where a regular input window size is used for STFT but a shorter output window is used for the overlap-add in the iSTFT, for STFT-domain deep learning based frame-online speech enhancement. Based on this STFT and iSTFT configuration, we employ single- or multi-microphone complex spectral mapping for frame-online enhancement, where a deep neural network (DNN) is trained to predict the real and imaginary (RI) components of target speech from the mixture RI components. In addition, we use the RI components predicted by the DNN to conduct frame-online beamforming, the results of which are then used as extra features for a second DNN to perform frame-online post-filtering. The frequency-domain beamforming in between the two DNNs can be easily integrated with complex spectral mapping and is designed to not incur any algorithmic latency. Additionally, we propose a future-frame prediction technique to further reduce the algorithmic latency. Evaluation results on a noisy-reverberant speech enhancement task demonstrate the effectiveness of the proposed algorithms. Compared with Conv-TasNet, our STFT-domain system can achieve better enhancement performance for a comparable amount of computation, or comparable performance with less computation, maintaining strong performance at an algorithmic latency as low as 2 ms.
On the Locality of Attention in Direct Speech Translation
Apr 19, 2022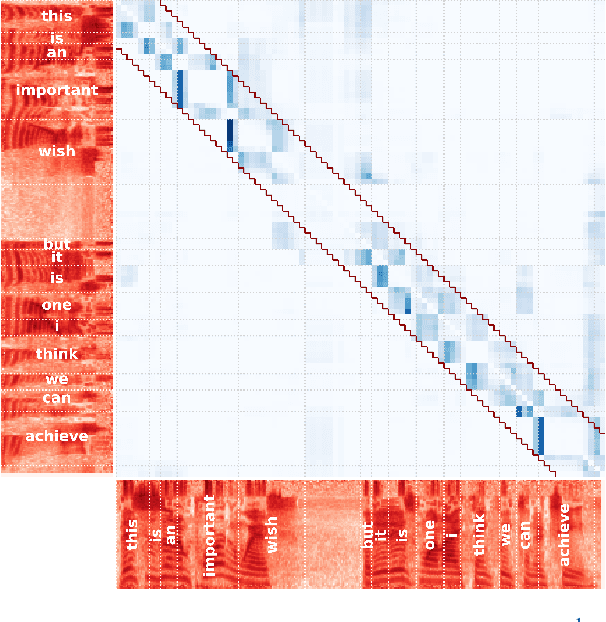
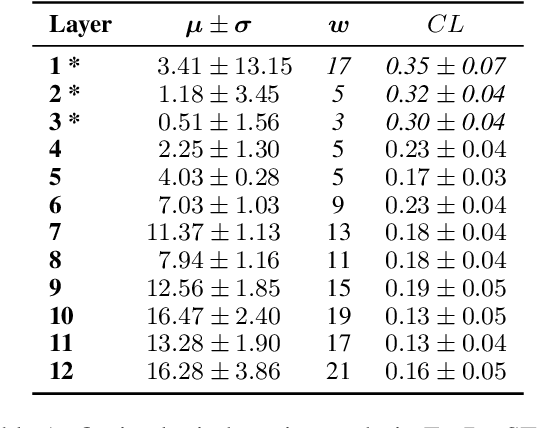
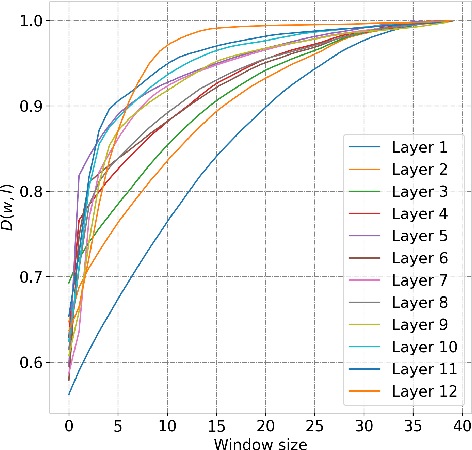
Transformers have achieved state-of-the-art results across multiple NLP tasks. However, the self-attention mechanism complexity scales quadratically with the sequence length, creating an obstacle for tasks involving long sequences, like in the speech domain. In this paper, we discuss the usefulness of self-attention for Direct Speech Translation. First, we analyze the layer-wise token contributions in the self-attention of the encoder, unveiling local diagonal patterns. To prove that some attention weights are avoidable, we propose to substitute the standard self-attention with a local efficient one, setting the amount of context used based on the results of the analysis. With this approach, our model matches the baseline performance, and improves the efficiency by skipping the computation of those weights that standard attention discards.
The PCG-AIID System for L3DAS22 Challenge: MIMO and MISO convolutional recurrent Network for Multi Channel Speech Enhancement and Speech Recognition
Feb 21, 2022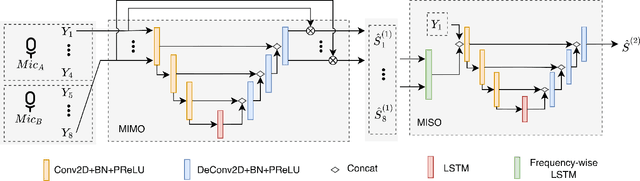
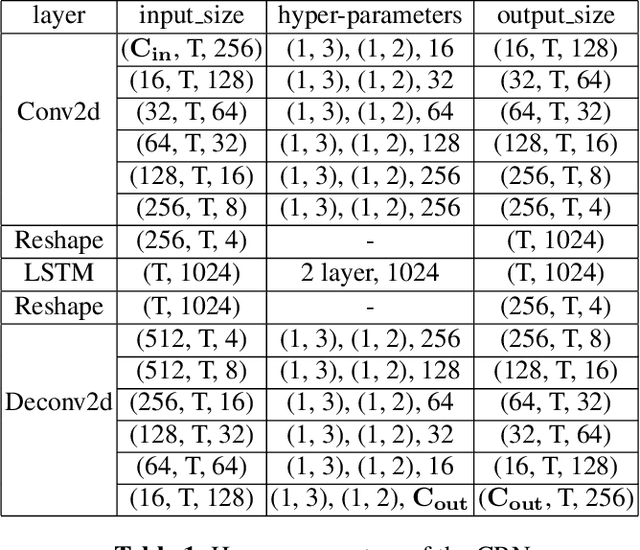
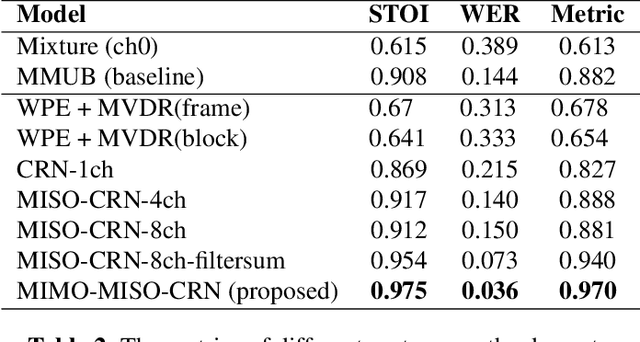
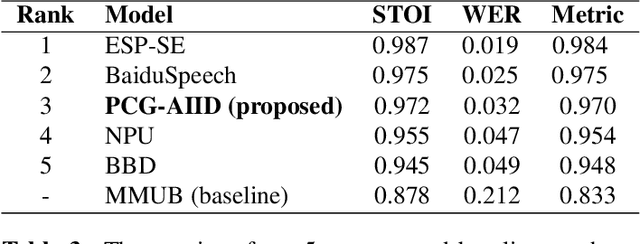
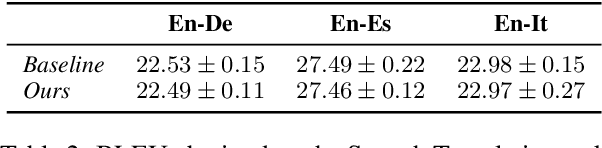
This paper described the PCG-AIID system for L3DAS22 challenge in Task 1: 3D speech enhancement in office reverberant environment. We proposed a two-stage framework to address multi-channel speech denoising and dereverberation. In the first stage, a multiple input and multiple output (MIMO) network is applied to remove background noise while maintaining the spatial characteristics of multi-channel signals. In the second stage, a multiple input and single output (MISO) network is applied to enhance the speech from desired direction and post-filtering. As a result, our system ranked 3rd place in ICASSP2022 L3DAS22 challenge and significantly outperforms the baseline system, while achieving 3.2% WER and 0.972 STOI on the blind test-set.
SuperVoice: Text-Independent Speaker Verification Using Ultrasound Energy in Human Speech
May 28, 2022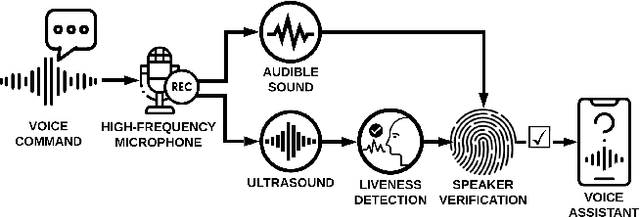
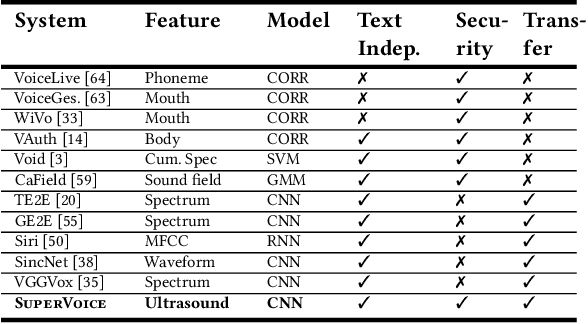
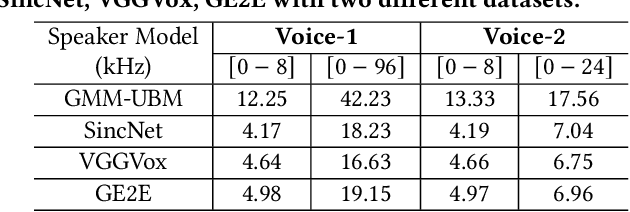
Voice-activated systems are integrated into a variety of desktop, mobile, and Internet-of-Things (IoT) devices. However, voice spoofing attacks, such as impersonation and replay attacks, in which malicious attackers synthesize the voice of a victim or simply replay it, have brought growing security concerns. Existing speaker verification techniques distinguish individual speakers via the spectrographic features extracted from an audible frequency range of voice commands. However, they often have high error rates and/or long delays. In this paper, we explore a new direction of human voice research by scrutinizing the unique characteristics of human speech at the ultrasound frequency band. Our research indicates that the high-frequency ultrasound components (e.g. speech fricatives) from 20 to 48 kHz can significantly enhance the security and accuracy of speaker verification. We propose a speaker verification system, SUPERVOICE that uses a two-stream DNN architecture with a feature fusion mechanism to generate distinctive speaker models. To test the system, we create a speech dataset with 12 hours of audio (8,950 voice samples) from 127 participants. In addition, we create a second spoofed voice dataset to evaluate its security. In order to balance between controlled recordings and real-world applications, the audio recordings are collected from two quiet rooms by 8 different recording devices, including 7 smartphones and an ultrasound microphone. Our evaluation shows that SUPERVOICE achieves 0.58% equal error rate in the speaker verification task, it only takes 120 ms for testing an incoming utterance, outperforming all existing speaker verification systems. Moreover, within 91 ms processing time, SUPERVOICE achieves 0% equal error rate in detecting replay attacks launched by 5 different loudspeakers.
Towards Representative Subset Selection for Self-Supervised Speech Recognition
Mar 18, 2022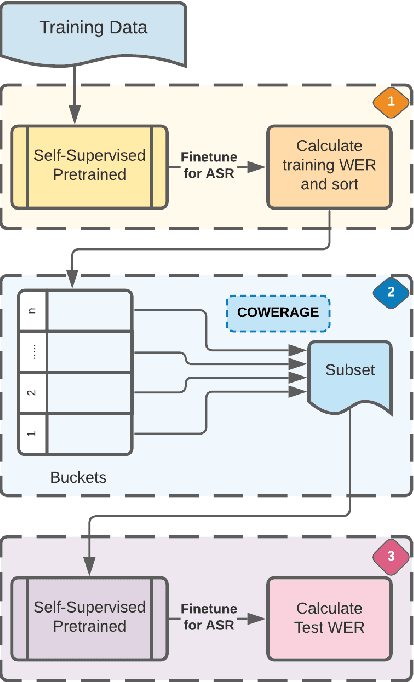
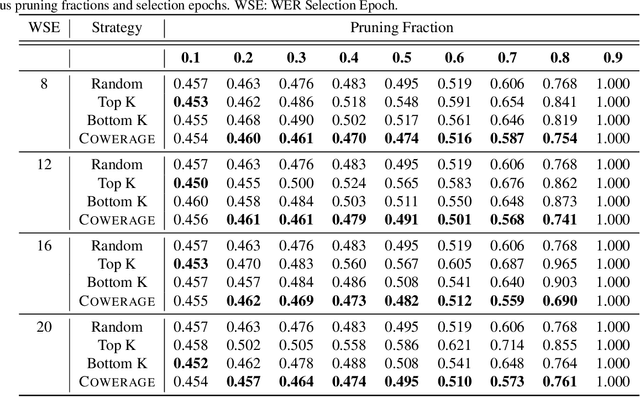
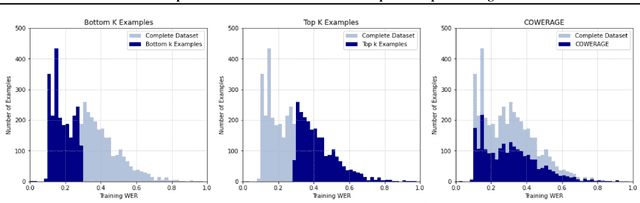

Self-supervised speech recognition models require considerable labeled training data for learning high-fidelity representations for Automatic Speech Recognition (ASR), which hinders their application to low-resource languages. We consider the task of identifying an optimal subset of training data to fine-tune self-supervised speech models for ASR. We make a surprising observation that active learning strategies for sampling harder-to-learn examples do not perform better than random subset selection for fine-tuning self-supervised ASR. We then present the COWERAGE algorithm for better subset selection in self-supervised ASR which is based on our finding that ensuring the coverage of examples based on training WER in the early training epochs leads to better generalization performance. Extensive experiments on the wav2vec 2.0 model and TIMIT dataset show the effectiveness of COWERAGE, with up to 27% absolute WER improvement over active learning methods. We also report the connection between training WER and the phonemic cover and demonstrate that our algorithm ensures inclusion of phonemically diverse examples.
Do self-supervised speech models develop human-like perception biases?
May 31, 2022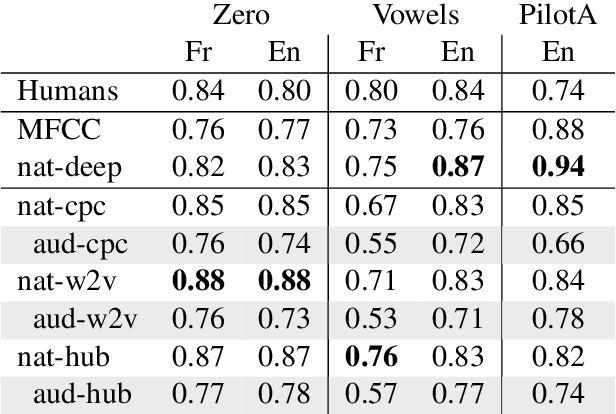
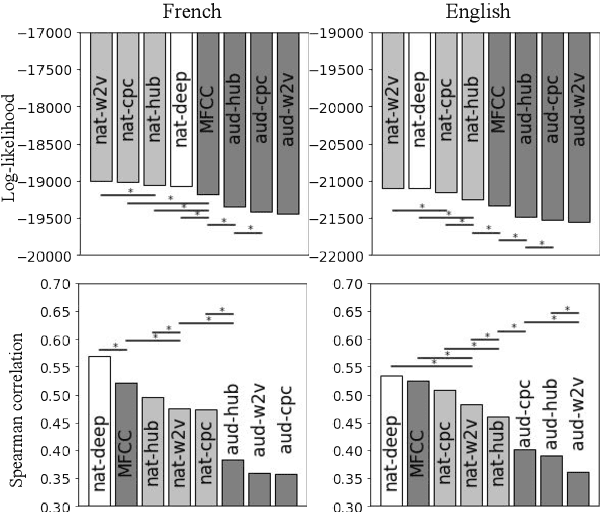
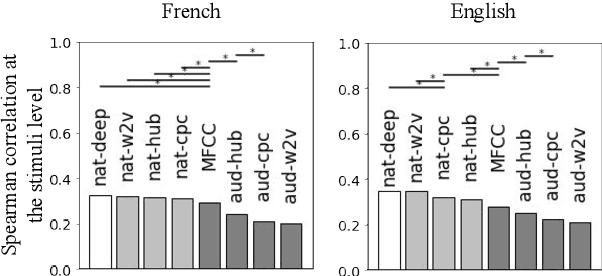
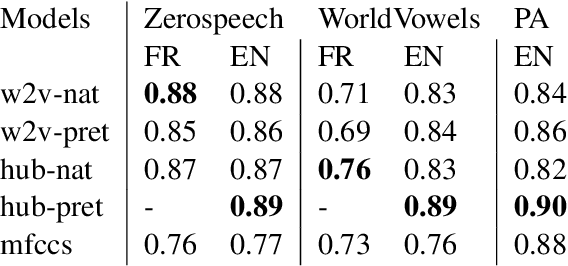
Self-supervised models for speech processing form representational spaces without using any external labels. Increasingly, they appear to be a feasible way of at least partially eliminating costly manual annotations, a problem of particular concern for low-resource languages. But what kind of representational spaces do these models construct? Human perception specializes to the sounds of listeners' native languages. Does the same thing happen in self-supervised models? We examine the representational spaces of three kinds of state-of-the-art self-supervised models: wav2vec 2.0, HuBERT and contrastive predictive coding (CPC), and compare them with the perceptual spaces of French-speaking and English-speaking human listeners, both globally and taking account of the behavioural differences between the two language groups. We show that the CPC model shows a small native language effect, but that wav2vec 2.0 and HuBERT seem to develop a universal speech perception space which is not language specific. A comparison against the predictions of supervised phone recognisers suggests that all three self-supervised models capture relatively fine-grained perceptual phenomena, while supervised models are better at capturing coarser, phone-level, effects of listeners' native language, on perception.
Cognitive Coding of Speech
Oct 08, 2021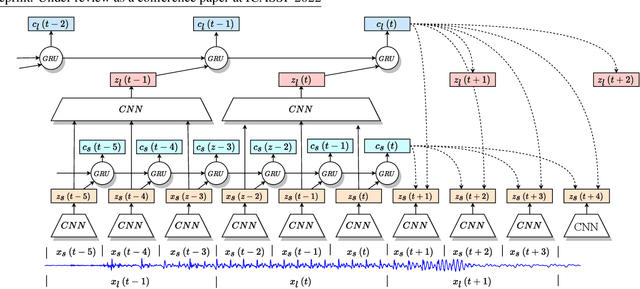
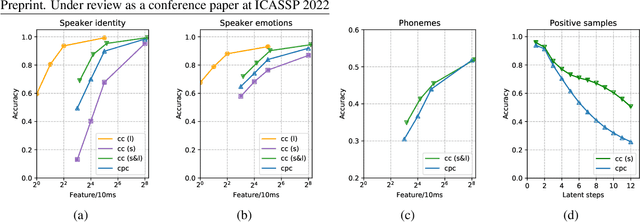
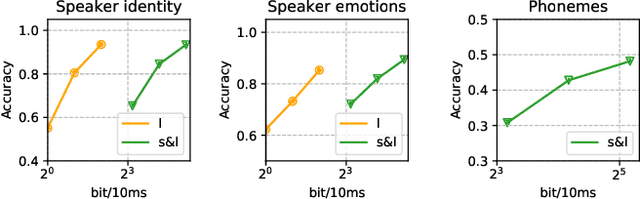
We propose an approach for cognitive coding of speech by unsupervised extraction of contextual representations in two hierarchical levels of abstraction. Speech attributes such as phoneme identity that last one hundred milliseconds or less are captured in the lower level of abstraction, while speech attributes such as speaker identity and emotion that persist up to one second are captured in the higher level of abstraction. This decomposition is achieved by a two-stage neural network, with a lower and an upper stage operating at different time scales. Both stages are trained to predict the content of the signal in their respective latent spaces. A top-down pathway between stages further improves the predictive capability of the network. With an application in speech compression in mind, we investigate the effect of dimensionality reduction and low bitrate quantization on the extracted representations. The performance measured on the LibriSpeech and EmoV-DB datasets reaches, and for some speech attributes even exceeds, that of state-of-the-art approaches.