 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Language Agnostic Data-Driven Inverse Text Normalization
Jan 24, 2023
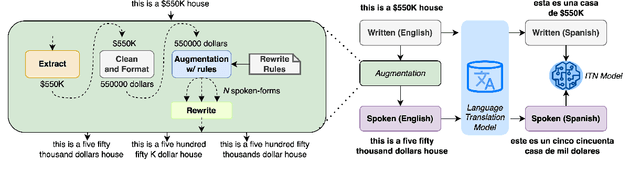
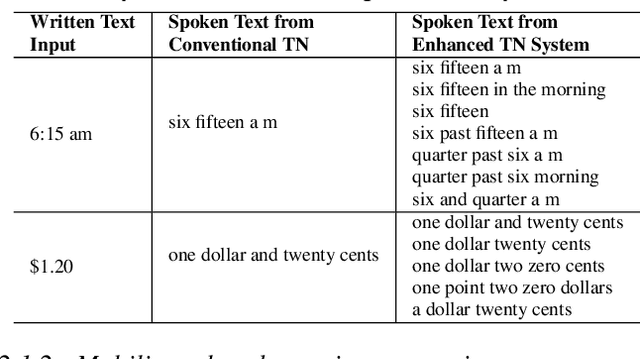
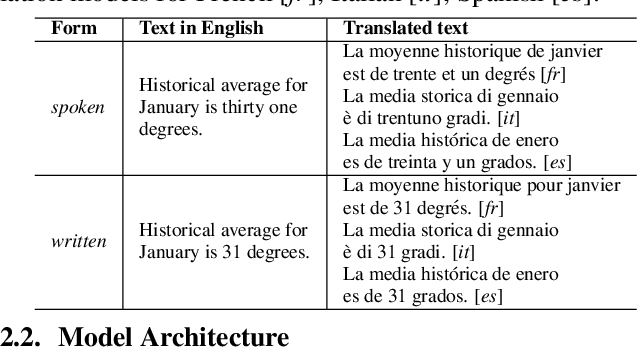
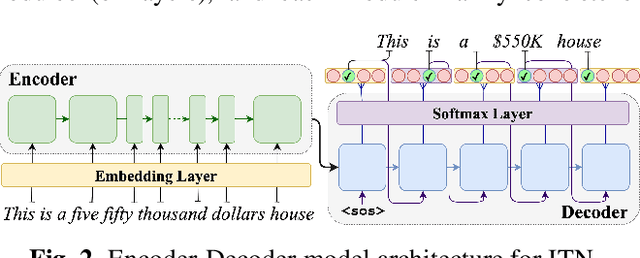
With the emergence of automatic speech recognition (ASR) models, converting the spoken form text (from ASR) to the written form is in urgent need. This inverse text normalization (ITN) problem attracts the attention of researchers from various fields. Recently, several works show that data-driven ITN methods can output high-quality written form text. Due to the scarcity of labeled spoken-written datasets, the studies on non-English data-driven ITN are quite limited. In this work, we propose a language-agnostic data-driven ITN framework to fill this gap. Specifically, we leverage the data augmentation in conjunction with neural machine translated data for low resource languages. Moreover, we design an evaluation method for language agnostic ITN model when only English data is available. Our empirical evaluation shows this language agnostic modeling approach is effective for low resource languages while preserving the performance for high resource languages.
Masked Part-Of-Speech Model: Does Modeling Long Context Help Unsupervised POS-tagging?
Jun 30, 2022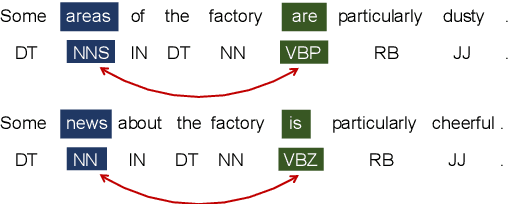

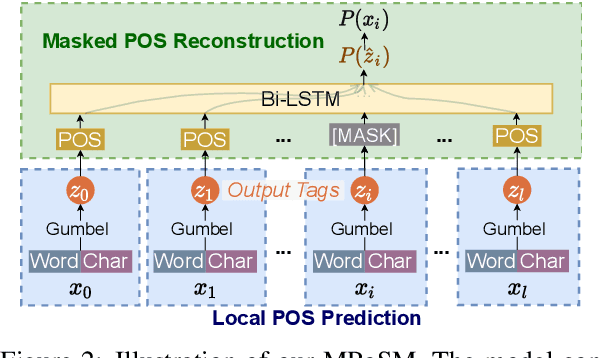
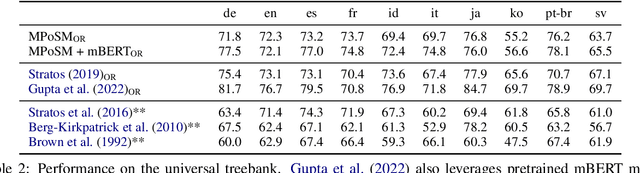
Previous Part-Of-Speech (POS) induction models usually assume certain independence assumptions (e.g., Markov, unidirectional, local dependency) that do not hold in real languages. For example, the subject-verb agreement can be both long-term and bidirectional. To facilitate flexible dependency modeling, we propose a Masked Part-of-Speech Model (MPoSM), inspired by the recent success of Masked Language Models (MLM). MPoSM can model arbitrary tag dependency and perform POS induction through the objective of masked POS reconstruction. We achieve competitive results on both the English Penn WSJ dataset as well as the universal treebank containing 10 diverse languages. Though modeling the long-term dependency should ideally help this task, our ablation study shows mixed trends in different languages. To better understand this phenomenon, we design a novel synthetic experiment that can specifically diagnose the model's ability to learn tag agreement. Surprisingly, we find that even strong baselines fail to solve this problem consistently in a very simplified setting: the agreement between adjacent words. Nonetheless, MPoSM achieves overall better performance. Lastly, we conduct a detailed error analysis to shed light on other remaining challenges. Our code is available at https://github.com/owenzx/MPoSM
Rapid dynamic speech imaging at 3 Tesla using combination of a custom vocal tract coil, variable density spirals and manifold regularization
Sep 06, 2022
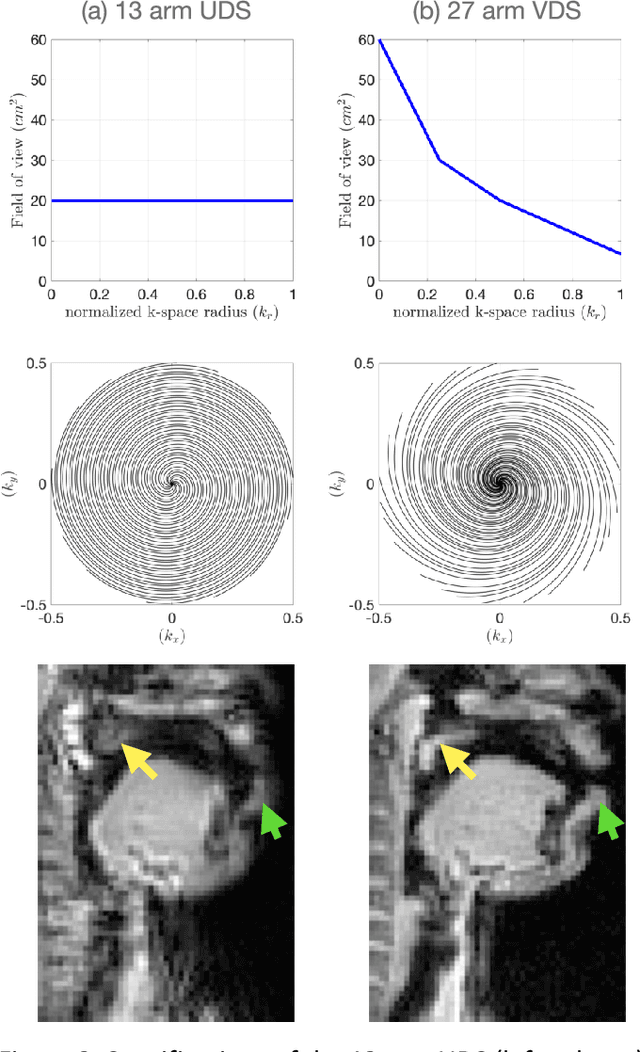
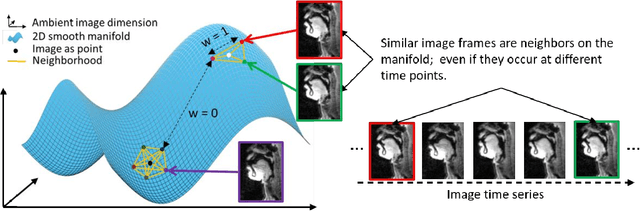
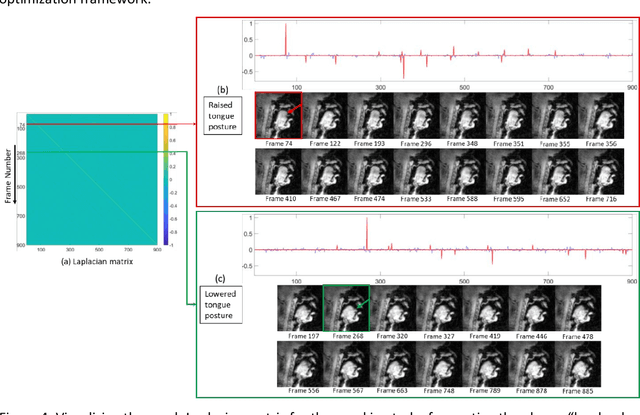
Purpose: To improve dynamic speech imaging at 3 Tesla. Methods: A novel scheme combining a 16-channel vocal tract coil, variable density spirals (VDS), and manifold regularization was developed. Short readout duration spirals (1.3 ms long) were used to minimize sensitivity to off-resonance. The manifold model leveraged similarities between frames sharing similar vocal tract postures without explicit motion binning. Reconstruction was posed as a SENSE-based non-local soft weighted temporal regularization scheme. The self-navigating capability of VDS was leveraged to learn the structure of the manifold. Our approach was compared against low-rank and finite difference reconstruction constraints on two volunteers performing repetitive and arbitrary speaking tasks. Blinded image quality evaluation in the categories of alias artifacts, spatial blurring, and temporal blurring were performed by three experts in voice research. Results: We achieved a spatial resolution of 2.4mm2/pixel and a temporal resolution of 17.4 ms/frame for single slice imaging, and 52.2 ms/frame for concurrent 3-slice imaging. Implicit motion binning of the manifold scheme for both repetitive and fluent speaking tasks was demonstrated. The manifold scheme provided superior fidelity in modeling articulatory motion compared to low rank and temporal finite difference schemes. This was reflected by higher image quality scores in spatial and temporal blurring categories. Our technique exhibited faint alias artifacts, but offered a reduced interquartile range of scores compared to other methods in alias artifact category. Conclusion: Synergistic combination of a custom vocal-tract coil, variable density spirals and manifold regularization enables robust dynamic speech imaging at 3 Tesla.
Declipping of Speech Signals Using Frequency Selective Extrapolation
Apr 07, 2022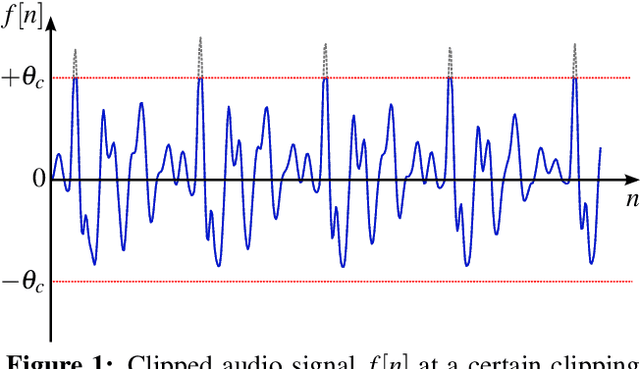

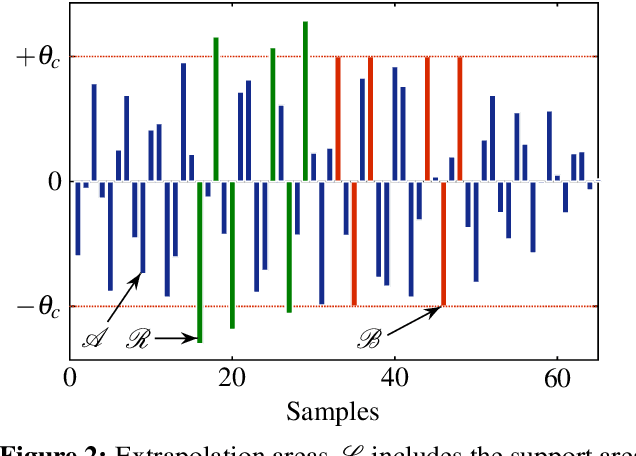
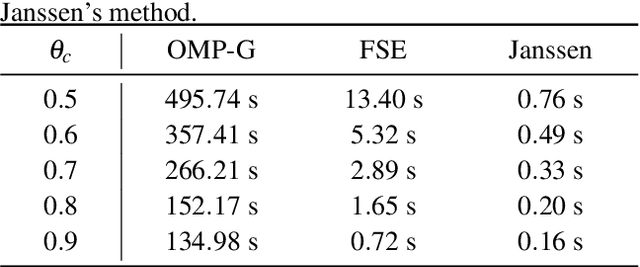
The reconstruction of clipped speech signals is an important task in audio signal processing to achieve an enhanced audio quality for further processing. In this paper, Frequency Selective Extrapolation (FSE), which is commonly used for error concealment or the reconstruction of incomplete image data, is adapted to be able to restore audio signals which are distorted from clipping. For this, FSE generates a model of the signal as an iterative superposition of Fourier basis functions. Clipped samples can then be replaced by estimated samples from the model. The performance of the proposed algorithm is evaluated by using different speech test data sets. Compared to other state-of-the-art declipping algorithms, this leads to a maximum gain in SNR of up to 3:5 dB and an average gain of 1 dB.
Korean Tokenization for Beam Search Rescoring in Speech Recognition
Mar 28, 2022
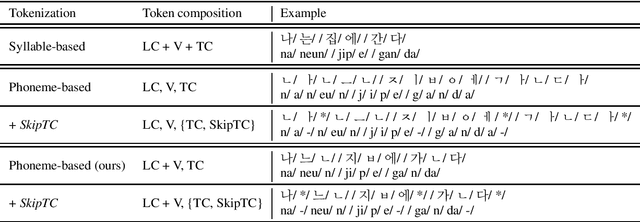
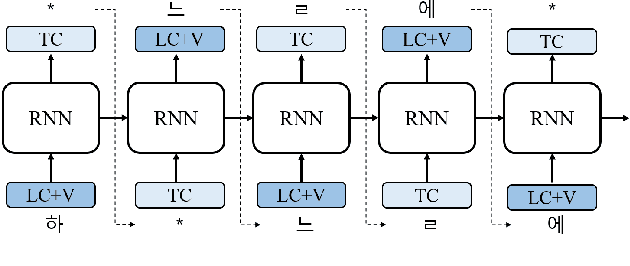
The performance of automatic speech recognition (ASR) models can be greatly improved by proper beam-search decoding with external language model (LM). There has been an increasing interest in Korean speech recognition, but not many studies have been focused on the decoding procedure. In this paper, we propose a Korean tokenization method for neural network-based LM used for Korean ASR. Although the common approach is to use the same tokenization method for external LM as the ASR model, we show that it may not be the best choice for Korean. We propose a new tokenization method that inserts a special token, SkipTC, when there is no trailing consonant in a Korean syllable. By utilizing the proposed SkipTC token, the input sequence for LM becomes very regularly patterned so that the LM can better learn the linguistic characteristics. Our experiments show that the proposed approach achieves a lower word error rate compared to the same LM model without SkipTC. In addition, we are the first to report the ASR performance for the recently introduced large-scale 7,600h Korean speech dataset.
Generative Data Augmentation Guided by Triplet Loss for Speech Emotion Recognition
Aug 09, 2022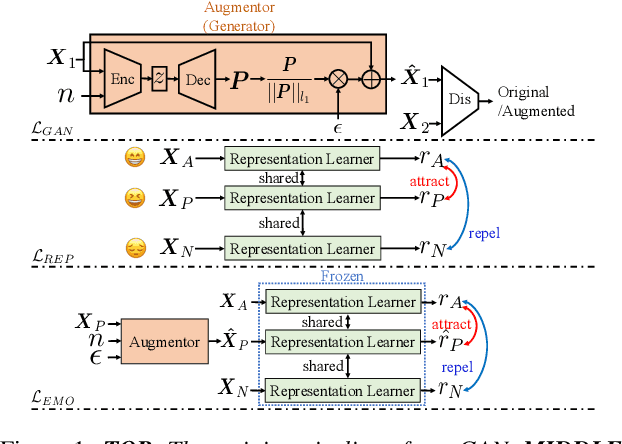
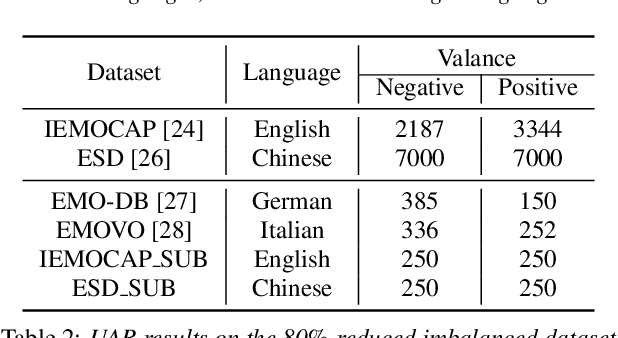
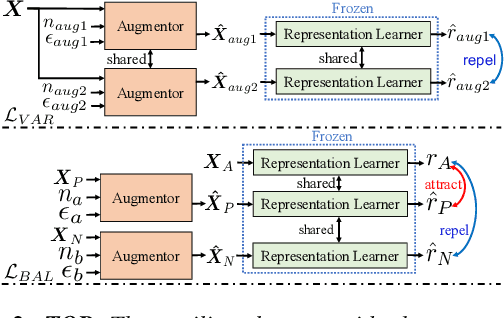
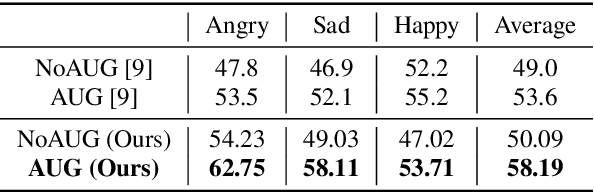
Speech Emotion Recognition (SER) is crucial for human-computer interaction but still remains a challenging problem because of two major obstacles: data scarcity and imbalance. Many datasets for SER are substantially imbalanced, where data utterances of one class (most often Neutral) are much more frequent than those of other classes. Furthermore, only a few data resources are available for many existing spoken languages. To address these problems, we exploit a GAN-based augmentation model guided by a triplet network, to improve SER performance given imbalanced and insufficient training data. We conduct experiments and demonstrate: 1) With a highly imbalanced dataset, our augmentation strategy significantly improves the SER performance (+8% recall score compared with the baseline). 2) Moreover, in a cross-lingual benchmark, where we train a model with enough source language utterances but very few target language utterances (around 50 in our experiments), our augmentation strategy brings benefits for the SER performance of all three target languages.
Fearless Steps Challenge Phase-1 Evaluation Plan
Nov 03, 2022
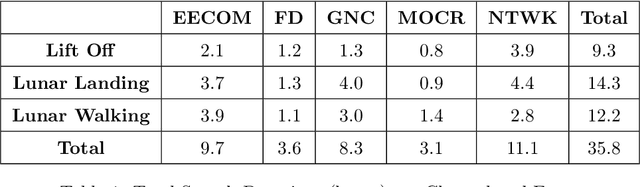
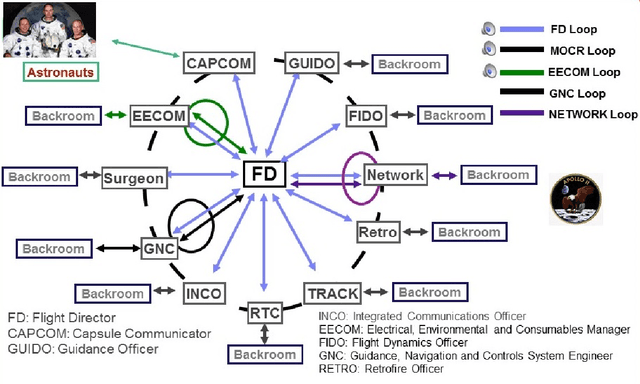
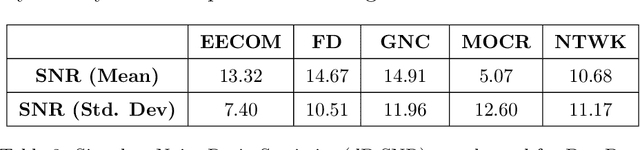
The Fearless Steps Challenge 2019 Phase-1 (FSC-P1) is the inaugural Challenge of the Fearless Steps Initiative hosted by the Center for Robust Speech Systems (CRSS) at the University of Texas at Dallas. The goal of this Challenge is to evaluate the performance of state-of-the-art speech and language systems for large task-oriented teams with naturalistic audio in challenging environments. Researchers may select to participate in any single or multiple of these challenge tasks. Researchers may also choose to employ the FEARLESS STEPS corpus for other related speech applications. All participants are encouraged to submit their solutions and results for consideration in the ISCA INTERSPEECH-2019 special session.
Optimization of a Real-Time Wavelet-Based Algorithm for Improving Speech Intelligibility
Feb 05, 2022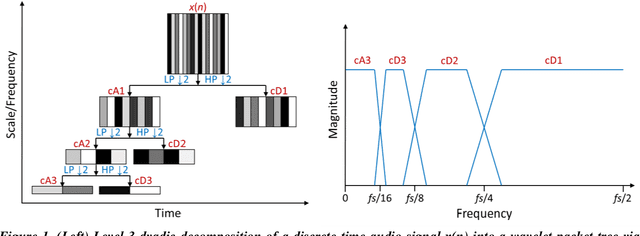
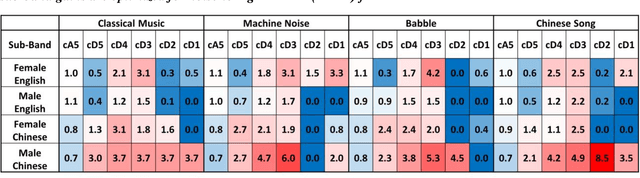

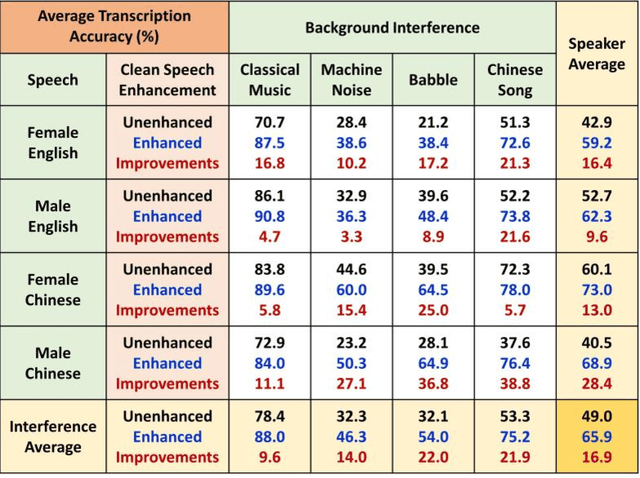
The optimization of a wavelet-based algorithm to improve speech intelligibility is reported. The discrete-time speech signal is split into frequency sub-bands via a multi-level discrete wavelet transform. Various gains are applied to the sub-band signals before they are recombined to form a modified version of the speech. The sub-band gains are adjusted while keeping the overall signal energy unchanged, and the speech intelligibility under various background interference and simulated hearing loss conditions is enhanced and evaluated objectively and quantitatively using Google Speech-to-Text transcription. For English and Chinese noise-free speech, overall intelligibility is improved, and the transcription accuracy can be increased by as much as 80 percentage points by reallocating the spectral energy toward the mid-frequency sub-bands, effectively increasing the consonant-vowel intensity ratio. This is reasonable since the consonants are relatively weak and of short duration, which are therefore the most likely to become indistinguishable in the presence of background noise or high-frequency hearing impairment. For speech already corrupted by noise, improving intelligibility is challenging but still realizable. The proposed algorithm is implementable for real-time signal processing and comparatively simpler than previous algorithms. Potential applications include speech enhancement, hearing aids, machine listening, and a better understanding of speech intelligibility.
Multi-speaker Emotional Text-to-speech Synthesizer
Dec 07, 2021
We present a methodology to train our multi-speaker emotional text-to-speech synthesizer that can express speech for 10 speakers' 7 different emotions. All silences from audio samples are removed prior to learning. This results in fast learning by our model. Curriculum learning is applied to train our model efficiently. Our model is first trained with a large single-speaker neutral dataset, and then trained with neutral speech from all speakers. Finally, our model is trained using datasets of emotional speech from all speakers. In each stage, training samples of each speaker-emotion pair have equal probability to appear in mini-batches. Through this procedure, our model can synthesize speech for all targeted speakers and emotions. Our synthesized audio sets are available on our web page.
* 2 pages; Published in the Proceedings of Interspeech 2021; Presented in Show and Tell; For the published paper, see https://www.isca-speech.org/archive/interspeech_2021/cho21_interspeech.html
Bidirectional Representations for Low Resource Spoken Language Understanding
Nov 24, 2022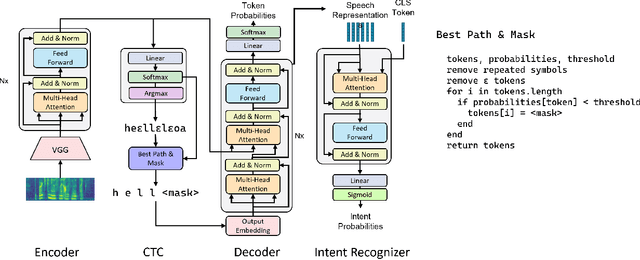


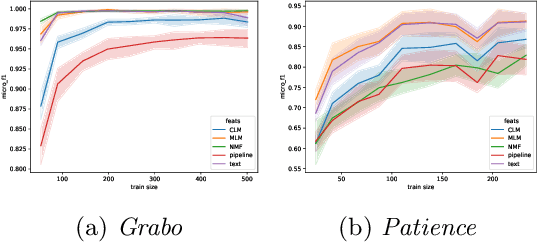
Most spoken language understanding systems use a pipeline approach composed of an automatic speech recognition interface and a natural language understanding module. This approach forces hard decisions when converting continuous inputs into discrete language symbols. Instead, we propose a representation model to encode speech in rich bidirectional encodings that can be used for downstream tasks such as intent prediction. The approach uses a masked language modelling objective to learn the representations, and thus benefits from both the left and right contexts. We show that the performance of the resulting encodings before fine-tuning is better than comparable models on multiple datasets, and that fine-tuning the top layers of the representation model improves the current state of the art on the Fluent Speech Command dataset, also in a low-data regime, when a limited amount of labelled data is used for training. Furthermore, we propose class attention as a spoken language understanding module, efficient both in terms of speed and number of parameters. Class attention can be used to visually explain the predictions of our model, which goes a long way in understanding how the model makes predictions. We perform experiments in English and in Dutch.